
Joint Entity and Relation Extraction Network with Enhanced Explicit and Implicit Semantic Information


Abstract
:1. Introduction
- We propose a Joint Entity and Relation Extraction Network with Enhanced Explicit and Implicit Semantic Information (EINET). On the premise of using the pre-trained model, we introduce explicit semantic information and fully explore the implicit semantic information for joint entity and relation extraction.
- As far as we know, we are the first one to use semantic role labeling information for joint entity and relation extraction. Semantic role labeling can not only provide explicit semantic information for NER and RE, but also helps the model to enhance semantic understanding of text.
- While adopting the BERT pre-trained model, we further explore the implicit semantic information of entities and local contexts based on different Bi-LSTMs. By our separate encoding method, the different features of entities and local contexts are fully explored, so as to purposefully improve the performance of named entity recognition and relation extraction.
- We propose to integrate global semantic information and local context length representation in relation extraction to further improve the model performance.
- Our model shows strong competitiveness on three publicly available joint entity and relation extraction datasets (Conll04, SCIERC, ADE), achieving competitive experimental results.
2. Related Work
2.1. Sequence Tagging Based Method
2.2. Span-Based Method
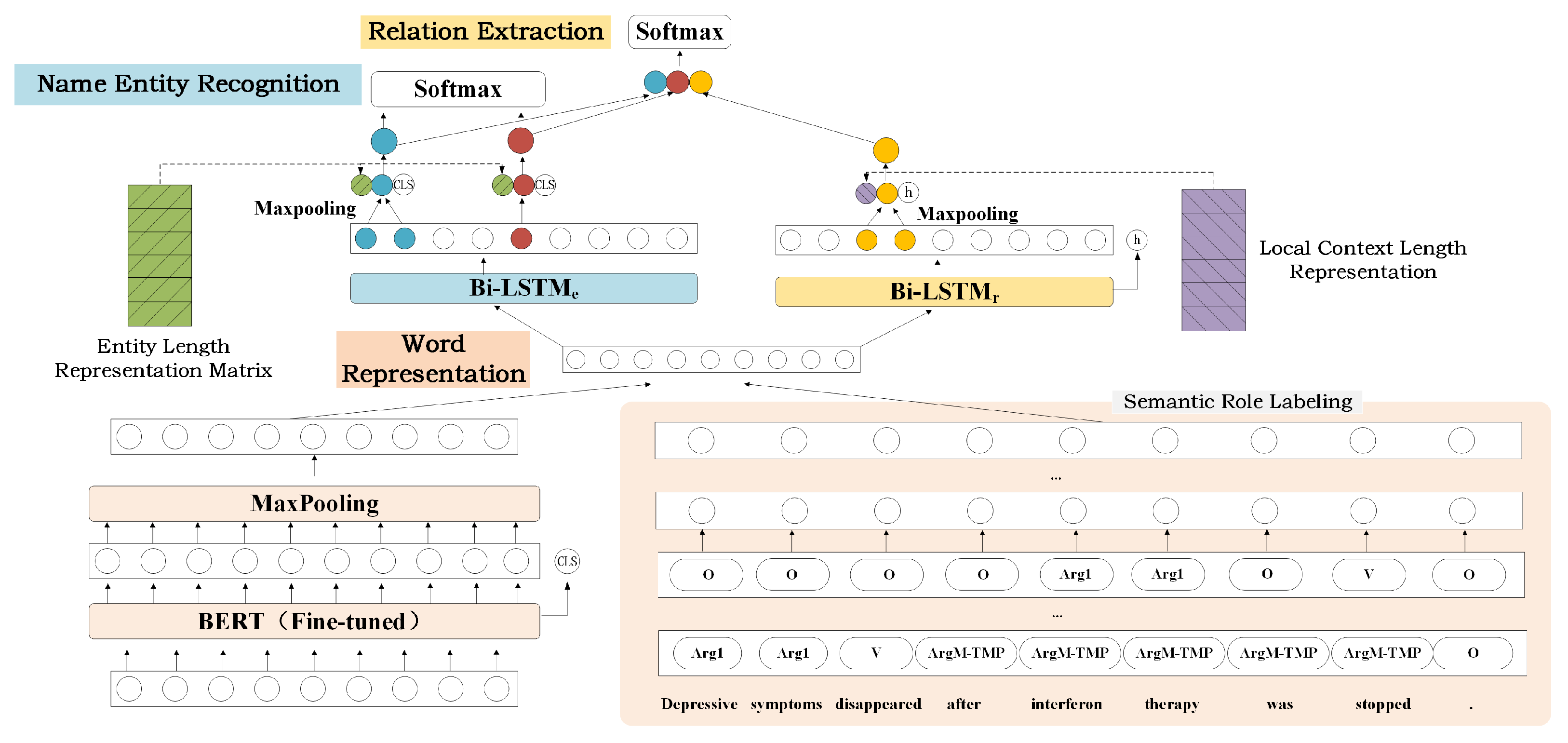
3. Materials and Methods
3.1. Word Representation
3.1.1. Pre-Trained Model
3.1.2. Semantic Role Labeling Information
3.2. Named Entity Recognition
3.3. Relation Extraction
4. Experiment and Result Analysis
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Implementation Details
4.2. Comparison of Results on Datasets
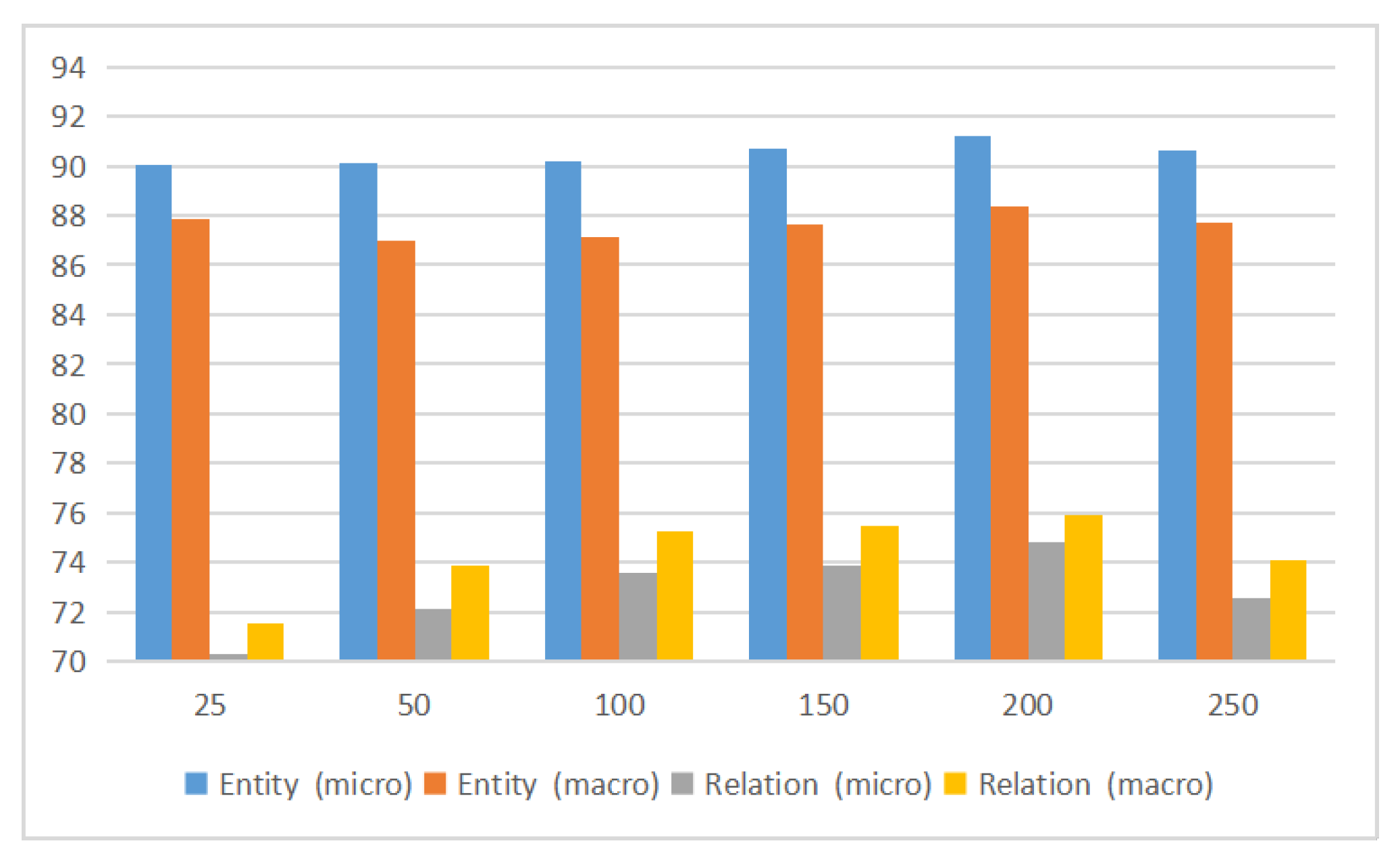
4.3. Ablation Analysis
4.4. Visualization
4.5. Error Cases
- (1)
- Incorrect spans: A common error is the prediction of a slightly incorrect entity span, usually with one more or one less word than the ground truth. Here, “interferon alfa” should be marked as an entity but we marke “interferon” as one entity. This error occurs particularly often in domain-specific ADE and SciERC datasets.
- (2)
