
High Inclusiveness and Accuracy Motion Blur Real-Time Gesture Recognition Based on YOLOv4 Model Combined Attention Mechanism and DeblurGanv2


Abstract
:1. Introduction
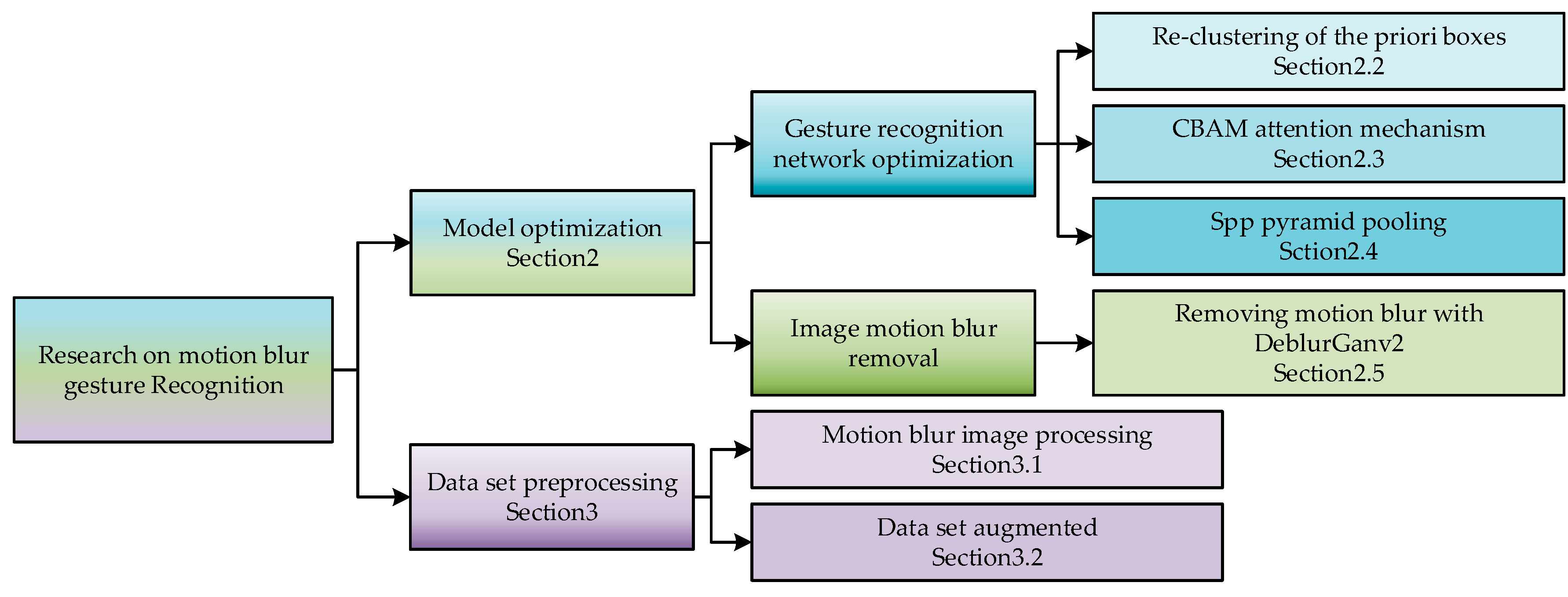
2. Algorithm Improvement
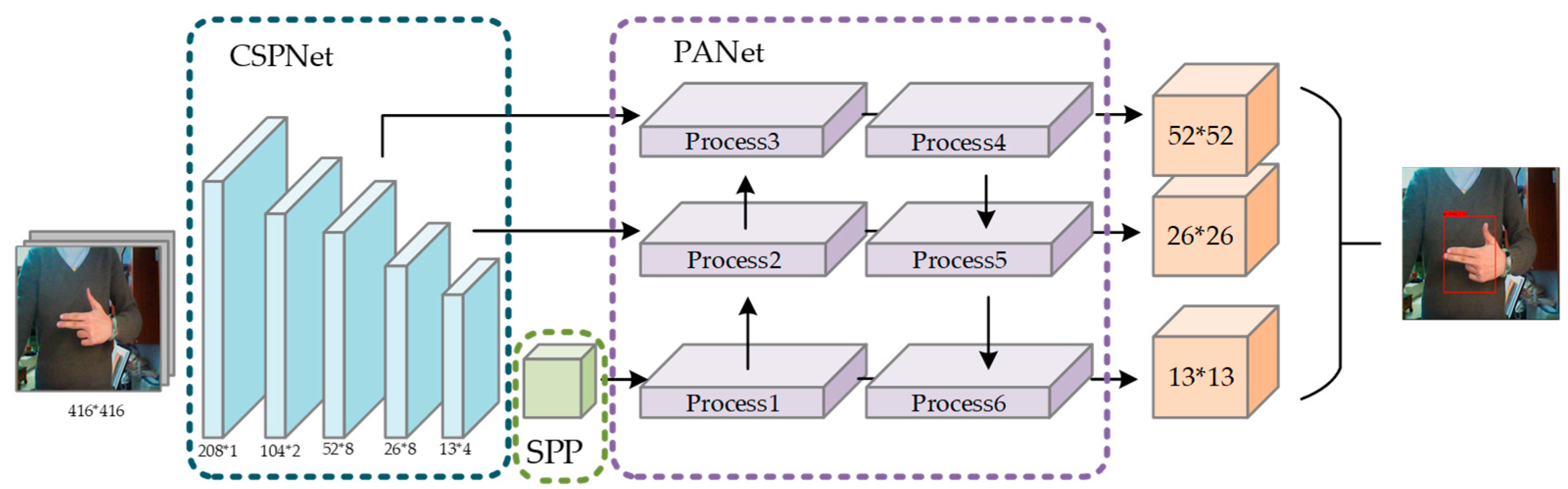
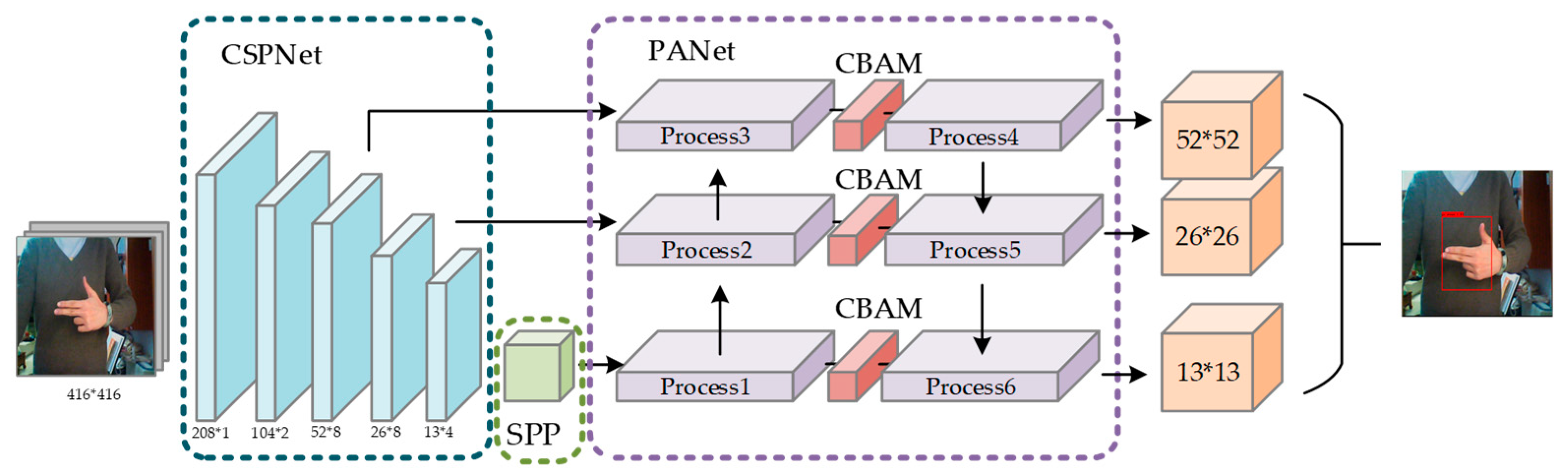
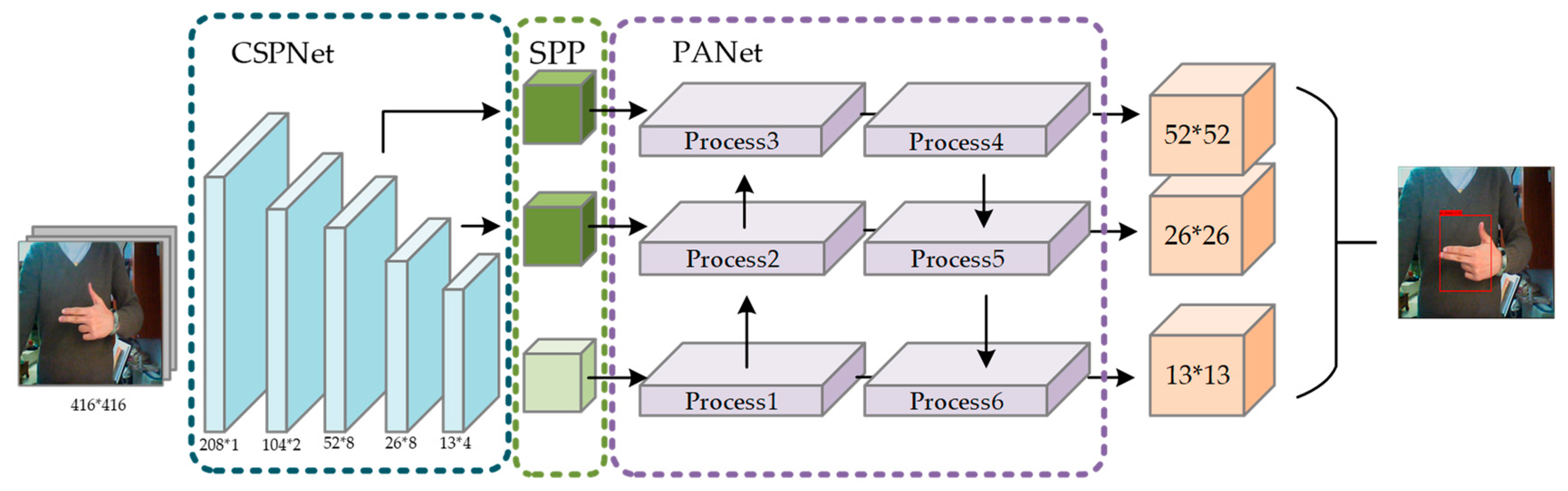
2.1. YOLOv4 Target Detection Algorithm
- Upgrading the original backbone feature extraction network Darknet-53 to CSPDarknet-53;
- Enhancing the effect of feature extraction network, using the SPP and PANet structure;
- Utilizing the Mosaic function to complete the data enhancement;
- Using CIOU as return LOSS;
- Using Mish function as the activation function of the network.
