This paper defines a question difficulty estimation as determining the optimal difficulty level
of a given question, where
is a set of difficulty levels. It assumes that a question consists of a questionary sentence
q and a set of information components
. An information component can be a passage associated with
q, candidate answers in multiple-choice QAs, or a video-clip description in video QAs. Then, the difficulty estimation becomes a classification problem in which a classifier
parameterized by
determines
given
q and
A. According to
Figure 1,
q is “Why did Mami experience culture shock in Japan?” and the passage “A Japanese student ...” and five candidate answers become the elements of information component set,
A. Then, the classifier
f determines the question difficulty given
q and
A.
The proposed model of which architecture is given in
Figure 2 implements
with two kinds of attention modules. It takes
q and
A as its input and encodes them using a pre-trained language model. Then, it represents the bi-directional relationships between
q and every
with the dual multi-head attention and the relationship among
’s with the transformer encoder. Indeed, the representation of the relationships are accomplished in two steps, since the relationship among
’s can be expressed after the relationships between
q and every
are all represented. After that, it predicts the difficult level of
q using the relationships.
3.1. Encoding Question Components
The proposed model first encodes the questionary sentence
q and a set of information components
into vector representations. As the first step of vector representation,
q and all
’s are expressed in the standard format for BERT [
32] using special tokens of [CLS] and [SEP] (This paper assumes that all components in a question are represented in a text form. The question difficulty estimation for the QAs that require analysis of a video or audio stream is out of the scope of this paper). For instance, when
q is “Why did Mami experience culture shock in Japan?”, it is expressed as “[CLS] why did ma ##mi experience culture shock in japan ? [SEP]”. Then, the formatted
q and
’s are encoded into vector representations using the BERT-Base. That is,
where
and
are the pooled representations corresponding to the [CLS] token of
q and
respectively, while
and
represent the sequence representations of the whole tokens in
q and
. This paper uses only
and
in the following steps because the individual tokens deliver more information than the special token in solving QA tasks.
3.2. Representing Relationships Using Attention Model
The attention model is responsible for capturing the relationships between q and A, and the model consists of two attention modules: a dual multi-head co-attention and a transformer encoder based on the multi-head attention. The proposed model first represents the relationships between q and every directly since the questionary sentence q is a key factor in the question-and-answering. Thus, all information components should be represented in accordance with the questionary sentence. However, these representations do not express the relationship among ’s sufficiently. Although the inter-information among ’s is reflected indirectly and slightly through the relationships between q and ’s, a direct inter-information relationship plays an important role in estimating the question difficulty and thus the second attention module is designed to consider the inter-information relationship directly.
In order to identify the bi-directional relationship between
q and
(
), the proposed model adopts the dual multi-head co-attention (DUMA) [
18]. DUMA is composed of two multi-head attentions where each multi-head attention captures a single directional attention representation. Thus, it captures both representations from
q to
and from
to
q. Then, it fuses these two representations to obtain a final unified representation. That is, the relationship between
q and
, denoted as
, is obtained by applying DUMA to the representations of
and
in Equation (
1).
where
denotes a multi-head attention and
is a function for fusing two representations dynamically.
The multi-head attention
is an attention mechanism to obtain a representation by paying attention jointly to the information from different representations at different positions [
33], where the attention is obtained by applying the scaled dot-product attention several times in parallel and then concatenating the results of the attention. Formally, the multi-head attention maps a sequence of query
and a set of key-value pairs of
and
to a representation by
where
,
,
, and
are all learnable parameters. Here,
represents the scaled dot-product attention. It is a weighted sum of the values of which weight is determined by the dot product of the query with all the keys. Thus, it is defined as
where
is a key dimensionality that works for a scaling factor.
