
CarFree: Hassle-Free Object Detection Dataset Generation Using Carla Autonomous Driving Simulator


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- 3D bounding boxes that represent the location and the pose of every object in the 3D coordinate;
- Camera images that are 2D RGB data from the virtual forward-facing camera installed on the ego vehicle;
- Semantic segmentation images that are pixel-wise classifications by different color codes for each corresponding camera image (e.g., blue for vehicles and red for pedestrians).
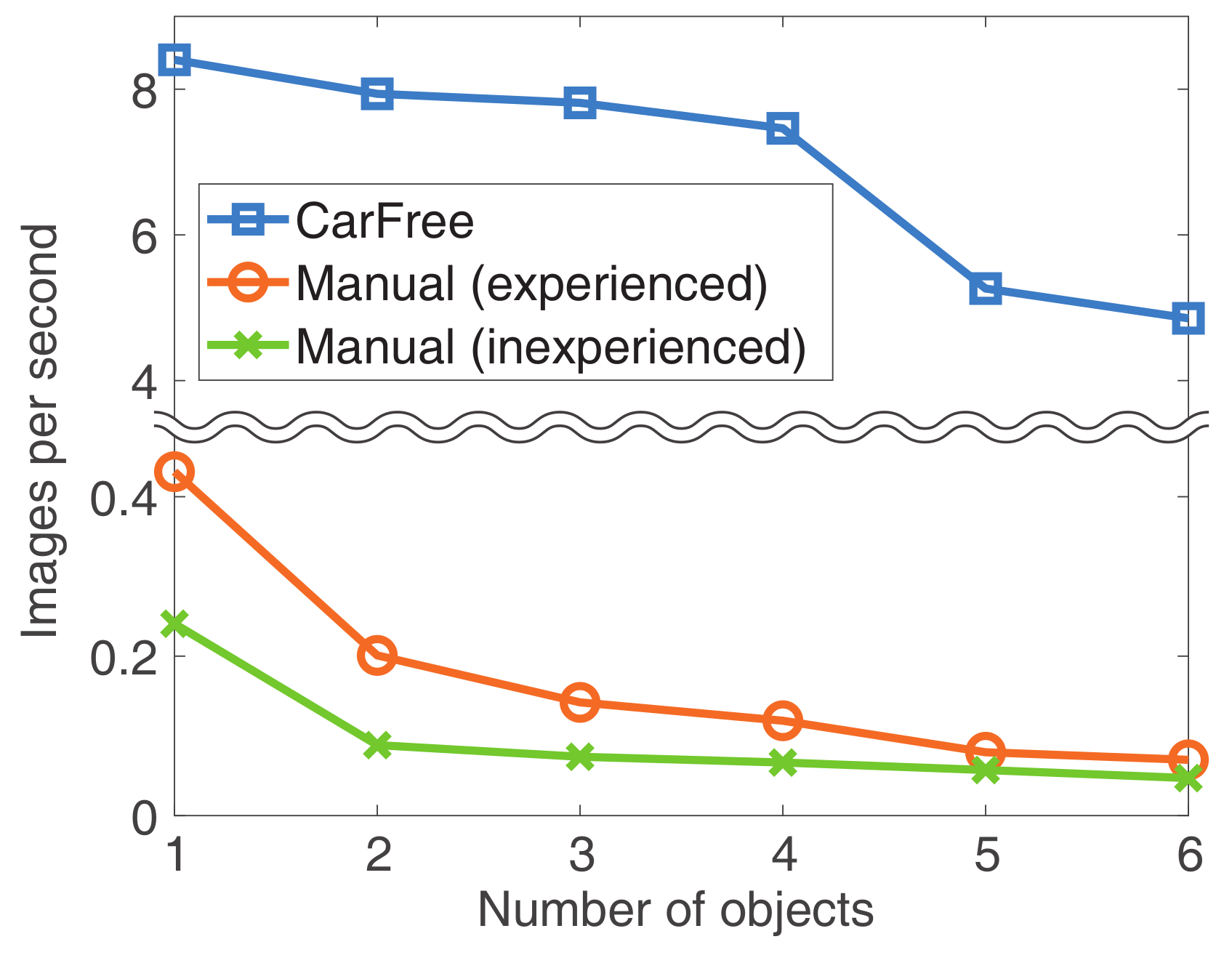
- Scalability. How many images can be processed while finding their GTs in a given time?
