
A Methodology for Utilizing Vector Space to Improve the Performance of a Dog Face Identification Model


Abstract
:1. Introduction
2. Related Studies
2.1. Human Face Identification
2.2. Deep Learning on Animal Biometrics
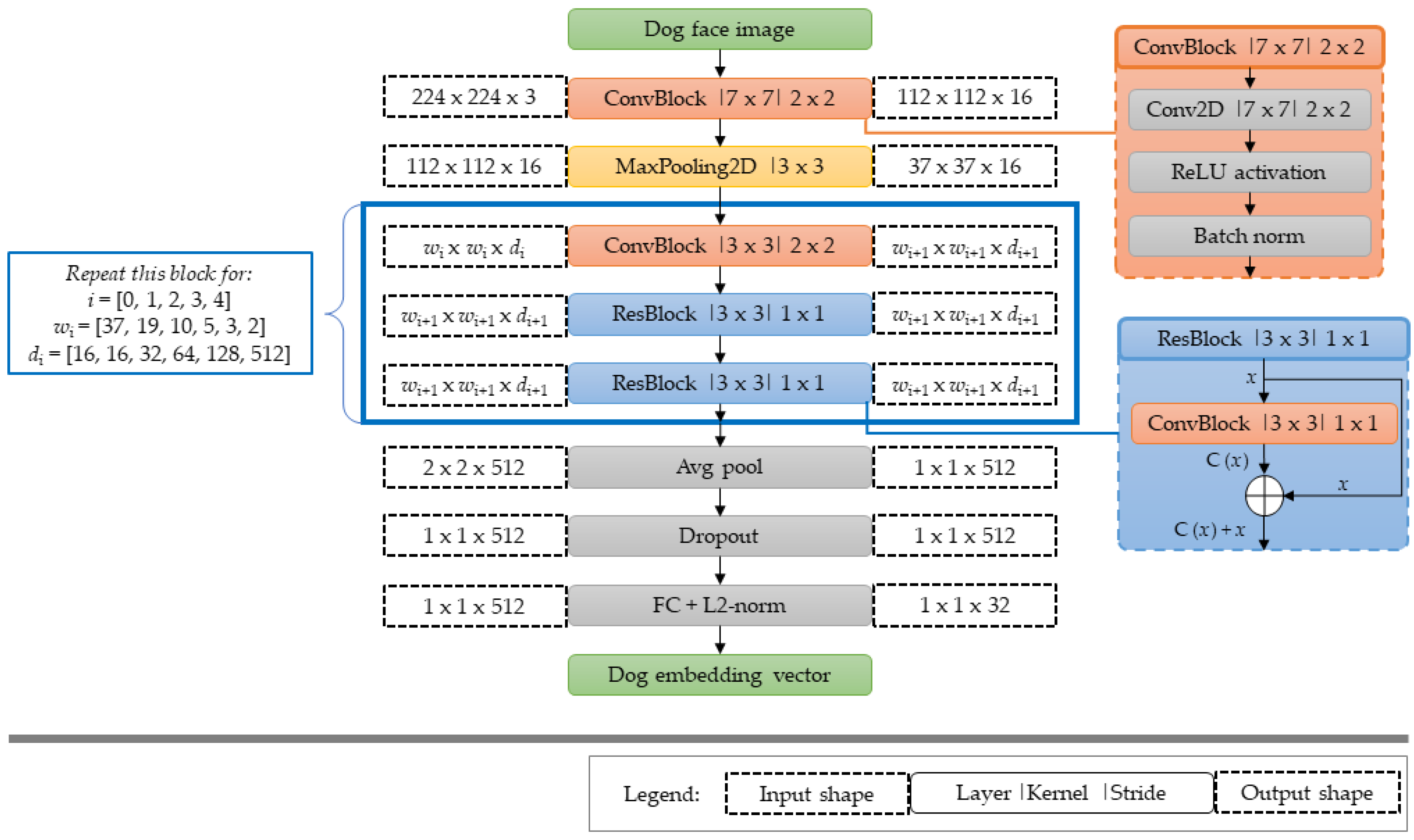
3. Methodology
3.1. Architecture
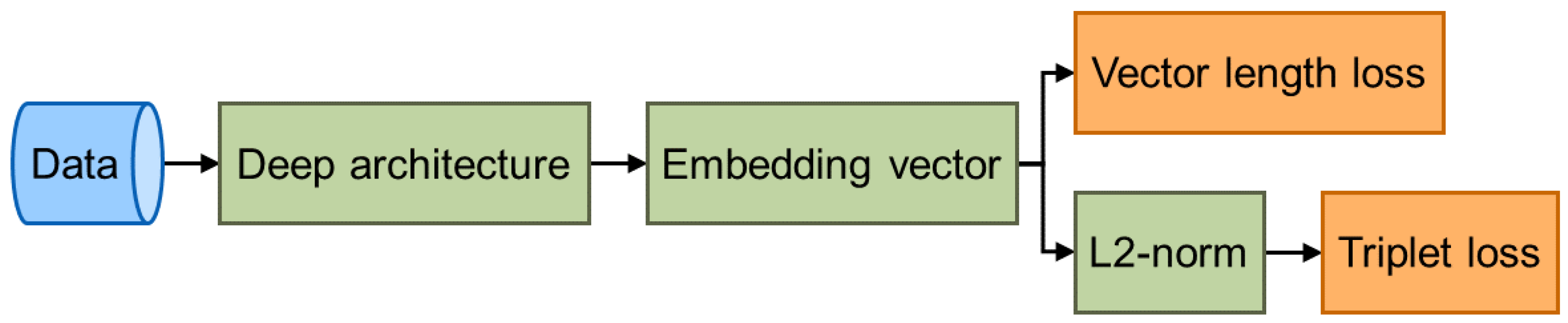
3.2. The Existing Loss Functions
3.3. Vector Length Loss
3.4. Learning Method
