
Improving Non-Autoregressive Machine Translation Using Sentence-Level Semantic Agreement

Abstract
:1. Introduction
2. Background
2.1. Non-Autoregressive Translation
2.2. Glancing Transformer
3. Method
3.1. Semantic Agreement between Source and Generated Sentence
3.2. Semantic Agreement in Encoder
3.3. Ahead Supervision for Better Representation
3.4. Optimization and Inference
4. Experiments
4.1. Datasets and Settings
4.1.1. Datasets
4.1.2. Sequence-Level Knowledge Distillation
4.1.3. Baselines
4.1.4. Model Setup
4.1.5. Training and Inference
4.2. Main Results
- Our model, SLSA, is based on the architecture of GLAT, but our model obtained the better results than GLAT. It had a significant improvement (about 0.85 BLEU+) on the EN → DE task. In addition, on the DE → EN task, it gained +1.3 BLEU over GLAT. The reason is that SLSA introduces the semantic agreement between the encoder and decoder. The semantic agreement in the encoder can ensure the encoder projects the representation of the source target sentences into the shared space. The semantic agreement between the source and target sentences can ensure the sentence-level representation of the generated sentence is consistent with the representation of the source sentence. Meanwhile, this semantic agreement gives the decoder a constraint, which limits the decoder to generating semantically relevant words. Furthermore, the result of our model was better than SLSAv1. SLSAv1 uses the mean square error to pull the similar representation closer, but it cannot push the dissimilar representations away. We think this is the reason for better results of the SLSA.
- Compared with the other fully NAT models, our model achieved better results and remained simple. Hint-NAT and TCL-NAT need a pretrained autoregressive model to provide the knowledge for the non-autoregressive model. Although DCRF-NAT does not need a pretrained autoregressive model, it introduces the CRF module and uses viterbi to generate the target sentence, which may reduce the decoding speed when the target sentence is lengthy. However, SLSA only modifies the training process, and it can perform the vanilla decoding process. Compared with CNAT, on the WMT14 EN → DE task, our model achieved a better result.
- As for the NPD, it did have a critical effect on improving the performance of the NAT model, as the previous works [4,25] pointed out. When we reranked the candidates with an autoregressive model, a result of 27.01 BLEU was obtained by our model on the EN → DE task and obtains a comparable result to the autoregressive model transformer, which achieved 27.2 BLEU.
4.3. Analyses
4.3.1. Effect of Different Lengths
4.3.2. Effect on Reducing Word Repetition
4.3.3. Visualization
4.4. Ablation Study