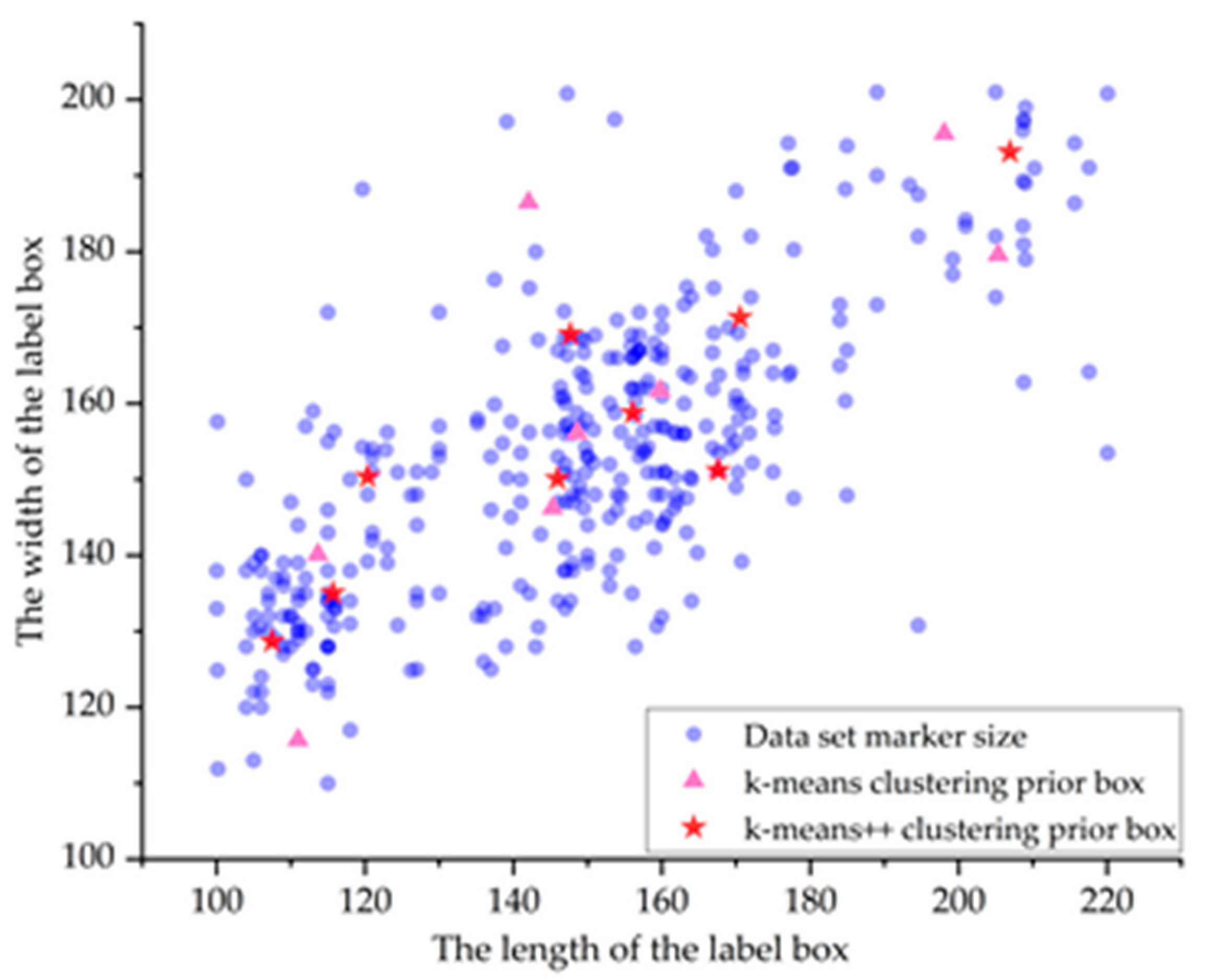
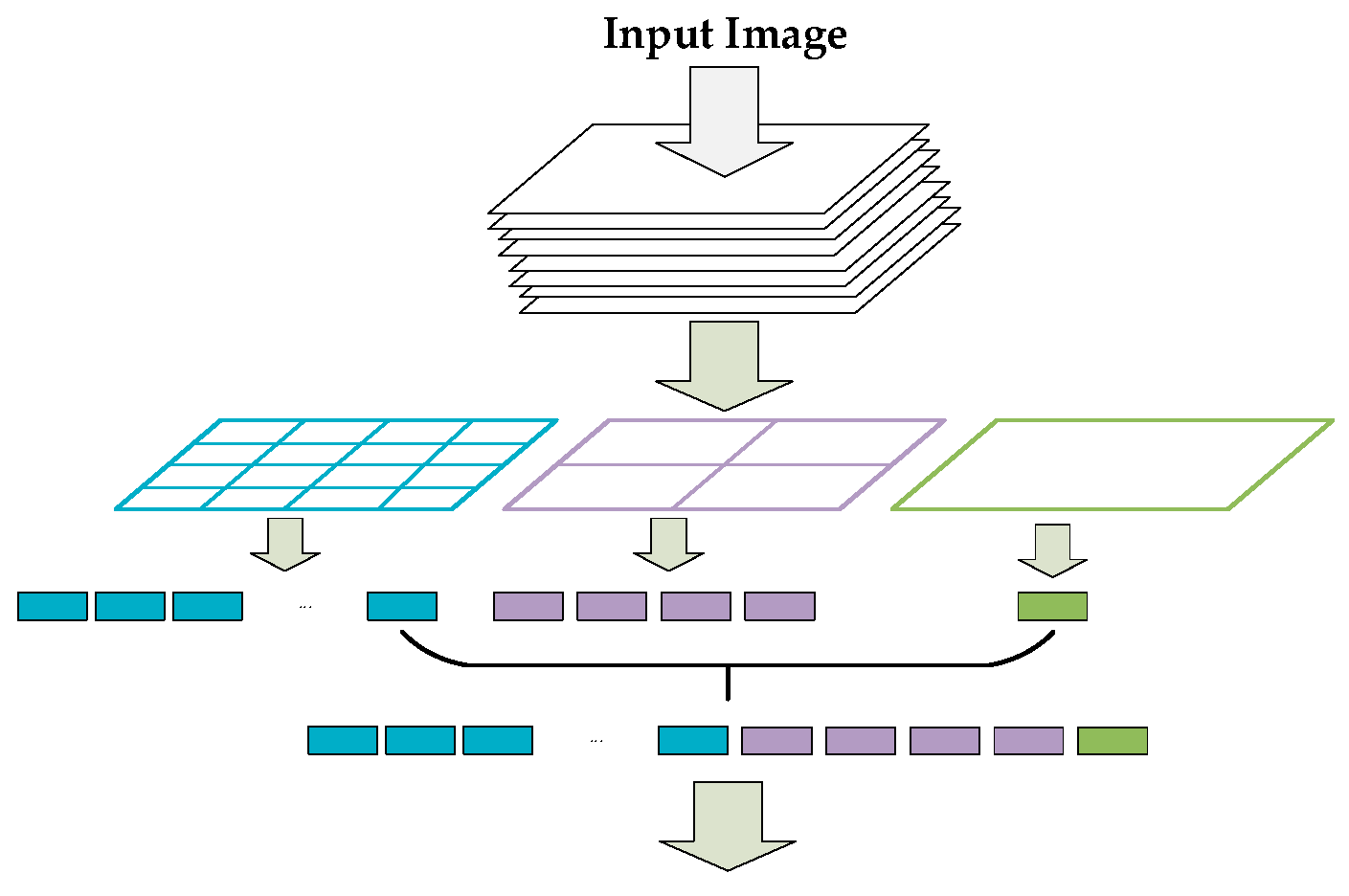
2.2. Reclustering of Priori Boxes
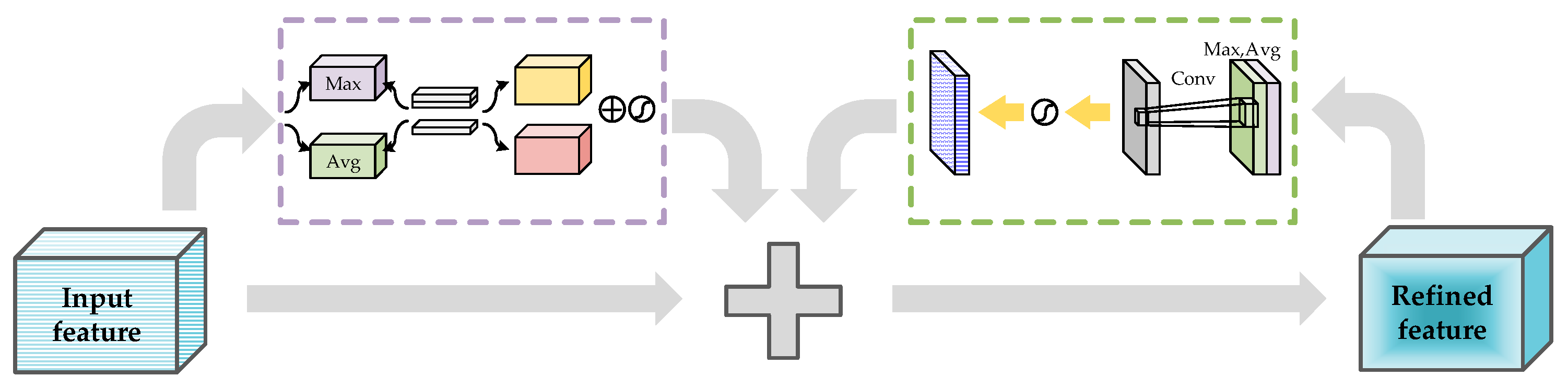
2.3. Introduction of Attention Mechanism
2.4. SPP Spatial Pooling Pyramid Structure
2.5. Motion Blur Reduction of Input Image
3. Dataset and Experimental Environment Construction
3.1. Dataset Establishment and Augmentation Optimization
3.2. Establishment of Experimental Environment
4. Network Training and Model Effect Analysis
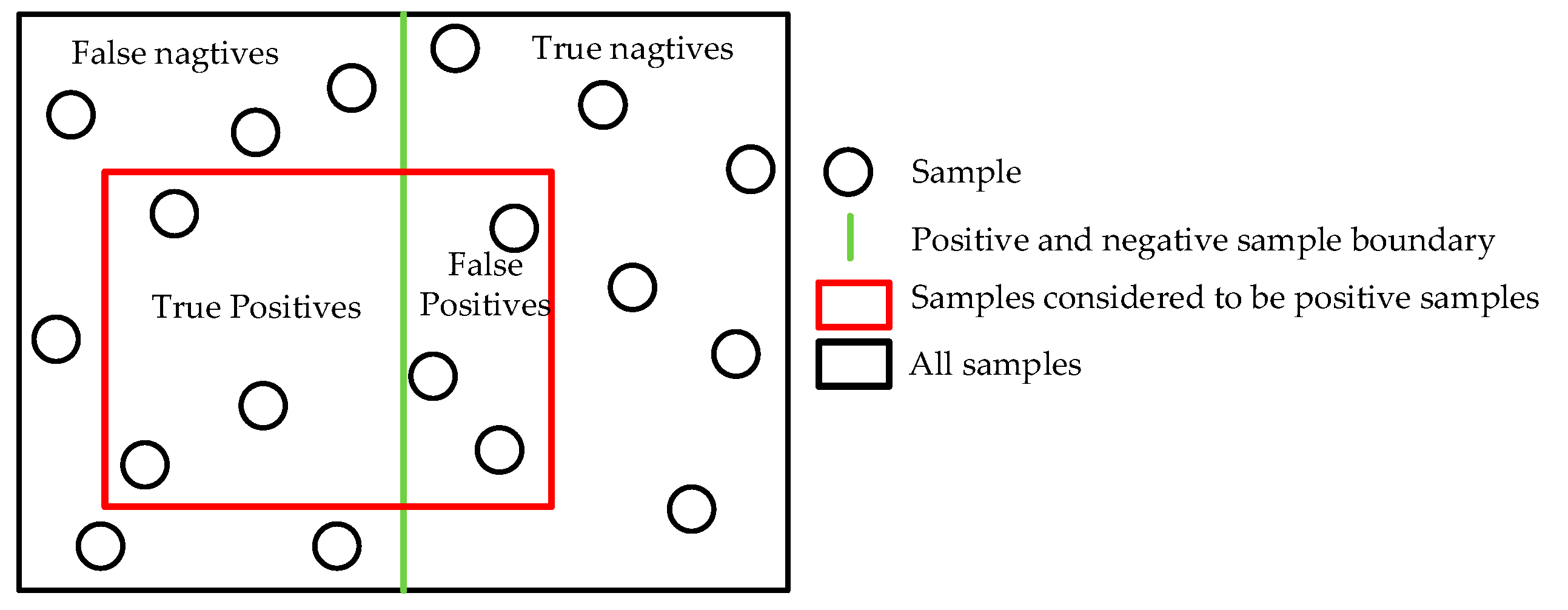
4.1. Model Performance Evaluation
4.2. Effect Analysis of Motion Blur Gesture Detection
4.2.1. Image Motion Blur Reduction Effect
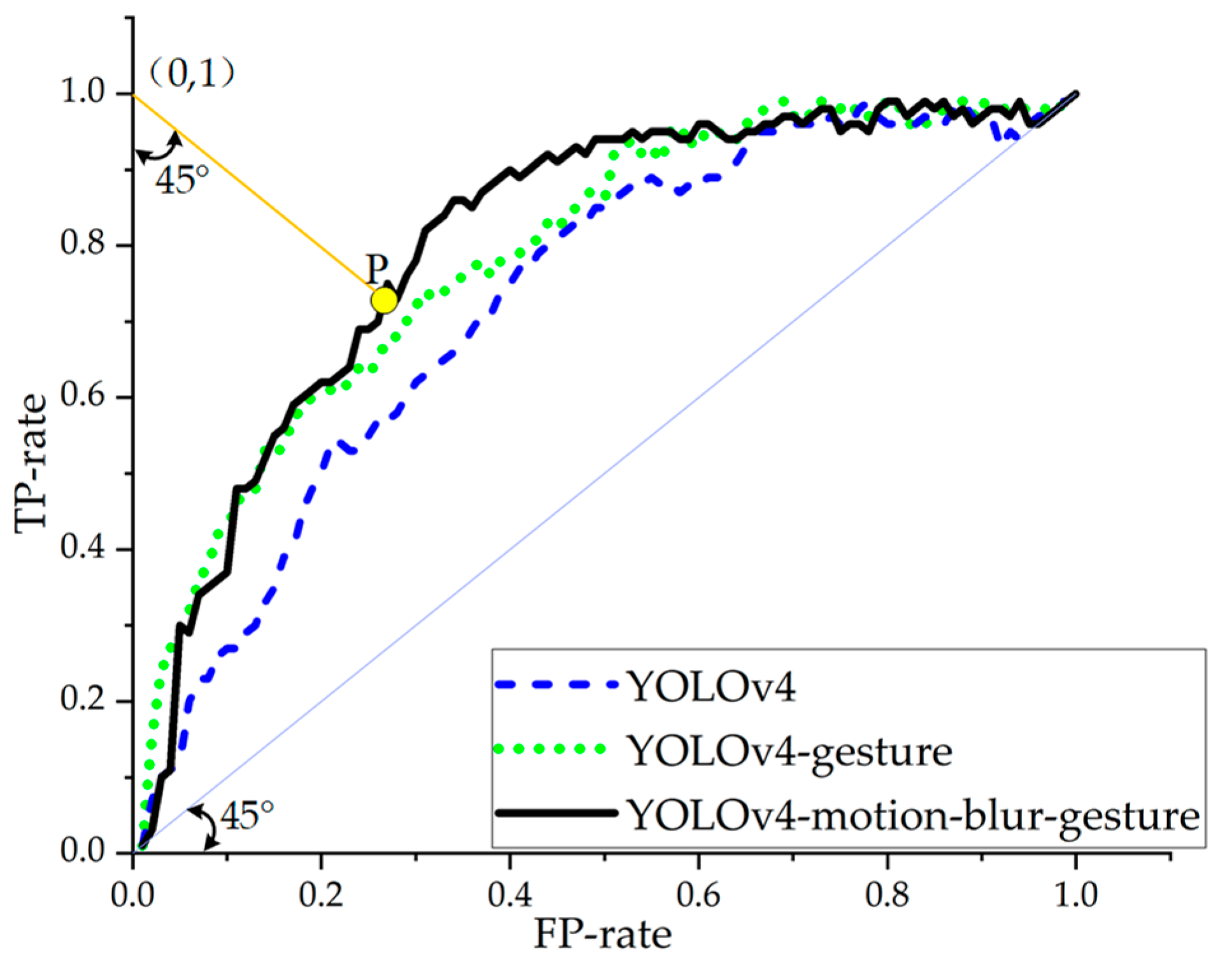
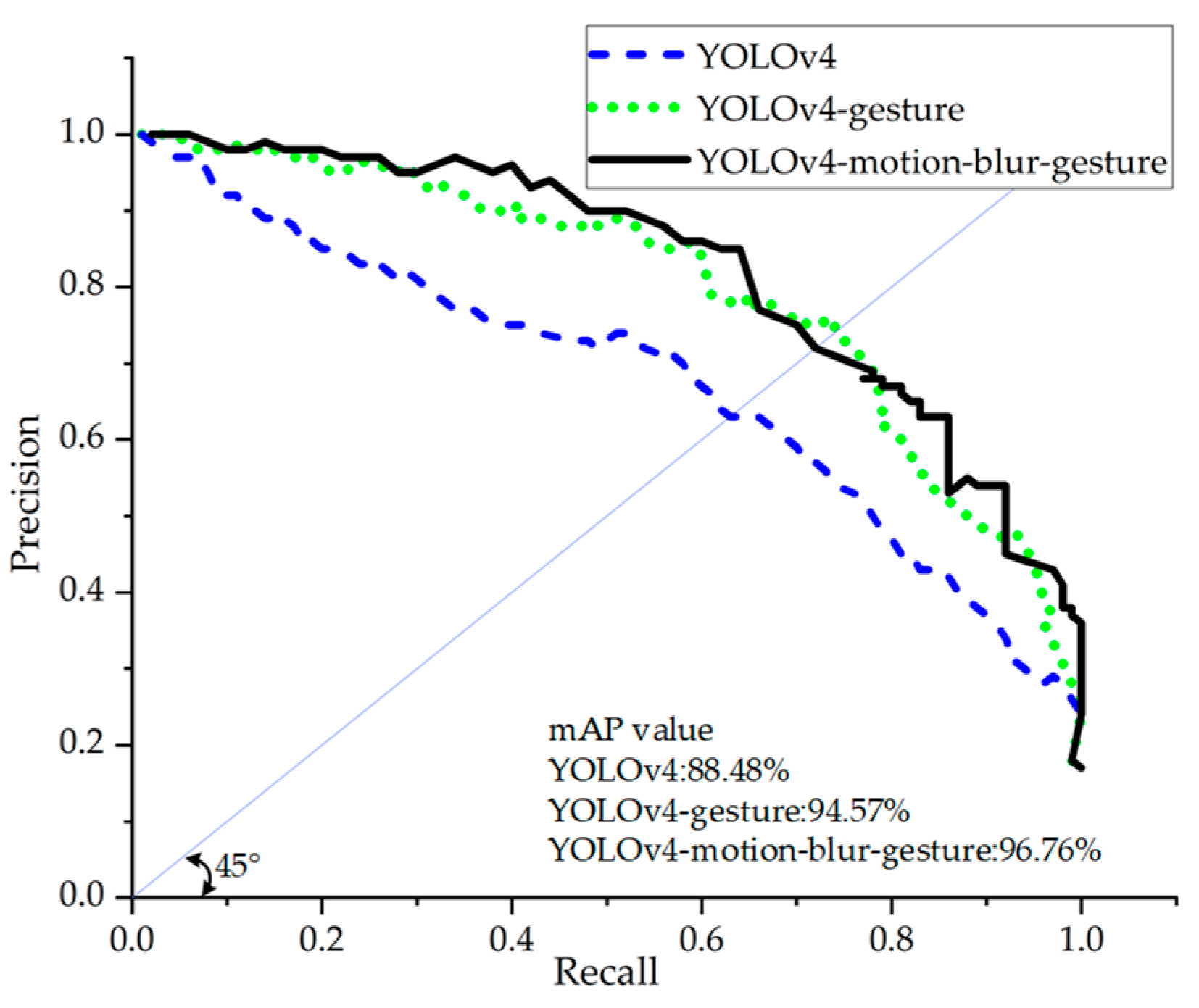
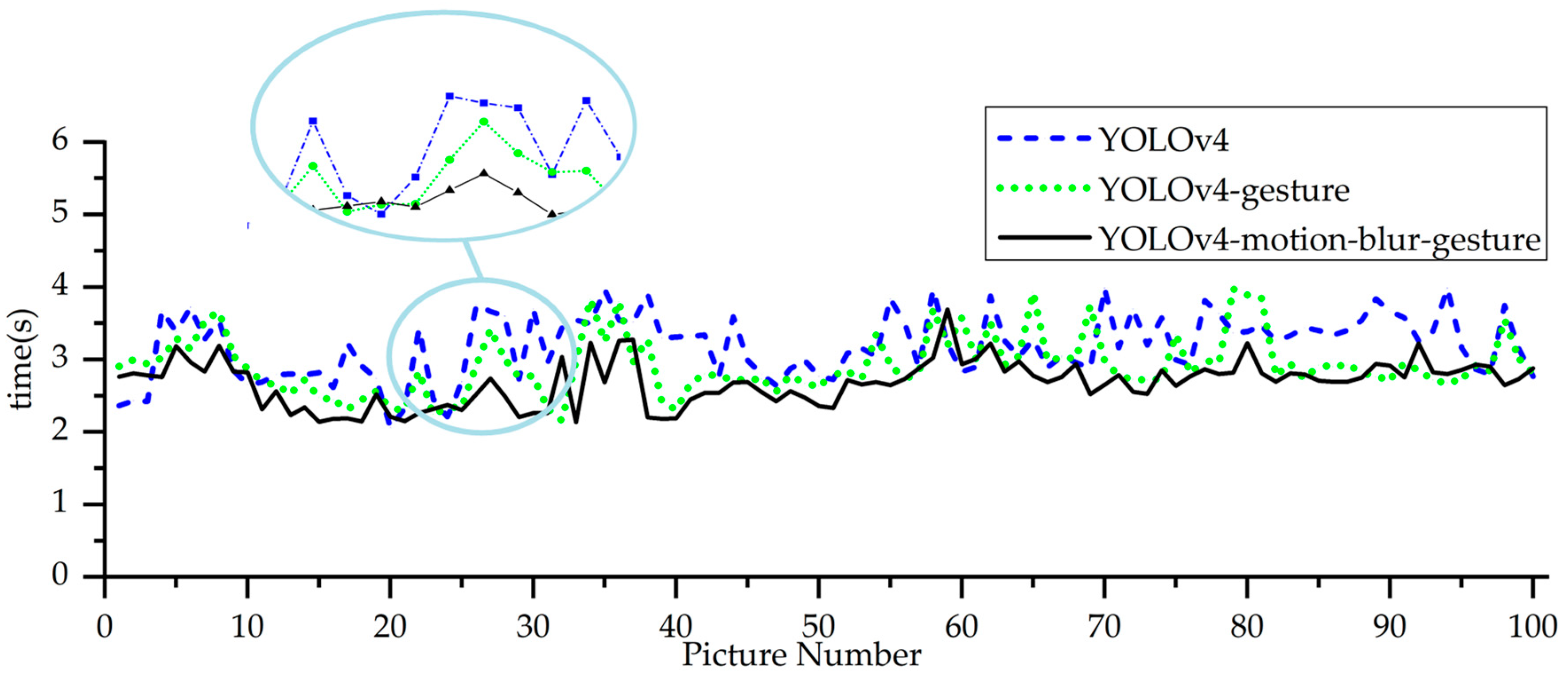
4.2.2. Motion Blur Gesture Detection Accuracy and Recognition Speed Effect
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhuang, H.C.; Wang, N.; Gao, H.B.; Deng, Z.Q. Quickly obtaining range of articulated rotating speed for electrically driven large-load-ratio six-legged robot based on maximum walking speed method. IEEE Access. 2019, 7, 29453–29470. [Google Scholar] [CrossRef]
- Zhuang, H.C.; Gao, H.B.; Deng, Z.Q. Gait planning research for an electrically driven large-load-ratio six-legged robot. Appl. Sci. 2017, 7, 296. [Google Scholar] [CrossRef] [Green Version]
