1. Introduction
Pile foundations are used to transmit construction loads deep into the ground in order to ensure structure stability [
1,
2]. Furthermore, computing the bearing capacity of piles is essential when designing economic and safe geotechnical structures [
3]. To date, numerous approaches have been conceived for the sake of creating alternative methods and techniques that contain numerical, experimental, and analytical approaches aiming at predicting the bearing capacity of piles [
4,
5,
6]. Among the most frequently used methods is the Cone Penetration Test (
CPT), known for producing accurate results in a variety of situations [
7,
8]. This is probably due to the fact that
CPT-based methods have been modeled in harmony with the
CPT results, which were proven to estimate more effective different geotechnical properties, and make more precise pile capacity predictions [
6]. Other semi-empirical methods have been widely utilized, such as Meyerhof’s formula, which could yield an acceptable pile-bearing capacity [
4]. On the other hand, the High-Strain Dynamic Load Test (
HSDLT) and the Static Load Test (
SLT) have been employed considerably for predicting the pile-bearing capacity [
9]. The
HSDT is preferable to the
SLT, because it operates with a faster, more advanced, and economic technology [
2]. This quality supports its paramount importance addressed by the American Standards Test Methods to standardize the
HSDT method [
1]. The literature on bearing capacity values revealed a relatively close accuracy in both the
HSDT and the
SLT [
1]. Momeni et al. [
10] added that
HSDT is faster and more economic compared to SLT, but it generally requires several
HSDT tests for each project to obtain a reliable result [
11]. Hence, increasing the number of
HSDT tests is extremely undesirable since it may increase the total project budget. Moreover, other empirical researchers have proposed traditional methods for estimating the bearing capacity [
12,
13,
14,
15]. The quality of easiness and common usage has made these methods very important. However, determining the bearing capacity of bored and driven piles by means of the aforementioned methods is found to be time-consuming and costly [
16]. This is probably due to the complex behavior of piles, heterogeneity of the soil around piles, material and shape of piles, and their installation. Accordingly, all the proposed methods/models in the literature yielded ineffective predictions [
17]. On the other hand, currently, due to emerging new easy-to-use performance software such as PLAXIS, utilizing finite element analysis for which the system is discretized into a number of meshes to obtain axial capacity is of interest [
18]. For this reason, numerical methods based on the finite element approach have recently become well-known for the evaluation of bearing capacity, yielding effective results [
19,
20]. Recently, the application of some new advanced techniques, namely “artificial intelligence (
AI)” or “machine learning (
ML)”, has witnessed a spectrum of interest, and they provided exceptional results in solving several issues by learning from the available data [
21,
22].
Subsequently, the use of machine-learning methods to predict pile-bearing capacity has witnessed considerable development since the early 1990s [
21,
22,
23,
24]. Several studies are now able to estimate the pile-bearing capacity with a higher degree of precision in comparison to traditional methods. Among the fundamental research dealing with the pile-bearing capacity, Nawari et al. have used one hidden layer of the
ANN model by investigating a database consisting of 25 test data. The chosen input parameters included the
SPT-N values and geometrical properties. The
ANN model efficiently predicted the pile-bearing capacity compared to traditional methods [
25]. Furthermore, Mahnesh has predicted the pile-bearing capacity by using Support Vector Machines and Generalized Regression Neural Network with an input layer containing dynamic stress-wave data [
26]. He concluded that the Generalized Regression Neural Network was the best model with a high correlation coefficient (0.977). In addition, Milad et al. have developed an effective model based on Artificial Neural Network, genetic programming, and linear regression methods to predict the bearing capacity of piles by learning from 100 samples. They utilized the Flap number, basic properties of the surrounding soil, pile geometry, and pile-soil friction angle as an input layer. The suggested
ANN model has better stability compared to the other methods [
27]. Jahed et al. used hybrid
PSO–ANN to predict the bearing capacity of rock-socketed piles, by taking into consideration soil length to socket length ratio, total length to diameter ratio, uniaxial compressive strength, and standard penetration test. The proposed
PSO–ANN model has demonstrated its efficiency since it produced a high correlation coefficient (R = 0.9685) [
1]. Moayedi et al. have used
ANFIS, GP, and
SA–GP for modeling a database consisting of 50 tests. The chosen input parameters included the pile length, pile cross-sectional area, hammer weight, pile set, and drop height. The
SA–GP model efficiently predicted the pile-bearing capacity compared to other methods [
28]. Shaik et al. have predicted the pile-bearing capacity by using
ANFIS and
ANFIS–GMDH–PSO with an input layer containing
CPT and pile loading test results [
29]. They have proven that the metaheuristic hybrid
ANFIS–GMDH–PSO model is the best one, with a high correlation coefficient (0.998) [
29]. Harandizadeh et al. have used hybrid
MLP–GWO and
ANFIS–GWO to predict the bearing capacity of piles from the input layer, including pile area, pile length, flap number, average cohesion, and friction angle, average soil-specific weight, and average pile-soil friction angle. The proposed
MLP–GWO model has demonstrated that its efficiency yielded a high correlation coefficient (
R = 0.991) [
30].
Table 1 summarizes more than ten studies that have used machine-learning models to predict the pile-bearing capacity.
According to the authors’ knowledge, previous studies have been limited mostly to the use of
ANN, ANFIS, and
SVM methods for predicting the pile-bearing capacity, although recent studies have shown that other techniques could have yielded more effective and accurate results [
35,
36,
37]. Furthermore, they assessed the predictive capability of suggested models depending on only one split to check the data learning validity. Consequently, the ability of their proposed model to overcome over-fitting and under-fitting problems cannot be assured. Moreover, the majority of published papers have proposed machine-learning models in the form of mathematical equations, which are hard to duplicate in future studies. Admittedly, this practice has very little value for other researchers and civil engineers in the field. Conveniently, to overcome these limitations, investigators have presented their optimal models in the form of a programmed interface or a simple script by a well-known programming language such as Python or Matlab for generating the proposed model. This will make it available to anyone interested in the problem of modeling regardless of their proficiency level.
