
Impact of the Sub-Grid Scale Turbulence Model in Aeroacoustic Simulation of Human Voice


Abstract
:1. Introduction
2. CFD Model of Incompressible Flow in the Larynx
2.1. Mathematical Model
2.1.1. Smagorinsky SGS Model
2.1.2. One-Equation SGS Model
2.1.3. Wall-Adapting Local Eddy-Viscosity SGS Model
2.2. Boundary Conditions
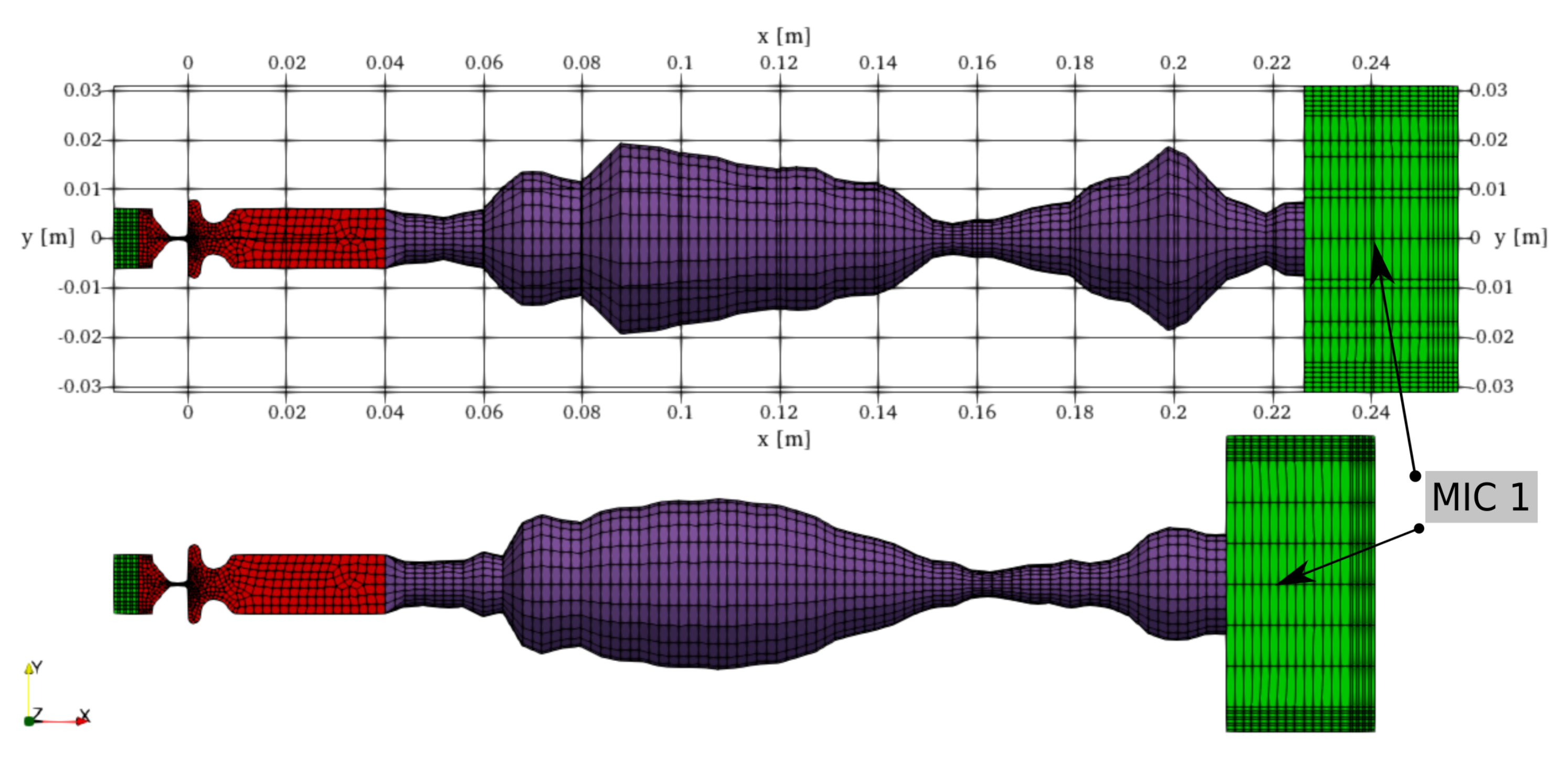
2.3. CFD Geometry and Mesh
2.4. Discretization and Numerical Solution
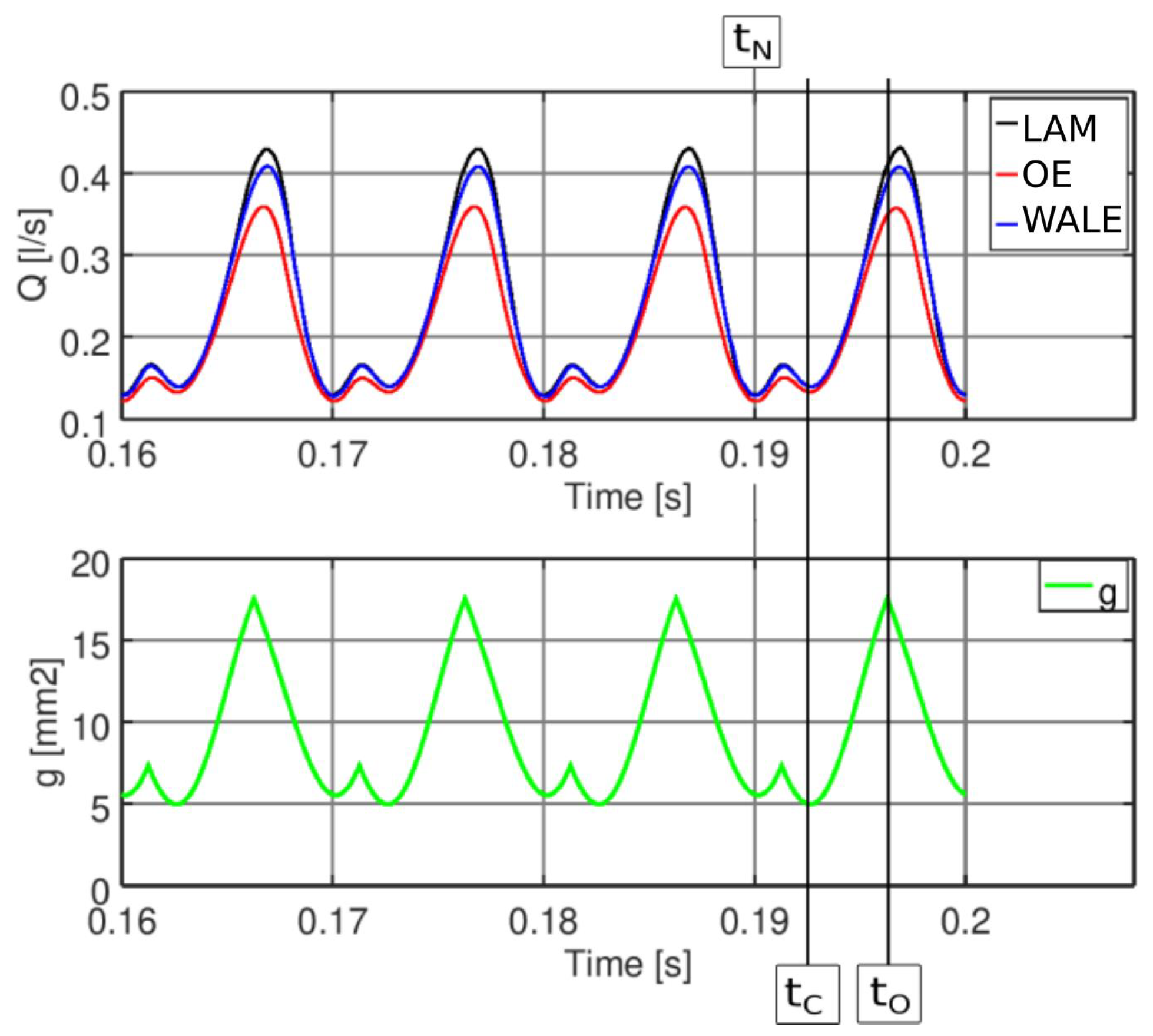
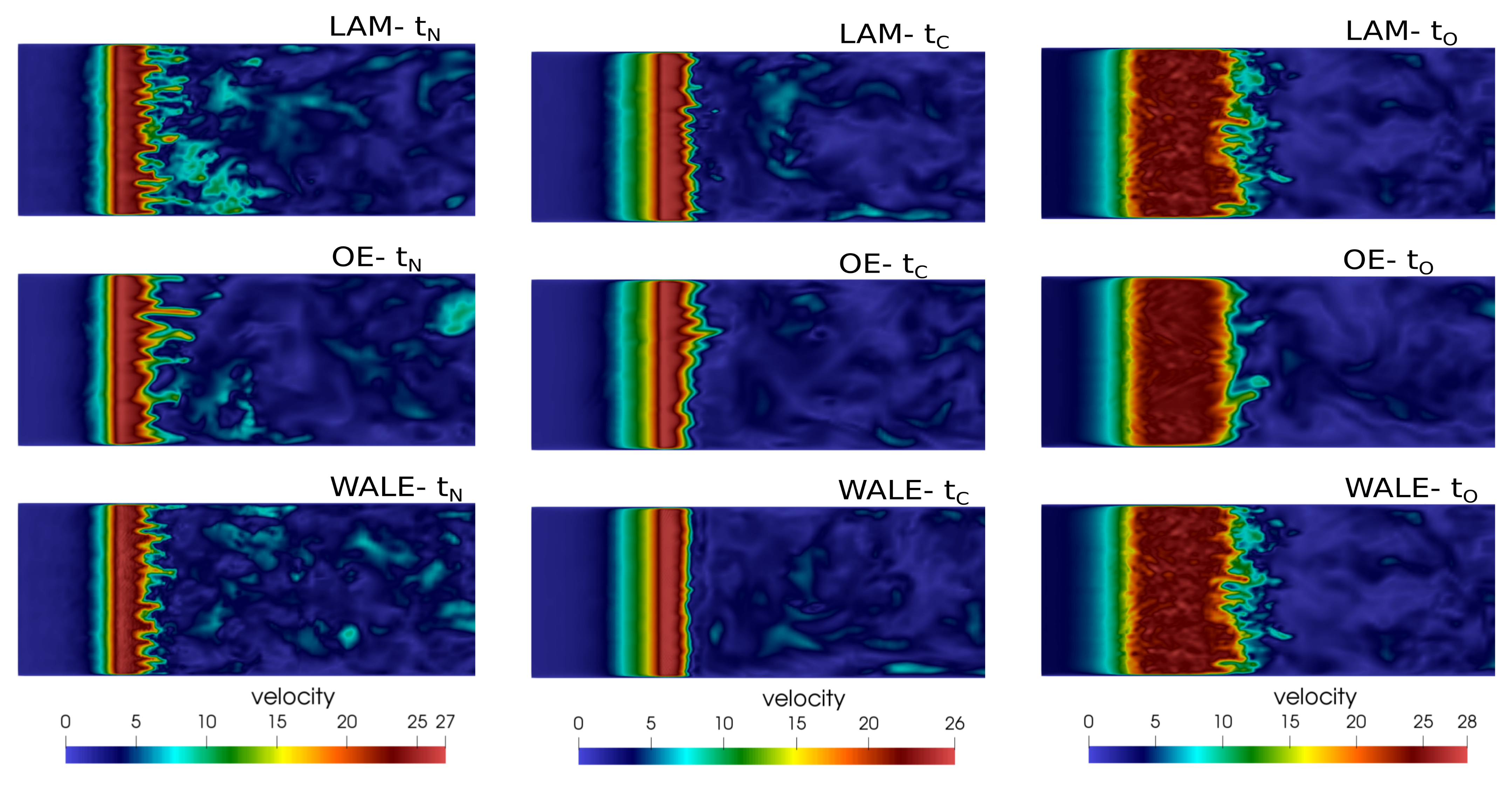
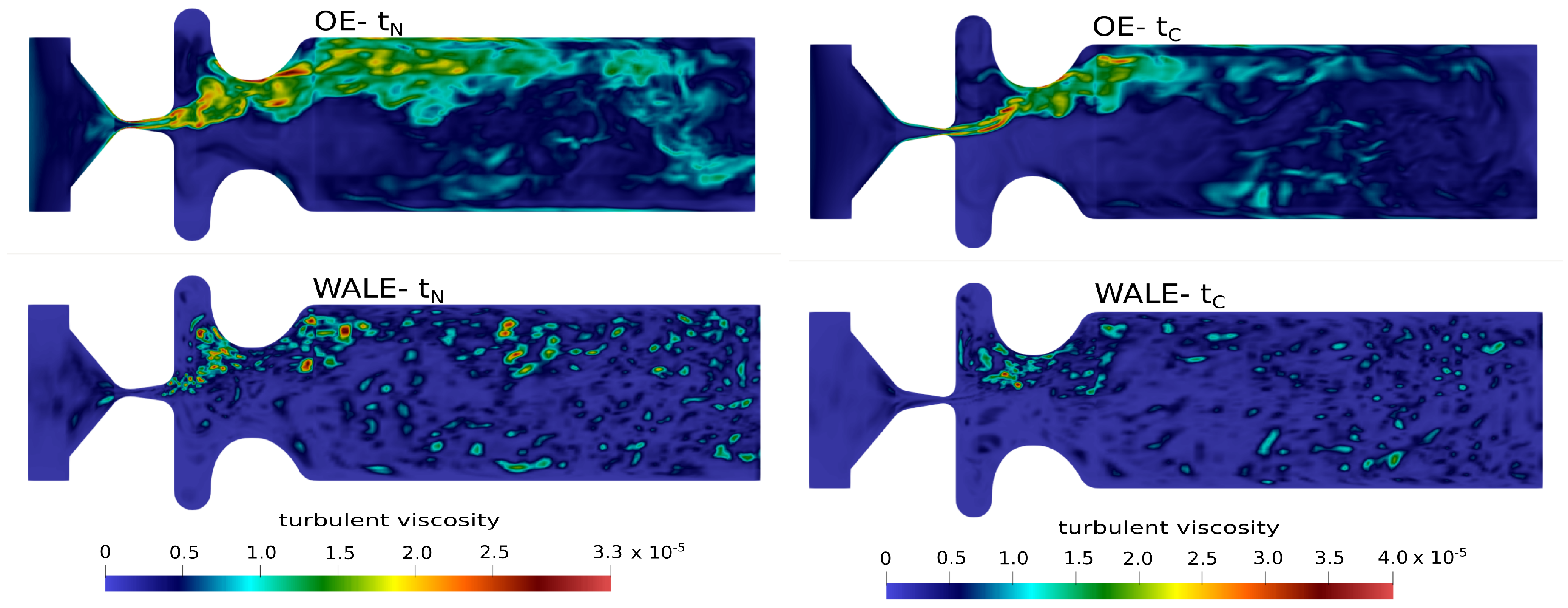
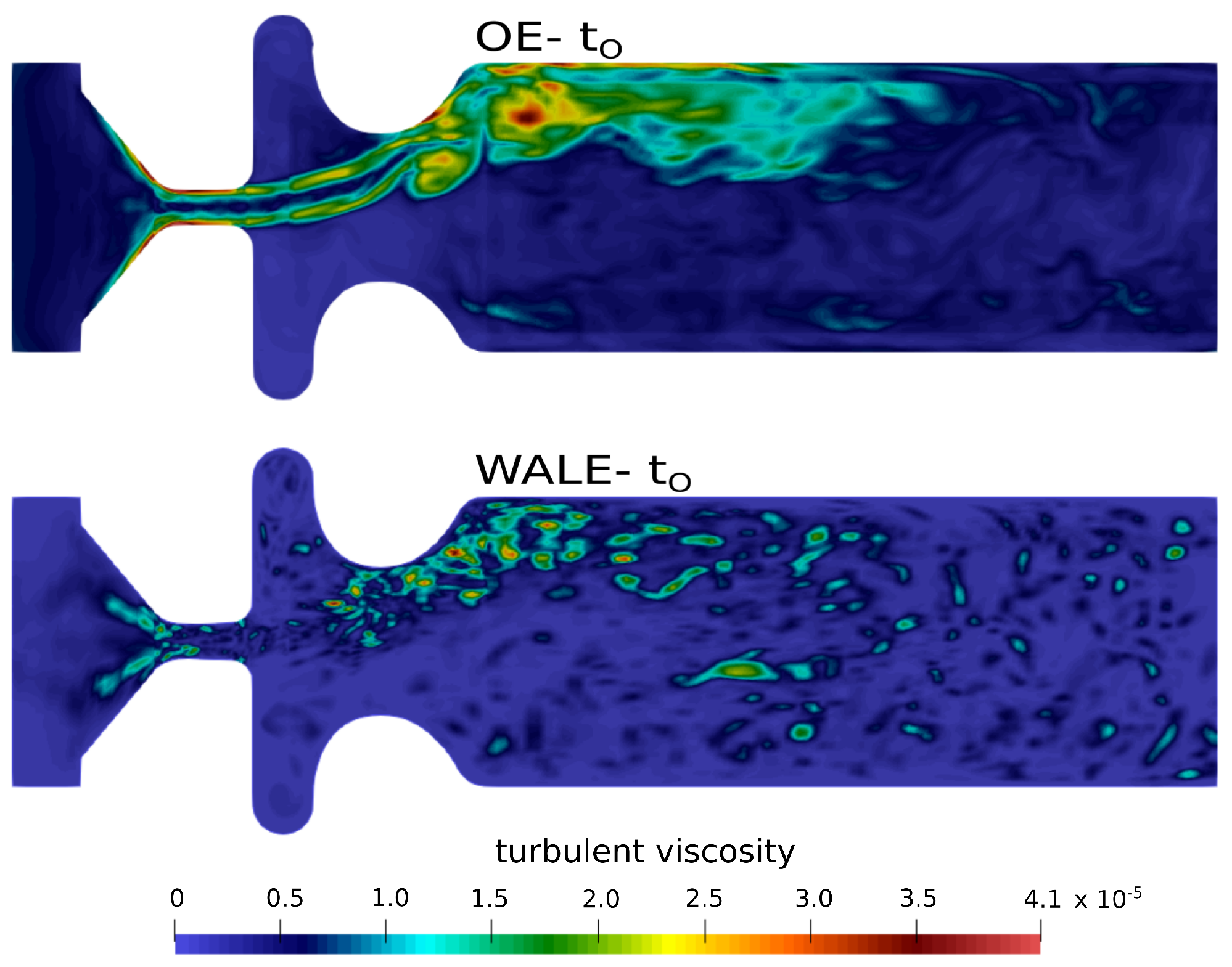
2.5. CFD Results
3. Computational Aeroacoustic (CAA) Model of Human Phonation
- i.
- A monopole source term due to the motion of vocal folds (the term is zero, when the walls are fixed and also the monopole source term at inlet is often omitted due to a non-reflecting boundary condition).
- ii.
- A dipole source term due to the unsteady force exerted by the surface of the vocal folds onto the fluid.
- iii.
- A quadrupole sound term due to the unsteady flow inside the vocal tract. See [2] for more details.
3.1. Mathematical Model
3.1.1. Acoustic Perturbation Equations (APEs)
- The velocity field is purely solenoidal, that is, ,
- The density is constant, that is, and ,
- The acoustic field is irrotational, that is, .
3.1.2. Perturbed Convective Wave Equation (PCWE)
3.2. Geometry, Mesh and Numerical Solution
3.3. CAA Results
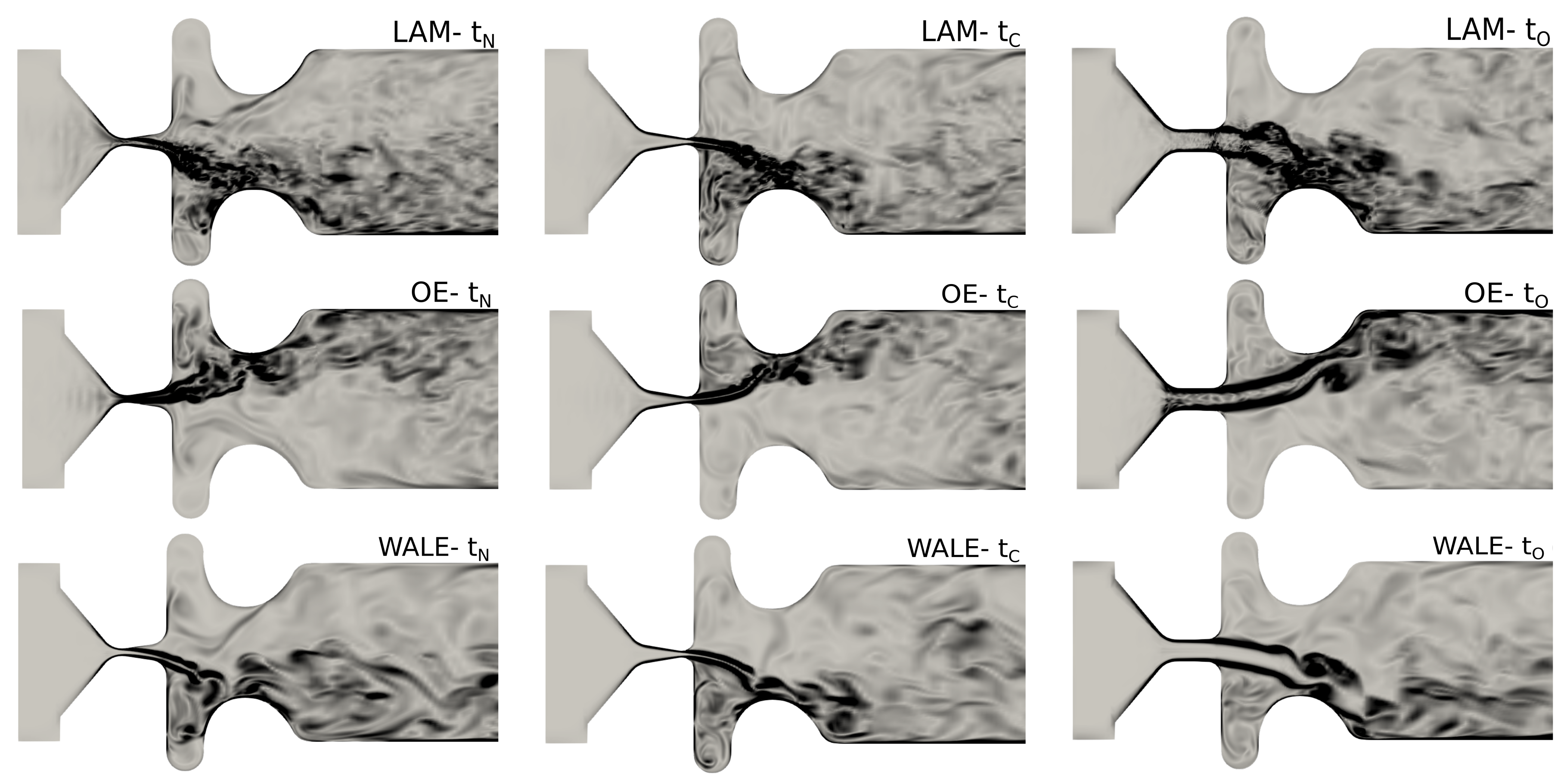
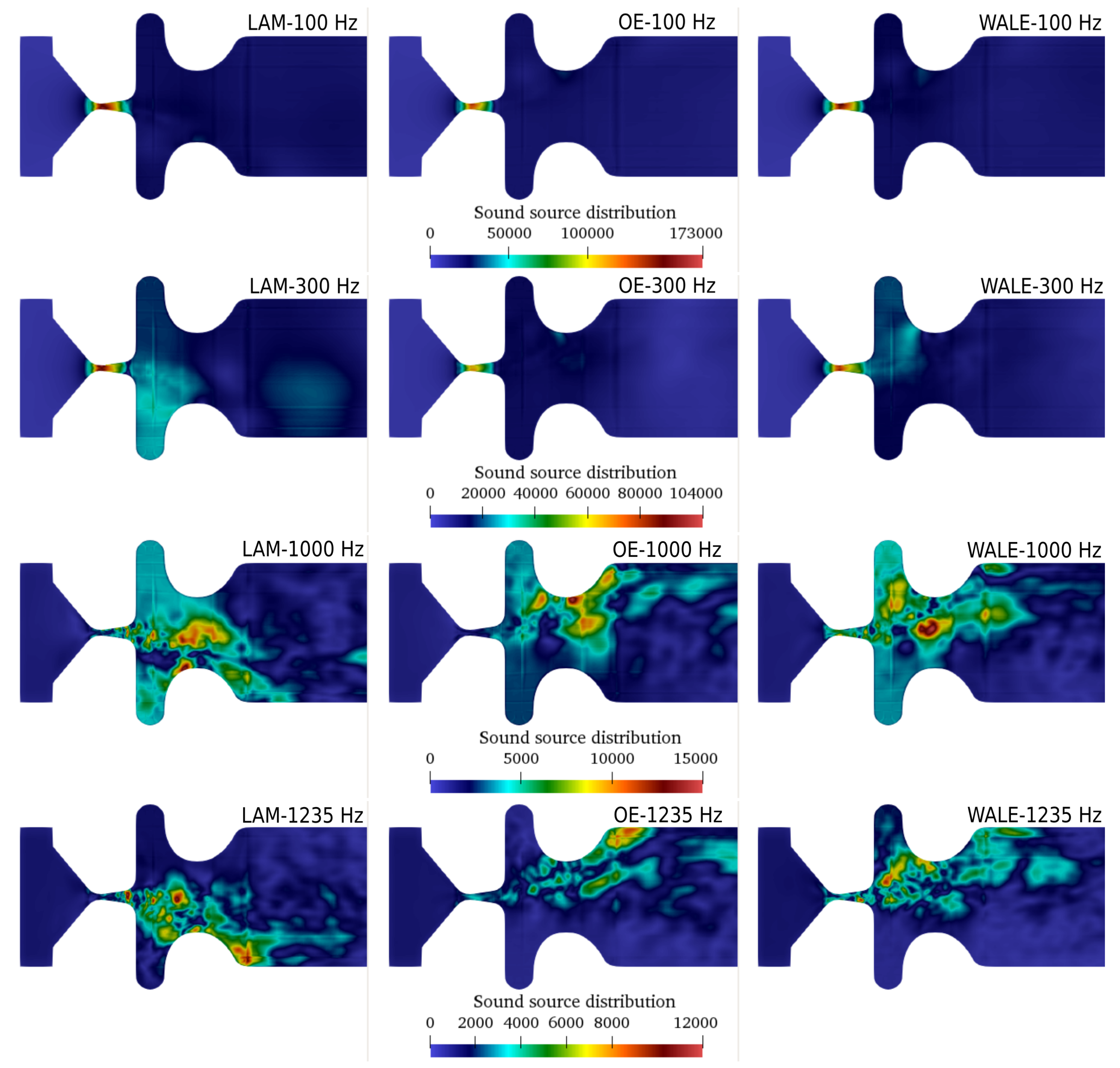
3.3.1. Acoustic Sources
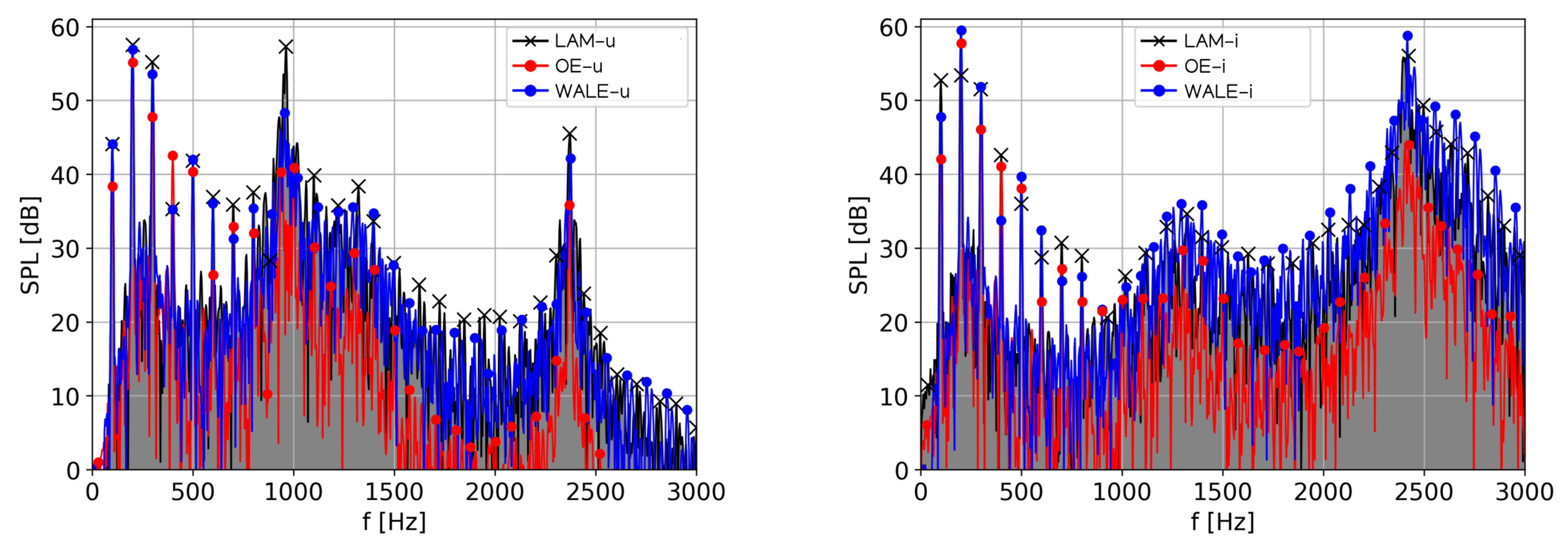
3.3.2. Wave Propagation
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Titze, I.R. Principles of Voice Production; Prentice Hall: Englewood Cliffs, NJ, USA, 1994. [Google Scholar]
