
Heterogeneous Parallel Implementation of Large-Scale Numerical Simulation of Saint-Venant Equations

 , ,
, ,
Abstract
:1. Introduction
2. Governing Equations and Numerical Method
3. Heterogeneous Implementation
4. Performance Optimization and Testing
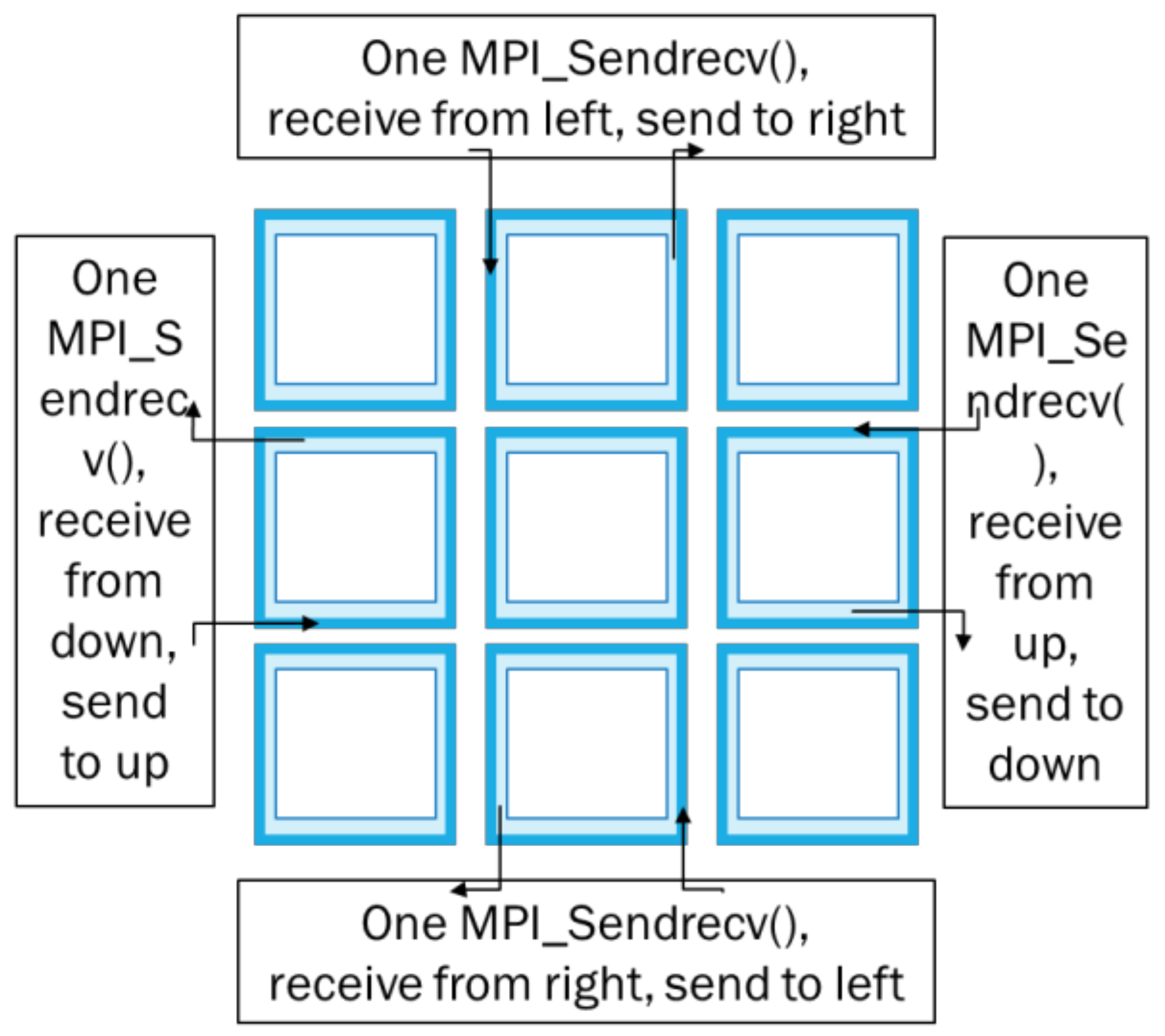
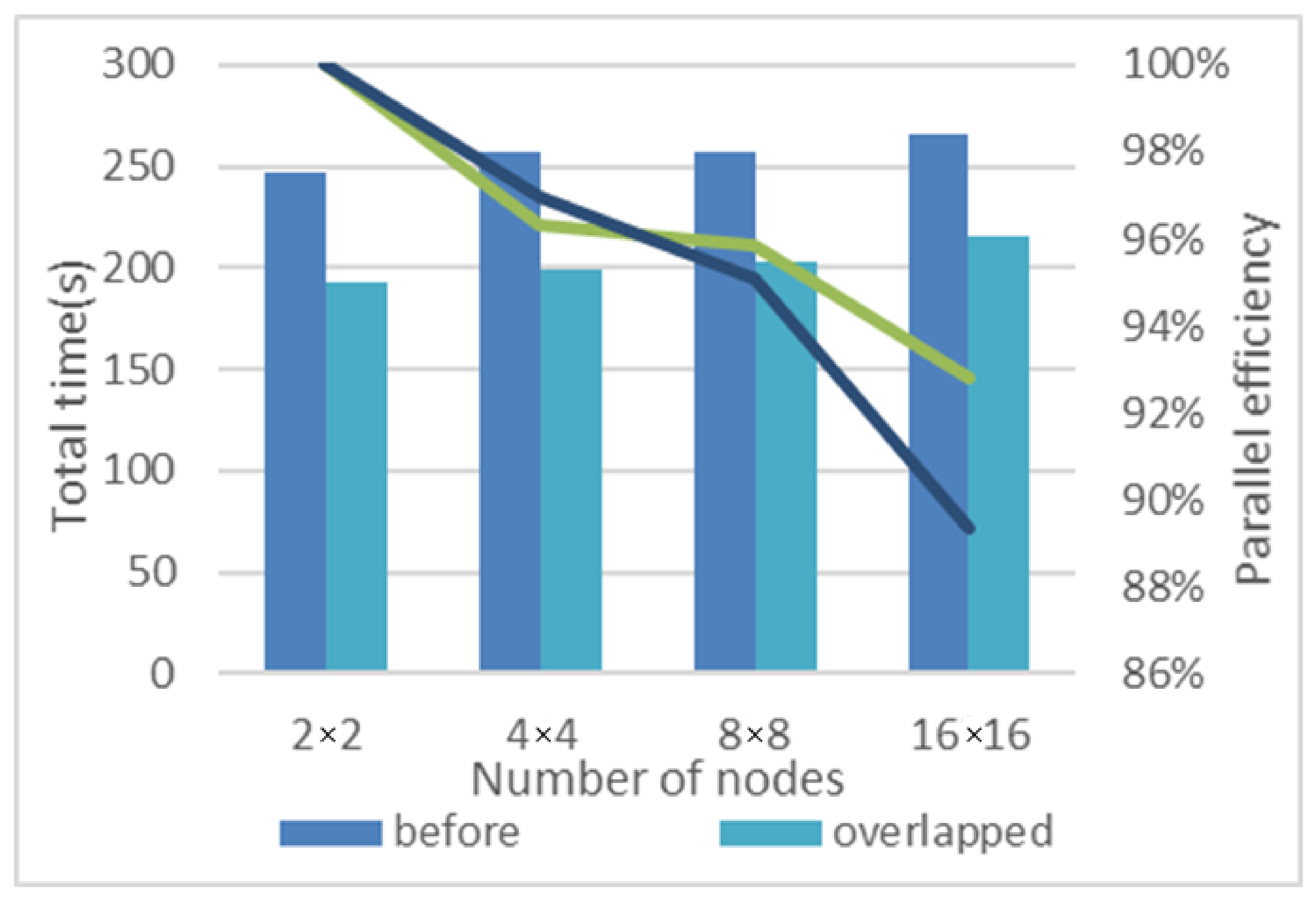
4.1. Overlap Computation and Communication
- Copy data of the ghost cells to send buffers;
- Ghost cell exchange with Isend/Irecv calls;
- Compute (part 1): Update the inner field of the domain;
- Call MPI_Waitall();
- Copy data from receive buffers to the ghost cells;
- Compute (part 2): Update the halo cells;
- Repeat.
