1. Introduction
OSNs have gone well beyond information circulation, becoming a vital part of all human activities. The power of OSNs in diverting public opinion can be compared to and is frequently even greater than the power of traditional mass media or other forms of social interaction [
1]. Users of varying intentions and origins continuously interact and impact public opinion trends, sometimes with disruptive consequences. The public openness of OSN platforms has given ground to the rise of automated accounts which mimic human behavior. Such accounts, also known as
social bots, are machine or human controlled software, either benevolent or malevolent, depending on their intentions [
2]. The impact of such accounts has attracted the attention of the scientific community, as their spread and reach is constantly increased, while their activities are continuously refined and transformed.
Background. Particularly in Twitter, where the target audience is more vocal on differing opinions and ideologies, bots find fertile ground and ample opportunities in planting discord, stealing sensitive data and attracting users for personal gain. In many cases, such as the recent US elections, official government authorities are becoming increasingly aware of the interference of social bots in the voting process, by influencing the opinions of individuals [
3]. As OSN users become more engaged and absorbed in using media, different social bots with various intentions, focused on specific purposes, emerge. For example, there may be bot accounts, the primary purpose of which is to continuously spam explicit, questionable or misleading content in an attempt to spread false rumors and news, known as
spam bots [
4,
5,
6,
7]. Another emerging instance of accounts are politically infused bots, namely
political bots, that get actively involved in elections and political debates in order to sow discord and deconstruct democratic procedures [
8,
9,
10,
11,
12]. There are also bot-assisted humans or human-assisted bots, known as
cyborgs [
13] and even
self-declared bots [
9], which are accounts that announce their bot identity.
It is evident that the threat that bots impose on OSNs is alarming as they frequently create practical confrontations between individuals. These threats expand beyond individual harm and can create rifts and divisions between communities, polarizing the public [
14,
15]. Social bots have frequently been employed in voicing negative opinions on sensitive matters (e.g., climate change) [
16], causing harmful consequences. Moreover, they are also a challenge for the global economy, as their intrusion in internet traffic [
17] and online transactions jeopardize the transparency of economic disputes and the protection of global economic data [
18,
19]. Characterizing all social bot accounts as ill-willed would be inaccurate, as there are many that are neutral or even beneficial for users [
20]. However, the unfortunate reality is that the majority of social bot accounts do not have benign purposes [
21].
Challenges. Recent research has shown that in order to avoid being suspended, social bot accounts can potentially learn to adapt in human behaviors; they show evidence of evolution [
22] and linger in social media for prolonged periods of time, further expanding their functions. What is also worrying, is the fact that humans seem to have a hard time distinguishing bot from human accounts [
23]. Although Twitter itself has put a lot of effort into detecting and removing fake and bot accounts [
24,
25,
26], the issue still remains. Thus, detecting and tackling bot accounts is of vital importance for the structure of society to function properly. In accordance with this purpose, existing and recent bibliographies have focused mainly on developing robust frameworks and algorithms that can distinguish human from bot accounts and pinpoint some guidelines for future detection and suspension of such accounts. Dominant among the proposed methodologies are mainly supervised and some unsupervised ML approaches which combine network dynamics for a well-rounded framework.
While significant research has been undertaken in detecting social bot accounts, there is a notable gap in distinguishing different types of bots and inferring what differentiates them [
22]. The challenges that arise in this type of detection is that the existing developed models are suited for the binary classification of accounts and cannot be easily adjusted for the refined needs of detecting different type of bots. To facilitate the identification of different bots and eventually dictate new guidelines for tackling these accounts, a new ML approach is highly important.
This work is motivated by the strong need of a refined framework which will advance ML algorithms to surpass the limitations of a simple bot or human distinction.
Another potential challenge is that behavioral information for the different characteristics of bot types is limited, and thus determining their varied traits requires more than a simple ML algorithm. Currently, there is restrained support in explaining the attributes that differentiate bot accounts (e.g., a spam bot from a simple bot). This creates a cloud of confusion in present bot detection models, as the plain labeling of bot or human cannot reveal the category of a bot account, nor the characteristics that led to this categorization. The present bibliography on bot detection adduces an impressive number of features employed in the detection of bots and humans. These features belong in several categories and serve different purposes on predicting the probability of an account being a bot. However, an open subject of research is the examination of the importance of these features in prediction and the deployment of an inferential process that could determine which features truly matter during a bot type classification. This work builds an efficient bot type detection approach which is more robust, exploiting the emerging field of explainable ML to provide feedback on the different classification of bot types.
