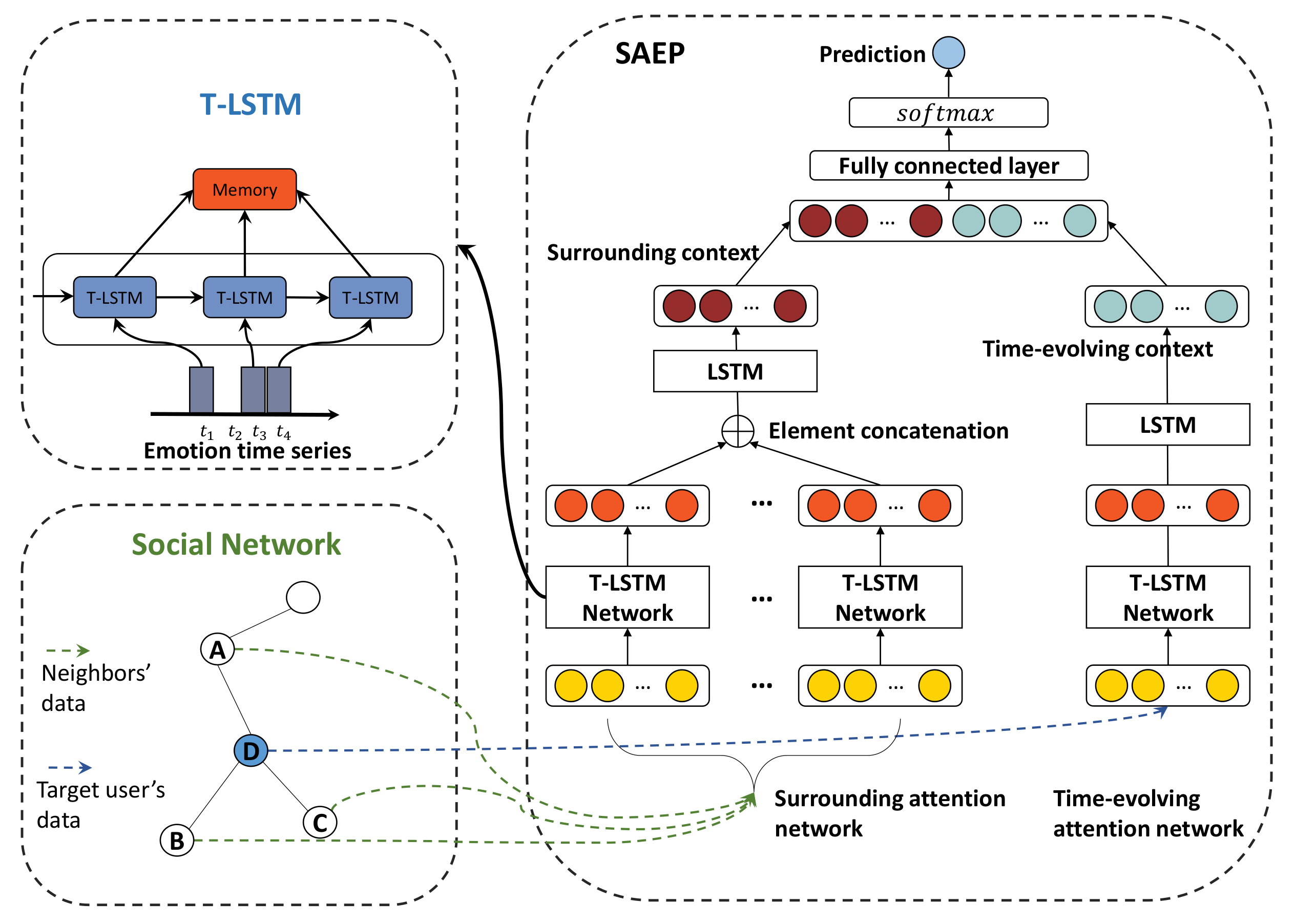
5.2. T-LSTM Network
LSTM [
42] was designed to capture long- and short-term dependencies while overcoming the vanishing gradient problem. However, a standard LSTM network implicitly assumes that the time intervals between the elements of an input sequence are the same, which means that LSTM has difficulty in handling irregular time series data with missing values.
