
AraSenCorpus: A Semi-Supervised Approach for Sentiment Annotation of a Large Arabic Text Corpus



Abstract
:1. Introduction
2. Related Work
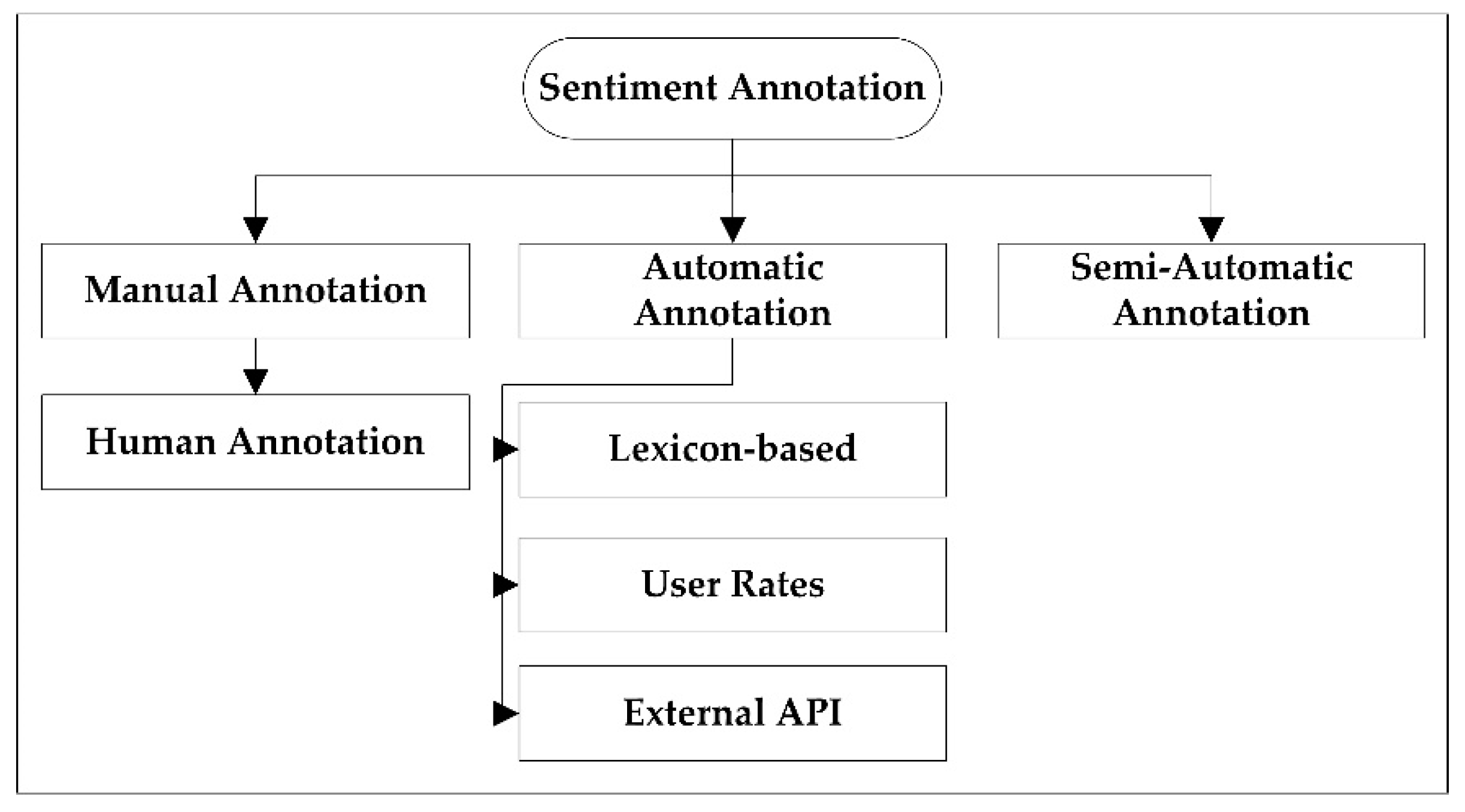
2.1. Sentiment Annotation
2.2. Sentiment Classification
3. Methodology
3.1. Data Collection Process
3.1.1. Challenges in Data Collection from Twitter
3.1.2. Challenges in Using Twitter as a Data Source
- Ethical issues: Reproducing tweets in an academic publication has to be handled with care, especially concerning tweets related to sensitive topics. In our research, our topic targets sentiment analysis for Arabic text where the extracted tweets are not sensitive.
- Legal issues: Under Twitter’s API Terms of Service, it is prohibited to share Twitter datasets. Our corpus will be available for the research community by sharing the IDs of tweets only, which can be used by other researchers to obtain the tweets, along with their sentiment labels.
- Retrieving datasets: Using certain keywords may not retrieve all of the tweets related to a topic. In our research, it is also a challenge to build a sentiment corpus by searching for a limited number of keywords in Arabic, while there are many Arabic dialects as well. We overcome this problem by collecting sentiment terms/phrases from multiple Arabic sentiment lexicons in modern standard Arabic and Arabic dialects.
- Cost: Twitter data cost a lot of money when they are obtained from a licensed reseller of Twitter data. It is also difficult to obtain Twitter data using the free API. However, our developed system can obtain a large amount of data.
- Spam: There are large numbers of tweets on Twitter that can attract a large amount of spam. In our research, we found a lot of tweets that contained sexual expressions that had to be excluded from the sentiment corpus.