- Logical: Sometimes, the relationship between entities is not explicitly described in the sentence, but can be logically inferred from the context. In the case described, the “Work-For” relationship between “Robert Bernero” and “DOE” needs to be inferred from some information (“Robert Bernero, chief of waste disposal for the commission” and “the commission refers to DOE”).
- (3)
- Missing annotation: There are some cases where a correct prediction is missing in the ground truth. Here, in addition to the correct prediction (Shoshone-Bannock, Located-In, Idaho), EIENT also outputs (Hatcher, Live-In, Onondaga territory), (Hatcher, Live-In, Shoshone-Bannock) and (Hatcher, Live-In, Idaho), which are correct but unmarked.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| NER | Named Entity Recognition |
| RE | Relation Extraction |
| SRL | Semantic Role Labeling |
| BERT | Bidirectional Encoder Representation from Transformers |
| Bi-LSTM | Bi-directional Long Short-Term Memory |
| EINET | Joint Entity and Relation Extraction Network with Enhanced Explicit and |
| Implicit Semantic Information | |
| OOV | Out of Vocabulary |
References
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Conference of the Association for Computational Linguistics (ACL 2019), Florence, Italy, 28 July–2 August 2019; Volume 1, pp. 2978–2988. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, W.; Xie, Y.; Lin, A.; Li, X.; Tan, L.; Xiong, K.; Li, M.; Lin, J. End-to-End Open-Domain Question Answering with BERTserini. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; pp. 72–77. [Google Scholar]
- Chatterjee, A.; Narahari, K.N.; Joshi, M.; Agrawal, P. SemEval-2019 Task 3: EmoContext Contextual Emotion Detection in Text. In Proceedings of the13th International Workshop on Semantic Evaluation (SemEval@NAACL-HLT 2019), Minneapolis, MN, USA, 6–7 June 2019; pp. 39–48. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhao, H.; Li, Z.; Zhang, S.; Zhou, X.; Zhou, X. Semantics-Aware BERT for Language Understanding. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA, 7–12 February 2020; pp. 9628–9635. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. SG-Net: Syntax-Guided Machine Reading Comprehension. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA, 7–12 February 2020; pp. 9636–9643. [Google Scholar]
- Geng, Z.; Zhang, Y.; Han, Y. Joint entity and relation extraction model based on rich semantics. Neurocomputing 2021, 429, 132–140. [Google Scholar] [CrossRef]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar]
