
How Do You Speak about Immigrants? Taxonomy and StereoImmigrants Dataset for Identifying Stereotypes about Immigrants


Abstract
:1. Introduction
- RQ1:
- Is it possible to create a more fine grained taxonomy of stereotypes about immigrants from a social psychology perspective that focuses on frames and not on attributes defining the group?
- RQ2:
- How feasible is to create a stereotype-annotated dataset relying on the new taxonomy?
- RQ3:
- How effective classical machine learning and state-of-the-art transformers models are at distinguishing different categories of stereotypes about immigrants with this taxonomy?
2. Related Work
3. Social Psychology Grounded Taxonomy and StereoImmigrants Dataset
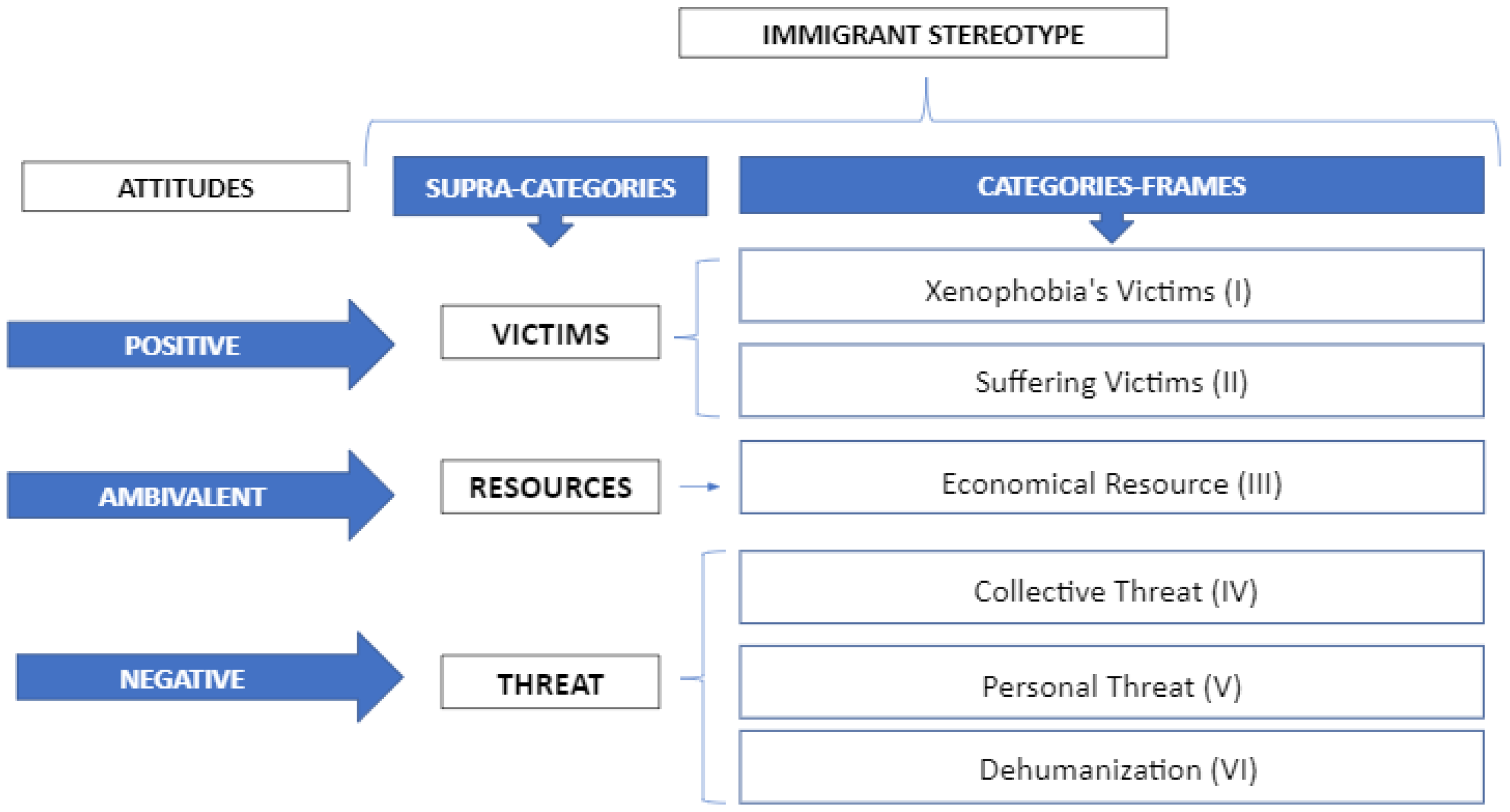
3.1. A Social Psychology Grounded Taxonomy
3.2. Annotation of the StereoImmigrants Dataset
3.3. Evaluation of the Taxonomy
4. Models
- XLM-RoBERTa: It was trained on 2.5 TB of newly created clean CommonCrawl data in 100 languages. It provides strong gains over previously released multilingual models like M-BERT on downstream tasks like classification, sequence labelling, and question answering. In [87], it was reported with better results to the one obtained by fine-tuning with Spanish data only.
- BETO: This is a recent BERT model trained on a big Spanish dataset [87]. It has been compared with multilingual models obtaining better or competitive results [88]. BETO was trained using 12 self-attention layers with 16 attention heads each and 1024 as hidden sizes. It was trained using the data from Wikipedia and all of the sources of the OPUS Project [89]. BETO also was ranked in a better place than Logistic Regression in the prediction of aggressive tweets [90].
- SpanBERTa: SpanBERTa (https://skimai.com/roberta-language-model-for-spanish/), accessed on 8 April 2021, was trained on 18 GB of the OSCAR’s Spanish corpus (https://oscar-corpus.com/), accessed on 8 April 2021, following the RoBERTa’s training schema [91]. It is built on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with much larger mini-batches and learning rates.
5. Experimental Settings
- Experiment I: Stereotype vs. Nonstereotype This experiment is very relevant for us because we have annotated not attributes that speakers assign to a group but narratives about the group that in an implicit way convey a stereotyped vision of the collective. Due to negative examples also being sentences from members of the Parliament speaking about immigration, we want to see if the models detect the subtle difference that consists in approaching the issue without personifying the problem in one group, i.e., immigrants as a social category.