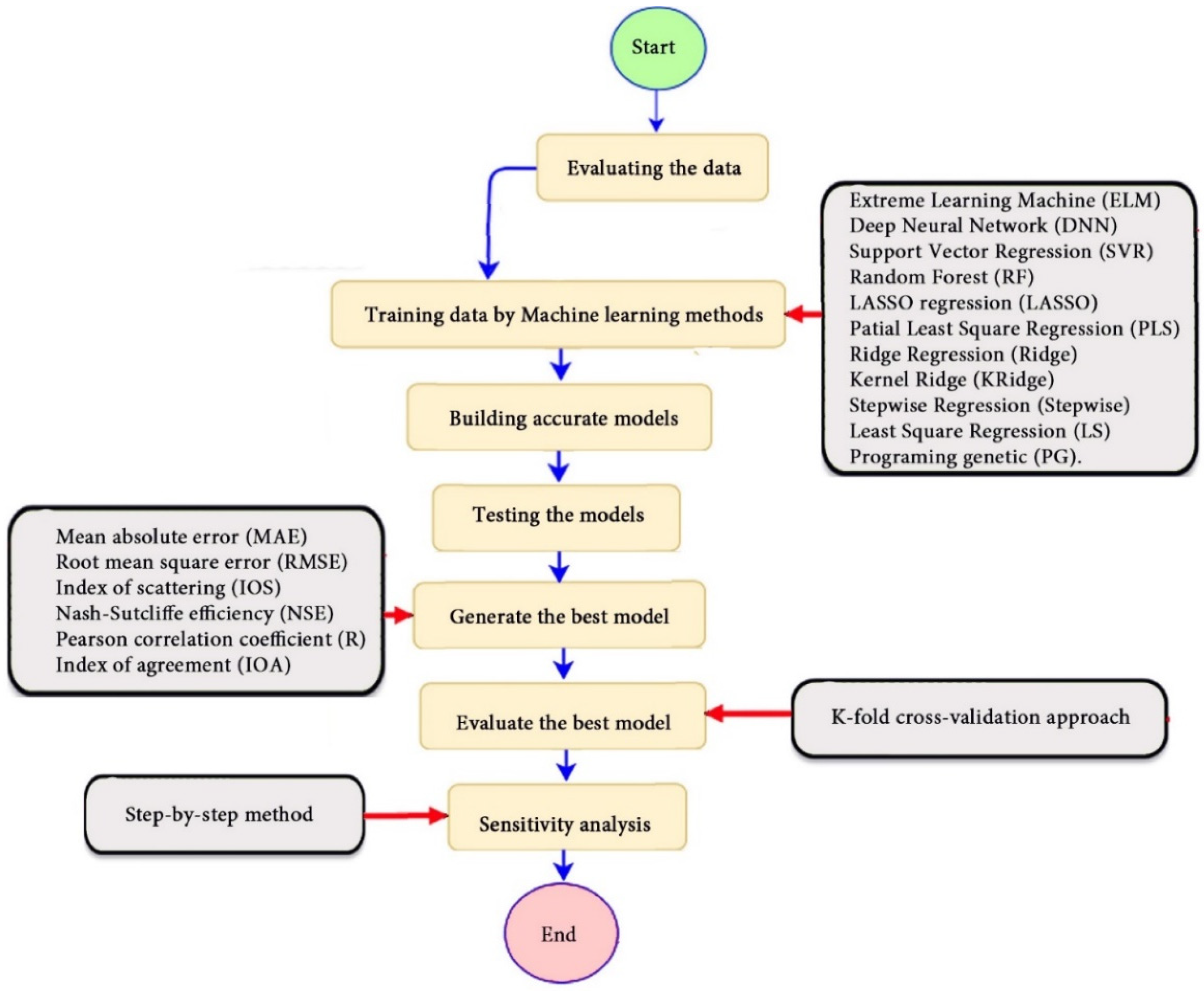
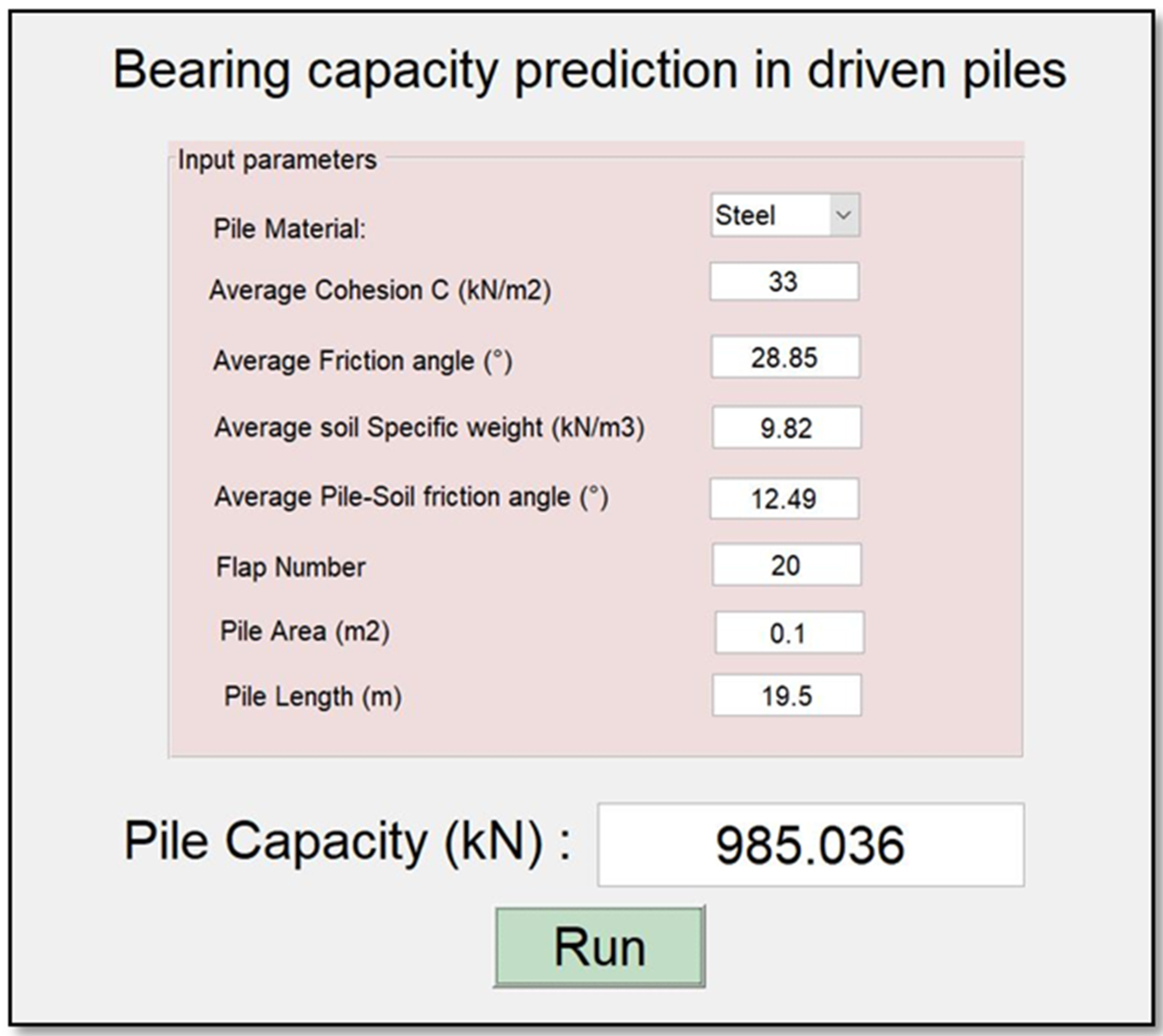
The current study contributes to providing a new alternative model for predicting the pile-bearing capacity based on 12 advanced machine-learning methods, which are applied for the first time for this aim. Furthermore, a high-performance method to estimate the generalization capability of the learning model, and to check the validity of the model for other cases, has been used, namely “K-fold cross-validation analysis”. Finally, in order to treat the hard usage problem of machine-learning models in future studies, the proposed optimal model was used afterwards to develop a GUI public interface. Consequently, the suggested “BeaCa2021” interface is very handy and easy-to-use by civil engineers and researchers, by offering plenty of benefits such as reliability, easiness, and lowering the budget used to predict the pile-bearing capacity from relevant and easily obtained parameters without the need to operate expensive in situ tests.
