1. Introduction
Due to clear advantages in terms of the prediction accuracy of deep learning (DL) models that are presently being applied in a broad variety of disciplines. VGGNet and AlexNet, two of the most popular DL models for computer vision tasks, have a lot of hype because they promise things such as superhuman autonomous driving or health diagnostics [
1]. Simultaneously, a drawback of DL is becoming more generally recognized as the opaque nature of its decision-making process. Pre-trained models, commonly called black boxes, make it impossible to understand which components of the input contributed to the output and in what way [
2]. The end user may desire an exploit that is simple enough to be easily communicated, but the CNN may be needed to conduct a highly intricate chain of operations in order to accomplish the task. As a consequence, there is a trade-off between how realistic the description is of the internal dynamics of the network and how explainable it is [
3].
Image classification systems are prone to adversarial attacks [
4], which add tiny alterations to photos, leading these algorithms to make erroneous predictions. These attacks are extremely powerful against even the most successful convolutional network-based systems [
5,
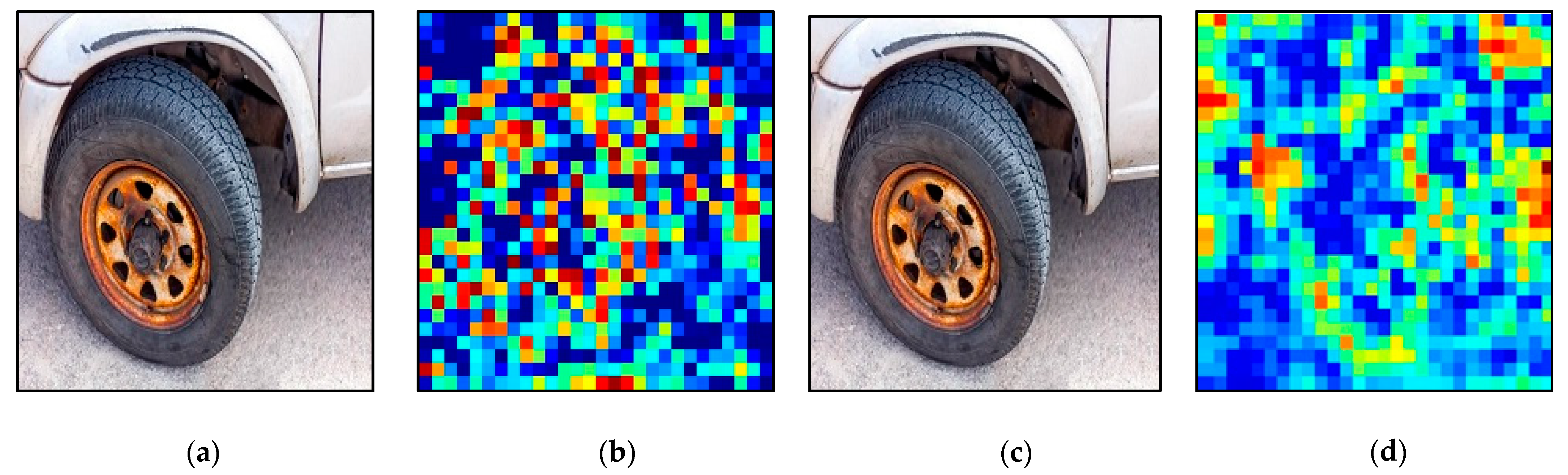
6], despite the perturbations being typically unnoticed or regarded as little “noise” in the image. The success of adversarial attacks puts real-world convolutional network applications at risk of security breaches. The network performs calculations that are very different from those made by human brains. As provided below, the Figures depict original and attack images with a feature-map and also its attacked feature-map as shown in
Figure 1.
This research describes adversarial attack detection on image classification or prediction algorithms such as AlextNet, VGGNet, and ResNet. It further provides different feature-map detection methods and proposes to exploit a feature-map that works well on individual objects in an image possible to use.
To summarize, the following are the major contributions: (1) it presents an adversarial attack using the “Wherefore? What? and How?” concepts. Researchers can quickly and effectively establish adversarial attack awareness using the proposed method; (2) it discusses the strengths and flaws of the proposed methods to explore each for a specific application; and (3) it also describes different types of attacks on image pixel and its detection methods.
2. Related Work
Agarwal et al. [
7] proposed a non-DL approach which involves searching for features using a set of well-known image transforms, such as the Discrete Wavelet Transform, the Discrete Sine Transform, and classifying the features using a support-vector-machine-based classifier. The detection algorithm yielded at least 84.2% and 80.1% detection accuracy under seen and unseen database test settings, respectively. Additionally, they also emphasized how the impact of the adversarial perturbation can be neutralized using a wavelet-decomposition-based filtering method of denoising.
Guesmi et al. [
8] carried out defensive approximation classification with the same level of accuracy without the application of retraining. The convolution neural network’s resources and energy consumption were also decreased by using an approximation computing model. If a strong transferability-based attack on a LeNet-5 or Alexnet, the proposed implementation makes them more resistant to 99% and 87%, respectively, as the approximate logic implementation is easier to use.
