
Evaluation and Prediction of Higher Education System Based on AHP-TOPSIS and LSTM Neural Network


Abstract
:1. Introduction
2. Related Work
- Determining the types of indicators and research objects and collecting relevant data.
- Adopting AHP to construct multilevel indicators, which covers risk factors that need to be considered as extensively as possible.
- Applying TOPSIS to comprehensively qualify these indicators.
- Making sensitivity analyses or case applications to verify model rationality.
3. Higher Education Evaluation System
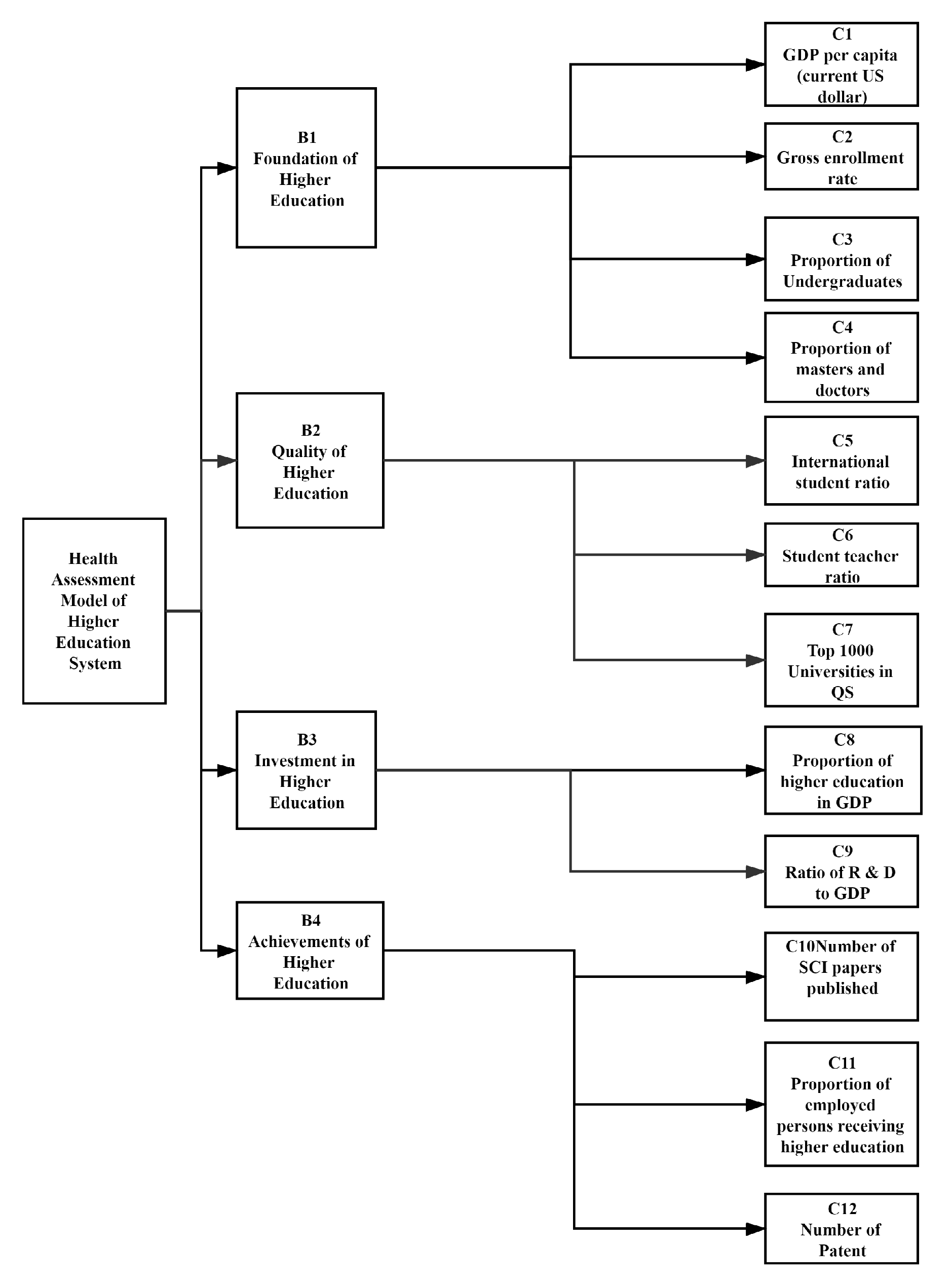
3.1. Design of Evaluation System
- Population, social and economic background of higher education: To understand the structure, process and achievements of higher education and various relationships between them, we first need to examine the basic conditions on which national higher education system relies. These conditions mainly include the situation of the population and social and economic development because these conditions restrict and affect the formulation and implementation of relevant higher education policies and affect the supply and demand of colleges and universities, teachers, teaching facilities and other higher education resources.
- Financial and human resources invested in higher education: These kinds of indicators mainly investigate the proportion of higher education institutions in national resources, the source of funds and the level of higher education used, as well as the number and proportion of all personnel employed in higher education departments. At the same time, these indicators also examine how financial funds for higher education are transformed to help students in their studies and scientific research.
- Access to higher education, participation and further study: Such indicators mainly include: (1) the participation rate of senior secondary education; (2) the participation rate of higher education (including public and private universities); (3) the participation in adult education; (4) the ratio of foreign students receiving higher education in China and Chinese students receiving higher education in foreign countries (the difference between exit and entry); (5) the type and proportion of adult workers participating in continuing education and training; (6) the dropout rate of private college students; and so on. The reason for adding the indicator is that international student mobility involves the economic expenditures and incomes of sending and receiving countries, as well as the corresponding brain drain.
- Social output and scientific output: These kinds of indicators mainly investigate the labor market output of higher education to the whole working age population, as well as the achievements of higher education in scientific research. These are: (1) the unemployment rate of students in higher education at all levels; (2) the proportion of employees receiving higher education; (3) the number of papers published; and (4) the number of patents published.