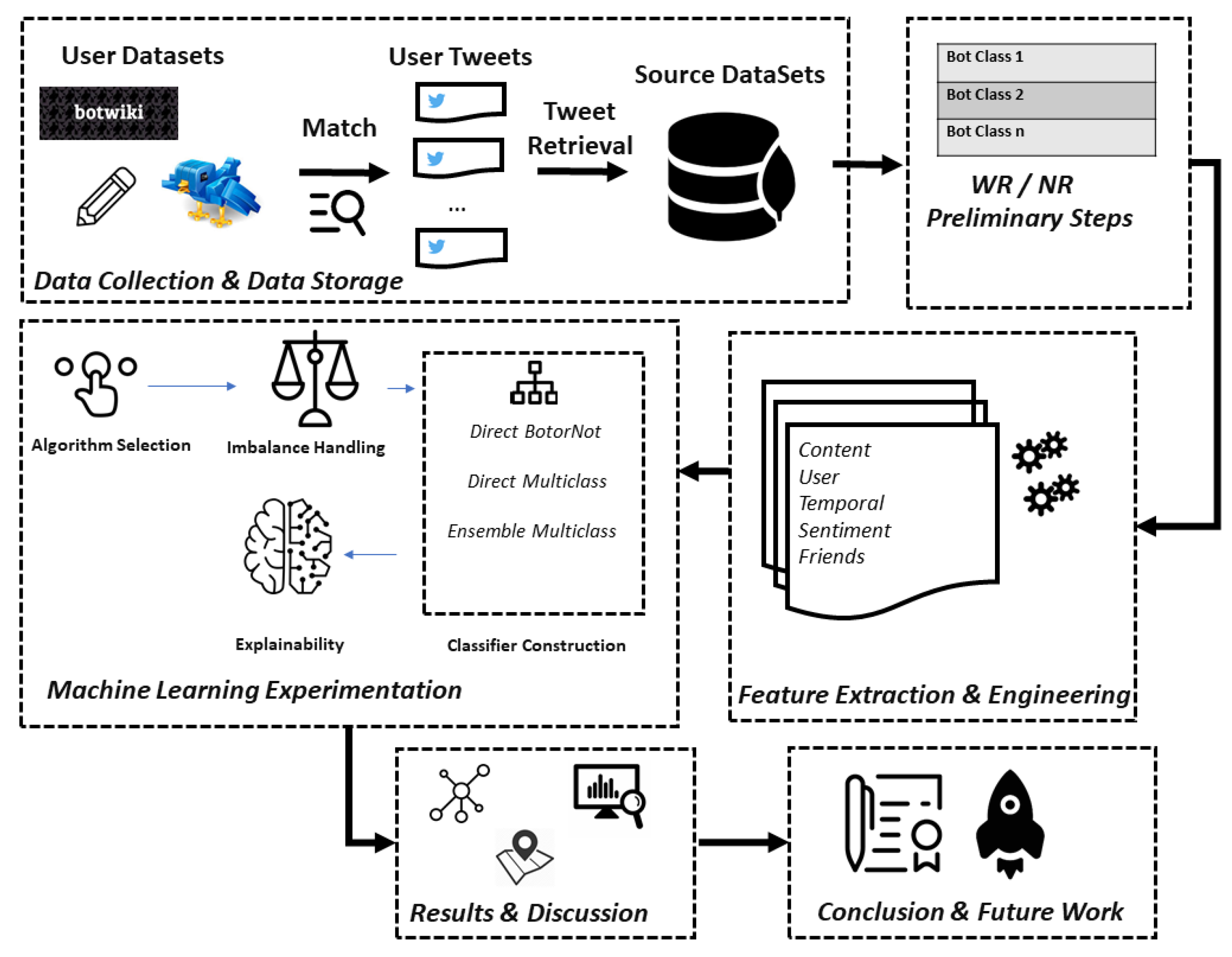
Contributions. The above interconnected challenges have motivated this work which aims to cover the current research gap of multi-class bot detection, while also enhancing and improving current state-of-the-art practices with explainable and feature engineering methods. In summary, the major contributions of this work are the following:
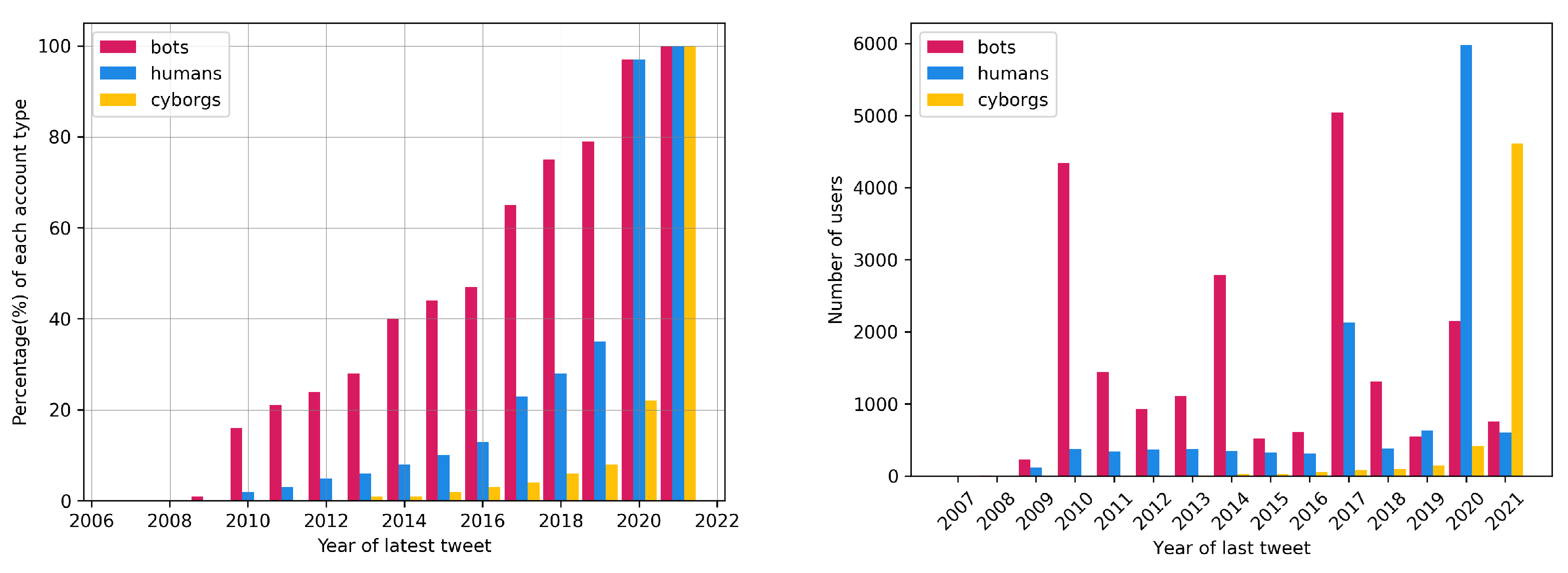
Newly introduced bot categories and extensive exploratory analysis of datasets: We perform an exploratory analysis of all open datasets and reveal that most of them are outdated and do not keep pace with the evolutionary nature of bots (as discussed in
Section 3). Based on this analysis, we define new bot categories that have not been detected in previous bibliographies and map them to the training datasets of our classifiers, enriching a robust multi-class detection schema.