3.1.3. Data Collection Methodology
3.1.4. Representative Consideration
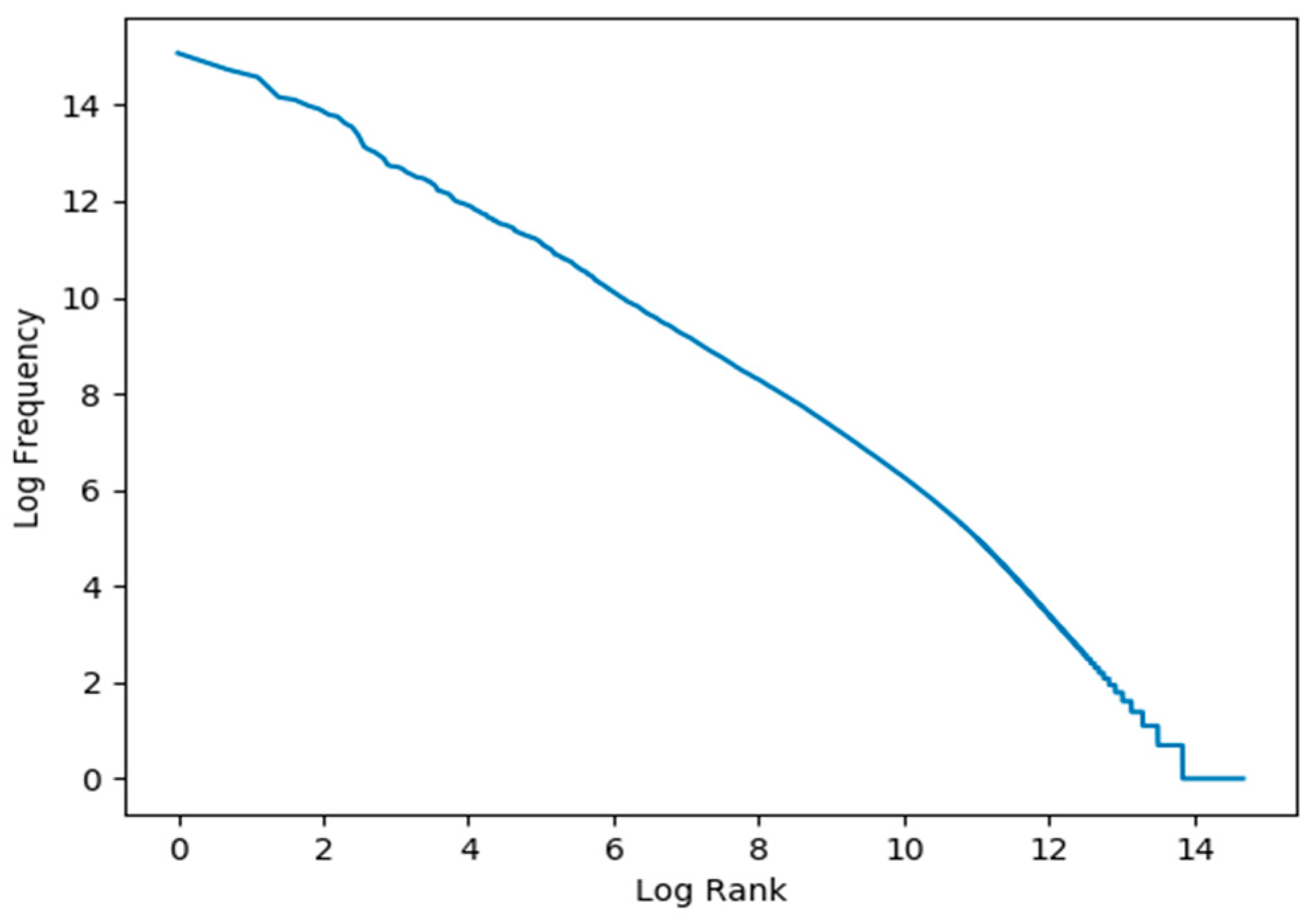
3.1.5. Corpus Cleaning and Preprocessing
3.1.6. Corpus Characteristics and Potential Applications
3.2. Corpus Framework
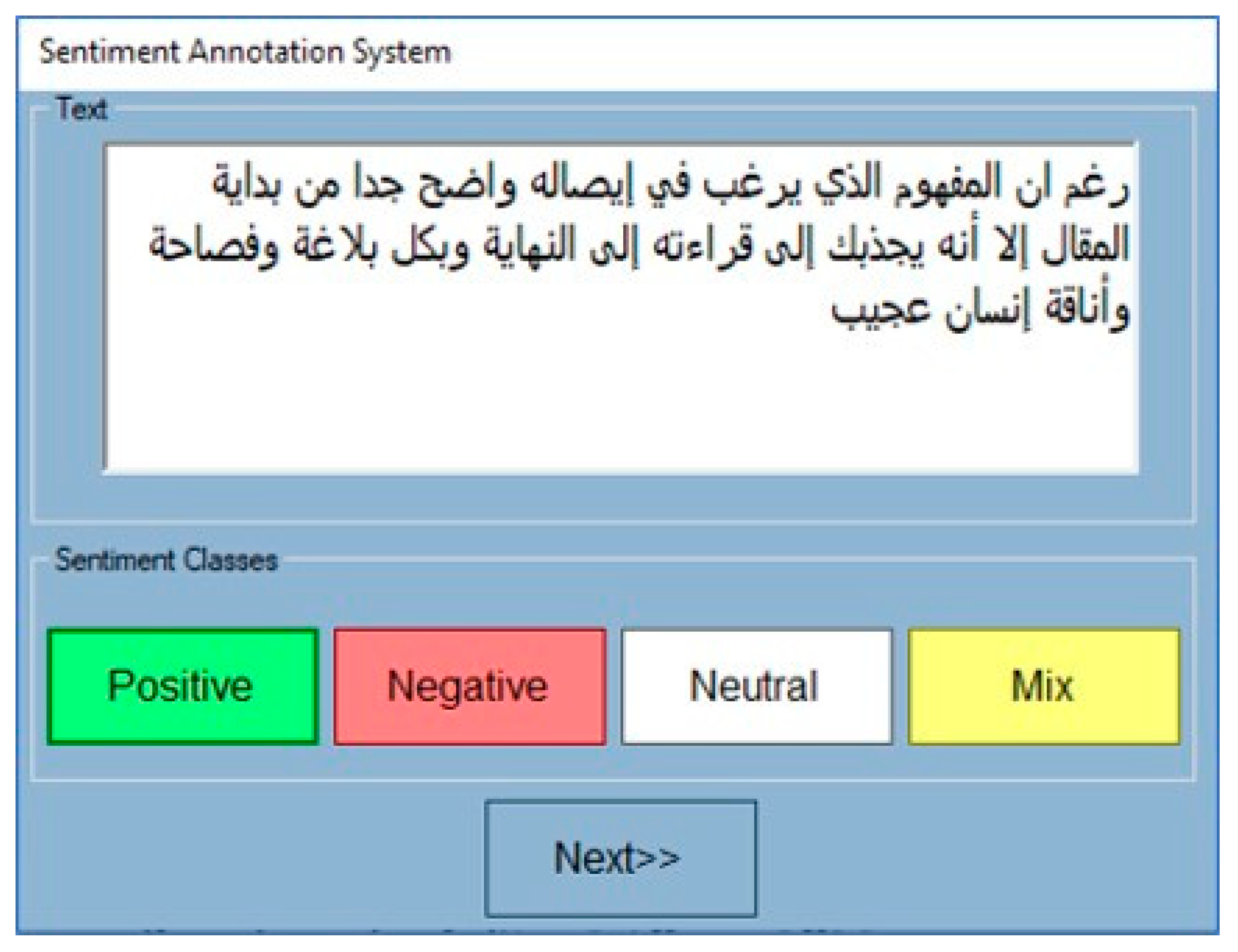
3.2.1. Manually Annotated Dataset
- What to annotate: Tweets that bear a positive or negative sentiment and tweets that do not bear any positivity or negativity (neutral tweets).
- What not to annotate: tweets containing both positive and negative sentiments.
- How to handle special cases such as negations, sarcasm, or quotations.
- Tweets bearing positive terms/phrases: for instance, “رائع” (wonderful) and “بسيطة ومفيدة” (simple and useful).