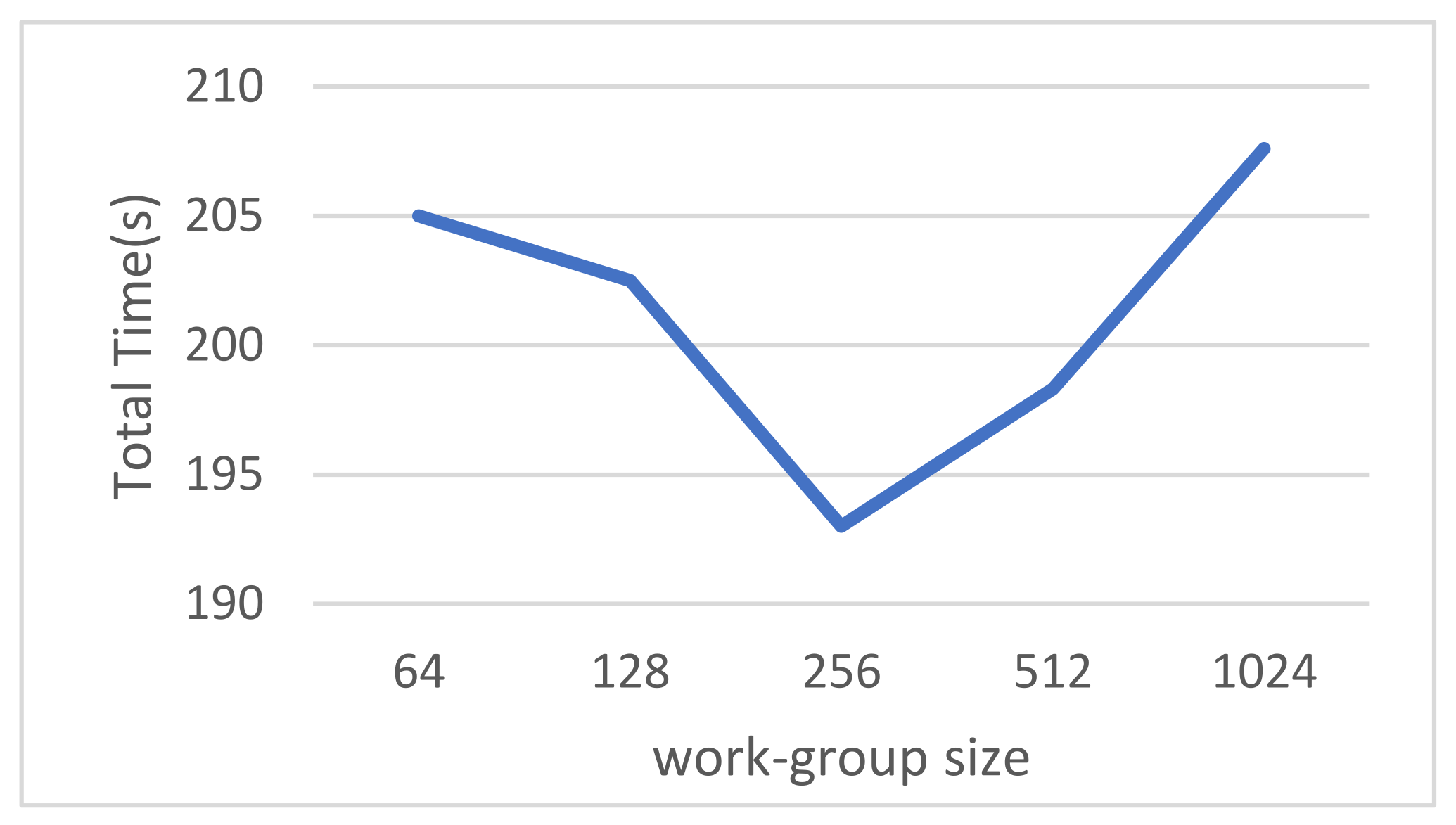
4.2. Work Group Optimization
4.3. Using Local Memory
4.4. Heterogeneous Parallel Performance Testing
4.5. Computational Time Comparison Tests
4.5.1. CPU Single-Core and Multi-Core Comparison
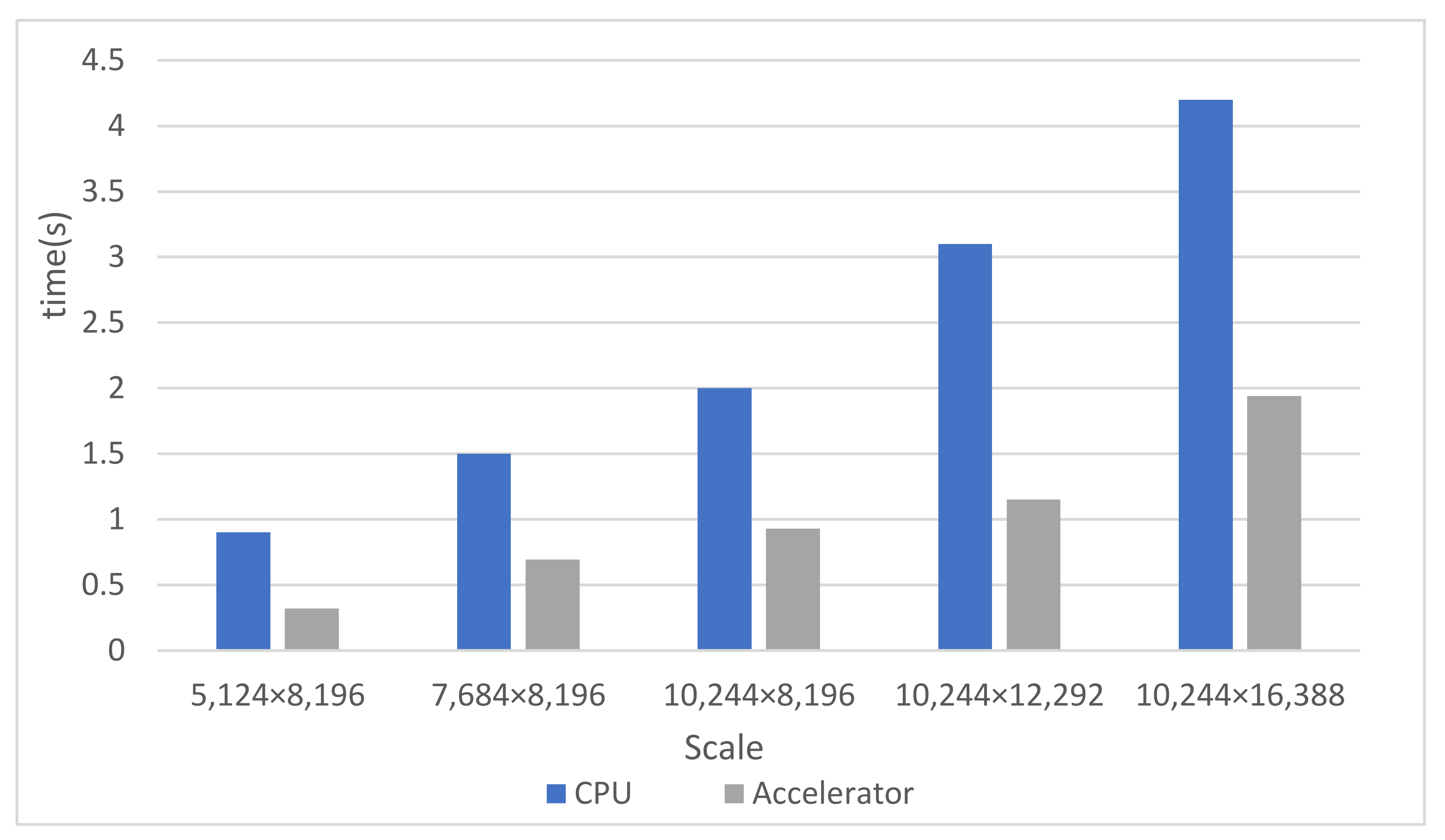
4.5.2. CPU and Accelerators Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Xiang, Y.; Sheng, J.B.; Yang, M.; Zhang, S.C.; Yang, Z.H. Impacts on ecological environment due to dam removal or decommissioning. Chin. J. Geotech. Eng. 2008, 30, 1758. [Google Scholar]
- Saint-Venant, B.D. Theory of unsteady water flow, with application to river floods and to propagation of tides in river channels. Fr. Acad. Sci. 1871, 73, 148–154. [Google Scholar]
- Hu, J. A simple numerical scheme for the 2D shallow-water system. arXiv 2017, arXiv:1801.07441. [Google Scholar]
- Dawson, C.; Mirabito, C.M. The Shallow Water Equations. 2008. Available online: https://users.oden.utexas.edu/~arbogast/cam397/dawson_v2.pdf (accessed on 20 April 2022).