3.4.1. Stage 1 of Learning Method
3.4.2. Stage 2 of Learning Method
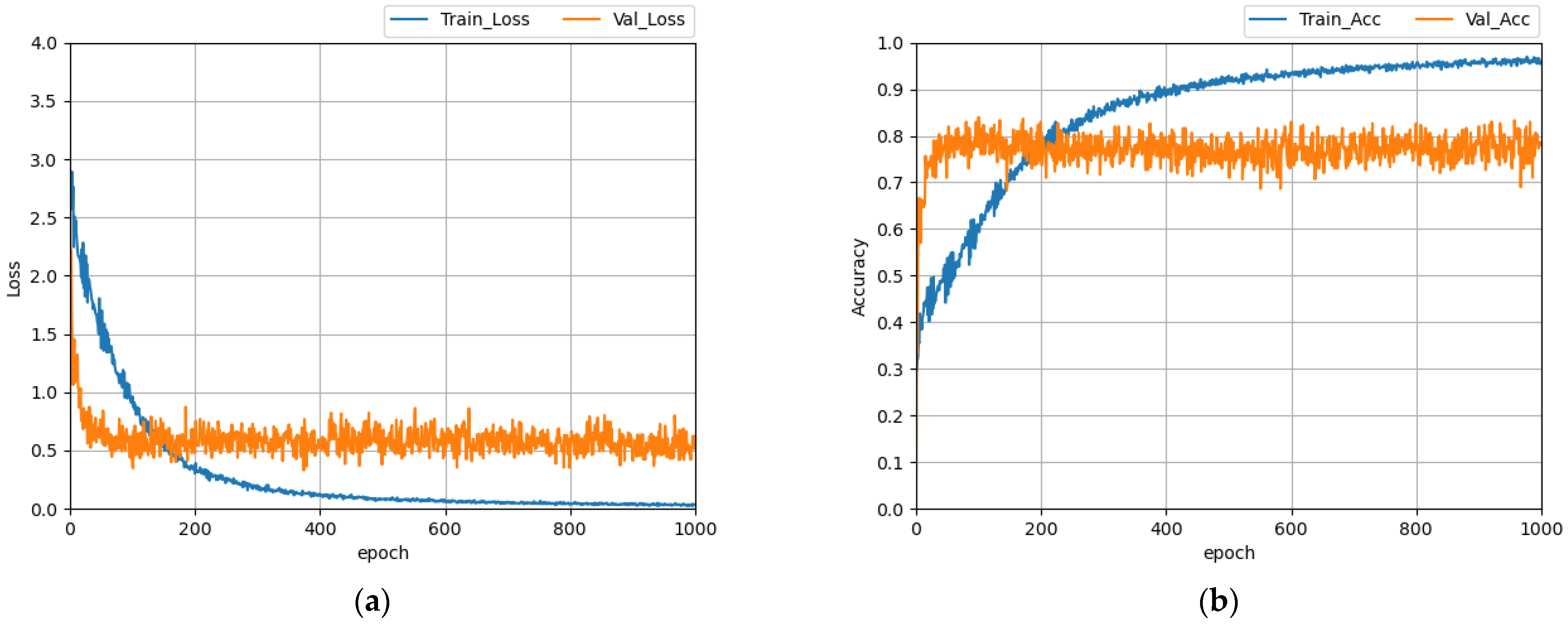
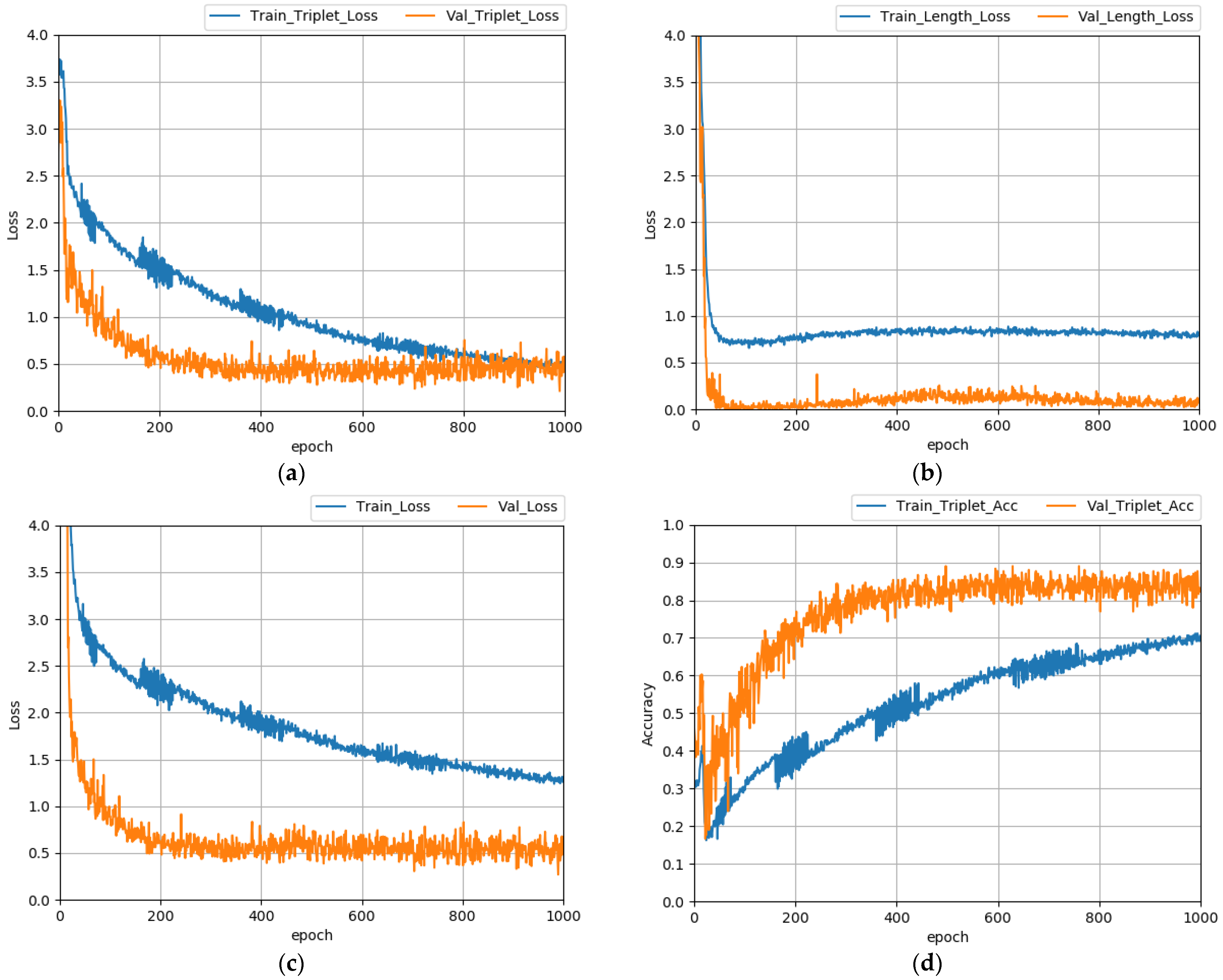
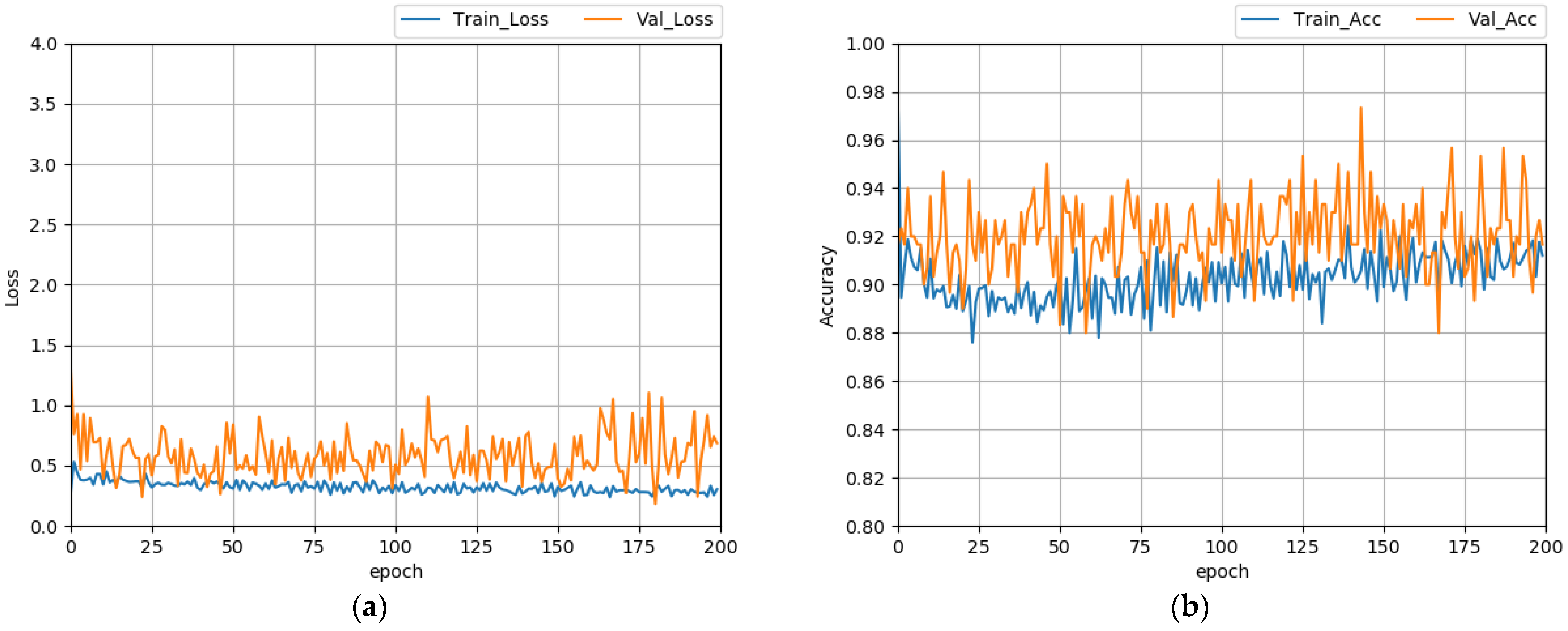
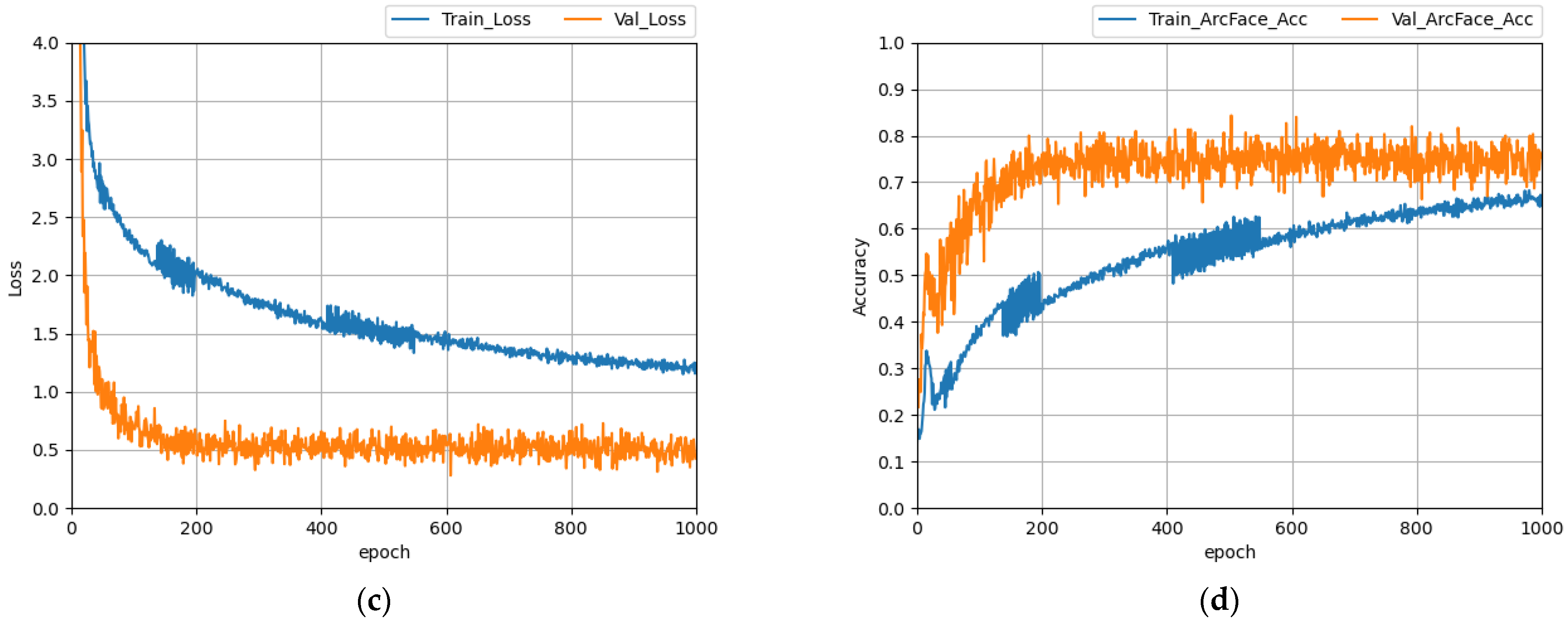
4. Implementation
4.1. Toy Experiment
4.2. Dataset and Model Definition
4.3. Models Implementation
5. Evaluation
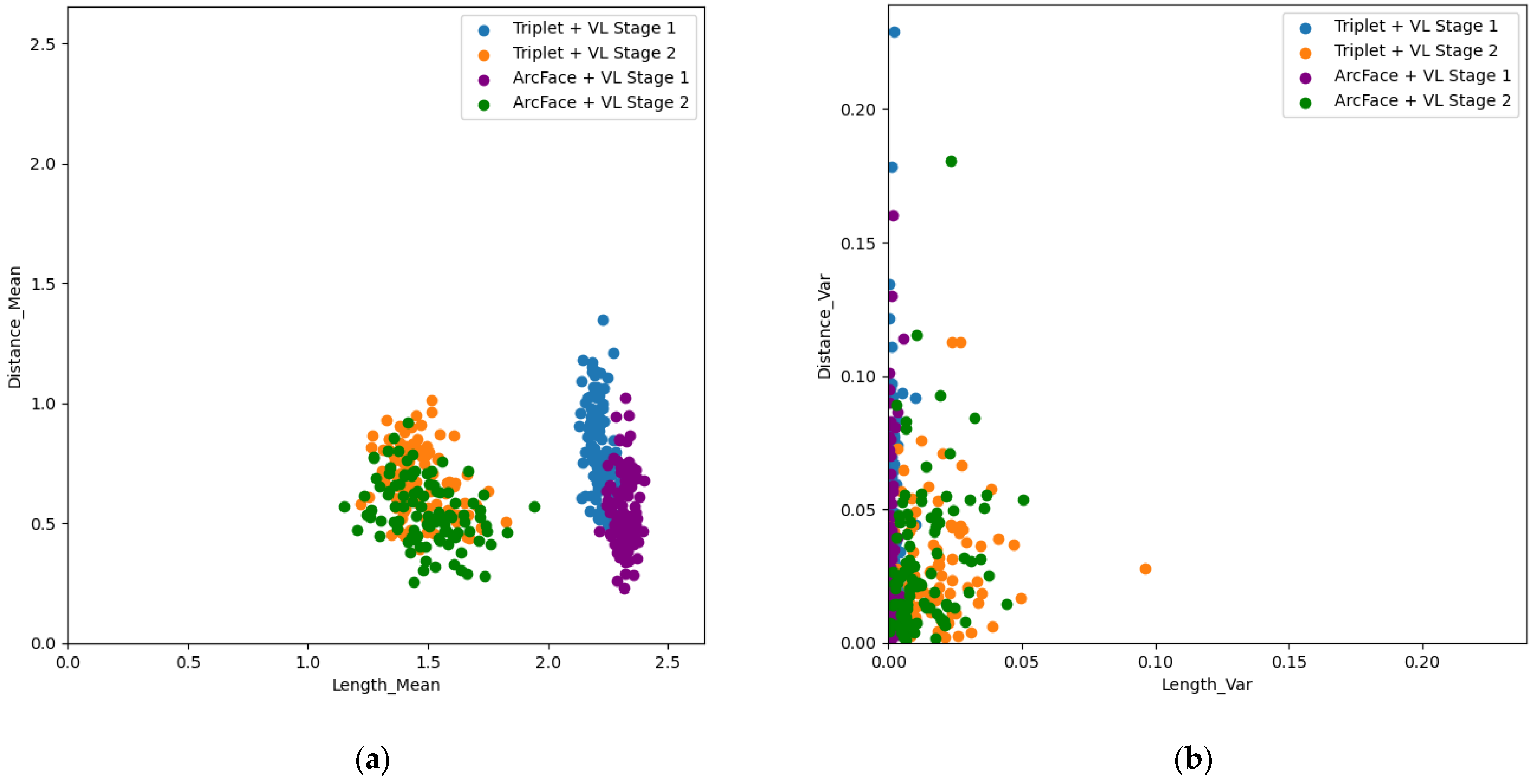
- Comparison of embedding vector distribution between the learning methods: The embedding vectors of the open set were extracted from the model trained by the base learning method, the SOTA learning method, and the proposed learning method, and their distributions were compared. The embedding vectors used values before the L2-norm layer. The distribution was compared by the mean and variance for the length of the embedding vector and the distance between the center of the object’s embedding vectors and the embedding vector for each object;
- Face verification: The model discerned whether a pair of images was the same object and calculated its accuracy. Specifically, the distance (d) between the two embedding vectors extracted by the model was compared to a specific threshold (t), and when d < t, the images were discerned as the same object. The accuracy of the discernment result is calculated. The receiver operating characteristic (ROC) curve and the optimum accuracy were compared between models while changing the threshold. This procedure was repeated 100 times to calculate the average of the ROC curves;
- Face identification: one image was selected for each object included in the open set to configure a set of 100 sub-training sets, and the remaining data comprised the sub-testing set. Rank 1 and rank 5 were extracted by comparing the distance between the embedding vectors of one sub-testing data and all sub-training data, their accuracy was calculated, and this procedure was repeated 1000 times for the entire sub-testing set to compare the mean, maximum, and minimum accuracy of rank 1 and rank 5.
