
A Zeroth-Order Adaptive Learning Rate Method to Reduce Cost of Hyperparameter Tuning for Deep Learning


Abstract
:1. Introduction
- Non-convex but smooth . That is, is non-convex but satisfies .
- Unbiased estimate and bounded variance of . That is, , and .
- We propose a highly computation-efficient adaptive learning rate method, Adacomp, which only uses loss values rather than exploiting gradients as other adaptive methods. Additionally, Adacomp is robust to initial learning rate and other hyper-parameters, such as batch size and network architecture.
- Based on the analysis of Adacomp, we give a new insight into why a diminishing learning rate is necessary when solving Equation (1) and why a gradient clipping strategy can outperform a fixed learning rate.
- We conduct extensive experiments to compare the proposed Adacomp with several first-order adaptive methods on MNIST, KMNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100 classification tasks. Additionally, we compare Adacomp with two evolutionary algorithms on MNIST and CIFAR-10 datasets. Experimental results validate that Adacomp is not only robust to initial learning rate and batch size, but also network architecture and initialization, with high computational efficiency.
2. Related Work
2.1. Learning Rate Annealing
2.2. Per-Dimension First-Order Adaptive Methods
2.3. Hyperparameter Optimization
2.4. Zeroth-Order Adaptive Methods
3. Adacomp Method
3.1. Idea 1: Search Optimal Learning Rate
3.2. Idea 2: Approximate Unknown Terms
- When , we should decrease γ to restrict the progress along the wrong direction.
- When , we should increase γ to make aggressive progress.
- When γ is too small, we should increase γ to prevent Adacomp from becoming trapped in a local minimum.
- When γ is too large, we should decrease γ to stabilize the training process.
- Expression of . Note that works only if . In this case, we should increase to speed up training. However, the increment should be bounded and inverse to current to avoid divergence. Based on these considerations, we define as , where is used to keep unchanged and is used to ensure that the increment amplitude is at most .
