
A Novel Image Encryption Algorithm Based on Voice Key and Chaotic Map

Abstract
:Featured Application
Abstract
1. Introduction
1.1. Analysis of Common Identity Authentication Methods
1.2. Combination of Image Encryption and Identity Recognition Technologies
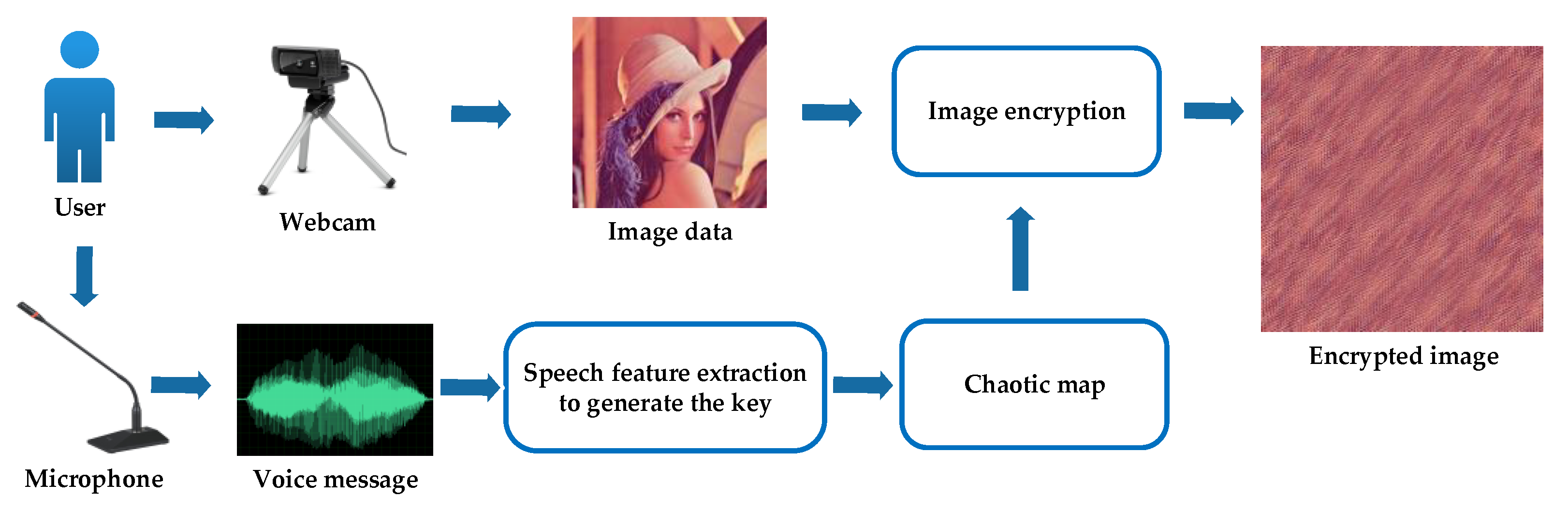
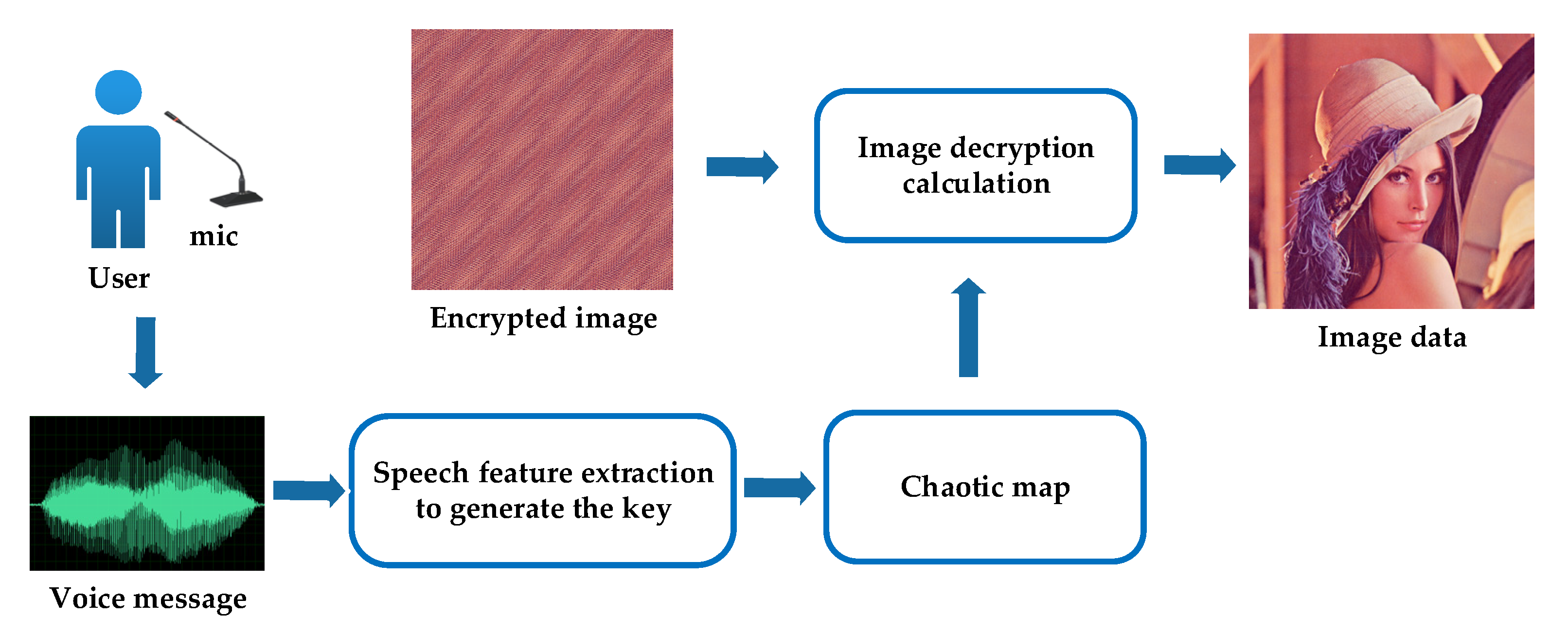
2. Principles of the Proposed Method
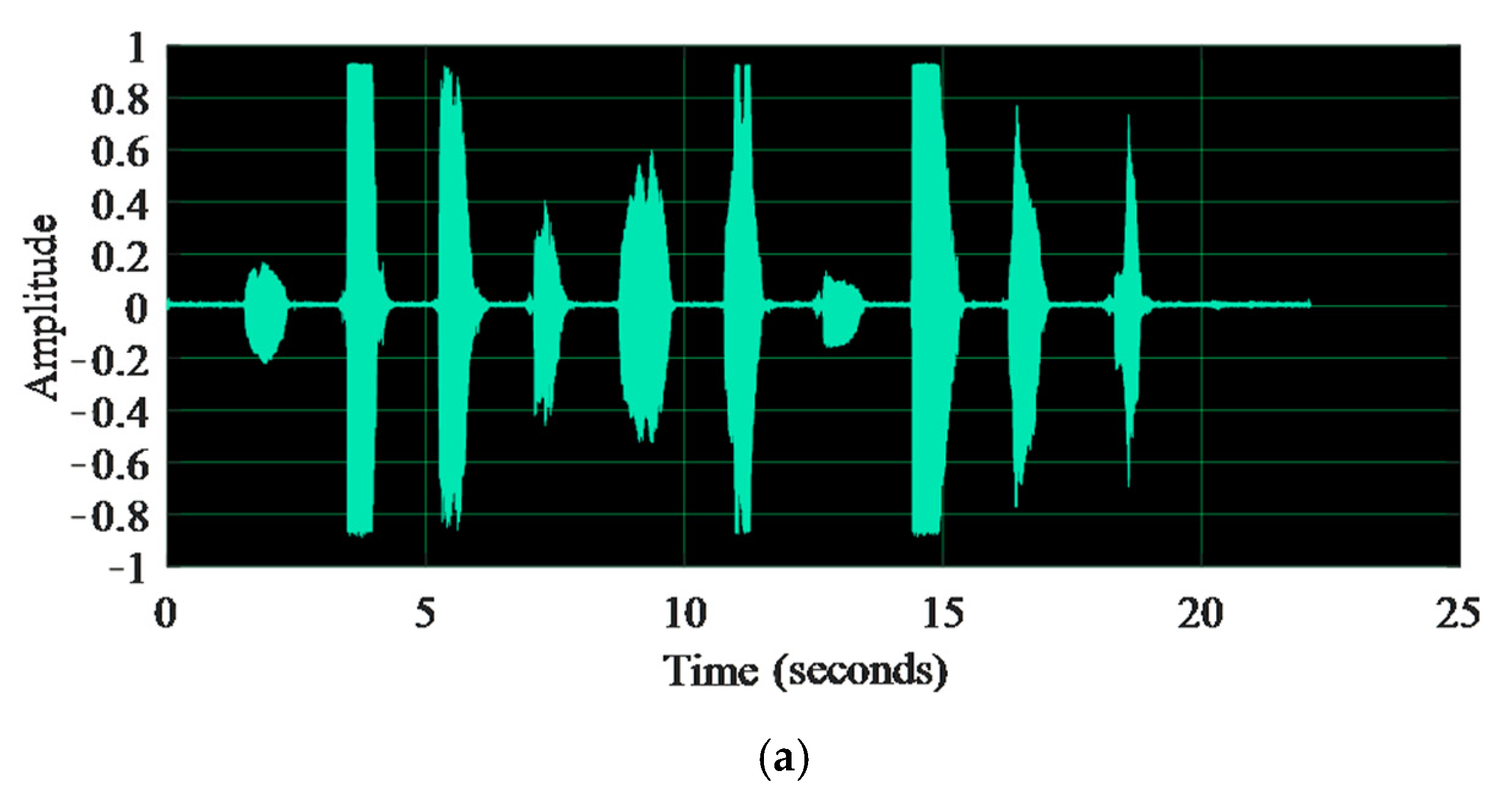
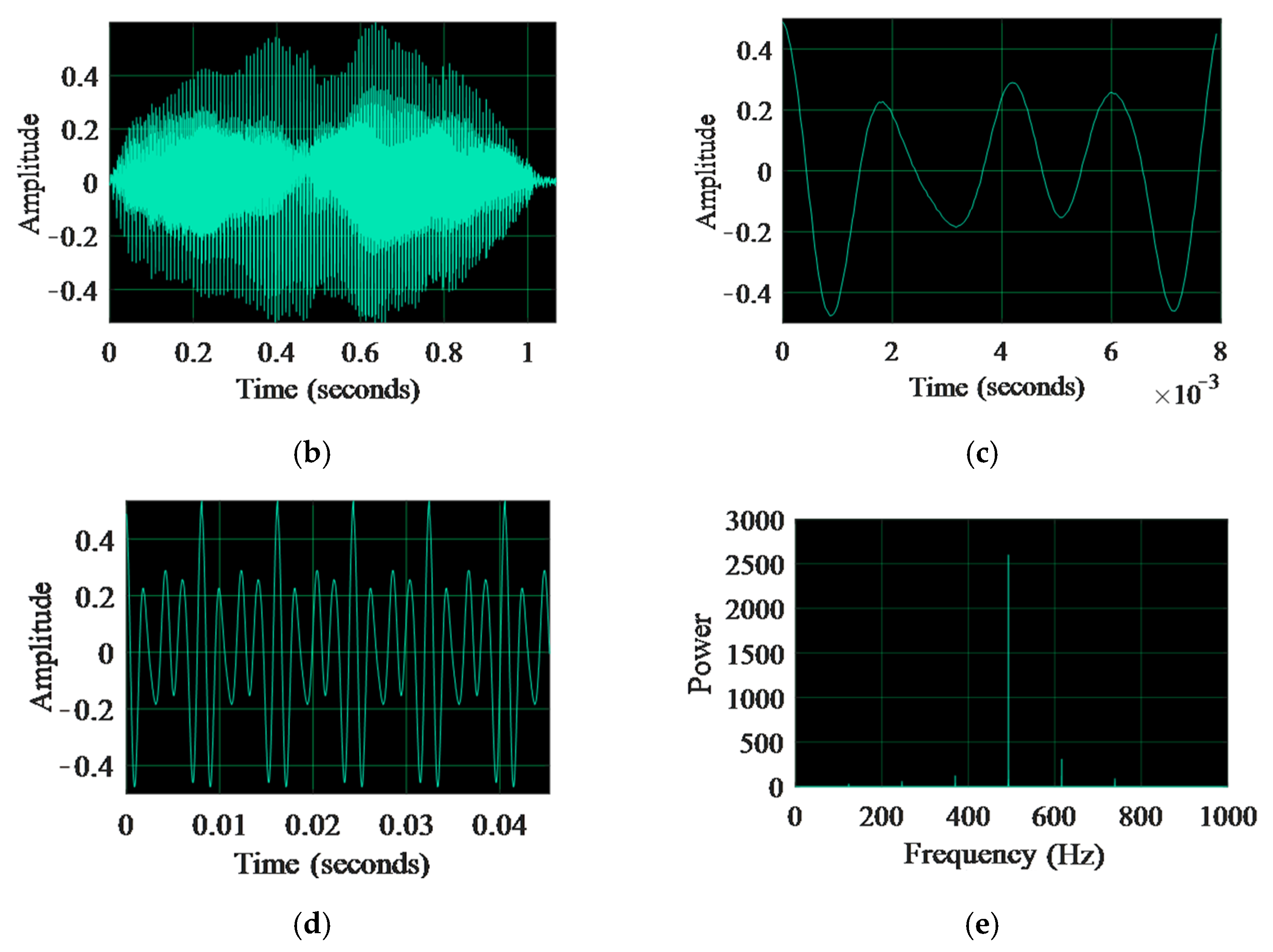
2.1. Voice Key Generation Process
2.2. Proposed Image Encryption and Decryption Algorithm
2.2.1. Encryption Process
| Algorithm 1: Image encryption | |||||||
| Input: (nw1~nw6, k1~k9, fm, image matrix a) | |||||||
| begin | |||||||
| for (i = 1, 3000) do | |||||||
| LnL1 = nw1/k1 | |||||||
| µ1 = k2 + nw3/k3 | |||||||
| LnL1+1=LnL1 × µ1 × (1 − LnL1) | |||||||
| LnL2 = nw2/k4 | |||||||
| µ1 = k5 + nw4/k6 | |||||||
| LnL1+1 = LnL1 × µ1 × (1 − LnL1) | |||||||
| end | |||||||
| m1 = round((LnL1(nw5 + k9 × fm + k7) + 1/2 × the number of rows) | |||||||
| b = round((LnL2(nw6 + k9 × fm + k8) + 1/2 × the number of columns) | |||||||
| for (i = 1, the number of rows) do | |||||||
| for (j = 1, the number of columns) do | |||||||
| matrix scrambling | |||||||
| end | |||||||
| end | |||||||
| return a | |||||||
| end | |||||||
| Algorithm 2: Matrix scrambling | |||||
| Input: (matrix a, m1, b) | |||||
| begin | |||||
| for (i = 1, the number of rows) do | |||||
| m1,=mod(m1, the number of rows) | |||||
| Left cyclic shift (m1) | |||||
| m1 = m1 + b | |||||
| end | |||||
| for (j = 1, the number of columns) do | |||||
| m1,=mod(m1, the number of columns) | |||||
| Downward cyclic shift (m1) | |||||
| m1 = m1 + b | |||||
| end | |||||
| return a | |||||
| end | |||||
2.2.2. Decryption Process
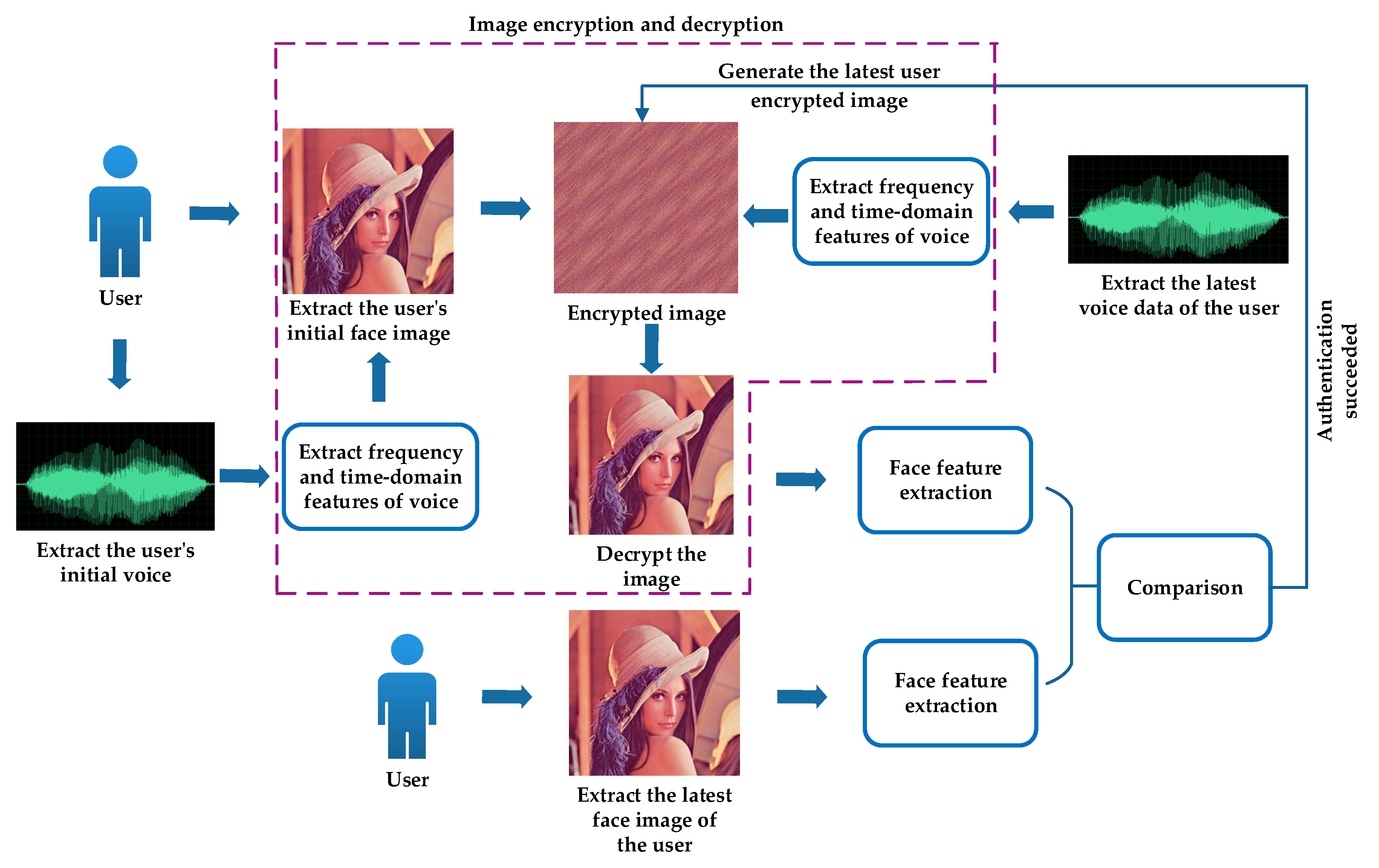