- Experiment II: Victims vs. Threat With this experiment we tried to see if the model can detect which dimension of stereotype about immigrants has been used in the political discourse. One common rhetorical strategy used by politicians that present immigrants as a threat to the majority group is to dedicate a part of their speech to recognise the suffering of the minority. However, these claims of compassion are framed by a discourse that clearly presents immigration as a problem and migrants as a threat. We are interested to see if a model is able to distinguish the deeper meaning of that statement as the human annotators did.
6. Results and Discussion
6.1. Experiment I: Stereotype vs. Nonstereotype
6.2. Experiment II: Victims vs. Threat
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| GSR | Gender Stereotype Reinforcement |
| LR | Logistic Regression |
| M-BERT | Multilingual BERT |
| ML | Machine Learning |
| NB | Naïve Bayes |
| NER | Name Entity Recognition |
| NLI | Natural Language Inference |
| NLP | Natural Language Processing |
| RF | Random Forest |
| SCM | Stereotype Content Model |
| SVM | Support Vector Machine |
Appendix A. Taxonomy: Categories and Frames
Appendix A.1. Category 1: Xenophobia’s Victims
Appendix A.2. Category 2: Suffering Victims
Appendix A.3. Category 3: Economical Resource
Appendix A.4. Category 4: Collective Threat
Appendix A.5. Category 5: Personal Threat
Appendix A.6. Category 6: Dehumanisation
Appendix B. Keywords Used to Filter Immigration-Related Speeches

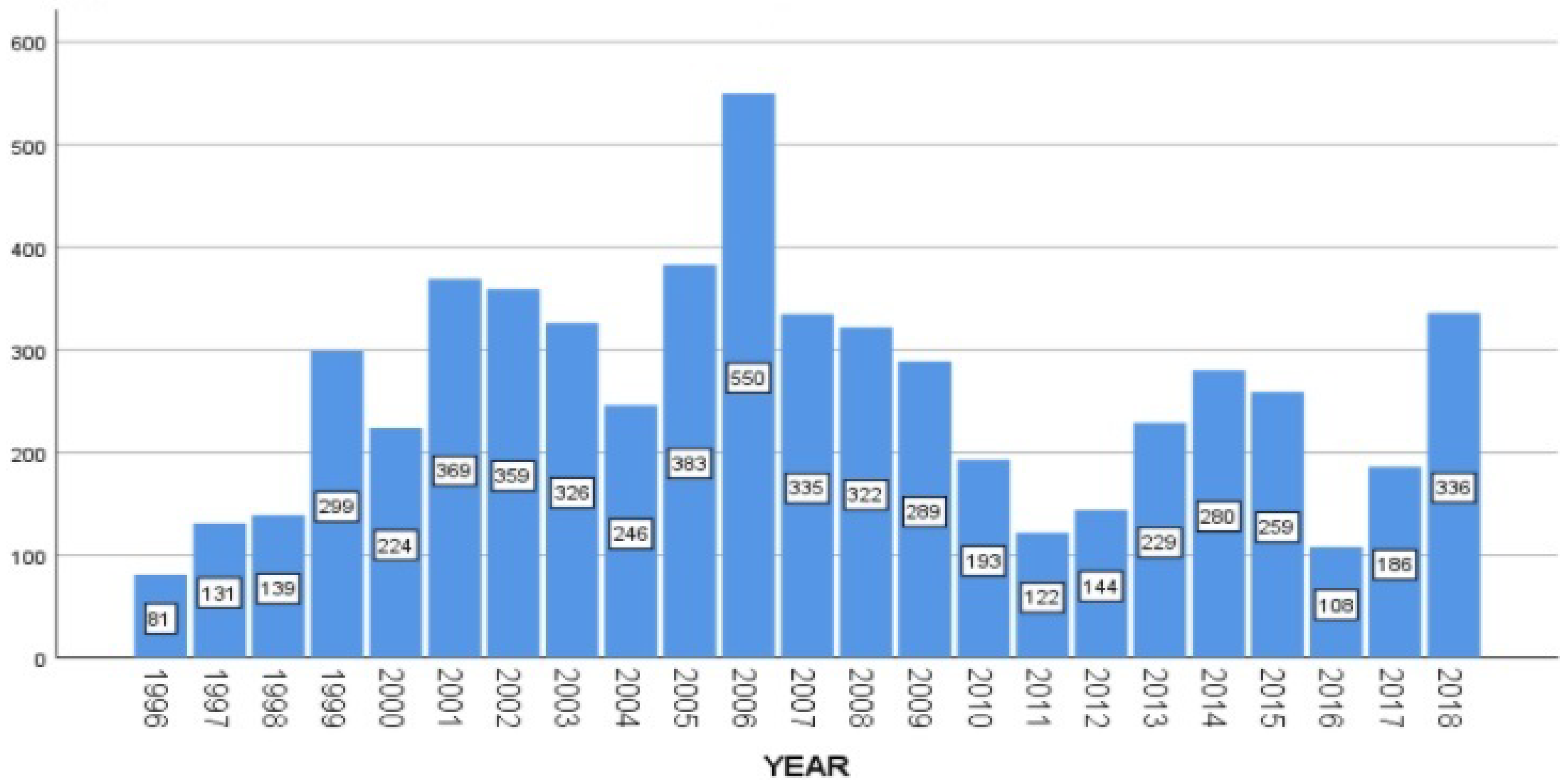{kind=link}
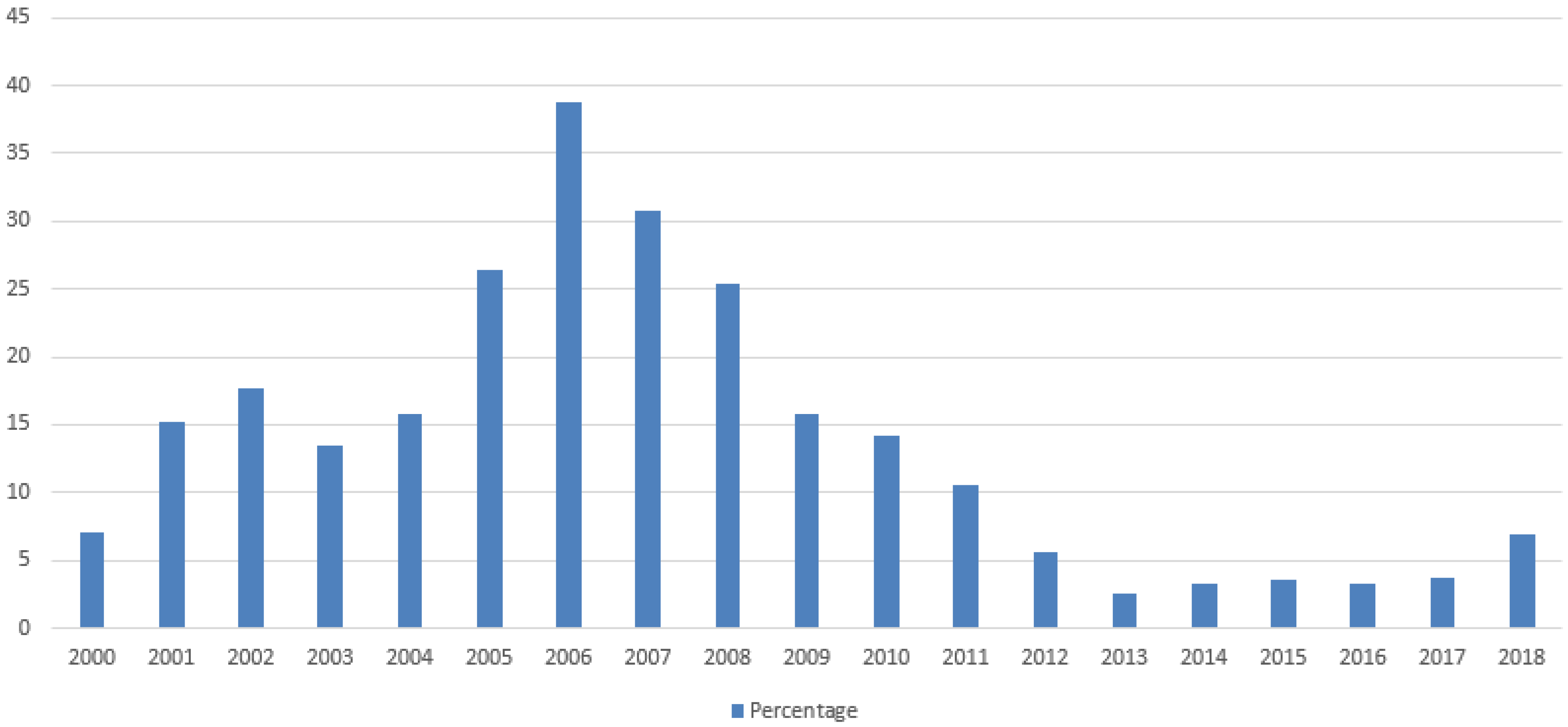{kind=link}
{kind=link}
| anti-inmigrante | deportado | inmigración | pateras |
| anti-inmigrantes | deportados | inmigrante | permisos de residencia |
| asilada | deportar | inmigrantes | polizones |
| asiladas | desheredados de la tierra | islamofobia | racismo |
| asilado | devolución | migrantes | racista |
| asilados | efecto llamada | migratoria | refugiada |
| centro de acogida | efecto salida | migratorias | refugiadas |
| centros de acogida | emigrantes | migratorio | refugiado |
| ciudadanía inmigrada | etnocentrismo | multiculturalismo | refugiados |
| ciudadano emergente | expatriada | nativismo | repatriación |
| ciudadanos emergentes | expatriadas | nuevas ciudadanas | schengen |
| colonialismo | expatriado | nuevos ciudadanos | sociedad de acogida |
| deportación | expatriados | países de recepción | xenófoba |
| deportada | extranjería | países emisores | xenofobia |
| deportadas | indocumentados | países en tránsito | xenófobo |
References
- Brown, R. Prejudice Its Social Psychology; Wiley-Blackwell: New York, NY, USA, 2010. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM Sigkdd Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Sánchez-Junquera, J.; Rosso, P.; Montes-y Gómez, M.; Ponzetto, S.P. Unmasking Bias in News. arXiv 2019, arXiv:1906.04836. [Google Scholar]
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and resolution of rumours in social media: A survey. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Sánchez-Junquera, J.; Villaseñor-Pineda, L.; Montes-y Gómez, M.; Rosso, P.; Stamatatos, E. Masking domain-specific information for cross-domain deception detection. Pattern Recognit. Lett. 2020, 135, 122–130. [Google Scholar] [CrossRef]
- Nadeem, M.; Bethke, A.; Reddy, S. Stereoset: Measuring stereotypical bias in pretrained language models. arXiv 2020, arXiv:2004.09456. [Google Scholar]
- Steele, C.M.; Aronson, J. Stereotype threat and the intellectual test performance of African Americans. J. Personal. Soc. Psychol. 1995, 69, 797–811. [Google Scholar] [CrossRef]
- Desombre, C.; Jury, M.; Bagès, C.; Brasselet, C. The Distinct Effect of Multiple Sources of Stereotype Threat. J. Soc. Psychol. 2018, 159, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Desombre, C.; Jury, M.; Renard, M.; Brasselet, C. Validation factorielle d’une mesure des menaces du stéréotype en langue française. L’Année Psychol. 2020, 120, 251–269. [Google Scholar] [CrossRef]
- Smith, M.B. The Open and Closed Mind. Investigations into the nature of belief systems and personality systems. Science 1960, 132, 142–143. [Google Scholar] [CrossRef]
- Kossowska, M.; Czernatowicz-Kukuczka, A.; Sekerdej, M. Many faces of dogmatism: Prejudice as a way of protecting certainty against value violators among dogmatic believers and atheists. Br. J. Psychol. 2017, 108, 127–147. [Google Scholar] [CrossRef]
