
Wind Power Forecasting with Deep Learning Networks: Time-Series Forecasting †

 , ,
, ,
Abstract
:1. Introduction
- Practically, most existing approaches to forecasting do not model the uncertainty of wind well. Thus, a high-accuracy wind power model needs high resolution weather data inputs generated by an NWP model, which is not a trivial task.
- Typically, deep learning-based neural networks for day ahead wind power forecasting outperform traditional neural networks such as ANN in renewable power forecasting problems, as these deep learning networks (DLNs) do not need extra data pre-processing, i.e., decomposition, in order to retrieve features from datasets.
- ▪
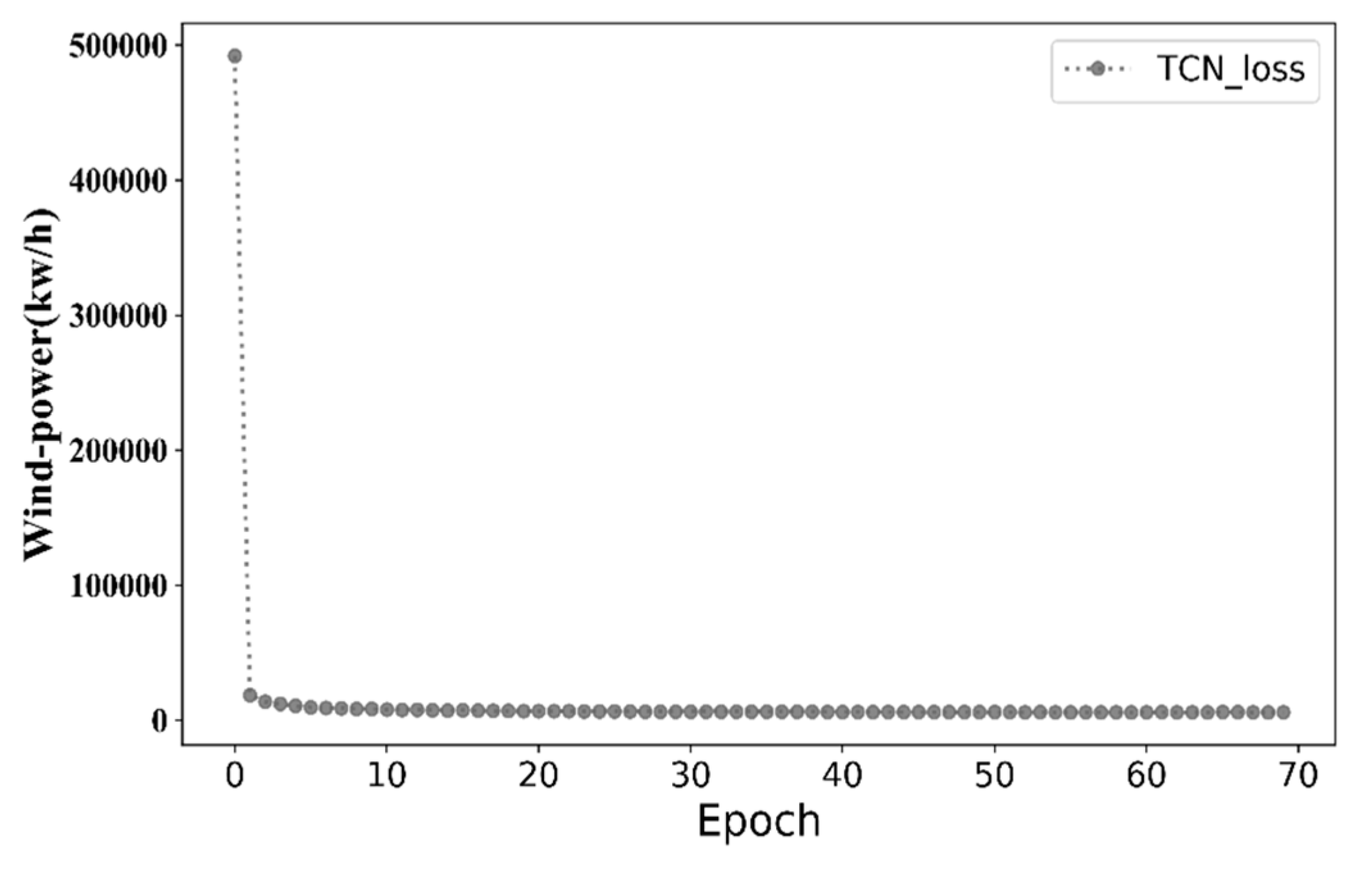
- The optimal parameters of the models were investigated using evolutionary algorithms (EAs) in order to minimize convergence loss in the learning process.