4. Discussion
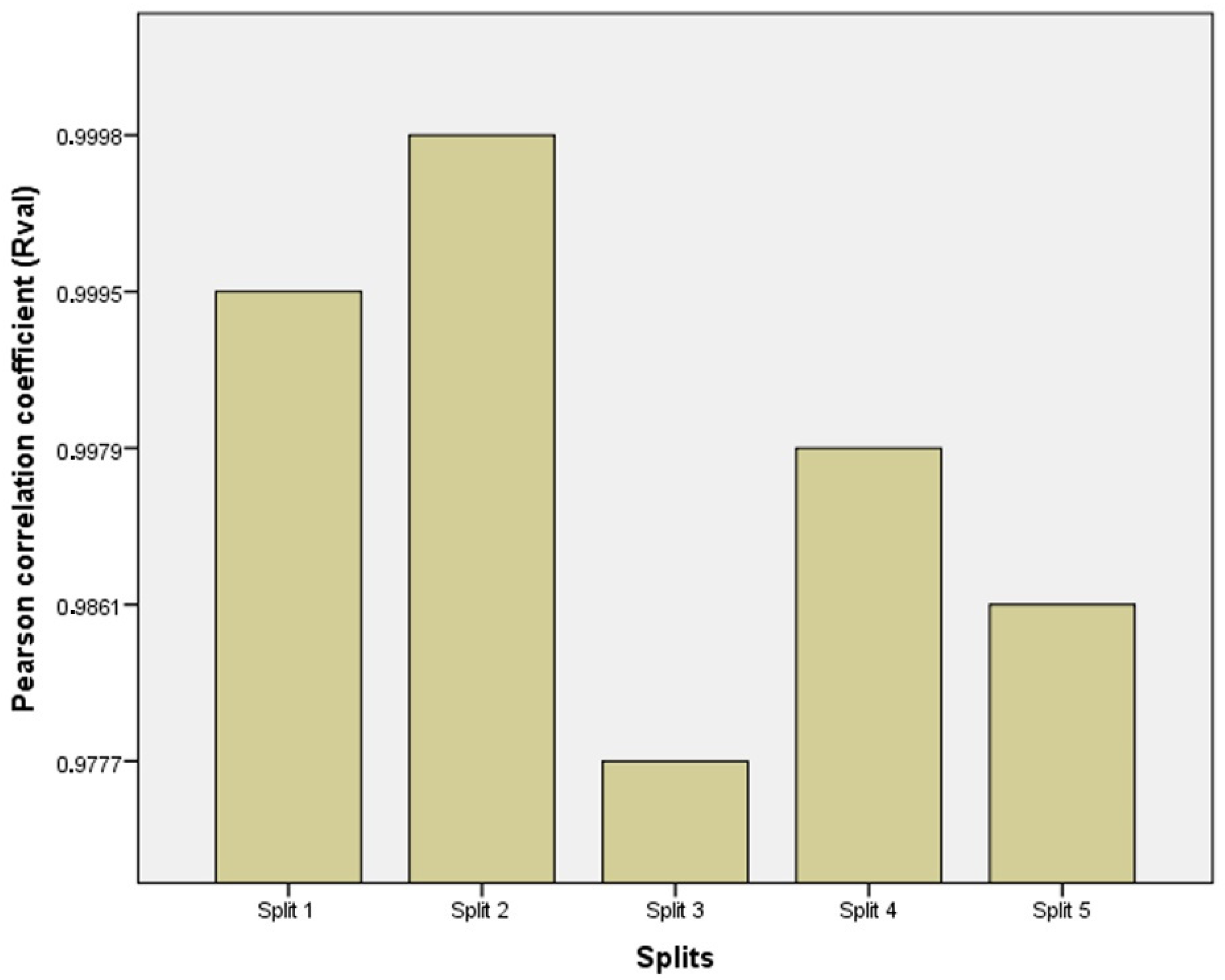
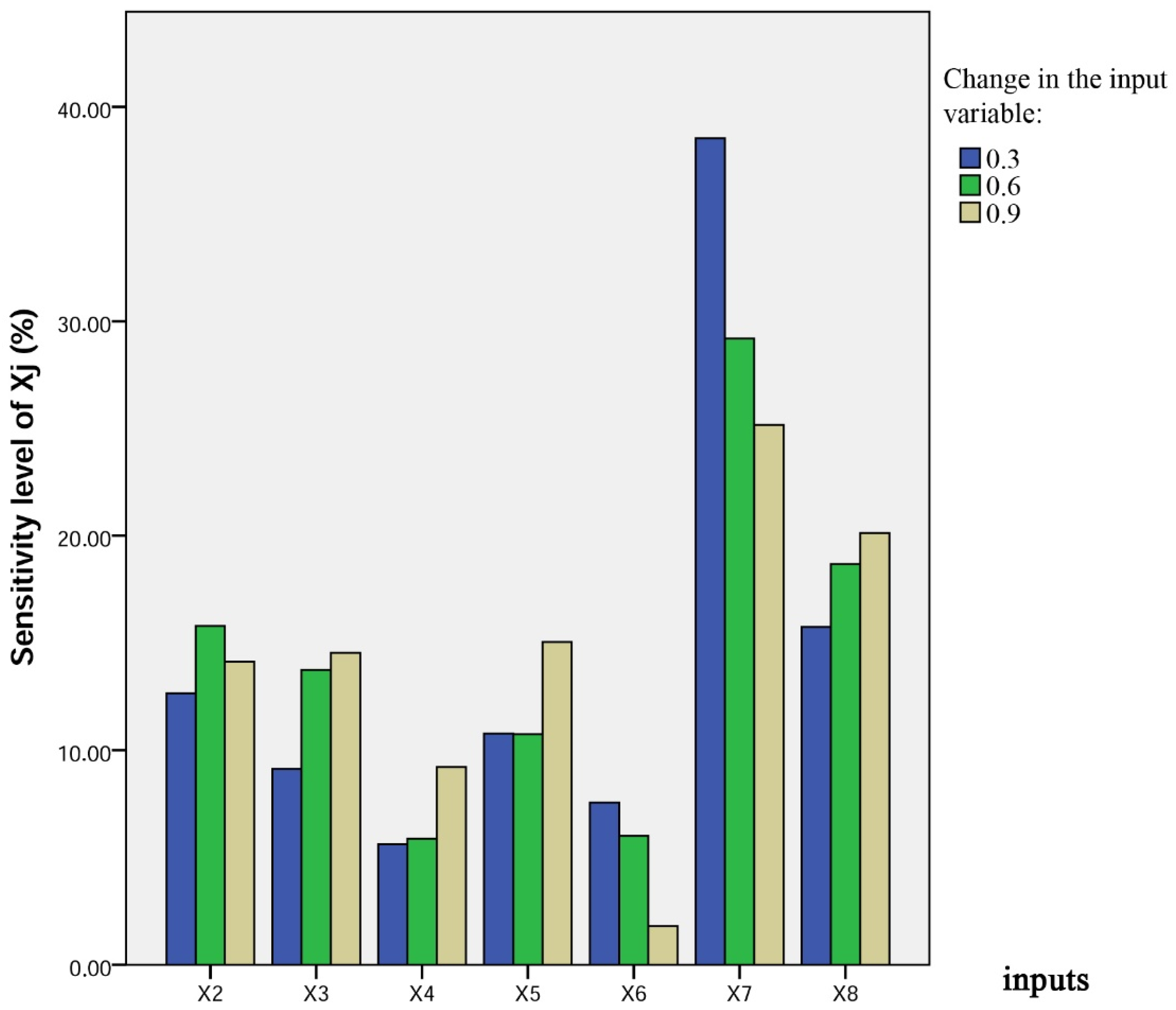
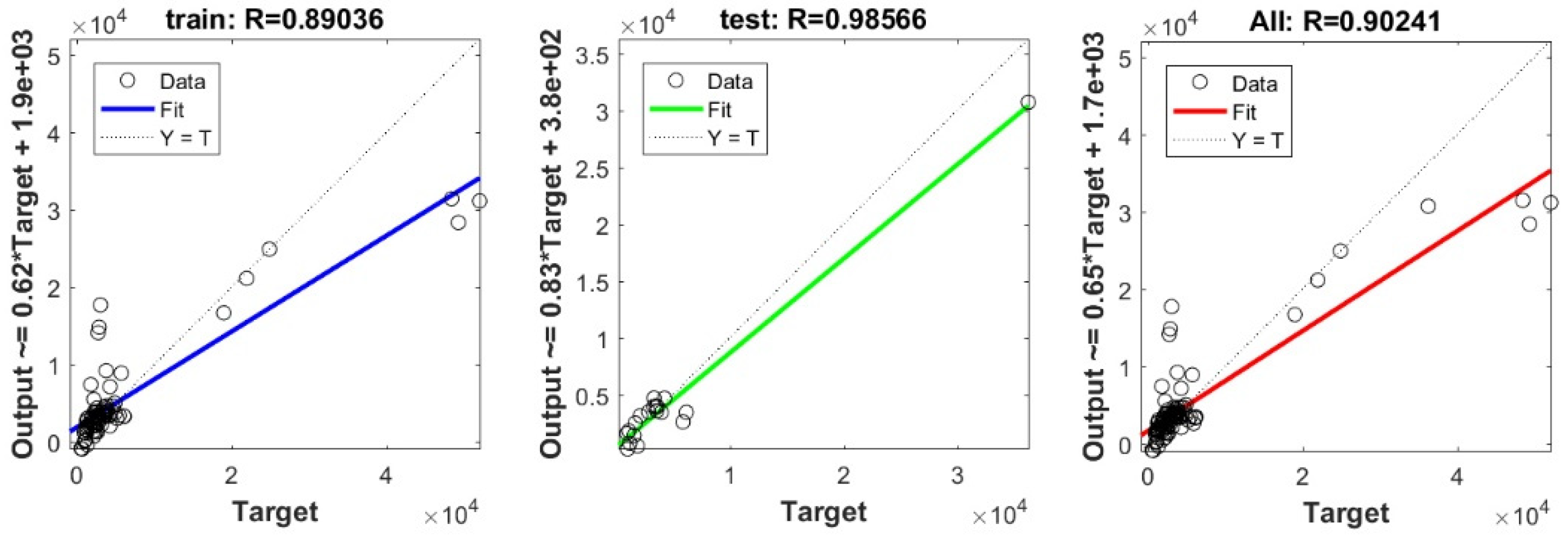
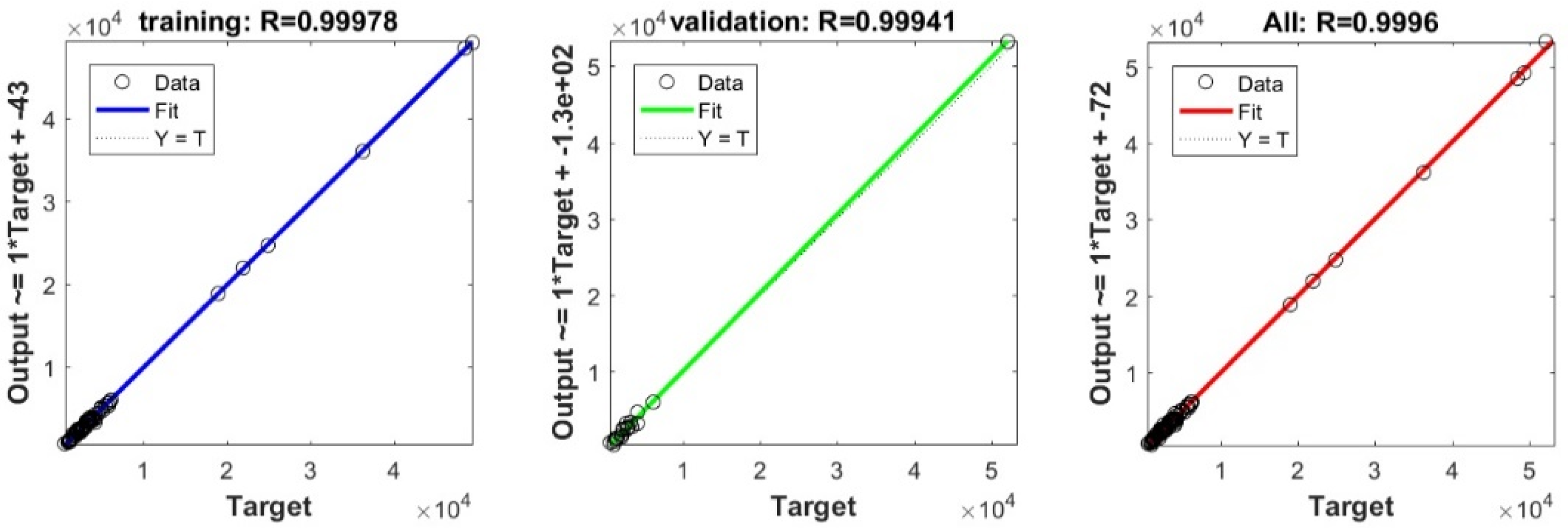
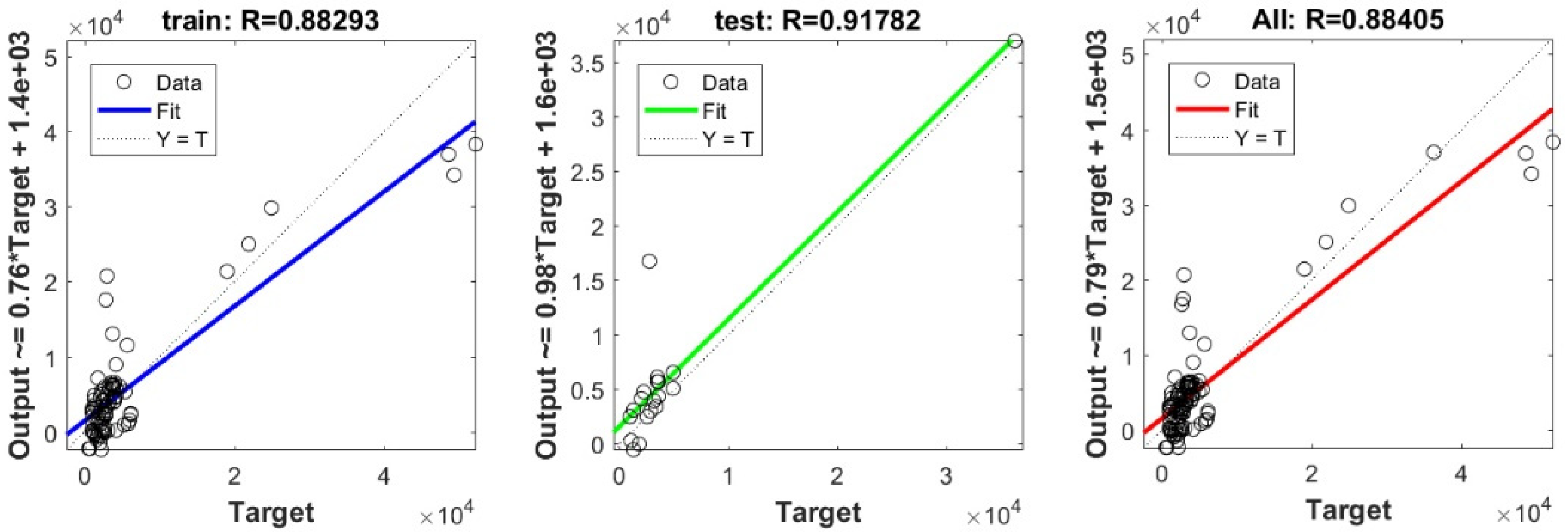
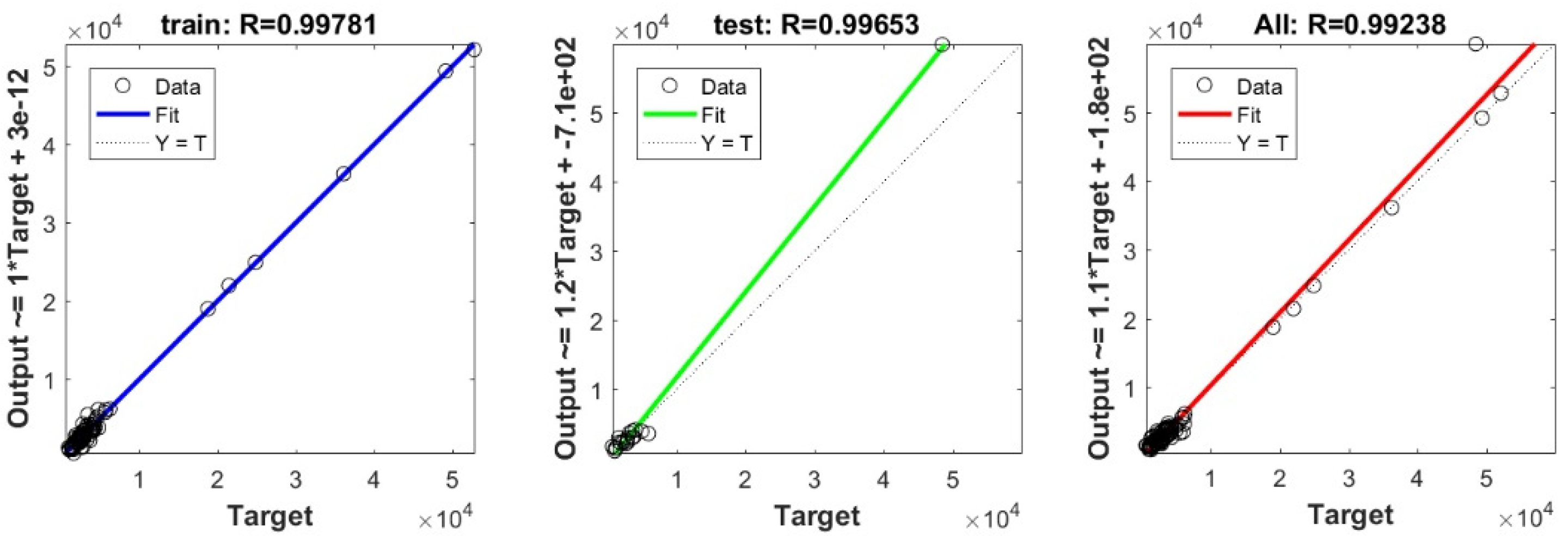
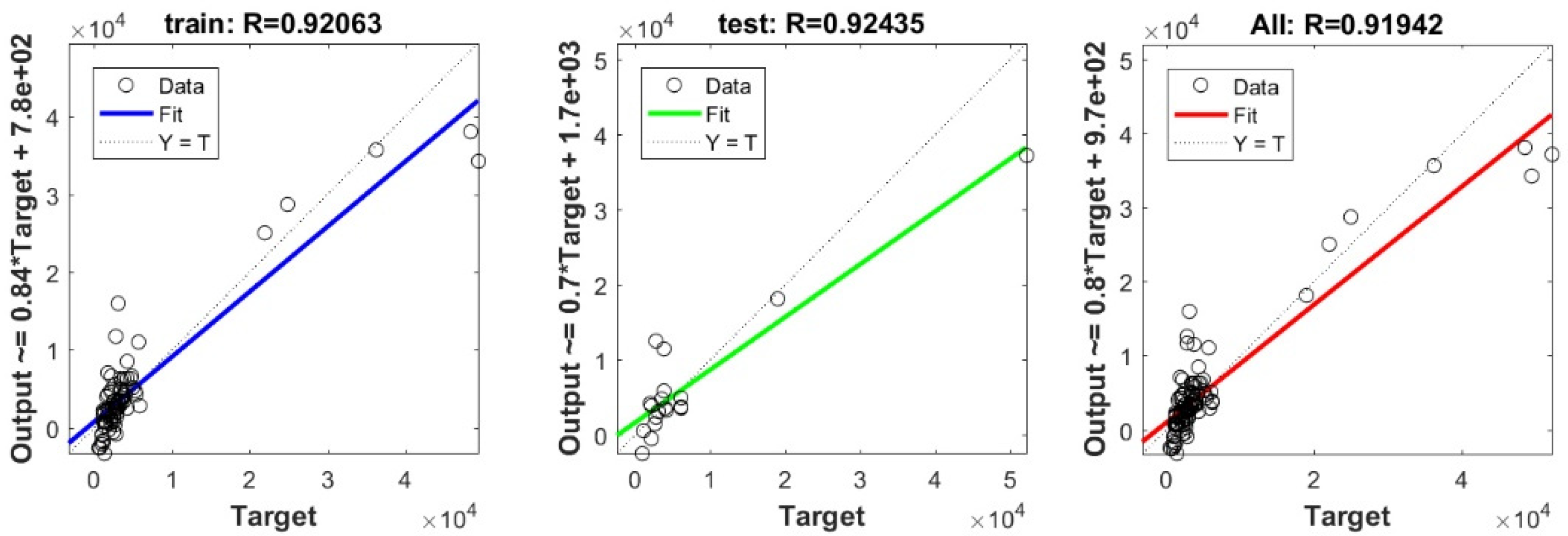
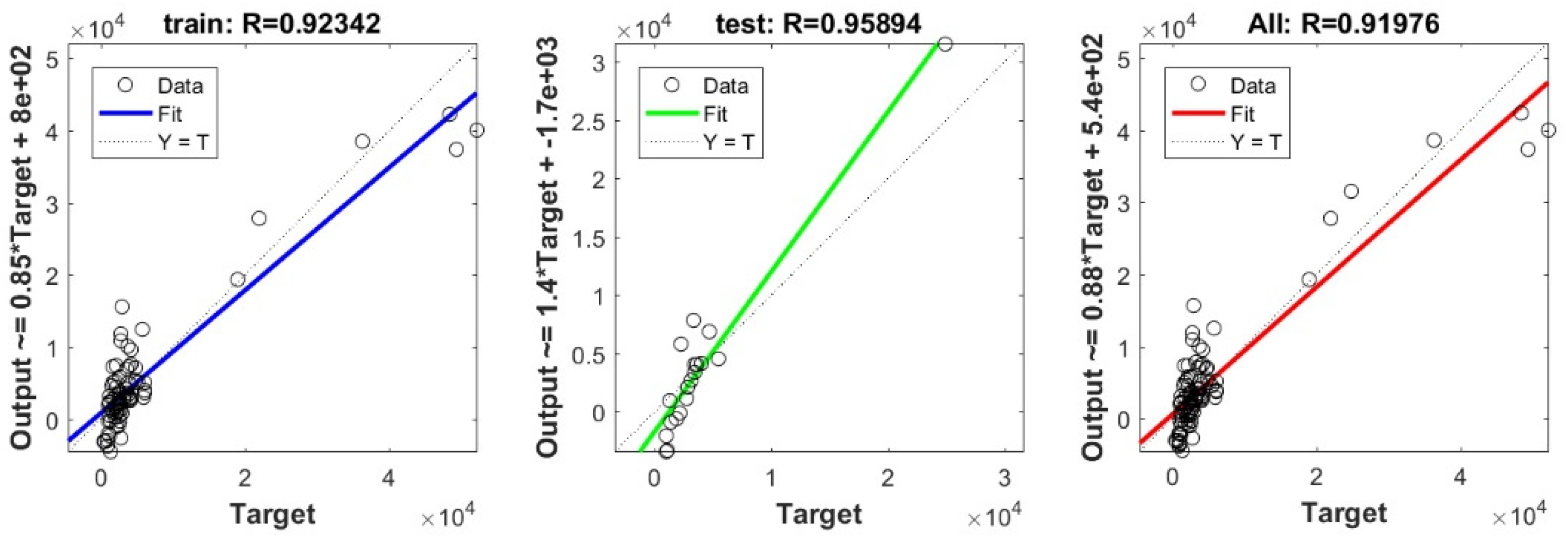
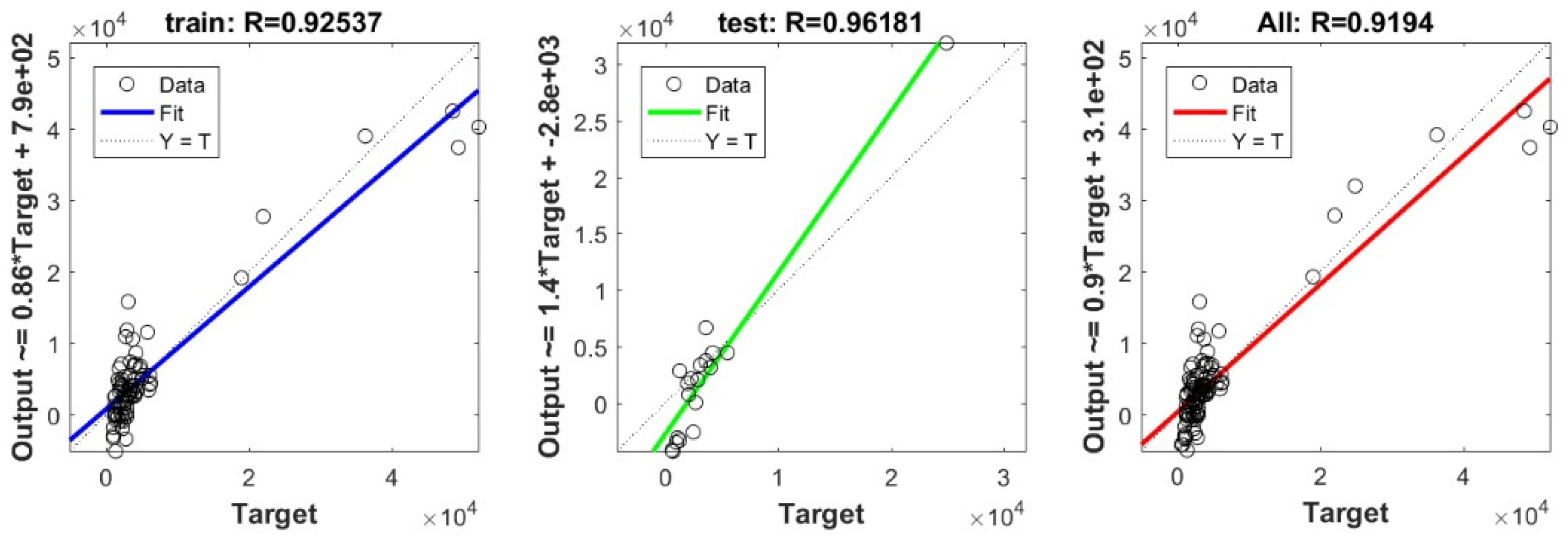
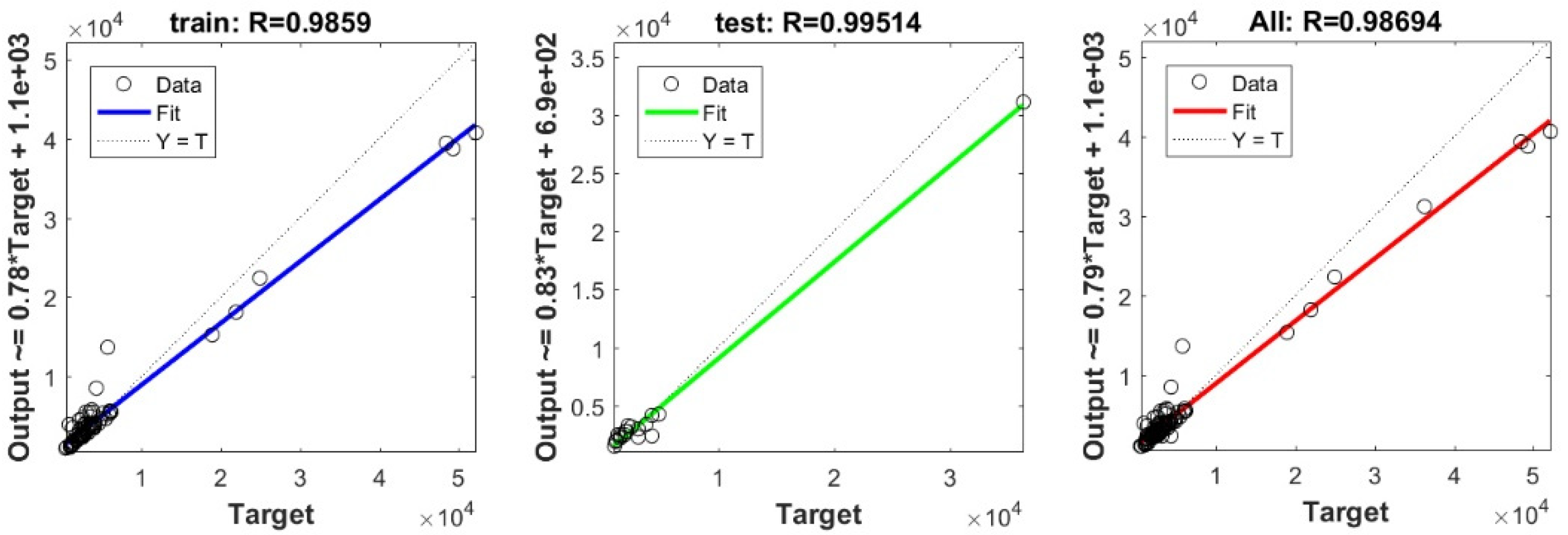
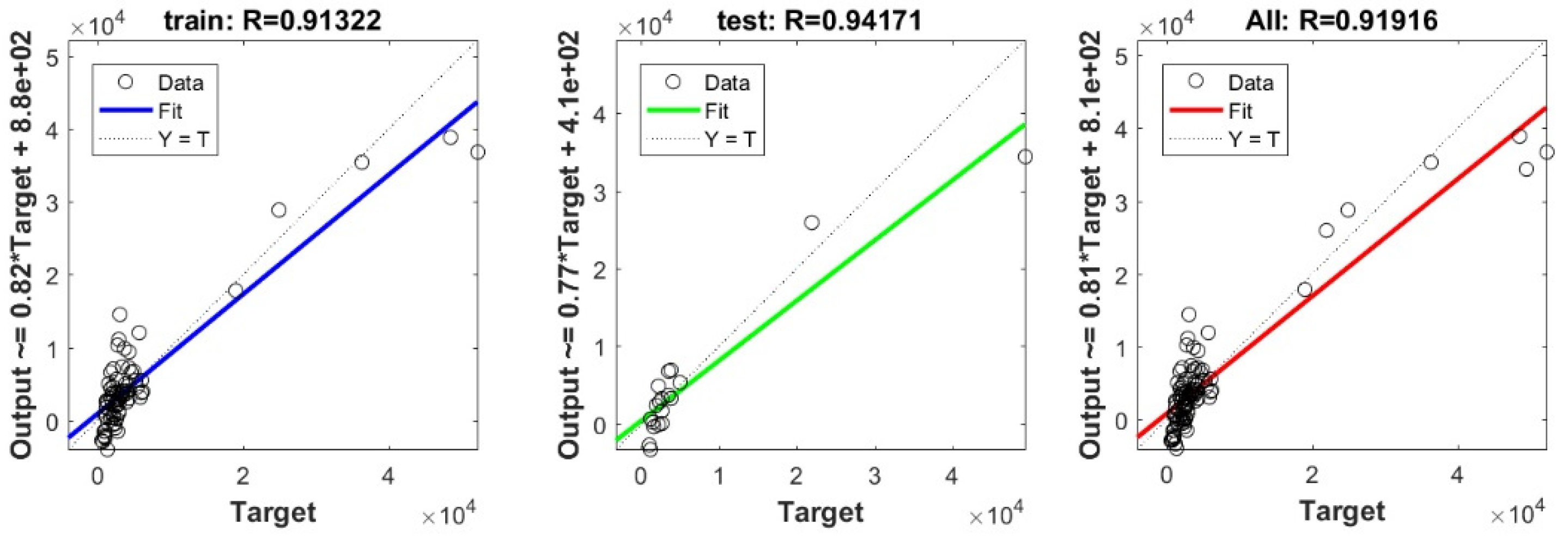
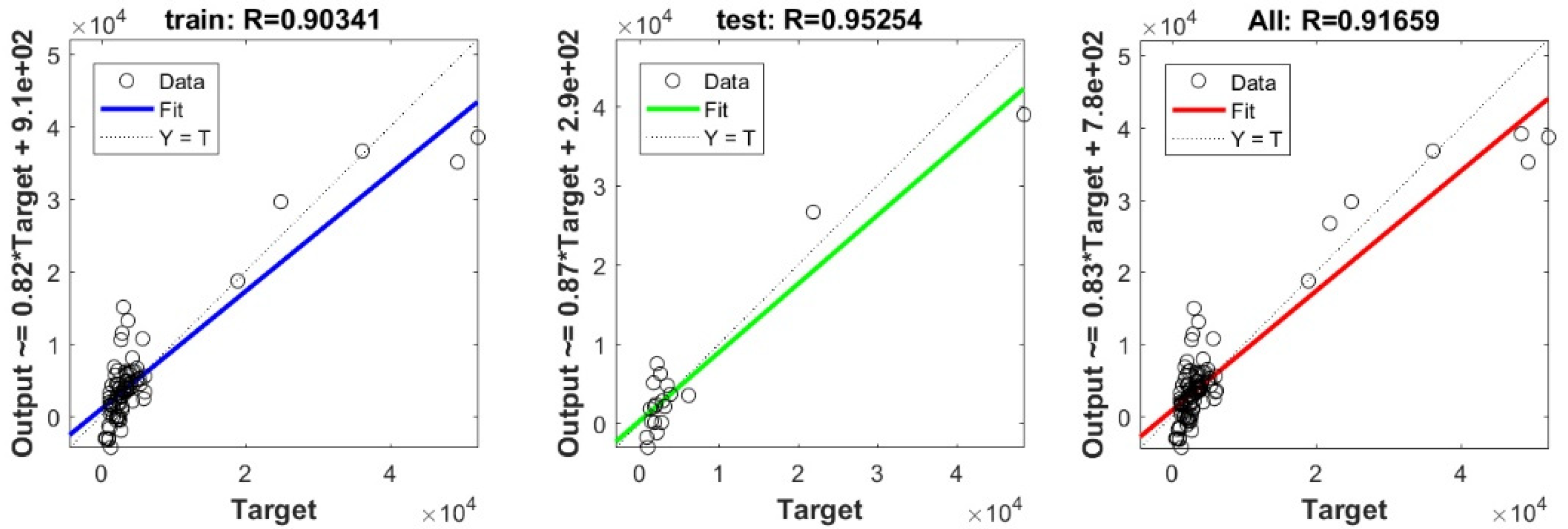
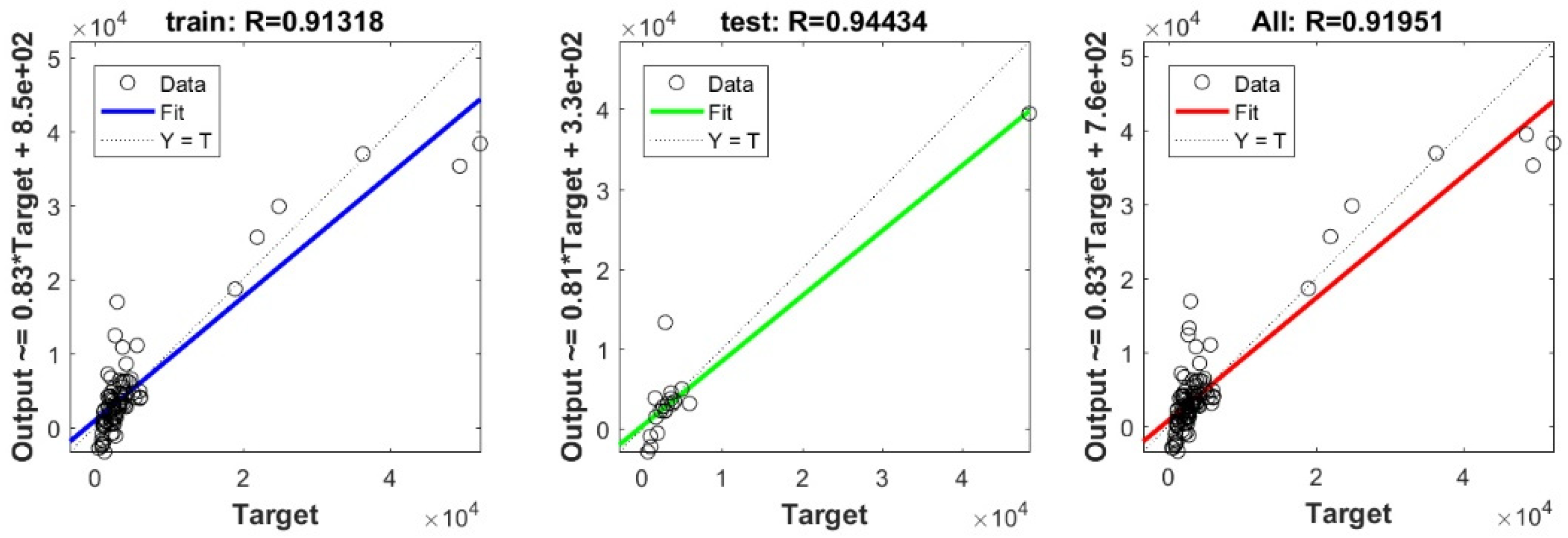
In the current study, a very important contribution in the geotechnical community has been introduced for the sake of enhancing the performance of the pile-bearing capacity model. It is worth mentioning here that the model quality is influenced by the method utilized. Hence, other unused advanced machine-learning methods demonstrated efficient results in other areas. Consequently, in the current study, we examined the usage of twelve advanced machine-learning methods, such as Deep Neural Network (DNN), Extreme Learning Machine (ELM), Support Vector Regression (SVR), LASSO regression (LASSO), Random Forest (RF), Ridge Regression (Ridge), Partial Least Square Regression (PLS), Stepwise Regression (Stepwise), Kernel Ridge (KRidge), Genetic Programming (GP), and Least Square Regression (LSR), to predict the pile-bearing capacity. According to the authors’ knowledge, the