- Tajfel, H.; Sheikh, A.A.; Gardner, R.C. Content of stereotypes and the inference of similarity between members of stereotyped groups. Acta Psychol. 1964, 22, 191–201. [Google Scholar] [CrossRef]
- Dovidio, J.F.; Hewstone, M.; Glick, P.; Esses, V.M. Prejudice, stereotyping and discrimination: Theoretical and empirical overview. SAGE Handb. Prejud. Stereotyping Discrim. 2010, 80, 3–28. [Google Scholar]
- Bergsieker, H.B.; Leslie, L.; Constantine, V.S.; Fiske, S. Stereotyping by omission: Eliminate the negative, accentuate the positive. J. Personal. Soc. Psychol. 2012, 102, 1214–1238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Glick, P.; Fiske, S. The Ambivalent Sexism Inventory: Differentiating Hostile and Benevolent Sexism. J. Personal. Soc. Psychol. 1996, 70, 491–512. [Google Scholar] [CrossRef]
- Lipmann, W. Public Opinion; Harcourt Brace: New York, NY, USA, 1922. [Google Scholar]
- Kinder, D. Opinion and action in the realm of politics. In The Handbook of Social Psychology; Gilbert, D.T., Fiske, S., Lindzey, G., Eds.; Wiley: New York, NY, USA, 1998; Volume 2, pp. 778–867. [Google Scholar]
- Scheufele, D.A. Framing as a Theory of Media Effects. J. Commun. 2006, 49, 103–122. [Google Scholar] [CrossRef]
- Pan, Z.; Kosicki, G. Framing Analysis: An Approach to News Discourse. Political Commun. 1993, 10, 55–75. [Google Scholar] [CrossRef]
- Bateson, G. Ecology of Mind. Psychyatric Res. Rep. 1955, 2. [Google Scholar]
- Tversky, A.; Kahneman, D. The framing of decisions and the psychology of choice. Science 1981, 211, 453–458. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goffman, E. Frame Analysis; Harper & Row: New York, NY, USA, 1974. [Google Scholar]
- Gamson, W.; Modigliani, A. The Changing Culture of Affirmative Action. In Research in Political Sociology; Braungart, R., Ed.; JAI Press Inc.: Greenwich, CT, USA, 1987; Volume 3, pp. 137–177. [Google Scholar]
- Lakoff, G. Don’t Think of an Elephant! Know Your Values and Frame the Debate; Chelsea Green Publishing: Vermont, VT, USA, 2004. [Google Scholar]
- Bruner, J. Acts of Meaning; Harvard University Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Baeza-Yates, R. Bias on the web. Commun. ACM 2018, 61, 54–61. [Google Scholar] [CrossRef]
- Potthast, M.; Kiesel, J.; Reinartz, K.; Bevendorff, J.; Stein, B. A stylometric inquiry into hyperpartisan and fake news. arXiv 2017, arXiv:1702.05638. [Google Scholar]
- Bolukbasi, T.; Chang, K.W.; Zou, J.Y.; Saligrama, V.; Kalai, A.T. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Adv. Neural Inf. Process. Syst. 2016, 29, 4349–4357. [Google Scholar]
- Lauscher, A.; Glavaš, G.; Ponzetto, S.P.; Vulić, I. A general framework for implicit and explicit debiasing of distributional word vector spaces. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8131–8138. [Google Scholar]
- Sanguinetti, M.; Poletto, F.; Bosco, C.; Patti, V.; Stranisci, M. An italian twitter corpus of hate speech against immigrants. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Sap, M.; Card, D.; Gabriel, S.; Choi, Y.; Smith, N.A. The Risk of Racial Bias in Hate Speech Detection. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 1668–1678. [Google Scholar]
- Saleem, H.M.; Dillon, K.P.; Benesch, S.; Ruths, D. A web of hate: Tackling hateful speech in online social spaces. arXiv 2017, arXiv:1709.10159. [Google Scholar]
- la Peña Sarracén, G.L.D.; Rosso, P. Aggressive Analysis in Twitter using a Combination of Models. In Proceedings of the Iberian Languages Evaluation Forum Co-Located with 35th Conference of the Spanish Society for Natural Language Processing, IberLEF@SEPLN 2019, Bilbao, Spain, 24 September 2019. [Google Scholar]
- Glavaš, G.; Karan, M.; Vulić, I. XHate-999: Analyzing and Detecting Abusive Language Across Domains and Languages. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6350–6365. [Google Scholar]
- Shekhar, C.; Bagla, B.; Maurya, K.K.; Desarkar, M.S. Walk in Wild: An Ensemble Approach for Hostility Detection in Hindi Posts. arXiv 2021, arXiv:2101.06004. [Google Scholar]
- Manzini, T.; Lim, Y.C.; Black, A.W.; Tsvetkov, Y. Black is to Criminal as Caucasian is to Police: Detecting and Removing Multiclass Bias in Word Embeddings. In Long and Short Papers, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, pp. 615–621. [Google Scholar]
- Anzovino, M.; Fersini, E.; Rosso, P. Automatic Identification and Classification of Misogynistic Language on Twitter. In Natural Language Processing and Information Systems; Silberztein, M., Atigui, F., Kornyshova, E., Métais, E., Meziane, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 57–64. [Google Scholar]