- ▪
- Four crucial architecture parameters for developed wind power prediction models were analysed, incorporating the differential evolution (DE) algorithm [16,17,18] in the learning process of the TCN model, namely, (i) number of filters, (ii) activation function, (iii) optimizer, and (iv) dilatation coefficient, in order to determine the initial model architecture for model training, according to the natural feature of TCN.
- ▪
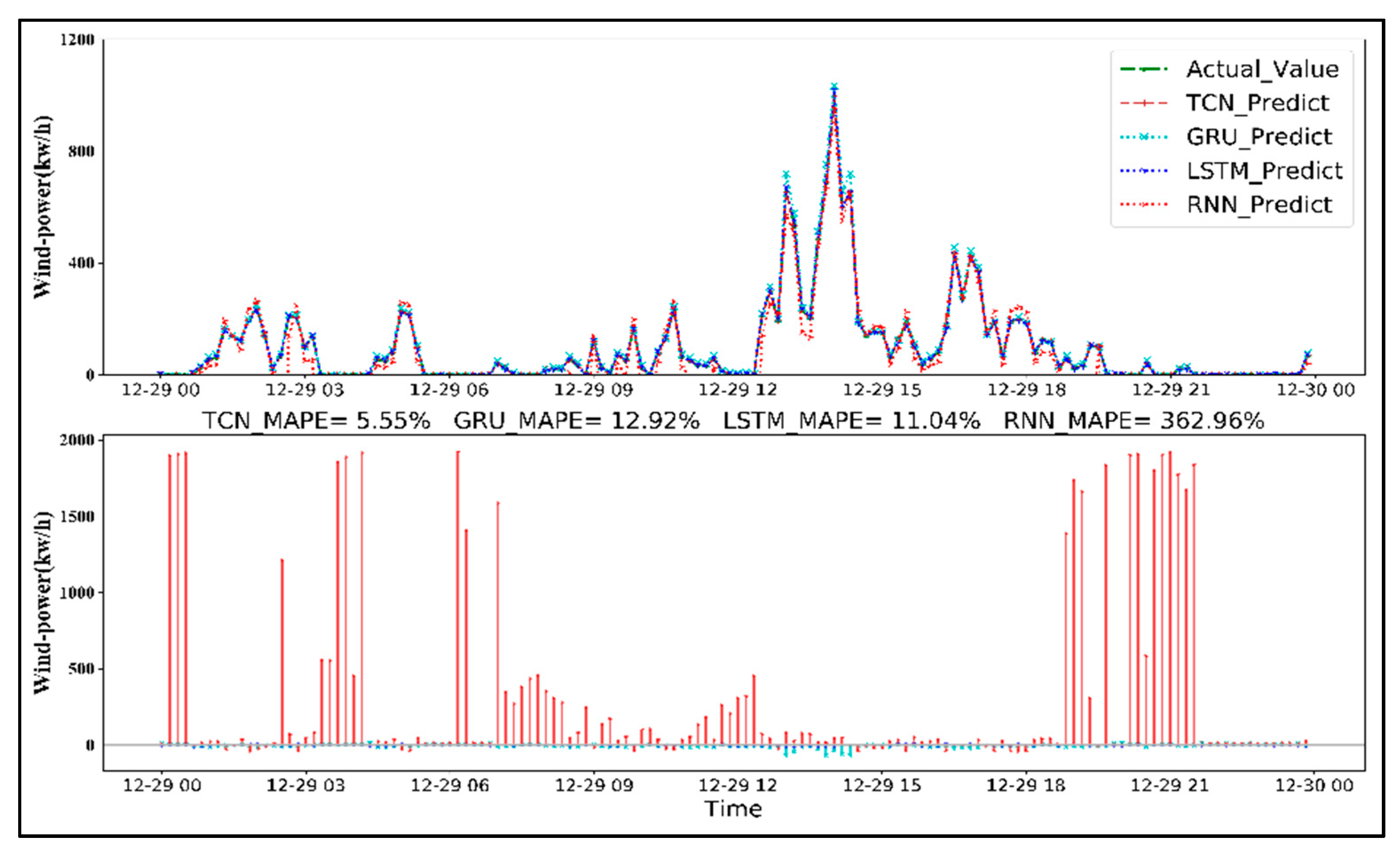
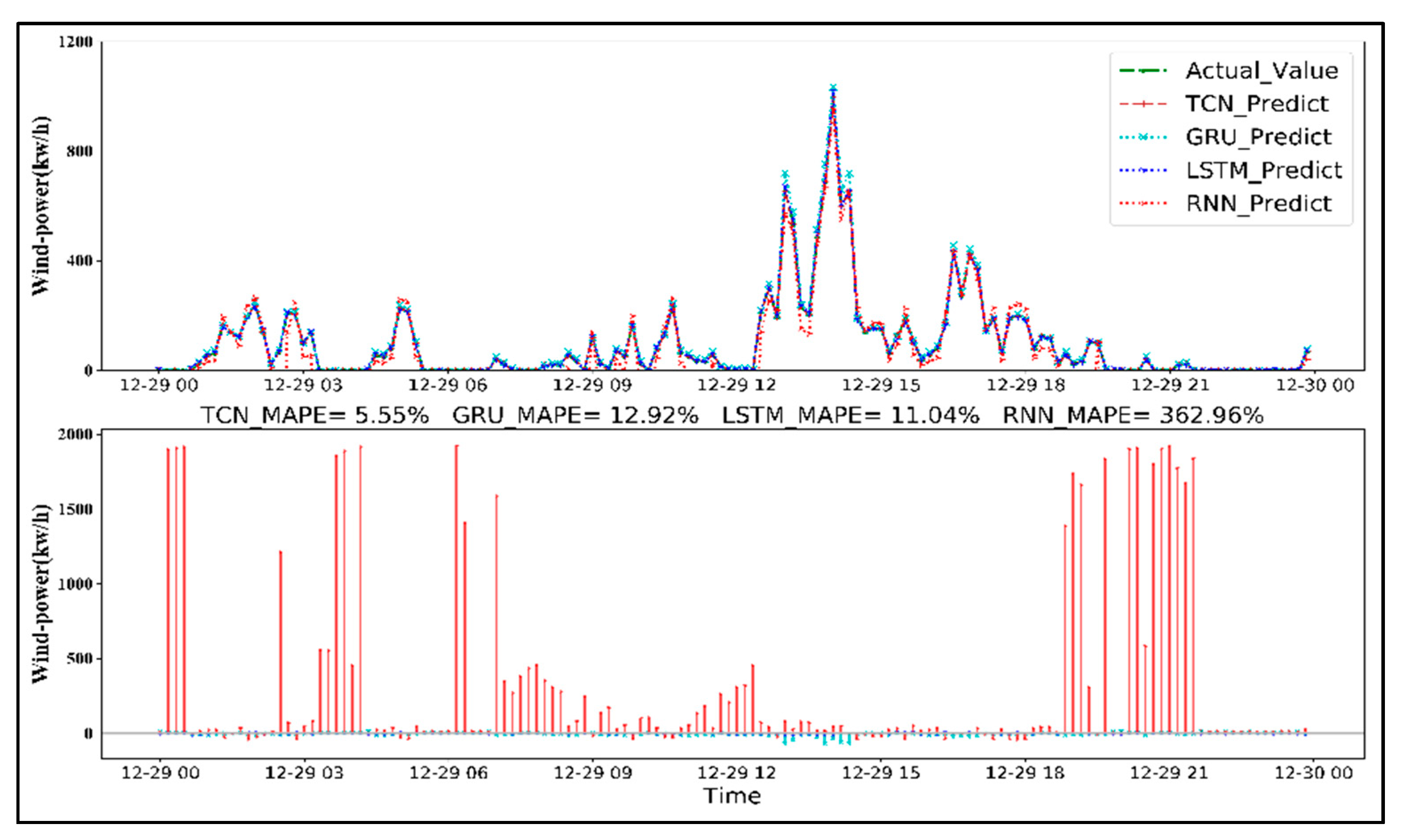
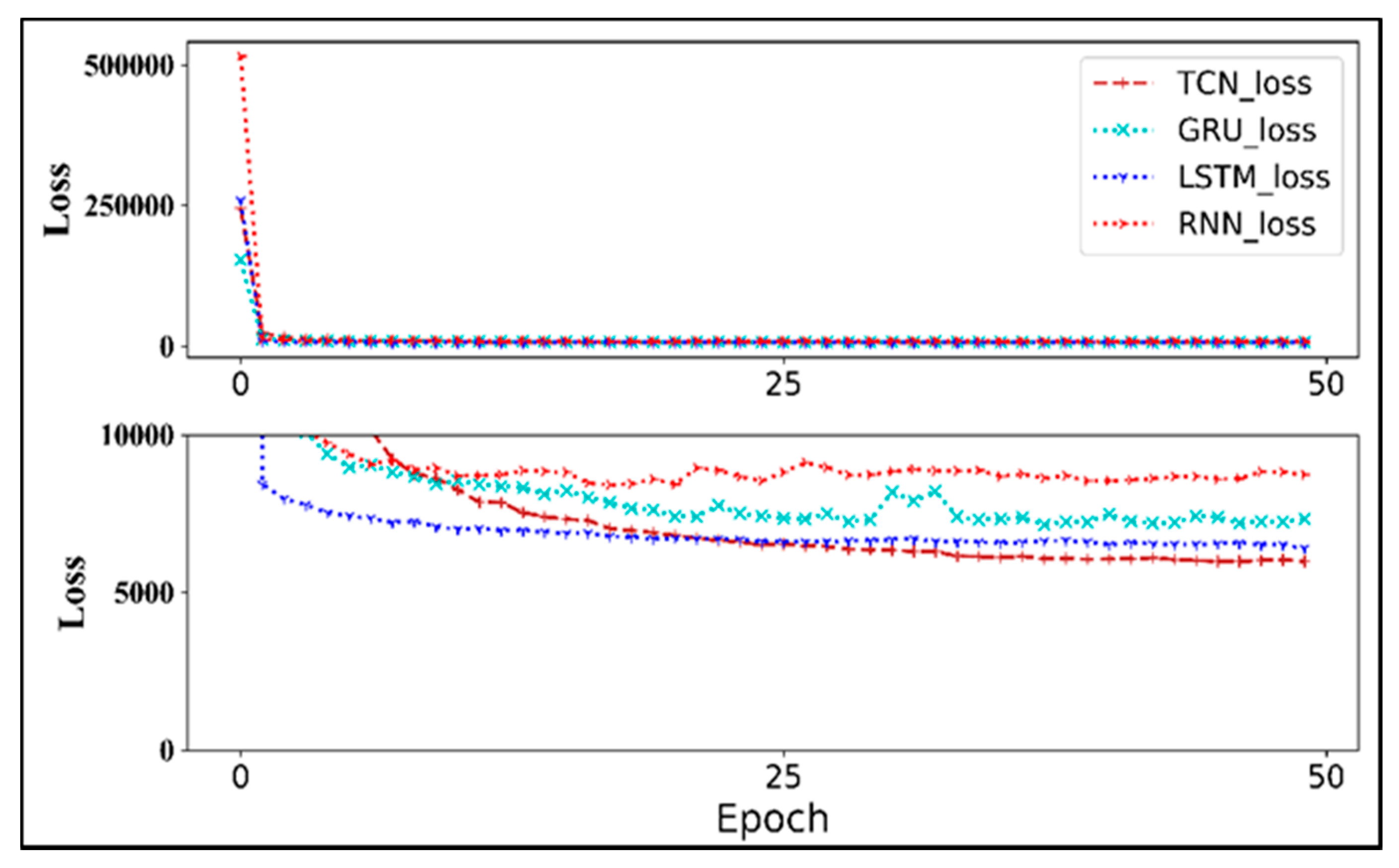
- In our experiment, the prediction error of the TCN model for wind power prediction decreased most steadily among the four models, followed by LSTM, GRU, and RNN.