3. Application of the Proposed Image Encryption Algorithm in Identification Technology
4. Experimental Results and Security Analysis
4.1. Experimental Results
4.2. Security Analysis
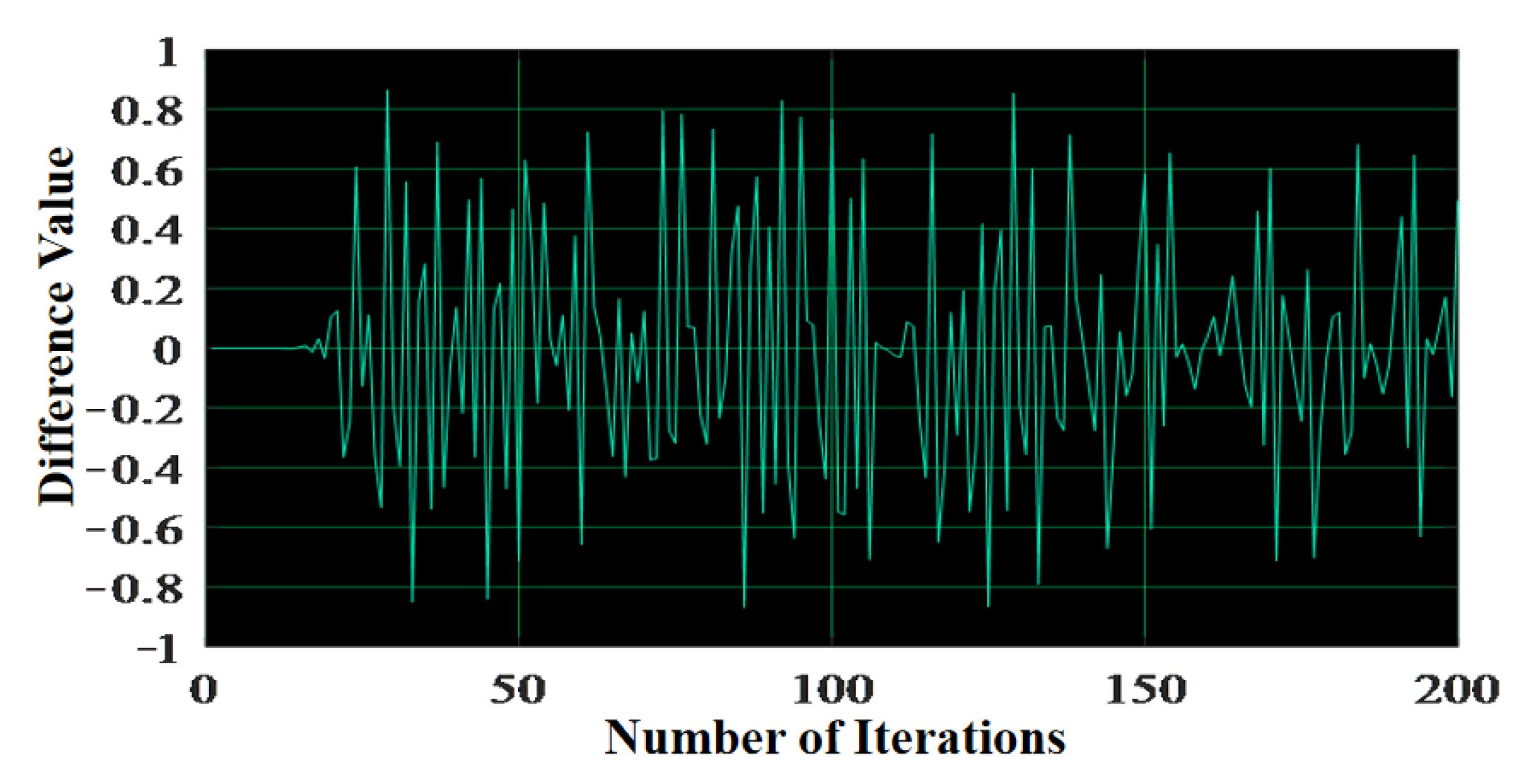
4.2.1. Key Sensitivity Analysis
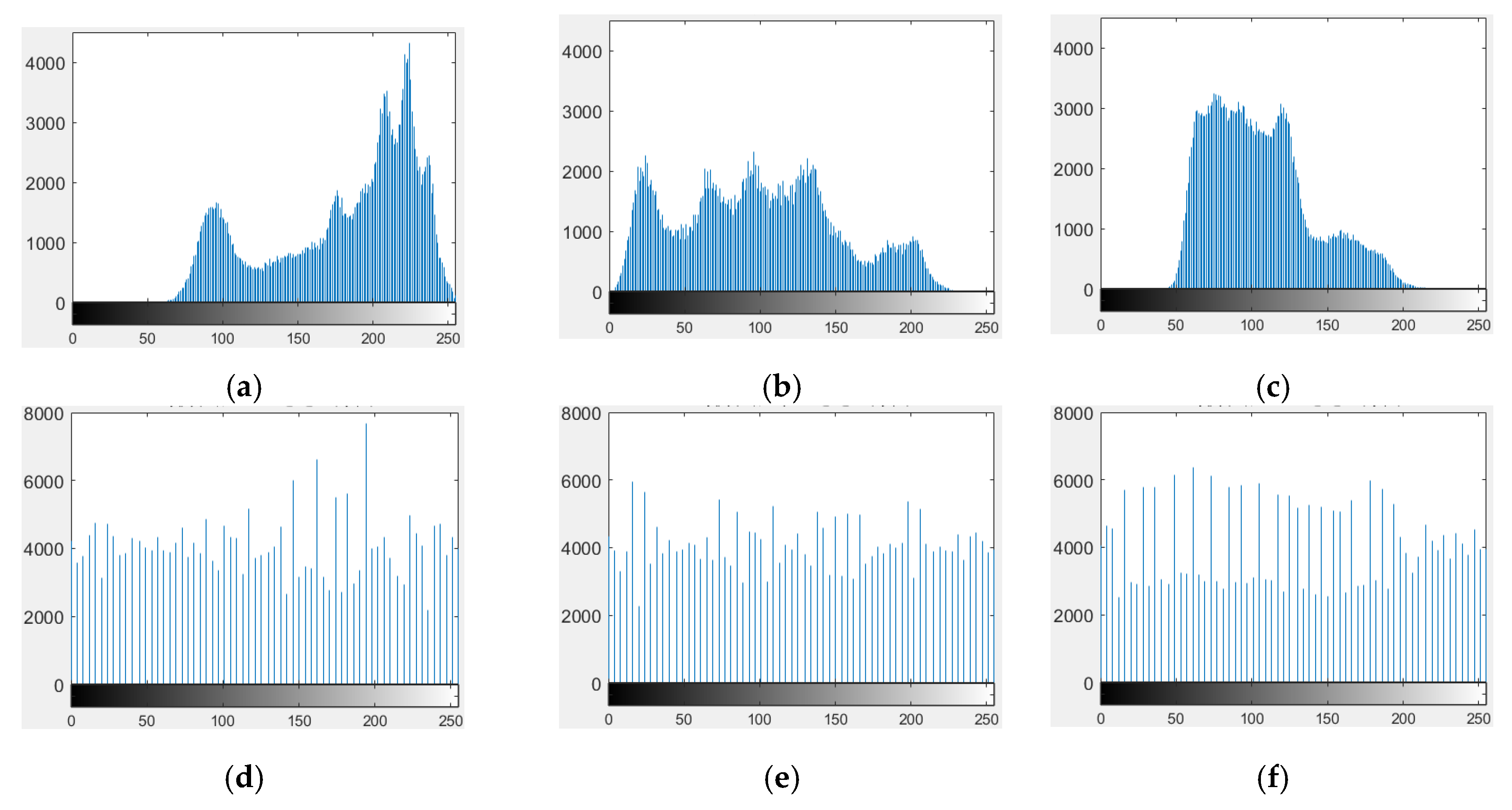
4.2.2. Correlation between Adjacent Pixels

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.2.3. Ability of Resisting Differential Attack
| Fp (Hz) | nw1~nw6 | R | G | B | |||
|---|---|---|---|---|---|---|---|
| NPCR | UACI | NPCR | UACI | NPCR | UACI | ||
| 55 | 5, 4, 2, 3, 2, 4 | 0.9938 | 0.2271 | 0.9951 | 0.2411 | 0.9916 | 0.1521 |
| 55 | 5, 4, 3, 3, 2, 4 | ||||||
| 55 | 5, 4, 2, 3, 2, 4 | 0.9920 | 0.2139 | 0.9946 | 0.2377 | 0.9908 | 0.1497 |
| 56 | 5, 4, 2, 3, 2, 4 | ||||||
| 1200 | 3, 2, 4, 3, 5, 2 | 0.9893 | 0.2105 | 0.9940 | 0.2287 | 0.9891 | 0.1376 |
| 1200 | 3, 2, 5, 3, 5, 2 | ||||||
| 1200 | 3, 2, 4, 3, 5, 2 | 0.9925 | 0.2138 | 0.9943 | 0.2375 | 0.9909 | 0.1496 |
| 1201 | 3, 2, 4, 3, 5, 2 | ||||||
| Ref. [35] | Ref. [36] | Ref. [37] | Ref. [38] | Ref. [39] | |
|---|---|---|---|---|---|
| NPCR (%) | 99.54 | 99.6146 | 99.6048 | 99.4602 | 99.655 |
| UACI (%) | 28.27 | 33.5113 | 33.2966 | 33.2161 | 33.516 |
4.2.4. Key Space Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- How, K.W.; Han, P.Y.; Yin, O.S.; Yen, Y.H. Spatiotemporal spectral histogramming analysis in hand gesture signature recognition. J. Intell. Fuzzy Syst. 2021, 40, 4275–4286. [Google Scholar] [CrossRef]
- Lim, S.L.; Lee, K.L.; Byeon, O.B.; Kim, T.K. Efficient Iris Recognition through Improvement of Feature Vector and Classifier. ETRI J. 2001, 23, 61–70. [Google Scholar] [CrossRef] [Green Version]
- Barkhoda, W.; Akhlaqian, F.; Amiri, M.D.; Nouroozzadeh, M.S. Retina identification based on the pattern of blood vessels using fuzzy logic. EURASIP J. Adv. Signal Process. 2011, 2011, 113. [Google Scholar] [CrossRef] [Green Version]
