
AWEU-Net: An Attention-Aware Weight Excitation U-Net for Lung Nodule Segmentation

 , ,
, ,  , and
, and
Abstract
:1. Introduction
- •
- A fully automated deep learning-based framework called AWEU-Net is proposed for improving the accuracy of lung nodule detection and segmentation;
- •
- PAWE and CWEU mechanisms are proposed to model the correlation between the spatial and channel features and encourage the CNN model to learn the most relevant features that enhance its ability to discriminate between nodule and non-nodule feature representations;
- •
- A comparative study of different nodule detection models and nodule segmentation models is presented using two publicly available datasets, namely LUNA16 and LIDC-IDRI.
2. Related Work
2.1. Classical Computer Vision-Based Approaches
2.2. Deep Learning-Based Approaches
3. Proposed Methodology
3.1. Pre-Processing
3.2. Nodule Detection Model
3.3. Nodule Segmentation Model
3.4. Attention Mechanism
3.4.1. Position Attention-Aware Weight Excitation (PAWE)
3.4.2. Channel Attention-Aware Weight Excitation (CAWE)
4. Experimental Results and Discussion
4.1. Datasets
- Lung Image Database Consortium image collection (LIDC-IDRI) [32] consists of 1018 CT scans performed on 1010 patients from 7 different organisations. Each CT scan has been analysed by four radiologists, who individually identified the nodule and manually segmented the region of all the nodules with a diameter larger than three millimetres. Each CT scan can include one or more nodule regions, so the total segmented masks are 5066. Looking closely at the dataset, many nodules are very small and do not satisfy the malignancy index. Therefore, we used a diameter threshold larger than 20 mm to excluded all tiny nodules from our dataset. Afterwards, we split our final dataset, which contains 2044 nodule masks in total, into train, validation and test sets of , , and respectively;
- LUng Nodule Analysis 2016 (LUNA16) [33] is derived from the LIDC-IDRI dataset [32]. It contains 888 CT scans from the LIDC-IDRI dataset for the grand challenge with round annotation masks for all the segmented nodules. The LUNA16 challenge dataset contains 1186 nodule annotations. We obtained 2300 nodule masks from the annotation after pre-processing. We split the dataset into train, validation and test sets similar to the LIDC-IDRI dataset.