- Takanobu, R.; Zhang, T.; Liu, J.; Huang, M. A Hierarchical Framework for Relation Extraction with Reinforcement Learning. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI 2019), Honolulu, HI, USA, 27 January–1 February 2019; pp. 7072–7079. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL 2018), Melbourne, VIC, Australia, 15–20 July 2018; Volume 1, pp. 506–514. [Google Scholar]
- Zeng, D.; Zhang, H.; Liu, Q. CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA, 7–12 February 2020; pp. 9507–9514. [Google Scholar]
- Yu, B.; Zhang, Z.; Shu, X.; Liu, T.; Wang, Y.; Wang, B.; Li, S. Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy. In Proceedings of the ECAI 2020—24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2282–2289. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Yuan, Y.; Zhou, X.; Pan, S.; Zhu, Q.; Song, Z.; Guo, L. A Relation-Specific Attention Network for Joint Entity and Relation Extraction. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI 2020), Yokohama, Japan, 11–17 June 2020; pp. 4054–4060. [Google Scholar]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Adversarial training for multi-context joint entity and relation extraction. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2830–2836. [Google Scholar]
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3219–3232. [Google Scholar]
- Li, X.; Yin, F.; Sun, Z.; Li, X.; Yuan, A.; Chai, D.; Zhou, M.; Li, J. Entity-Relation Extraction as Multi-Turn Question Answering. In Proceedings of the 57th Conference of the Association for Computational Linguistics (ACL 2019), Florence, Italy, 28 July–2 August 2019; Volume 1, pp. 1340–1350. [Google Scholar]
- Zhao, T.; Yan, Z.; Cao, Y.; Li, Z. Asking Effective and Diverse Questions: A Machine Reading Comprehension based Framework for Joint Entity-Relation Extraction. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI 2020), Yokohama, Japan, 7–15 January 2020; pp. 3948–3954. [Google Scholar]
- Zhao, T.; Yan, Z.; Cao, Y.; Li, Z. A Unified Multi-Task Learning Framework for Joint Extraction of Entities and Relations. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI 2021), Online, 2–9 February 2021; pp. 14524–14531. [Google Scholar]
- Dixit, K.; Al-Onaizan, Y. Span-Level Model for Relation Extraction. In Proceedings of the 57th Conference of the Association for Computational Linguistics (ACL 2019), Florence, Italy, 28 July–2 August 2019; Volume 1, pp. 5308–5314. [Google Scholar]
- Luan, Y.; Wadden, D.; He, L.; Shah, A.; Ostendorf, M.; Hajishirzi, H. A general framework for information extraction using dynamic span graphs. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 3036–3046. [Google Scholar]