- Parvathi, R.; Sankar, M. An Exhaustive Multi Factor Face Authentication Using Neuro-Fuzzy Approach. Wirel. Pers. Commun. 2019, 109, 2353–2375. [Google Scholar] [CrossRef]
- Park, H.; Kim, T. User Authentication Method via Speaker Recognition and Speech Synthesis Detection. Secur. Commun. Netw. 2022, 2022, 5755785. [Google Scholar] [CrossRef]
- Lakkannavar, B.F.; Kodabagi, M.M.; Naik, S.P. Signature Recognition and Verification Using Zonewise Statistical Features. In International Conference on Computer Networks, Big Data and IoT; Springer: Cham, Switzerland, 2020; pp. 748–757. [Google Scholar] [CrossRef]
- Boucherit, I.; Zmirli, M.O.; Hentabli, H.; Rosdi, B.A. Finger vein identification using deeply-fused Convolutional Neural Network. J. King Saud Univ.-Comput. Inf. Sci. 2020, 34, 646–656. [Google Scholar] [CrossRef]
- Sodhro, A.H.; Sennersten, C.; Ahmad, A. Towards Cognitive Authentication for Smart Healthcare Applications. Sensors 2022, 22, 2101. [Google Scholar] [CrossRef]
- Khan, A.; Geng, S.; Zhao, X.; Shah, Z.; Jan, M.U.; Abdelbaky, M.A. Design of MIMO antenna with an enhanced isolation technique. Electronics 2020, 9, 1217. [Google Scholar] [CrossRef]
- Noor, K.; Jan, T.; Basheri, M.; Ali, A.; Khalil, R.A.; Zafar, M.H.; Ashraf, M.; Babar, M.I.; Shah, S.W. Performances Enhancement of Fingerprint Recognition System Using Classifiers. IEEE Access 2018, 7, 5760–5768. [Google Scholar] [CrossRef]
- Gil Hong, H.; Lee, M.B.; Park, K.R. Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors. Sensors 2017, 17, 1297. [Google Scholar] [CrossRef] [Green Version]
- AlMahafzah, H.; Alrwashdeh, M.Z. A survey of multi- biometric systems. Int. J. Comput. Appl. 2012, 43, 36–43. [Google Scholar] [CrossRef]