3.2. Datasets and Methodology
3.3. Analytic Hierarchy Process (AHP)
| Algorithm 1 Process of the AHP. |
| Input: Relative importance of each indicator |
| Output: Weighted matrix of evaluation system |
| 1: Analyzing relationships among the various indicators and establishing a hierarchical structure of the system. |
| 2: Comparing importance of same-level indicators pair-wise for a judgment matrix. |
| 3: Calculating weights of each indicator by the judgment matrix. |
| 4: Calculating general weights of the indicators in each level and sorting them. |
3.3.1. Establishment of the Judgment Matrix
3.3.2. Consistency Check
3.3.3. Calculate the Weight of Each Indicator
3.4. Technique for Order Preference by Similarity to an Ideal Solution (TOPSIS)
3.4.1. Principles of TOPSIS
| Algorithm 2 Process of weighted TOPSIS. |
| Input: Original dataset |
| The weight of each indicator |
| Output: The higher education level of each research object |
| 1: Normalizing indicator nature in the original dataset. |
| 2: Constructing the normalized matrix . |
| 3: for , each column of F do |
| 4: The dimension of the worst plan ← the maximum value of elements in . |
| 5: The dimension of the best plan ← the maximum value of elements in . |
| 6: end for |
| 7: for do |
| 8: Determining the best plan . |
| 9: Determining the worst plan . |
| 10: Calculating : the closeness between and . |
| 11: Calculating : the closeness between and . |
| 12: end for |
| 13: Calculating the relative closeness of each evaluation object . |
| 14: Sorting according to the size of value. |
3.4.2. Calculation of Weighted TOPSIS Method
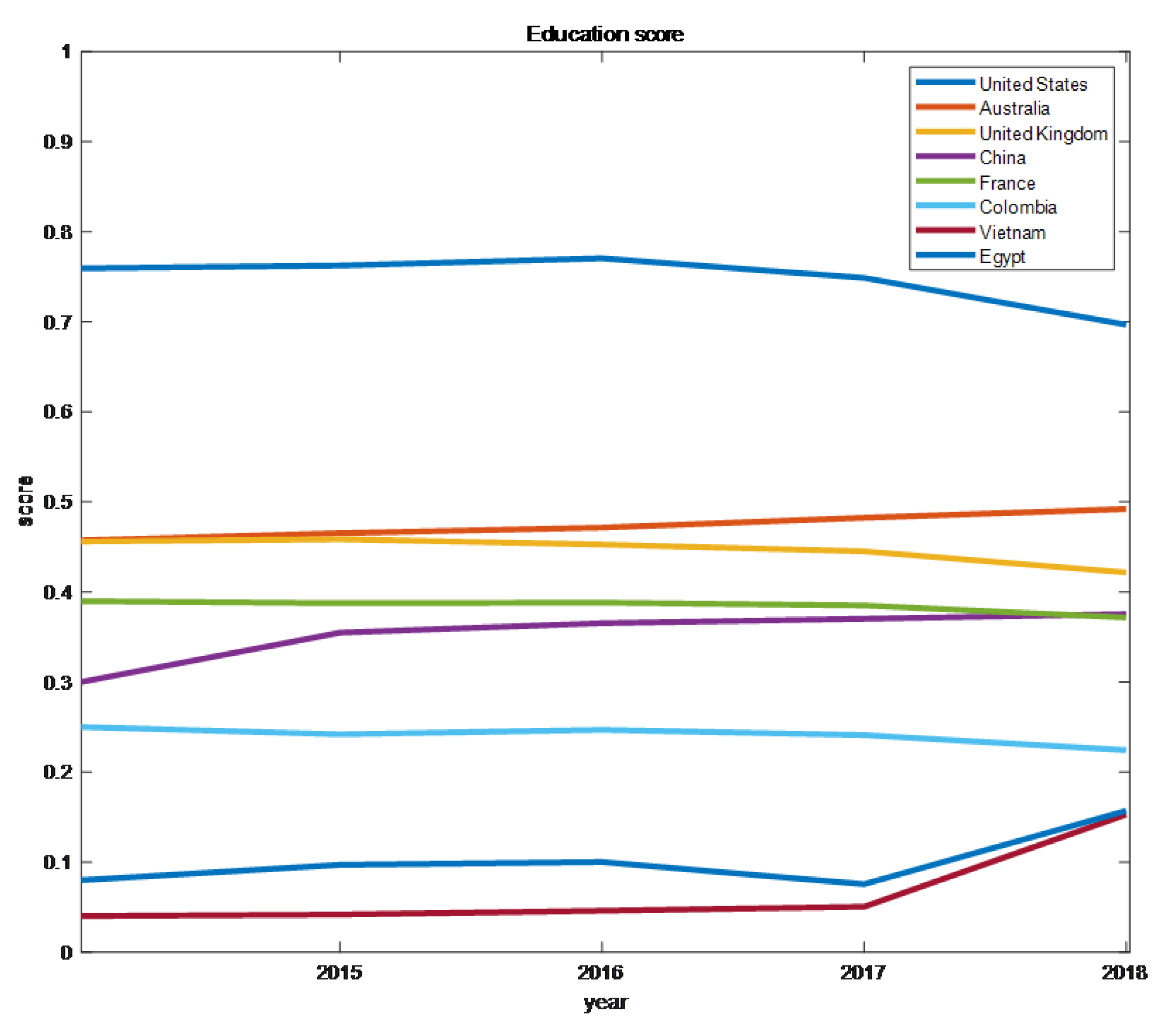
3.5. Evaluation of National Higher Education for Statistical Countries
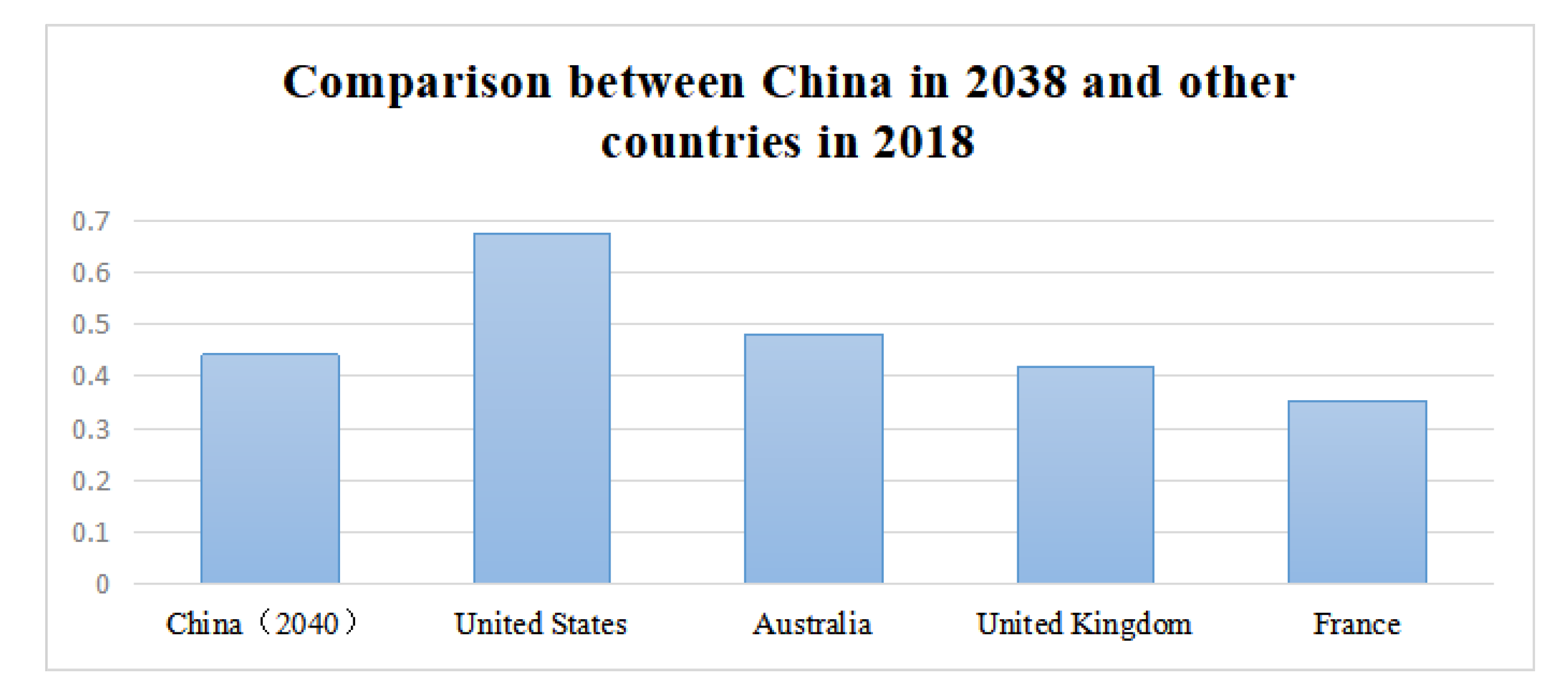
3.6. The State of China’s Higher Education Development
4. Higher Education Prediction Model
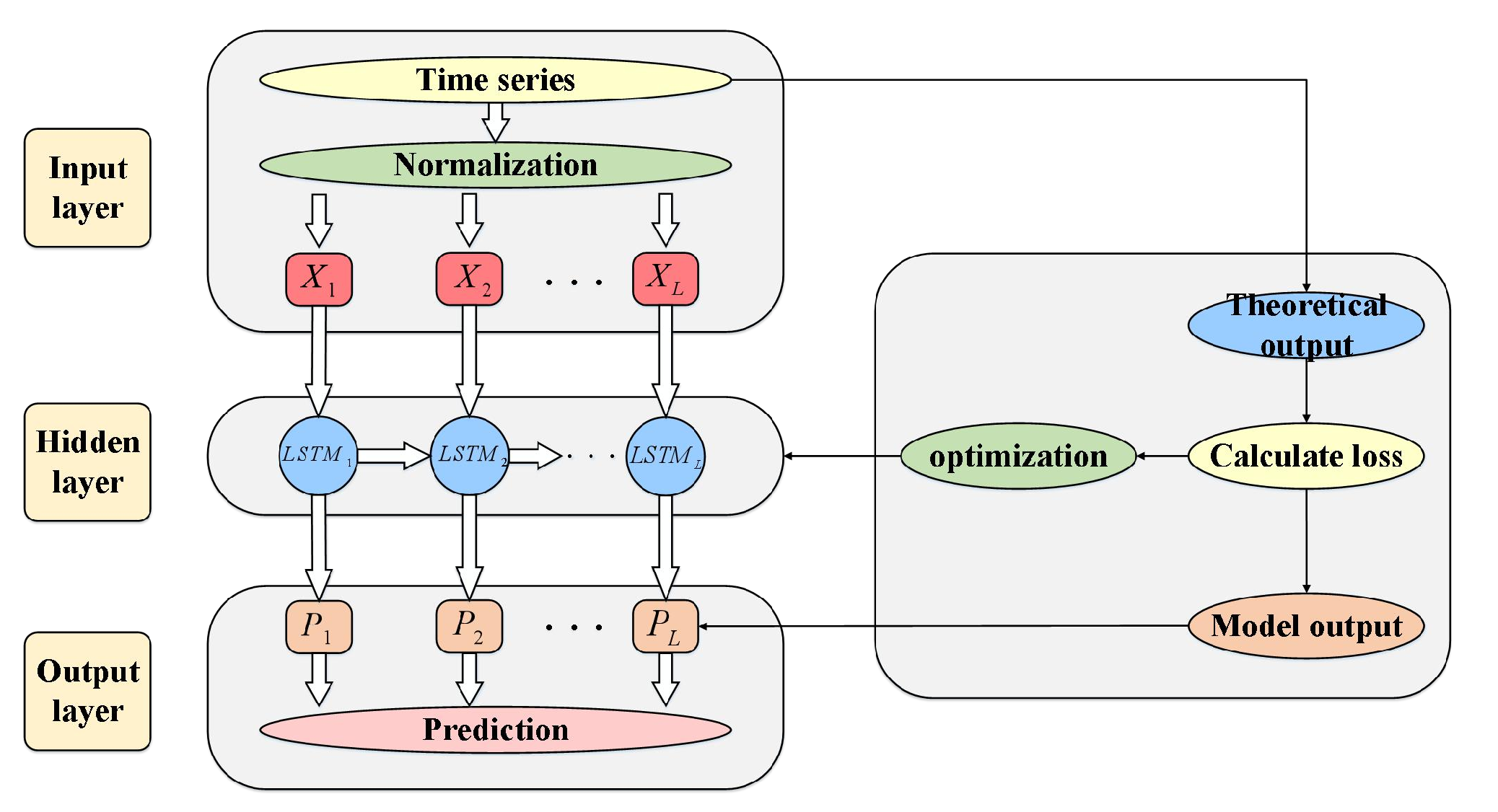
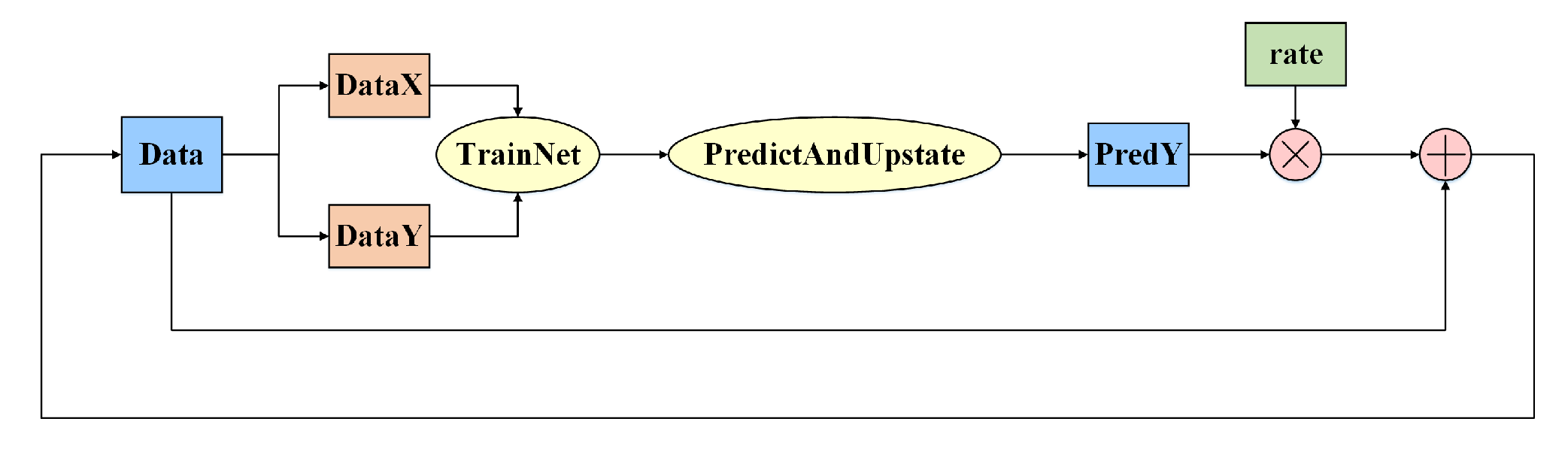
4.1. Framework of the Prediction Model
4.2. Input Data of the Module
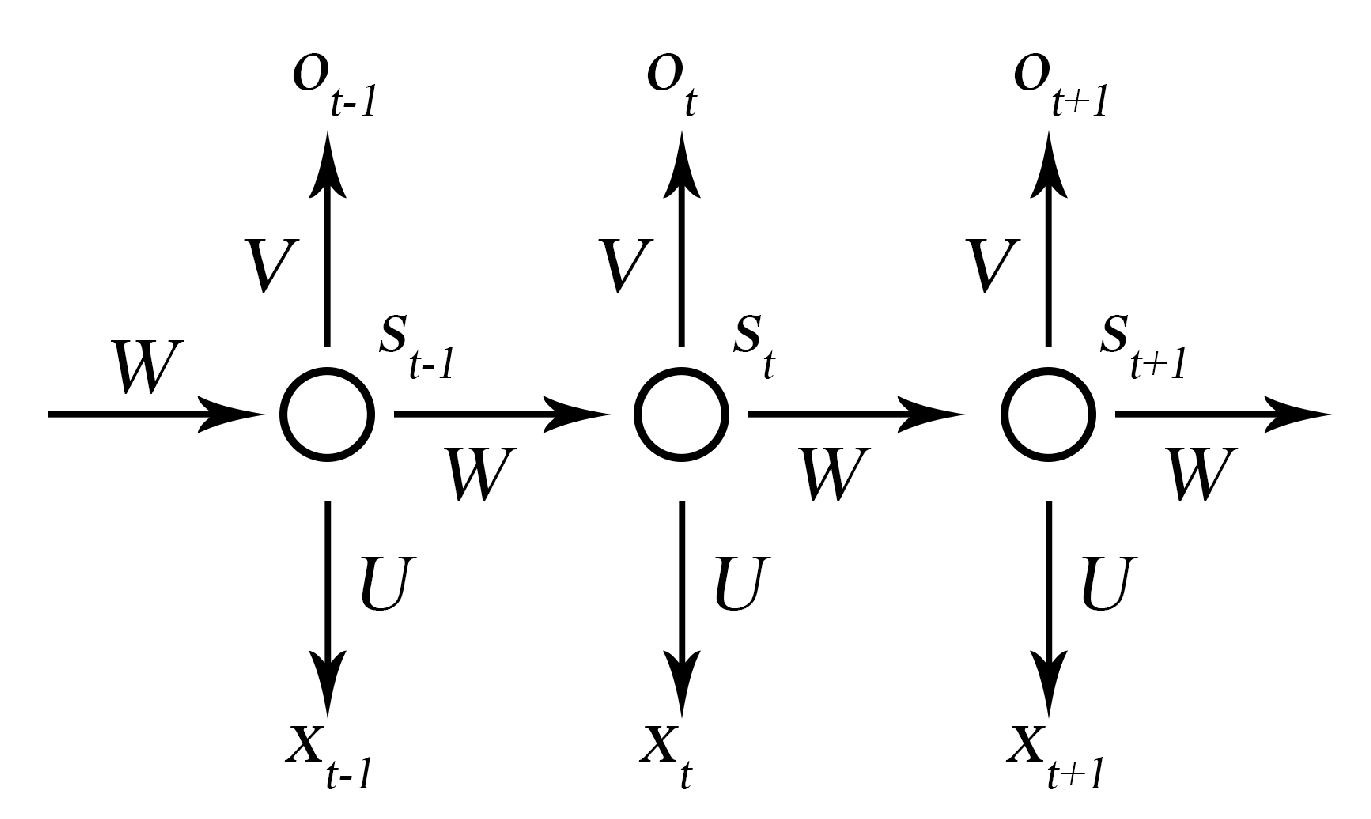
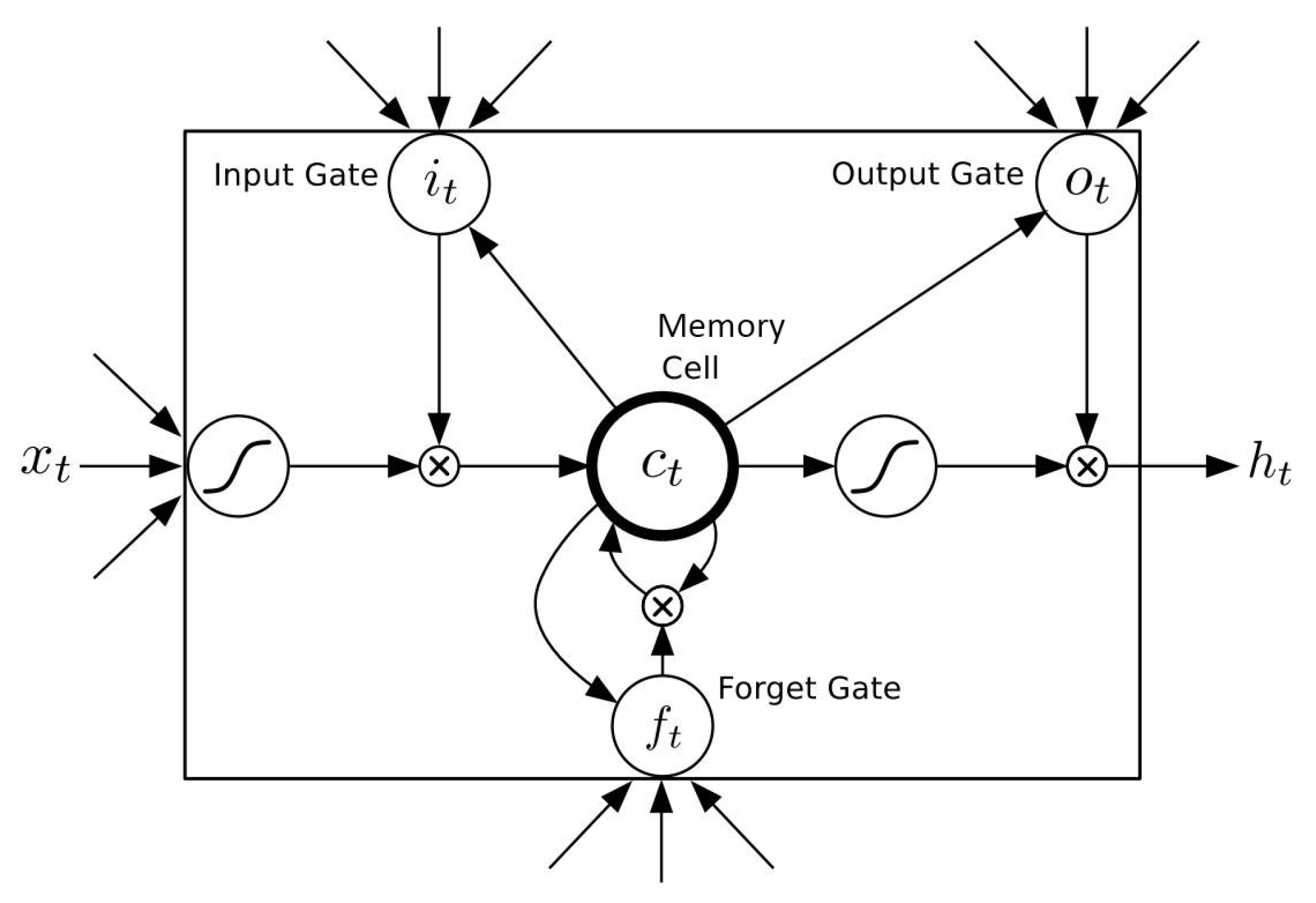
4.3. LSTM Neural Network
4.4. The Segmentation Method of Time Series
| Algorithm 3 Algorithm of the time series data segmentation. |
| Input: Time series |
| Output: The aggregate of mapping relationships between previous series and target values |
| 1: for do |
| 2: The previous series |
| 3: The corresponding value of the previous series |
| 4: end for |
| 5: Obtain the aggregate of previous series |
| 6: Obtain the aggregate of target values |
4.5. Circumstance Setting
4.5.1. Circumstance without Policy
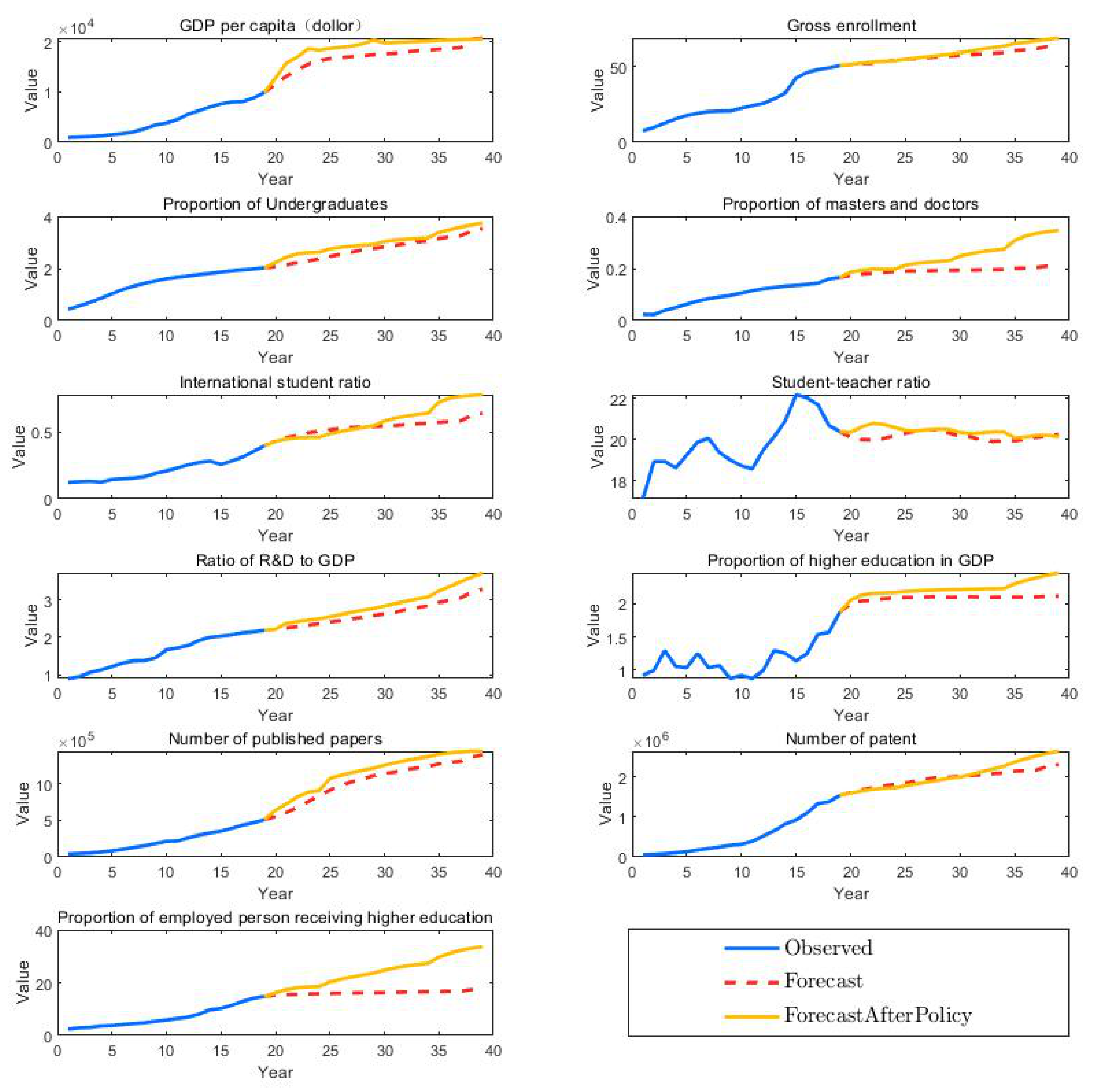
4.5.2. Circumstances with Policies
- Specific Policies and TimelineConsidering that the national policies are not static, we assume that the policies are adjusted once every 5 years, and the current higher education system is evaluated periodically accordingly. While implementing the policies, we focus on the evaluation of China’s higher education. According to the model prediction results without policy influence, we design the policies and timeline as shown in Table 7. The timeline describes the key improvement indicators and corresponding policies every 5 years. Moreover, the timeline only represents the main implementation time, not the end time, of the policies.The details are illustrated as follows.