In recent years, to use LSTM network to capture information in irregular series data, more innovative solutions have been proposed [
43]. One method involves imputing data to make the time intervals between the elements of the input sequence to be regular. Based on this idea, many studies have estimated missing data by treating imputed values as trainable variables. However, the limitation of this method lies in the fact that the estimated missing data are evidently different from reality.
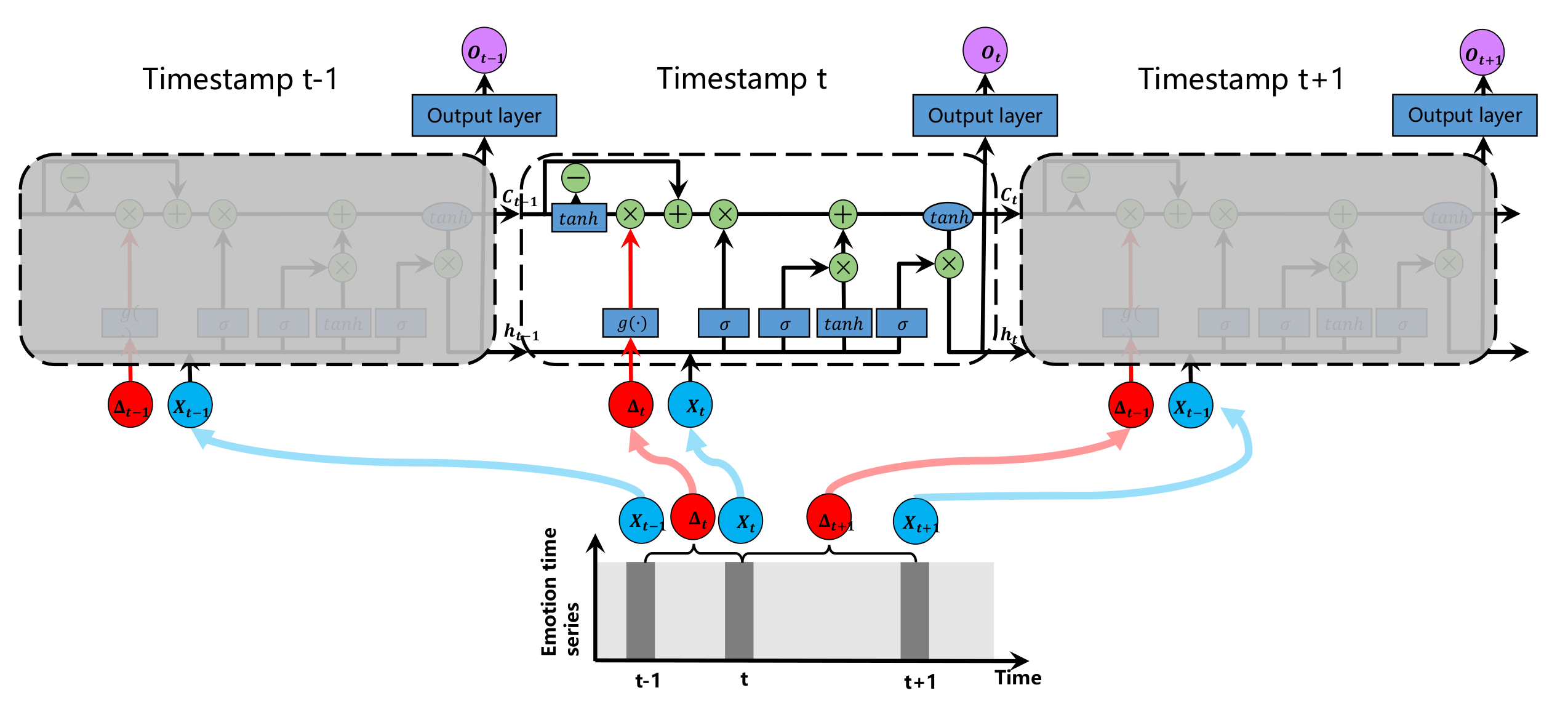
Another method to solve the time irregularity is to adjust the memory unit of LSTM by using the short-term memory discount. This method of using time gaps to adjust memory is called T-LSTM [
44]. The T-LSTM architecture is presented in
Figure 6. Blue boxes denote networks, and green circles indicate point-wise operators. T-LSTM takes time series and time intervals as input. The major component of the T-LSTM architecture is the subspace decomposition applied to the memory of the previous time stamp, which decomposes the previous memory into long-term and short-term components, and uses the time interval (
) to discount the short-term influences.