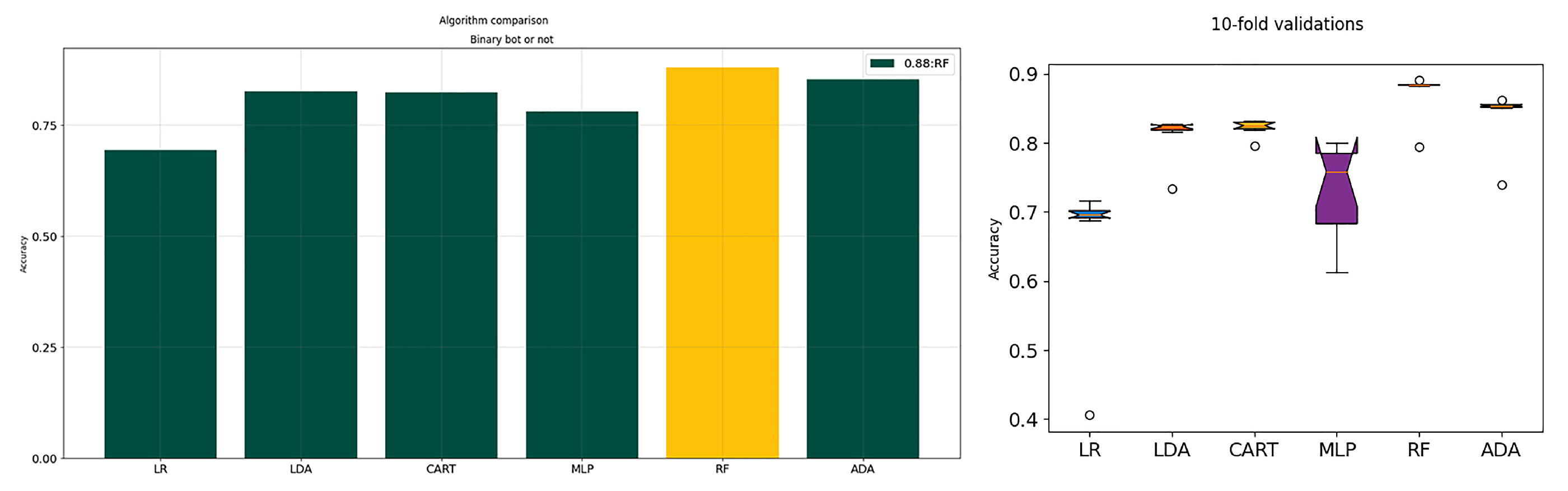
New ML models: We implement a set of classifiers combined with imbalance handling techniques, which in contrast to most previous works, are able to identify different types of bots. Our approach competes with existing state-of-the-art ML approaches, despite the multi-class classification challenges, as presented in
Section 5.2. We also provide a publicly available web application and open API which uses these models for inferring both the probability of an account being a bot and the probability of it being a specific type of bot, at
bot-detectiveV2.csd.auth.gr (accessed on 1 October 2021). We open our source code at
https://github.com/idimitriadis/Botomics (accessed on 1 October 2021).
Two-stage multi-feature engineering: A multi-feature engineering process is introduced, aiming to examine the performance of the classifiers under different combinations of feature categories (as described in
Section 4.1). Our experimentation has shown that even with few features, we achieve a high classification performance.
An explainable and exploratory ML framework: In contrast to most previous work that had not emphasized the explainability of their results, we rationalize the predictions of the proposed classifiers (see
Section 6). To that end, we utilize popular explainability frameworks, in conjunction with statistical methods, in order to profile each bot category, based on the features that mostly affect their prediction. Apart from providing bot probability scores with the use of the API, we also offer a web portal which also returns textual feature explanatory snippets to unfold the classification prediction steps.
Reproducible data sharing: We build and open two new datasets of accounts enhanced with the newly detected bot categories, which have not been included in the current status of bot and human account datasets. These datasets augment the different sources of bot types, contributing to further scientific research in the field.
The remainder of this paper is organized as follows:
Section 2 summarizes the related work.
Section 3 discusses the process of data collection and the results of our exploratory analysis, while
Section 4 outlines our feature engineering approach and ML methodology.
Section 5 presents the experimental results of our research and
Section 6 describes our explainability approach. Finally,
Section 7 and
Section 8 include the discussion, conclusions and future potential regarding this paper.
2. Related Work
Before delving into the developed methods and algorithms for bot detection, it is important to highlight the nature of a bot and its functionalities. According to Botwiki (
https://botwiki.org/bots/, accessed on 1 October 2021), a bot is “a software application that runs automated tasks over the Internet. Typically, bots perform tasks that are both simple and structurally repetitive, at a much higher and intense rate than would be possible for a human alone.” A different interpretation is that a bot is “a software application that is programmed to do certain tasks” (
https://www.cloudflare.com/learning/bots/what-is-a-bot/, accessed on 1 October 2021). Essentially, bots are automated tools that function without the need for human intervention or control, except when control is defined by research objectives [
13]. Their purpose is to perform repetitive tasks that would seem mundane or time consuming for humans, exhibiting much faster rates than a human account. A practical and more humanly intuitive notion is that bots are “predictable automatons that do not have the capacity for emotions, meaning-making, creativity, and sociality” [
27].