- Tweets bearing negative terms/phrases: for instance, “سيئ” and “تجربة مريرة” (difficult experience).
- Positive or negative situations or events, for example, “تسبب فيروس كورونا بخسائر فادحة لمعظم دول العالم” (corona virus caused heavy losses to most of the world countries). This tweet will be marked as negative since it has two negative terms “خسائر” (losses) and “فادحة” (fatal).
- All objective tweets that do not contain any sentiment terms/phrases will be considered neutral and marked as “neutral”.
- Tweets containing both positive and negative terms/phrases with the same intensity of positive and negative terms/phrases will be marked as “mixed” and will not be considered in this research.
- Tweets containing negations before positive or negative terms/phrases will flip the polarity of sentiment, for example “غيرمريحة” (uncomfortable) is a phrase with negation and a positive term. Tweets containing such phrases should be marked as negative tweets.
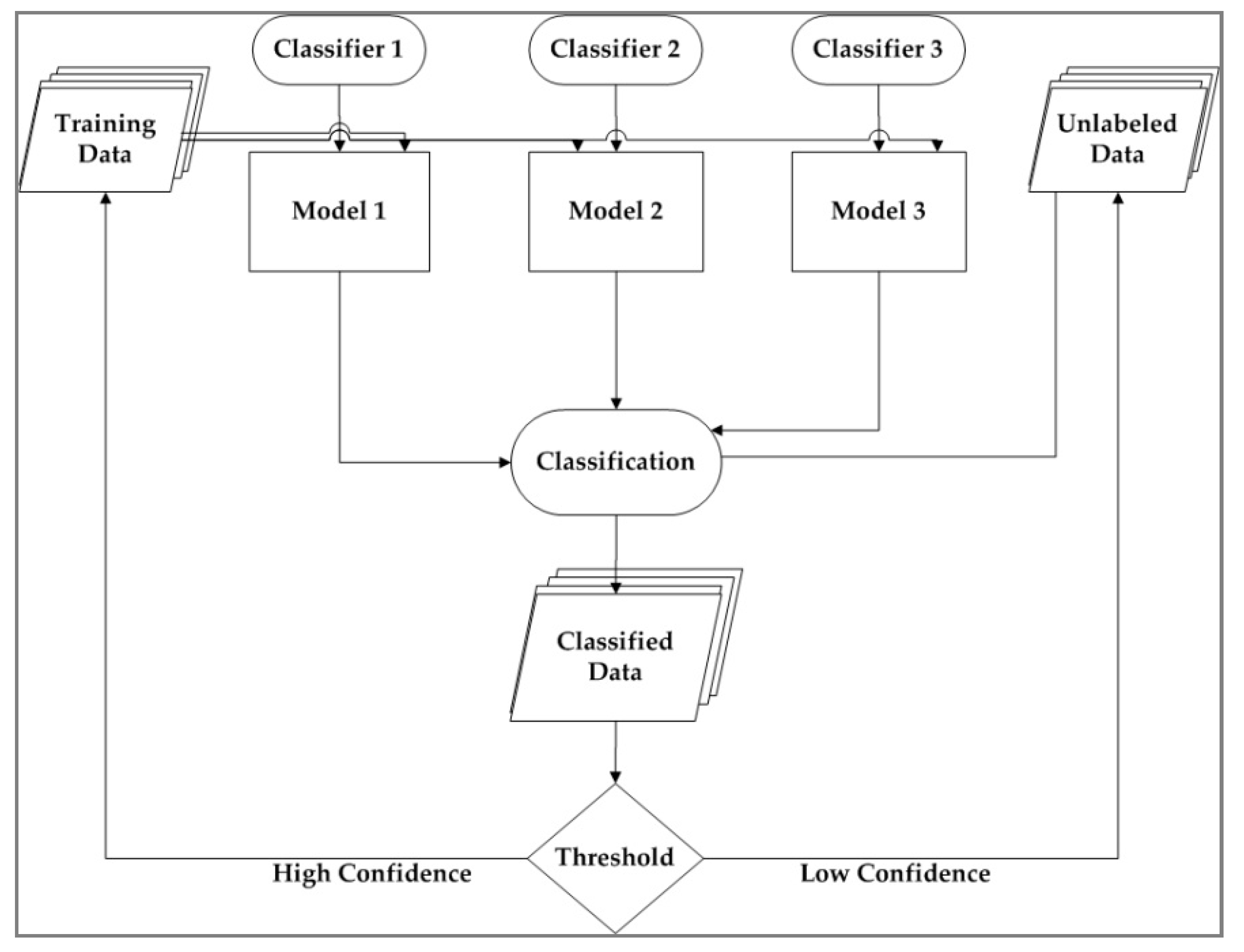
3.2.2. Semi-Supervised Annotated Corpus
- Classifier#1: Learning rate (LR) = 0.5, epoch = 10, wordNgrams = 1, and dimension = 100.
- Classifier#2: Learning rate (LR) = 0.5, epoch = 10, wordNgrams = 2, and dimension = 100.
- Classifier#3: Learning rate (LR) = 0.5, epoch = 10, wordNgrams = 3, and dimension = 100.
| Algorithm 1: Semi-Supervised (Self-Learning) Annotation Algorithm. |
 |
3.3. Sentiment Classification
3.3.1. Dataset
3.3.2. Experimental Setup
3.3.3. Evaluation Metrics
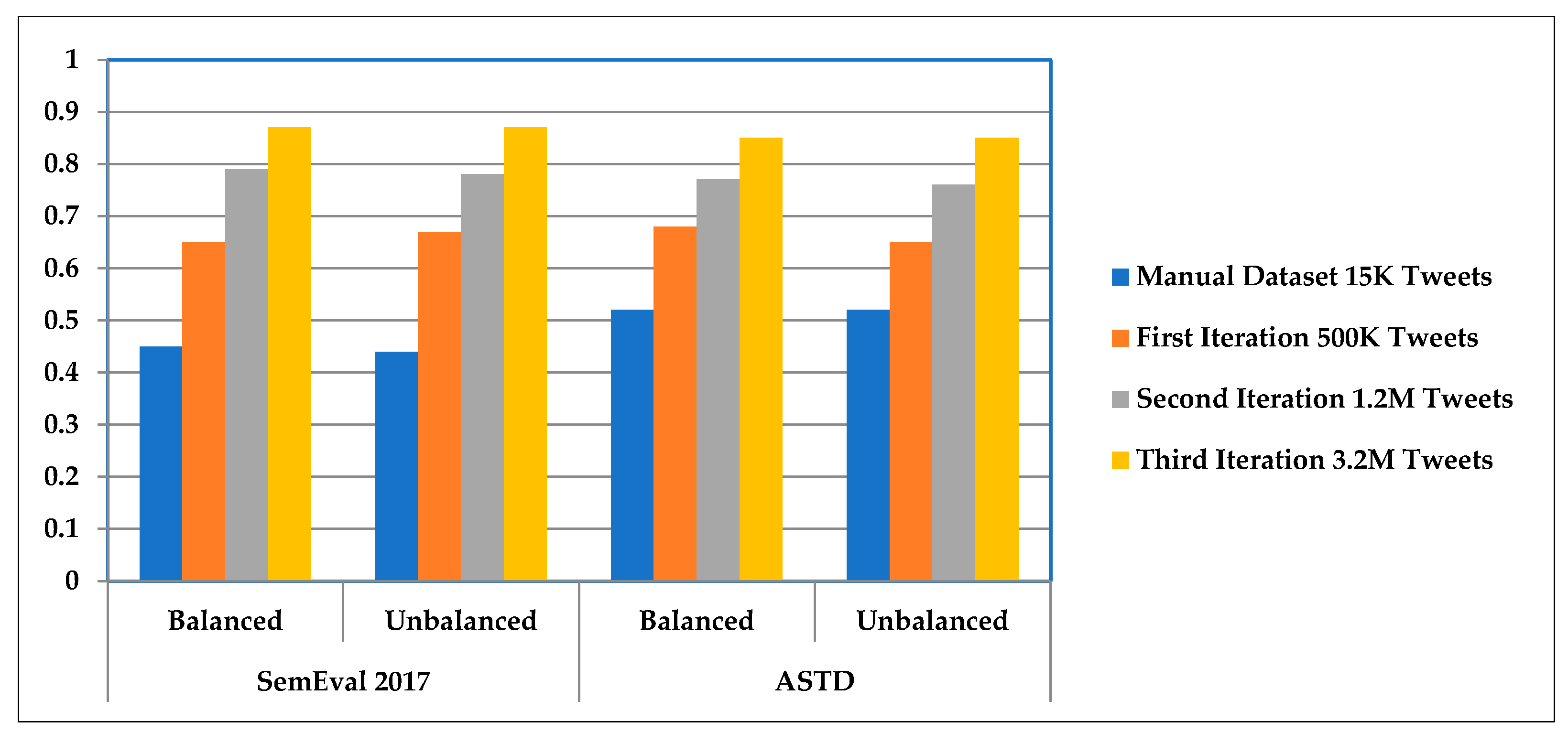