First, using the memory of the previous moment, the short-term memory is obtained through the network. Note that this decomposition operation is data-driven, and its parameters are learned at the same time as the rest of the network parameters by back-propagation. After the short-term memory
is computed, considering that the effect of short-term memory is also related to the time gap, a time decay function
is used to calculate the weight and adjust short-term memory to obtain the discounted short-term memory
. Finally, to compose the adjusted previous memory back
, the complement subspace of the long-term memory
is combined with the discounted short-term memory. The detailed mathematical expressions of the T-LSTM network in
Figure 6 are given by Equations (
3)–(
8) [
44].
where
is the previous hidden state.
and
represent the current and previous cell states, respectively.
is the time interval, and
is a heuristic decay function, so the larger the value of
, the less the effect of short-term memory. Different types of
can be chosen according to the application requirements. For example,
is preferred for less time-consuming datasets, and
can be selected for more time-consuming datasets. After the experimental analysis, a better performance of
is used in the proposed SAEP model.
5.3. Time-Evolving Attention Network
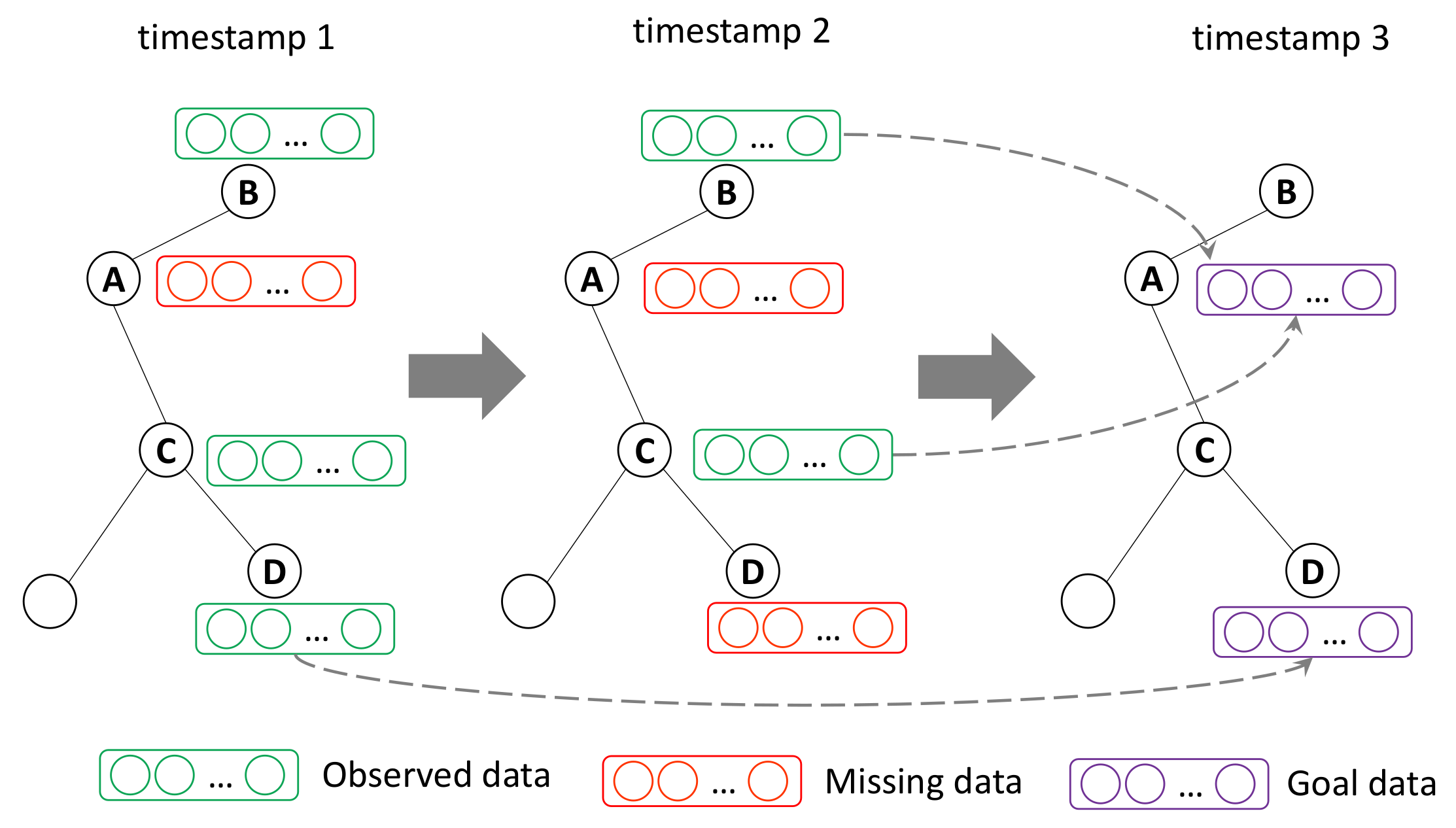
An important factor that should be considered for individual emotion prediction is the time-evolving influence, that is, how a user’s historical behaviors and individual emotional states can be related to the individual future emotional states. To capture this temporal correlation of users’ emotional states, a memory-based attention network is constructed in the proposed model, called time-evolving attention network.