Bots exponentially gain ground in OSNs and their dominance is already evident. For example, according to a recent survey, two thirds of the URLs shared in Twitter feeds are posted by bots [
28]. As the popularity of bots grows and social media platforms routinely benefit or are harmed by their use, researchers have turned their attention to tracking bots, especially on Twitter. During the past years, there have been various attempts at detecting a bot, or specific categories of bots. In general, the timeline of bot detection spans a decade, with research studies increasing in later years [
22]. As the popularity of bots grows and social media platforms routinely benefit or are harmed by their use, researchers have turned their attention to tracking bots, especially on Twitter. This can be further highlighted by the wide influence of bots in presidential elections [
29,
30], financial markets [
19], pandemic related news [
31] and cryptocurrency manipulation [
32] as well as the various and different bot categories [
2], and particularly social bots [
33].
Recent studies have highlighted that the majority of existing literature relies either on ML approaches or unsupervised methodologies in order to construct robust implementations that fulfill this purpose. There have also been attempts that provide web-based tools which gather data related to user accounts on social media from specialized APIs and infer if the account is a bot. In the following we will review the latest and most important bot detection approaches.
Regarding supervised approaches and spam bots, Ref. [
34] is the first attempted research work that refers to spam bot detection via an ML Classifier. Apart from classifying Twitter accounts as spam bot or human, this work takes the first step towards exploring the major characteristics of spam bot accounts, such as tweet frequency, longevity and networks of followers. Spammers and social bots are also the central point of another paper [
35], where the authors construct fake accounts to attract spammer activity and exploit the accumulated data to construct robust classifiers based on textual and network features. However, it is fairly evident that, as detection methodologies evolve, so do bot accounts, which adapt and develop evasion strategies. Thus, Ref. [
36] proposes new features that are not affected by evasion strategies and are either graph related (clustering coefficient, betweenness centrality) or neighbor related (followers of neighbors, tweets of neighbors, etc.). This meticulous construction of features eventually yields good results, with low false positive rates. Several studies [
37,
38,
39] use Random Forest classifiers and rely on well-established user and content-based features for detection, while also examining the robustness of the utilized features. In addition, another approach [
40] enhances the current frameworks by adding behavioral features, in an effort to move away from single account detection and instead track groups of spambots. Finally, Ref. [
41] proposes a hybrid approach that primarily takes into account the interactions of a bot account with his followers and combines them with predefined features, constructing classifiers with high accuracy levels.
As far as social bots are concerned, a notable effort by [
10] constructs various novel datasets that contain social bots which act as fake follower inflators for Twitter accounts. Along with this addition, they simultaneously examine the efficiency of different feature sets in conjunction with several different classifiers. The Random Forest classifier is once more proven dominant. BotOrNot [
5,
8,
9,
42], a more refined framework that utilizes over 1000 features distributed in several categories (user, content, network, sentiment) is also presented as a state-of-the-art solution in bot detection. In addition, BotorNot is one of the few solutions that actually perform multi-class classification of bots. The authors of [
28] propose a full-fledged framework that utilizes 1150 features and gives emphasis on the interactions between a genuine human account and a social bot account. More recent efforts [
43,
44,
45], move away from a simple classifier detection and instead focus on the malicious effect that social bots have on Twitter, by analyzing political and marketing campaigns or pointing out the biggest challenges in their detection, such as their evolving behavior, which largely imitates human actions. In addition, the latest methodologies include subsetting the bot accounts in order to select the best dataset setup for improved classifier accuracy [
8] and adversarial algorithms [
46,
47] that synthetically create social bot accounts to directly interact with other accounts, learn their strategies and improve detection rates. Apart from works that focus solely on bots, Ref. [
13] introduces the distinction between humans, bots and cyborgs (human controlled bots) and proposes an entropy-based framework to classify them.
Unsupervised approaches are still gaining ground, thus research ventures are notably limited in comparison with supervised methodologies. Researchers in [
48] use statistical inference and behavioral features to trace clusters of extroverted users, labelling them as social bot accounts. Behavioral similarities are also the primary subject of [
49] which via unsupervised simulations reveal suspicious activities. An online framework, namely DeBot, that does not require labeled data and is focused on correlated activities between accounts was presented in [
50]. The rationale of this approach is that two accounts that appear to have highly similar activities are likely to be bots. The metric of temporal synchronicity is the core aspect of Debot in detecting simultaneous changes in the state of discrete elements. In the same spirit Rtbust [
51], is another unsupervised framework that exploits temporal patterns (retweets, mentions, likes) to highlight malicious activity.
Recent studies have explored group approaches, that cannot be considered either supervised or unsupervised. Their focus is drawn towards botnets, which can be conceptualized as groups of bots that act together to achieve a common purpose. Notable in these methodologies are network approaches that attempt to detect synchronized and suspicious account behavior [
52,
53,
54], analyze the connectivity of such accounts and propose appropriate countermeasures for their detection and deactivation.
Despite their robustness and effectiveness, bot detection methodologies have recently been criticized for some crucial deficiencies. As bot behaviors evolve over time, the produced methodologies are sometimes unable to stay up to date and are rendered useless in detection campaigns [
6], while it has been pointed out that focusing on the evasion strategies of bots rather than simply detecting their presence is the next logical step towards the evolution of the field [
55]. In addition, the need for training the classifiers on previously unknown bot classes in order to potentially increase their efficiency is raised as an urgent solution to restrained accuracy scores [
56]. One of the main issues that emerge is the lack of credible, annotated datasets, on which supervised solutions are trained [
57]. At this point it should also be mentioned that only a few works pay attention to the intrepretability of their results [
8,
58,
59], highlighting the need for more explainable models. Last but not least, bot detection platforms have been proven to be prone to increased false positive rates [
60], a fact that hinders and reduces their credibility.