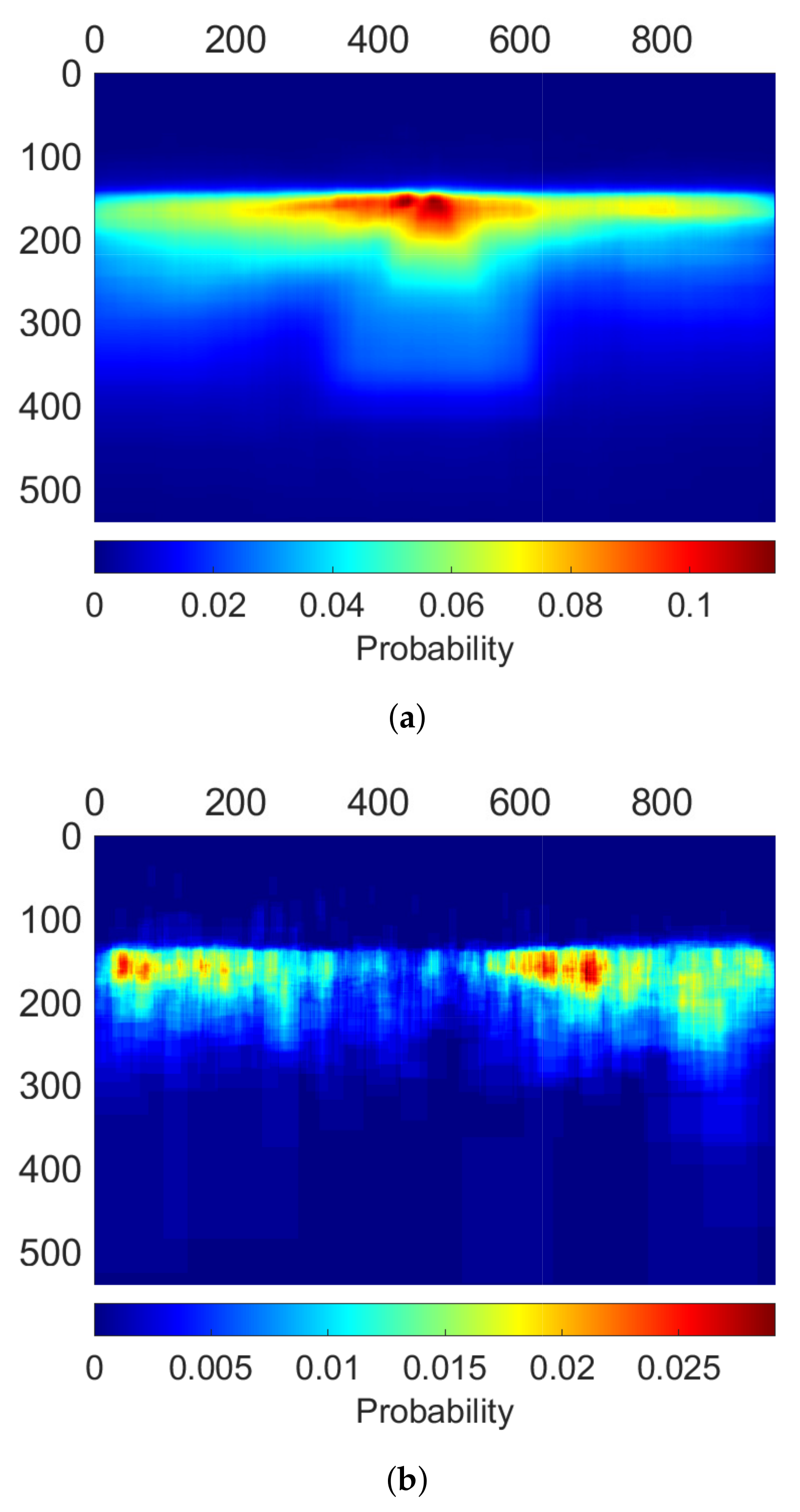
- Precision. How precise are the generated GTs in terms of locating bounding boxes?