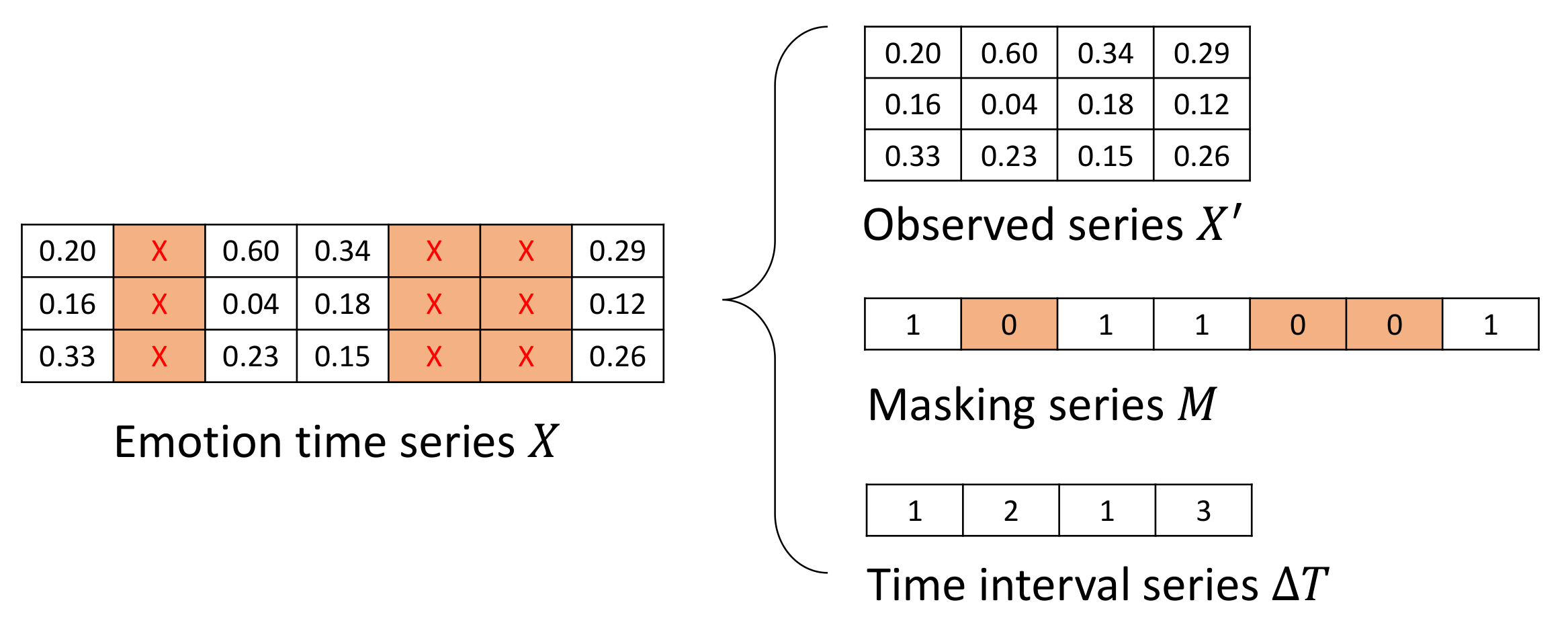
Given a user
, their emotion time series
X is used to extract the observed series
and time interval series
. In the encoding phase, the goal is to use a T-LSTM network to capture information in an irregular time series. A T-LSTM network is used to encode the information of the user’s individual emotional change trend in the form of a T-LSTM hidden state, which takes the observed series
and time interval series
as input data. The iterative process is expressed by Equation (
9).
where
and
respectively are cell adjusted state and hidden state.
Many approaches capture contextual information in a time series. The most popular method is based on the encoder–decoder architecture consisting of two RNNs and an attention mechanism that aligns the target to the source tokens [
45]. The attention mechanism used in these methods calculates the attention context by analyzing the encoder and decoder at each step. However, such calculations are expensive. Britz et al. [
46] present a memory-based attention approach, and they demonstrate the efficiency of their model in experiments. In this paper, a memory-based attention approach is used to efficiently compute the time-evolving context.
During encoding, a fixed-size memory representation
is computed, where
Z is a hyperparameter that indicates the number of time-evolving context vectors in the SAEP model, and
D is the dimensionality of the cell states. A score vector
is predicted at each encoding time step
u, and the memory representation
C in Equation (
10) as a linear combination of the encoder states weighted by a score vector
.
where
is a parameter matrix in
.
represents position encoding, which ensures that the context information learned is different. More specifically, because
is not necessarily different from
, the predictions of the context vectors may be symmetric. To enable the model to learn different context information, the position encodings enforce the first few context vectors
to focus on the start of the series, and the last few context vectors
to focus on the end of the series. To obtain the position encoding
, it is necessary to compute a constant matrix
L. Mathematically, each element of
L can be expressed as shown in Equation (
12).
where
denotes the context vector index, and
U is the maximum series length across all emotion time series.
In the proposed SAEP model, a standard LSTM network is used as the decoder, which can employ memory representations to reconstruct the original emotion time series. Similar to the encoding phase, a score vector
is computed at each decoding step. Then, the time-evolving context vector
is finally obtained by using Equation (
13), which is a linear combination of memory representations weighted by a score vector
(Equation (
14)).
where
denotes the current hidden state of the decoder, and
represents the learned parameter matrix. To obtain the current hidden state of the decoder
and the current cell state
, with the previous hidden state
, the previous cell state
, and earlier output
as the input data for the decoder,
is calculated using Equation (
15).