- Chen, J.; Yuan, C.; Wang, X.; Bai, Z. MrMep: Joint Extraction of Multiple Relations and Multiple Entity Pairs Based on Triplet Attention. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL 2019), Hong Kong, China, 3–4 November 2019; pp. 593–602. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wadden, D.; Wennberg, U.; Luan, Y.; Hajishirzi, H. Entity, Relation, and Event Extraction with Contextualized Span Representations. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5783–5788. [Google Scholar]
- Eberts, M.; Ulges, A. Span-Based Joint Entity and Relation Extraction with Transformer Pre-Training. In Proceedings of the ECAI 2020—24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2006–2013. [Google Scholar]
- Ji, B.; Yu, J.; Li, S.; Ma, J.; Wu, Q.; Tan, Y.; Liu, H. Span-based Joint Entity and Relation Extraction with Attention-based Span-specific and Contextual Semantic Representations. In Proceedings of the 28th International Conference on Computational Linguistics (COLING 2020), Barcelona, Spain, 8–13 December 2020; pp. 88–99. [Google Scholar]
- Shen, Y.; Ma, X.; Tang, Y.; Lu, W. A Trigger-Sense Memory Flow Framework for Joint Entity and Relation Extraction. In Proceedings of the WWW ’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1704–1715. [Google Scholar]
- Roth, D.; Yih, W. A Linear Programming Formulation for Global Inference in Natural Language Tasks. In Proceedings of the Eighth Conference on Computational Natural Language Learning (CoNLL 2004), Boston, MA, USA, 6–7 May 2004; pp. 1–8. [Google Scholar]
- Gupta, P.; Schutze, H.; Andrassy, B. Table Filling Multi-Task Recurrent Neural Network for Joint Entity and Relation Extraction. In Proceedings of the COLING 2016—26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 2537–2547. [Google Scholar]
- Gurulingappa, H.; Rajput, A.M.; Roberts, A.; Fluck, J.; Hofmann-Apitius, M.; Toldo, L. Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. J. Biomed. Inform. 2012, 45, 885–892. [Google Scholar] [CrossRef] [PubMed]
- Tran, T.; Kavuluru, R. Neural Metric Learning for Fast End-to-End Relation Extraction. arXiv 2019, arXiv:1905.07458. [Google Scholar]
- Nguyen, D.Q.; Verspoor, K. End-to-End Neural Relation Extraction Using Deep Biaffine Attention. In Proceedings of the Advances in Information Retrieval—41st European Conference on IR Research (ECIR 2019), Cologne, Germany, 14–18 April 2019; pp. 729–738. [Google Scholar]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 2018, 114, 34–45. [Google Scholar] [CrossRef] [Green Version]