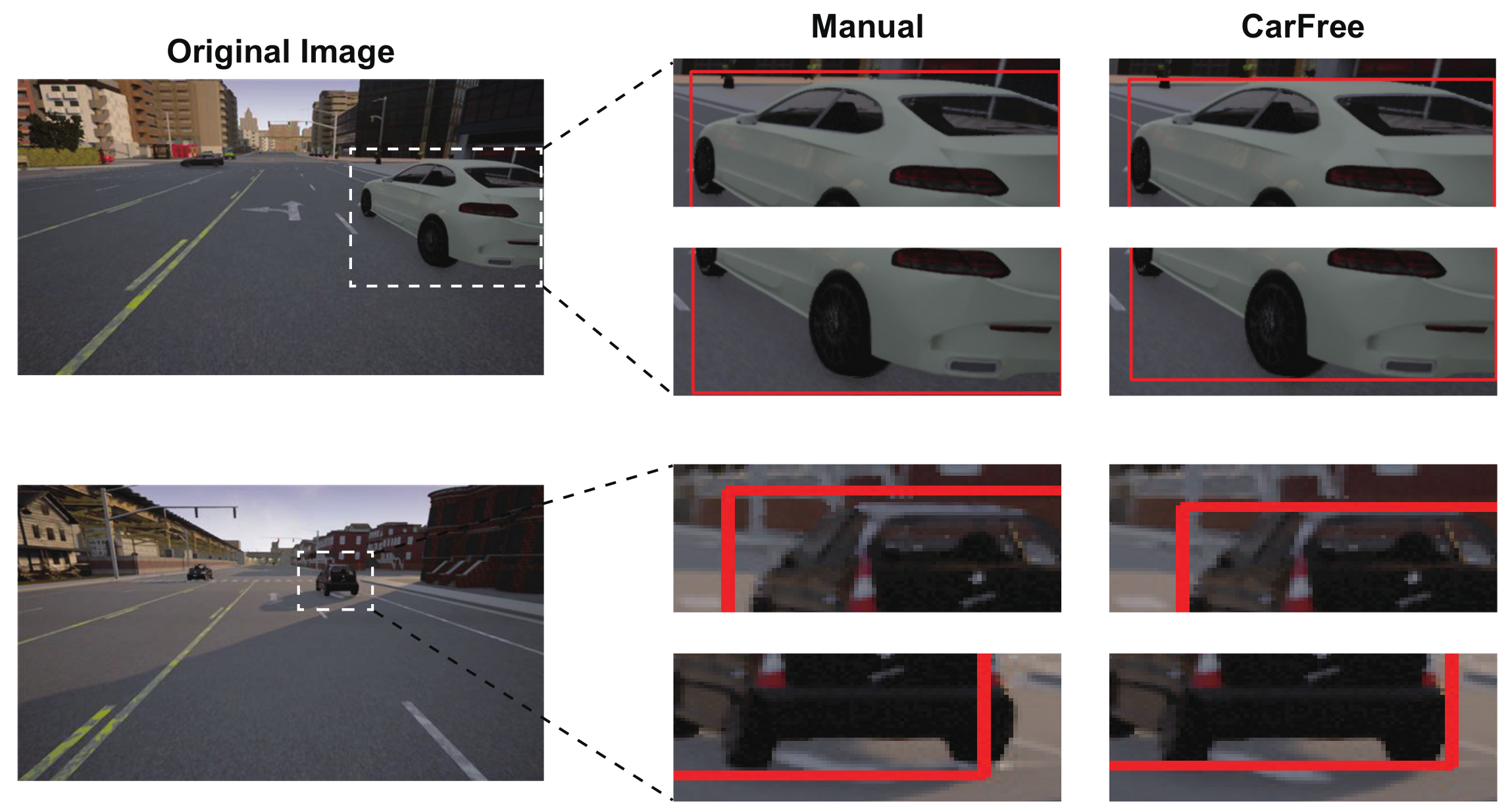
- Training performance. How effective is the generated dataset for training DNNs in terms of their object detection performance?
- To the best of our knowledge, this study is one of the first works to propose public domain, open-source tools for automatically synthesizing 2D object detection datasets for autonomous driving.
- Moreover, this study shows that by using the synthesized training dataset with diverse weather and lighting conditions, the accuracy for the real-world object detection can be significantly improved.
2. Related Work
3. Background
3.1. Object Detection for Autonomous Driving
3.2. Carla Autonomous Driving Simulator
- 3D bounding boxes and classes: Assuming n actors operating in the town, n corresponding 3D bounding boxes are extracted. A 3D bounding box is denoted by its eight corner points in the set of 3D bounding boxes {, ⋯, }, where each point C is represented by in the 3D coordinate. We can also find each actor’s class, denoted by , which is either vehicle or pedestrian.