- Expressions of and . Note that work only if , where the twice is used to keep unchanged and the remaining terms are used to control the decrement amplitude. In this case, we should decrease to prevent too much movement along the incorrect direction. However, the decrement should be bounded to satisfy the two following properties.
- −
- When is small, the decrement of should be less than the increment in given the same unless is forced to zero, which potentially leads to training stopping too early. Therefore, we define in to satisfy . Note that when is small, which satisfies the requirement.
- −
- When is large, the decrement of should be larger than the increment in given the same . That is, we can fast decrease the large learning rate when the function loss is negative. Therefore, we set in to satisfy that (in the case ) is greater than (in the case ).
Furthermore, the inferior bound of is used to ensure when , i.e., the meaningfulness of .
| Algorithm 1 Two-phase Training Algorithm. |
Input: Initial , balance rate , iteration number T, and phase threshold Output:  |
4. Experiments
4.1. Experimental Setup
4.2. Results on MNIST Dataset
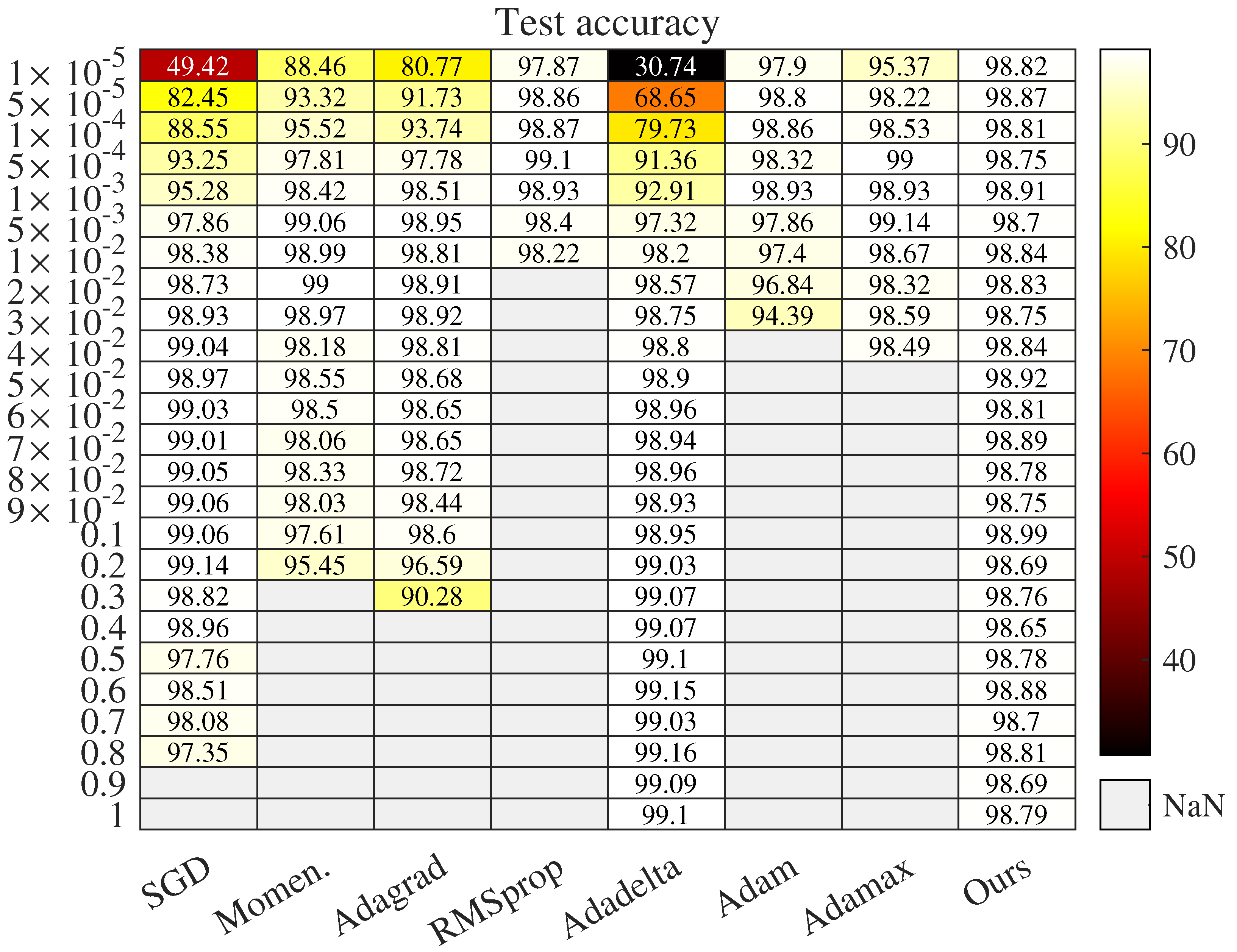
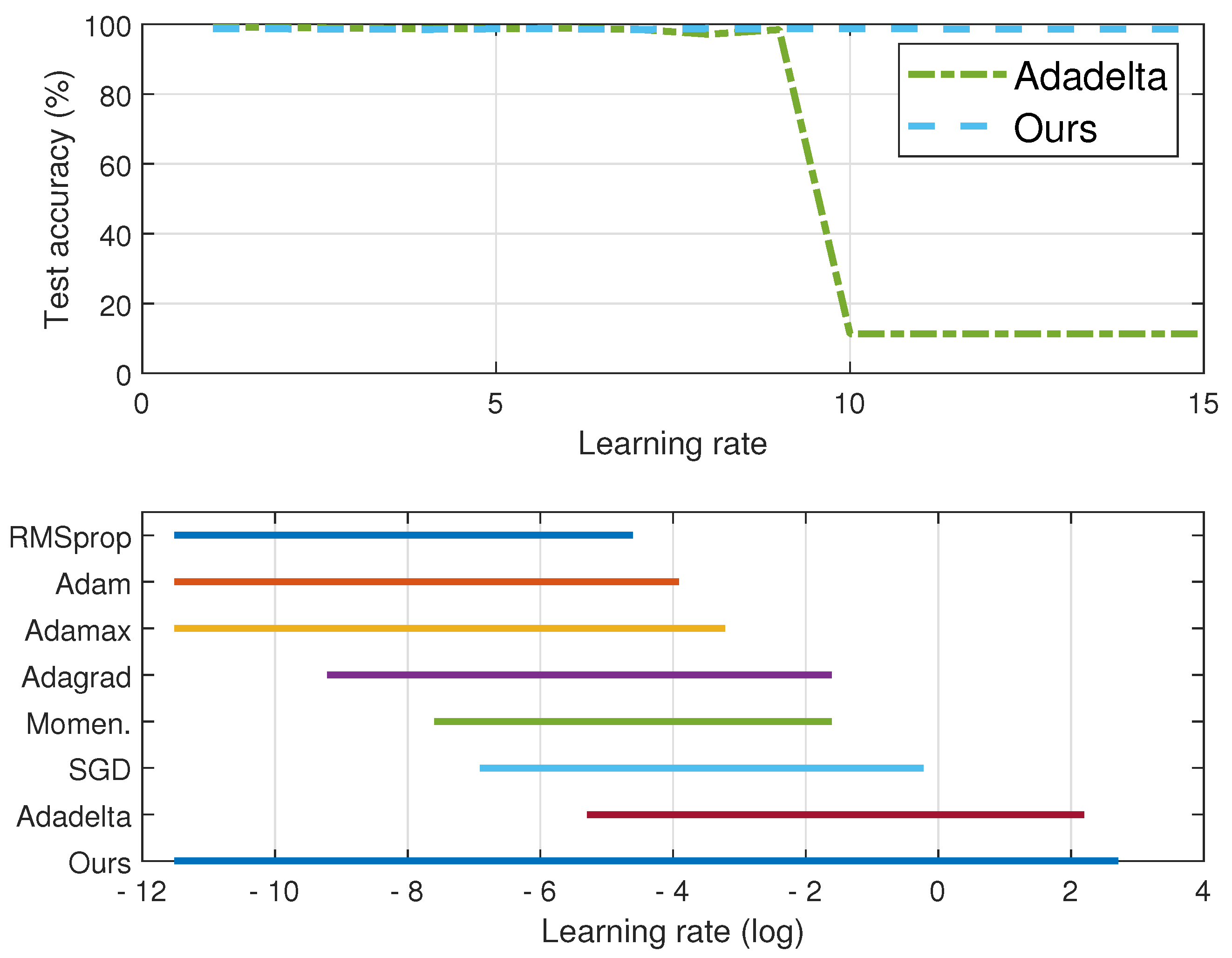
4.2.1. Robustness to Initial Learning Rate
