In this section, we introduce the details of our dataset and preprocessing. It is followed by experimental settings and results. After comparing and verifying the proposed model performance, we analyze the results with the visualization of attention maps and feature importance.
4.1. Dataset
We use 2.5 million units of ship and weather data from 19 types of containers. The data are collected by the container sensors from 2016 to 2019. We use ship spec data from Lloyd List Intelligence. The nominal
twenty-foot equivalent unit TEU of containers is from 4000 to 13,000. A dependent variable,
fuel oil consumption (FOC), is acquired from the main diesel engine of the containers. Before cleansing the data, we select the features that we can use. However, more than half of the features consist of many missing values. This disturbs the model learning and it is difficult to replace the missing values. To avoid these problems, we exclude unusable features. The feature draft is divided into four parts (i.e., forward, starboard, port, and aft) depending on the position. We integrate four draft features into the draft as their values are slightly different. Through the exclusion and integration feature process, 19 features were left for use. In reference to the work in [
9], we also divide the features into several categories (i.e., navigational status, formulation, performance, and weather data).
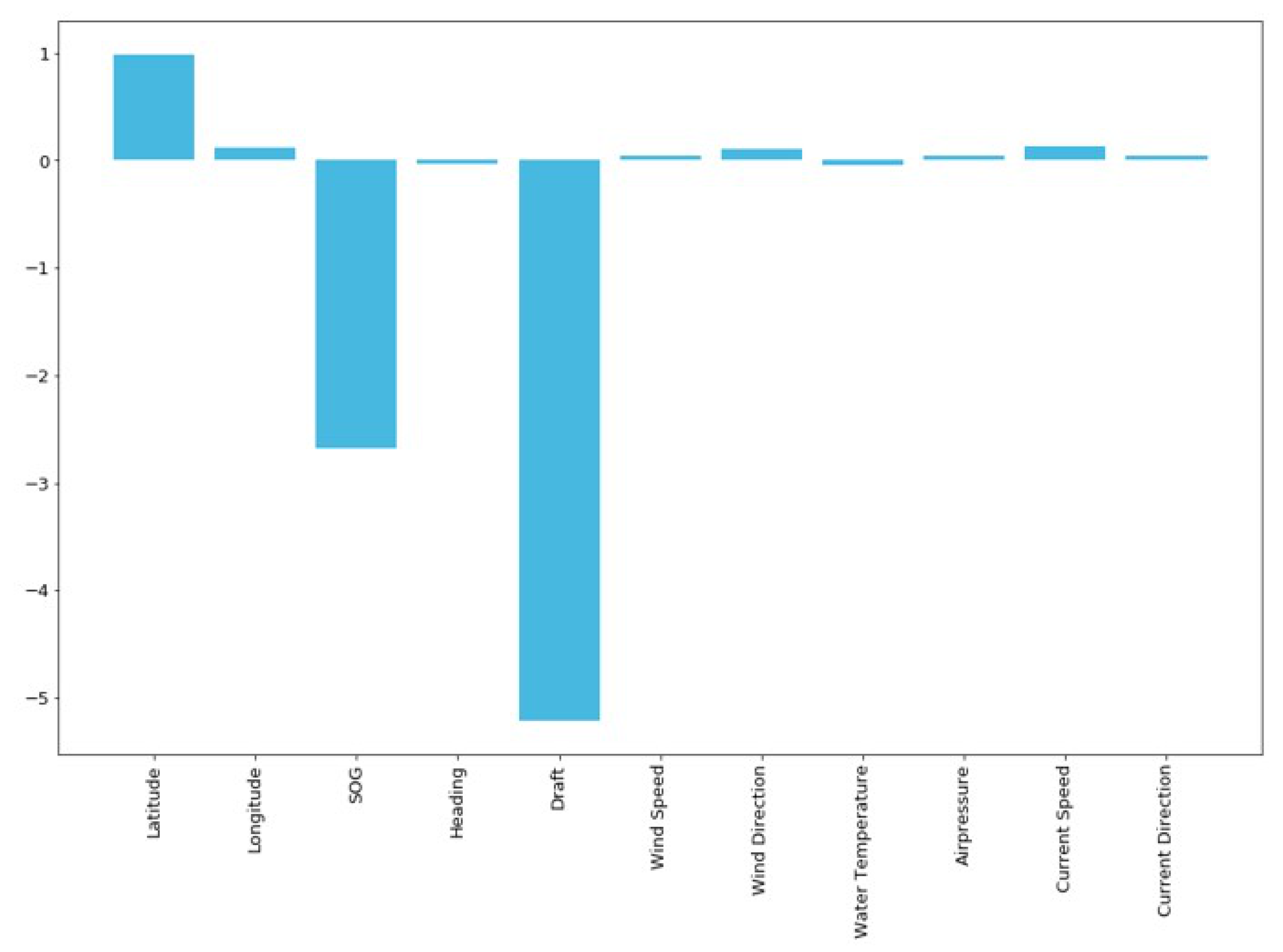
Table 1 presents the list of features. In the learning process, we remove the vessel code feature to generalize the model regardless of the vessel types.