- Zhao, W.; Zhang, C.; Frankel, S.H.; Mongeau, L. Computational aeroacoustics of phonation, Part I: Computational methods and sound generation mechanisms. J. Acoust. Soc. Am. 2002, 112, 2134–2146. [Google Scholar] [CrossRef]
- Zhang, Z.; Mongeau, L.; Frankel, S.H. Experimental verification of the quasi-steady approximation for aerodynamic sound generation by pulsating jets in tubes. J. Acoust. Soc. Am. 2002, 112, 1652–1663. [Google Scholar] [CrossRef]
- Dollinger, M.; Kobler, J.; Berry, D.A.; Mehta, D.; Luegmair, G.; Bohr, C. Experiments on Analysing Voice Production: Excised (Human, Animal) and In Vivo (Animal) Approaches. Curr. Bioinform. 2011, 6, 286–304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kniesburges, S.; Thomson, S.L.; Barney, A.; Triep, M.; Šidlof, P.; Horáček, J.; Brücker, C.; Becker, S. In vitro experimental investigation of voice production. Curr. Bioinform. 2011, 6, 305–322. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sadeghi, H.; Döllinger, M.; Kaltenbacher, M.; Kniesburges, S. Aerodynamic impact of the ventricular folds in computational larynx models. J. Acoust. Soc. Am. 2019, 145, 2376–2387. [Google Scholar] [CrossRef]
- Sadeghi, H.; Kniesburges, S.; Falk, S.; Kaltenbacher, M.; Schützenberger, A.; Döllinger, M. Towards a Clinically Applicable Computational Larynx Model. Appl. Sci. 2019, 9, 2288. [Google Scholar] [CrossRef] [Green Version]
- Alipour, F.; Scherer, R.C. Pulsatile airflow during phonation: An excised larynx model. J. Acoust. Soc. Am. 1995, 97, 1241–1248. [Google Scholar] [CrossRef]
- Oren, L.; Khosla, S.; Murugappan, S.; King, R.; Gutmark, E. Role of Subglottal Shape in Turbulence Reduction. Ann. Otol. Rhinol. Laryngol. 2009, 118, 232–240. [Google Scholar] [CrossRef] [PubMed]
- Alipour, F.; Scherer, R.C. Characterizing glottal jet turbulence. J. Acoust. Soc. Am. 2006, 119, 1063–1073. [Google Scholar] [CrossRef]