- –
- 2019–2023: Build a good foundation(1) Strongly develop the economy and build a good foundation of education: According to the poverty line standard established by the world bank, as an upper-middle-income country, the number of poor people in China is calculated according to the standard of 5.50 international dollars per day. In the “World Bank East Asia and Pacific Economic Update—Spring 2022” [28] released on 4 April 2022, it is estimated that the total number of poor people in China in 2022 is 153 million, and the poverty rate comes to 10.83%. Although the number of poor people in China has decreased rapidly in recent years, it is undeniable that due to China’s huge population base, the poor population will still hinder China’s educational development. If we want to popularize higher education, we must strongly develop the economy and minimize the development differences between regions. Therefore, the first priority is to reduce poverty in poor areas and thus the proportion of the poor population while targeting the national economy for better GDP. In addition, it is important to improve basic education, particularly in those disadvantaged provinces. The more developed the basic education, the better the source of higher education for students.(2) Increase investment in universities and build a good foundation for schools: Universities are the foundation of higher education. Increasing investment in universities helps improve school environment and scientific research, which lead future universities to accommodate and train more outstanding talents and thus, in turn, build a good foundation for universities.
- –
- 2023–2027: Innovation model(1) Educate the capabilities of innovation and emphasize research talents: China’s technological innovation has been a weakness, so universities should focus on training some research talents and improve students’ innovative capabilities. With the implementation of the policy from 2019 to 2023, the proportion of undergraduate students is expected to increase, as is the proportion of master’s and doctoral students through the cultivation of innovative research talents. Transforming undergraduates into high-quality and large-volume master’s and doctoral students is also a way to increase research talents to some degree.(2) School and enterprise developing together to explore entrepreneurial talents: Entrepreneurial talents are also necessary. We can innovate the school training system and cooperate with large enterprises, enhance the capabilities of innovation and entrepreneurship and promote the transformation of industrial innovation at the same time.
- –