Higashi et al. [
9] used the sensitivities of image classifiers to offer a unique technique for identifying adversarial pictures that is fast and accurate. Due to the fact that adversarial pictures are formed by adding noise, they concentrate on the behavior of the outputs of image classifiers for images that have been filtered differently. When the strength of an image classifier is increased, the output of a SoftMax function in the classifier is substantially altered in the case of adversarial images, but the output is rather steady in the case of normal images. They also explored the operation-oriented properties of several noise reduction techniques.
Tsingenopoulos, et al. [
10] proposed an auto attacker revolutionary reinforcement learning system in which agents learn how to operate around a black-box model by questioning it, extracting the underlying decision behavior efficiently, and successfully undermining it. The auto attacker is a first-of-its-kind reinforcement learning system that makes no assumptions about the differentiability or structure of the underlying function. As a result, it is resistant to standard defenses such as gradient obfuscation and adversarial training. The auto-attacker revolutionary reinforcement learning method works well even if the output is less descriptive or missing.
Xie et al. [
11] developed innovative network topologies that promote adversary robustness by conducting feature denoising in order to improve adversarial resilience. They have specifically designed blocks in their networks that denoise the features by using non-local techniques or other filters. The complete network is trained from beginning to finish whenever new blocks come into the network. The designed system can be used in both white-box and black-box assault contexts. The ImageNet technique achieves 55.7% accuracy under 10-iteration on projected gradient descent white-box attacks, while the previous algorithm achieves 27.9% accuracy. While under severe 2000-iteration on projected gradient descent white-box attacks, their method achieved 42.6% accuracy.
Miller et al. [
5] discussed an overview of the attack anomaly detection system by considering a successful, targeted test-time evasion attack example that was developed with a “clean” example
x from a parent class
cs and perturbing it until the perturbed example’s judgement is identical to the source class
cs. They also carried out work on test-time evasion (TTE), data poisoning (DP), backdoor DP, and reverse engineering (RE) attacks and particularly defenses against the anomaly detection.
Vargas and Su [
12] considered an assault in which a pixel is selected at random to be perturbed by the same amount that may be used to cause an attack. Propagation Maps and Locality Analysis are two probable tools for understanding a one-pixel attack. In the CIFAR dataset, the average of PMean over 318 successful assaults was calculated on ResNet out of 1000 trials. Every time an attack is successful, it is carried out again at the same spot on the picture. This process is repeated 5000 times on the CIFAR-10 dataset to achieve a statistically significant result.
Ye et al. [
13] improved model interpretability, by introducing the saliency map approach which is analogous to bringing the process of attention to the model in order to grasp the progress of object recognition by deep networks. Then, to identify hostile cases, provide a new saliency map that is integrated with additional sounds and makes use of the inconsistent strategy. Using several example adversarial attacks on common data sets, such as ImageNet and popular models, they discovered that their technique was capable of detecting all of the assaults with a high detection success rate successfully.
Jia and Gong [
2] used adversarial scenarios, to address the potential and problems of defending against ML-equipped inference attacks. The existing adversarial example construction approaches fall short because they do not take into account the specific problems and needs for producing noise when fighting against inference attacks. They used the example of defending against inferential attacks on online social networks to show the potential and obstacles that might be encountered.
Momeny et al. [
4] suggested an approach that may be used to test the resilience of CNNs to several forms of noise at the same time. For the restoration of noisy pictures, it does not need any preprocessing. The suggested Nested-Residual Guided CNN for the classification of noisy pictures has a reduced time complexity when compared to other methods. Further, it is better at classifying images compared to other methods because of its higher accuracy and efficiency.
Akhtar and Mia [
14] presented the first thorough overview of adversarial attacks on DL in computer vision, which includes both theoretical and practical considerations. They carried out the design of adversarial assaults, investigated the presence of such attacks, and proposed countermeasures. Their contribution further explored the feasibility of adversarial attacks in real-world situations.
Martins et al. [
15] provided the analysis of adversarial attacks, which is referred to as adversarial ML. They are widely researched in the areas of picture classification and spam detection. They concluded that adversarial attack approaches were successful in both virus and intrusion situations, with a large variety of tactics having been examined. They also determined adversarial defensive strategies that have not yet been properly investigated.
Harder et al. [
16] demonstrated how Fourier analysis of input photos and feature-maps may be utilized to identify benign test samples from adversarial images by comparing the Fourier transforms. They suggested two innovative detection methods. First, they present a technique for detecting acoustic signals that is based on acoustic signals; which makes use of the magnitude spectrum of the input pictures. The second technique expands on the first by extracting the phase of Fourier coefficients of feature-maps at various levels. They were able to increase adversarial detection rates as a result of this enhancement when compared to current best-practices detectors.
Panda et al. [
6] constructed the dimensionality of inputs or parameters in a network, on the surface, seems to restrict the “space” in which adversarial instances are found. They show that, guided by their intuitive understanding, discretization significantly increases the resilience of DL networks against adversarial attacks. Their work is more specific, discretizing the input space significantly increases the adversarial resilience of the DL network over a wide variety of perturbations while causing only a small loss inaccuracy.