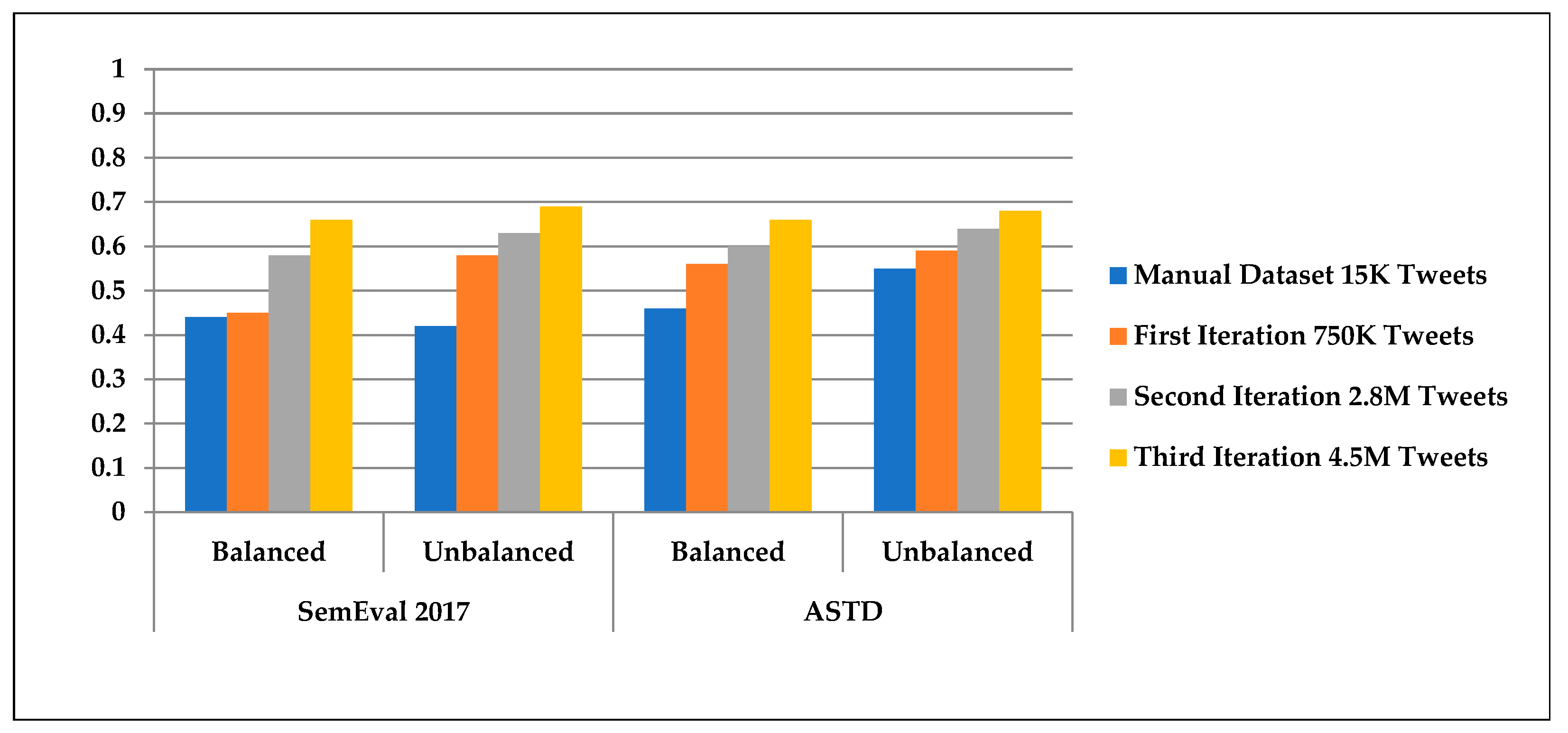
4. Results
5. Discussion and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hovy, E.; Lavid, J. Towards a ‘science’of corpus annotation: A new methodological challenge for corpus linguistics. Int. J. Transl. 2010, 22, 13–36. [Google Scholar]
- Horbach, A.; Thater, S.; Steffen, D.; Fischer, P.M.; Witt, A.; Pinkal, M. Internet corpora: A challenge for linguistic processing. Datenbank-Spektrum 2015, 15, 41–47. [Google Scholar] [CrossRef]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017. [Google Scholar]
- Nabil, M.; Aly, M.; Atiya, A. Astd: Arabic sentiment tweets dataset. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- fastText. Available online: https://fasttext.cc/ (accessed on 2 March 2021).