- 2028–2033: Key scientific researchAbsorb high-quality talents and search for technological innovation. At this stage, we need to focus on scientific research, introduce more excellent young scholars and teachers and reduce the ratio of students to teachers to ensure quality of teaching. By increasing investment in scientific research, we enhance the scientific research capabilities of colleges and research institutes and boost the output of papers and patents.
- –
- 2034–2038: InternationalizationBroaden international horizon and improve treatment of international students. When the foundation of China’s higher education system develops, it becomes more attractive to top international talents and thus they are more inclined to study in China. If China further improves services for foreign students, the proportion of foreign students would rise even further, making the education system more open and diverse.
- Improvement of the Model After the policy’s formulation, we need to quantify the impact of the policy on all aspects of higher education and add it to the model. However, due to the lack of training set data, we refer to the econometric model of the impact of policy factors on China’s higher education investment proposed by Cheng et al. [29] and obtain constructive conclusions in this paper. In their paper, they made a quantitative analysis of the degree to which China’s education policy factors affected higher education investment from 1985 to 2007. The results of the model show that under the condition of determining the level of economic development, the impact of education policy on higher education investment is positive. However, under the limited conditions, such as the determination of the scale of college students, the impact of education policy on the total investment in higher education is negative. For instance, due to the impact of a series of major education policies promulgated and implemented in 1993, investment in higher education increased by an average of CNY 1 million under the condition that the economic aggregate remained unchanged and decreased by an average of CNY 40 million when the number of college students remained unchanged. In addition, after the enrollment expansion policy was implemented in 1999, the investment in higher education increased by an average of CNY 2 million under the condition that the economic aggregate remained unchanged, When the number of college students remains unchanged, the average decrease is CNY 5 million. Inspired by this paper, we define the impact of policies on different indicators. According to our model, when policies change, it impacts the prediction of the original series periodically. We assume the impact factor of policy on each indicator as . Obviously, is sensitive to different indicators. In China, since the promulgation and implementation of policies generally take five years as a cycle, the value of each cycle is the same. Combining with China’s specific national conditions, the values of for each indicator in different cycles are shown in Table 8.