- Garcia, R.; Kahawita, R.A. Numerical solution of the st. venant equations with the maccormack fi-nite-difference scheme. Int. J. Numer. Methods Fluids 2010, 6, 259–274. [Google Scholar] [CrossRef]
- Fiedler, F.R.; Ramirez, J.A. A numerical method for simulating discontinuous shallow flow over an infiltrating surface. Int. J. Numer. Methods Fluids 2000, 32, 219–239. [Google Scholar] [CrossRef]
- Kamboh, S.A.; Sarbini, I.N.; Labadin, J.; Eze, M.O. Simulation of 2D Saint-Venant equations in open channel by using MATLAB. J. IT Asia 2016, 5, 15–22. [Google Scholar] [CrossRef] [Green Version]
- Lacasta, A.; Hernández, M.M.; Murillo, J.; García-Navarro, P. GPU implementation of the 2D shallow water equations for the simulation of rainfall/runoff events. Environ. Earth Sci. 2015, 74, 7295–7305. [Google Scholar] [CrossRef]
- Ding, Z.-Z.; Chu, G.-S.; Hu, C.-J.; Li, Y. Parallelization and optimization of Saint-Venant solver on Sunway many-core processor. Comput. Eng. Sci. 2020, 43, 820–829. [Google Scholar]
- Huang, X. Adaptive mesh refinement for computational aeroacoustics. In Proceedings of the 11th AIAA/CEAS Aeroacoustics Conference, Monterey, CA, USA, 23–25 May 2005. [Google Scholar]
- Zhao, X. A three-dimensional robust volume-of-fluid solver based on the adaptive mesh refinement. Theor. Appl. Mech. Lett. 2021, 11, 100309. [Google Scholar] [CrossRef]
- Bader, M.; Böck, C.; Schwaiger, J.; Vigh, C. Dynamically Adaptive Simulations with Minimal Memory Requirement—Solving the Shallow Water Equations Using Sierpinski Curves. SIAM J. Sci. Comput. 2010, 32, 212–228. [Google Scholar] [CrossRef]
- Tubbs, K.R.; Tsai, T.C. Multilayer shallow water flow using lattice boltzmann method with high performance computing. Adv. Water Resour. 2009, 32, 1767–1776. [Google Scholar] [CrossRef]
- Esteves, M.; Faucher, X.; Galle, S.; Vauclin, M. Overland flow and infiltration modelling for small plots during unsteady rain: Numerical results versus observed values. J. Hydrol. 2000, 228, 265–282. [Google Scholar] [CrossRef]
- Valiani, A.; Caleffi, V.; Zanni, A. Case Study: Malpasset Dam-Break Simulation using a Two-Dimensional Finite Volume Method. J. Hydraul. Eng. 2002, 128, 460–472. [Google Scholar] [CrossRef]
- Caleffi, V.; Valiani, A.; Zanni, A. Finite volume method for simulating extreme flood events in natural channels. J. Hydraul. Res. 2003, 41, 167–177. [Google Scholar] [CrossRef]
- Kim, D.-H.; Cho, Y.-S.; Yi, Y.-K. Propagation and run-up of nearshore tsunamis with HLLC approximate Riemann solver. Ocean Eng. 2007, 34, 1164–1173. [Google Scholar] [CrossRef]
- Bhadke, Y.; Kawale, M. Development of 3D-CFD code for heat conduction process using CUDA. In Proceedings of the 2014 International Conference on Advances in Engineering and Technology Research, ICAETR, Unnao, India, 1–2 August 2014. [Google Scholar] [CrossRef]
- Di Cristo, C.; Greco, M.; Iervolino, M.; Martino, R.; Vacca, A. A remark on finite volume methods for 2D shallow water equations over irregular bottom topography. J. Hydraul. Res. 2020, 59, 337–344. [Google Scholar] [CrossRef]
- Altaie, H.; Dreyfuss, P. Numerical solutions for 2D depth-averaged shallow water equations. Int. Math. Forum 2018, 13, 79–90. [Google Scholar] [CrossRef]