Sutanto and Lee [
17] offered an approach for detecting adversarial noise that does not require prior knowledge of the kind of adversarial noise used by the adversary. In order to do this, they offer a blurring network that is trained solely with normal pictures. They also recommended that it be used as the starting condition of the deep image prior network. The usage of adversarial noisy pictures for training the neural network is not required in other neural network-based detection approaches, which need the use of a large number of adversarial noisy photos.
Izmailov et al. [
18] investigated the following two issues. How can an adversary take advantage of the geometric and statistical aspects of data distribution when the assault is of a certain scale and scope? When constructing a decision rule, what countermeasures may be utilized to prevent it from malicious distribution shift within the specified size of the attack? Even though we do not supply a complete answer to the problem, we do gather and interpret the observations in a way that can be used to make better decisions about the design of ML algorithms.
Raju and Lipasti [
19] studied and proposed BlurNet as a protection against the Robust Physical Perturbation (RP-2) attacks. First, they provided evidence to support their case by carrying out a frequency analysis of the first layer feature-maps of the network using the LISA dataset. The RP-2 technique introduces high-frequency noise into the input picture during the training process. They conducted a black-box transfer attack in order to demonstrate that low-pass filtering the feature-maps is more advantageous than filtering the input data. Several regularization strategies were discussed for incorporating this low-pass filtering characteristic into the network’s training regime, as well as white-box assaults on the network. In the end, they carried out an adaptive assault assessment and described that when total variation regularization, one of the recommended countermeasures, is used, the success rate of the attack drops from 90% to 20%.
De Silva et al. [
1] have suggested a solution to protect ML algorithms against test data fabrication with a common assumption that feature entries of test data are equally susceptible to falsification. The researchers describe an adversarial learning approach that takes into consideration the susceptibility features of test data entries while developing an attack-resilient classifier.