- ▪
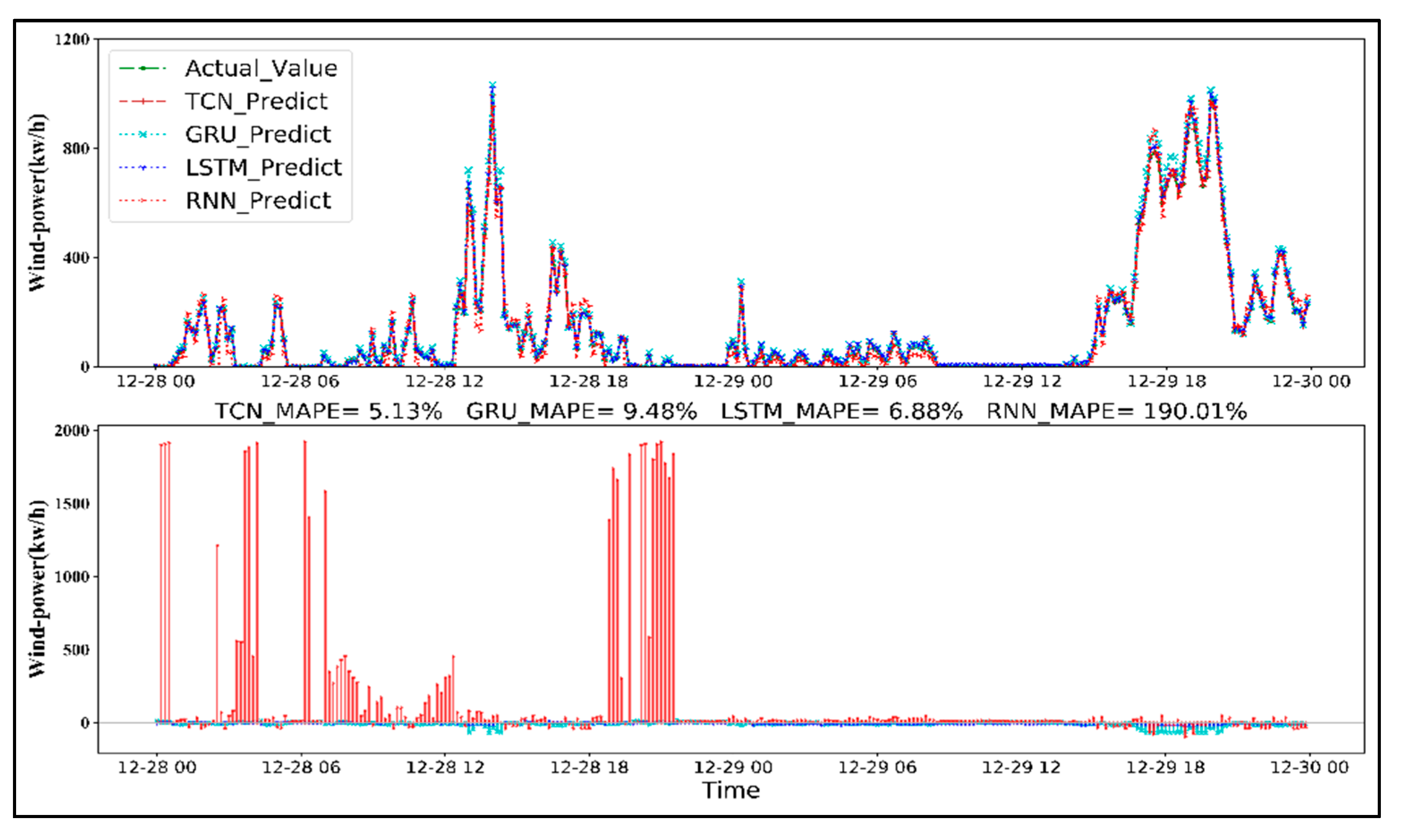
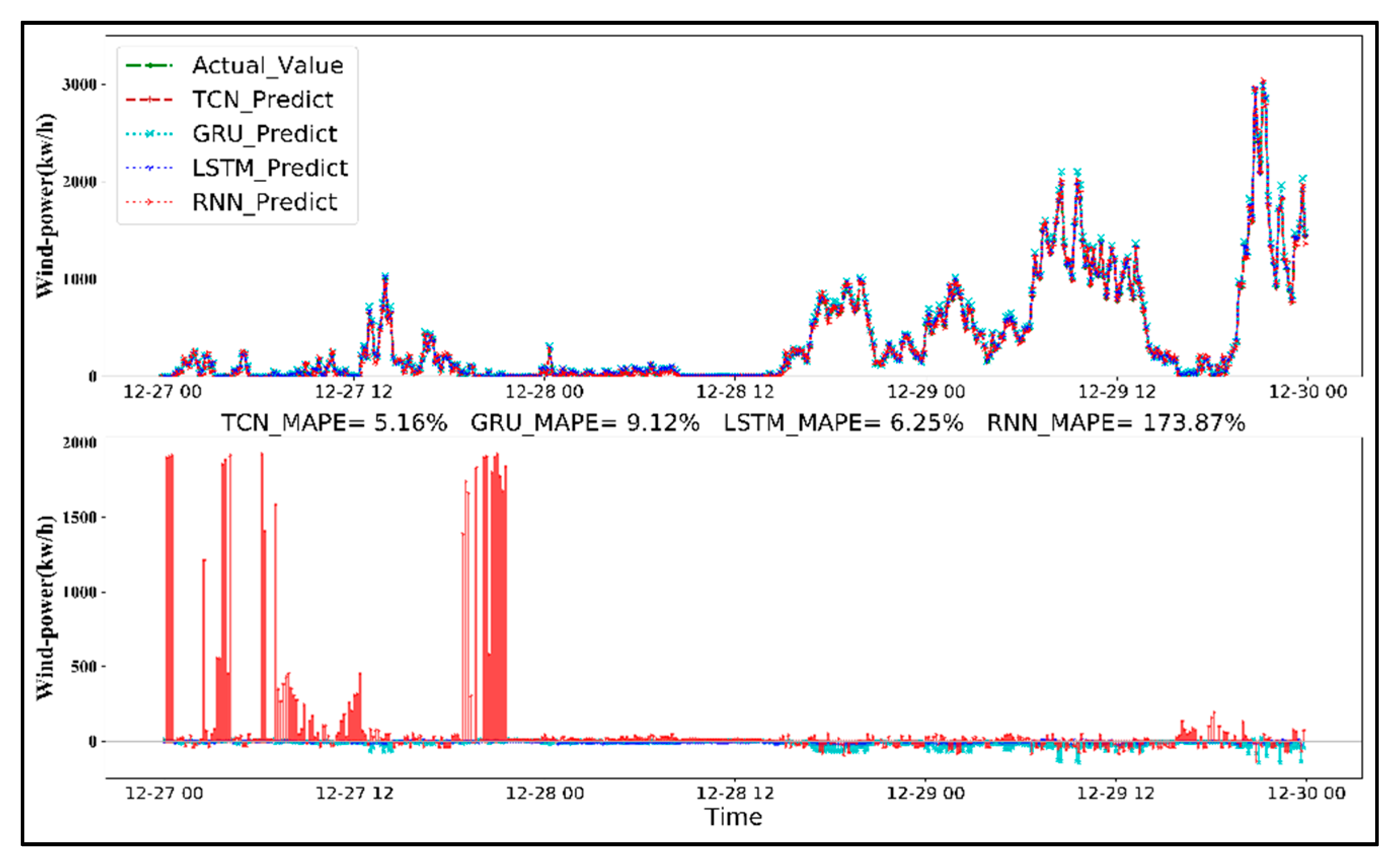
- With an increasing amount of historical data, the prediction error (MAPE) of the TCN-based model decreased significantly; the 72 h forecast error of the 1-week, 1-month, and 1-year training datasets was 66.43%, 10.93%, and 5.13%, respectively.
- ▪
- Compared with LSTM, GRU, and RNN models, the TCN model created long effective memory in the deep learning framework and exhibited a lower forecast error to predict 24-, 48-, and 72-h ahead of wind power generation, which is more suitable for sequence modeling based on sequence-to-sequence applications.