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Rao, A.; Spasojevic, N. Actionable and political text classification using word embeddings and lstm. arXiv 2016, arXiv:1607.02501. [Google Scholar]
- Baly, R.; El-Khoury, G.; Moukalled, R.; Aoun, R.; Hajj, H.; Shaban, K.B.; El-Hajj, W. Comparative evaluation of sentiment analysis methods across Arabic dialects. Procedia Comput. Sci. 2017, 117, 266–273. [Google Scholar] [CrossRef]
- Al-Laith, A.; Shahbaz, M. Tracking sentiment towards news entities from arabic news on social media. Future Gener. Comput. Syst. 2021, 118, 467–484. [Google Scholar] [CrossRef]
- Aly, M.; Atiya, A. Labr: A large scale arabic book reviews dataset. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013. [Google Scholar]
- ElSahar, H.; El-Beltagy, S.R. Building large arabic multi-domain resources for sentiment analysis. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Elnagar, A.; Einea, O. Brad 1.0: Book reviews in arabic dataset. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Elnagar, A.; Lulu, L.; Einea, O. An annotated huge dataset for standard and colloquial arabic reviews for subjective sentiment analysis. Procedia Comput. Sci. 2018, 142, 182–189. [Google Scholar]
- Elnagar, A.; Khalifa, Y.S.; Einea, A. Hotel Arabic-reviews dataset construction for sentiment analysis applications. In Intelligent Natural Language Processing: Trends and Applications; Springer: Cham, Swizerland, 2018; pp. 35–52. [Google Scholar]
- Guellil, I.; Adeel, A.; Azouaou, F.; Hussain, A. Sentialg: Automated corpus annotation for algerian sentiment analysis. In Proceedings of the International Conference on Brain Inspired Cognitive Systems, Xi’an, China, 7–8 July 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Gamal, D.; Alfonse, M.; El-Horbaty, E.S.M.; Salem, A.B.M. Twitter benchmark dataset for Arabic sentiment analysis. Int. J. Mod. Educ. Comput. Sci. 2019, 11, 33. [Google Scholar] [CrossRef] [Green Version]
- Abdellaoui, H.; Zrigui, M. Using tweets and emojis to build tead: An Arabic dataset for sentiment analysis. Comput. Sist. 2018, 22, 777–786. [Google Scholar] [CrossRef]
- Dahou, A.; Xiong, S.; Zhou, J.; Haddoud, M.H.; Duan, P. Word embeddings and convolutional neural network for arabic sentiment classification. In Proceedings of the Coling 2016, the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016. [Google Scholar]
- Abo, M.E.M.; Shah, N.A.K.; Balakrishnan, V.; Kamal, M.; Abdelaziz, A.; Haruna, K. SSA-SDA: Subjectivity and sentiment analysis of sudanese dialect Arabic. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Aljouf, Saudi Arabia, 10–11 April 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Al-Twairesh, N.; Al-Negheimish, H. Surface and deep features ensemble for sentiment analysis of arabic tweets. IEEE Access 2019, 7, 84122–84131. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Khalifa, H.; Al-Salman, A.; Al-Ohali, Y. Arasenti-tweet: A corpus for arabic sentiment analysis of saudi tweets. Procedia Comput. Sci. 2017, 117, 63–72. [Google Scholar] [CrossRef]
- Alqarafi, A.; Adeel, A.; Hawalah, A.; Swingler, K.; Hussain, A. A Semi-supervised Corpus Annotation for Saudi Sentiment Analysis Using Twitter. In Proceedings of the International Conference on Brain Inspired Cognitive Systems, Xi’an, China, 7–8 July 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Brum, H.B.; Nunes, M.D.G.V. Semi-supervised Sentiment Annotation of Large Corpora. In Proceedings of the International Conference on Computational Processing of the Portuguese Language, Canela, Brazil, 24–26 September 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Iosifidis, V.; Ntoutsi, E. Large scale sentiment learning with limited labels. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Amazon Mechanical Turk. Available online: https://www.mturk.com (accessed on 2 March 2021).
- Alahmary, R.M.; Al-Dossari, H.Z.; Emam, A.Z. Sentiment analysis of Saudi dialect using deep learning techniques. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Baly, R.; Khaddaj, A.; Hajj, H.; El-Hajj, W.; Shaban, K.B. Arsentd-lev: A multi-topic corpus for target-based sentiment analysis in arabic levantine tweets. arXiv 2019, arXiv:1906.01830, 2019. [Google Scholar]
- CrowdFlowerplatform. Available online: https://appen.com/ (accessed on 2 March 2021).