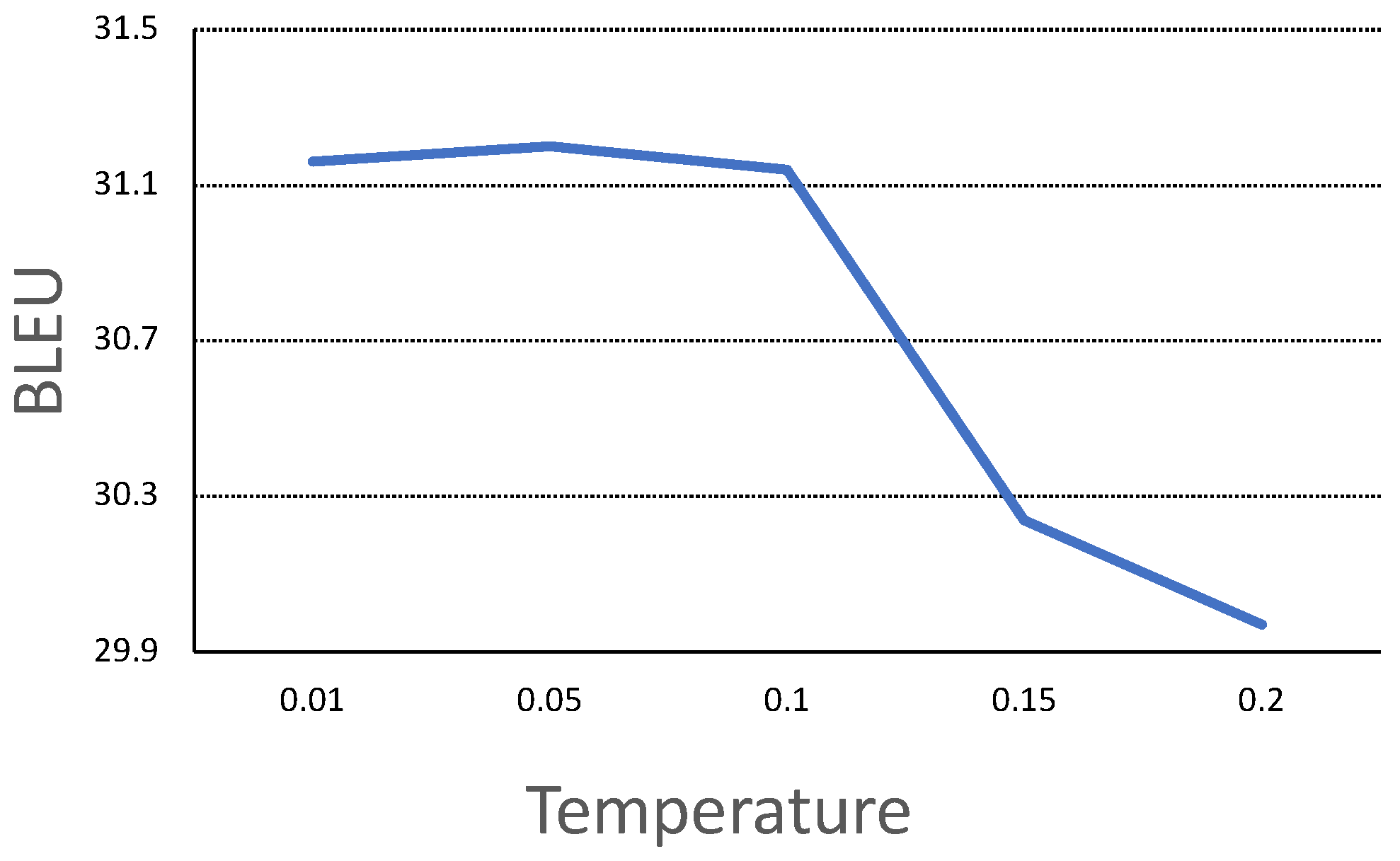
4.4.1. Influence of Temperature
4.4.2. Effectiveness of Each Loss
5. Related Work
5.1. Non-Autoregressive Machine Translation
5.2. Sentence-Level Agreement
5.3. Contrastive Learning
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the ICML 2017, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Gu, J.; Bradbury, J.; Xiong, C.; Li, V.O.; Socher, R. Non-autoregressive neural machine translation. arXiv 2017, arXiv:1711.02281. [Google Scholar]
- Shao, C.; Zhang, J.; Feng, Y.; Meng, F.; Zhou, J. Minimizing the bag-of-ngrams difference for non-autoregressive neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 198–205. [Google Scholar]
- Sun, Z.; Li, Z.; Wang, H.; Lin, Z.; He, D.; Deng, Z.H. Fast structured decoding for sequence models. arXiv 2019, arXiv:1910.11555. [Google Scholar]
- Qian, L.; Zhou, H.; Bao, Y.; Wang, M.; Qiu, L.; Zhang, W.; Yu, Y.; Li, L. Glancing transformer for non-autoregressive neural machine translation. arXiv 2020, arXiv:2008.07905. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Norouzi, M. Non-autoregressive machine translation with latent alignments. arXiv 2020, arXiv:2004.07437. [Google Scholar]
- Ghazvininejad, M.; Karpukhin, V.; Zettlemoyer, L.; Levy, O. Aligned cross entropy for non-autoregressive machine translation. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 3515–3523. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Yan, Y.; Li, R.; Wang, S.; Zhang, F.; Wu, W.; Xu, W. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer. arXiv 2021, arXiv:2105.11741. [Google Scholar]
- Wang, R.; Finch, A.; Utiyama, M.; Sumita, E. Sentence embedding for neural machine translation domain adaptation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 560–566. [Google Scholar]
- Pan, X.; Wang, M.; Wu, L.; Li, L. Contrastive learning for many-to-many multilingual neural machine translation. arXiv 2021, arXiv:2105.09501. [Google Scholar]
- Liu, Y.; Wan, Y.; Zhang, J.; Zhao, W.; Yu, P. Enriching non-autoregressive transformer with syntactic and semantic structures for neural machine translation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Kiev, Ukraine, 21–23 April 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1235–1244. [Google Scholar] [CrossRef]
- Lee, J.; Mansimov, E.; Cho, K. Deterministic non-autoregressive neural sequence modeling by iterative refinement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1173–1182. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Zhou, C.; Neubig, G.; Gu, J. Understanding knowledge distillation in non-autoregressive machine translation. arXiv 2019, arXiv:1911.02727. [Google Scholar]
- Kim, Y.; Rush, A.M. Sequence-level knowledge distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1317–1327. [Google Scholar]