5. Performance Evaluation
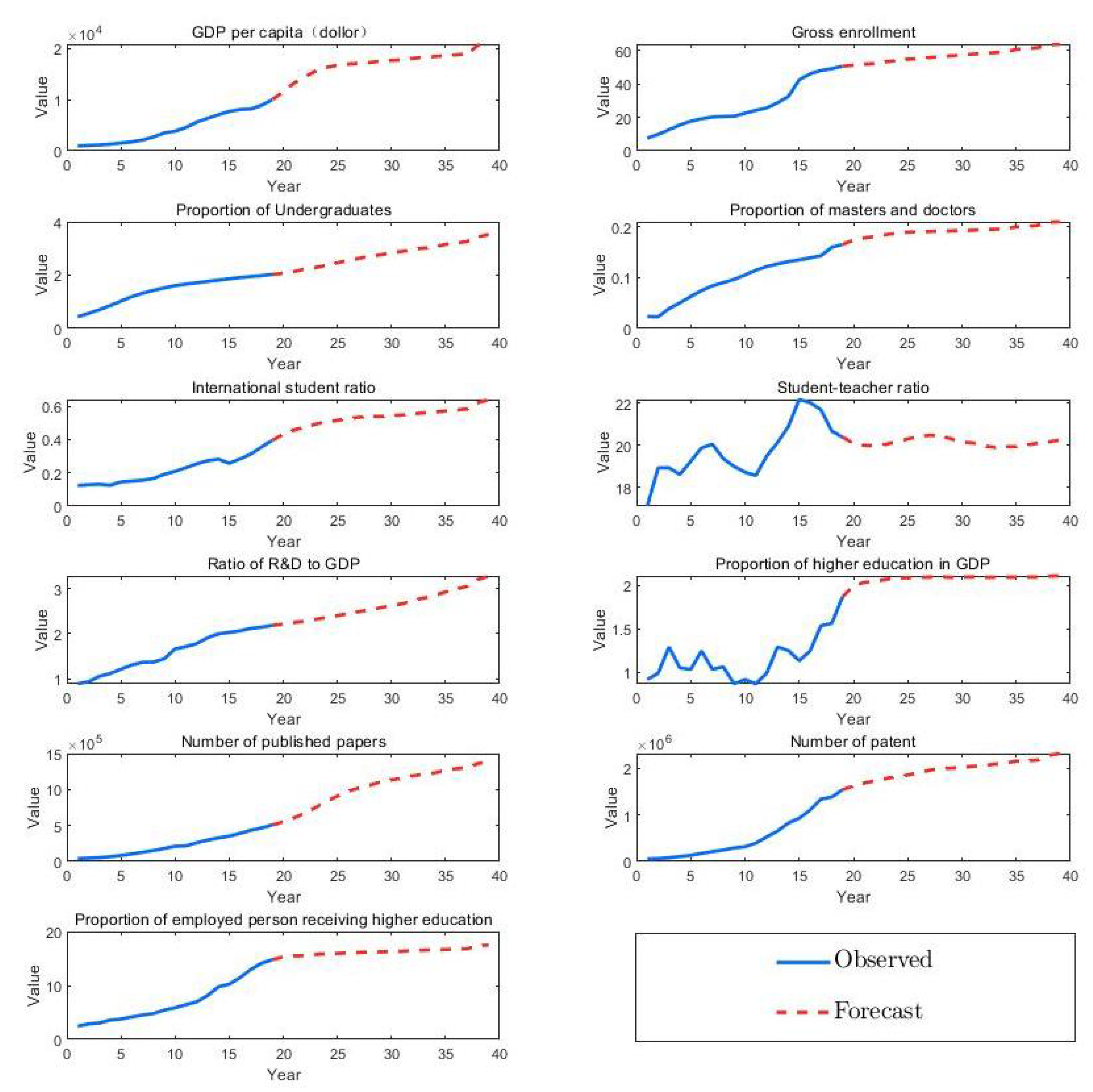
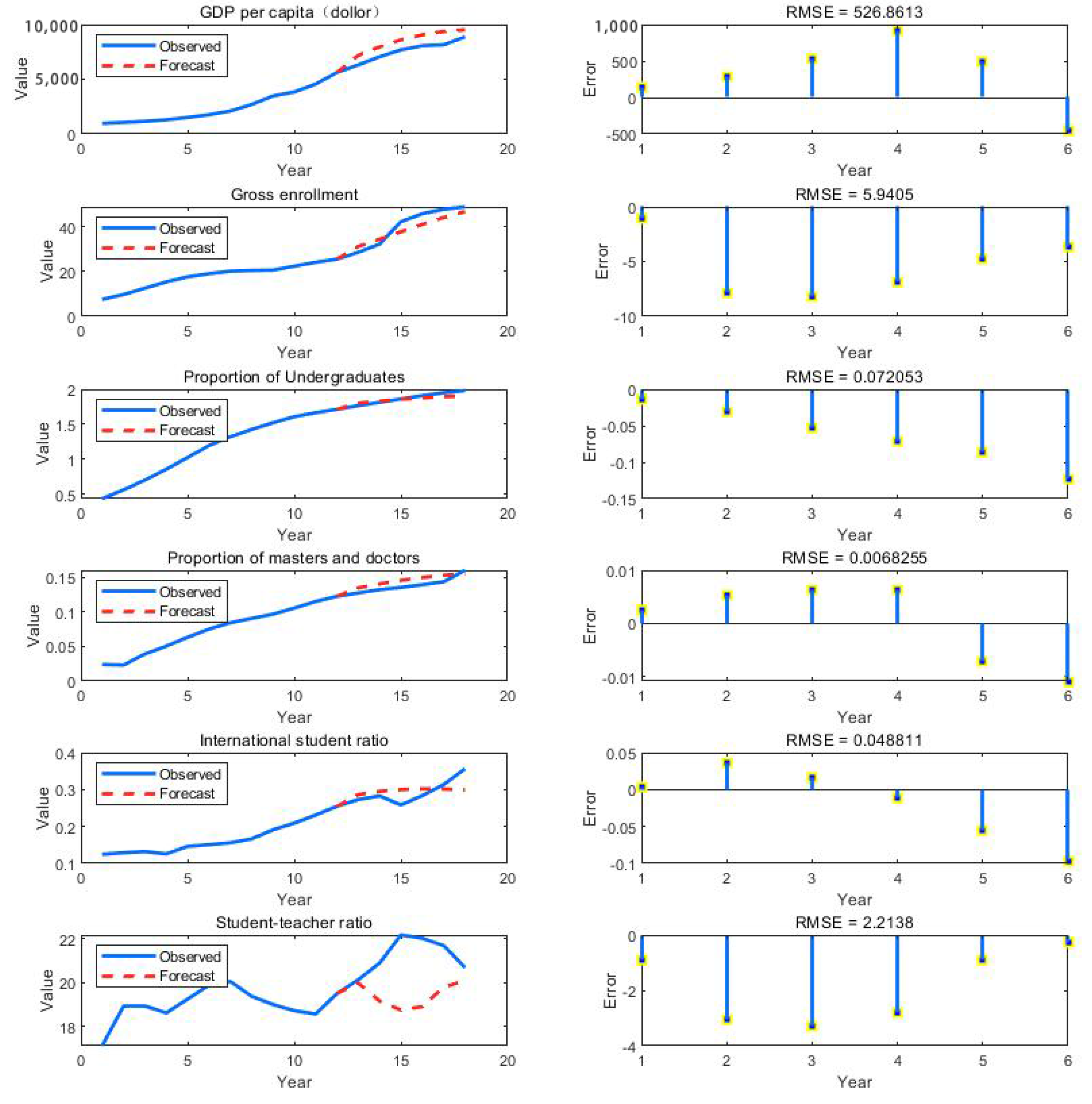
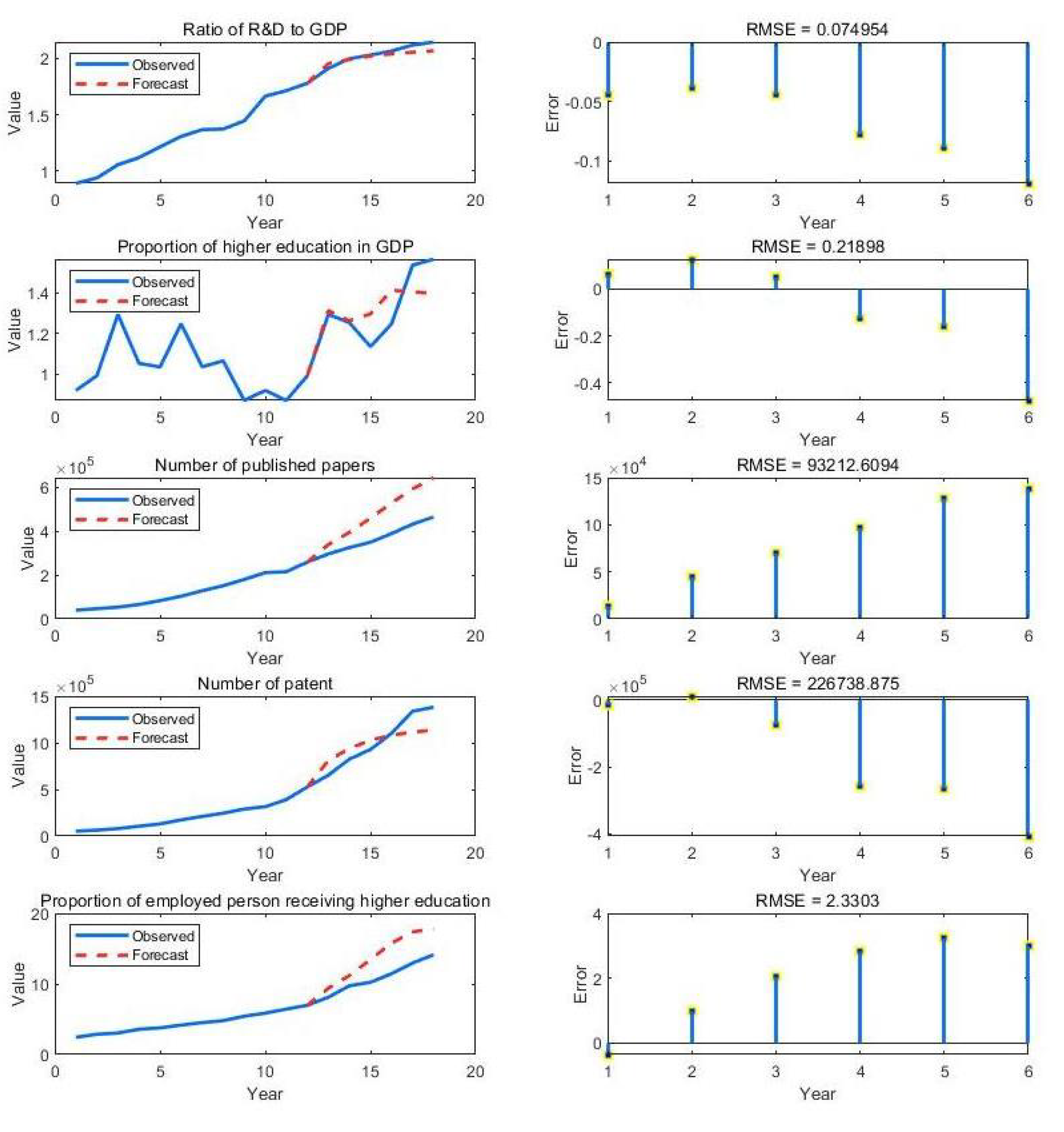
5.1. Experimental Results without Policy Influence
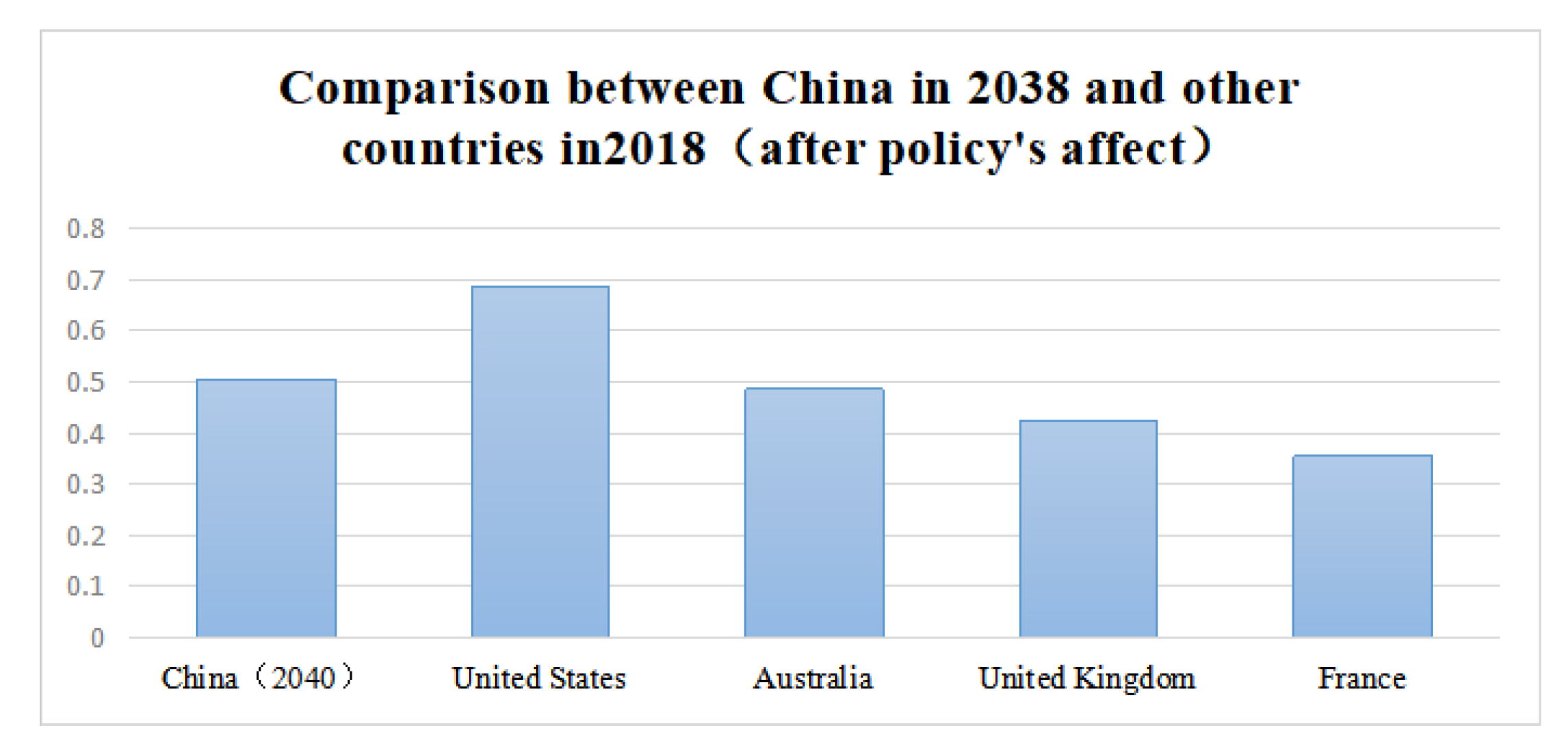
5.2. Experimental Results with Policy Influence
Impact of Policy Implementation
- For students: There will be gradually increasing opportunities for them to receive higher education, even with allowances for those poorer ones. However, rising gross enrollment rate and innovative requirements from the society lead universities’ students to compete more intensely. Their pressures from learning and competition remain after the policies are implemented, involving better study environments and more abundant teaching resources.
- For teachers: During the transformation period (SAME questions what to what), they will be better treated with more benefits and scientific research funds, which promote better research projects. Initially, the ratio of students to teachers increases, and so do the teachers’ duties. However, their burdens may be lessened after the implementation of new policies in 2029. With the implementation of supportive policies for scientific research and institutions, teachers’ capabilities required by the schools will be improved as well. These include teaching and scientific investigations, two main tasks for university teachers.
- For universities: It is valuable to raise construction funds, scientific research funds and the number and quality of students. However, this also brings pressure on the management of students, especially international students. At the same time, with continuous improvement in innovation and entrepreneurship training systems, universities need to keep a balance between enterprises and scientific research. It is a long-term goal for universities to be diversified and top-notch in teaching and scientific research. Such a transformation comes with great pressure. Even afterwards, universities need to constantly make adjustments to adapt to reality.