- Kyriakou, K.; Barlas, P.; Kleanthous, S.; Otterbacher, J. Fairness in proprietary image tagging algorithms: A cross-platform audit on people images. In Proceedings of the International AAAI Conference on Web and Social Media, Munich, Germany, 11–14 June 2019; pp. 313–322. [Google Scholar]
- Barlas, P.; Kyriakou, K.; Guest, O.; Kleanthous, S.; Otterbacher, J. To “See” is to Stereotype: Image Tagging Algorithms, Gender Recognition, and the Accuracy-Fairness Trade-off. Proc. ACM Hum. Comput. Interact. 2021, 4, 1–31. [Google Scholar] [CrossRef]
- Beukeboom, C.J.; Forgas, J.; Vincze, O.; Laszlo, J. Mechanisms of linguistic bias: How words reflect and maintain stereotypic expectancies. Soc. Cogn. Commun. 2014, 31, 313–330. [Google Scholar]
- Garg, N.; Schiebinger, L.; Jurafsky, D.; Zou, J. Word embeddings quantify 100 years of gender and ethnic stereotypes. Proc. Natl. Acad. Sci. USA 2018, 115, E3635–E3644. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, P.P.; Li, I.M.; Zheng, E.; Lim, Y.C.; Salakhutdinov, R.; Morency, L.P. Towards debiasing sentence representations. arXiv 2020, arXiv:2007.08100. [Google Scholar]
- Fabris, A.; Purpura, A.; Silvello, G.; Susto, G.A. Gender stereotype reinforcement: Measuring the gender bias conveyed by ranking algorithms. Inf. Process. Manag. 2020, 57, 102377. [Google Scholar] [CrossRef]
- Cryan, J.; Tang, S.; Zhang, X.; Metzger, M.; Zheng, H.; Zhao, B.Y. Detecting Gender Stereotypes: Lexicon vs. Supervised Learning Methods. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–11. [Google Scholar]
- Dev, S.; Li, T.; Phillips, J.M.; Srikumar, V. On Measuring and Mitigating Biased Inferences of Word Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 7659–7666. [Google Scholar]
- Fokkens, A.; Ruigrok, N.; Beukeboom, C.; Sarah, G.; Van Atteveldt, W. Studying muslim stereotyping through microportrait extraction. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Manuela, S.; Gloria, C.; Di Nuovo, E.; Frenda, S.; Stranisci, M.A.; Bosco, C.; Tommaso, C.; Patti, V.; Irene, R. HaSpeeDe 2@ EVALITA2020: Overview of the EVALITA 2020 Hate Speech Detection Task. In Proceedings of the Seventh Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2020), Turin, Italy, 12–13 December 2020; pp. 1–9. [Google Scholar]
- Fiske, S.; Xu, J.; Cuddy, A.; Glick, P. (Dis)respecting versus (Dis)liking: Status and Interdependence Predict Ambivalent Stereotypes of Competence and Warmth. J. Soc. Issues 1999, 55, 473–489. [Google Scholar] [CrossRef]
- Fiske, S.T.; Cuddy, A.J.C.; Glick, P.; Xu, J. A model of (often mixed) stereotype content: Competence and warmth respectively follow from perceived status and competition. J. Personal. Soc. Psychol. 2002, 82, 878–902. [Google Scholar] [CrossRef]
- Fiske, S.T.; Cuddy, A.J.C.; Glick, P. Universal dimensions of social perception: Warmth and competence. Trends Cogn. Sci. 2007, 11, 77–83. [Google Scholar] [CrossRef]
- Cuddy, A.; Fiske, S.; Glick, P. The BIAS Map: Behaviors from Intergroup Affect and Stereotypes. J. Personal. Soc. Psychol. 2007, 92, 631–648. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fiske, S.T. Stereotype content: Warmth and Competence Endure. Curr. Dir. Psychol. Sci. 2018, 27, 67–73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, T.L.; Fiske, S.T. Not an outgroup, not yet an ingroup: Immigrants in the Stereotype Content Model. Int. J. Intercult. Relations 2006, 30, 751–768. [Google Scholar] [CrossRef]
- Kervyn, N.; Fiske, S.; Yzerbyt, V. Forecasting the primary dimension of social perception: Symbolic and realistic threats together predict warmth in the Stereotype Content Model. Soc. Psychol. 2015, 46, 36–45. [Google Scholar] [CrossRef] [PubMed]
- University of Oklahoma; Institute of Group Relations; Sherif, M. Intergroup Conflict and Cooperation: The Robbers Cave Experiment; University Book Exchange: Norman, OK, USA, 1961; Volume 10. [Google Scholar]
- Zanna, M. On the nature of prejudice. Can. Psychol. 1994, 35, 11–23. [Google Scholar] [CrossRef]
- Stephan, W.G.; Diaz-Loving, R.; Duran, A. Integrated Threat Theory and Intercultural Attitudes: Mexico and the United States. J. Cross Cult. Psychol. 2000, 31, 240–249. [Google Scholar] [CrossRef]
- McConahay, J.B.; Hough, J.C. Symbolic Racism. J. Soc. Issues 1976, 32, 23–45. [Google Scholar] [CrossRef]
- Kinder, D.R.; Sears, D.O. Prejudice and politics: Symbolic racism versus racial threats to the good life. J. Personal. Soc. Psychol. 1981, 40, 414–431. [Google Scholar] [CrossRef]