2. Literature Review
2.1. DNNs for Processing Time-Series Data
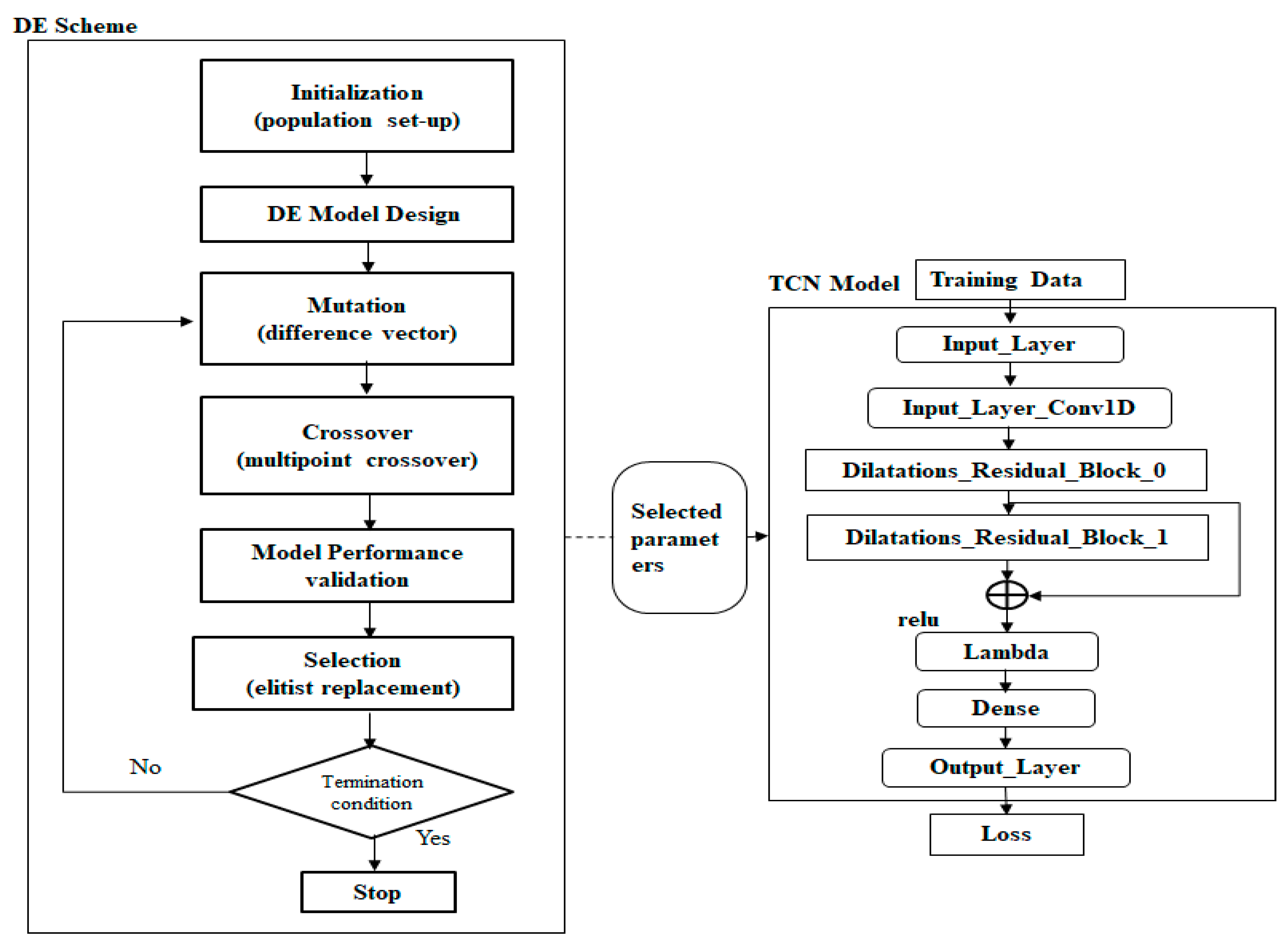
2.2. Differential Evolution Algorithm
- (i)
- Initialization
- (ii)
- Mutation
- (iii)
- Crossover
- (iv)
- Selection
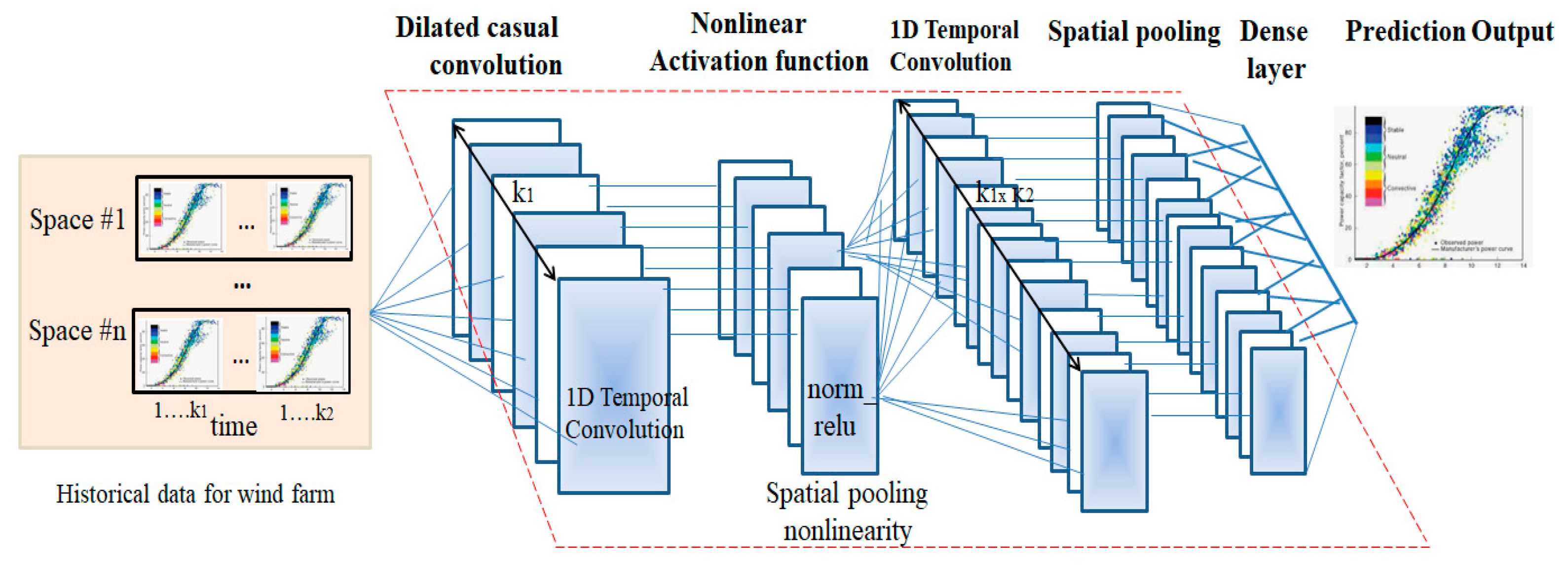
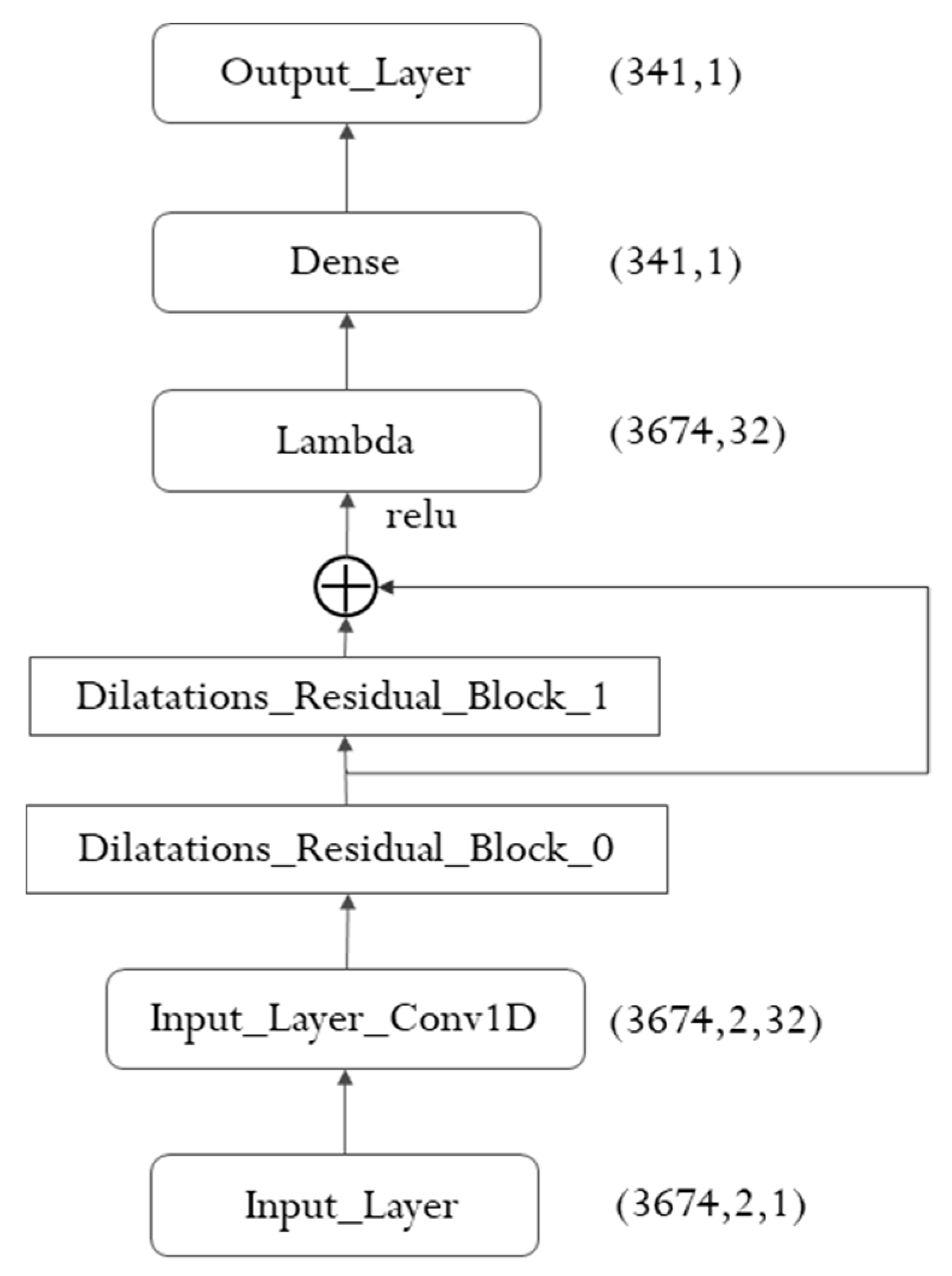
3. Wind Power Forecasting Model with Temporal Convolutional Networks
3.1. Architectural Design for TCN
3.2. Parameter Selection for TCN Model Using Evolutionary Algorithm
3.2.1. Preliminary Architecture Design
- (i)
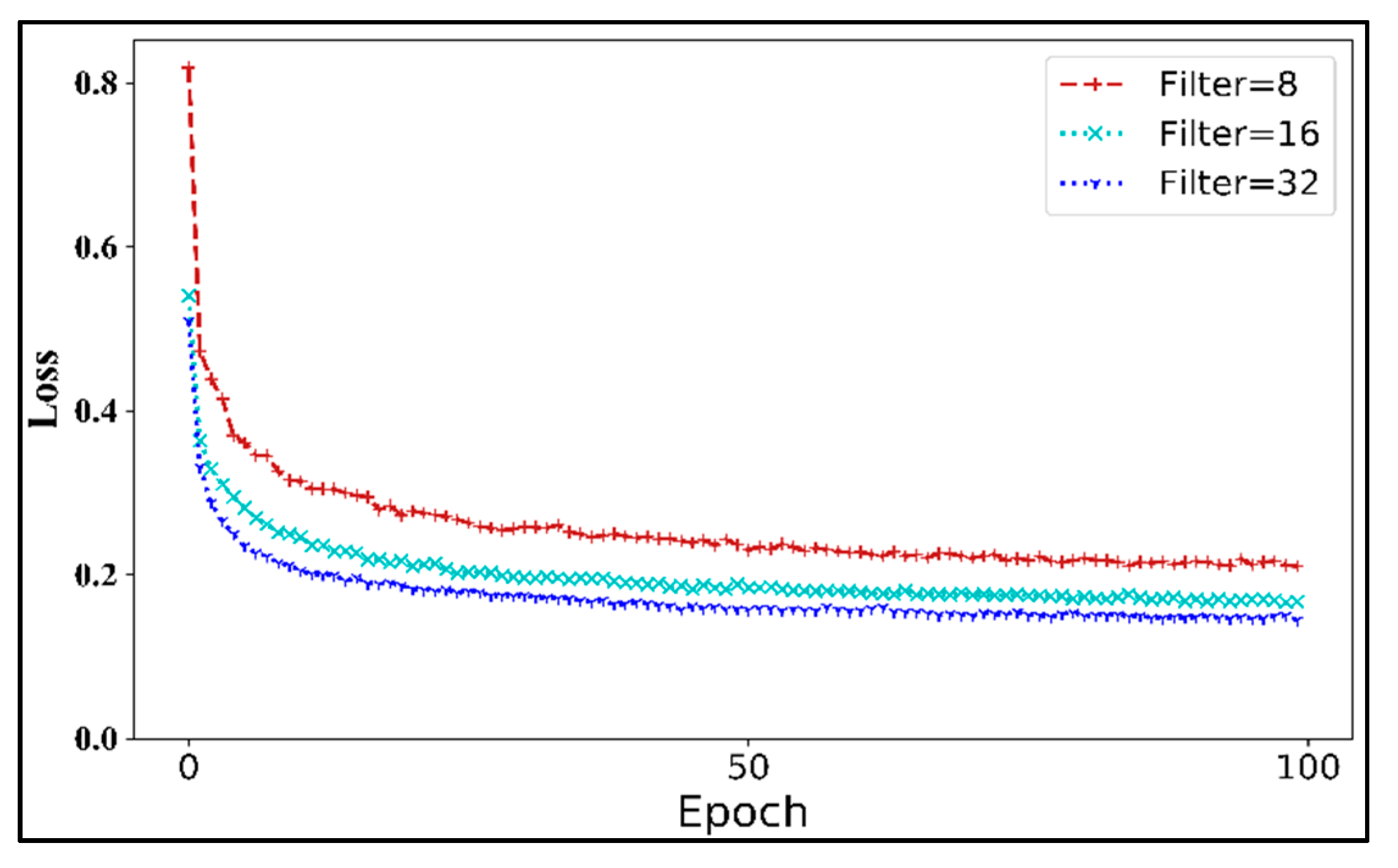
- Filter size
- (ii)
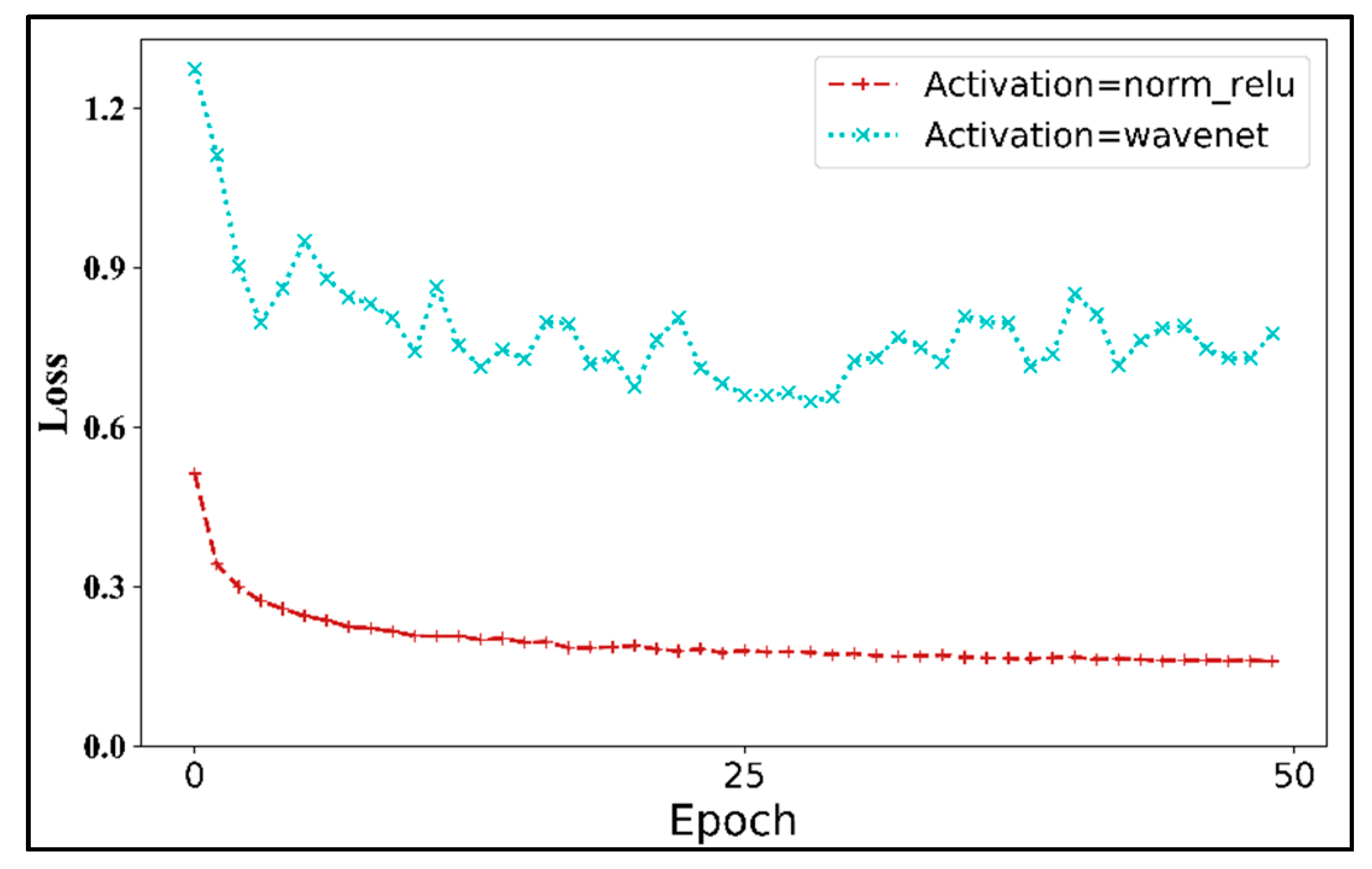
- Activation function
- (iii)
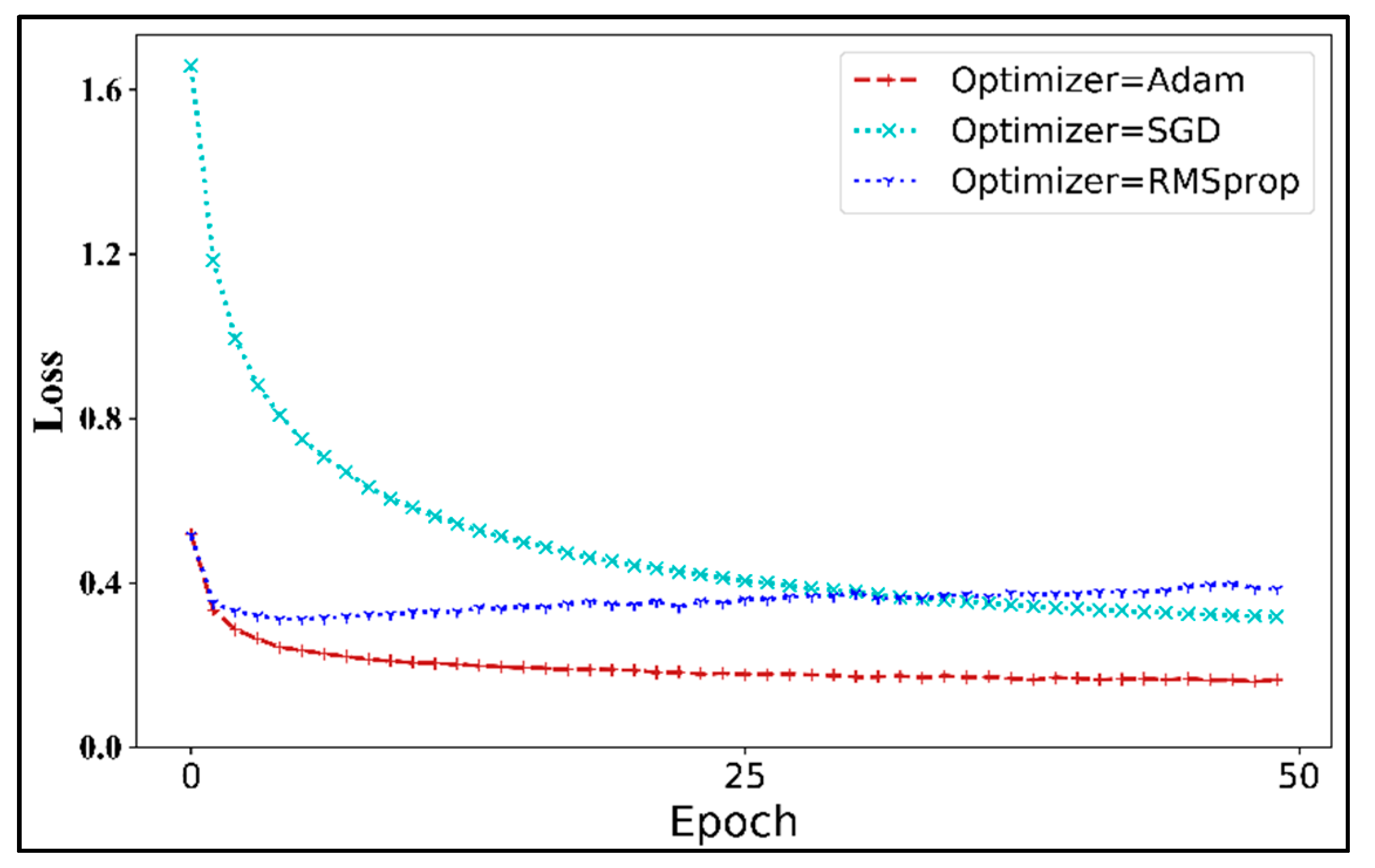
- Optimizer
- (iv)
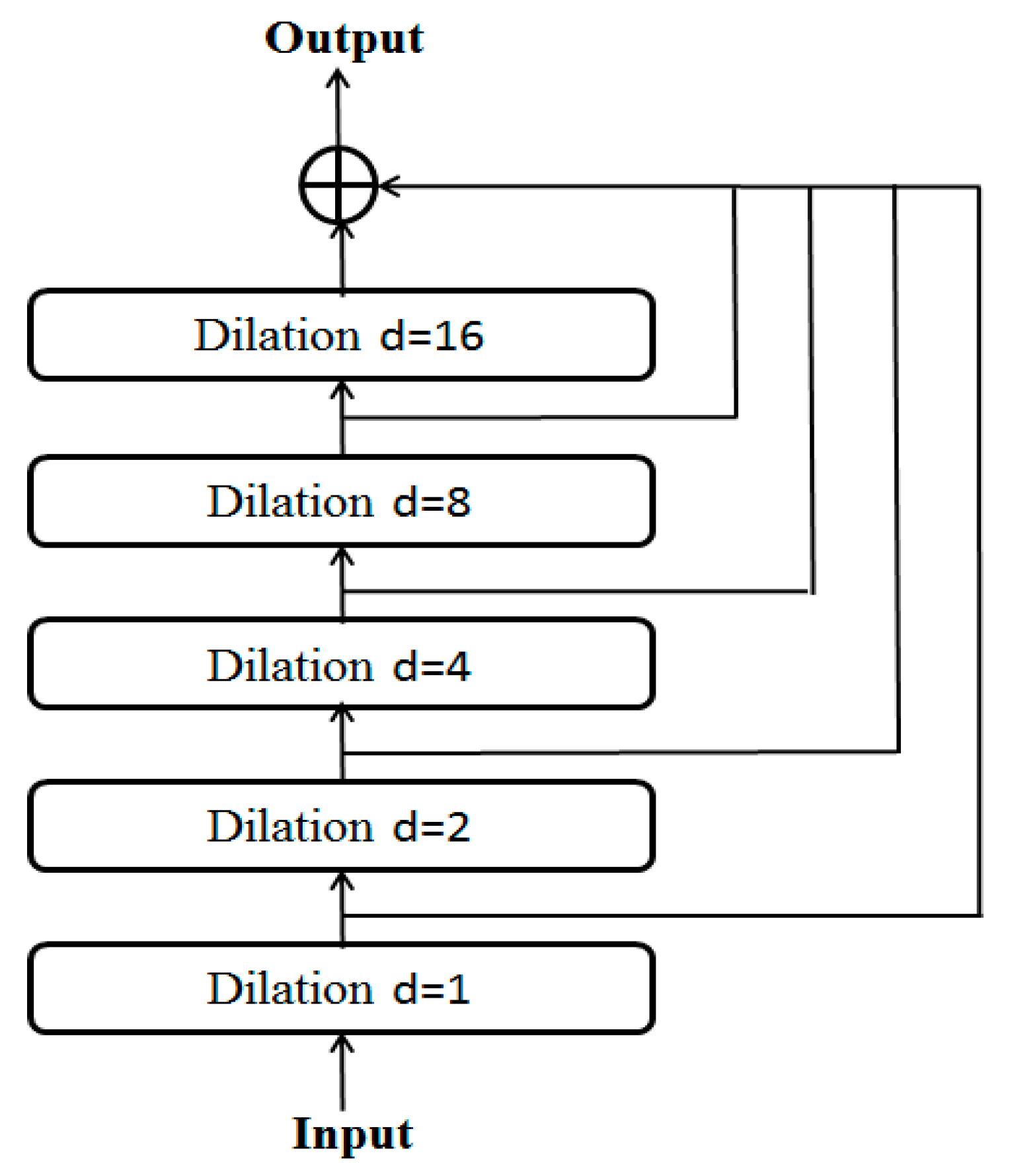
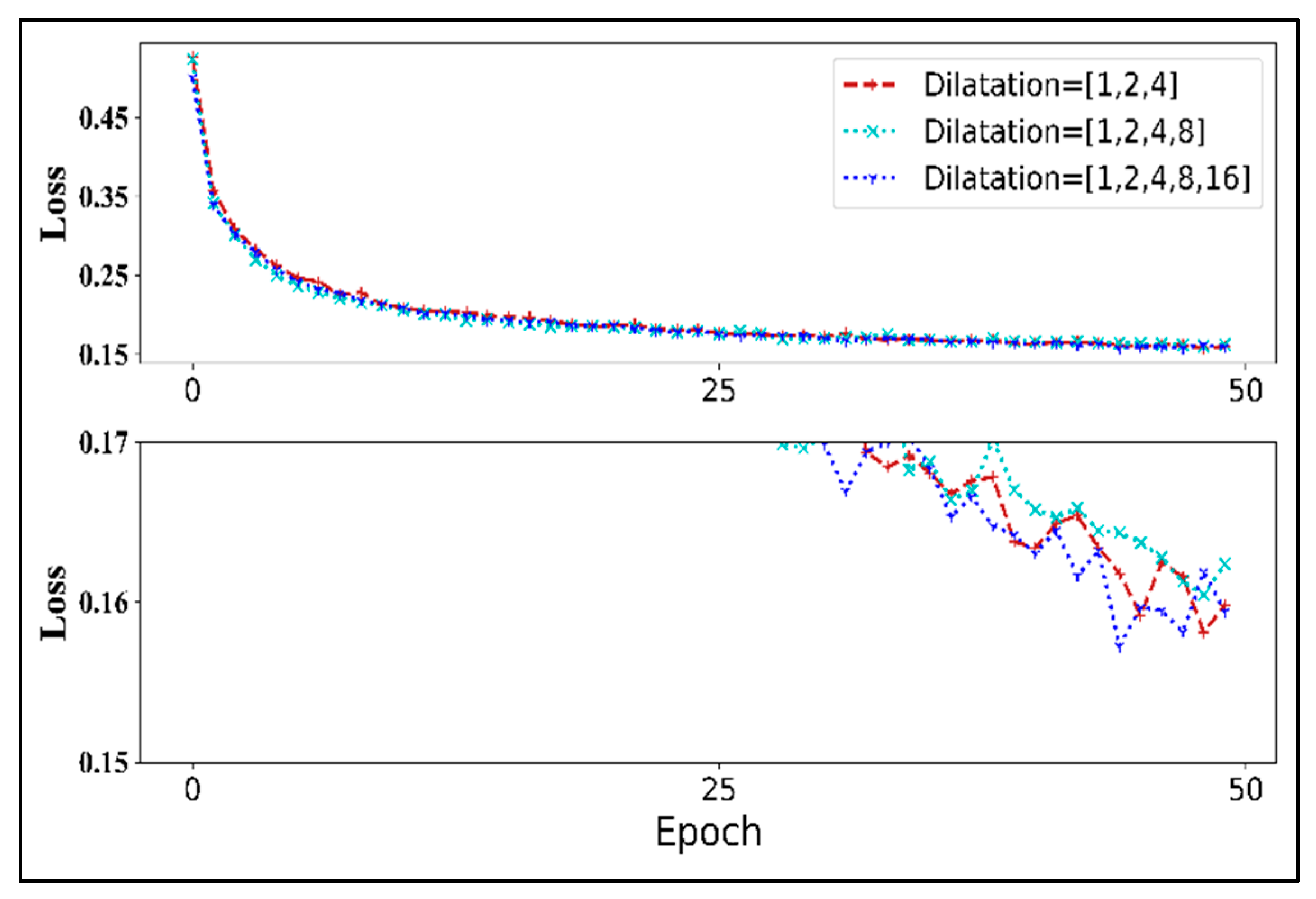
- Dilatation coefficient
3.2.2. Analysis of Architecture Design
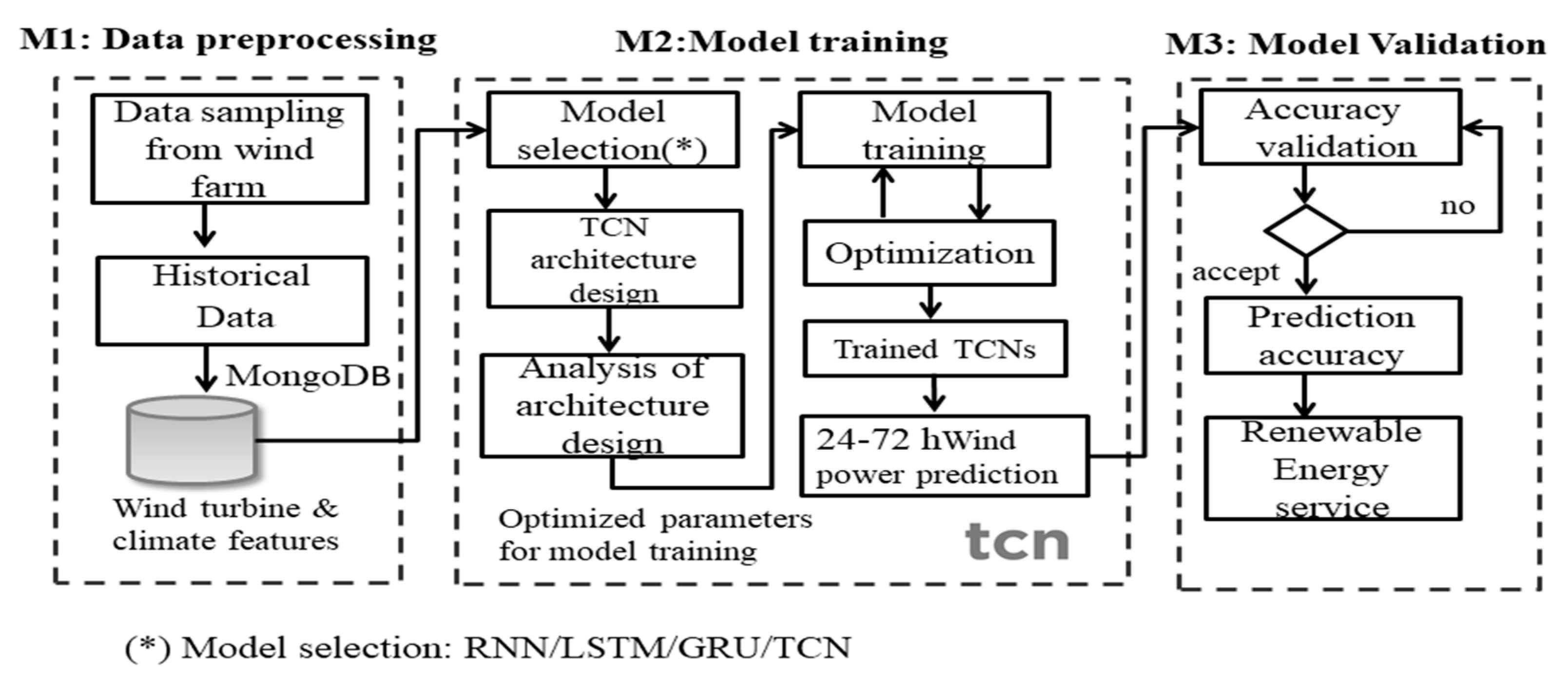
3.3. Overall Process of the Model Operations
| Algorithm 1 Pseudocode of the TCN-based model for wind power prediction. |
| Input: 1. Historical weather data and wind turbine power outputs from Scada wind farm in Turkey, containing five parameters sampled every 10 min, with a total of 52,560 samples listed. 2. Model parameters of the proposed TCN model including the batch set, kernel, and epochs. |
| Output: predicted accuracy of wind power generation |