- Zhang, Z. Mechanics of human voice production and control. J. Acoust. Soc. Am. 2016, 140, 2614–2635. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- de Oliviera-Rosa, M.; Pereira, J.; Grellet, M.; Alwan, A. A contribution to simulating a three-dimensional larynx model using the finite element method. J. Acoust. Soc. Am. 2003, 114, 2893–2905. [Google Scholar] [CrossRef] [Green Version]
- Alipour, F.; Scherer, R.C. Flow separation in a computational oscillating vocal fold model. J. Acoust. Soc. Am. 2004, 116, 1710–1719. [Google Scholar] [CrossRef] [PubMed]
- Bae, Y.; Moon, Y.J. Computation of phonation aeroacoustics by an INS/PCE splitting method. Comput. Fluids 2008, 37, 1332–1343. [Google Scholar] [CrossRef]
- Larsson, M.; Müller, B. Numerical simulation of confined pulsating jets in human phonation. Comput. Fluids 2009, 38, 1375–1383. [Google Scholar] [CrossRef] [Green Version]
- Link, G.; Kaltenbacher, M.; Breuer, M.; Döllinger, M. A 2D finite-element scheme for fluid–solid–acoustic interactions and its application to human phonation. Comput. Methods Appl. Mech. Eng. 2009, 198, 3321–3334. [Google Scholar] [CrossRef]
- Thomson, S. Investigating coupled flow-structure-acoustic interactions of human vocal fold flow-induced vibration. J. Acoust. Soc. Am. 2015, 138, 1776. [Google Scholar] [CrossRef]
- Šidlof, P.; Zörner, S.; Hüppe, A. A hybrid approach to computational aeroacoustics of human voice production. Biomech. Model. Mechanobiol. 2015, 14, 473–488. [Google Scholar] [CrossRef]
- Jiang, W.; Zheng, X.; Xue, Q. Computational Modeling of Fluid–Structure–Acoustics Interaction during Voice Production. Front. Bioeng. Biotechnol. 2017, 5, 7. [Google Scholar] [CrossRef] [Green Version]