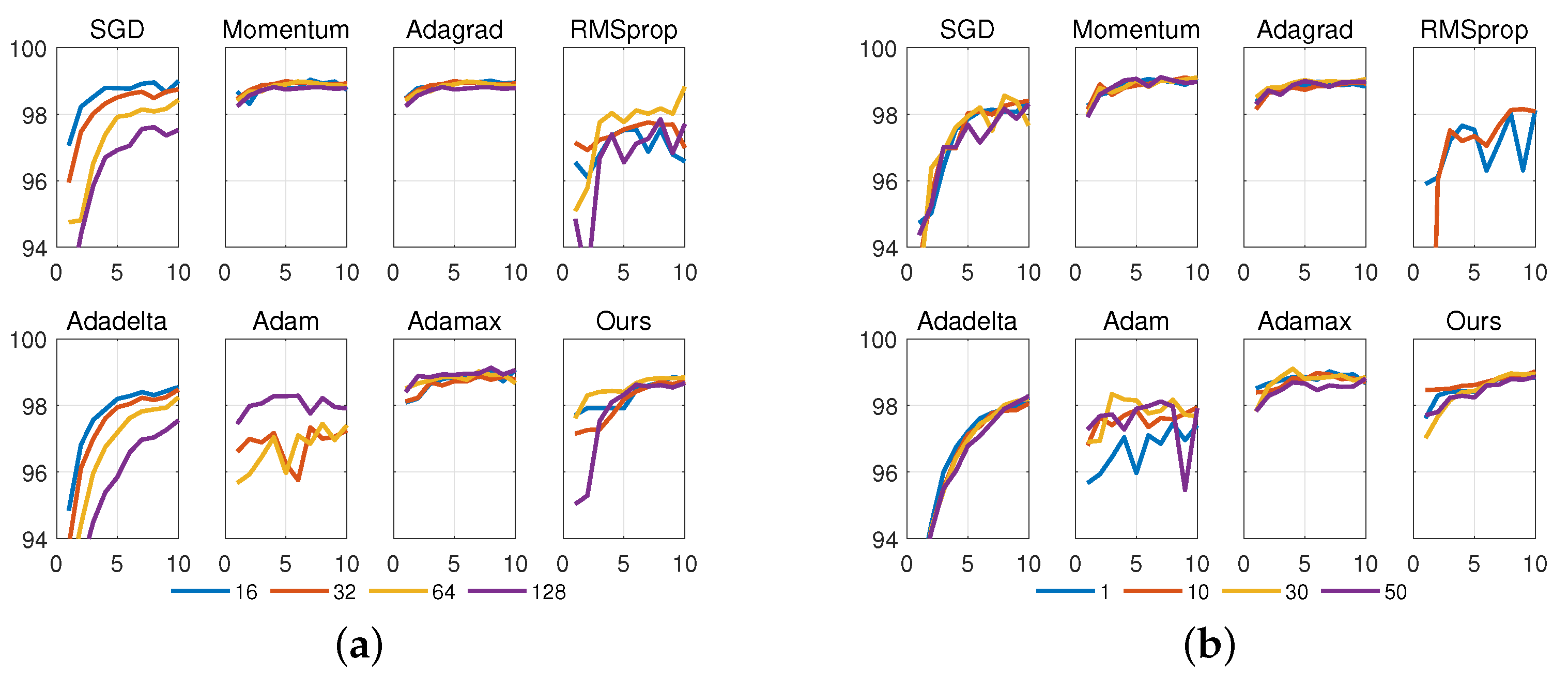
4.2.2. Robustness to Other Hyperparameters
4.2.3. Convergence Speed and Efficiency
4.3. Results on CIFAR-10 Dataset
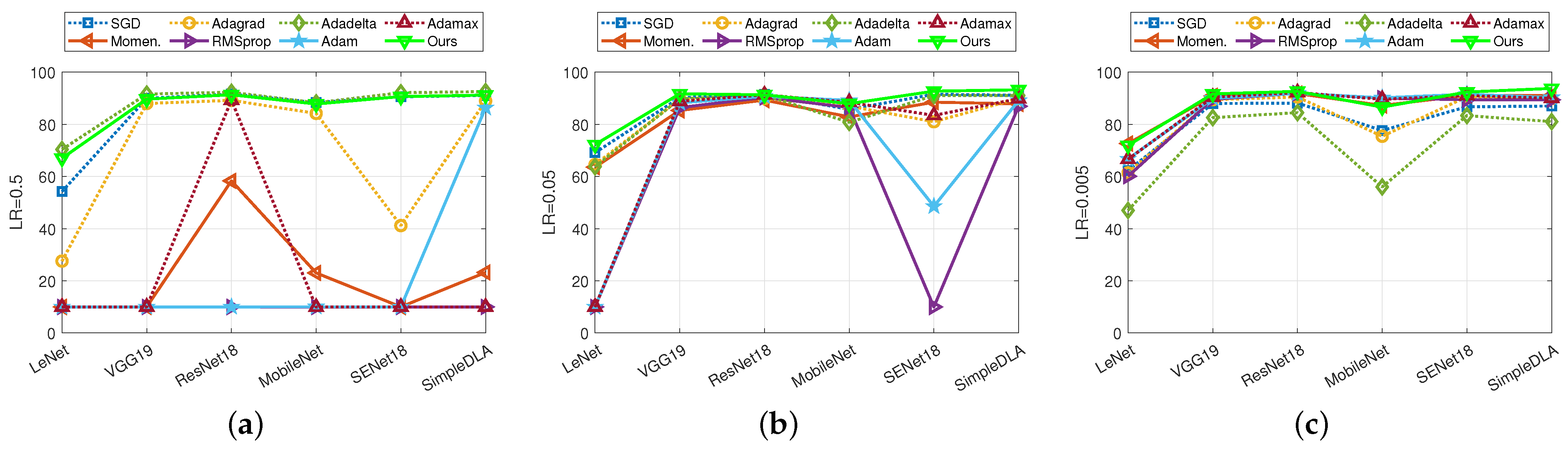
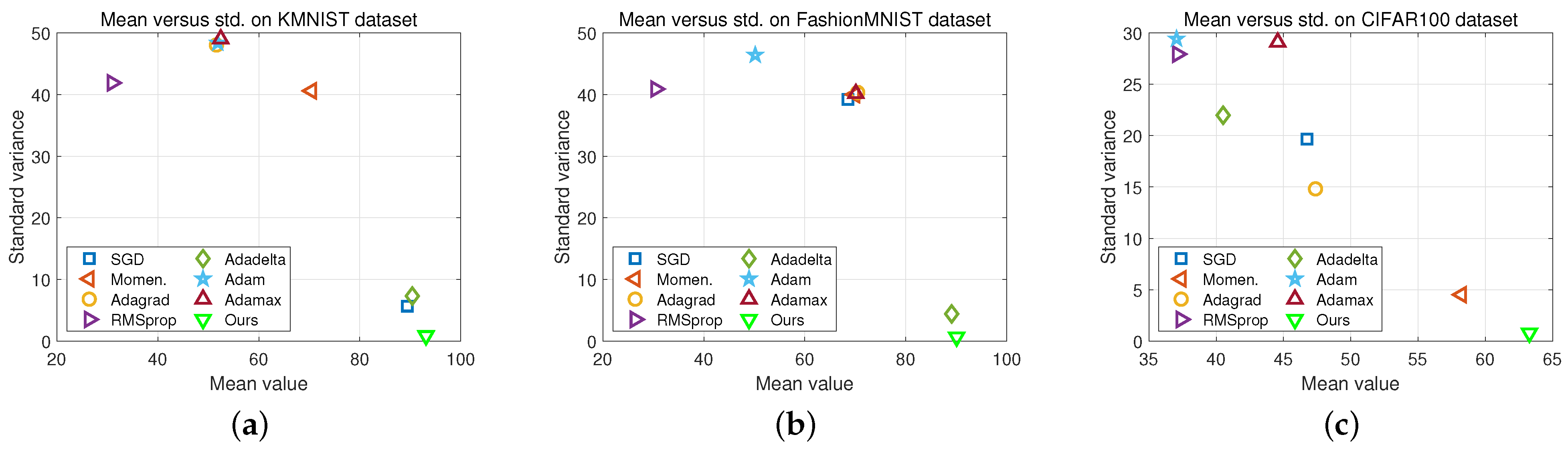
4.4. Results for Other Datasets
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Extended Experiments
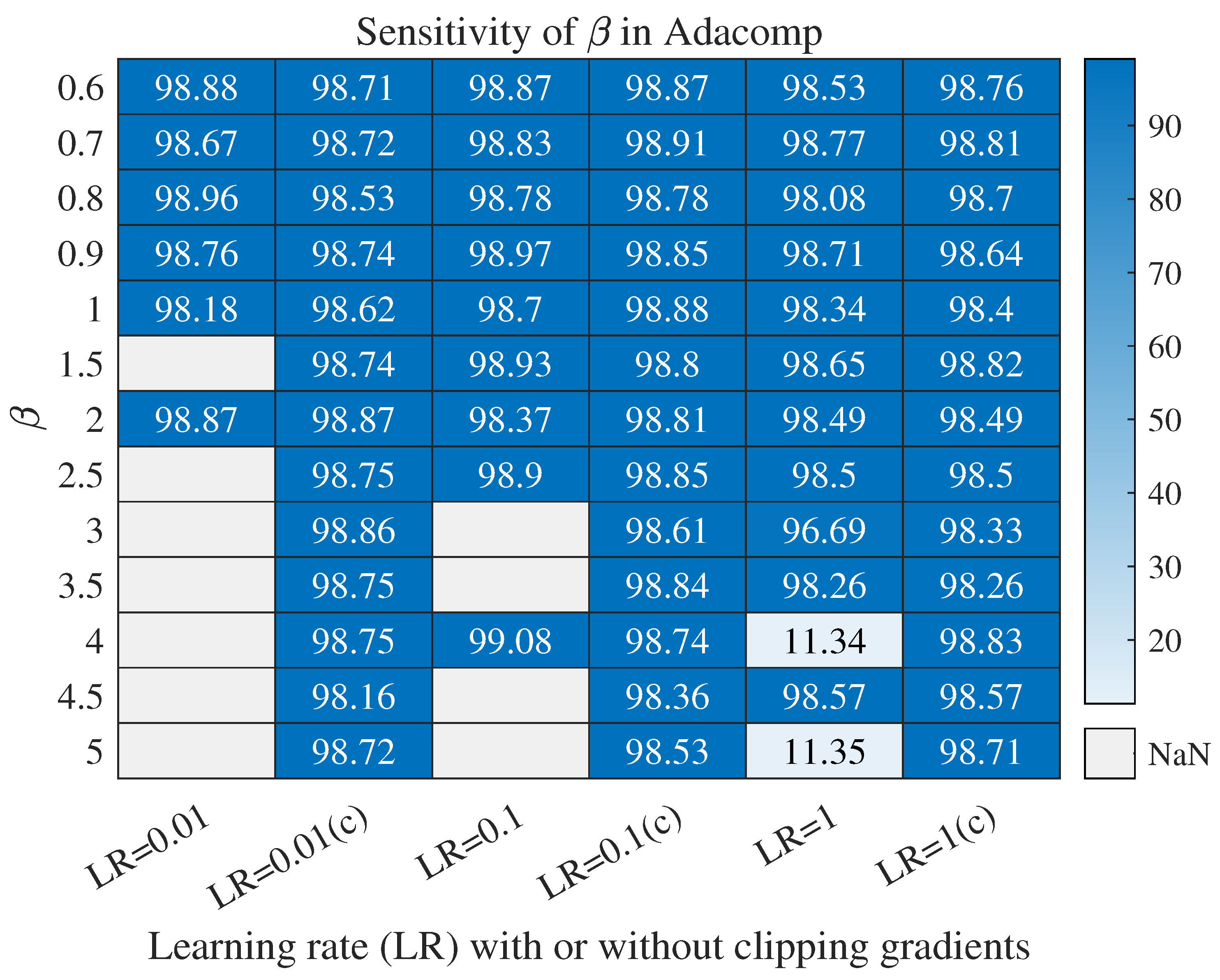
- Setting different values of in Adacomp to show its impacts. As shown in Equation (9), is a parameter used for tuning the tradeoff between and . In Section 4, was set as a constant for all experiments, without presenting the impacts of . Here, experimental results on MNIST show that Adacomp is not so sensitive to .
- Using more metrics to provide an overall validation. In Section 4, we used prediction accuracy to compare algorithms for classification tasks. The single metric may not provide the overall validation. Here, we provided complementary experiments with three more metrics, precision, recall, and F1-score. Experimental results on MNIST, Fashion-MNIST, and CIFAR-10 show that Adacomp performs stably under the additional metrics.