use of the aforementioned machine-learning methods in predicting the pile-bearing capacity is very rare. Therefore, this study began with collecting a wide range of data consisting of 100 static load-bearing tests on the UBC of both steel- and concrete-driven piles from different countries, such as Iran, Mexico, and India. Afterward, we selected eight relevant factors based on the literature recommendations, such as average cohesion (kN/m2), average friction angle (°), average soil-specific weight (kN/m3), average pile-soil friction angle (°), flap number, pile area (m2), and pile length (m). Based on that, eleven advanced machine-learning methods (DNN, ELM, SVR, LASSO, RF, Ridge, PLS, Stepwise, KRidge, GP, and LS) were applied for modeling the selected optimal input set for the first time. The findings clearly indicate that the Deep Neural Network (DNN) presents the most appropriate model, which yielded the minimum values of error metrics (MEA, RMSE, and IOS) and the higher values of R2, R, and IOA compared to other models. Furthermore, the newly developed model was assessed by the K-fold cross-validation method and compared to other proposed models from the literature based on the correlation coefficient. The conclusion drawn is that the optimal DNN model could produce new data without causing over-fitting or under-fitting, plus being much more precise than the other proposed empirical models. Moreover, the last part in the current study consisted of the sensitivity analysis, which provided an overview of the most influential parameters on the pile-bearing capacity according to the proposed model. The findings indicate that the pile area was the most influential factor on the pile-bearing capacity. Pile length also had a considerable effect. In addition, the cohesion and friction angle demonstrated a moderate effect on the pile-bearing capacity, with a sensibility ratio ranging between 9% and 15%. Finally, the proposed optimal model was then used to develop a GUI public interface in order to facilitate its usage in the future. A reliable, easy-to-use, and graphical interface, named “BeaCa2021, presented in the current study, was programmed via Matlab software. The essential advantage of “BeaCa2021” is to help researchers and civil engineers interested in the problem of modeling regardless of their proficiency, by offering them plenty of benefits, such as reliability, easiness, and lowering the budget used for predicting the pile-bearing capacity from relevant and easily obtained parameters without the need to operate expensive in situ tests.
The results obtained in the current study also proved that the performance of the pile-bearing capacity model was considerably enhanced by using new machine-learning methods. The model prediction by the
DNN was improved by 8.91% with the
ANN method proposed by Nawari et al. [