- Gad, R.; Elsayed, A.; Zorkany, M.; Elfishawy, N. Multi-biometric systems: A state of the art survey and research directions. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 128–138. [Google Scholar] [CrossRef]
- Dehghani, A.; Ghassabi, Z.; Moghddam, H.A.; Moin, M.-S. Human recognition based on retinal images and using new similarity function. EURASIP J. Image Video Process. 2013, 2013, 58. [Google Scholar] [CrossRef] [Green Version]
- Hou, B.; Yan, R. Convolutional Autoencoder Model for Finger-Vein Verification. IEEE Trans. Instrum. Meas. 2019, 69, 2067–2074. [Google Scholar] [CrossRef]
- Fernandez, F.A. Biometric Sample Quality and Its Application to Multimodal Authentication Systems. Ph.D. Thesis, Universidad Politecnica de Madrid (UPM), Madrid, Spain, 2008. [Google Scholar]
- Wu, X.; Xu, J.; Wang, J.; Li, Y.; Li, W.; Guo, Y. Identity authentication on mobile devices using face verification and ID image recognition. Procedia Comput. Sci. 2019, 162, 932–939. [Google Scholar] [CrossRef]
- Saxena, N.; Varshney, D. Smart Home Security Solutions using Facial Authentication and Speaker Recognition through Artificial Neural Networks. Int. J. Cogn. Comput. Eng. 2021, 2, 154–164. [Google Scholar] [CrossRef]
- Han, C.Y. An image encryption algorithm based on modified logistic chaotic map. Optik 2019, 181, 779–785. [Google Scholar] [CrossRef]
- Pak, C.; An, K.; Jang, P.; Kim, J.; Kim, S. A novel bit-level color image encryption using improved 1D chaotic map. Multimedia Tools Appl. 2018, 78, 12027–12042. [Google Scholar] [CrossRef]
- Parvaz, R.; Zarebnia, M. A combination chaotic system and application in color image encryption. Opt. Laser Technol. 2018, 101, 30–41. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Luo, G.; Qin, K.; Li, C. An image encryption scheme based on chaotic tent map. Nonlinear Dyn. 2016, 87, 127–133. [Google Scholar] [CrossRef]