- Comparing with evolutionary algorithms to enrich experiments. In Section 4, we compared Adacomp with six first-order adaptive algorithms, lacking comparison with some state-of-the-art approaches. For completeness, we compared Adacomp with two typical evolutionary methods, the genetic algorithm and particle swarm optimization algorithm. Experimental results show that Adacomp can significantly save time cost at the sacrifice of little accuracy degradation.
Appendix A.1. Impacts of β on Adacomp

Appendix A.2. Comparison Using More Metrics
Appendix A.3. Comparison with Evolutionary Algorithms
- For the GA, we set 10 generations with 20 populations in each generation. Mutation, random selection, and retain probability were set as 0.2, 0.1, 0.4, respectively.
- For PSO, swarm size and number of iterations were both set as 100, inertia weight and acceleration coefficients were both set as 0.5.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
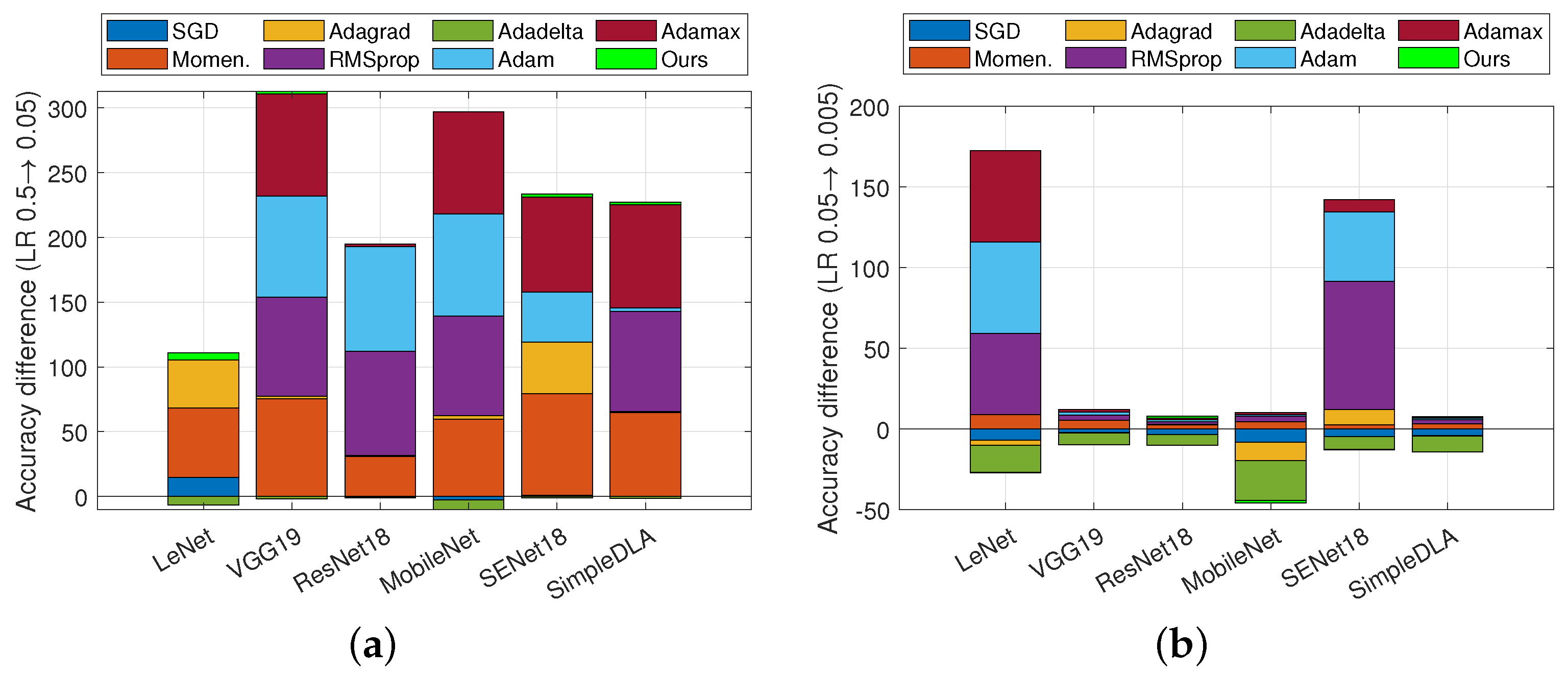{kind=link}
{kind=link}
{kind=link}
| Dataset | MNIST | Fashion-MNIST | CIFAR-10 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | Acc. | Prec. | Reca. | F1-sc. | Acc. | Prec. | Reca. | F1-sc. | Acc. | Prec. | Reca. | F1-sc. | |
| GA [52] | Maximum | 99.16 | 99.19 | 99.16 | 99.17 | 92.22 | 92.56 | 91.96 | 92.25 | 61.45 | 62.45 | 61.34 | 61.89 |
| Time | 32 m/110 m | 58 m/71 m | 5.8 h/5.8 h | ||||||||||
| PSO [53] | Maximum | 99.11 | 99.16 | 99.09 | 99.12 | 91.99 | 92.48 | 91.72 | 92.09 | 65.41 | 65.96 | 65.39 | 65.67 |
| Time | 23 m/66 m | 16 m/34 m | 3.0 h/6.5 h | ||||||||||
| Ours | Maximum | 98.45 | 98.45 | 98.44 | 98.44 | 89.10 | 89.05 | 89.10 | 89.05 | 67.45 | 67.09 | 67.45 | 67.26 |
| Time | 2.57 m–2.6 m | 2.7 m–2.75 m | 0.63 h–0.64 h | ||||||||||
| LR | Dataset | MNIST | Fashion-MNIST | CIFAR-10 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | Acc. | Pre. | Reca. | F1-sc. | Acc. | Pre. | Reca. | F1-sc. | Acc. | Pre. | Reca. | F1-sc. | |
| 0.01 | SGD | 97.71 | 97.13 | 97.10 | 97.11 | 88.30 | 88.24 | 88.30 | 88.25 | 60.11 | 59.72 | 60.12 | 59.72 |
| Moment. | 98.78 | 98.77 | 98.78 | 98.77 | 91.60 | 91.61 | 91.60 | 91.62 | 67.16 | 67.00 | 67.16 | 67.01 | |
| Adagrad | 98.90 | 98.90 | 98.89 | 98.89 | 91.95 | 91.93 | 91.95 | 91.93 | 62.71 | 62.54 | 62.71 | 62.44 | |
| RMSprop | 11.24 | 2.16 | 10.00 | 3.55 | 87.78 | 87.80 | 87.78 | 87.76 | 47.91 | 47.52 | 47.91 | 47.57 | |
| Adadelta | 96.40 | 96.38 | 96.36 | 96.37 | 86.55 | 86.44 | 86.55 | 86.47 | 47.00 | 46.34 | 47.00 | 45.89 | |
| Adam | 97.85 | 97.85 | 97.83 | 97.84 | 88.00 | 88.03 | 88.00 | 88.01 | 10.00 | 9.99 | 10.00 | 9.93 | |
| Adamax | 98.64 | 98.63 | 98.63 | 98.63 | 90.11 | 90.10 | 90.11 | 90.10 | 66.38 | 66.19 | 66.38 | 66.23 | |
| Ours | 98.08 | 98.08 | 98.07 | 98.07 | 88.89 | 88.85 | 88.89 | 88.85 | 65.36 | 64.88 | 65.36 | 65.11 | |
| 0.1 | SGD | 98.86 | 98.86 | 98.85 | 98.86 | 91.33 | 91.29 | 91.33 | 91.30 | 65.82 | 65.60 | 65.81 | 65.64 |
| Moment. | 97.83 | 97.82 | 97.81 | 97.81 | 87.88 | 88.03 | 87.88 | 87.93 | 44.71 | 44.12 | 44.71 | 44.25 | |
| Adagrad | 96.97 | 96.95 | 96.95 | 96.95 | 88.68 | 88.62 | 88.68 | 88.63 | 53.02 | 52.58 | 53.02 | 52.62 | |
| RMSprop | 10.78 | 5.11 | 9.99 | 6.76 | 11.36 | 17.58 | 11.36 | 13.80 | 10.00 | 10.00 | 10.00 | 9.62 | |
| Adadelta | 98.80 | 98.79 | 98.79 | 98.79 | 91.15 | 91.12 | 91.15 | 91.12 | 62.07 | 61.89 | 62.07 | 61.85 | |
| Adam | 10.81 | 21.63 | 10.00 | 13.67 | 10.00 | 7.99 | 10.00 | 8.88 | 10.00 | 10.00 | 10.00 | 9.63 | |
| Adamax | 10.65 | 4.13 | 9.99 | 5.84 | 84.36 | 84.35 | 84.36 | 84.34 | 10.00 | 9.99 | 10.00 | 9.64 | |
| Ours | 97.92 | 97.91 | 97.91 | 97.91 | 88.90 | 88.86 | 88.90 | 88.86 | 67.45 | 67.09 | 67.45 | 67.26 | |
| 1 | SGD | 9.80 | 0.98 | 10.00 | 1.78 | 10.00 | 1.00 | 10.00 | 1.81 | 10.00 | 10.00 | 10.00 | 10.00 |
| Moment. | 9.80 | 0.98 | 10.00 | 1.78 | 10.00 | 10.00 | 10.00 | 10.00 | 10.00 | 9.99 | 9.99 | 9.77 | |
| Adagrad | 10.97 | 3.13 | 9.99 | 4.76 | 62.34 | 70.20 | 62.34 | 64.65 | 10.00 | 10.00 | 10.00 | 9.34 | |