- Moscovici, S. The coming era of representations. In Cognitive Analysis of Social Behaviour; Codol, J., Leyens, J., Eds.; Nijhoff: The Hague, The Netherlands, 1982. [Google Scholar]
- Moscovici, S. The phenomenon of social representation. In Social Representations; Farr, R., Moscovici, S., Eds.; Cambridge University Press: Cambridge, NY, USA, 1984; pp. 3–69. [Google Scholar]
- Breakwell, G.; Canter, D. Empirical Approaches to Social Representations; Oxford Science Publications; Clarendom Press: Oxford, UK, 1993. [Google Scholar]
- Moscovici, S. Essai Sur l’histoire Humaine de la Nature; Flammarion: Paris, France, 1968. [Google Scholar]
- Pérez, J.; Moscovici, S.; Chulvi, B. Nature and culture as principles for social classification. Anchorage of social representations on ethnical minorities. Int. J. Soc. Psychol. 2002, 17, 51–67. [Google Scholar] [CrossRef]
- Perez, J.; Moscovici, S.; Chulvi, B. The taboo against group contact: Hypothesis of Gypsy ontologization. Br. J. Soc. Psychol. 2007, 46, 249–272. [Google Scholar] [CrossRef] [PubMed]
- Haslam, N.; Loughnan, S.; Reynolds, C.; Wilson, S. Dehumanization: A New Perspective. Soc. Personal. Psychol. Compass 2007, 1, 409–422. [Google Scholar] [CrossRef]
- Leyens, J.P.; Paladino, P.M.; Rodriguez-Torres, R.; Vaes, J.; Demoulin, S.; Rodriguez-Perez, A.; Gaunt, R. The emotional side of prejudice: The attribution of secondary emotions to ingroups and outgroups. Personal. Soc. Psychol. Rev. 2000, 4, 186–197. [Google Scholar] [CrossRef]
- Moscovici, S.; Pérez, J. A study of minorities as victims. Eur. J. Soc. Psychol. 2007, 37, 725–746. [Google Scholar] [CrossRef]
- Moscovici, S.; Pérez, J.A. A new representation of minorities as victims. In Coping with Minority Status: Responses to Exclusion and Inclusion; Butera, F., Levine, J.M., Eds.; Cambridge University Press: Cambridge, NY, USA, 2009; pp. 82–103. [Google Scholar]
- Barkan, E. The Guilt of Nations: Restitution and Negotiating Historical Injustices; Norton: New York, NY, USA, 2000. [Google Scholar]
- Sironi, A.; Bauloz, C.; Emmanuel, M. Glossary on Migration; International Organization for Migration (IOM): Geneva, Switzerland, 2019. [Google Scholar]
- Steele, S. The Content of our Character; St. Martin’s Press: New York, NY, USA, 1990. [Google Scholar]
- Gamson, W. Talking Politics; Cambridge University Press: New York, NY, USA, 1992. [Google Scholar]
- Sap, M.; Gabriel, S.; Qin, L.; Jurafsky, D.; Smith, N.A.; Choi, Y. Social Bias Frames: Reasoning about Social and Power Implications of Language. arXiv 2020, arXiv:1911.03891. [Google Scholar]
- Eagly, A.H.; Chaiken, S. The Psychology of Attitudes; Harcourt Brace Jovanovich College Publishers: Brussels, Belgium, 1993. [Google Scholar]
- Kaplan, K.J. On the ambivalence-indifference problem in attitude theory and measurement: A suggested modification of the semantic differential technique. Psychol. Bull. 1972, 77, 361–372. [Google Scholar] [CrossRef]
- Rauh, C.; Schwalbach, J. The ParlSpeech V2 data set: Full-text corpora of 6.3 million parliamentary speeches in the key legislative chambers of nine representative democracies. Harv. Dataverse 2020. [Google Scholar] [CrossRef]
- Rudkowsky, E.; Haselmayer, M.; Wastian, M.; Jenny, M.; Emrich, Š.; Sedlmair, M. More than bags of words: Sentiment analysis with word embeddings. Commun. Methods Meas. 2018, 12, 140–157. [Google Scholar] [CrossRef] [Green Version]
- Proksch, S.O.; Lowe, W.; Wäckerle, J.; Soroka, S. Multilingual sentiment analysis: A new approach to measuring conflict in legislative speeches. Legis. Stud. Q. 2019, 44, 97–131. [Google Scholar] [CrossRef] [Green Version]
- Reher, D.S.; Cortés, L.; González, F.; Requena, M.; Sánchez, M.I.; Sanz, A.; Stanek, M. Informe Encuesta Nacional de Inmigrantes (ENI—2007); Instituto Nacional de Estadística: Buenos Aires, Argentina, 2008. [Google Scholar]
- CES. La Inmigración y el Mercado de Trabajo en España; Colección Informes; Consejo Económico y Social: Madrid, Spain, 2004. [Google Scholar]
- Izquierdo Escribano, A. Inmigración: Mercado de Trabajo y Protección Social en España; Consejo Económico y Social: Madrid, Spain, 2003. [Google Scholar]
- Sharpe, D. Chi-Square Test is Statistically Significant: Now What? Pract. Assess. Res. Eval. 2015, 20. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, Z.; Mayhew, S.; Roth, D. Cross-lingual ability of multilingual bert: An empirical study. arXiv 2019, arXiv:1912.07840. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How multilingual is multilingual bert? arXiv 2019, arXiv:1906.01502. [Google Scholar]