- Rahab, H.; Zitouni, A.; Djoudi, M. SANA: Sentiment analysis on newspapers comments in Algeria. J. King SaudUniv. Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Al-Thubaity, A.; Alharbi, M.; Alqahtani, S.; Aljandal, A. A saudi dialect twitter corpus for sentiment and emotion analysis. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Atoum, J.O.; Nouman, M. Sentiment analysis of Arabic jordanian dialect tweets. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 256–262. [Google Scholar] [CrossRef] [Green Version]
- Al-Moslmi, T.; Albared, M.; Al-Shabi, A.; Omar, N.; Abdullah, S. Arabic senti-lexicon: Constructing publicly available language resources for Arabic sentiment analysis. J. Inf. Sci. 2018, 44, 345–362. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.Z.; Lahcen, A.A.; Belfkih, S. ASA: A framework for Arabic sentiment analysis. J. Inf. Sci. 2020, 46, 544–559. [Google Scholar] [CrossRef]
- Mdhaffar, S.; Bougares, F.; Esteve, Y.; Hadrich-Belguith, L. Sentiment analysis of tunisian dialects: Linguistic ressources and experiments. In Proceedings of the Third Arabic Natural Language Processing Workshop (WANLP 2017), Valencia, Spain, 3–4 April 2017. [Google Scholar]
- Abdul-Mageed, M.; Diab, M.T. AWATIF: A Multi-Genre Corpus for Modern Standard Arabic Subjectivity and Sentiment Analysis. In Proceedings of the LREC 2012, Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Mourad, A.; Darwish, K. Subjectivity and sentiment analysis of modern standard Arabic and Arabic microblogs. In Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Atlanta, GA, USA, 13–14 June 2013. [Google Scholar]
- Abdulla, N.A.; Ahmed, N.A.; Shehab, M.A.; Al-Ayyoub, M. Arabic sentiment analysis: Lexicon-based and corpus-based. In Proceedings of the 2013 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, 3–5 December 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Catal, C.; Nangir, M. A sentiment classification model based on multiple classifiers. Appl. Soft Comput. 2017, 50, 135–141. [Google Scholar] [CrossRef]
- Alharbi, F.R.; Khan, M.B. Identifying comparative opinions in Arabic text in social media using machine learning techniques. SN Appl. Sci. 2019, 1, 213. [Google Scholar] [CrossRef] [Green Version]
- Al-Laith, A.; Alenezi, M. Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic. Information 2021, 12, 86. [Google Scholar] [CrossRef]
- Farha, I.A.; Magdy, W. Mazajak: An online Arabic sentiment analyser. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Mulki, H.; Haddad, H.; Gridach, M.; Babaoglu, I. Empirical evaluation of leveraging named entities for Arabic sentiment analysis. arXiv 2019, arXiv:1904.10195. [Google Scholar] [CrossRef]
- El-Beltagy, S.R. NileULex: A phrase and word level sentiment lexicon for Egyptian and modern standard Arabic. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Abdulla, N.A.; Ahmed, N.A.; Shehab, M.A.; Al-Ayyoub, M.; Al-Kabi, M.N.; Al-rifai, S. Towards improving the lexicon-based approach for arabic sentiment analysis. Int. J. Inf. Technol. Web Eng.(IJITWE) 2014, 9, 55–71. [Google Scholar] [CrossRef] [Green Version]
- Number of Monthly Active Twitter Users Worldwide from 1st Quarter 2010 to 1st Quarter 2019. Available online: https://www.statista.com/statistics/282087/number-of-monthly-active-twitter-users/ (accessed on 2 March 2021).
- Mohammad Salameh, S.M.M.; Kiritchenko, S. Arabic Sentiment Analysis and Cross-lingual Sentiment Resources. Available online: https://saifmohammad.com/WebPages/ArabicSA.html (accessed on 2 March 2021).
- Elsahar, H. Large Multi-Domain Resources for Arabic Sentiment Analysis. Available online: https://github.com/hadyelsahar/large-arabic-sentiment-analysis-resouces (accessed on 2 March 2021).
- NileULex. Available online: https://github.com/NileTMRG/NileULex (accessed on 2 March 2021).
- MASC. Available online: https://github.com/almoslmi/masc (accessed on 2 March 2021).
- Salameh, M.; Mohammad, S.; Kiritchenko, S. Sentiment after translation: A case-study on arabic social media posts. In Proceedings of the 2015 conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015. [Google Scholar]
- Youssef, M.; El-Beltagy, S.R. MoArLex: An Arabic sentiment lexicon built through automatic lexicon expansion. Procedia Comput. Sci. 2018, 142, 94–103. [Google Scholar] [CrossRef]
- Torre, I.G.; Luque, B.; Lacasa, L.; Kello, C.T.; Hernández-Fernández, A. On the physical origin of linguistic laws and lognormality in speech. R. Soc. Open Sci. 2019, 6, 191023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sicilia-Garcia, J.; Ming, E.I.; Smith, F.J. Extension of Zipf’s law to words and phrases. In Proceedings of the COLING 2002: The 19th International Conference on Computational Linguistics, Taipei, Taiwan, 26–30 August 2002. [Google Scholar]