| RMSprop | 10.01 | 6.06 | 9.99 | 7.54 | 10.10 | 10.00 | 10.10 | 9.63 | 10.00 | 9.99 | 9.99 | 9.71 | |
| Adadelta | 99.02 | 99.01 | 99.01 | 99.01 | 91.91 | 91.91 | 91.91 | 91.91 | 65.26 | 65.22 | 65.26 | 65.19 | |
| Adam | 10.15 | 40.75 | 10.00 | 16.05 | 10.00 | 9.99 | 10.00 | 9.73 | 10.00 | 9.99 | 9.99 | 9.74 | |
| Adamax | 10.57 | 4.15 | 10.00 | 5.86 | 9.99 | 8.99 | 9.99 | 9.46 | 10.00 | 9.99 | 10.00 | 9.78 | |
| Ours | 98.45 | 98.45 | 98.44 | 98.44 | 89.10 | 89.05 | 89.10 | 89.05 | 65.67 | 65.56 | 65.67 | 65.61 | |
References
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Pierson, H.A.; Gashler, M.S. Deep learning in robotics: A review of recent research. Adv. Robot. 2017, 31, 821–835. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.; Zeng, X.; Xia, F.; Huang, W.; Liu, X. Application of deep learning methods in biological networks. Brief. Bioinform. 2021, 22, 1902–1917. [Google Scholar] [CrossRef] [PubMed]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Nesterov, Y. Squared functional systems and optimization problems. In High Performance Optimization; Springer: Berlin/Heidelberg, Germany, 2000; pp. 405–440. [Google Scholar]
- Ghadimi, S.; Lan, G. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM J. Optim. 2013, 23, 2341–2368. [Google Scholar] [CrossRef] [Green Version]
- Carmon, Y.; Duchi, J.C.; Hinder, O.; Sidford, A. Accelerated methods for nonconvex optimization. SIAM J. Optim. 2018, 28, 1751–1772. [Google Scholar] [CrossRef] [Green Version]
- Lan, G. First-Order and Stochastic Optimization Methods for Machine Learning; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Lan, G. An optimal method for stochastic composite optimization. Math. Program. 2012, 133, 365–397. [Google Scholar] [CrossRef] [Green Version]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2017, arXiv:1608.03983. [Google Scholar]
- Xia, M.; Li, T.; Xu, L.; Liu, L.; De Silva, C.W. Fault diagnosis for rotating machinery using multiple sensors and convolutional neural networks. IEEE/Asme Trans. Mechatron. 2017, 23, 101–110. [Google Scholar] [CrossRef]
- Wang, W.F.; Qiu, X.H.; Chen, C.S.; Lin, B.; Zhang, H.M. Application research on long short-term memory network in fault diagnosis. In Proceedings of the 2018 International Conference on Machine Learning and Cybernetics (ICMLC), Chengdu, China, 15–18 July 2018; Volume 2, pp. 360–365. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited 2012, 14, 2. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wen, L.; Gao, L.; Li, X.; Zeng, B. Convolutional neural network with automatic learning rate scheduler for fault classification. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar]
- Wen, L.; Li, X.; Gao, L. A New Reinforcement Learning based Learning Rate Scheduler for Convolutional Neural Network in Fault Classification. IEEE Trans. Ind. Electron. 2020, 68, 12890–12900. [Google Scholar] [CrossRef]
- Han, J.H.; Choi, D.J.; Hong, S.K.; Kim, H.S. Motor fault diagnosis using CNN based deep learning algorithm considering motor rotating speed. In Proceedings of the 2019 IEEE 6th International Conference on Industrial Engineering and Applications (ICIEA), Tokyo, Japan, 12–15 April 2019; pp. 440–445. [Google Scholar]
- Fischer, A. A special Newton-type optimization method. Optimization 1992, 24, 269–284. [Google Scholar] [CrossRef]
- Li, Y.; Wei, C.; Ma, T. Towards Explaining the Regularization Effect of Initial Large Learning Rate in Training Neural Networks. arXiv 2019, arXiv:1907.04595. [Google Scholar]
- Nakkiran, P. Learning rate annealing can provably help generalization, even for convex problems. arXiv 2020, arXiv:2005.07360. [Google Scholar]
- Pouyanfar, S.; Chen, S.C. T-LRA: Trend-based learning rate annealing for deep neural networks. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 50–57. [Google Scholar]