- Camera images: A forward-facing camera is installed on the ego vehicle, from which a 960 × 540 resolution RGB image can be retrieved. Each image is given by a 960 × 540 matrix I, where each element represents the color code of the pixel at the location in the 2D image coordinate.
- Semantic segmentation images: For each RGB image, its corresponding semantic segmentation image is also extracted, given by a 960 × 540 matrix S, where each element represents the class the object the pixel belongs to by the pre-defined color codes.
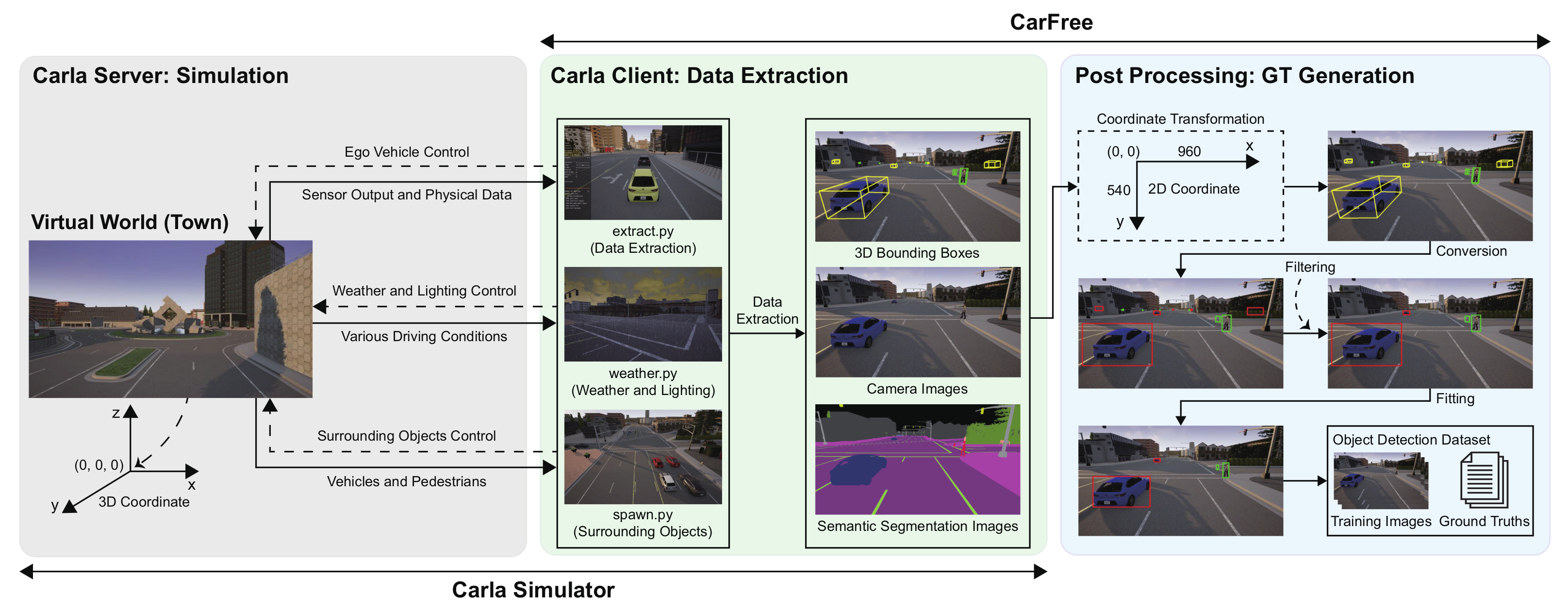
4. Overall Architecture
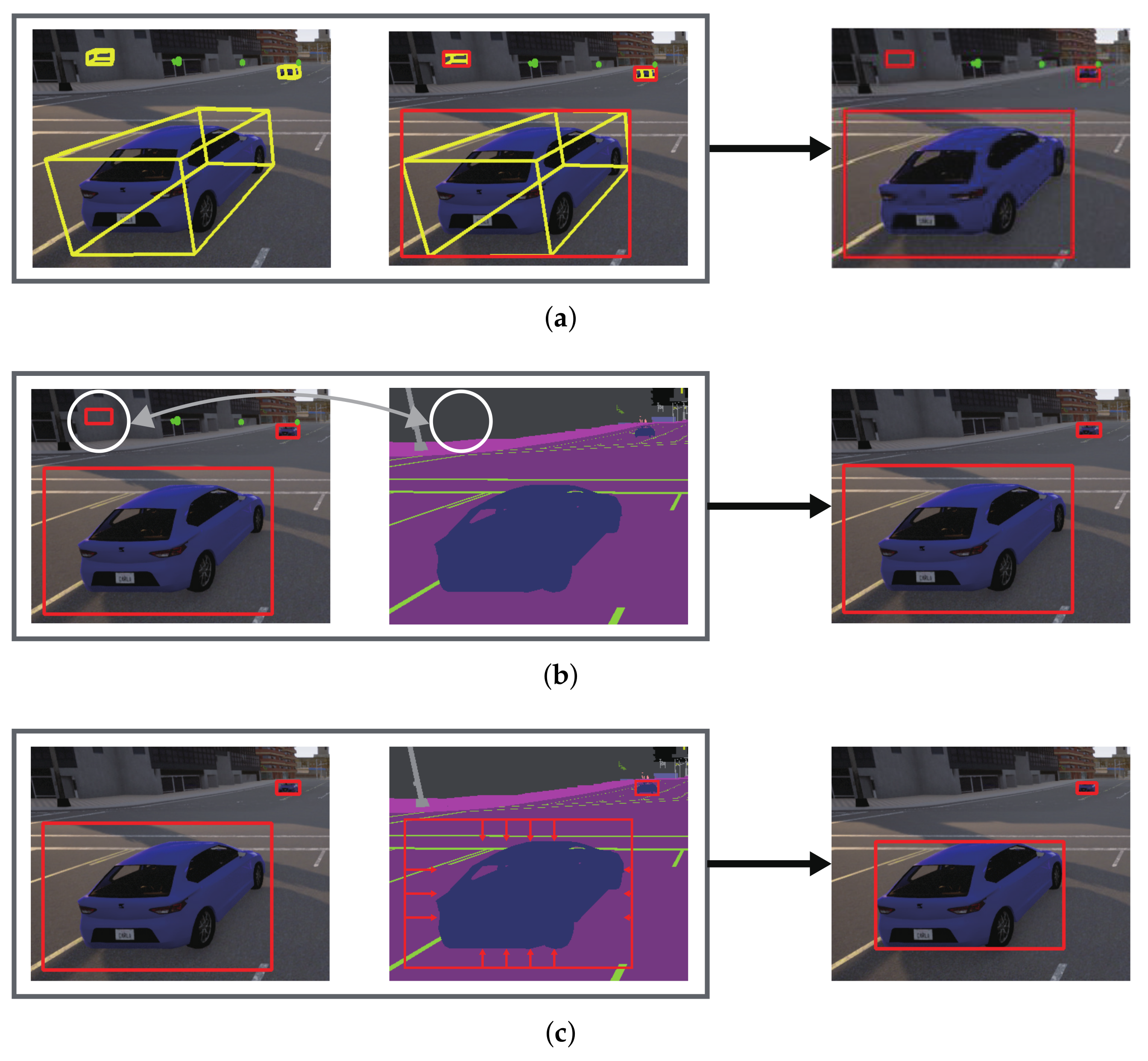
- First, the eight points of each 3D bounding box are projected to the 2D image coordinate of the forward-facing camera (Section 5.1).
- Second, for the projected eight points, their minimum area bounding box that barely encloses them is derived (Section 5.2).
- Third, occluded objects are removed because, for example, objects behind a wall are still present at this stage (Section 5.3).
- Fourth, each bounding box is tightly fitted to the object by removing the gap between the initial bounding box and the actual object boundary (Section 5.4).
5. Automatic Ground Truth Generation
5.1. Coordinate Transformation
5.2. Conversion to 2D Bounding Boxes
| Algorithm 1: Conversion to 2D bounding boxes |
Require:
Ensure:
|
5.3. Filtering out Occluded Objects
| Algorithm 2: Check the visibility of an object |
Require: Require:T: Target object class Require:S: Semantic segmentation image Ensure: True when the object is visible, False otherwise
|
| Algorithm 3: Fitting to object boundary |
Require: Require:T: Target object class Require:S: Semantic segmentation image Ensure:
|
5.4. Fitting to Object Boundary
6. Experiments
6.1. Implementation
- spawn.py for deploying required vehicles and pedestrians in the town,
- weather.py for controlling the weather and lighting conditions, and
- extract.py for controlling the ego vehicle and extracting data from the Carla server.