Chen et al. [
20] reviewed literature primarily and conducted adversarial research on specific application scenarios. They generated adversarial examples by adding perturbations to the information carrier in order to realize the adversarial attack on reinforcement learning systems. They gave a detailed overview of the literature on adversarial attacks in several fields of reinforcement learning applications, along with the best ways to defend against them.
Chai and Velipasalar [
21] offered an approach to identify the adversarial instances created by several adversarial assaults, including the dispersion reduction technique, projected gradient descent technique, varied inputs method, and momentum iterative fast gradient sign technique. Their method, which uses one dimensional Gabor filter responses, is very good at figuring out adversarial samples made from a wide range of surrogate neural network models and datasets.
Jang et al. [
22] proposed that students learn how to construct hostile instances by using the generator. They offer a recursive and stochastic generator that, in contrast to previous systems that generate a one-shot perturbation via a deterministic generator, creates significantly stronger and more diversified perturbations that thoroughly show the susceptibility of the target classifier. Tests on the MNIST and CIFAR-10 datasets confirmed that the classifier adversarial trained with their method outperforms the classifier trained with a recursive and stochastic generator method under a variety of white-box and black-box attacks.
Akhtar and Dasgupta [
23] presented a quick review of diverse hostile and security measures. Frameworks in the first category are aimed at increasing the resilience of DNNs in order to appropriately classify AEs. For example, adversarial training, which entails training the ML approaches with both clean and malicious samples. A single step update along the sign of the gradient of a loss function necessary to the sample is used to construct the attack elements. Natural generative adversarial networks (NGANs) are generative adversarial networks (GANs) that use generative adversarial networks (GANs) to produce AAs by minimizing the distance between the inner representations.
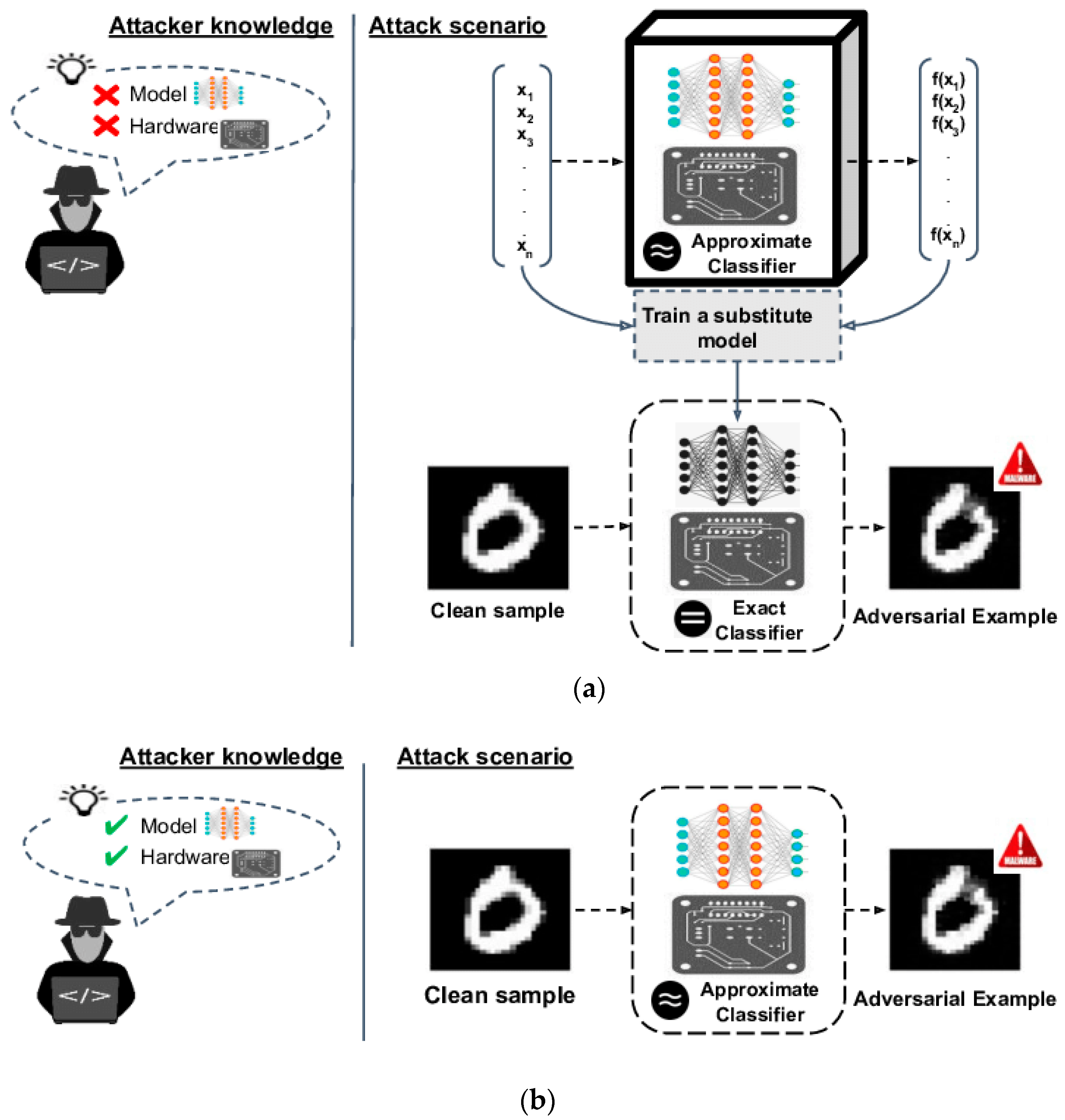
In summary, it can be said that previous researches [
1,
5,