We set two criteria for removing abnormal data and imputation of missing data since there are still missing and abnormal data. First, we detect abnormal data from the criteria. The detected data is defined as removal candidates. If they satisfy the imputation criteria, we replace them with other values. The criteria for removal of abnormal data is as follows:
- (1)
Illogical values. Some values that are not possible to exist are defined as removal candidates.
- (a)
Out of range values in latitude, longitude, and direction features.
- (b)
Negative values in FOC, speed over groud (SOG), and draft features.
- (c)
Meaningless symbols in features.
- (2)
Abnormal values. Some values are possible to exist, but strongly out of the distribution. We define them as removal candidates.
- (a)
Zero values in FOC, SOG, and draft.
- (b)
Strongly out of the distribution in SOG and draft features.
- (c)
Sequential abnormal data through moving average.
By applying the removal criteria, we can define abnormal data as removal candidates. We subsequently check the possibility of imputation on the removal candidates and missing data based on the imputation criteria. The imputation criteria are as below:
Sequential values. Ship data are sequential during sailings. In the sequence, if abnormal or missing data are between other normal data, we replace the data with the moving average value.
Static values. If the data are static like the water temperature feature, we use the hourly or daily average value for imputation.
We replace the removal candidates and missing data based on the criteria. However, if the data are dynamic like the direction feature or there is no normal data nearby in a sequence, we remove them. With the removal and imputation processes, the datasets are approximately 2 million. We could only apply imputation in some cases since the malfunction of the sensing systems tends to last for a certain period of time. We use the processed data in the experiments.
4.5. Experimental Results
We conduct two experiments in this subsection. First, we determine the hyperparameters in the base models. Besides, we verify the importance of the sequential property by comparing MLP and sequence models. As attention modules need the backbone model, we use the sequence model with the best settings of the previous sequence models. We add attention modules on the sequence models and compare the performance based on attention types. Simultaneously, we verify the performance of attention modules by comparing them with sequence models without attention modules. In the experiments, MAE and RMSE show the error between the prediction values and real FOC.
Base Experiment.
Table 2 shows the prediction performance of the base models, MLP, LSTM, GRU, and their bi-directional models. As mentioned for the sequential property of ship data, sequence models achieve better performance than MLP. Besides, BiGRU shows the best performance among the other base sequence models. Based on the performance of the models with the different hyperparameters, we select the hyperparameters to use for further experiments.
Attention Experiment. After the experiments of base models, we compared each attention type on sequence models. Our attentions are TA, FA, ENS, and others are AB and SA.
Table 3 presents the prediction performance of each attention on the sequence models. Generally, it records better performance besides AB when we apply attention. For SA, we notice the improvement of performance except BiGRU. For our models, at least one of TA and FA outperforms SA and sequence models without attention modules. Besides, ENS achieves the best performance. The MAE of ENS with BiLSTM is 0.3, which indicates that the prediction error at a point in time is 0.3 tons/hour. Considering the range of the FOC is from 0 to 10, the prediction is approximate to the real FOC.