- For countries: As for reforms in the higher education system, the fundamental purpose is to make the system play a better role in promoting economic development and industrial innovation. There are going to be resistances and difficulties facing the national reforms. Constructions of basic education, the combination of schools and enterprises and investments in universities all have an impact country-wide. After the transformation, the higher education system will be gradually improved with national supports and therefore promote social progresses and national developments. However, in the process of transformation, there will be great resistance, such as the problem of funds, whether the results can be produced on time, the problem of multicultural interaction with the increase in foreign students and the problem of academic stress. According to our prediction, it is very difficult to improve the education system in the short term.
5.3. Sensitivity Analysis
- Preprocessing: For variables to be predicted in the dataset, we calculate their periodic values and rank them from small to large. Next, we obtain the periodic values of the first N smallest variables to be predicted. Then, we calculate the correlation coefficients between the variables and those to be predicted and arrange the variables in order from large to small according to their corresponding correlation coefficients. Finally, we extract the variables with sums of correlation coefficients being greater than a coefficient threshold to form a training set.
- LSTM modeling: We organize the training set into a time sequence and input the time sequence into the LSTM network composed of multiple connected LSTM units to obtain the current training model.
- Optimizing: We use the training model to calculate the values of the variables predicted at the set time and compare them with the actual values of the variables predicted to obtain the root mean square errors (RMSEs). Compared with the RMSEs of previous rounds of training, the smaller values are taken as the RMSEs of current rounds of training, and the corresponding training model is reserved as the optimal solution model.