- Takase, T.; Oyama, S.; Kurihara, M. Effective neural network training with adaptive learning rate based on training loss. Neural Networks 2018, 101, 68–78. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Tang, S.; Shen, C.; Wang, D.; Li, S.; Huang, W.; Zhu, Z. Adaptive deep feature learning network with Nesterov momentum and its application to rotating machinery fault diagnosis. Neurocomputing 2018, 305, 1–14. [Google Scholar] [CrossRef]
- Ward, R.; Wu, X.; Bottou, L. AdaGrad stepsizes: Sharp convergence over nonconvex landscapes. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6677–6686. [Google Scholar]
- Hadgu, A.T.; Nigam, A.; Diaz-Aviles, E. Large-scale learning with AdaGrad on Spark. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2828–2830. [Google Scholar]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Yazan, E.; Talu, M.F. Comparison of the stochastic gradient descent based optimization techniques. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017; pp. 1–5. [Google Scholar]
- Pan, H.; He, X.; Tang, S.; Meng, F. An improved bearing fault diagnosis method using one-dimensional CNN and LSTM. J. Mech. Eng. 2018, 64, 443–452. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Shankar, K.; Zhang, Y.; Liu, Y.; Wu, L.; Chen, C.H. Hyperparameter tuning deep learning for diabetic retinopathy fundus image classification. IEEE Access 2020, 8, 118164–118173. [Google Scholar] [CrossRef]
- Wang, J.; Xu, J.; Wang, X. Combination of Hyperband and Bayesian Optimization for Hyperparameter Optimization in Deep Learning. arXiv 2018, arXiv:1801.01596. [Google Scholar]
- Neary, P. Automatic hyperparameter tuning in deep convolutional neural networks using asynchronous reinforcement learning. In Proceedings of the 2018 IEEE International Conference on Cognitive Computing (ICCC), San Francisco, CA, USA, 2–7 July 2018; pp. 73–77. [Google Scholar]
- Rijsdijk, J.; Wu, L.; Perin, G.; Picek, S. Reinforcement Learning for Hyperparameter Tuning in Deep Learning-based Side-channel Analysis. IACR Cryptol. Eprint Arch. 2021, 2021, 71. [Google Scholar]
- Wu, J.; Chen, S.; Liu, X. Efficient hyperparameter optimization through model-based reinforcement learning. Neurocomputing 2020, 409, 381–393. [Google Scholar] [CrossRef]
- Chen, S.; Wu, J.; Liu, X. EMORL: Effective multi-objective reinforcement learning method for hyperparameter optimization. Eng. Appl. Artif. Intell. 2021, 104, 104315. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Jiang, N.; Yang, M. Layer-wise learning based stochastic gradient descent method for the optimization of deep convolutional neural network. J. Intell. Fuzzy Syst. 2019, 37, 5641–5654. [Google Scholar] [CrossRef]
- Xiao, X.; Yan, M.; Basodi, S.; Ji, C.; Pan, Y. Efficient hyperparameter optimization in deep learning using a variable length genetic algorithm. arXiv 2020, arXiv:2006.12703. [Google Scholar]
- Singh, P.; Chaudhury, S.; Panigrahi, B.K. Hybrid MPSO-CNN: Multi-level Particle Swarm optimized hyperparameters of Convolutional Neural Network. Swarm Evol. Comput. 2021, 63, 100863. [Google Scholar] [CrossRef]
- Neshat, M.; Nezhad, M.M.; Abbasnejad, E.; Mirjalili, S.; Tjernberg, L.B.; Garcia, D.A.; Alexander, B.; Wagner, M. A deep learning-based evolutionary model for short-term wind speed forecasting: A case study of the Lillgrund offshore wind farm. Energy Convers. Manag. 2021, 236, 114002. [Google Scholar] [CrossRef]
- Haidong, S.; Hongkai, J.; Ke, Z.; Dongdong, W.; Xingqiu, L. A novel tracking deep wavelet auto-encoder method for intelligent fault diagnosis of electric locomotive bearings. Mech. Syst. Signal Process. 2018, 110, 193–209. [Google Scholar] [CrossRef]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: Berlin, Germany, 2003; Volume 87. [Google Scholar]
- Zhang, J.; He, T.; Sra, S.; Jadbabaie, A. Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity. arXiv 2020, arXiv:1905.11881. [Google Scholar]
- LeCun, Y. The MNIST Database of Handwritten Digits. 1998. Available online: http://Yann.Lecun.Com/Exdb/Mnist/ (accessed on 15 May 2021).