- Chi, R.; Wu, B.; Hu, L.; Zhang, Y. Enhancing Joint Entity and Relation Extraction with Language Modeling and Hierarchical Attention. In Proceedings of the Web and Big Data—Third International Joint Conference (APWeb-WAIM 2019), Chengdu, China, 1–3 August 2019; pp. 314–328. [Google Scholar]
- Wang, J.; Lu, W. Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), Online, 16–20 November 2020; pp. 1706–1721. [Google Scholar]
- Ye, D.; Lin, Y.; Li, P.; Sun, M. Packed Levitated Marker for Entity and Relation Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 4904–4917. [Google Scholar]
- Li, F.; Zhang, M.; Fu, G.; Ji, D. A neural joint model for entity and relation extraction from biomedical text. BMC Bioinform. 2017, 18, 198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Sun, C.; Wu, Y.; Zhou, H.; Li, L.; Yan, J. UniRE: A Unified Label Space for Entity Relation Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics, Online, 1–6 August 2021; pp. 220–231. [Google Scholar]
- Yan, Z.; Zhang, C.; Fu, J.; Zhang, Q.; Wei, Z. A Partition Filter Network for Joint Entity and Relation Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP 2021), Punta Cana, Dominican Republic, 7–11 November 2021; pp. 185–197. [Google Scholar]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2021), Online, 6–11 June 2021; pp. 50–61. [Google Scholar]
- Sai, S.T.Y.S.; Chakraborty, P.; Dutta, S.; Sanyal, D.K.; Das, P.P. Joint Entity and Relation Extraction from Scientific Documents: Role of Linguistic Information and Entity Types. In Proceedings of the 2nd Workshop on Extraction and Evaluation of Knowledge Entities from Scientific Documents (EEKE 2021), Online, 29–30 September 2021; pp. 15–19. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Entity | Relation | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| Relation-Metric [32] ‡ | 84.46 | 84.67 | 84.57 | 67.97 | 58.18 | 62.68 |
| Biaffine Attention [33] ‡ | - | - | 86.20 | - | - | 64.40 |
| Multi-turn QA [18] † | 89.00 | 86.60 | 87.80 | 69.20 | 68.20 | 68.90 |
| Multi-head + AT [16] ‡ | - | - | 83.61 | - | - | 61.95 |
| Multi-head [34] ‡ | 83.75 | 84.06 | 83.90 | 63.75 | 60.43 | 62.04 |
| Hierarchical Attention [35] * | - | - | 86.51 | - | - | 63.32 |
| SpERT [26] † | 88.25 | 89.64 | 88.94 | 73.04 | 70.00 | 71.47 |
| SpERT [26] ‡ | 85.78 | 86.84 | 86.25 | 74.75 | 71.52 | 72.87 |