- Fralick, S. Learning to recognize patterns without a teacher. IEEE Trans. Inf. Theory 1967, 13, 57–64. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Dataset | Year Size | Domain | Annotation Method | Type |
|---|---|---|---|---|
| [10] Labr | 2013 63,257 | Book reviews | Automatic | DA |
| [11] HTL, RES, MOV, PROD | 2015 33,000 | Movies, hotels, restaurants, and products reviews | Automatic | MSA/DA |
| [12] BRAD 1.0 | 2016 510,600 | Book reviews | Automatic | MSA |
| [13] BRAD 2.0 | 2018 692,586 | Book reviews | Automatic | MSA/DA |
| [14] HARD | 2017 490,587 | Reviews | Automatic | MSA/DA |
| [15] SentiALG | 2018 8000 | Automatic | DA | |
| [16] | 2018 151,000 | Tweets | Automatic | DA |
| [19] SSA-SDA | 2019 5456 | Politics | Automatic | DA |
| [17] TEAD | 2018 6M | Tweets | Automatic | MSA/DA |
| [21] AraSenTi-Tweet | 2017 17,573 | Tweets | Semi-automatic | MSA/DA |
| [22] | 2018 4000 | Tweets | Semi-automatic | MSA/DA |
| [4] ASTD | 2015 10,000 | Tweets | Manual | MSA/DA |
| [26] SDCT | 2019 32,063 | Tweets | Manual | DA |
| [27] ArSentD-LEV | 2019 4000 | Tweets | Manual | DA |
| [29] SANA | 2019 513 | Comments | Manual | DA |
| [30] | 2018 5400 | Tweets | Manual | DA |
| [31] | 2019 1000 | Tweets | Manual | DA |
| [32] MASC | 2018 8860 | Reviews | Manual | MSA/DA |
| [33] MSAC | 2019 2000 | Reviews | Manual | DA |
| [34] TSAC | 2017 17,000 | Facebook Comments | Manual | DA |
| [35] AWATIF | 2012 10,723 | Penn Arabic Treebank, web forums, and Wikipedia | Manual | MSA/DA |
| [36] | 2013 2300 | Tweets | Manual | MSA/DA |
| [37] ArTwitter | 2013 2000 | Tweets | Manual | DA |
| Classification | Approaches | Features/Techniques | Studies |
|---|---|---|---|
| Machine Learning | Support Vector Machines (SVM), Decision Tree (DT), Naïve Bayes (NB), and Multinomial Naïve Bayes (MNB) | Term Frequency—Inverse Document Frequency (TF-IDF), N-grams, Count Vector | [4,10,11,12,13,15,16,19,22,26,27,29,32,33,34,40] |
| Deep Learning | Long Short-Term Memory (LSTM), Bidirectional Long Short-Term Memory (B-LSTM), and Convolutional Neural Network (CNN) | Continuous Bag of Words (CBOW) | [16,19,24,30] |
| Lexicon-based | Lexicon Terms | [10,13,30] |
| # | Lexicon | # of Terms/Phrases | Type | Study |
|---|---|---|---|---|
| 1 | 230 Arabic words | 230 | MSA | [50] |
| 2 | Large Arabic Resources for Sentiment Analysis | 1913 | MSA/DA | [11] |
| 3 | MorLex | 10,761 | MSA/DA | [51] |
| 4 | NileULex | 5953 | MSA/DA | [43] |
| 5 | senti-lexicon | 3880 | MSA/DA | [32] |
| Title | Number |
|---|---|
| Tokens | 479,661,838 |
| Unique Tokens | 9,281,106 |
| Average Words per Tweet | 13.8 |
| Users | 7,649,717 |
| Total Tweets | 34,706,737 |
| Year | # of Tweets | Year | # of Tweets |
|---|---|---|---|
| 2007 | 116 | 2014 | 385,841 |
| 2008 | 756 | 2015 | 824,102 |
| 2009 | 65,287 | 2016 | 2,238,905 |
| 2010 | 730,772 | 2017 | 1,395,090 |
| 2011 | 291,451 | 2018 | 3,514,951 |
| 2012 | 336,933 | 2019 | 5,382,799 |
| 2013 | 214,461 | 2020 | 19,325,273 |
| Positive | Negative | Neutral | Total | |
|---|---|---|---|---|
| Training Set | 1,013,576 | 1,013,576 | 1,013,576 | 3,040,728 |
| Dataset | Positive | Negative | Neutral | Total | Study | ||
|---|---|---|---|---|---|---|---|
| Two Classes | Balanced | 743 | 743 | − | 1486 | [3] | |
| Unbalanced | 743 | 1142 | − | 1885 | |||
| SemEval 2017 | Three Classes | Balanced | 743 | 743 | 743 | 2229 | |
| Unbalanced | 743 | 1142 | 1444 | 3329 | |||
| ASTD | Two Classes | Balanced | 799 | 799 | − | 1598 | [4] |
| Unbalanced | 799 | 1684 | − | 2483 | |||
| Three Classes | Balanced | 799 | 799 | 799 | 2397 | ||
| Unbalanced | 799 | 1684 | 813 | 3296 |
| Hyper Parameter | LSTM |
|---|---|
| Activation Function | softmax |
| Hidden Layers | 6 |
| Dropout rate | 0.3 |
| Learning rate | 0.001 |
| Number of epochs | 10 |
| Batch size | 1024 |
| Dataset | Al-Twairesh, N.; Al-Negheimish, H.2019 [20] | Farha, Ibrahim et al., 2019 [41] | Our Models |
|---|---|---|---|
| SemEval 2017 | 80.37 | 63 | 87.4 |
| ASTD | 79.77 | 72 | 85.2 |
| Dataset | Farha, Ibrahim et al., 2019 [41] | Our Models |
|---|---|---|
| SemEval 2017 | 63.38 | 69.4 |
| ASTD | 64.10 | 68.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Laith, A.; Shahbaz, M.; Alaskar, H.F.; Rehmat, A. AraSenCorpus: A Semi-Supervised Approach for Sentiment Annotation of a Large Arabic Text Corpus. Appl. Sci. 2021, 11, 2434. https://doi.org/10.3390/app11052434
Al-Laith A, Shahbaz M, Alaskar HF, Rehmat A. AraSenCorpus: A Semi-Supervised Approach for Sentiment Annotation of a Large Arabic Text Corpus. Applied Sciences. 2021; 11(5):2434. https://doi.org/10.3390/app11052434
Chicago/Turabian StyleAl-Laith, Ali, Muhammad Shahbaz, Hind F. Alaskar, and Asim Rehmat. 2021. "AraSenCorpus: A Semi-Supervised Approach for Sentiment Annotation of a Large Arabic Text Corpus" Applied Sciences 11, no. 5: 2434. https://doi.org/10.3390/app11052434