- Sváček, P.; Horáček, J. Finite element approximation of flow induced vibrations of human vocal folds model: Effects of inflow boundary conditions and the length of subglottal and supraglottal channel on phonation onset. Appl. Math. Comput. 2018, 319, 178–194. [Google Scholar] [CrossRef]
- Suh, J.; Frankel, S. Numerical simulation of turbulence transition and sound radiation for flow through a rigid glottal model. J. Acoust. Soc. Am. 2007, 121, 3728–3739. [Google Scholar] [CrossRef]
- Mihaescu, M.; Khosla, S.M.; Murugappan, S.; Gutmark, E.J. Unsteady laryngeal airflow simulations of the intra-glottal vortical structures. J. Acoust. Soc. Am. 2010, 127, 435–444. [Google Scholar] [CrossRef] [PubMed]
- Mihaescu, M.; Mylavarapu, G.; Gutmark, E.J.; Powell, N.B. Large Eddy Simulation of the pharyngeal airflow associated with Obstructive Sleep Apnea Syndrome at pre and post-surgical treatment. J. Biomech. 2011, 44, 2221–2228. [Google Scholar] [CrossRef]
- Schwarze, R.; Mattheus, W.; Klostermann, J.; Brücker, C. Starting jet flows in a three-dimensional channel with larynx-shaped constriction. Comput. Fluids 2011, 48, 68–83. [Google Scholar] [CrossRef] [Green Version]
- de Luzan, C.F.; Chen, J.; Mihaescu, M.; Khosla, S.M.; Gutmark, E. Computational study of false vocal folds effects on unsteady airflows through static models of the human larynx. J. Biomech. 2015, 48, 1248–1257. [Google Scholar] [CrossRef] [Green Version]
- Sadeghi, H.; Kniesburges, S.; Kaltenbacher, M.; Schützenberger, A.; Döllinger, M. Computational Models of Laryngeal Aerodynamics: Potentials and Numerical Costs. J. Voice 2018. [Google Scholar] [CrossRef] [PubMed]
- Schickhofer, L.; Malinen, J.; Mihaescu, M. Compressible flow simulations of voiced speech using rigid vocal tract geometries acquired by MRI. J. Acoust. Soc. Am. 2019, 145, 2049–2061. [Google Scholar] [CrossRef]