| MRC4ERE++ [19] * | 89.30 | 88.50 | 88.90 | 72.20 | 71.50 | 71.90 |
| UMT w/ NLGQ [20] * | 88.70 | 88.80 | 88.80 | 72.90 | 71.60 | 72.20 |
| UMT w/ PseudoGQ [20] * | 88.80 | 89.00 | 88.90 | 73.20 | 71.60 | 72.40 |
| TriMF [28] † | 89.26 | 90.34 | 90.30 | 73.01 | 71.63 | 72.35 |
| Two are better than one [36] † | - | - | 90.10 | - | - | 73.80 |
| Two are better than one [36] ‡ | - | - | 86.90 | - | - | 75.80 |
| EINET † | 92.43 | 90.22 | 91.31 | 77.15 | 72.78 | 74.90 |
| EINET ‡ | 90.65 | 86.70 | 88.51 | 77.98 | 74.16 | 75.91 |
| Model | Entity | Relation | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| SciIE [17] | 67.20 | 61.50 | 64.20 | 47.60 | 33.50 | 39.30 |
| DyGIE [22] | - | - | 65.20 | - | - | 41.46 |
| DyGIE++ [25] | - | - | 67.50 | - | - | 48.40 |
| SpERT [26] | 70.87 | 69.79 | 70.33 | 53.40 | 48.54 | 50.84 |
| UNIRE [39] | 65.80 | 71.10 | 68.40 | 37.30 | 36.60 | 36.90 |
| PFN [40] | - | - | 66.80 | - | - | 38.40 |
| PURE [41] | - | - | 68.90 | - | - | 50.10 |
| TriMF [28] | 70.18 | 70.17 | 70.17 | 52.63 | 52.32 | 52.44 |
| SpERT.PL [42] | 69.82 | 71.25 | 70.53 | 51.94 | 50.62 | 51.25 |
| PL-Marker [37] | - | - | 69.90 | - | - | 53.20 |
| EINET | 71.26 | 71.43 | 71.34 | 55.34 | 50.73 | 52.93 |
| Model | Entity | Relation | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| BiLSTM + SDP [38] | 82.70 | 86.70 | 84.60 | 67.50 | 75.80 | 71.40 |
| Multi-head [34] | 84.72 | 88.16 | 86.40 | 72.10 | 77.24 | 74.58 |
| Multi-head+AT [16] | - | - | 86.73 | - | - | 75.52 |
| Relation-Metric [32] | 86.16 | 88.08 | 87.11 | 77.36 | 77.25 | 77.29 |
| SpERT(without overlap) [26] | 89.26 | 89.26 | 89.25 | 78.09 | 80.43 | 79.24 |
| SpERT(with overlap) [26] | 88.99 | 89.59 | 89.28 | 77.77 | 79.96 | 78.84 |
| PFN [40] | - | - | 89.60 | - | - | 80.00 |
| Two are better than one [36] | - | - | 89.70 | - | - | 80.10 |
| EINET(without overlap) | 90.03 | 91.12 | 90.57 | 80.38 | 83.79 | 82.04 |
| EINET(with overlap) | 89.69 | 91.29 | 90.48 | 79.74 | 83.11 | 81.38 |
| Model | Entity(F1) | Relation(F1) | |||
|---|---|---|---|---|---|
| Micro-Average | Macro-Average | Micro-Average | Macro-Average | ||
| 1 | EINET | 91.31 | 88.51 | 74.90 | 75.91 |
| 2 | w/o SRL | 89.93 | 87.57 | 72.86 | 73.50 |
| 3 | w/o | 90.39 | 87.50 | 73.73 | 74.62 |
| 4 | w/o | 90.72 | 88.01 | 73.46 | 74.63 |
| 5 | w/o and | 90.19 | 87.33 | 73.16 | 74.39 |
| 6 | w/o global semantics (relation) | 91.01 | 88.10 | 74.26 | 75.78 |
| 7 | w/o local context length information | 90.85 | 87.87 | 74.07 | 75.52 |
