
Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection



Abstract
:1. Introduction
2. Current State of Object Detection and Classification
2.1. Object Detection
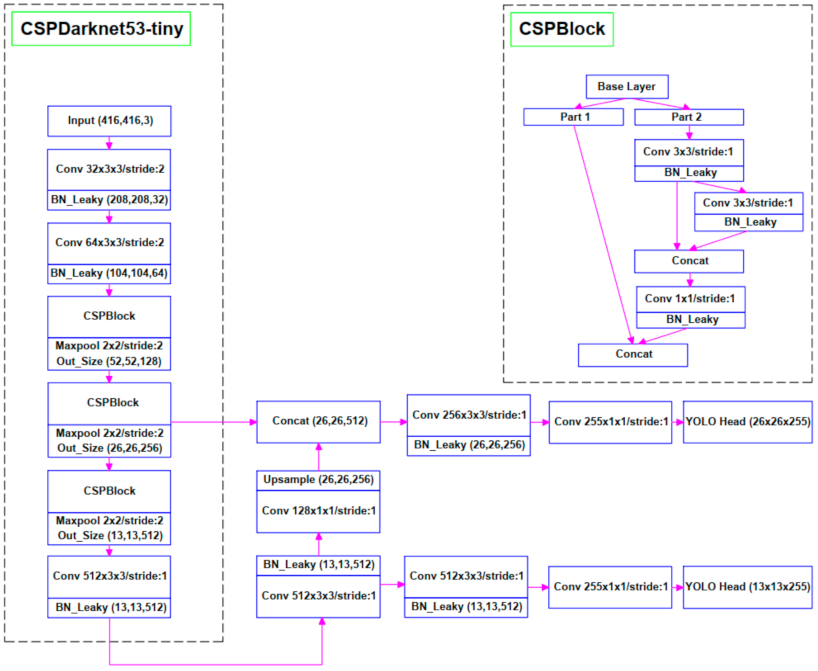
2.2. YOLO Architectures
3. Dataset
4. Methodology
5. Results
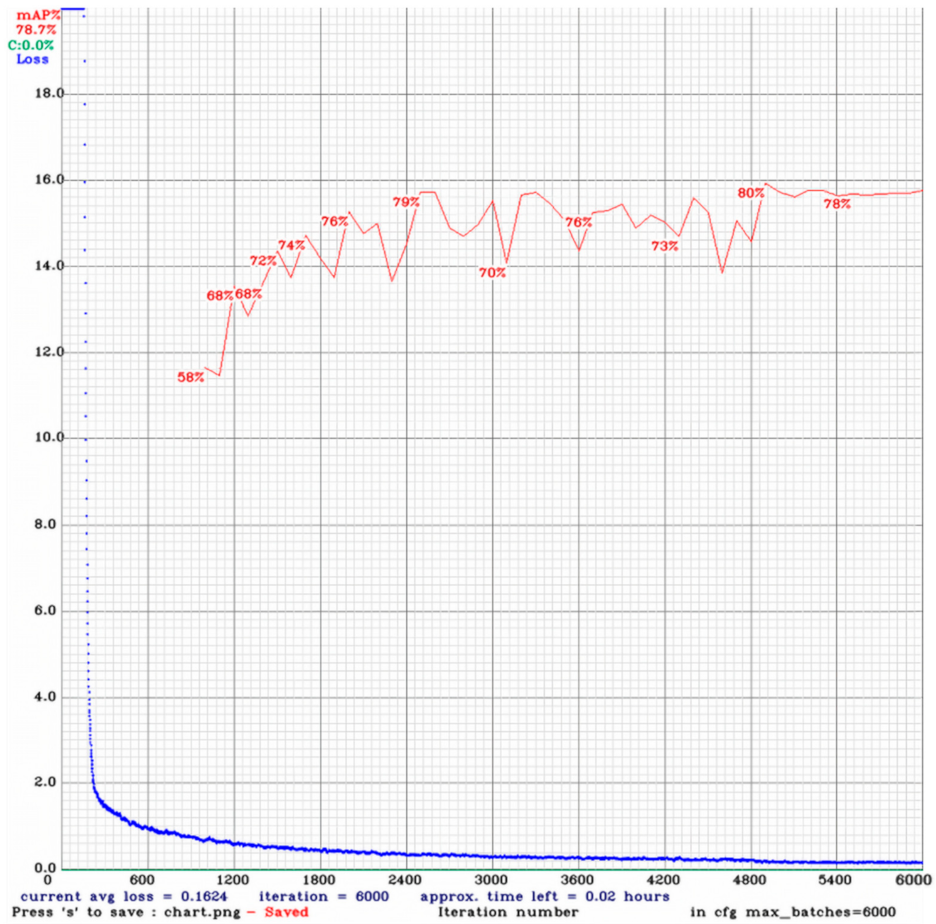
5.1. Performance Comparison between YOLOv4 and YOLOv4-Tiny
5.2. Performance of YOLOv5s
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Harvey, J.; Al-Qadi, I.L.; Ozer, H.; Flintsch, G. (Eds.) Pavement, Roadway, and Bridge Life Cycle Assessment 2020. In Proceedings of the International Symposium on Pavement. Roadway, and Bridge Life Cycle Assessment 2020, LCA 2020, Sacramento, CA, USA, 3–6 June 2020; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- She, X.; Hongwei, Z.; Wang, Z.; Yan, J. Feasibility study of asphalt pavement pothole properties measurement using 3D line laser technology. Int. J. Transp. Sci. Technol. 2021, 10, 83–92. [Google Scholar] [CrossRef]
- Wang, H.W.; Chen, C.H.; Cheng, D.Y.; Lin, C.H.; Lo, C.C. A real-time pothole detection approach for intelligent transportation system. Math. Probl. Eng. 2015, 2015, 869627. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Shen, Z.; Li, P. Crack detection of track plate based on YOLO. In Proceedings of the 12th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 14–15 December 2019; pp. 15–18. [Google Scholar]
- Cord, A.; Chambon, S. Automatic road defect detection by textural pattern recognition based on AdaBoost. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 244–259. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Jazizadeh, F.; Masri, S.F.; Becerik-Gerber, B. Unsupervised approach for autonomous pavement-defect detection and quantification using an inexpensive depth sensor. J. Comput. Civ. Eng. 2013, 27, 743–754. [Google Scholar] [CrossRef]
- Luo, L.; Feng, M.Q.; Wu, J.; Leung, R.Y. Autonomous pothole detection using deep region-based convolutional neural network with cloud computing. Smart Struct. Syst. 2019, 24, 745–757. [Google Scholar]
- Silva, L.A.; Sanchez San Blas, H.; Peral García, D.; Sales Mendes, A.; Villarubia González, G. An architectural multi-agent system for a pavement monitoring system with pothole recognition in UAV images. Sensors 2020, 20, 6205. [Google Scholar] [CrossRef]
- Fernandez-Llorca, D.; Minguez, R.Q.; Alonso, I.P.; Lopez, C.F.; Daza, I.G.; Sotelo, M.Á.; Cordero, C.A. Assistive intelligent transportation systems: The need for user localization and anonymous disability identification. IEEE Intell. Transp. Syst. Mag. 2017, 9, 25–40. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Malta, A.; Mendes, M.; Farinha, T. Augmented Reality Maintenance Assistant Using YOLOv5. Appl. Sci. 2021, 11, 4758. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Ho, T.T.; Kim, T.; Kim, W.J.; Lee, C.H.; Chae, K.J.; Bak, S.H.; Choi, S. A 3D-CNN model with CT-based parametric response mapping for classifying COPD subjects. Sci. Rep. 2021, 11, 1–12. [Google Scholar] [CrossRef]