- Bian, F.; Li, R.; Liang, P. SVM based simultaneous hand movements classification using sEMG signals. In Proceedings of the 2017 IEEE International Conference on Mechatronics and Automation (ICMA), Takamatsu, Japan, 6–9 August 2017; pp. 427–432. [Google Scholar]
- Mendes, J.; Freitas, M.; Siqueira, H.; Lazzaretti, A.; Stevan, S.; Pichorim, S. Comparative analysis among feature selection of sEMG signal for hand gesture classification by armband. IEEE Lat. Am. Trans. 2020, 18, 1135–1143. [Google Scholar] [CrossRef]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 32–39. [Google Scholar]
- Mistry, P.; Maes, P.; Chang, L. WUW-wear Ur world: A wearable gestural interface. In Proceedings of the 27th International Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 4111–4116. [Google Scholar]
- Wilhelm, M.; Krakowczyk, D.; Albayrak, S. PeriSense: Ring-Based Multi-Finger Gesture Interaction Utilizing Capacitive Proximity Sensing. Sensors 2020, 20, 3990. [Google Scholar] [CrossRef]
- Jiang, S.; Gao, Q.H.; Liu, H.Y.; Shull, P.B. A novel, co-located EMG-FMG-sensing wearable armband for hand gesture recognition. Sens. Actuator A Phys. 2020, 301, 111738. [Google Scholar] [CrossRef]