| 1: Initialize the model parameters of the model |
| 2: Set the value of the epochs to 50 |
| 3: Assign the stop condition value (ε) as 0.0001 |
| 4: Training loop |
| 5: While (the number of epochs) do |
| 6: Determine the optimal parameters of TCN model, as given in Equations (1)–(9) |
| 7: Perform the wind power prediction, as given in Equations (10) and (11) |
| 8: Return (model_file) |
| 9: The training results of the model_file include: (1) filter size, (2) activation function, (3) optimizer, (4) dilatation coefficient, (5) final loss of the cost function, and (6) output result of the training process () |
| 10: Return train (output_file) |
| 11: End loop |
| 12: Test phase |
| 13: Accuracy prediction with loss of cost function by using specific parameters from the model |
| 14: return predict (accuracy) |
| 15: End |
4. Results
4.1. Case Study: Performance Analysis for TCN-Based Model (Scada Wind Farm, Turkey)
- Date/Time: 10 min intervals
- LV ActivePower (kW): The power generated by the turbine for that moment.
- Wind Speed (m/s): The wind speed at the hub height of the turbine.
- Theoretical Power Curve (KWh): The theoretical power values that the turbine generates with that wind speed, which is given by the turbine manufacturer.
- Wind Direction (°): The wind direction at the hub height of the turbine
4.2. Method Comparisons