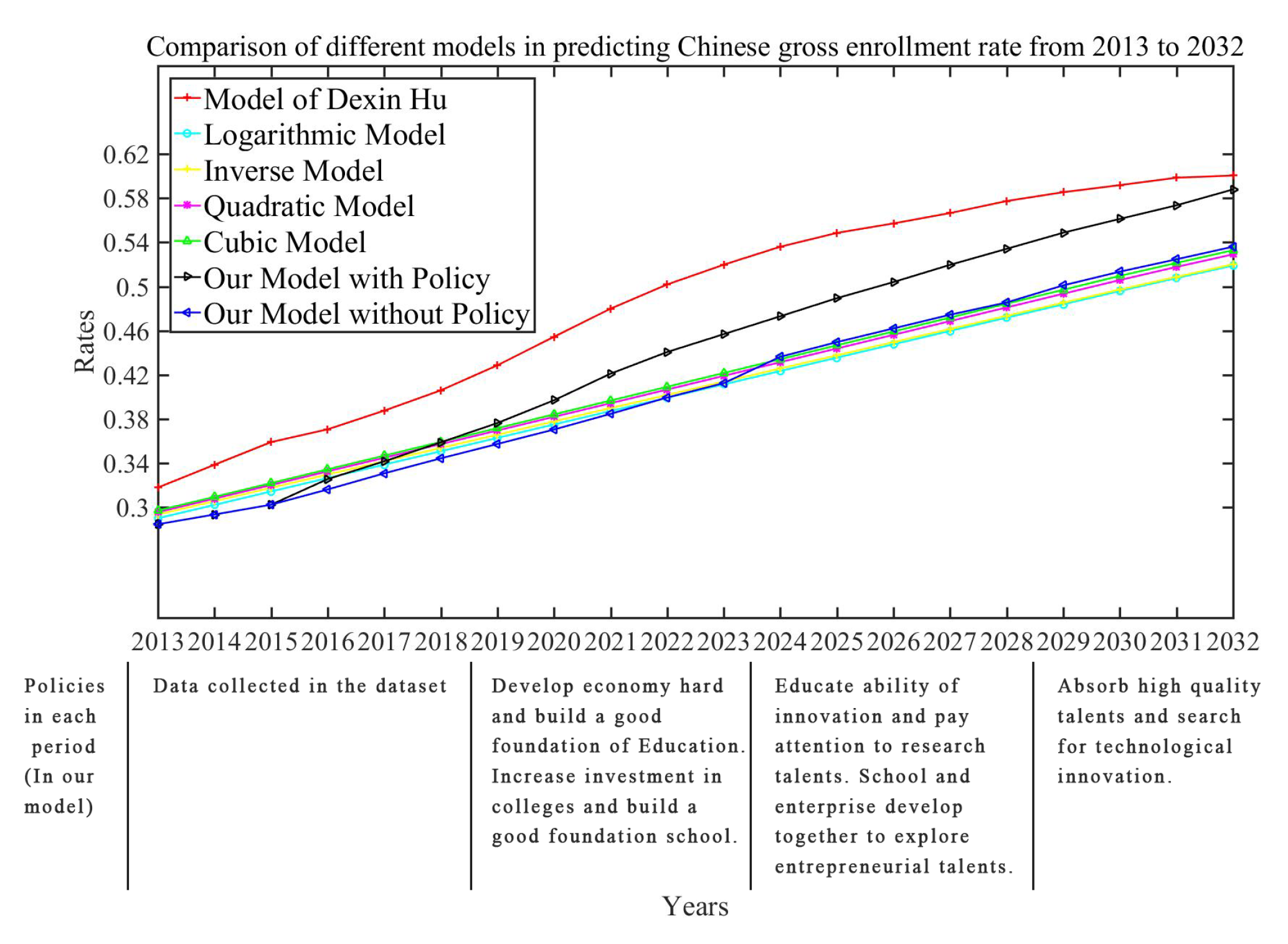
5.4. Comparison with Other Models
5.5. Some Defects of Our Model
6. Conclusions and Future Work
- Standardizing investment behavior. While encouraging the expansion of the investment scale of higher education and scientific research, we should also avoid the waste of social resources caused by ineffective investment. The waste of resources is mainly concentrated in the aspects of material and financial. On the one hand, currently, many colleges and universities have the phenomenon that the utilization rate of scientific research equipment is low or even idle. According to the statistics of the State Education Commission of the PRC, more than 20% of instruments and equipment in universities across the country are idle, and the utilization rate of expensive large-scale scientific research equipment is no more than 15%. On the other hand, a few researchers apply for scientific research projects purely for “money”. Once the scientific research project is established, they ignore the rationality and efficiency of the use of funds, resulting in the false use of project funds and serious economic waste. Thus, achieving a rational allocation of resources and making the best use of educational investment is of great significance for accelerating the development of higher education.In view of the above waste of resources, we can make the following suggestions: In the aspects of resource investment, the government should reduce direct investment and encourage universities to seek funding channels by improving education quality and efficiency. In the management of universities, we should improve the use efficiency of teaching instruments and equipment, avoid the waste caused by the repeated purchase of equipment as far as possible, standardize the use of instruments by teachers and students, reduce the cost of maintenance and the loss of instruments and equipment and make the best use of ground objects to the greatest extent. Be familiar with the macro development trend of higher education and create a development environment that conforms to the trend of the times for higher education. Higher education is always influenced by the macro trends taking place in the surrounding world, which will shape the future of higher education and teaching. For example, due to the implementation of some university construction projects, the international ranking of Chinese universities has been rising rapidly. On the other hand, it has also caused a serious uneven distribution of resources among universities. The economically developed eastern region of China occupies a vast amount of educational resources. Even if some universities in the western region have a deep foundation, they are gradually overtaken by the eastern universities due to a lack of resources. In addition, teachers’ degrees in China’s colleges and universities have generally improved, which also makes the competition for teachers’ positions increasingly fierce, and the student-teacher ratio has increased slightly. In addition, the digital learning environment is changing the way higher education institutions build learning ecosystems for learners and teachers. Higher education institutions increasingly need to support open standards in the application of educational technology so that they can provide more students with a flexible learning experience. The current situation and development trend of higher education will provide a general direction for the government’s policy making.After understanding the development status of China’s higher education, we can put forward the following suggestions: (1) Advocate the effective exchange of regional educational resources, such as the mode of the joint running of colleges and universities and the mutual recognition of course examination results established in Wuhan. Thus, we can further integrate regional educational resources. (2) Give full play to the role of open education resources to promote the sustainable development of online education. (3) Pay attention to the individual differences among students and realize the accurate allocation of teaching resources according to the different learning conditions of students. Carry out reforms of the talent training system, including the integration of interdisciplinary scientific research and teaching. Higher education institutions can be encouraged to carry out wide-area interdisciplinary scientific research on major social issues, such as water cleaning, environmental sustainable development, gender equality, high-risk language protection and local noncultural heritage protection. In addition, the establishment of national laboratories, online periodical resource platforms and interschool collaborative network platforms promote necessary infrastructures and resources for high-quality graduate education.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Millot, B. International rankings: Universities vs. higher education systems. Int. J. Educ. Dev. 2015, 40, 156–165. [Google Scholar] [CrossRef]
- Yi, M.C. Popularization process of higher education in China and its influencing factors—Prediction based on time series trend extrapolation model. China High. Educ. Res. 2016, 3, 47–55. [Google Scholar]
- Pereira, C.A.; Araujo, J.F.; Maria, M.T. The Brazilian higher education evaluation model: “SINAES” sui generis? Int. J. Educ. Dev. 2018, 61, 5–15. [Google Scholar] [CrossRef] [Green Version]
- Khatibi, V.; Keramati, A.; Shirazi, F. Deployment of a business intelligence model to evaluate Iranian national higher education. Soc. Sci. Humanit. Open 2020, 2, 100056. [Google Scholar] [CrossRef]
- Benito, M.; Gil, P.; Romera, R. Evaluating the influence of country characteristics on the Higher Education System Rankings’ progress. J. Inf. 2020, 14, 101051. [Google Scholar] [CrossRef]
- Kajol, R.S.; Neethu, K.P.; Madhurekaa, K.; Harita, A.; Mohan, P. Parallel SVM model for forest fire prediction. Soft Comput. Lett. 2021, 3, 100014. [Google Scholar]
- Gao, Y.F.; Hang, Y.; Yang, M.L. A cooling load prediction method using improved CEEMDAN and Markov Chains correction. J. Build. Eng. 2021, 42, 103041. [Google Scholar] [CrossRef]
- Duan, H.M.; Pang, X.Y. A multivariate grey prediction model based on energy logistic equation and its application in energy prediction in China. Energy 2021, 229, 120716. [Google Scholar] [CrossRef]
- Arar, M.F.; Ayan, K. A feature dependent Naive Bayes approach and its application to the software defect prediction problem. Appl. Soft Comput. 2017, 59, 197–209. [Google Scholar] [CrossRef]
- Ekmekcioglu, O.; Koc, K.; Ozger, M. Stakeholder Perceptions in Flood Risk Assessment: A Hybrid Fuzzy AHP-TOPSIS Approach for Istanbul, Turkey. Int. J. Disaster Risk Reduct. 2021, 60, 102327. [Google Scholar] [CrossRef]
- Bakioglu, G.; Atahan, A.O. AHP integrated TOPSIS and VIKOR methods with Pythagorean fuzzy sets to prioritize risks in self-driving vehicles. Appl. Soft Comput. 2020, 99, 106948. [Google Scholar] [CrossRef]
- Azimifard, A.; Moosavirad, S.H.; Ariafar, S. Selecting sustainable supplier countries for Iran’s steel industry at three levels by using AHP and TOPSIS methods. Resour. Policy 2018, 57, 30–44. [Google Scholar] [CrossRef]
- Vasan, D.; Alazab, M.; Wassan, S.; Safaei, B.; Zheng, Q. Image-Based malware classification using ensemble of CNN architectures (IMCEC). Comput. Secur. 2020, 92, 101748. [Google Scholar] [CrossRef]
- Chen, W.L.; Yeo, C.K.; Lau, C.T.; Lee, B.S. Leveraging social media news to predict stock index movement using RNN-boost. Data Knowl. Eng. 2018, 118, 14–24. [Google Scholar] [CrossRef]