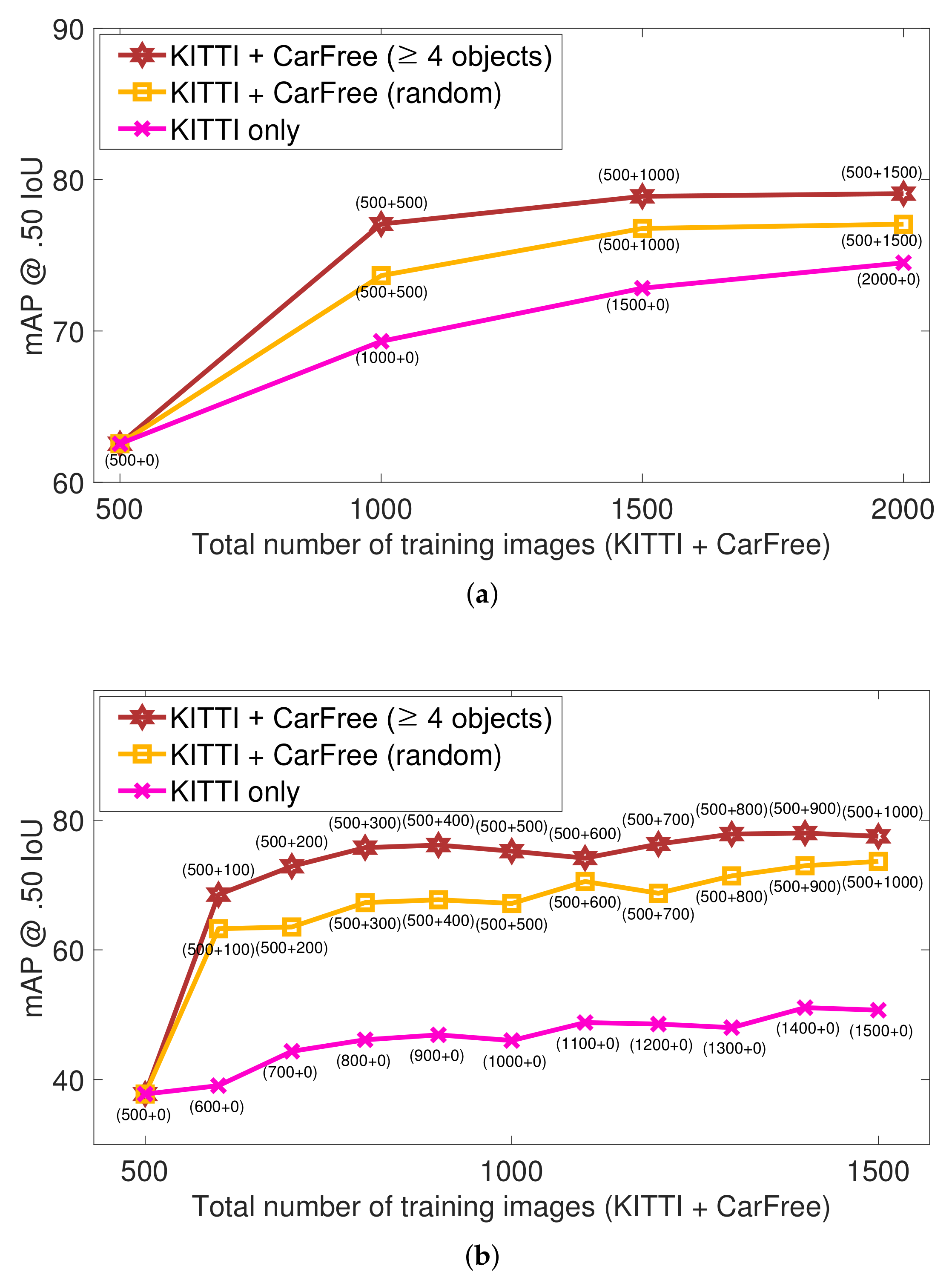
6.2. Evaluation
- KITTI only: In addition to the baseline images, other random KITTI images are incrementally added as well.