- Yang, M.; Wang, R.; Chen, K.; Wang, X.; Zhao, T.; Zhang, M. A Novel Sentence-Level Agreement Architecture for Neural Machine Translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2585–2597. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 June 2002; pp. 311–318. [Google Scholar]
- Shu, R.; Lee, J.; Nakayama, H.; Cho, K. Latent-variable non-autoregressive neural machine translation with deterministic inference using a delta posterior. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8846–8853. [Google Scholar]
- Gu, J.; Wang, C.; Zhao, J. Levenshtein transformer. arXiv 2019, arXiv:1905.11006. [Google Scholar]
- Ghazvininejad, M.; Levy, O.; Liu, Y.; Zettlemoyer, L. Mask-predict: Parallel decoding of conditional masked language models. arXiv 2019, arXiv:1904.09324. [Google Scholar]
- Guo, J.; Xu, L.; Chen, E. Jointly masked sequence-to-sequence model for non-autoregressive neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 376–385. [Google Scholar]
- Li, Z.; He, D.; Tian, F.; Qin, T.; Wang, L.; Liu, T.Y. Hint-based training for non-autoregressive translation. In Proceedings of the ICLR 2019 Conference, New Orleans, LA, USA, 6–9 May 2018. [Google Scholar]
- Guo, J.; Tan, X.; Xu, L.; Qin, T.; Chen, E.; Liu, T.Y. Fine-tuning by curriculum learning for non-autoregressive neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7839–7846. [Google Scholar]
- Ma, X.; Zhou, C.; Li, X.; Neubig, G.; Hovy, E. Flowseq: Non-autoregressive conditional sequence generation with generative flow. arXiv 2019, arXiv:1909.02480. [Google Scholar]
- Bao, Y.; Huang, S.; Xiao, T.; Wang, D.; Dai, X.; Chen, J. Non-Autoregressive Translation by Learning Target Categorical Codes. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Virtual, 6–11 June 2021; pp. 5749–5759. [Google Scholar]
- Wang, Y.; Tian, F.; He, D.; Qin, T.; Zhai, C.; Liu, T.Y. Non-autoregressive machine translation with auxiliary regularization. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5377–5384. [Google Scholar]
- Shao, C.; Feng, Y.; Zhang, J.; Meng, F.; Chen, X.; Zhou, J. Retrieving sequential information for non-autoregressive neural machine translation. arXiv 2019, arXiv:1906.09444. [Google Scholar]
- Huang, C.; Zhou, H.; Zaiane, O.R.; Mou, L.; Li, L. Non-autoregressive translation with layer-wise prediction and deep supervision. arXiv 2021, arXiv:2110.07515. [Google Scholar]
- Yang, M.; Wang, R.; Chen, K.; Utiyama, M.; Sumita, E.; Zhang, M.; Zhao, T. Sentence-level agreement for neural machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3076–3082. [Google Scholar]