13] were computationally costly because they were based on the pre-generation of adversarial samples. The limited-memory Broyden–Fletcher–Goldfarb–Shanno algorithm [
8,
13], the rapid gradient sign technique [
9,
11], projected gradient descent [
9,
11], distributional adversarial assault [
24], and DeepFool [
25] were all employed in the frameworks of these threat models. Adversarial training, which aims to increase the resilience of the DL model by integrating adversarial samples into the training stage, is currently the most effective heuristic defense. This research came up with an exploit feature-map method that uses picture weight data to figure out the object weight feature-map to get attack parts.
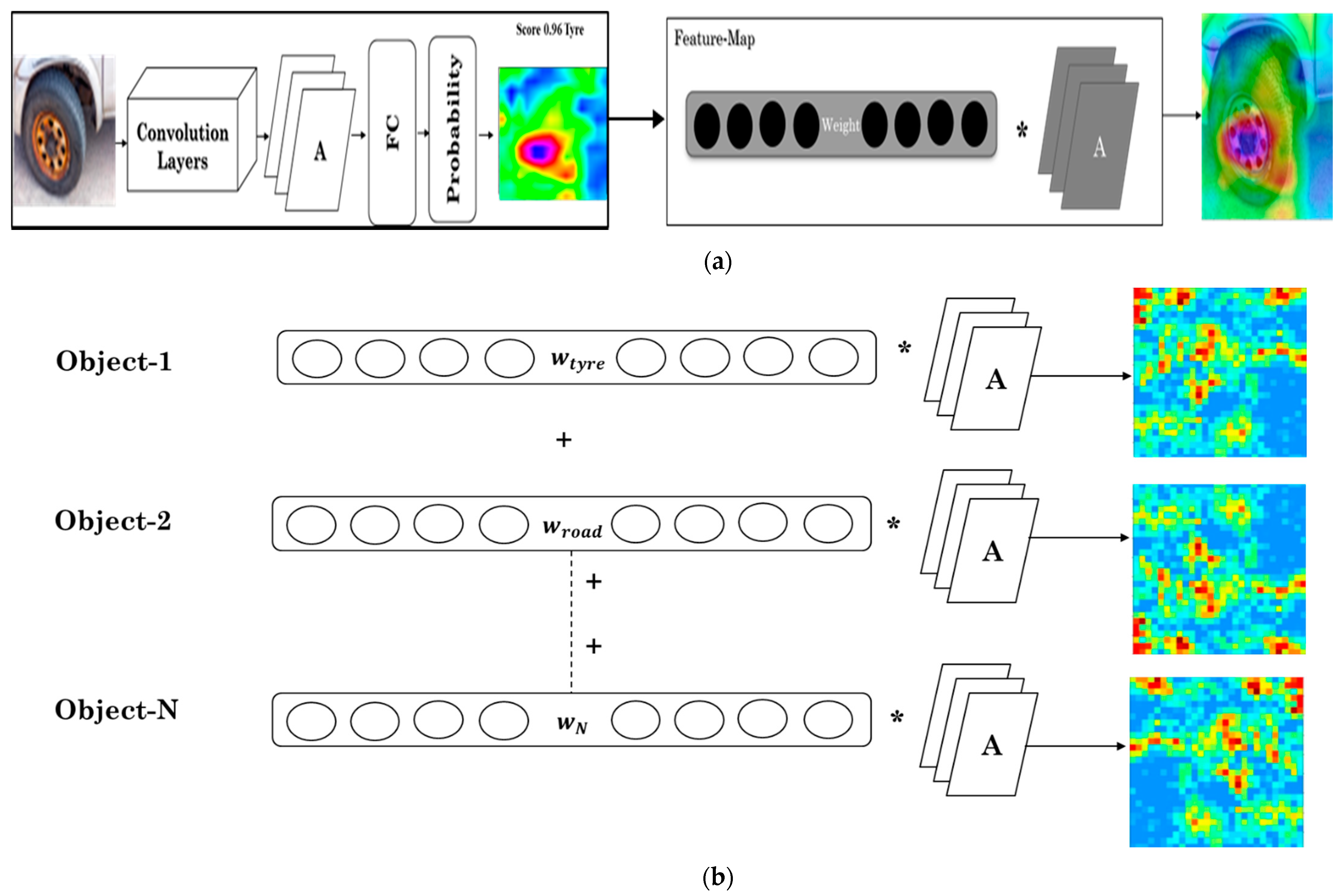
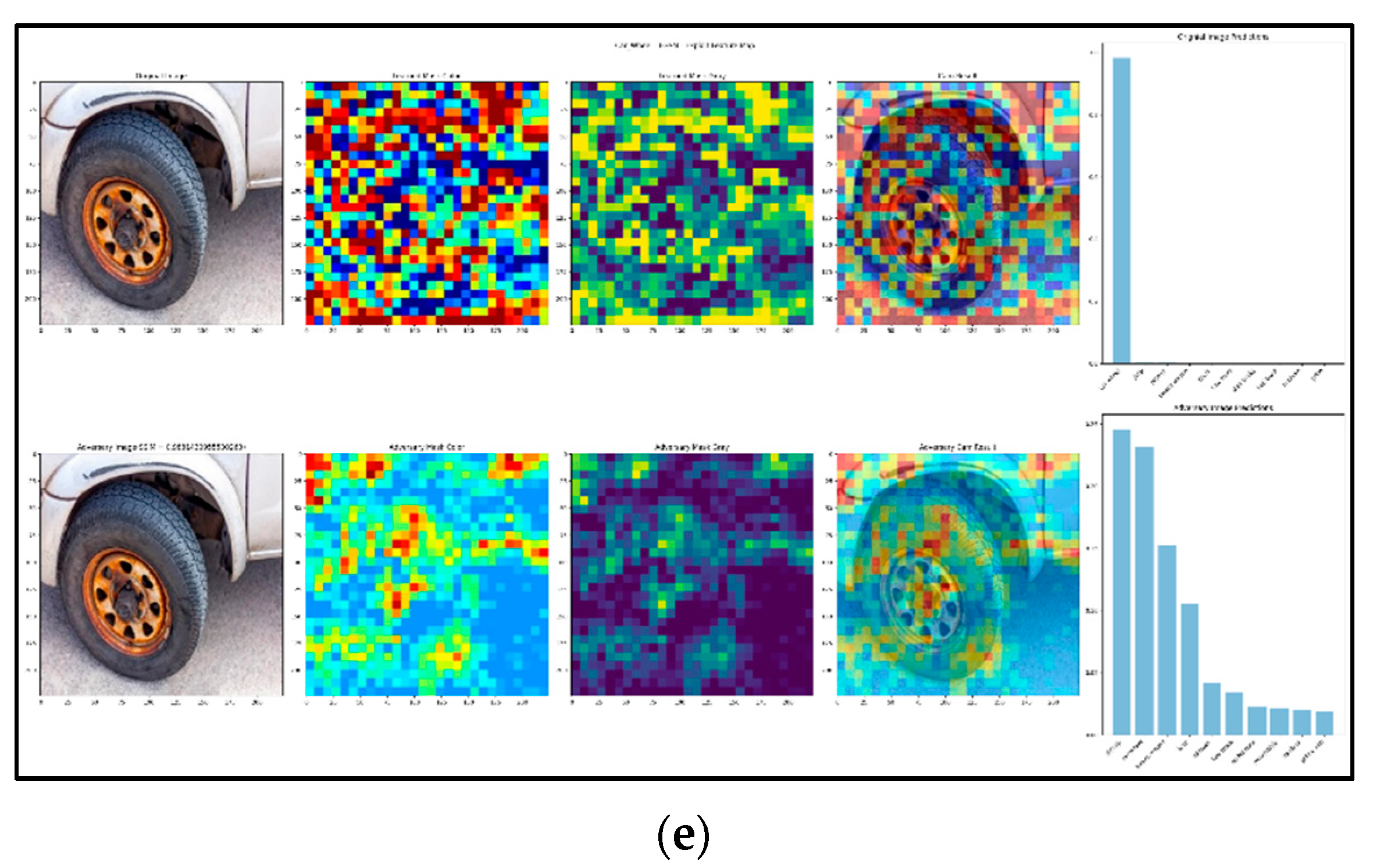
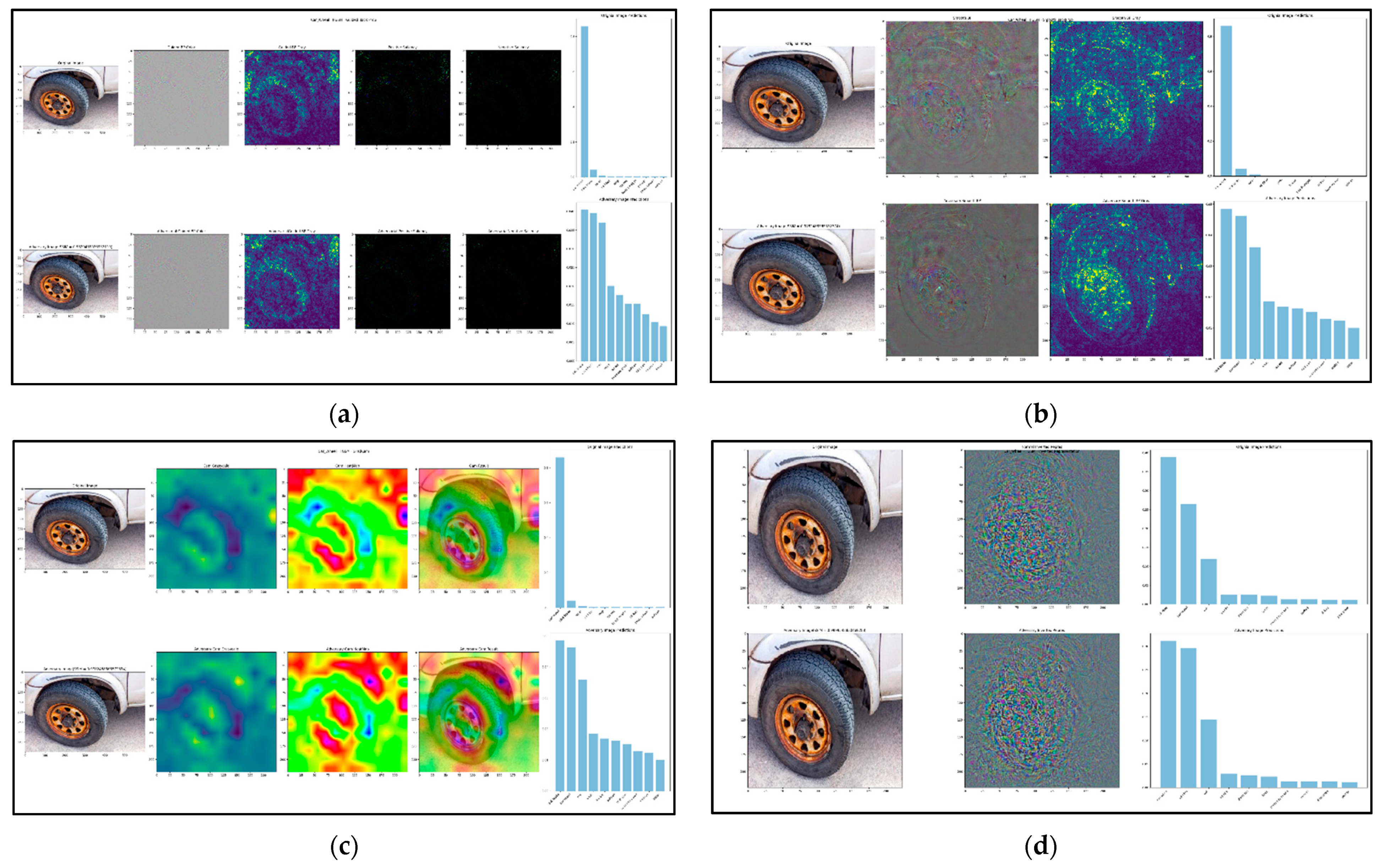
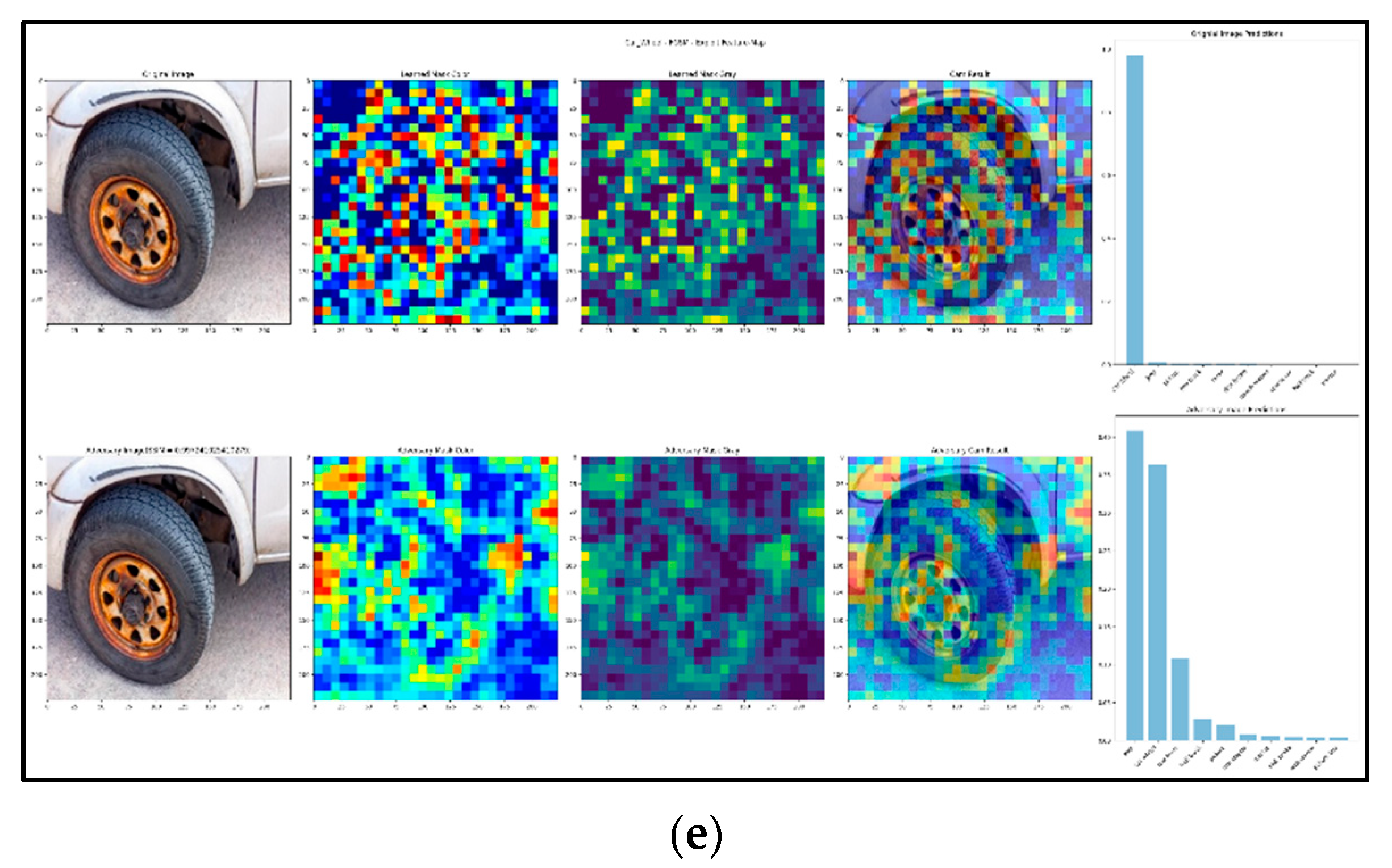
5. Novel Exploit Feature-Map Approach
The novel exploit feature-map which is divided into two parts: the first part will detect each and every object map on the input picture, as shown in
Figure 3a. The second part will combine all of the parts of the feature-map to achieve the final detection on the input image, as shown in
Figure 3b.