- Clanuwat, T.; Bober-Irizar, M.; Kitamoto, A.; Lamb, A.; Yamamoto, K.; Ha, D. Deep Learning for Classical Japanese Literature. arXiv 2018, arXiv:1812.01718. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 1 October 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bakhshi, A.; Noman, N.; Chen, Z.; Zamani, M.; Chalup, S. Fast automatic optimisation of CNN architectures for image classification using genetic algorithm. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 1283–1290. [Google Scholar]
- Lorenzo, P.R.; Nalepa, J.; Kawulok, M.; Ramos, L.S.; Pastor, J.R. Particle swarm optimization for hyper-parameter selection in deep neural networks. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 481–488. [Google Scholar]






| Variables | Explanations |
|---|---|
| Number of total iterations and index of the current iteration. | |
| Empirical loss function and gradient at model parameter w and sample . | |
| Expected function and gradient of and with respect to . | |
| Smooth constant of and variance of with respect to . | |
| Abbreviations for and , respectively. | |
| Mini-batch sampled at t-th iteration with size of b. | |
| Learning rate at t-th iteration, parameter of Adacomp used to adjust . | |
| Difference in at two consecutive iterations, i.e., . |
| Method | Epochs | Speed | Training/Total Time (s) | |
|---|---|---|---|---|
| SGD | 13 | 19 | 1.46 | 68.13/78.22 |
| Momentum | 11 | 12 | 1.09 | 69.11/79.36 |
| Adagrad | 12 | 22 | 1.83 | 68.55/78.68 |
| RMSprop | 6 | 16 | 2.67 | 69.18/79.34 |
| Adadelta | 19 | 43 | 2.26 | 68.56/78.68 |
| Adam | 4 | 7 | 1.75 | 68.40/78.49 |
| Adamax | 9 | 28 | 3.5 | 68.55/78.67 |
| Ours | 25 | 23 | 0.92 | 68.25/78.26 |
| Dataset | KMNIST | Fashion-MNIST | CIFAR-100 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| lr | 0.001 | 0.01 | 0.1 | 1 | 0.001 | 0.01 | 0.1 | 1 | 0.001 | 0.01 | 0.1 | 1 | Tr./To. Time (s) |
| SGD | 87.43 | 92.74 | 95.07 | 82.36 | 83.31 | 88.60 | 92.26 | 10.00 | 17.91 | 50.82 | 57.69 | 60.59 | 1004.3/1145.5 |
| Momen. | 93.20 | 94.96 | 83.54 | 10.00 | 91.11 | 92.24 | 86.14 | 10.00 | 51.63 | 60.57 | 61.63 | 59.07 | 1052.4/1196.1 |
| Adagrad | 92.02 | 94.34 | 10.00 | 10.00 | 89.36 | 91.92 | 90.58 | 10.00 | 25.47 | 52.77 | 58.23 | 53.04 | 1017.0/1158.0 |
| RMSprop | 93.78 | 10.00 | 10.00 | 10.00 | 91.79 | 10.00 | 10.00 | 10.00 | 59.70 | 58.63 | 29.17 | 1.00 | 1042.0/1185.9 |
| Adadelta | 79.65 | 91.99 | 94.58 | 95.40 | 83.15 | 88.31 | 92.45 | 92.46 | 11.48 | 35.77 | 54.79 | 60.02 | 1025.2/1166.5 |
| Adam | 95.35 | 92.10 | 10.00 | 10.00 | 92.06 | 88.62 | 10.00 | 10.00 | 61.09 | 61.04 | 25.08 | 1.00 | 1030.5/1170.9 |
| Adamax | 95.09 | 94.70 | 10.00 | 10.00 | 92.52 | 91.10 | 86.82 | 10.00 | 57.51 | 61.41 | 58.37 | 1.00 | 1033.6/1176.0 |
| Ours | 93.96 | 91.90 | 93.51 | 93.11 | 89.94 | 90.88 | 90.24 | 89.25 | 63.96 | 62.14 | 63.50 | 63.50 | 1010.1/1148.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Ren, X.; Zhao, F.; Yang, S. A Zeroth-Order Adaptive Learning Rate Method to Reduce Cost of Hyperparameter Tuning for Deep Learning. Appl. Sci. 2021, 11, 10184. https://doi.org/10.3390/app112110184
Li Y, Ren X, Zhao F, Yang S. A Zeroth-Order Adaptive Learning Rate Method to Reduce Cost of Hyperparameter Tuning for Deep Learning. Applied Sciences. 2021; 11(21):10184. https://doi.org/10.3390/app112110184
Chicago/Turabian StyleLi, Yanan, Xuebin Ren, Fangyuan Zhao, and Shusen Yang. 2021. "A Zeroth-Order Adaptive Learning Rate Method to Reduce Cost of Hyperparameter Tuning for Deep Learning" Applied Sciences 11, no. 21: 10184. https://doi.org/10.3390/app112110184