4.2. Model Implementation
4.3. Evaluation Measures
4.4. Nodule Detection
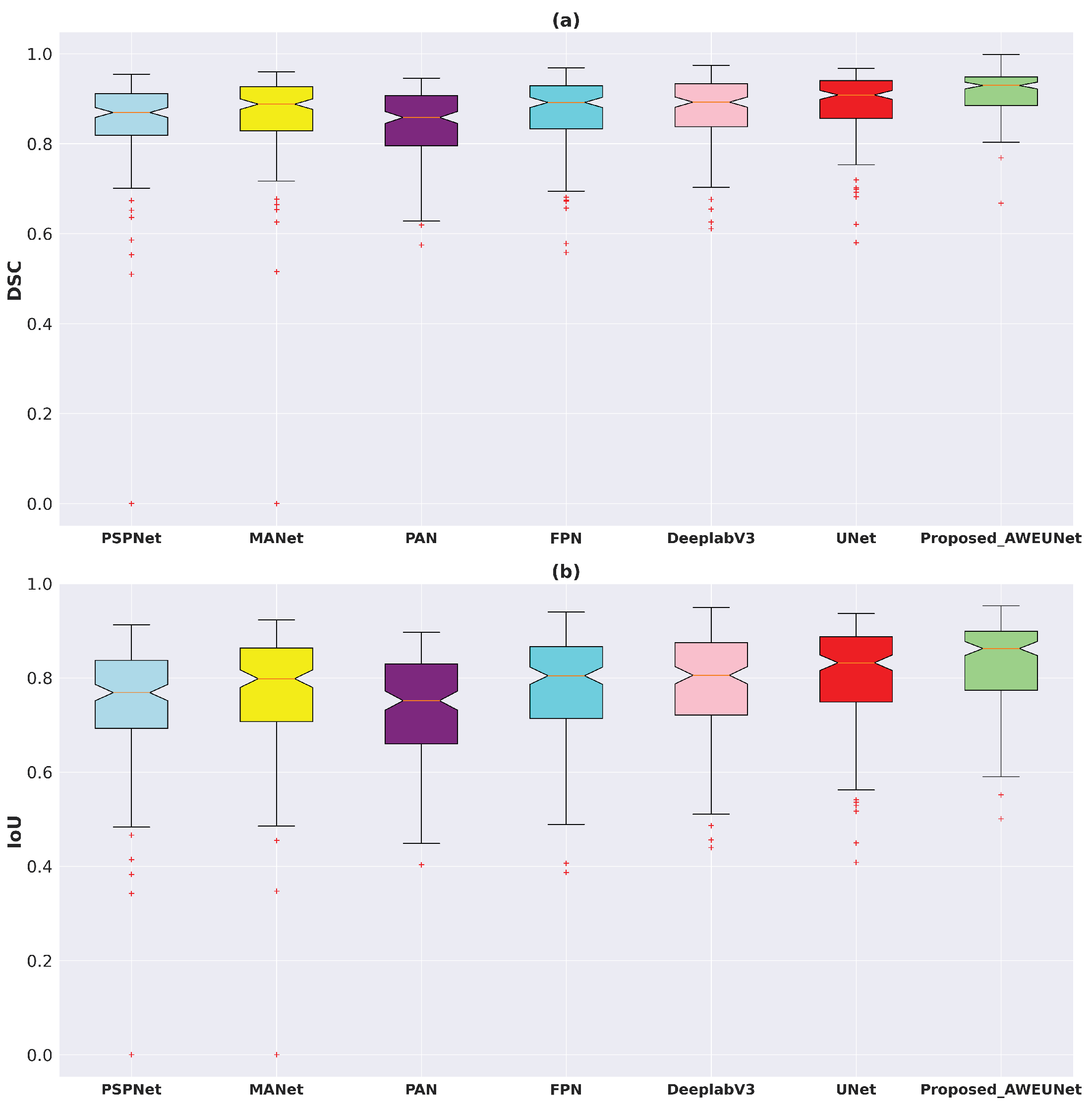
4.5. Nodule Segmentation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CAD | Computer-aided Diagnosis |
| CADe | Computer-aided Detection |
| CASe | Computer-aided Segmentation |
| CT | Computed Tomography |
| AI | Artificial Intelligence |
| GMM | Gaussian Mixture Model |
| CNNs | Convolutional Neural Networks |
| R-CNN | Region-based Convolutional Neural Network |
| ROI | Region of Interest (ROI) |
| RPN | Region Proposal Network |
| FPN | Feature Pyramid Network |
| ReLU | Rectified Linear Unit |
| SGD | Stochastic Gradient Descent |
| BCE | Binary Cross-Entropy |
| Dice | Dice Coefficient |
| IoU | Intersection Over Union |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
| ACC | Accuracy |
| SEN | Sensitivity |
| SPE | Specificity |
| GPU | Graphics Processing Unit |
| GB | Gigabytes |
| DL | Deep Learning |
References
- Cancer. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer/ (accessed on 8 August 2021).
- World Lung Cancer Day 2020 Fact Sheet. Available online: https://www.chestnet.org/newsroom/chest-news/2020/07/world-lung-cancer-day-2020-fact-sheet/ (accessed on 8 August 2021).
- The National Lung Screening Trial Research Team. Reduced lung-cancer mortality with low-dose computed tomographic screening. N. Engl. J. Med. 2011, 365, 395–409. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, K.H.; Lee, T.L.M.; Yen, M.H.; Kou, S.; Rosen, B.; Chiang, J.H.; Kohane, I.S. Reproducible Machine Learning Methods for Lung Cancer Detection Using Computed Tomography Images: Algorithm Development and Validation. J. Med. Internet Res. 2020, 22, e16709. [Google Scholar] [CrossRef] [PubMed]
- Seattle Cancer Care Alliance Proton Therapy Center. Available online: https://www.sccaprotontherapy.com/cancers-treated/lung-cancer-treatment (accessed on 8 August 2021).