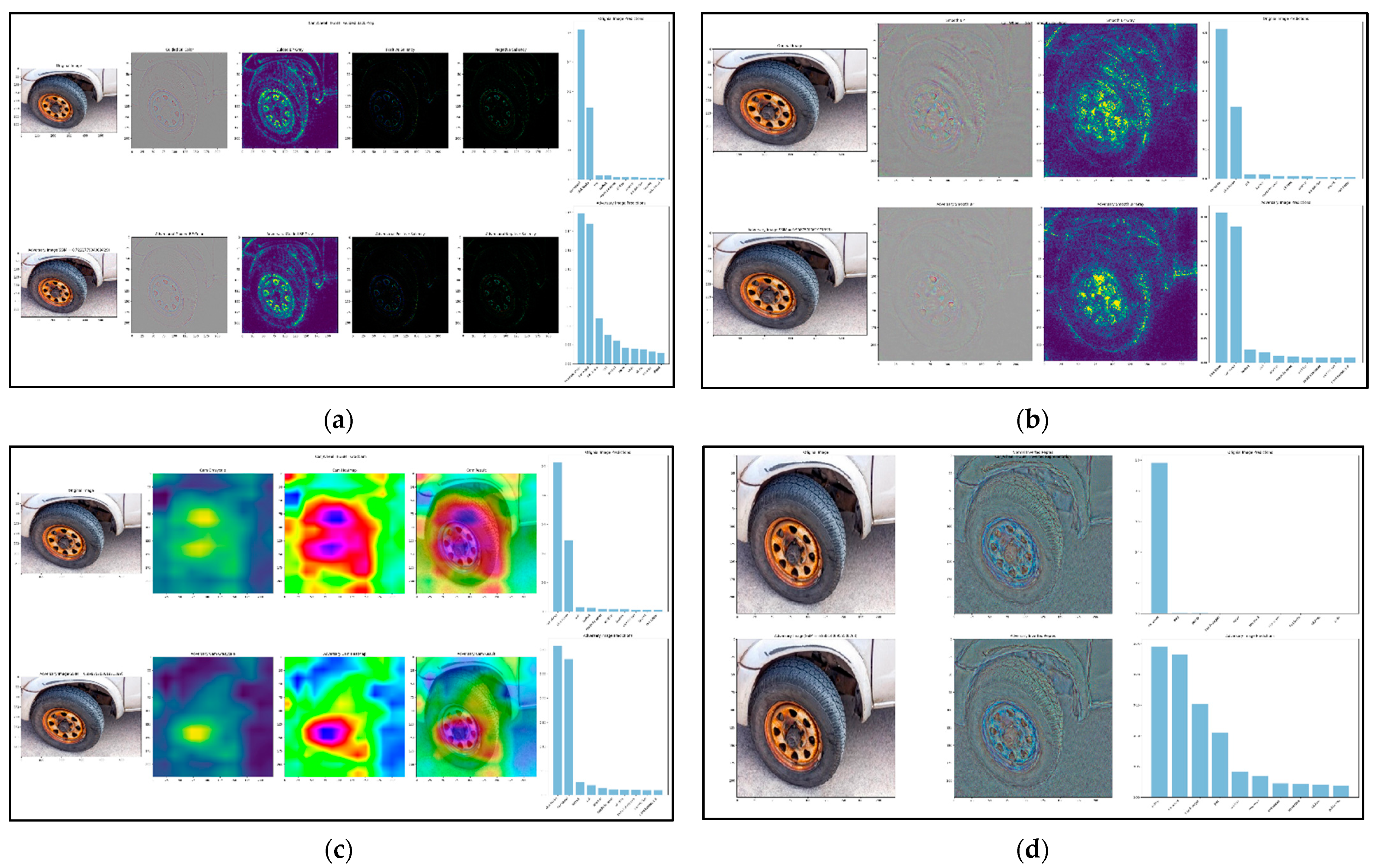
In order to define an explanatory rule for a black box f(x), one must start by specifying which variations of the input x will be used to study f. The aim of saliency is to identify which regions of an image x0 are used by the black box to produce the output value f(x0). We can do so by observing how the value of f(x) changes as x is obtained “deleting” different regions R of x0. For example, if f(x0) = +1 denotes a robin image, we expect that f(x) = +1 as well unless the choice of R deletes the robin from the image. Given that x is a perturbation of x0, this is a local explanation, and we expect the explanation to characterize the relationship between f and x0.
While conceptually simple, there are several problems with this idea. The first one is to specify what it means by “delete” information. We are generally interested in simulating naturalistic or plausible imaging effect, leading to more meaningful perturbations and hence explanations. Since we do not have access to the image generation process, we consider three obvious proxies: replacing the region R with a constant value, injecting noise, and blurring the image.
Formally, let
be a
mask, associating each pixel
with a scalar value
. Then the perturbation operator is defined as
where
µ0 represents the average color,
n(u) represents the number of i.i.d. Gaussian noise samples for each pixel, and
σ0 represents the maximum isotropic standard deviation of the Gaussian blur kernel
(we choose
σ0 = 10, which results in a highly blurred picture). One feature of the proposed approach is that the produced visualizations are obviously exploiting adversarial assaults, which is a significant advantage. When one plays the deletion game, a minimum mask is made that stops the item from being recognized by the network.
7. Conclusions
According to this study, a thorough, formal framework for learning explanations as a meta-predictor has been developed. In addition, a unique image exploit feature-map paradigm is introduced here, which teaches an algorithm where to look by evaluating which parts of an image have the most influence on its result when it is disturbed. The suggested approach, in contrast to many mapping methods, makes explicit alterations to the picture, making it more exploitable and testable. When compared to other approaches, novel exploit feature-map works in less than 8–9 min, indicating that it has a modest temporal complexity. Whereas the error rate for existing techniques is not less than 40%, our method has the best performance of 50 samples, with an error rate of 28.42%, while the error rate for existing approaches is 40%. As a result, the defensive filtering technique will be used in the future, which will denoise the assault pixel. A method that can be used for any ML model should also be developed to provide protection against both black-box and white-box threats. It is revealed that there is currently no defensive mechanism exist that is. efficient and effective when dealing with hostile samples. Adversarial training, which is the most effective defensive mechanism, is too computationally costly for practical deployment, and several efficient heuristic defenses have been shown to be susceptible to adaptive white-box adversaries.
In the future it is possible to improve the interpretability of deep networks. For instance, how can the algorithm be used to guard against assault in gray-box situations? We anticipate that future research will address these concerns in depth.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}