Our work provides a holistic approach in an attempt to fill the identified gaps, by broadening the scope of its research, rather than focusing on solving a particular issue. More specifically, our work initially presents an exploratory analysis of the open datasets, which have been used by all the previous works, and uncovers that most of these data are unavailable or outdated. At the same time, as recommended above, we propose a new validated division of different bot types, based on the description of each available dataset. Although feature engineering has been extensively discussed, we extend this work by providing a complete analysis for features used in binary- and multi-class bot classification tasks, while we also offer credible, interpretable results. Finally, we present a set of both binary- and multi-class ML models, inspired by [
9], which offer competing results, in comparison to current state-of-the-art approaches.
6. Explainability and Statistical Analysis
As highlighted in our previous work [
58], targeting bot detection without explainable functionality is prohibiting in decision rationalization and trustfulness. In this work, the predictions of our models are augmented with highlighting the features that define whether an account is a human or a bot and provide the reasoning behind this prediction. Most importantly, in the multi-class detection problem, this strategy showcases the differences in each bot class, to reflect the behavior of accounts belonging in each class.
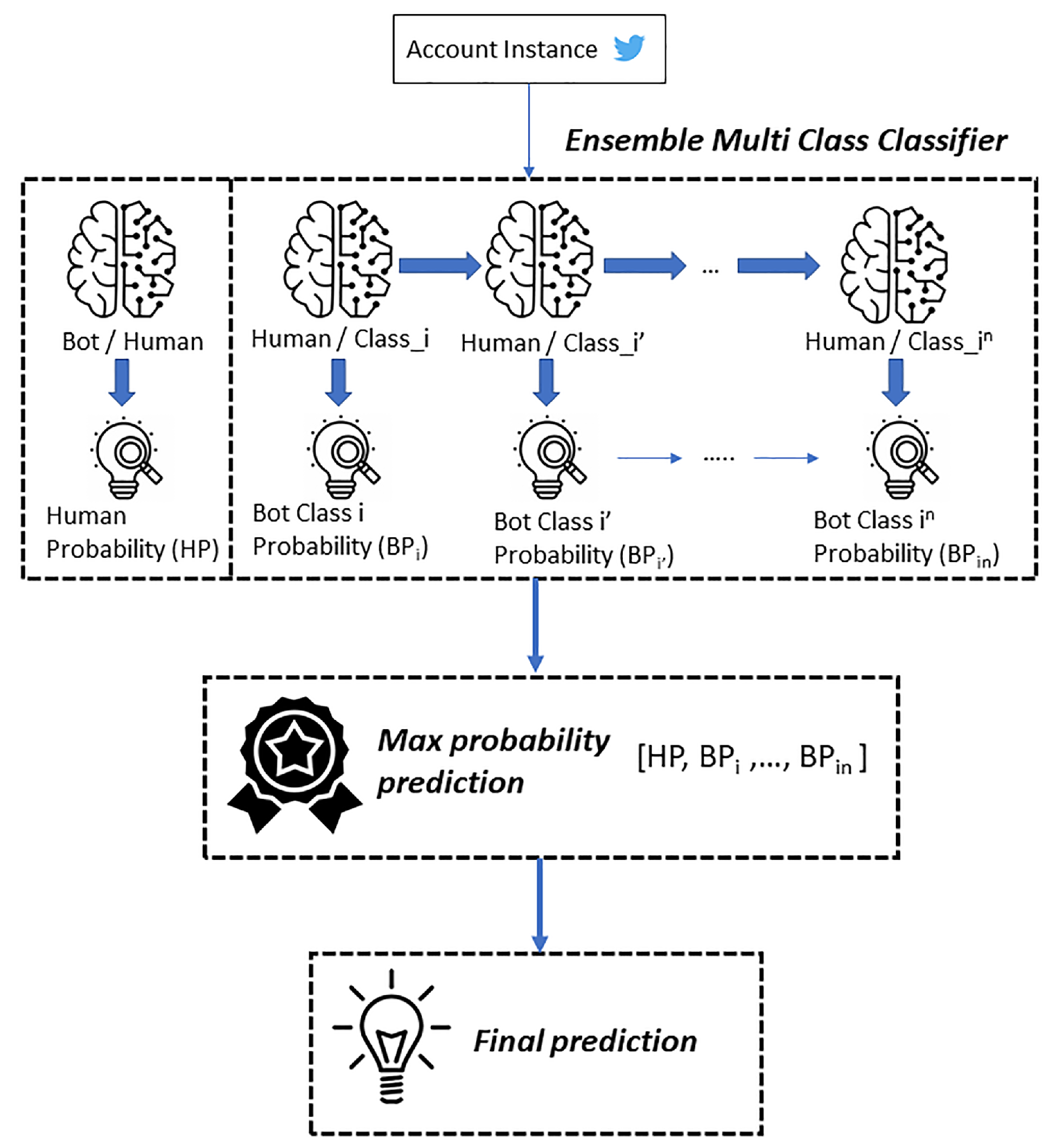
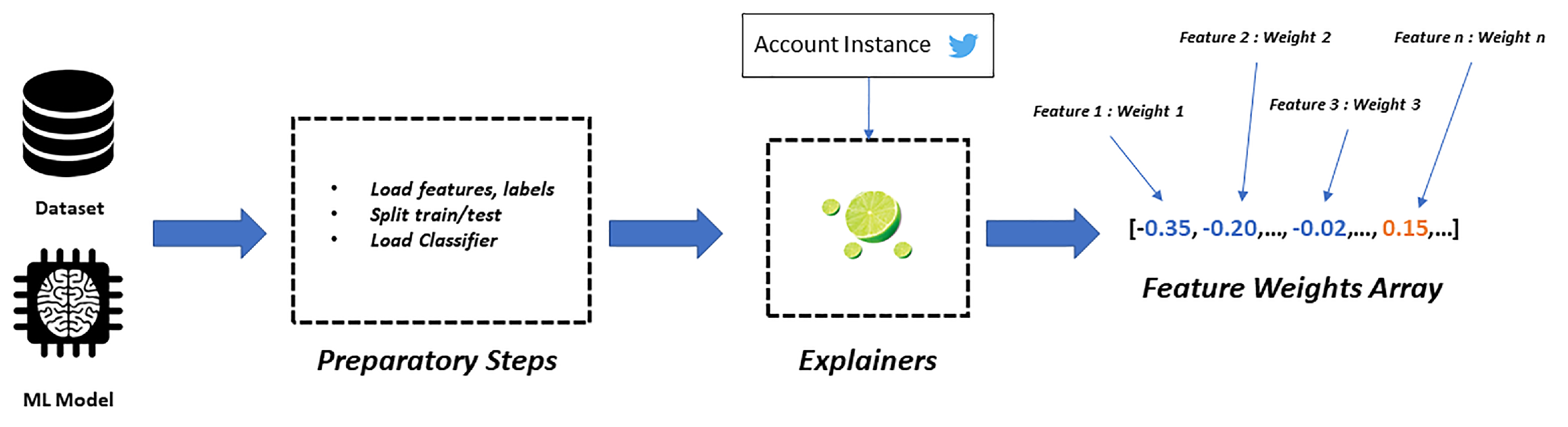
This work proposes a simple and flexible explainability pipeline (outlined in
Figure 9). Although a Random Forest classifier provides interpretable results by design, its explainability can not be utilized in our case due to the large number of features and number of estimators used. In our explainability pipeline we use the widely accepted LIME [
66] as our explainer, to offer interpretable predictions of the binary classifier or/and the multi-class classifier.