Algorithm 1 outlines the calculation process for the time-evolving context. First, in the encoding stage, the encoder processes the observed series to obtain the current encoder hidden state
. Then, a fixed-size memory representation
C is obtained, which is a linear combination of the encoder states
weighted by the score vector
. Finally, in the decoding phase, the memory representation
C is weighted by the score vector
to obtain the time-evolving context
.
| Algorithm 1: Time-evolving context vector calculation |
| Input: Observed series , Time interval series , Number of time-evolving context vector Z, Dimensionality of the cell states D |
| Output: Time-evolving context |
| 1: //Encoding phase |
| 2: Obtain encoder hidden state according to Equation (9). |
| 3: Compute position encoding matrix L by Equation (12); |
| 4: Compute score vector according to Equation (11). |
| 5: for z from 1 to Z do |
| 6: Compute fixed-size memory representation by using Equation (10). |
| 7:end for |
| 8: //Decoding phase |
| 9: Obtain decoder hidden state by using Equation (15). |
| 10: Calculate score vector according to Equation (14). |
| 11: Compute time-evolving context by using Equation (13); |
5.4. Surrounding Attention Network
Another important factor is the influence of the social network environment, that is, how neighbor individual emotional states influence each other. In this section, the surrounding attention network, a memory-based attention network similar to the time-evolving attention network, is used to explore the influence of neighboring individual emotional states.
Given a specific user
, the emotion time series set of their neighbors
is denoted by
. Then, the collection of neighbors’ observed series
, and the set of time interval series of neighbors
are obtained. For each neighbor
, a T-LSTM network encodes their individual emotion time series with the observed series
and the time interval series
as the input data, and obtains the set of encoder’s hidden states
by the means of following Equation (
16).
where
and
are the hidden state and cell-adjusted state of user
, respectively. It is important that all parameters in the surrounding attention network are shared by all neighbors.
In the encoding step, the set of neighbors’ memory representations
is updated, the element
is a fixed-size memory representation of the neighbor
, where
Z is the number of time-evolving context vectors, and
D is the size of the cell states. First, a score vector
is obtained by predicting the
Z scores at each encoding step. The memory representation
in Equation (
17) is then calculated as a weighted sum over a score vector
(Equation (
18)).
where
denotes a parameter matrix, and
is a vector of position encodings that can make the learning attention context different.
was calculated using Equation (
12). Note that in the surrounding attention network,
is shared by all neighbors.
The decoding phase of the surrounding attention network is aimed at obtaining the surrounding context vector
. There are slight differences from the calculation of time-evolving context vector in the
Section 5.3, the memory representations of the neighbors are used as input, rather than the fixed-size memory representation of a single user. Therefore, the neighbors’ memory representations
are concatenated, called surrounding memory representation
.
To compute the surrounding context vector
, a score vector
is predicted at each decoding step similarly. The surrounding context vector,
(Equation (
19)) is a linear combination of the rows in the surrounding memory representation
weighted by using a Score vector
in Equation (
20).
where
is the current hidden state of the decoder, and
is a learned parameter matrix. Similarly, the decoder current hidden state
and the current cell state
are computed by using Equation (
21) and taking the previous hidden state
, the previous cell state
, and earlier output
as input data:
Algorithm 2 shows the calculation process for the surrounding context. Initially, for each neighbor
, the fixed-size memory representation
is computed. Subsequently, the memory representations of all the neighbors are concatenated to obtain the surrounding memory representation
. Then, the surrounding memory representation
is weighted by the score vector
to obtain the surrounding context
.