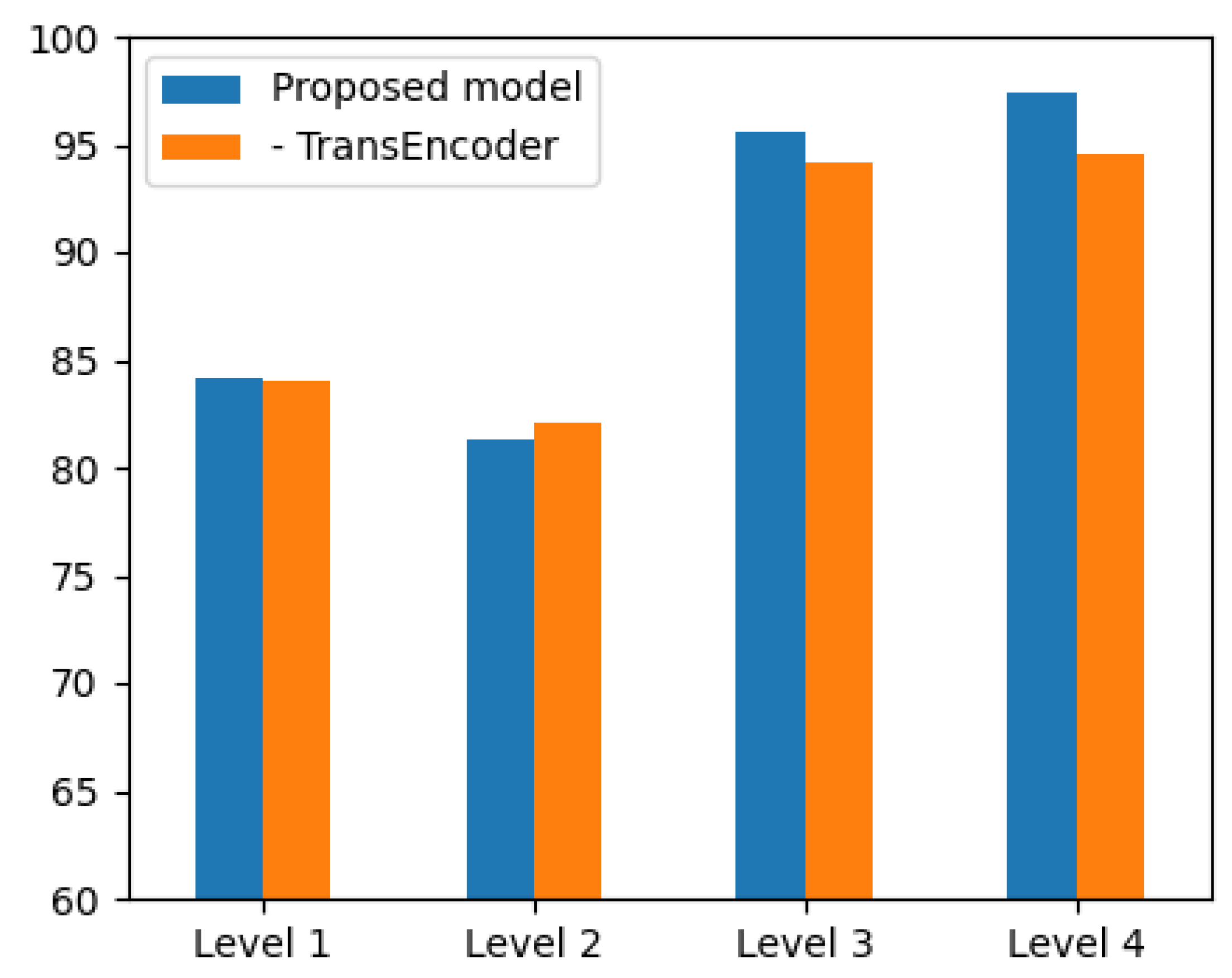
Among several candidates of
function in Equation (3), the performance of using the concatenation is higher than that of using the element-wise summation according to our experiments below (see
Section 4.2). This result complies with the results of the previous study by Zhu et al. [
18], and thus the concatenation is used as a fuse function in this paper.
After obtaining
n’s by applying Equation (3) to
and every
, the proposed model applies a transformer encoder based on the multi-head attention [
33] to them in order to capture inter-information relationship directly. For this, all
’s are concatenated as
, and then the transformer encoder is applied to
to produce the direct representation
of inter-information relationship. That is,
where
denotes the transformer encoder. The transformer encoder is a stack of transformer blocks. The
l-th transformer block is composed of two layers of a multi-head attention (MHA) and a feed-forward network (FFN). That is, the two layers of
and
are
where
is a layer normalization [
34], and
and
are the outputs of the
l-th and
-th transformer block, respectively. The output of the 0-th transformer block is set as
. That is,
.