The explainability phase, as depicted in
Figure 1, resulted in explainer predictions for each instance, accompanied with the features that affected this prediction, all adjusted in the framework of the model that we were examining per explainer. For example, the explanations of the baseline binary classifier would have a “bot” or “human” label predicted by the classifier, and interpreted by the explainer, a true label of the same value which can obviously be close to the found label and the top ten features with their corresponding weights. Even though the results of the explainers are quite useful in not only validating the feature engineering process, but also shedding a clear light on what differentiates bot classes, they still remain static representations and lack a graphical visualization. To that end, once we completed the explaining process by conducting a statistical analysis and measurement in order to pinpoint the varying aspects of each class, distribution plots were utilized for the top features of each class belonging to the two classifiers that portrayed the distribution of values for every instance of the datasets. Moreover, we experimented with some key parameters of the explainability framework, in an effort to provide as realistic and accurate results, as possible. Our work towards this direction is further presented below.
Refining Explainable Results
Previous work on explaining the results of human–bot classifiers has been strictly based on providing some information on the features that define each prediction. Moreover, this analysis has only been applied to binary classifiers. In this section, we present our attempt to provide improved results, not only by experimenting with different parameters, but by extending the application to all bot types that are referred to in this paper.
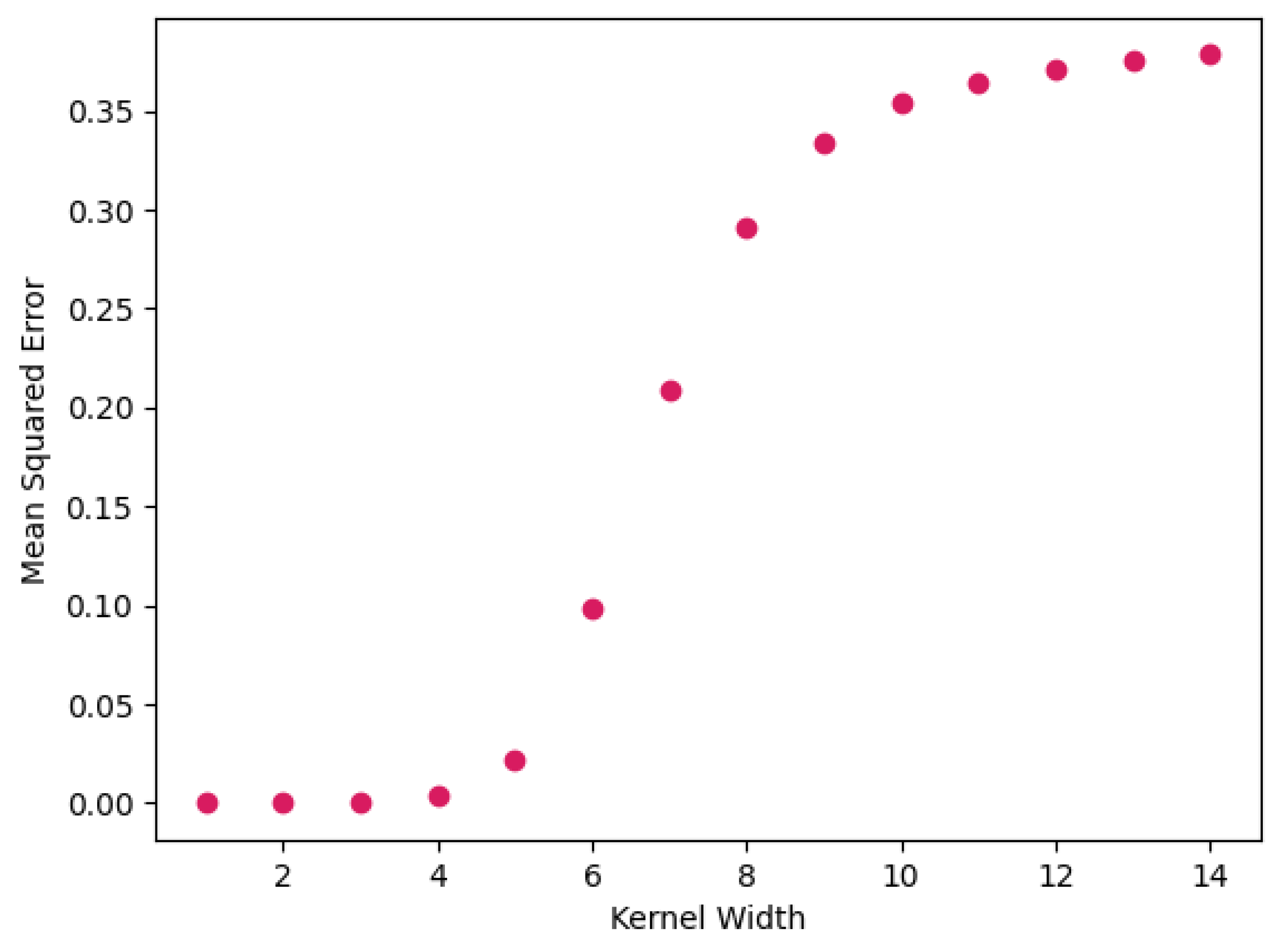
We will use a popular explainability framework called LIME. Although LIME is considered to be a state-of-the-art tool for ML interpretability, recent research has shown that in some cases it faces some issues of instability [
67,
68], mainly due to the sampling step when new instances are randomly chosen. Improving the model is beyond the scope of this paper, however we experiment with different kernel widths, which seem to greatly affect the predictions made by LIME in comparison to those produced by our ML models, see
Figure 10. Kernel width actually defines the region around the reference point from which new points are generated.