- Cañete, J.; Chaperon, G.; Fuentes, R.; Ho, J.H.; Kang, H.; Pérez, J. Spanish Pre-Trained BERT Model and Evaluation Data. In Proceedings of the ICLR 2020, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Úbeda, P.L.; Díaz-Galiano, M.C.; Lopez, L.A.U.; Martín-Valdivia, M.T.; Martín-Noguerol, T.; Luna, A. Transfer learning applied to text classification in Spanish radiological reports. In Proceedings of the LREC 2020 Workshop on Multilingual Biomedical Text Processing (MultiligualBIO 2020), Marseille, France, 16 May 2020; pp. 29–32. [Google Scholar]
- Tiedemann, J. Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC), Istanbul, Turkey, 23–25 May 2012; pp. 2214–2218. [Google Scholar]
- Casavantes, M.; López, R.; González, L. UACh at MEX-A3T 2020: Detecting Aggressive Tweets by Incorporating Author and Message Context. In Proceedings of the 2nd SEPLN Workshop on Iberian Languages Evaluation Forum (IberLEF), Malaga, Spain, 23 September 2020. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Menger, V.; Scheepers, F.; Spruit, M. Comparing Deep Learning and Classical Machine Learning Approaches for Predicting Inpatient Violence Incidents from Clinical Text. Appl. Sci. 2018, 8, 981. [Google Scholar] [CrossRef] [Green Version]
- Jones, E.E.; Davis, K.E. From acts to dispositions: The attribution process in social perception. In Advances in Experimental Social Psychology; Academic Press: New York, NY, USA, 1965; Volume 2, pp. 219–266. [Google Scholar]
- Jones, E.E.; Harris, V.A. The attribution of attitudes. J. Exp. Soc. Psychol. 1967, 3, 1–24. [Google Scholar] [CrossRef]
- Jones, E.E. The rocky road from acts to dispositions. Am. Psychol. 1979, 34, 107–117. [Google Scholar] [CrossRef]
- Watzlawick, P.; Beavin, J.; Jackson, D. Pragmatics of Human Communication: A Study of Interactional Patterns, Pathologies, and Paradoxes; W. W. Norton & Company Incorporated: New York, NY, USA, 1967. [Google Scholar]



| Length in Tokens | |||||
|---|---|---|---|---|---|
| Instances | Min | Mean ± Standard Deviation | Max | ||
| Stereotype | 1. Xenophobia’s Victims | 186 | 6 | 50.55 ± 30.59 | 183 |
| 2. Suffering Victims | 557 | 7 | 47.32 ± 24.41 | 151 | |
| 3. Economical Resources | 194 | 9 | 42.39 ± 22.31 | 128 | |
| 4. Collective threat | 655 | 8 | 43.42 ± 23.28 | 162 | |
| 5. Personal threat | 81 | 9 | 48.26 ± 25.56 | 149 | |
| All dimensions joined | 1673 | 6 | 45.62 ± 24.69 | 183 | |
| Nonstereotype | 1962 | 3 | 36.00 ± 21.17 | 165 | |
| Total | 3635 | 3 | 40.43 ± 23.35 | 183 | |
| Attitudes towards Immigrants | |||||
|---|---|---|---|---|---|
| Taxonomy Categories | Pro-Immigrant | Anti-Immigrant | Neutral | Total | |
| Xenophobia’s Victims | Obs | 916 | 90 | 143 | 1149 |
| Adj. Res | 25.4 | −23.6 | −3.0 | ||
| Suffering Victims | Obs | 2002 | 414 | 363 | 2779 |
| Adj. Res | 34.8 | −32.3 | −4.2 | ||
| Economical resource | Obs | 482 | 187 | 259 | 928 |
| Adj. Res | 4.4 | −12.7 | 11.1 | ||
| Collective threat | Obs | 339 | 2406 | 508 | 3253 |
| Adj. Res | −50.5 | 51.2 | 0.3 | ||
| Personal threat | Obs | 108 | 268 | 45 | 421 |
| Adj. Res | −8.2 | 10.4 | −2.8 | ||
| Total (Obs) | 3847 | 3365 | 1318 | 8530 | |
| BETO | SpanBERTa | M-BERT | XLM-RoBERTa |
|---|---|---|---|
| 0.861 ± 0.016 | 0.766 * ± 0.021 | 0.829 * ± 0.022 | 0.780 ± 0.105 |
| LR | SVM | NB | RF |
| 0.82 | 0.81 | 0.73 | 0.81 |
| N-Grams with Highest Mutual Information | |
|---|---|
| Nonstereotype | inmigrantes irregulares; señor rajoy; señor zapatero; países africanos; abordar asunto; abordar problema; absolutamente acuerdo; acción exterior; acción política; acoger personas; acogida refugiados; acogida temporal; acorde derechos; acuerdo materia; acuerdos gobierno; acuerdos marruecos; acuerdos mauritania; acuerdos readmisión; adquisición nacionalidad; afecta unión europea; agencia europea fronteras; aguas canarias; aguas territoriales; asilo inmigración; asunto preocupa; atención inmigración; autoridad moral; ayuda refugiado; ayuda áfrica;... |
| Stereotype | efecto llamada; inmigrantes ilegales; política inmigración; inmigración irregular; unión europea; materia inmigración; derechos humanos; inmigrantes irregulares; consejo europeo; inmigración ilegal; drama humano; regularización masiva; islas canarias; seres humanos; política común; proceso regularización; inmigración delincuencia; llegada masiva; respeto derechos; situación irregular; economía sumergida; mujeres inmigrantes; centros acogida; orden expulsión; centros internamiento; costas canarias; miles personas; europea inmigración; política migratoria; política exterior; respeto derechos humanos; menores acompañados; acogida canarias; drama humanitario; empresarios sindicatos; menores inmigrantes; crecimiento económico; acogida inmigrantes;... |