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alexiadis, M.; Dokopoulos, P.; Sahsamanoglou, H. Wind speed and power forecasting based on spatial correlation models. IEEE Trans. Energy Convers. 1999, 14, 836–842. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W.; Campos-Amezcua, R.; Heard, C. Wind speed prediction using a univariate ARIMA model and a multivariate NARX model. Energies 2016, 9, 109. [Google Scholar] [CrossRef] [Green Version]
- Mohandes, M.; Halawani, T.; Rehman, S.; Hussain, A.A. Support vector machines for wind speed prediction. Renew. Energy 2004, 29, 939–947. [Google Scholar] [CrossRef]
- Moreno, S.; da Silva, R.G.; Mariani, V.C.; Coelho, L. Multi-step-ahead wind speed forecasting based on a hybrid decomposition method and temporal convolutional networks. Energy 2021, 238, 121981. [Google Scholar] [CrossRef]
- Donadio, L.; Fang, J.; Porté-Agel, F. Numerical weather prediction and artificial neural network coupling for wind energy forecast. Energies 2021, 14, 338. [Google Scholar] [CrossRef]
- Hong, Y.Y.; Rioflorido, C.L.P.P. A hybrid deep learning-based neural network for 24-h ahead wind power forecasting. Appl. Energy 2019, 250, 530–539. [Google Scholar] [CrossRef]
- Mana, M.; Astolfi, D.; Castellani, F.; Meißner, C. Day-ahead wind power forecast through high-resolution mesoscale model: Local computational fluid dynamics versus artificial neural network downscaling. J. Sol. Energy Eng. 2020, 142, 034502. [Google Scholar] [CrossRef]