| Algorithm 2: Surrounding context vector calculation |
| Input: The set of observation series , The set of time interval series , Number of time-evolving context vector Z, Dimensionality of the cell states D |
| Output: Surrounding context vector |
| 1: //Encoding phase |
| 2: for each neighbor do |
| 3: Obtain encoder hidden state according to Equation (16); |
| 4: Compute position encoding matrix L by using Equation (12); |
| 5: Compute score vector according to Equation (18); |
| 6: for z from 1 to Z do |
| 7: Compute fixed-size memory representation by Equation (17); |
| 8: end for |
| 9: end for |
| 10: Concatenate the neighbors’ memory and obtain surrounding memory representation ; |
| 11: //Decoding phase |
| 12: Obtain decoder hidden state by using Equation (21); |
| 13: Calculate score vector according to Equation (20); |
| 14: Compute surrounding context vector by using Equation (19);
|
The typical attention mechanism used in previous approaches generates a new attention context at each decoding step. In this model, instead of accessing the encoder state at each encoder step, the SAEP model only need to obtain the pre-computed fixed-size memory representation during encoding, which leads to a smaller computational complexity.
5.5. Learning and Prediction
The goal of the present work is to use information from online social networks and time-evolving data to predict future individual emotions. Therefore, the surrounding context vector
and the time-evolving context vector
are concatenated. Then, concatenation
O is sent to the full connection layer and pass through softmax. The implementation can be expressed by Equations (
22) and (
23), respectively:
where
denotes the weight matrix of the fully connected layer. The output
of the softmax layer is the probability distribution of the final individual emotion category, where the individual emotion category with the highest probability is considered as the individual emotion prediction label. Consequently, the total loss
is expressed as follows:
where
N denotes the number of users in the network, and
D is the dimensionality of the emotion vector.
and
are the predicted and actual emotion vector elements, respectively.
represents the elements of the masking series.
In the model training phase, SAEP model keeps track of the latest hidden state and all outputs. The last hidden state of the network as the first hidden state of the decoder. A hybrid input strategy is used to feed the data into the feed encoder to speed up the convergence of the model and reduce overfitting. In particular, for some emotion vectors, the actual emotion vector is used as the next input data, if not missing data; otherwise, the decoder’s estimate will be used as the next input data. For the missing emotion vector, the proposed model directly considers the estimated value of the decoder as an alternative value.
Well-trained models can be used to predict individual emotions. Similar to the learning stage, the user’s original individual emotion time series and the neighboring individual emotion time series are processed into the encoder, and obtain the surrounding memory representation and the individual memory representation. In the decoding stage, when an element is not missing, the original individual emotion vector is given; otherwise, the estimated vector is given in order to use as much information as possible from the original emotion time series.
Algorithm 3 summarizes the training and prediction algorithms for SAEP.
| Algorithm 3: Training and prediction algorithm for SAEP |
| Input: Social network , The set of emotion time series , Number of time-evolving context vector Z, Dimensionality of the cell states D, The number of samples in each batch, The number of epoch |
| Output:Emotion label |
| 1: Initializing the network structure parameters; |
| 2: for for numbers of training epochs do |
| 3: for numbers of iteration times do |
| 4: draw a mini-batch of sequences X and their corresponding neighbors’ context sequence sets ; |
| 5: //forward pass to encoder network |
| 6: Compute surrounding context vector ; |
| 7: Compute time-evolving context vector ; |
| 8: Concatenate surrounding context and time-evolving context by using Equation (22); |
| 9: Predict emotion by using Equation (23); |
| 10: Compute the loss function according to Equation (24). |
| 11: //backward pass |
| 12: Compute gradients; |
| 13: Update parameters; |
| 14: end for |
| 15: end for |
| 16: for user in G do |
| 17: Compute surrounding context vector ; |
| 18: Compute time-evolving context vector ; |
| 19: Concatenate surrounding context and time-evolving context by using Equation (22); |
| 20: Predict emotion by using Equation (23); |
| 21: end for |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}