- Zörner, S.; Šidlof, P.; Hüppe, A.; Kaltenbacher, M. Flow and Acoustic Effects in the Larynx for Varying Geometries. Acta Acust. United Acust. 2016, 102, 257–267. [Google Scholar] [CrossRef]
- Yoshizawa, A.; Horiuti, K. A statistically-derived subgrid-scale kinetic energy model for the large-eddy simulation of turbulent flows. J. Phys. Soc. Jpn. 1985, 54, 2834–2839. [Google Scholar] [CrossRef]
- Nicoud, F.; Ducros, F. Subgrid-scale stress modelling based on the square of the velocity gradient tensor. Flow Turbul. Combust. 1999, 62, 183–200. [Google Scholar] [CrossRef]
- Lesieur, M.; Métais, O.; Comte, P. Large-Eddy Simulations of Turbulence; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Versteeg, H.K.; Malalasekera, W. An Introduction to Computational Fluid Dynamics: The Finite Volume Method; Pearson Education: London, UK, 2007. [Google Scholar]
- Ferziger, H. Direct and large eddy simulation of turbulence. Numer. Methods Fluid Mech. 1998, 16, 53–73. [Google Scholar]
- Clark, A.; Ferziger, H.; Reynolds, C. Evaluation of subgrid-scale models using an accurately simulated turbulent flow. J. Fluid Mech. 1979, 91, 1–16. [Google Scholar] [CrossRef]
- Leonard, A. Energy cascade in large-eddy simulations of turbulent fluid flows. In Advances in Geophysics; Elsevier: Amsterdam, The Netherlands, 1975; Volume 18, pp. 237–248. [Google Scholar]
- Smagorinsky, J. General circulation experiments with the primitive equations: I. The basic experiment. Mon. Weather Rev. 1963, 91, 99–164. [Google Scholar] [CrossRef]
- Šidlof, P. Large eddy simulation of airflow in human vocal folds. In Topical Problems of Fluid Mechanics 2015; Institute of Thermomechanics: Prague, Czech Republic, 2015; pp. 187–196. [Google Scholar]