| Predicted Labels | ||
|---|---|---|
| Stereotype | Nonstereotype | |
| Stereotype | 1451 | 222 |
| Nonstereotype | 240 | 1433 |
| Classified Examples with the Right Label |
|---|
| 1. Nos gustaría que lo acompañara de política migratoria real también. (Nonstereotype) |
| (We would like that actual immigration policy was considered as well.) |
| 2. Señorías, la política de integración es la gran asignatura pendiente. (Nonstereotype) |
| (Ladies and gentlemen, integration policy is the great pending issue.) |
| 3. Es decir, se tiene que cambiar la política de inmigración del Gobierno. (Nonstereotype) |
| (In other words, the government’s immigration policy has to be changed.) |
| 4. El secretario de empleo dijo: España seguirá necesitando inmigrantes. (S: Economical Resource) |
| (The employment secretary said: Spain will continue needing immigrants.) |
| 5. En lo que va de año han llegado a Canarias más de 3500 personas en pateras. (S: Threat) |
| (So far this year, more than 3500 people have arrived in the Canary Islands in boats.) |
| 6. El problema, señora vicepresidenta, está en que en el cuerno de África mueren todas las semanas 40,000 niños por falta de nutrición. |
| (S: Victims) (The problem, Vice President, is that 40,000 children die every week in the Horn of Africa due to lack of nutrition.) |
| Misclassified Examples |
| 1. Entendemos que España puede jugar un papel destacado en cuanto a este problema, pero Europa será más creíble si afronta problemas |
| reales quelos ciudadanos perciban. (Nonstereotype) |
| (We understand that Spain can play a leading role in this problem, but Europe will be more credible if it faces real problems |
| that citizens perceive.) |
| 2. Evidentemente nos encontramos ante una situación compleja, la relativa a las remesas en un momento en el que la política migratoria |
| ha adquiridouna gran dimensión. (Nonstereotype) |
| (Obviously we face with a complex situation, relating to remittances at a time when migration policy has acquired a |
| great dimension.) |
| 3. Desde que aprobamos en 1985 la Ley de extranjería, de los derechos y obligaciones de los extranjeros en España, ha mantenido una línea |
| congruente. (Nonstereotype) |
| (Since we approved in 1985 the Law on foreigners, on the rights and obligations of foreigners in Spain, it has maintained a |
| congruent line.) |
| 4. El asunto de la inmigración requiere medidas de control pero fundamentalmente -y lo apuntaba usted ayer- medidas de solidaridad y este |
| y este es un reto europeo. (S: Victims) |
| (The issue of immigration requires control measures but fundamentally—and you pointed this out yesterday—solidarity measures |
| and this is a European challenge.) |
| 5. Decían que lo que pasaba en España era un coladero para los distintos países de la Unión Europea y a ustedes no les importó lo más mínimo. |
| En aquella época el ministro. (S: Threat) |
| (They said that what was happening in Spain was a drain for the different countries of the European Union and you did not |
| care at all. At that time the minister) |
| 6. Por tanto, se abre un camino esperanzador, y yo solamente les deseo éxitos por el bien del conjunto de los trabajadores inmigrantes, |
| por el bien de la |
| política en el Estado. (S: Economical Resource) |
| (Therefore, a hopeful path opens, and I only wish you success for the good of all immigrant workers, for the good of |
| politics in the State) |
| BETO | SpanBERTa | M-BERT | XLM-RoBERTa |
|---|---|---|---|
| 0.834 ± 0.034 | 0.704 * ± 0.064 | 0.809 ± 0.022 | 0.785 ± 0.070 |
| LR | SVM | NB | RF |
| 0.79 | 0.78 | 0.72 | 0.77 |
| N-Grams with More Mutual Information | |
|---|---|
| Victims | ley extranjería; ceuta melilla; guardia civil; política inmigración; presión migratoria; partido popular; acoger personas; acogida canarias; acogida inmigrantes; acogida integración; acogida personas; acogida temporal; acuerdos bilaterales; administración justicia; aeropuertos fronteras; fronteras terrestres; aflorar irregulares; afrontar problema; aguas canarias; aguas territoriales; amnistía internacional; apoyo; aquellas personas; aquellos inmigrantes; aquellos países; archipiélago canario; asuntos sociales; atención humanitaria; atención sanitaria;... |