Note that forces every to consider all other ’s (), since it is based on the self-attention of which query is , and both key and value are other ’s. As a result, gets able to reflect the inter-information relationship. Therefore, becomes the representation that does not reflect only the relationships between the questionary sentence q and information components , but also the inter-relationship among all pairs of information components.
3.3. Difficulty Prediction and Implementation
After all relationships between
q and
A are represented as
where
is the hidden dimension of
TransEncoder in Equation (
4), the difficulty of a question is determined by a MLP classifier of which input is
. The classifier first summarizes
into a single dense representation
. There are several operators for this summarization such as max-pooling, average-pooling, and attention. This paper adopts max-pooling for summarizing
because it is known to be effective in obtaining representative features [
35] and shows higher performance than others in our preliminary experiments. After obtaining the final representation
, the MLP predicts the final difficulty level
of
q. The proposed model is trained to minimize the standard cross-entropy loss.
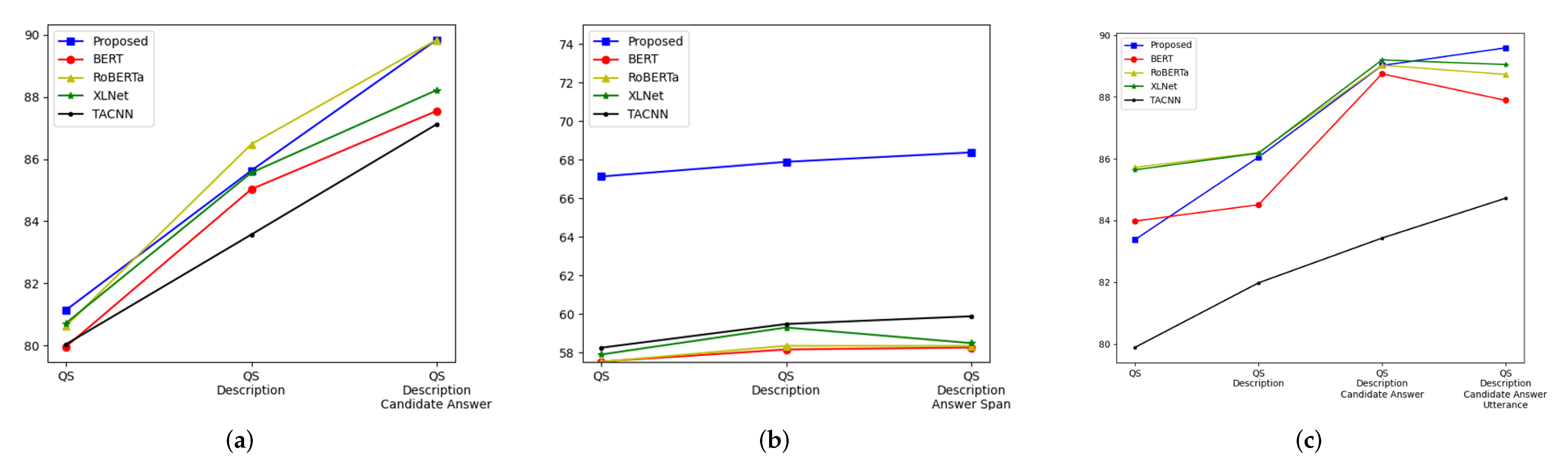
The proposed model can be applied to most well-known question answering tasks. In the machine reading comprehension tasks such as SQuAD, a question is composed of a questionary sentence, an associated passage, and an answer span. The tasks meet our problem formulation in that the questionary sentence is q, the associated passage is , and the answer span is . Thus, the proposed model can be applied to this type of tasks without any change. In the multiple-choice QAs such as RACE, a question is composed of a questionary sentence, an associated passage, and multiple answer candidates. The difference between the multiple-choice QAs and the machine reading comprehension is that the multiple-choice QAs have multiple answer candidates instead of a single answer. To encode the multiple candidate answers, the proposed model concatenates all candidate answers into one sentence. That is, it regards the multiple candidate answers as one information component. The rest is the same as the machine reading comprehension.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}