- Emeksiz, C.; Tan, M. Multi-step wind speed forecasting and Hurst analysis using novel hybrid secondary decomposition approach. Energy 2022, 238, 121764. [Google Scholar] [CrossRef]
- Jiang, P.; Liu, Z.; Niu, X.; Zhang, L. A combined forecasting system based on statistical method, artificial neural networks, and deep learning methods for short-term wind speed forecasting. Energy 2021, 217, 119361. [Google Scholar] [CrossRef]
- Neshat, M.; Nezhad, M.M.; Abbasnejad, E.; Mirjalili, S. A deep learning-based evolutionary model for short-term wind speed forecasting: A case study of the Lillgrund offshore wind farm. Energy Convers. Manag. 2021, 236, 114002. [Google Scholar] [CrossRef]
- Sareta, K. Short-term wind speed forecasting system using deep learning for wind turbine applications. Int. J. Electr. Comput. Eng. 2020, 10, 5779–5784. [Google Scholar]
- Kariniotakis, G. Renewable Energy Forecasting, from Models to Applications; Cambridge Elsevier Science & Technology: Cambridge, UK, 2017. [Google Scholar]
- UK Power Networks. KASM SDRC 9.3: Installation of Forecasting Modules, November 2016. Available online: https://innovation.ukpowernetworks.co.uk/wp-content/uploads/2019/05/Installation-of-forecasting-modules.pdf (accessed on 8 February 2021).