As there is a significant improvement from TA, FA, and ENS in BiLSTM relative to the other methods, we select BiLSTM as the backbone model. From the above experiments, we observe the improvement of the performance by capturing the ship data properties. It is more useful to consider the sequential property than applying MLP. TA, FA, and ENS designed to capture data properties are effective to predict fuel consumption accurately.
4.6. Further Experiments
We verified the performance of the proposed methods from the previous experiments. However, ENS performance is dependent on TA and FA performance. In this subsection, we evaluate and verify the methods to improve TA and FA performance. We expect it to increase the performance of ENS. Last, we apply our attention modules on the recent backbone model, Transformer [
22]. By adopting the other backbone model, we also verify the compatibility of the proposed attention modules. For further experiments, we keep the settings that we found the most proper from the previous experiments.
Sequence Length Experiment. For the previous experiments, we fixed the sequence length
as a default value. However, it is necessary to verify the results depending on different sequence lengths, since the information for sequence models depends on the sequence length. We set
and compared the performance of each attention model. As shown in
Table 4, the model performance decreases as the sequence length increases. In contrast, the attention type ENS achieves the best performance regardless of sequence lengths. For our dataset and models,
is suitable and we keep the setting for the other experiments.
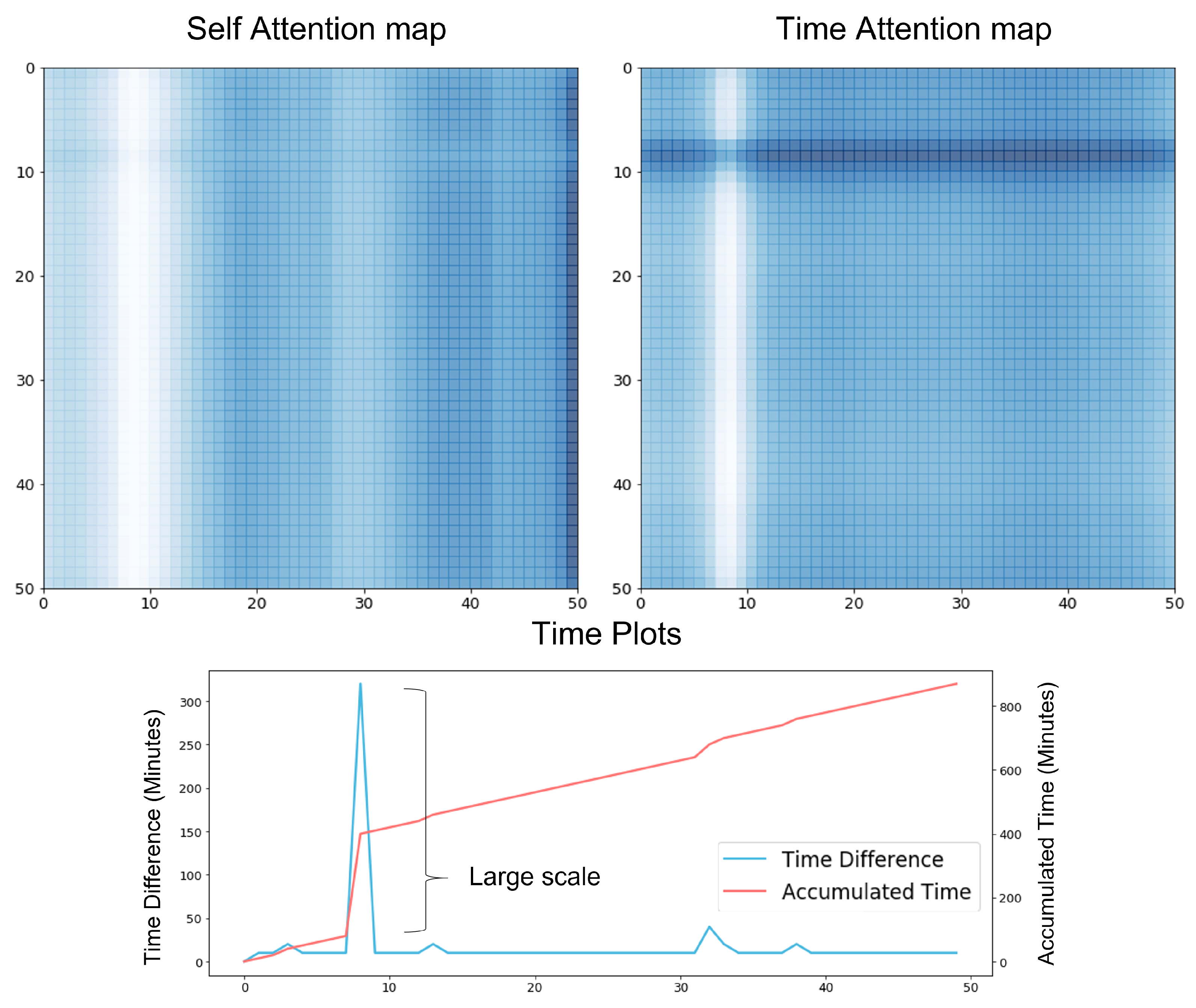
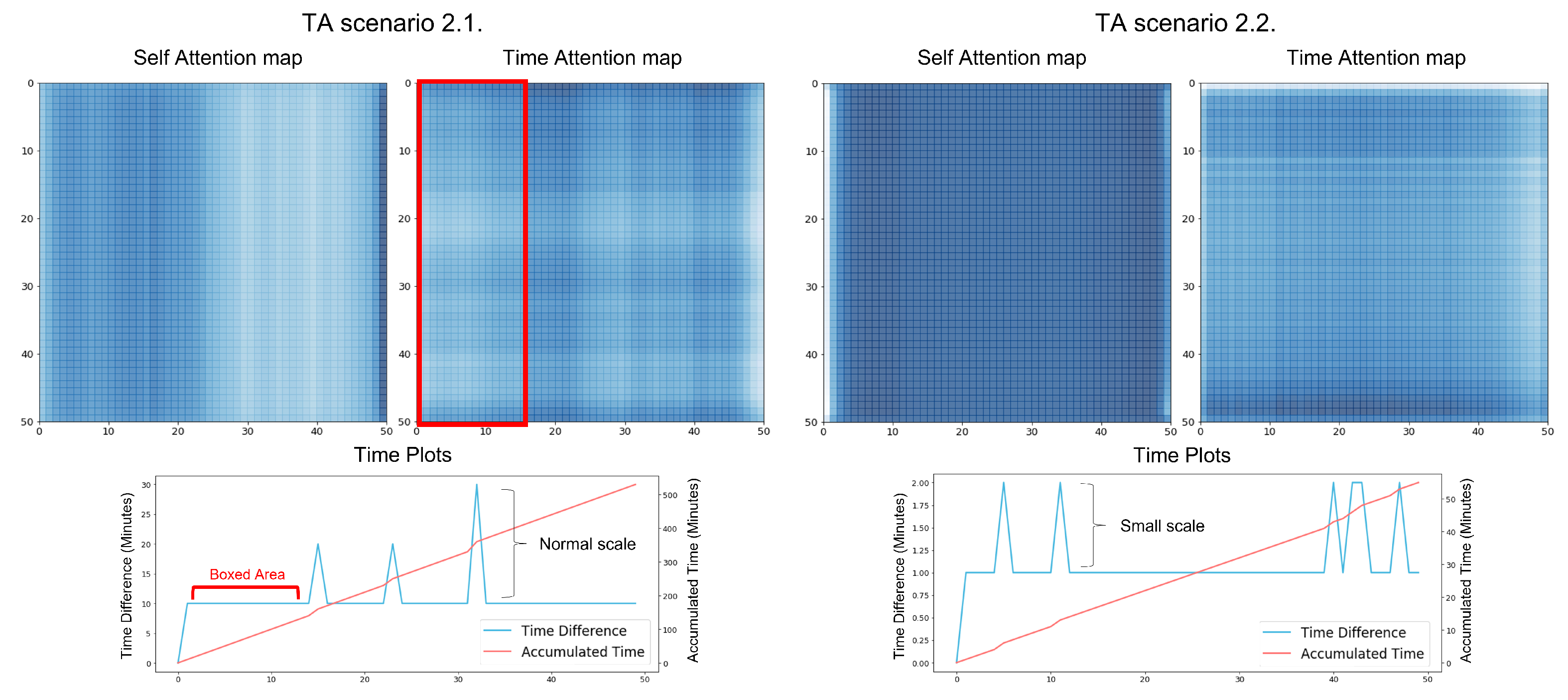
Time Masking Experiment. In attention modules, we can also adjust the amount of information by the masking technique. We considered the time-based masking technique [
27,
29] for TA. This masking technique forces attention to consider only information satisfying the masking standard. For our data, the range of time interval accumulation is from 0 to 1500. The time interval accumulation refers to the accumulating time difference between right before data in the sequence. Based on the range, we define a hyperparameter masking time,
. TA uses only the data for which the time interval accumulation is under
.