- Moin, A.; Zhou, A.; Rahimi, A.; Menon, A.; Benatti, S.; Alexandrov, G.; Tamakloe, S.; Ting, J.; Yamamoto, N.; Khan, Y.; et al. A wearable biosensing system with in-sensor adaptive machine learning for hand gesture recognition. Nat. Electron. 2021, 4, 54–63. [Google Scholar] [CrossRef]
- Song, K.; Kim, S.H.; Jin, S.; Kim, S.; Lee, S.; Kim, J.S.; Park, J.M.; Cha, Y. Pneumatic actuator and flexible piezoelectric sensor for soft virtual reality glove system. Sci. Rep. 2019, 9, 8988. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.W.; Baek, S.; Park, S.W.; Koo, M.; Kim, E.H.; Lee, S.; Jin, W.; Kang, H.; Park, C.; Kim, G.; et al. 3D motion tracking display enabled by magneto-interactive electroluminescence. Nat. Commun. 2020, 11, 6072. [Google Scholar] [CrossRef] [PubMed]
- Mantecón, T.; Del-Blanco, C.R.; Jaureguizar, F.; García, N. Hand gesture recognition using infrared imagery provided by leap motion controller. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Lecce, Italy, 24–27 October 2016; pp. 47–57. [Google Scholar]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Wang, M.; Yan, Z.; Wang, T.; Cai, P.Q.; Gao, S.Y.; Zeng, Y.; Wan, C.J.; Wang, H.; Pan, L.; Yu, J.C.; et al. Gesture recognition using a bioinspired learning architecture that integrates visual data with somatosensory data from stretchable sensors. Nat. Electron. 2020, 3, 563–570. [Google Scholar] [CrossRef]