- Gupta, D. Fundamentals of Deep Learning—Introduction to Recurrent Neural Networks. 2019. Available online: https://www.analyticsvidhya.com/blog/2017/12/introduction-to-recurrent-neural-networks/ (accessed on 20 March 2021).
- Hochreiter, S. Long-short term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kandpal, A. Generating Text Using an LSTM Network, Codeburst Web Site. 2018. Available online: https://machinelearningmastery.com/text-generation-lstm-recurrent-neural-networks-python-keras/ (accessed on 8 February 2021).
- Firat, O.; Oztekin, I. Learning Deep Temporal Representations for Brain Decoding. In Proceedings of the First International Workshop, MLMMI 2015, Lille, France, 11 July 2015; pp. 25–34. [Google Scholar]
- Ding, L.; Xu, C. TricorNet: A. Hybrid Temporal Convolutional and Recurrent Network for Video Action Segmentation. arXiv 2017, arXiv:1705.07818. [Google Scholar]
- Wang, X.; Xu, J.; Shi, W.; Liu, J. OGRU: An Optimized Gated Recurrent Unit Neural Network. J. Phys. Conf. Ser. 2019, 1325, 012089. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1003–1012. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvare, F.Z.; Troncoso, A. Deep Learning for Time Series Forecasting: A Survey. Big Data 2021, 9, 3–21. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.; Mu, L.; Wang, L.; Ranjan, R. Temporal Convolutional Networks for the Advance Prediction of ENSO. Sci. Rep. 2020, 10, 8055. [Google Scholar] [CrossRef]
- Storn, R.; Price, K.V. Differential Evolution: A Simple and Efficient Heuristic for Global Optimization over Continuous Space. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Georgioudakis, M.; Plevris, V. A Comparative Study of Differential Evolution Variants in Constrained Structural Optimization. Front. Built Environ. Comput. Methods Struct. Eng. 2020, 6, 1–14. [Google Scholar] [CrossRef]
- Zhang, J.; Sanderson, A.C. JADE: Adaptive Differential Evolution with Optional External Archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Yu, W.J.; Shen, M.; Chen, W.N.; Zhan, Z.H.; Gong, Y.J.; Lin, Y. Differential Evolution with Two-level Parameter Adaption. IEEE Trans. Cybern. 2014, 44, 1080–1099. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Yin, M. Application of Differential Evolution Algorithm on Self-Potential Data. PLoS ONE 2012, 7, e51199. [Google Scholar] [CrossRef] [PubMed]
- Rémy, P. Keras-tcn, GitHub. Available online: https://github.com/philipperemy/keras-tcn (accessed on 15 February 2021).
- Erisen, B. Wind Turbine Scada Dataset: 2018 Scada Data of a Wind Turbine in Turkey. Available online: https://www.kaggle.com/berkerisen/wind-turbine-scada-dataset (accessed on 7 January 2021).
- Giebel, G.; Brownsword, R.; Kariniotakis, G.; Denhard, M.; Draxl, C. The State-of-the-Art in Short-Term Prediction of Wind Power: A Literature Overview, 2nd ed. 2011. Available online: http://ecolo.org/documents/documents_in_english/wind-predict-ANEMOS.pdf (accessed on 10 February 2021).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Limitations | |
|---|---|---|
| Physical methods [1] |
|
|
| Statistical methods [2,3] |
|
|
| Hybrid methods [4,5,6,7,8,9] |
|
|
| Deep learning methods [10,11] |
|
|
| Features | Limitations | |
|---|---|---|
| RNN [14] |
|
|
| LSTM [15,16] |
|
|
| GRU [17,18,19] |
|
|
| TCN [20,21,22,23] |
|
|
| Number of Filter | Kernel_Size | Dilatations | Number of Stack | Optimizer | |
|---|---|---|---|---|---|
| Parameter Value | 32 | 10 | [1, 2, 4, 8, 16] | 2 | Adam |
| Maximum | Minimum | Average | |
|---|---|---|---|
| Training accuracy | 98.2% | 97.1% | 97.8% |
| Test accuracy | 96.7% | 92.9% | 95.1% |
| Average | 97.45% | 95.0% | 96.4% |
| Algorithm | Parameter Setting |
|---|---|
| DE | NP = 10, F = 0.5, CR = 0.3, G = 30 |
| Target Vector | Filter_Size | Dilatation | Number of Stacks | Activation Function | Optimizer |
|---|---|---|---|---|---|
| #1 | 8 | [1, 2, 4, 8] | 2 | norm_relu | RMSporp |
| #2 | 32 | [1, 2, 4, 8, 16] | 2 | wavenet | RMSporp |
| #3 | 16 | [1, 2, 4, 8] | 4 | norm_relu | Adam |
| #4 | 8 | [1, 2, 4, 8] | 3 | norm_relu | SGD |
| #5 | 32 | [1, 2, 4, 8] | 3 | wavenet | RMSporp |
| #6 | 8 | [1, 2, 4, 8] | 2 | wavenet | SGD |
| #7 | 16 | [1, 2, 4, 8, 16] | 3 | norm_relu | SGD |
| #8 | 16 | [1, 2, 4, 8] | 2 | wavenet | SGD |
| #9 | 32 | [1, 2, 4] | 4 | norm_relu | Adam |
| Algorithm | Layers | Total Params/Kernels | AF/LF | Optimizer | Dilations | Number of Stack |
|---|---|---|---|---|---|---|
| TCN model for wind power prediction | TCN | 45,761/16 | norm_Relu | Adam | [1, 2, 4, 8] | 4 |
| Input Layer | 0 | - | ||||
| Initial_Conv | (11,16) | |||||
| Dilated ConvLayer | (16,161,16) | norm_Relu/MSE | ||||
| Dropout layer | 0 | |||||
| Conv Layer | (16,17,16) | norm_Relu/MSE | ||||
| OutputDense Layer | (17,1) | linear |
| IP | Programming Language | Operating System | Numerical Library |
|---|---|---|---|
| 192.168.1.10 (AMD Ryzen Threadripper, 1920X, 3.4G) | Python 3.5 | Ubuntu 14.04 LTS 64 | Tensorflow-gpu 1.1.3 |
| Pandas 0.23.4 | |||
| Numpy 1.1.8 | |||
| Matplotlib 3.3.2 |
| Parameter | Output Unit | Optimizers | Learning Rate (lr) | Layers | |
|---|---|---|---|---|---|
| Model | |||||
| RNN | 64 | RMSporp | 0.002 | 3 | |
| LSTM | 64 | RMSporp | 0.002 | 2 | |
| GRU | 32 | RMSporp | 0.01 | 2 | |
| Performance | Excellent | Good | Medium | Bad | |
|---|---|---|---|---|---|
| Period | |||||
| Week | RNN | GRU | LSTM | TCN | |
| Month | LSTM | GRU | TCN | RNN | |
| Year | TCN | LSTM | GRU | RNN | |
| Research Team | Prediction Cycle | Prediction Intervals | Prediction Error (MAPE) |
|---|---|---|---|
| ANEMOS, ANEMOS.plus & SafeWind, 2011 [31] | Short-term | within 36 h | 17–35% |
| ANEMOS.plus & SafeWind, 2017 [12] | Short-term | within 48 h | 11–14% |
| UK Power Networks 2016 [13] | Medium-term | within 120 h | 10% |
| Proposed model | Medium-term | within 72 h | Near 5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, W.-H.; Wang, P.; Chao, K.-M.; Lin, H.-C.; Yang, Z.-Y.; Lai, Y.-H. Wind Power Forecasting with Deep Learning Networks: Time-Series Forecasting. Appl. Sci. 2021, 11, 10335. https://doi.org/10.3390/app112110335
Lin W-H, Wang P, Chao K-M, Lin H-C, Yang Z-Y, Lai Y-H. Wind Power Forecasting with Deep Learning Networks: Time-Series Forecasting. Applied Sciences. 2021; 11(21):10335. https://doi.org/10.3390/app112110335
Chicago/Turabian StyleLin, Wen-Hui, Ping Wang, Kuo-Ming Chao, Hsiao-Chung Lin, Zong-Yu Yang, and Yu-Huang Lai. 2021. "Wind Power Forecasting with Deep Learning Networks: Time-Series Forecasting" Applied Sciences 11, no. 21: 10335. https://doi.org/10.3390/app112110335