- Zhou, Y.; Bao, L.; Chen, C.L.P. Image encryption using a new parametric switching chaotic system. Signal Process. 2013, 93, 3039–3052. [Google Scholar] [CrossRef]
- Muñoz-Guillermo, G. Image encryption using q-deformed logistic map. Inf. Sci. 2021, 552, 352–364. [Google Scholar] [CrossRef]
- Li, R.; Liu, Q.; Liu, L. Novel image encryption algorithm based on improved logistic map. IET Image Process. 2019, 13, 125–134. [Google Scholar] [CrossRef]
- Liu, W.; Sun, K.; Zhu, C. A fast image encryption algorithm based on chaotic map. Opt. Lasers Eng. 2016, 84, 26–36. [Google Scholar] [CrossRef]
- Wang, X.; Chen, S.; Zhang, Y. A chaotic image encryption algorithm based on random dynamic mixing. Opt. Laser Technol. 2021, 138, 106837. [Google Scholar] [CrossRef]
- Shakiba, A. A novel randomized one-dimensional chaotic Chebyshev mapping for chosen plaintext attack secure image encryption with a novel chaotic breadth first traversal. Multimed. Tools Appl. 2019, 78, 34773–34799. [Google Scholar] [CrossRef]
- Zhen, P.; Zhao, G.; Min, L.; Jin, X. Chaos-based image encryption scheme combining DNA coding and entropy. Multimed. Tools Appl. 2016, 75, 6303–6319. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, C. A novel image encryption scheme based on conservative hyperchaotic system and closed-loop diffusion between blocks. Signal Process. 2020, 171, 107484. [Google Scholar] [CrossRef]
- Naim, M.; Pacha, A.A.; Serief, C. A novel satellite image encryption algorithm based on hyperchaotic systems and Josephus problem. Adv. Space Res. 2021, 67, 2077–2103. [Google Scholar] [CrossRef]
- Hua, Z.Y.; Zhou, Y.C. Image encryption using 2D Logistic-adjusted-Sine map. Inform. Sci. 2016, 339, 237–253. [Google Scholar] [CrossRef]