- Park, S.S.; Tran, V.T.; Doan, N.P.; Hwang, K.B. Evaluation of Damage Level for Ground Settlement Using the Convolutional Neural Network. In CIGOS 2021, Emerging Technologies and Applications for Green Infrastructure; Springer: Singapore, 2021; pp. 1261–1268. [Google Scholar]
- Ho, T.T.; Park, J.; Kim, T.; Park, B.; Lee, J.; Kim, J.Y.; Choi, S. Deep learning models for predicting severe progression in COVID-19-infected patients: Retrospective study. JMIR Med. Inform. 2021, 9, e24973. [Google Scholar] [CrossRef]
- Nguyen DL, H.; Do DT, T.; Lee, J.; Rabczuk, T.; Nguyen-Xuan, H. Forecasting damage mechanics by deep learning. CMC Comput. Mater. Contin. 2017, 61, 951–977. [Google Scholar]
- Do, D.T.; Lee, J.; Nguyen-Xuan, H. Fast evaluation of crack growth path using time series forecasting. Eng. Fract. Mech. 2019, 218, 106567. [Google Scholar] [CrossRef]
- Dinh, V.Q.; Munir, F.; Azam, S.; Yow, K.C.; Jeon, M. Transfer learning for vehicle detection using two cameras with different focal lengths. Inf. Sci. 2020, 514, 71–87. [Google Scholar] [CrossRef]
- Dinh, V.Q.; Nguyen, T.D.; Nguyen, P.H. Stereo Domain Translation for Denoising and Super-Resolution Using Correlation Loss. In Proceedings of the 7th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 26–27 November 2020; pp. 261–266. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 11–14 October 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A real-time object detection method for constrained environments. IEEE Access 2019, 8, 1935–1944. [Google Scholar] [CrossRef]
- Du, Y.; Pan, N.; Xu, Z.; Deng, F.; Shen, Y.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2020, 22, 1659–1672. [Google Scholar] [CrossRef]
- Rahman, A.; Patel, S. Annotated Potholes Image Dataset. Kaggle. 2020. Available online: https://www.kaggle.com/chitholian/annotated-potholes-dataset (accessed on 21 November 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction | Predicted as Positive | Predicted as Negative | |
|---|---|---|---|
| Actual | |||
| Positive | True Positive (TP) | False Negative (FN) | |
| Negative | False Positive (FP) | True Negative (TN) | |
| Metric | Precision (%) | Recall (%) | |
|---|---|---|---|
| Model | |||
| YOLOv4 | 84 | 74 | |
| YOLOv4-tiny | 84 | 73 | |
| Model | mAP (%) |
|---|---|
| YOLOv4 | 77.7 |
| YOLOv4-tiny | 78.7 |
| YOLOv5s | 74.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.-S.; Tran, V.-T.; Lee, D.-E. Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection. Appl. Sci. 2021, 11, 11229. https://doi.org/10.3390/app112311229
Park S-S, Tran V-T, Lee D-E. Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection. Applied Sciences. 2021; 11(23):11229. https://doi.org/10.3390/app112311229
Chicago/Turabian StylePark, Sung-Sik, Van-Than Tran, and Dong-Eun Lee. 2021. "Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection" Applied Sciences 11, no. 23: 11229. https://doi.org/10.3390/app112311229