- Scherer, R.; Shinwari, D.; De Witt, J.; Zhang, C.; Kucinschi, R.; Afjeh, A. Intraglottal pressure profiles for a symmetric and oblique glottis with a divergence angle of 10 degrees. J. Acoust. Soc. Am. 2001, 109, 1616–1630. [Google Scholar] [CrossRef]
- Agarwal, M.; Scherer, R.; Hollien, H. The false vocal folds: Shape and size in frontal view during phonation based on laminagraphic tracings. J. Voice 2003, 17, 97–113. [Google Scholar] [CrossRef]
- Pope, S.B. Turbulent Flows; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar] [CrossRef]
- Georgiadis, N.J.; Rizzetta, D.P.; Fureby, C. Large-eddy simulation: Current capabilities, recommended practices, and future research. AIAA J. 2010, 48, 1772–1784. [Google Scholar] [CrossRef]
- Jiang, X.; Lai, C.H. Numerical Techniques for Direct and Large-Eddy Simulations; CRC Press: Boca Raton, FL, USA; Taylor & Francis Group: Abingdon, UK, 2009. [Google Scholar]
- Fletcher, C.A. Fluid Dynamics: The Governing Equations. In Computational Techniques for Fluid Dynamics 2; Springer: Berlin/Heidelberg, Germany, 1991; pp. 1–46. [Google Scholar]
- Launchbury, D.R. Unsteady Turbulent Flow Modelling and Applications; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Jasak, H. Error Analysis and Estimation for the Finite Volume Method with Applications to Fluid Flows. Ph.D. Thesis, Imperial College of Science, Technology and Medicine, London, UK, 1996. [Google Scholar]
- Erath, B.; Plesniak, M. An investigation of asymmetric flow features in a scaled-up driven model of the human vocal folds. Exp. Fluids 2010, 49, 131–146. [Google Scholar] [CrossRef]
- Lodermeyer, A.; Becker, S.; Döllinger, M.; Kniesburges, S. Phase-locked flow field analysis in a synthetic human larynx model. Exp. Fluids 2015, 56. [Google Scholar] [CrossRef]