- Callister, M.; Baldwin, D.; Akram, A.; Barnard, S.; Cane, P.; Draffan, J.; Franks, K.; Gleeson, F.; Graham, R.; Malhotra, P.; et al. British Thoracic Society guidelines for the investigation and management of pulmonary nodules: Accredited by NICE. Thorax 2015, 70, ii1–ii54. [Google Scholar] [CrossRef] [Green Version]
- Aresta, G.; Jacobs, C.; Araújo, T.; Cunha, A.; Ramos, I.; van Ginneken, B.; Campilho, A. iW-Net: An automatic and minimalistic interactive lung nodule segmentation deep network. Sci. Rep. 2019, 9, 11591. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keetha, N.V.; Babu P, S.A.; Annavarapu, C.S.R. U-Det: A Modified U-Net architecture with bidirectional feature network for lung nodule segmentation. arXiv 2020, arXiv:2003.09293. [Google Scholar]
- Cao, H.; Liu, H.; Song, E.; Hung, C.C.; Ma, G.; Xu, X.; Jin, R.; Lu, J. Dual-branch residual network for lung nodule segmentation. Appl. Soft Comput. 2020, 86, 105934. [Google Scholar] [CrossRef]
- Wu, B.; Zhou, Z.; Wang, J.; Wang, Y. Joint learning for pulmonary nodule segmentation, attributes and malignancy prediction. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1109–1113. [Google Scholar]
- Tang, H.; Zhang, C.; Xie, X. Nodulenet: Decoupled false positive reduction for pulmonary nodule detection and segmentation. In Proceedings of the 22nd International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 266–274. [Google Scholar]
- Kumar Singh, V.; Abdel-Nasser, M.; Pandey, N.; Puig, D. Lunginfseg: Segmenting COVID-19 infected regions in lung ct images based on a receptive-field-aware deep learning framework. Diagnostics 2021, 11, 158. [Google Scholar] [CrossRef]
- Jiang, J.; Hu, Y.-C.; Liu, C.J.; Halpenny, D.; Hellmann, M.D.; Deasy, J.O.; Mageras, G.; Veeraraghavan, H. Multiple resolution residually connected feature streams for automatic lung tumor segmentation from CT images. IEEE Trans. Med. Imaging 2018, 38, 134–144. [Google Scholar] [CrossRef]
- Dehmeshki, J.; Amin, H.; Valdivieso, M.; Ye, X. Segmentation of pulmonary nodules in thoracic CT scans: A region growing approach. IEEE Trans. Med. Imaging 2008, 27, 467–480. [Google Scholar] [CrossRef] [Green Version]
- Tan, Y.; Schwartz, L.H.; Zhao, B. Segmentation of lung lesions on CT scans using watershed, active contours, and Markov random field. Med. Phys. 2013, 40, 043502. [Google Scholar] [CrossRef] [Green Version]
- Farag, A.A.; Abd El Munim, H.E.; Graham, J.H.; Farag, A.A. A novel approach for lung nodules segmentation in chest CT using level sets. IEEE Trans. Image Process. 2013, 22, 5202–5213. [Google Scholar] [CrossRef]
- Dai, S.; Lu, K.; Dong, J.; Zhang, Y.; Chen, Y. A novel approach of lung segmentation on chest CT images using graph cuts. Neurocomputing 2015, 168, 799–807. [Google Scholar] [CrossRef]
- Navya, K.; Pradeep, G. Lung Nodule Segmentation Using Adaptive Thresholding and Watershed Transform. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 630–633. [Google Scholar]
- Li, X.; Li, B.; Liu, F.; Yin, H.; Zhou, F. Segmentation of pulmonary nodules using a GMM fuzzy C-means algorithm. IEEE Access 2020, 8, 37541–37556. [Google Scholar] [CrossRef]
- Savic, M.; Ma, Y.; Ramponi, G.; Du, W.; Peng, Y. Lung nodule segmentation with a region-based fast marching method. Sensors 2021, 21, 1908. [Google Scholar] [CrossRef]
- Skourt, B.A.; El Hassani, A.; Majda, A. Lung CT image segmentation using deep neural networks. Procedia Comput. Sci. 2018, 127, 109–113. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Hancock, M.C.; Magnan, J.F. Lung nodule malignancy classification using only radiologist-quantified image features as inputs to statistical learning algorithms: Probing the Lung Image Database Consortium dataset with two statistical learning methods. J. Med. Imaging 2016, 3, 044504. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Zeren, M.T.; Aytulun, S.K.; Kırelli, Y. Comparison of SSD and faster R-CNN algorithms to detect the airports with data set which obtained from unmanned aerial vehicles and satellite images. Avrupa Bilim ve Teknoloji Dergisi 2020, 643–658. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Quader, N.; Bhuiyan, M.M.I.; Lu, J.; Dai, P.; Li, W. Weight Excitation: Built-in Attention Mechanisms in Convolutional Neural Networks. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 87–103. [Google Scholar]