- Zhang, Y. Statistical test criteria for sensitivity indexes of image cryptosystems. Inf. Sci. 2021, 550, 313–328. [Google Scholar] [CrossRef]
- Alghafis, A.; Munir, N.; Khan, M.; Hussain, I. An Encryption Scheme Based on Discrete Quantum Map and Continuous Chaotic System. Int. J. Theor. Phys. 2020, 59, 1227–1240. [Google Scholar] [CrossRef]
- Huang, C.-K.; Liao, C.W.; Hsu, S.L.; Jeng, Y.C. Implementation of gray image encryption with pixel shuffling and gray-level encryption by single chaotic system. Telecommun. Syst. 2011, 52, 563–571. [Google Scholar] [CrossRef]
- Wu, Y.; Zhou, Y.; Noonan, J.P.; Agaian, S. Design of image cipher using latin squares. Inf. Sci. 2013, 264, 317–339. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Dai, L.; Liu, Y.; Wu, L. A three-dimensional bit-level image encryption algorithm with Rubik’s cube method. Math. Comput. Simul. 2021, 185, 754–770. [Google Scholar] [CrossRef]
- Bakhshandeh, A.; Eslami, Z. An authenticated image encryption scheme based on chaotic maps and memory cellular automata. Opt. Lasers Eng. 2013, 51, 665–673. [Google Scholar] [CrossRef]
- Song, C.-Y.; Qiao, Y.-L.; Zhang, X.-Z. An image encryption scheme based on new spatiotemporal chaos. Optik 2013, 124, 3329–3334. [Google Scholar] [CrossRef]
- Li, T.; Du, B.; Liang, X. Image Encryption Algorithm Based on Logistic and Two-Dimensional Lorenz. IEEE Access 2020, 8, 13792–13805. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, L.; Qian, T.; Liu, X.; Xie, Q. Content-adaptive image encryption with partial unwinding decomposition. Signal Process. 2020, 181, 107911. [Google Scholar] [CrossRef]
- Shen, Y.; Tang, C.; Xu, M.; Lei, Z. Optical selective encryption based on the FRFCM algorithm and face biometric for the medical image. Opt. Laser Technol. 2021, 138, 106911. [Google Scholar] [CrossRef]