5.1. Comparison of Embedding Vector Distribution between Learning Methods
5.2. Face Verification
5.3. Face Identification
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A








Appendix B
References
- Kumar, S.; Singh, S.K. Monitoring of pet animal in smart cities using animal biometrics. Future Gener. Comput. Syst. 2018, 83, 553–563. [Google Scholar] [CrossRef]
- Musgrave, C.; Cambier, J.L. System and Method of Animal Identification and Animal Transaction Authorization Using Iris Patterns. US Patent 6,424,727, 23 July 2002. [Google Scholar]
- Trigueros, D.S.; Meng, L.; Hartnett, M. Face recognition: From traditional to deep learning methods. arXiv 2018, arXiv:1811.00116. [Google Scholar]
- Schultz, M.; Joachims, T. Learning a distance metric from relative comparisons. In Advances in Neural Information Processing Systems 16; MIT Press: London, UK, 2004; pp. 41–48. [Google Scholar]
- Weinberger, K.Q.; Blitzer, J.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. In Advances in Neural Information Processing Systems 18; MIT Press: London, UK, 2006; pp. 1473–1480. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4690–4699. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- Sivic, J.; Everingham, M.; Zisserman, A. “Who are you?”-Learning person specific classifiers from video. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1145–1152. [Google Scholar]
- Chen, D.; Cao, X.; Wang, L.; Wen, F.; Sun, J. Bayesian face revisited: A joint formulation. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 566–579. [Google Scholar]
- Simonyan, K.; Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Fisher vector faces in the wild. BMVC 2013, 2, 4. [Google Scholar] [CrossRef] [Green Version]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Zheng, Y.; Pal, D.K.; Savvides, M. Ring loss: Convex feature normalization for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5089–5097. [Google Scholar]
- Zhang, Y.; Deng, W.; Wang, M.; Hu, J.; Li, X.; Zhao, D.; Wen, D. Global-local gcn: Large-scale label noise cleansing for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 7731–7740. [Google Scholar]
- Kim, Y.; Park, W.; Roh, M.C.; Shin, J. Groupface: Learning latent groups and constructing group-based representations for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 5621–5630. [Google Scholar]
- Awad, A.I. From classical methods to animal biometrics: A review on cattle identification and tracking. Comput. Electron. Agric. 2016, 123, 423–435. [Google Scholar] [CrossRef]
- Kumar, S.; Singh, S.K.; Singh, R.S.; Singh, A.K.; Tiwari, S. Real-time recognition of cattle using animal biometrics. J. Real-Time Image Process. 2017, 13, 505–526. [Google Scholar] [CrossRef]
- Kumar, S.; Pandey, A.; Satwik, K.S.R.; Kumar, S.; Singh, S.K.; Singh, A.K.; Mohan, A. Deep learning framework for recognition of cattle using muzzle point image pattern. Measurement 2018, 116, 1–17. [Google Scholar] [CrossRef]
- Kumar, S.; Singh, S.K.; Abidi, A.I.; Datta, D.; Sangaiah, A.K. Group sparse representation approach for recognition of cattle on muzzle point images. Int. J. Parallel Program. 2018, 46, 812–837. [Google Scholar] [CrossRef]
- Jarraya, I.; Ouarda, W.; Alimi, A.M. A preliminary investigation on horses recognition using facial texture features. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 2803–2808. [Google Scholar]
- Hansen, M.F.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.M.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- Crouse, D.; Jacobs, R.L.; Richardson, Z.; Klum, S.; Jain, A.; Baden, A.L.; Tecot, S.R. LemurFaceID: A face recognition system to facilitate individual identification of lemurs. BMC Zool. 2017, 2, 2. [Google Scholar] [CrossRef] [Green Version]
- Deb, D.; Wiper, S.; Gong, S.; Shi, Y.; Tymoszek, C.; Fletcher, A.; Jain, A.K. Face recognition: Primates in the wild. In Proceedings of the IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Los Angeles, CA, USA, 22–25 October 2018; pp. 1–10. [Google Scholar]
- Liu, J.; Kanazawa, A.; Jacobs, D.; Belhumeur, P. Dog breed classification using part localization. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 172–185. [Google Scholar]
- Wang, X.; Ly, V.; Sorensen, S.; Kambhamettu, C. Dog breed classification via landmarks. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5237–5241. [Google Scholar]
- Hsu, D. Using Convolutional Neural Networks to Classify Dog Breeds. CS231n: Convolutional Neural Networks for Visual Recognition. 2015. Available online: http://cs231n.stanford.edu/reports/2015/pdfs/fcdh_FinalReport.pdf (accessed on 26 February 2021).