None indicates that we did not adopt the masking technique and it is equal to
. As shown in the time masking of
Figure 5, if
, TA ignores the data over
and uses only the data under
to apply the attention.
Table 5 shows a slight improvement compared to TA without
, when
is 800. TA achieves better performance when considering the sequence data within a certain period of time. In addition, there is a tendency to decrease the model performance when
decreases. This is because TA uses only a small portion of data in sequence as the
reduces.
Total Similarity Masking Experiment. FA captures important data in sequence through the total feature similarity
. Unlike time,
has no specific range. Based on the idea of local attention [
20], we used bottom
masking, on the hyperparameter
. It means that we ignored the bottom
data based on the
values in the sequence when applying the attention. The
masking of
Figure 5 ignores the five numbers of data with the lowest
TS values when
.
Table 6 shows that there is slight improvement when we ignore only 0% to 20% data. Similar to the results of the masking TA experiment, the performance of FA decreases as the portion of ignoring data increases.
Time Function Experiment. In
Section 3.2, we handled function representation
used for making time importance. We used the sigmoid function with the learnable gradient and constant. For this experiment, we verified the performance of TA based on other functions, such as linear, quadratic, cubic, and exponential functions.
Table 7 presents the summary of the results. Nonlinear functions are more suitable for estimating time importance.
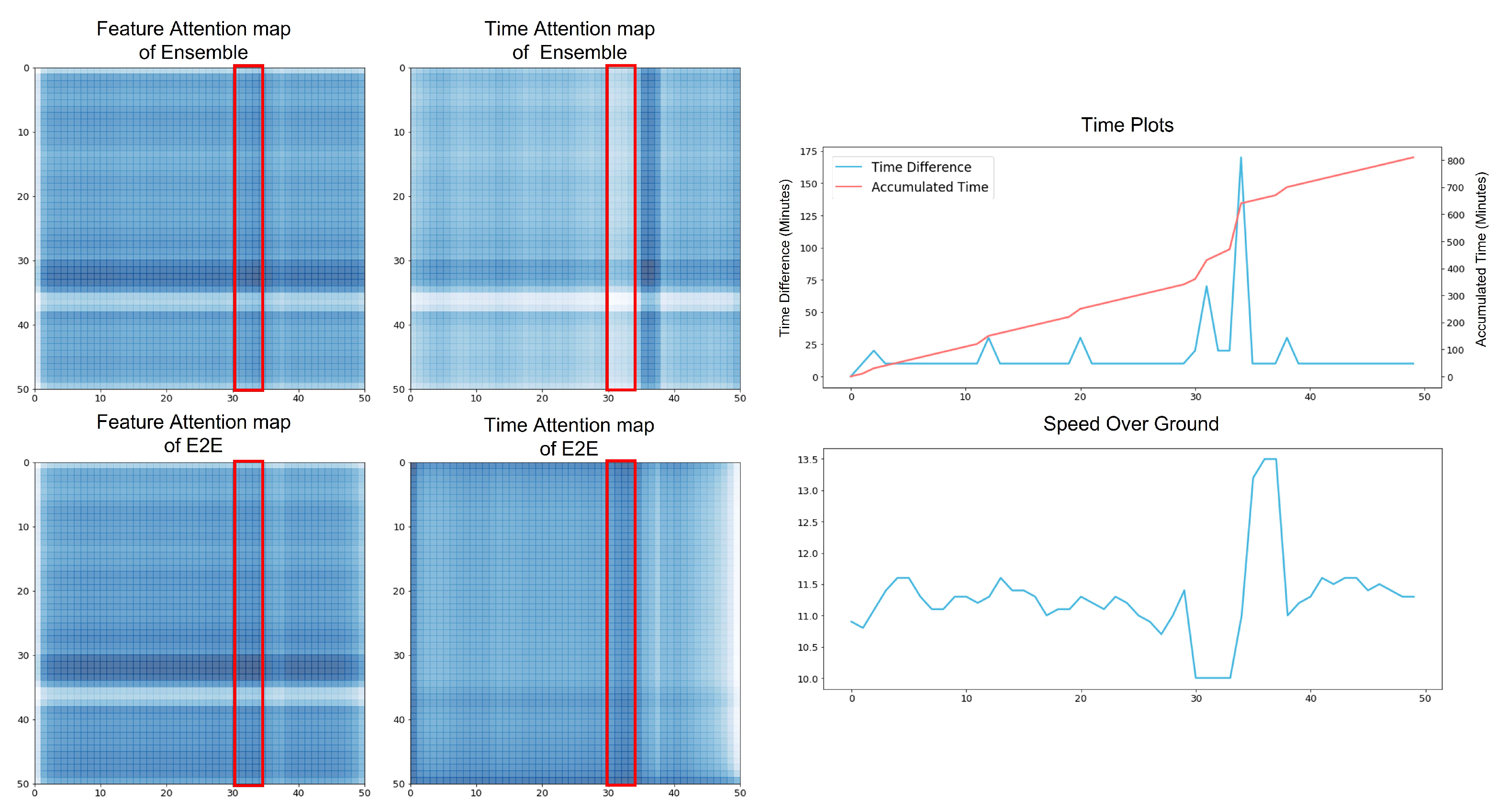
Ensemble Combination Experiment. From the previous result
Table 5,
Table 6 and
Table 7, we observed the performance depending on the masking and function types. We designed combinations of TA and FA to determine the optimal ENS in the searching space. We selected the top of the two models from each previous result. We also included naive TA and FA, which used the sigmoid function for TA and did not apply any masking. As shown in