25], 3.58% with the
PSO–ANN method proposed by Jahed et al. [
1], and 0.86% with the
MLP–GWO method proposed by Dehghanbanadaki et al. [
30]. The obtained results are logical because deep learning is generally employed either in the prediction or in the problematic classification, which can reduce the bias and variance plus avoiding over-fitting and under-fitting problems, as opposed to the traditional
ANN methods, to improve their predictive capability. According to these data, we can infer that the
DNN method, which was employed in this study for the first time for the purpose of modeling the pile-bearing capacity, could yield more effective and accurate results than the other machine-learning methods.
Despite the multiple extraordinary findings of this study, a number of important limitations need to be addressed. The fundamental limitation would be the fact that the sample size was relatively small, which may affect the precision of the pile-bearing capacity. This may lead to the proposed model’s inability to generalize the new conditions or circumstances that were not used in the training data stage. Besides, researchers generally utilize large and diverse data collected by transferring knowledge between them. This is an important issue to build on in future research, i.e., to rely on the data gathered from multiple countries to enhance its learning and, therefore, produce a better model. Additionally, further studies using meta-heuristic algorithms for the prediction of pile-bearing capacity are strongly recommended. We mention, for example, the Particle Swarm Optimization (
PSO) and Gravitational Search Algorithm (
GSA), Bee Colony Algorithm (
BCA), Bio-geography-Based Optimization (
BBO), Whale Optimization Algorithm (
WOA), Ant Colony Optimization (
ACO), and Grey Wolf Optimizer (
GWO). These algorithms have shown high-performance results when combined with machine-learning techniques, leading to improving their learning, and therefore rapidly converging to the best solution. The application of these meta-heuristic algorithms combined with machine-learning methods has shown impressive results in the abroad fields [
55,
61].
5. Conclusions
This study relied on a considerable number of steel- and concrete-driven pile data collected from different countries, such as Iran, Mexico, and India. The comparison of the results’ assessment between the different proposed models revealed the superiority of the DNN model proposed in our study, which yielded the highest accuracy in terms of MAE, RMSE, IOS, R, R2, and IOA in both the training/validation phases. The findings indicate that this model has a high correlation coefficient, ranging between 0.9777 and 0.9998 for the validation data in the 5 splits of the k-fold cross-validation approach, meaning that there was no over-fitting or under-fitting. Furthermore, the results indicated that the aforementioned DNN model is more effective compared to other empirical models proposed in the literature. The sensitivity analysis results proved that pile area had the most significant effect on the prediction of the pile-bearing capacity. Pile lengths had a moderate influence and were ranked second. In addition, cohesion and friction angle had little effect on the pile-bearing capacity. Finally, the proposed optimal model was then used to develop a GUI public interface with Matlab software, named “BeaCa2021”. The fundamental benefit of “BeaCa2021” is to help researchers and practicing civil engineers, regardless of their proficiency, interested in the problem of modeling, to estimate the pile-bearing capacity with the benefits of gaining time and money.
This work has opened up several questions that need further investigations to overcome certain limitations. Firstly, there is a need to use more data from other countries to enhance the learning phase, which is needed to develop the BeaCa2021 in the future. Secondly, we propose the usage of meta-heuristic algorithms combined with machine-learning methods for predicting the pile-bearing capacity in future studies. These algorithms have demonstrated high-performance results when used with machine-learning techniques, leading to improved learning.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}