- Ayanzadeh, A.; Vahidnia, S. Modified Deep Neural Networks for Dog Breeds Identification. Preprints 2018. [Google Scholar] [CrossRef]
- Mougeot, G.; Li, D.; Jia, S. A Deep Learning Approach for Dog Face Verification and Recognition. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Cuvu, Fiji, 26–30 August 2019; pp. 418–430. [Google Scholar]
- Moreira, T.P.; Perez, M.L.; de Oliveira Werneck, R.; Valle, E. Where is my puppy? retrieving lost dogs by facial features. Multimed. Tools Appl. 2017, 76, 15325–15340. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Tu, X.; Lai, K.; Yanushkevich, S. Transfer learning on convolutional neural networks for dog identification. In Proceedings of the IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 357–360. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epochs | Learning Rates | |
|---|---|---|
| 39 | 0.001 | |
| 12 | 0.0005 | |
| 12 | 0.0003 | |
| 6 | 0.0001 | |
| Total | 69 | - |
| Learning Methods | Loss | Accuracy |
|---|---|---|
| SOTA | 1.0612 | 65.00% |
| Triplet | 0.2069 | 93.33% |
| ArcFace | 0.3305 | 84.00% |
| Triplet + VL stage 1 | 0.27058 | 89.00% |
| Triplet + VL stage 2 | 0.1833 | 97.33% |
| ArcFace + VL stage 1 | 0.2809 | 84.33% |
| ArcFace + VL stage 2 | 0.2566 | 96.33% |
| Learning Methods | Threshold | Accuracy | Threshold | Accuracy |
|---|---|---|---|---|
| SOTA | α = 0.3 | 76.0% | best = 0.38 | 76.9% |
| Triplet | α = 0.3 | 55.9% | best = 1.29 | 87.0% |
| ArcFace | α = 0.3 | 55.2% | best = 1.31 | 86.4% |
| Triplet + VL | α = 0.3 | 54.3% | best = 2.49 | 88.4% |
| ArcFace + VL | α = 0.3 | 60.2% | best = 1.49 | 88.8% |
| Learning Methods | Rank 1 | Rank 5 | ||||
|---|---|---|---|---|---|---|
| Mean | Maximum | Minimum | Mean | Maximum | Minimum | |
| SOTA | 10.96% | 14.79% | 6.67% | 32.58% | 38.54% | 26.25% |
| Triplet | 37.52% | 45.21% | 31.04% | 65.84% | 72.50% | 59.58% |
| ArcFace | 38.41% | 44.38% | 32.92% | 65.92% | 70.83% | 60.83% |
| Triplet + VL | 39.74% | 47.08% | 32.92% | 68.80% | 73.96% | 63.12% |
| ArcFace + VL | 34.92% | 41.67% | 28.96% | 67.57% | 73.12% | 61.25% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, B.; So, H.; Rhee, J. A Methodology for Utilizing Vector Space to Improve the Performance of a Dog Face Identification Model. Appl. Sci. 2021, 11, 2074. https://doi.org/10.3390/app11052074
Yoon B, So H, Rhee J. A Methodology for Utilizing Vector Space to Improve the Performance of a Dog Face Identification Model. Applied Sciences. 2021; 11(5):2074. https://doi.org/10.3390/app11052074
Chicago/Turabian StyleYoon, Bohan, Hyeonji So, and Jongtae Rhee. 2021. "A Methodology for Utilizing Vector Space to Improve the Performance of a Dog Face Identification Model" Applied Sciences 11, no. 5: 2074. https://doi.org/10.3390/app11052074