- Schoder, S.; Weitz, M.; Maurerlehner, P.; Hauser, A.; Falk, S.; Kniesburges, S.; Döllinger, M.; Kaltenbacher, M. Hybrid aeroacoustic approach for the efficient numerical simulation of human phonation. J. Acoust. Soc. Am. 2020, 147, 1179–1194. [Google Scholar] [CrossRef] [PubMed]
- Valášek, J.; Kaltenbacher, M.; Sváček, P. On the application of acoustic analogies in the numerical simulation of human phonation process. Flow Turbul. Combust. 2018, 102, 129–143. [Google Scholar] [CrossRef]
- Hardin, J.C.; Pope, D.S. An acoustic/viscous splitting technique for computational aeroacoustics. Theor. Comput. Fluid Dyn. 1994, 6, 323–340. [Google Scholar] [CrossRef]
- Hüppe, A. Spectral Finite Elements for Acoustic Field Computation (Measurement-, Actuator-, and Simulation-Technology). Ph.D. Thesis, Shaker Verlag GmbH, Düren, Germany, 2014. [Google Scholar] [CrossRef]
- Hüppe, A.; Grabinger, J.; Kaltenbacher, M.; Reppenhagen, A.; Dutzler, G.; Kühnel, W. A non-conforming finite element method for computational aeroacoustics in rotating systems. In Proceedings of the 20th AIAA/CEAS Aeroacoustics Conference, Atlanta, GA, USA, 16–20 June 2014; p. 2739. [Google Scholar]
- Story, B.H.; Titze, I.R.; Hoffman, E.A. Vocal tract area functions from magnetic resonance imaging. J. Acoust. Soc. Am. 1996, 100, 537–554. [Google Scholar] [CrossRef] [PubMed]
- Kaltenbacher, B.; Kaltenbacher, M.; Sim, I. A modified and stable version of a perfectly matched layer technique for the 3-d second order wave equation in time domain with an application to aeroacoustics. J. Comput. Phys. 2013, 235, 407–422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaltenbacher, M. Numerical Simulation of Mechatronic Sensors and Actuators: Finite Elements for Computational Multiphysics; Springer: Berlin, Germany, 2015. [Google Scholar]
- Kaltenbacher, M. OpenCFS—Open Source Finite Element Software for Multi-Physical Simulation. Available online: https://www.opencfs.org (accessed on 21 February 2021).