- Shinde, S.; Kothari, A.; Gupta, V. YOLO based human action recognition and localization. Procedia Comput. Sci. 2018, 133, 831–838. [Google Scholar] [CrossRef]
- Yu, J.M.; Zhang, W. Face mask wearing detection algorithm based on improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. A Deep Learning Enabled Multi-Class Plant Disease Detection Model Based on Computer Vision. AI 2021, 2, 413–428. [Google Scholar] [CrossRef]
- Elboushaki, A.; Hannane, R.; Afdel, K.; Koutti, L. MultiD-CNN: A multi-dimensional feature learning approach based on deep convolutional networks for gesture recognition in RGB-D image sequences. Expert Syst. Appl. 2020, 139, 112829. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Gao, M.Y.; Cai, Q.Y.; Zheng, B.W.; Shi, J.; Ni, Z.H.; Wang, J.F.; Lin, H.P. A Hybrid YOLO v4 and Particle Filter Based Robotic Arm Grabbing System in Nonlinear and Non-Gaussian Environment. Electronics 2021, 10, 1140. [Google Scholar] [CrossRef]
- Huang, R.; Pedoeem, J.; Chen, C.X. YOLO-LITE: A real-time object detection algorithm optimized for non-GPU computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Society. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means ++: The advantages of carefull seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposiumon Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, H.; Deng, L.B.; Yang, C.; Liu, J.B.; Gu, Z.Q. Enhanced yolo v3 tiny network for real-time ship detection from visual image. IEEE Access. 