- Armato, S.G., III; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans. Med. Phys. 2011, 38, 915–931. [Google Scholar]
- Setio, A.A.A.; Traverso, A.; De Bel, T.; Berens, M.S.; Van Den Bogaard, C.; Cerello, P.; Chen, H.; Dou, Q.; Fantacci, M.E.; Geurts, B.; et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: The LUNA16 challenge. Med. Image Anal. 2017, 42, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Gulcehre, C.; Sotelo, J.; Bengio, Y. A robust adaptive stochastic gradient method for deep learning. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 125–132. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Fan, T.; Wang, G.; Li, Y.; Wang, H. Ma-net: A multi-scale attention network for liver and tumor segmentation. IEEE Access 2020, 8, 179656–179665. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Methods/Architectures | Dataset | Pre-Processing | Post-Processing | Results |
|---|---|---|---|---|---|
| Classical computer vision-based | |||||
| [14] | Region growing | PRIVATE | Local contrast & hole filling | - | acc |
| [15] | Active contours | LIDC-IDRI | Thresholding & morph operations | Markov random field | IoU |
| [16] | Level sets | LIDC-IDRI | Statistical intensity | Region condition | acc |
| [17] | Graph cuts | PRIVATE | Gaussian smoothing | - | dice |
| [18] | Adaptive thresholding | LIDC-IDRI | Histogram equalization & noise filtering | Morph operations | acc |
| [19] | GMM fuzzy C-means | LIDC-IDRI & GHGZMCPLA | Non-local mean filter & gaussian pyramid | Random walker | dice |
| [20] | Region-based fast marching | LIDC-IDRI | Convex hulls | Mean threshold | 61–93% dice |
| Deep learning-based | |||||
| [10] | U-Net | LIDC-IDRI | Nodule ROI selection | - | dice |
| [7] | iW-Net | LIDC-IDRI | Nodule ROI selection | - | IoU |
| [8] | U-Det | LUNA16 | Data aug. | - | dice |
| [11] | Nodulenet | LIDC-IDRI & LUNA16 | Nodule ROI selection & Data aug. | - | IoU |
| [9] | DB-ResNet | LIDC-IDRI | Nodule ROI selection & Data aug. | Remove noisy voxel | dice |
| [13] | MRRN | TCIA & MSKCC & LIDC-IDRI | Nodule ROI selection & Data aug. | - | dice |
| Datasets | Models | AP(%) |
|---|---|---|
| LIDC-IDRI | Optimized Faster R-CNN | 91.44 |
| Original Faster R-CNN | 85.45 | |
| Fast R-CNN | 79.41 | |
| R-CNN | 75.48 | |
| LUNA16 | Optimized Faster R-CNN | 92.67 |
| Original Faster R-CNN | 89.31 | |
| Fast R-CNN | 82.32 | |
| R-CNN | 78.17 |
| Datasets | Models | ACC | SEN | SPE | DSC | IoU |
|---|---|---|---|---|---|---|
| LUNA16 | PSPNet | 0.8718 | 0.8711 | 0.9012 | 0.8512 | 0.7513 |
| MANet | 0.8874 | 0.8686 | 0.9285 | 0.8663 | 0.7743 | |
| PAN | 0.8604 | 0.8709 | 0.8873 | 0.8424 | 0.7354 | |
| FPN | 0.8846 | 0.9143 | 0.8905 | 0.8722 | 0.7806 | |
| DeeplabV3 | 0.8918 | 0.9301 | 0.8910 | 0.8794 | 0.7916 | |
| U-Net (baseline) | 0.9014 | 0.9136 | 0.9199 | 0.8882 | 0.8054 | |
| Proposed_AWEU-Net | 0.9132 | 0.9169 | 0.9346 | 0.8979 | 0.8234 | |
| LIDC-IDRI | PSPNet | 0.9309 | 0.8514 | 0.9620 | 0.8684 | 0.7783 |
| MANet | 0.9327 | 0.8749 | 0.9557 | 0.8788 | 0.7905 | |
| PAN | 0.9268 | 0.8369 | 0.9603 | 0.8577 | 0.7653 | |
| FPN | 0.9393 | 0.8981 | 0.9562 | 0.8934 | 0.8127 | |
| DeeplabV3 | 0.9429 | 0.9023 | 0.9602 | 0.8983 | 0.8191 | |
| U-Net (baseline) | 0.9436 | 0.8968 | 0.9635 | 0.8987 | 0.8200 | |
| Proposed_AWEU-Net | 0.9466 | 0.9084 | 0.9641 | 0.9035 | 0.8321 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banu, S.F.; Sarker, M.M.K.; Abdel-Nasser, M.; Puig, D.; Raswan, H.A. AWEU-Net: An Attention-Aware Weight Excitation U-Net for Lung Nodule Segmentation. Appl. Sci. 2021, 11, 10132. https://doi.org/10.3390/app112110132
Banu SF, Sarker MMK, Abdel-Nasser M, Puig D, Raswan HA. AWEU-Net: An Attention-Aware Weight Excitation U-Net for Lung Nodule Segmentation. Applied Sciences. 2021; 11(21):10132. https://doi.org/10.3390/app112110132
Chicago/Turabian StyleBanu, Syeda Furruka, Md. Mostafa Kamal Sarker, Mohamed Abdel-Nasser, Domenec Puig, and Hatem A. Raswan. 2021. "AWEU-Net: An Attention-Aware Weight Excitation U-Net for Lung Nodule Segmentation" Applied Sciences 11, no. 21: 10132. https://doi.org/10.3390/app112110132