- Zhuang, C.; Zhai, A.L.; Yamins, D. Local aggregation for unsupervised learning of visual embeddings. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6002–6012. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 776–794. [Google Scholar]
- Hassani, K.; Khasahmadi, A.H. Contrastive multi-view representation learning on graphs. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 4116–4126. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Wu, Z.; Wang, S.; Gu, J.; Khabsa, M.; Sun, F.; Ma, H. Clear: Contrastive learning for sentence representation. arXiv 2020, arXiv:2012.15466. [Google Scholar]
- Fang, H.; Wang, S.; Zhou, M.; Ding, J.; Xie, P. Cert: Contrastive self-supervised learning for language understanding. arXiv 2020, arXiv:2005.12766. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | EN → DE | EN → RO | DE → EN | ||
|---|---|---|---|---|---|
| AT Model | Transformer | 27.2 | 33.70 | 34.50 | |
| Iterative-Based NAT models | NAT-IR(k = 10) [15] | 21.61 | 29.32 | 23.94 | |
| LaNAT (k = 4) [22] | 26.30 | / | / | ||
| LevT (k ≈ 6) [23] | 27.27 | / | / | ||
| CMLM (k = 4) [24] | 25.94 | 32.53 | 30.42 | ||
| CMLM (k = 10) | 27.03 | 33.08 | 31.71 | ||
| JM-NAT (k = 4) [25] | 26.82 | 32.97 | 31.27 | ||
| JM-NAT (k = 10) | 27.31 | 33.52 | 32.59 | ||
| Fully NAT models | NAT [4] | 17.69 | 26.22 | / | |
| Hint-NAT [26] | 21.11 | / | / | ||
| TCL-NAT [27] | 21.94 | / | 28.16 | ||
| DCRF-NAT [6] | 23.44 | / | / | ||
| Flowseq [28] | 21.45 | 29.34 | 27.55 | ||
| CMLM | 18.05 | 27.32 | / | ||
| GLAT [7] | 25.21 | 31.19 | 29.80 * | ||
| CNAT [29] | 25.56 | / | 31.15 | ||
| w/ NPD | NAT (NPD = 100) | 19.17 | 29.79 | 24.21 | |
| Hint-NAT (NPD = 9) | 25.20 | / | / | ||
| DCRF-NAT (NPD9) | 26.07 | / | 29.99 | ||
| GLAT (NPD = 7) | 26.55 | 32.87 | 31.23 * | ||
| CNAT (NPD = 9) | 26.60 | / | / | ||
| Ours | GLAT | 25.02 | 31.09 | 29.74 | |
| SLSAv1 | 25.53 | 31.23 | 30.45 | ||
| SLSA | 26.06 | 31.40 | 31.14 | ||
| SLSA (NPD = 7) | 27.01 | 32.90 | 32.39 | ||
| NAT | NAT-Reg | CMLM | GLAT | SLSA |
|---|---|---|---|---|
| 2.30 | 0.90 | 0.48 | 0.49 | 0.40 |
| Model | BLEU | |||
|---|---|---|---|---|
| SLSA | 30.34 | |||
| ✓ | 30.51 | |||
| ✓ | ✓ | 30.98 | ||
| ✓ | ✓ | 30.82 | ||
| ✓ | ✓ | ✓ | 31.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Huang, H.; Shi, S. Improving Non-Autoregressive Machine Translation Using Sentence-Level Semantic Agreement. Appl. Sci. 2022, 12, 5003. https://doi.org/10.3390/app12105003
Wang S, Huang H, Shi S. Improving Non-Autoregressive Machine Translation Using Sentence-Level Semantic Agreement. Applied Sciences. 2022; 12(10):5003. https://doi.org/10.3390/app12105003
Chicago/Turabian StyleWang, Shuheng, Heyan Huang, and Shumin Shi. 2022. "Improving Non-Autoregressive Machine Translation Using Sentence-Level Semantic Agreement" Applied Sciences 12, no. 10: 5003. https://doi.org/10.3390/app12105003