| Threat | inmigración irregular; derechos humanos; regularización masiva; inmigración ilegal; inmigrantes ilegales; proceso regularización; efecto llamada; inmigrantes irregulares; señor caldera; asilo refugio; mujeres inmigrantes; inmigración delincuencia; personas muerto; control inmigración; derecho asilo refugio; mauritania senegal; canaria nueva; derecho asilo; inmigración problema; trafican seres humanos; principal problema; inmigración clandestina;... |
| Predicted Labels | ||
|---|---|---|
| Victim | Threat | |
| Victim | 611 | 125 |
| Threat | 119 | 617 |
| Classified examples with the right label |
|---|
| 1. ¿Por qué ha muerto una persona joven? (Victims) |
| (Why did a young person die?) |
| 2. Derechos de ciudadanía para los inmigrantes. (Victims) |
| (Citizenship rights for immigrants.) |
| 3. Esta no es la forma de enfrentarse con un problema que requiere, sobre todo, grandes dosis de solidaridad. (Victims) |
| (This is not the way to deal with a problem that requires, above all, large doses of solidarity.) |
| 4. Hay en España más ciudadanos irregulares que nunca. (Threat) |
| (There are more irregular citizens in Spain than ever.) |
| 5. España hoy está desbordada con la inmigración ilegal. (Threat) |
| (Spain today is overwhelmed with illegal immigration.) |
| 6. Hay más llegadas de inmigrantes irregulares que nunca. (Threat) |
| (There are more arrivals of irregular immigrants than ever.) |
| Misclassified examples |
| 1. Por cierto, el Gobierno debería explicarnos cuántos inmigrantes se fugaron este fin de semana del centro de Las Raíces, si fueron veinte, |
| como dice |
| el delegado del Gobierno, o si fueron cien, como afirman fuentes policiales. (Threat) |
| (By the way, the Government should explain to us how many immigrants escaped this weekend from the center of Las Raices, |
| if there were twenty, as the Government delegate says, or if there were a hundred, as stated by police sources.) |
| 2. No queremos olvidar la operación Melilla, la expulsión de los 103 ciudadanos. (Victims) |
| (We do not want to forget the Melilla operation, the expulsion of the 103 citizens.) |
| 3. Por tanto, apostamos por una política de retorno, de repatriación humanitaria. (Threat) |
| (Therefore, we are committed to a policy of return, of humanitarian repatriation.) |
| 4. Esto es un escándalo, esto son más trabas a los migrantes cuando ya se encuentran dentro. (Victims) |
| (This is a scandal, these are more obstacles to migrants when they are already inside.) |
| 5. Ya son 25,000 los inmigrantes llegados a Canarias en lo que va de año y se cuentan por miles los que han dejado su vida en el intento. (Threat) |
| (There are already 25,000 immigrants who have arrived in the Canary Islands so far this year and there are thousands who have |
| lost their lives in the attempt.) |
| 6. ¿Por qué en tres meses no han tomado ninguna de las medidas propuestas para evitar las avalanchas que han generado tanto sufrimiento? |
| (Threat) |
| (Why in three months have they not taken any of the measures proposed to avoid the avalanches that have generated |
| so much suffering?) |
| Annotators Say Victims but BETO Predicts Threat | Annotators Say Threat but BETO Predicts Victims | Annotators and BETO Agreement | Total | |||
|---|---|---|---|---|---|---|
| Parties | Coalición Canaria | Obs. | 14 | 10 | 127 | 151 |
| Adj. Res. | 0.4 | −0.7 | 0.2 | |||
| IU | Obs. | 22 | 2 | 130 | 154 | |
| Adj. Res. | 2.7 | −3.3 | 0.3 | |||
| PP | Obs. | 11 | 40 | 330 | 381 | |
| Adj. Res. | −4.6 | 2.0 | 1.9 | |||
| PSOE | Obs. | 42 | 29 | 324 | 395 | |
| Adj. Res. | 1.8 | −0.6 | −0.9 | |||
| Other Parties | Obs. | 36 | 38 | 317 | 391 | |
| Adj. Res. | 0.6 | 1.4 | −1.5 | |||
| Total (Obs.) | 125 | 119 | 1228 | 1472 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez-Junquera, J.; Chulvi, B.; Rosso, P.; Ponzetto, S.P. How Do You Speak about Immigrants? Taxonomy and StereoImmigrants Dataset for Identifying Stereotypes about Immigrants. Appl. Sci. 2021, 11, 3610. https://doi.org/10.3390/app11083610
Sánchez-Junquera J, Chulvi B, Rosso P, Ponzetto SP. How Do You Speak about Immigrants? Taxonomy and StereoImmigrants Dataset for Identifying Stereotypes about Immigrants. Applied Sciences. 2021; 11(8):3610. https://doi.org/10.3390/app11083610
Chicago/Turabian StyleSánchez-Junquera, Javier, Berta Chulvi, Paolo Rosso, and Simone Paolo Ponzetto. 2021. "How Do You Speak about Immigrants? Taxonomy and StereoImmigrants Dataset for Identifying Stereotypes about Immigrants" Applied Sciences 11, no. 8: 3610. https://doi.org/10.3390/app11083610