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Kupyn, O.; Martyniuk, T.; Wu, J.R.; Wang, Z.Y. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Hardie, R. A fast image super-resolution algorithm using an adaptive Wiener filter. IEEE Trans. Image Process. 2007, 16, 2953–2964. [Google Scholar] [CrossRef]
- Zhang, M.; Gunturk, B.K. Multiresolution bilateral filtering for image denoising. IEEE Trans. Image Process. 2008, 17, 2324–2333. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, X.R.; Wu, X.M.; Luo, C.B.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. GIScience Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef] [Green Version]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Central Processing Unit |
|---|---|
| Win10-64bit | Intel(R) Core (TM) i7-5500U CPU @ 2.40GHz |
| Model | Tensorflow | Keras | Numpy | Opencv-Python |
|---|---|---|---|---|
| DeblurGanv2 | 2.3.0 | 2.4.3 | 1.19.2 | 4.5.1.48 |
| YOLOv4 YOLOv4-gesture YOLOv4-motion-blur-gesture | 1.14.0 | 2.3.1 | 1.19.4 | 4.5.0 |
| Parameter | Value |
|---|---|
| Batch size | 2 |
| Learning rate | 0.001 |
| Init_epoch | 0 |
| Freeze_epoch | 50 |
| Unfreeze_epoch | 100 |
| Fixed image size | 416*416 |