In order to provide more realistic explanations, we calculated the mean squared error (MSE) of our ML model predictions to those of LIME for different kernel widths. We can clearly observe that as the kernel width parameter increases, so does the mean square error. However, having a really low MSE is not always what should be preferred, since setting the kernel width to a very low value would mean that our main goal would be to predict this exact point correctly, which is not the case. Thereby, in our experiments we set the kernel width value equal to five, which seems to complement the MSE with the generalization of our model.
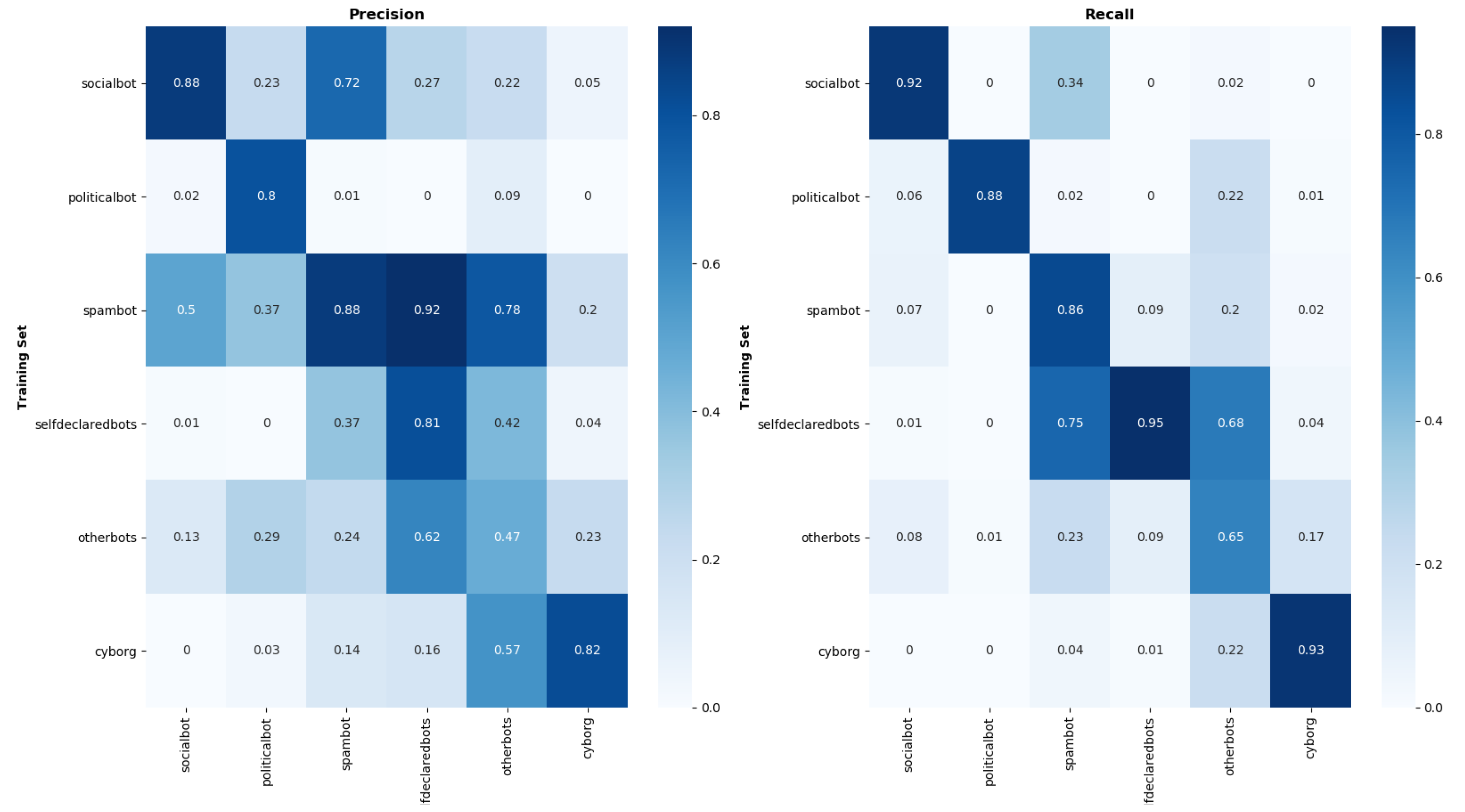
Initially we applied our explainability model to the BBC classifier, in order to highlight the main features that affect our model’s predictions. We created our explainer using the data that our model had been trained on and tested it on a sample of the spare test data. The next step involved applying a similar methodology for all the binary bot type classifiers, though limiting our dataset only to humans and certain bot types, depending on the classifier we were trying to interpret. The key findings are presented in
Table 9, along with the most important features per bot class.