- Huang, S.; Li, Q. A new dynamic one-equation subgrid-scale model for large eddy simulations. Int. J. Numer. Methods Eng. 2010, 81, 835–865. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Boundary | ||
|---|---|---|
| Inlet | from flux, | 350 |
| 0, | ||
| Outlet | , | 0 |
| , | ||
| Vocal folds , | ||
| Fixed walls |
| Symbol | Meaning | Time [s] |
|---|---|---|
| closed divergent | 0.1900 | |
| closed convergent | 0.1927 | |
| open glottis | 0.1963 |
| Case | Turb. Modelling | SGS Model | Walltime |
|---|---|---|---|
| LAM | laminar | - | 27 days |
| OE | LES | One-Equation | 34 days |
| WALE | LES | WALE | 37 days |
| Case | |||||||
| LAM-u | 44.05 | 57.48 | 55.20 | 33.12 | 34.25 | 57.31 | 45.49 |
| OE-u | 38.34 | 55.13 | 47.79 | 15.33 | 28.94 | 40.88 | 35.76 |
| WALE-u | 44.06 | 56.86 | 53.52 | 20.03 | 33.42 | 48.29 | 42.15 |
| Case | |||||||
| LAM-i | 52.68 | 53.31 | 51.52 | 28.99 | 32.46 | 34.62 | 56.02 |
| OE-i | 42.07 | 57.76 | 46.08 | 15.24 | 28.49 | 29.70 | 43.95 |
| WALE-i | 47.69 | 59.45 | 51.88 | 19.86 | 34.13 | 35.96 | 58.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lasota, M.; Šidlof, P.; Kaltenbacher, M.; Schoder, S. Impact of the Sub-Grid Scale Turbulence Model in Aeroacoustic Simulation of Human Voice. Appl. Sci. 2021, 11, 1970. https://doi.org/10.3390/app11041970
Lasota M, Šidlof P, Kaltenbacher M, Schoder S. Impact of the Sub-Grid Scale Turbulence Model in Aeroacoustic Simulation of Human Voice. Applied Sciences. 2021; 11(4):1970. https://doi.org/10.3390/app11041970
Chicago/Turabian StyleLasota, Martin, Petr Šidlof, Manfred Kaltenbacher, and Stefan Schoder. 2021. "Impact of the Sub-Grid Scale Turbulence Model in Aeroacoustic Simulation of Human Voice" Applied Sciences 11, no. 4: 1970. https://doi.org/10.3390/app11041970