- Li, Z.; Peng, C.; Tan, W.; Li, L. A Novel Chaos-Based Image Encryption Scheme by Using Randomly DNA Encode and Plaintext Related Permutation. Appl. Sci. 2020, 10, 7469. [Google Scholar] [CrossRef]
- Lin, C.-H.; Hu, G.-H.; Chan, C.-Y.; Yan, J.-J. Chaos-Based Synchronized Dynamic Keys and Their Application to Image Encryption with an Improved AES Algorithm. Appl. Sci. 2021, 11, 1329. [Google Scholar] [CrossRef]
- Wei, T.; Lin, P.; Zhu, Q.; Yao, Q. Instability of impulsive stochastic systems with application to image encryption. Appl. Math. Comput. 2021, 402, 126098. [Google Scholar] [CrossRef]
- Jiang, X.; Xiao, Y.; Xie, Y.; Liu, B.; Ye, Y.; Song, T.; Chai, J.; Liu, Y. Exploiting optical chaos for double images encryption with compressive sensing and double random phase encoding. Opt. Commun. 2020, 484, 126683. [Google Scholar] [CrossRef]











| Scheme | Year | Accuracy Rate (%) | |
|---|---|---|---|
| Ref. [2] | Iris Recognition | 2001 | 98.4 |
| Ref. [3] | Retina Identification | 2011 | 99.75 |
| Ref. [4] | Face Authentication | 2019 | 96 |
| Ref. [6] | Signature Recognition | 2020 | 97.5 |
| Ref. [7] | Finger vein Recognition | 2020 | 99.56 |
| Ref. [17] | Face Verification + ID Image Recognition | 2019 | 97.5 |
| Ref. [18] | Facial Authentication + Speaker Recognition | 2021 | 82.71 |
| Proposed (Tolerance 100 Hz) | Facial Authentication + Voice Recognition | 2022 | 100 |
| Proposed (Tolerance 60 Hz) | Facial Authentication + Voice Recognition | 2022 | 91.3 |
| Proposed (Tolerance 30 Hz) | Facial Authentication + Voice Recognition | 2022 | 61.3 |
| Proposed (Tolerance 10 Hz) | Facial Authentication + Voice Recognition | 2022 | 23.8 |
| Fp (Hz) | nw1~nw6 | |Cnccr − 1|min | |Cnccg − 1|min | |Cnccb − 1|min |
|---|---|---|---|---|
| 55 | 5, 4, 2, 3, 2, 4 | 0.0675 | 0.4152 | 0.5422 |
| 650 | 5, 3, 5, 2, 5, 3 | 0.0625 | 0.4150 | 0.5421 |