- KITTI+CarFree (random): In addition to the baseline images, our synthesized images are incrementally added in random.
- KITTI+CarFree (≥4 objects): In addition to the baseline images, our synthesized images with at least four objects are incrementally added.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Gaidon, A.; Wang, Q.; Cabon, Y.; Vig, E. Virtual worlds as proxy for multi-object tracking analysis. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4340–4349. [Google Scholar]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977. [Google Scholar]
- Cabon, Y.; Murray, N.; Humenberger, M. Virtual KITTI 2. arXiv 2020, arXiv:2001.10773. [Google Scholar]
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv 2016, arXiv:1610.01983. [Google Scholar]
- Richter, S.R.; Hayder, Z.; Koltun, V. Playing for benchmarks. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2232–2241. [Google Scholar]
- NVIDIA. NVIDIA Drive Constellation: Virtual Reality Autonomous Vehicle Simulator. 2017. Available online: https://developer.nvidia.com/drive/drive-constellation (accessed on 26 July 2021).
- Madrigal, A.C. Inside Waymo’s Secret World for Training Self-Driving Cars. 2017. Available online: https://www.theatlantic.com/technology/archive/2017/08/inside-waymos-secret-testing-and-simulation-facilities/537648/ (accessed on 26 July 2021).
- Cognata. Simulating Autonomy Autonomous Robotics Simulation Platform. 2018. Available online: https://www.cognata.com (accessed on 26 July 2021).
- Rootman, S. Cognata Builds Cloud-Based Autonomous Vehicle Simulation Platform with NVIDIA and Microsoft. 2018. Available online: https://www.cognata.com/cognata-builds-cloud-based-autonomous-vehicle-simulation-platform-nvidia-microsoft (accessed on 26 July 2021).
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-fidelity visual and physical simulation for autonomous vehicles. arXiv 2017, arXiv:1705.05065. [Google Scholar]
- LG Electronics. A ROS/ROS2 Multi-Robot Simulator for Autonomous Vehicles. 2019. Available online: https://github.com/lgsvl/simulator (accessed on 26 July 2021).
- NVIDIA. NVIDIA DRIVE Constellation. 2019. Available online: https://developer.nvidia.com/drive/drive-constellation (accessed on 26 July 2021).
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C, 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 26 July 2021).
- Girshick, R. Fast R-CNN. In Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv 2017, arXiv:1704.05519. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 11 August 2021).
- Lin, S.C.; Zhang, Y.; Hsu, C.H.; Skach, M.; Haque, M.E.; Tang, L.; Mars, J. The architectural implications of autonomous driving: Constraints and acceleration. In Proceedings of the 23rd International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Williamsburg, VA, USA, 24–28 March 2018; pp. 751–766. [Google Scholar]
- Kato, S.; Tokunaga, S.; Maruyama, Y.; Maeda, S.; Hirabayashi, M.; Kitsukawa, Y.; Monrroy, A.; Ando, T.; Fujii, Y.; Azumi, T. Autoware on board: Enabling autonomous vehicles with embedded systems. In Proceedings of the 9th ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS), Porto, Portugal, 11–13 April 2018; pp. 287–296. [Google Scholar]
- Alcon, M.; Tabani, H.; Kosmidis, L.; Mezzetti, E.; Abella, J.; Cazorla, F.J. Timing of autonomous driving software: Problem analysis and prospects for future solutions. In Proceedings of the 26th IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Sydney, NSW, Australia, 21–24 April 2020; pp. 267–280. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 22nd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL visual object classes challenge: A retrospective. Int. J. Comput. Vis. (IJCV) 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13rd European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer vision for autonomous vehicles: Problems, datasets and state of the art. arXiv 2017, arXiv:1704.05519. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the KITTI vision benchmark suite. In Proceedings of the 25th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Neuhold, G.; Ollmann, T.; Rota Bulo, S.; Kontschieder, P. The mapillary vistas dataset for semantic understanding of street scenes. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4990–4999. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2636–2645. [Google Scholar]
- Chang, M.F.; Lambert, J.W.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D tracking and forecasting with rich maps. arXiv 2019, arXiv:1911.02620. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. arXiv 2019, arXiv:1903.11027. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. arXiv 2019, arXiv:1912.04838. [Google Scholar]
- Kesten, R.; Usman, M.; Houston, J.; Pandya, T.; Nadhamuni, K.; Ferreira, A.; Yuan, M.; Low, B.; Jain, A.; Ondruska, P.; et al. Lyft Level 5 Perception Dataset 2020. 2019. Available online: https://level5.lyft.com/dataset/ (accessed on 11 August 2021).