- Balzano, A. Evaluation of methods for numerical simulation of wetting and drying in shallow water flow models. Coast. Eng. 1998, 34, 83–107. [Google Scholar] [CrossRef]
- Heniche, M.; Secretan, Y.; Boudreau, P.; Leclerc, M. A two-dimensional finite element drying-wetting shallow water model for rivers and estuaries. Adv. Water Resour. 2000, 23, 359–372. [Google Scholar] [CrossRef]
- Yang, Z.; Bai, F.; Xiang, K. A lattice Boltzmann model for the open channel flows described by the Saint-Venant equations. R. Soc. Open Sci. 2019, 6, 190439. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Guo, M.; Zhao, Y.; Jiang, J. GPUs-RRTMG_LW: High-efficient and scalable computing for a longwave radiative transfer model on multiple GPUs. J. Supercomput. 2020, 77, 4698–4717. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, Y.; Jiang, J.; Zhang, H. A Novel GPU-Based Acceleration Algorithm for a Longwave Radiative Transfer Model. Appl. Sci. 2020, 10, 649. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhao, Y.; Li, W.; Jiang, J.; Ji, X.; Zomaya, A.Y. Using a GPU to Accelerate a Longwave Radiative Transfer Model with Efficient CUDA-Based Methods. Appl. Sci. 2019, 9, 4039. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hard/Software Environment | Name | Details/Version |
|---|---|---|
| Hard environment (single node) | CPU | 32-core domestic × 86 processor × 1 |
| RAM | 16 GB DDR4 × 8 | |
| Acceleration device | Domestic GPGPU accelerator × 4, 16 GB HBM2 VRAM, bandwidth 1 TB/s | |
| Network | InfiniBand HDR network, Fat-tree topology, 200 Gbps | |
| Software environment | MPI | Openmpi 4.0.4 |
| gcc/g++ | 4.8.5 | |
| OpenMP | 3.1 | |
| Pthread | NPTL 2.17 | |
| OpenCL | Platform: AMD Accelerated Parallel Processing Driver version: 2982.0 OpenCL Standard: OpenCL 2.0 |
| Version | Calculating Time (s) | Sync Time (s) | Total Time (s) |
|---|---|---|---|
| Before | 240.61 | 6 | 246.61 |
| After | 189 | 5 | 194 |
| Workgroup Size | Use Local Memory Size (B) | Test Results (s) |
|---|---|---|
| 128 | 9360 | 84.36 |
| 256 | 18,576 | 83.85 |
| 384 | 27,792 | 84.27 |
| 512 | 37,008 | 84.64 |
| 640 | 46,224 | 84.16 |
| 768 | 55,440 | 84.30 |
| 896 | 64,656 | 84.30 |
| 1024 | 73,872 | Error |
| Workgroup Size | Use Local Memory Size (B) | Test Results (s) |
|---|---|---|
| 128 | 9360 | 37.11 |
| 256 | 18,576 | 37.37 |
| 384 | 27,792 | 37.75 |
| 512 | 37,008 | 36.33 |
| 640 | 46,224 | Error |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Y.; Li, Q.; Zhao, Z.; Zhang, J.; Gao, L.; Yuan, W.; Lu, Z.; Nie, N.; Shang, X.; Tao, S. Heterogeneous Parallel Implementation of Large-Scale Numerical Simulation of Saint-Venant Equations. Appl. Sci. 2022, 12, 5671. https://doi.org/10.3390/app12115671
Qi Y, Li Q, Zhao Z, Zhang J, Gao L, Yuan W, Lu Z, Nie N, Shang X, Tao S. Heterogeneous Parallel Implementation of Large-Scale Numerical Simulation of Saint-Venant Equations. Applied Sciences. 2022; 12(11):5671. https://doi.org/10.3390/app12115671
Chicago/Turabian StyleQi, Yongmeng, Qiang Li, Zhigang Zhao, Jiahua Zhang, Lingyun Gao, Wu Yuan, Zhonghua Lu, Ningming Nie, Xiaomin Shang, and Shunan Tao. 2022. "Heterogeneous Parallel Implementation of Large-Scale Numerical Simulation of Saint-Venant Equations" Applied Sciences 12, no. 11: 5671. https://doi.org/10.3390/app12115671