Figure 6, we found the effect of ENS depending on different functions and masking. In
or
, it generally proves better performance than others. On the other hand, the performance decreases as
increases. Finally, it achieves the best performance when we combined TA with
,
, and FA with
. It is also the same compared to all other experimental results.
Module Compatibility Experiment. The previous experiments show the results when the backbones are RNNs. In this experiment, we use Transformer [
22] as the backbone model to verify the compatibility of the proposed attention modules and the effect of the backbone. As the number of features is limited, we adopt the 2 and 4 layers of Transformer with small hidden sizes. In addition, we apply the proposed attention modules instead of the Transformer’s attention module.
Table 8 shows the results of Transformer depending on different hyperparameters. The single Transformer with four layers shows the best performance when the hidden size is 32. When we compare the results with the previous experiment,
Table 3, Transformer outperforms some of RNNs. However, the single Transformer does not get to the performance of the RNNs with the proposed attention modules. As the data are numeric, the embedding for representation in Transformer is not effective. In addition, the limited number of features is the other reason for the low performance of Transformer. Even in this situation, we notice the improvement of the performance, when we adopt the proposed attention modules, especially for the ENS. When we apply ENS, Transformer-4 with 64 hidden sizes shows the best performance including the results of the previous experiments. From this experiment, we verified the compatibility of the proposed attention modules. In the vessel domain, TA, FA, and ENS can replace the previous attention modules and exhibit better performance by considering ship data properties.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}