| 8 | w/o global semantics (relation) and local context length information | 90.40 | 87.40 | 73.56 | 74.71 |
| 9 | Baseline | 88.94 | 86.25 | 71.47 | 72.87 |
| Error Cases | ||
|---|---|---|
| Incorrect Spans | Sentences | Cutaneous necrosis after injection of polyethylene glycol—modified interferon alfa. |
| Ground Truth | Entities: {’type’: ’Adverse-Effect’, Cutaneous necrosis} {’type’: ’Drug’, interferon alfa} Relations: (interferon alfa, ’Adverse-Effect’, Cutaneous necrosis) | |
| Our Model | Entities: {’type’: ’Adverse-Effect’, Cutaneous necrosis} {’type’: ’Drug’, interferon} Relations: (interferon, ’Adverse-Effect’, Cutaneous necrosis) | |
| Logical | Sentences | “NRC has a broad programmatic concern that the pressure to meet unrealistic schedule milestones may leave DOE insufficient time to plan and to execute proper technical information-gathering activities.” said Robert Bernero, chief of waste disposal for the commission. |
| Ground Truth | Entities: {’type’: ’Org’, NRC} {’type’: ’Org’, DOE} {’type’: ’Peop’, Robert Bernero} Relations: (Robert Bernero, Work-For, DOE) | |
| Our Model | Entities: {’type’: ’Org’, NRC} {’type’: ’Org’, DOE} {’type’: ’Peop’, Robert Bernero} Relations: | |
| Missing Annotation | Sentences | Hatcher also fled to the Onondaga territory but has since moved to a Shoshone-Bannock reservation in Idaho. |
| Ground Truth | Entities: {’type’: ’Peop’, Hatcher } {’type’: ’Loc’, Onondaga territory} {’type’: ’Loc’, Shoshone-Bannock} {’type’: ’Loc’, Idaho} Relations: (Shoshone-Bannock, Located-In, Idaho) | |
| Our Model | Entities: {’type’: ’Peop’, Hatcher } {’type’: ’Loc’, Onondaga territory} {’type’: ’Loc’, Shoshone-Bannock} {’type’: ’Loc’, Idaho} Relations: (Shoshone-Bannock, Located-In, Idaho) (Hatcher, Live-In, Onondaga territory) (Hatcher, Live-In, Shoshone-Bannock) (Hatcher, Live-In, Idaho) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Huang, J. Joint Entity and Relation Extraction Network with Enhanced Explicit and Implicit Semantic Information. Appl. Sci. 2022, 12, 6231. https://doi.org/10.3390/app12126231
Wu H, Huang J. Joint Entity and Relation Extraction Network with Enhanced Explicit and Implicit Semantic Information. Applied Sciences. 2022; 12(12):6231. https://doi.org/10.3390/app12126231
Chicago/Turabian StyleWu, Huiyan, and Jun Huang. 2022. "Joint Entity and Relation Extraction Network with Enhanced Explicit and Implicit Semantic Information" Applied Sciences 12, no. 12: 6231. https://doi.org/10.3390/app12126231