| Model | mAP (epoch = 50) | mAP (epoch = 75) | mAP (epoch = 100) |
|---|---|---|---|
| YOLOv4 | 60.33% | 73.66% | 88.48% |
| YOLOv4-SPP | 64.76% | 78.21% | 90.85% |
| YOLOv4-CBAM | 64.83% | 83.74% | 93.44% |
| YOLOv4-gesture | 65.35% | 85.57% | 96.76% |
| Model | Average Detection Accuracy | mAP | Average Detection Time |
|---|---|---|---|
| YOLOv4 | 89.35% | 88.48% | 3.19s |
| YOLOv4-gesture | 96.42% | 94.57% | 2.92s |
| YOLOv4-motion-blur-gesture | 97.79% | 96.76% | 2.68s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, H.; Xia, Y.; Wang, N.; Dong, L. High Inclusiveness and Accuracy Motion Blur Real-Time Gesture Recognition Based on YOLOv4 Model Combined Attention Mechanism and DeblurGanv2. Appl. Sci. 2021, 11, 9982. https://doi.org/10.3390/app11219982
Zhuang H, Xia Y, Wang N, Dong L. High Inclusiveness and Accuracy Motion Blur Real-Time Gesture Recognition Based on YOLOv4 Model Combined Attention Mechanism and DeblurGanv2. Applied Sciences. 2021; 11(21):9982. https://doi.org/10.3390/app11219982
Chicago/Turabian StyleZhuang, Hongchao, Yilu Xia, Ning Wang, and Lei Dong. 2021. "High Inclusiveness and Accuracy Motion Blur Real-Time Gesture Recognition Based on YOLOv4 Model Combined Attention Mechanism and DeblurGanv2" Applied Sciences 11, no. 21: 9982. https://doi.org/10.3390/app11219982