- Inoue, K.; Hara, S.; Abe, M.; Hojo, N.; Ijima, Y. Model architectures to extrapolate emotional expressions in DNN-based text-to-speech. Speech Commun. 2021, 126, 35–43. [Google Scholar] [CrossRef]
- Atila, O.; Sengur, A. Attention guided 3D CNN-LSTM model for accurate speech based emotion recognition. Appl. Acoust. 2021, 182, 108260. [Google Scholar] [CrossRef]
- Yan, Y.; Xing, H.Y. A sea clutter detection method based on LSTM error frequency domain conversion. Alex. Eng. J. 2021, 61, 883–891. [Google Scholar] [CrossRef]
- Zhang, J.; Li, K.K.; Wang, Z. Parallel-fusion LSTM with synchronous semantic and visual information for image captioning. J. Vis. Commun. Image Represent. 2021, 75, 103044. [Google Scholar] [CrossRef]
- Gao, X.; Li, W.D. A graph-based LSTM model for PM2.5 forecasting. Atmos. Pollut. Res. 2021, 12, 101150. [Google Scholar] [CrossRef]
- Zhao, X.; Rui, X.T.; Li, C.; Ma, Z.Z.; Miao, Y.F. Evaluation and prediction methods for launch safety of propellant charge based on support vector regression. Appl. Soft Comput. 2021, 109, 107527. [Google Scholar] [CrossRef]
- Huang, K.; Lu, S.L.; Yuan, J.; Han, Z.; Wang, C.; Zhoua, Z. Evaluation of the operation data for improving the prediction accuracy of heating parameters in heating substation. Energy 2021, 238, 121632. [Google Scholar]
- Yong, Q.; Ou, L.Y. Research on the Quality Evaluation of Higher Education Development Based on CIPP Model. Sci. Educ. Lit. Collect. 2020, 3, 1–3. [Google Scholar]
- Wolszczak-Derlacz, J. An evaluation and explanation of (in)efficiency in higher education institutions in Europe and the U.S. with the application of two-stage semi-parametric DEA. Res. Policy 2017, 46, 1595–1605. [Google Scholar] [CrossRef]
- Saaty, T.L.; Vargas, L.G. Models, Methods, Concepts and Applications of the Analytic Hierarchy Process (book). In International Series in Operations Research &Management Science; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Yoon, K.; Hwang, C.L. Multiple attribute decision making. Eur. J. Oper. Res. 1995, 4, 287–288. [Google Scholar]
- Wei, J.C. Research on Vietnam’s Higher Education Policies and Regulations Since 1950s; Guangxi University for Nationalities: Nanning, China, 2013. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 8. [Google Scholar] [CrossRef]
- World Bank GROUP. World Bank East Asia and The Pacific Economic Update. In World Bank Other Operational Studies; World Bank Group: Washington, DC, USA, 2022. [Google Scholar]
- Cheng, L.F.; Zuo, J.J. An quantified model of the impact policy on China’s higher education. Mod. Educ. Manag. 2011, 9, 19–23. [Google Scholar]
- Hu, Y.M.; Tang, Y.P. Prediction of the scale of students and financial investment in Higher Education during the 14th five year plan. Chongqing High. Educ. Res. 2019, 7, 10–22. [Google Scholar]
- Mi, H.; Wen, X.L.; Zhou, Z.G. An empirical analysis of population factors and the change of China’s higher education scale in the next 20 years. Popul. Res. 2003, 6, 76–81. [Google Scholar]
- Bie, D.R.; Yi, M.C. Development standard, process prediction and path selection of higher education popularization. Educ. Res. 2021, 42, 63–79. [Google Scholar]
- Zheng, F.X. Comparative study of ARIMA and exponential smoothing in regional higher education scale prediction. J. Sichuan Univ. Sci. Technol. 2013, 26, 83–85. [Google Scholar]
- Li, S.H.; Li, W.P. Research on the scale development of China’s higher education from 2013 to 2030—Based on the analysis of the age population and economic level. Open Educ. Res. 2013, 19, 73–80. [Google Scholar]
- Hu, D.X.; Wang, M. Trend prediction of China’s higher education scale from 2016 to 2032. Educ. Acad. Mon. 2016, 6, 3–7. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standard | Second-Level Indicators | Weight |
|---|---|---|
| Research | Academic Reputation | 40% |
| Citations per faculty | 20% | |
| Teaching | Faculty/Student Ratio | 20% |
| Employment Ability of the Graduate | Global Employer Reputation | 10% |
| Internationalization | International Faculty Ratio | 5% |
| International Student Ratio | 5% |
| A | ⋯ | |||
|---|---|---|---|---|
| ⋯ | ||||
| ⋯ | ||||
| ⋯ |
| Ratio of to | Quantized Value |
|---|---|
| Equally important | 1 |
| A little more important | 3 |
| More important | 5 |
| Strongly important | 7 |
| Extremely important | 9 |
| The middle value between two judgments | 2, 4, 6, 8 |
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 |
| General Purpose | First-Level Indicators | Secondary Indicators |
|---|---|---|
| A Health assessment model of higher education system | B1 Foundation of higher education (0.3198) | C1 GDP per capita (current US dollar) (0.4852) |
| C2 Gross enrollment rate (0.2968) | ||
| C3 Proportion of undergraduates (0.1090) | ||
| C4 Proportion of masters and doctors (0.1090) | ||
| B2 Quality of higher education (0.3632) | C5 International student ratio (0.2922) | |
| C6 Student-teacher ratio (0.0925) | ||
| C7 Top 1000 universities in QS (0.6163) | ||
| B3 Investment in higher education (0.1788) | C8 Proportion of higher education in GDP (0.5000) | |
| C9 Ratio of R&D to GDP (0.5000) | ||
| B4 Achievements of higher education (0.1382) | C10 Number of SCI papers published (0.5396) | |
| C11 Proportion of employed persons receiving higher education (0.2970) | ||
| C12 Number of patents (0.1634) |
| Number of hidden layers | 200 |
| Loss function | MSE |
| Learning rate | 0.005 |
| Gradient threshold | 1 |
| Optimizer | Adam |
| Maximum training rounds | 250 |
| Time | 2019–2023 | 2024–2028 | 2029–2033 | 2034–2038 |
|---|---|---|---|---|
| Important indicators | GDP per capita Gross enrollment rate Ratio of R&D to GDP Proportion of higher education in GDP | Proportion of undergraduates Proportion of masters and doctors International student ratio | Student teacher ratio Number of SCI papers Number of patents | International student ratio |
| Corresponding policies | Develop hard economy and build a good foundation of education Increase investment in colleges and build a good foundation for schools | Educate the ability of innovation and pay attention to research talents School and enterprise developing together to explore entrepreneurial talents | Absorb high-quality talents and search for technological innovation | Broaden international horizon and improve the treatment of students |
| 2018–2023 | 2024–2028 | 2029–2033 | 2034–2038 | |
|---|---|---|---|---|
| GDP per capita | 0.6 | 0.5 | 0.3 | 0.3 |
| Gross enrollment rate | 0.25 | 0.2 | 0.1 | 0.1 |
| Proportion of undergraduates | 1 | 3 | 1 | 1 |
| Proportion of masters and doctors | 4 | 6 | 3 | 3 |
| International student ratio | 0.5 | 0.6 | 0.7 | 1 |
| Student-teacher ratio | −0.05 | −0.05 | −0.1 | −0.05 |
| Ratio of R&D to GDP | 0.2 | 0.2 | 0.1 | 0.1 |
| Proportion of higher education in GDP | 0.3 | 0.3 | 0.2 | 0.2 |
| Number of SCI papers published | 0.05 | 0.05 | 0.1 | 0.05 |
| Number of patents | 0.02 | 0.02 | 0.05 | 0.02 |
| Proportion of employed persons receiving higher education | 0.5 | 0.8 | 0.3 | 0.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, N.; Ren, Z.; Zhang, Z.; Fu, J. Evaluation and Prediction of Higher Education System Based on AHP-TOPSIS and LSTM Neural Network. Appl. Sci. 2022, 12, 4987. https://doi.org/10.3390/app12104987
Wang N, Ren Z, Zhang Z, Fu J. Evaluation and Prediction of Higher Education System Based on AHP-TOPSIS and LSTM Neural Network. Applied Sciences. 2022; 12(10):4987. https://doi.org/10.3390/app12104987
Chicago/Turabian StyleWang, Na, Ziru Ren, Zheng Zhang, and Junsong Fu. 2022. "Evaluation and Prediction of Higher Education System Based on AHP-TOPSIS and LSTM Neural Network" Applied Sciences 12, no. 10: 4987. https://doi.org/10.3390/app12104987