- Unity. 2020. Available online: https://unity.com/ (accessed on 11 August 2021).
- Epic Games. Unreal Engine. 2020. Available online: https://www.unrealengine.com (accessed on 11 August 2021).
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 102–118. [Google Scholar]
- Su, H.; Deng, J.; Fei-Fei, L. Crowdsourcing annotations for visual object detection. In Proceedings of the 26th AAAI Conference on Artificial Intelligence (AI), Toronto, ON, Canada, 22–126 July 2012. [Google Scholar]
- OpenCV. Cvat. 2018. Available online: https://github.com/opencv/cvat (accessed on 11 August 2021).
- Microsoft. VoTT. 2018. Available online: https://github.com/microsoft/VoTT (accessed on 11 August 2021).
- Brooks, J. COCO Annotator. 2019. Available online: https://github.com/jsbroks/coco-annotator/ (accessed on 11 August 2021).
- Dutta, A.; Zisserman, A. The VIA annotation software for images, audio and video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2276–2279. [Google Scholar]
- AlexeyAB. GUI for Marking Bounded Boxes of Objects in Images for Training Neural Network Yolo v3 and v2. 2016. Available online: https://github.com/AlexeyAB/Yolo_mark (accessed on 11 August 2021).
- Wada, K. Labelme: Image Polygonal Annotation with Python. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 11 August 2021).
- Castrejon, L.; Kundu, K.; Urtasun, R.; Fidler, S. Annotating object instances with a polygon-rnn. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5230–5238. [Google Scholar]
- Papadopoulos, D.P.; Uijlings, J.R.; Keller, F.; Ferrari, V. Extreme clicking for efficient object annotation. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4930–4939. [Google Scholar]
- Acuna, D.; Ling, H.; Kar, A.; Fidler, S. Efficient interactive annotation of segmentation datasets with polygon-rnn++. In Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 859–868. [Google Scholar]
- Rhinehart, N.; McAllister, R.; Kitani, K.; Levine, S. Precog: Prediction conditioned on goals in visual multi-agent settings. In Proceedings of the 17th IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 2821–2830. [Google Scholar]
- Kaneko, M.; Iwami, K.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation. In Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 258–266. [Google Scholar]
- Ravi Kiran, B.; Roldao, L.; Irastorza, B.; Verastegui, R.; Suss, S.; Yogamani, S.; Talpaert, V.; Lepoutre, A.; Trehard, G. Real-time dynamic object detection for autonomous driving using prior 3D-maps. arXiv 2018, arXiv:1809.11036. [Google Scholar]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to real reinforcement learning for autonomous driving. arXiv 2017, arXiv:1704.03952. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. arXiv 2017, arXiv:1704.02532. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Wang, T.; Yang, L.; Xing, E. Cirl: Controllable imitative reinforcement learning for vision-based self-driving. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 584–599. [Google Scholar]
- Hanhirova, J.; Debner, A.; Hyyppä, M.; Hirvisalo, V. A machine learning environment for evaluating autonomous driving software. arXiv 2020, arXiv:2003.03576. [Google Scholar]
- Karpaphy, A. [CVPR’21 WAD] Keynote—Andrej Karpathy, Tesla. 2021. Available online: https://youtu.be/g6bOwQdCJrc (accessed on 27 August 2021).







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, J.; Lee, H.; Kim, J.-C. CarFree: Hassle-Free Object Detection Dataset Generation Using Carla Autonomous Driving Simulator. Appl. Sci. 2022, 12, 281. https://doi.org/10.3390/app12010281
Jang J, Lee H, Kim J-C. CarFree: Hassle-Free Object Detection Dataset Generation Using Carla Autonomous Driving Simulator. Applied Sciences. 2022; 12(1):281. https://doi.org/10.3390/app12010281
Chicago/Turabian StyleJang, Jaesung, Hyeongyu Lee, and Jong-Chan Kim. 2022. "CarFree: Hassle-Free Object Detection Dataset Generation Using Carla Autonomous Driving Simulator" Applied Sciences 12, no. 1: 281. https://doi.org/10.3390/app12010281