| 1220 | 3, 2, 4, 3, 5, 2 | 0.0682 | 0.4141 | 0.5472 |
| Fp (Hz) | nw1~nw6 | |Cnccr − 1|min | |Cnccg − 1|min | |Cnccb − 1|min |
|---|---|---|---|---|
| 30~35 | 4, 3, 5, 2, 3, 2 | 0.0689 | 0.4138 | 0.5469 |
| 660~665 | 3, 5, 2, 4, 2, 3 | 0.0685 | 0.4156 | 0.5479 |
| 1220~1205 | 2, 3, 5, 3, 4, 2 | 0.0689 | 0.4152 | 0.5479 |
| Fp (Hz) | nw1~nw6 | Horizontal | Vertical | Diagonal | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R | G | B | R | G | B | R | G | B | ||
| 55 | 5, 4, 2, 3, 2, 4 | −0.0772 | −0.0213 | −0.0028 | 0.1237 | 0.0857 | 0.1114 | −0.0389 | 0.0517 | 0.0770 |
| 1200 | 2, 3, 5, 3, 4, 2 | 0.1764 | 0.1109 | 0.0494 | −0.0536 | −0.0542 | −0.0432 | 0.0043 | 0.0324 | 0.0037 |
| Original image | 0.9798 | 0.9690 | 0.9329 | 0.9894 | 0.9824 | 0.9578 | 0.9696 | 0.9552 | 0.9181 | |
| Fp (Hz) | nw1~nw6 | R UACI | G UACI | B UACI |
|---|---|---|---|---|
| 55 | 5, 4, 2, 3, 2, 4 | 0.3559 | 0.3422 | 0.3417 |
| 55 | 5, 4, 3, 3, 2, 4 | |||
| 55 | 5, 4, 2, 3, 2, 4 | 0.3383 | 0.3394 | 0.3387 |
| 56 | 5, 4, 2, 3, 2, 4 | |||
| 1200 | 3, 2, 4, 3, 5, 2 | 0.3336 | 0.3284 | 0.3177 |
| 1200 | 3, 2, 5, 3, 5, 2 | |||
| 1200 | 3, 2, 4, 3, 5, 2 | 0.3380 | 0.3392 | 0.3385 |
| 1201 | 3, 2, 4, 3, 5, 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Fu, T.; Fu, C.; Han, L. A Novel Image Encryption Algorithm Based on Voice Key and Chaotic Map. Appl. Sci. 2022, 12, 5452. https://doi.org/10.3390/app12115452
Li J, Fu T, Fu C, Han L. A Novel Image Encryption Algorithm Based on Voice Key and Chaotic Map. Applied Sciences. 2022; 12(11):5452. https://doi.org/10.3390/app12115452
Chicago/Turabian StyleLi, Jing, Tianshu Fu, Changfeng Fu, and Lianfu Han. 2022. "A Novel Image Encryption Algorithm Based on Voice Key and Chaotic Map" Applied Sciences 12, no. 11: 5452. https://doi.org/10.3390/app12115452