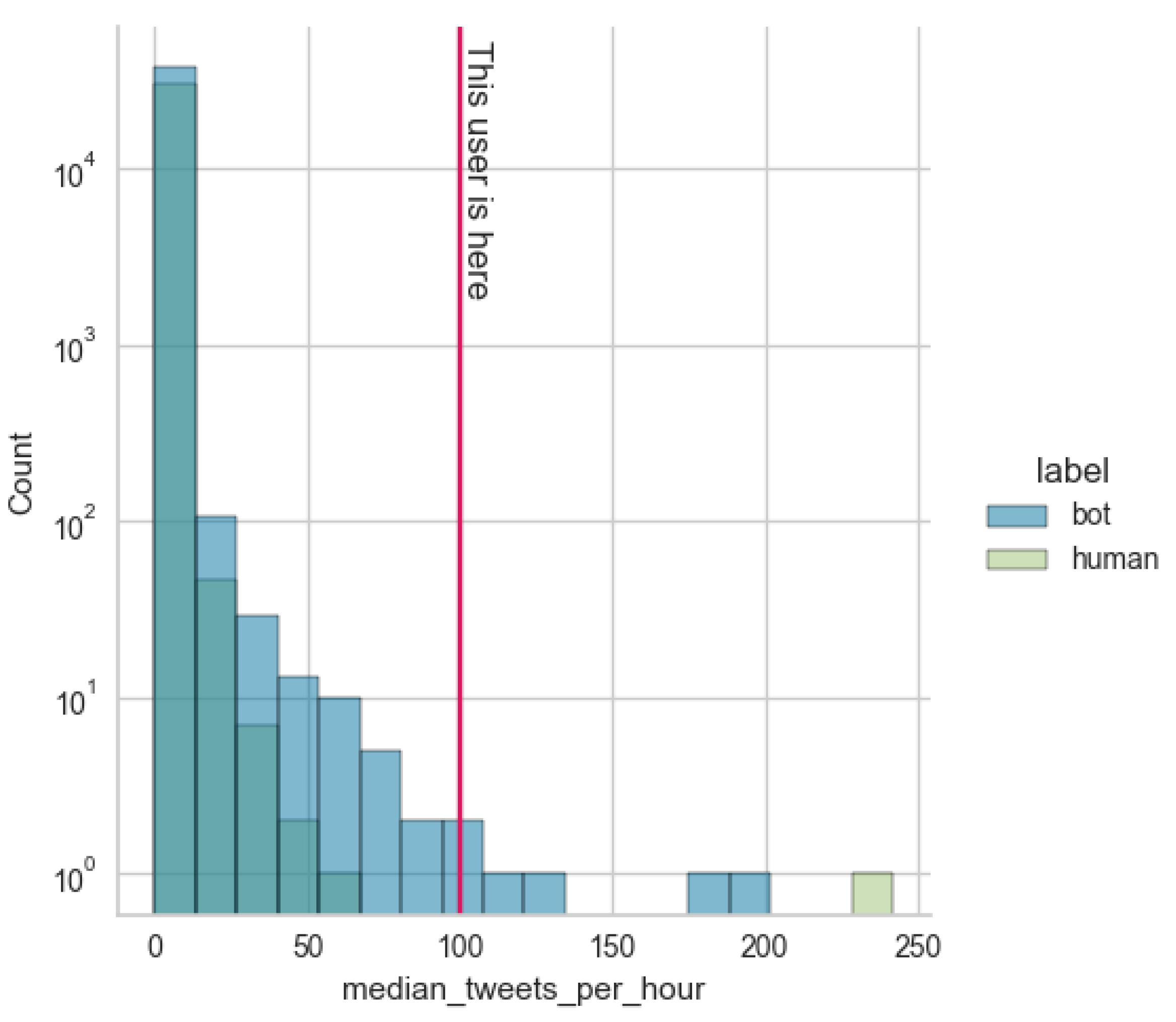
Finally, since our intentions included presenting an improved version of Bot-Detective, we decided to also present a visual explanation that rationalizes the prediction of our models, hence improving the interpretability of our results. To that end, our updated web service will also include figures which highlight the difference between the explored instance and the data that our model has been trained on. Such an example is presented in
Figure 11, where the red line depicts the explored instance, while the histogram refers to the bots and humans included in our dataset.
8. Conclusions and Future Work
In this paper we investigated the current state of supervised ML bot detection approaches on Twitter. We showed that the available data are mostly outdated and that previous research does not comply with the present data status, but rather focuses on past data. We also proposed a new bot type classification schema, based on the descriptions of the publicly available annotated datasets and newly introduced ones and proved its efficiency.
We perform a comprehensive feature analysis, enriched with explainability functionalities and demonstrate that different features account for different type of bots. Although we acknowledge the drawbacks of these data, we follow a different methodology to provide novel models for binary and multi-class bot detection. Our experiments show that our models perform really well on previously unseen data and that they generalize well, since they are tested on data coming from different datasets.
In future work, taking into consideration the lack of credible, up-to-date data, we intend to investigate adversarial methods to improve our models and make them adaptive to future, currently unobserved, new type of bots. Our main future goal would be to create novel generative models able to produce adversarial bot examples, leaving out the issue of data unavailability, and testing new discriminators against old and newly produced types of bots.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}