
Deep Learning-Based Method to Recognize Line Objects and Flow Arrows from Image-Format Piping and Instrumentation Diagrams for Digitization



Abstract
:1. Introduction
2. Related Work
3. Method of Recognizing Line Objects
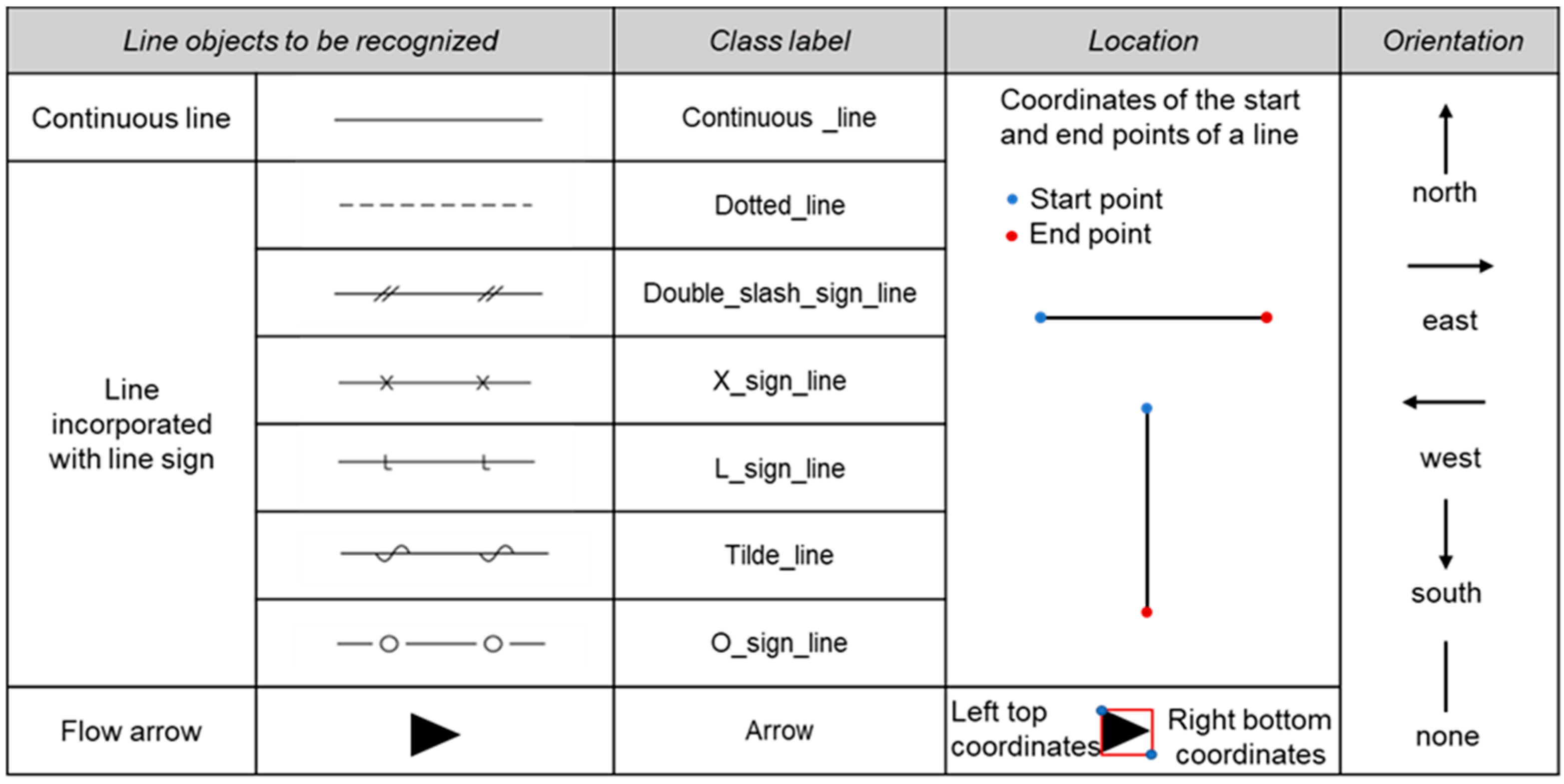
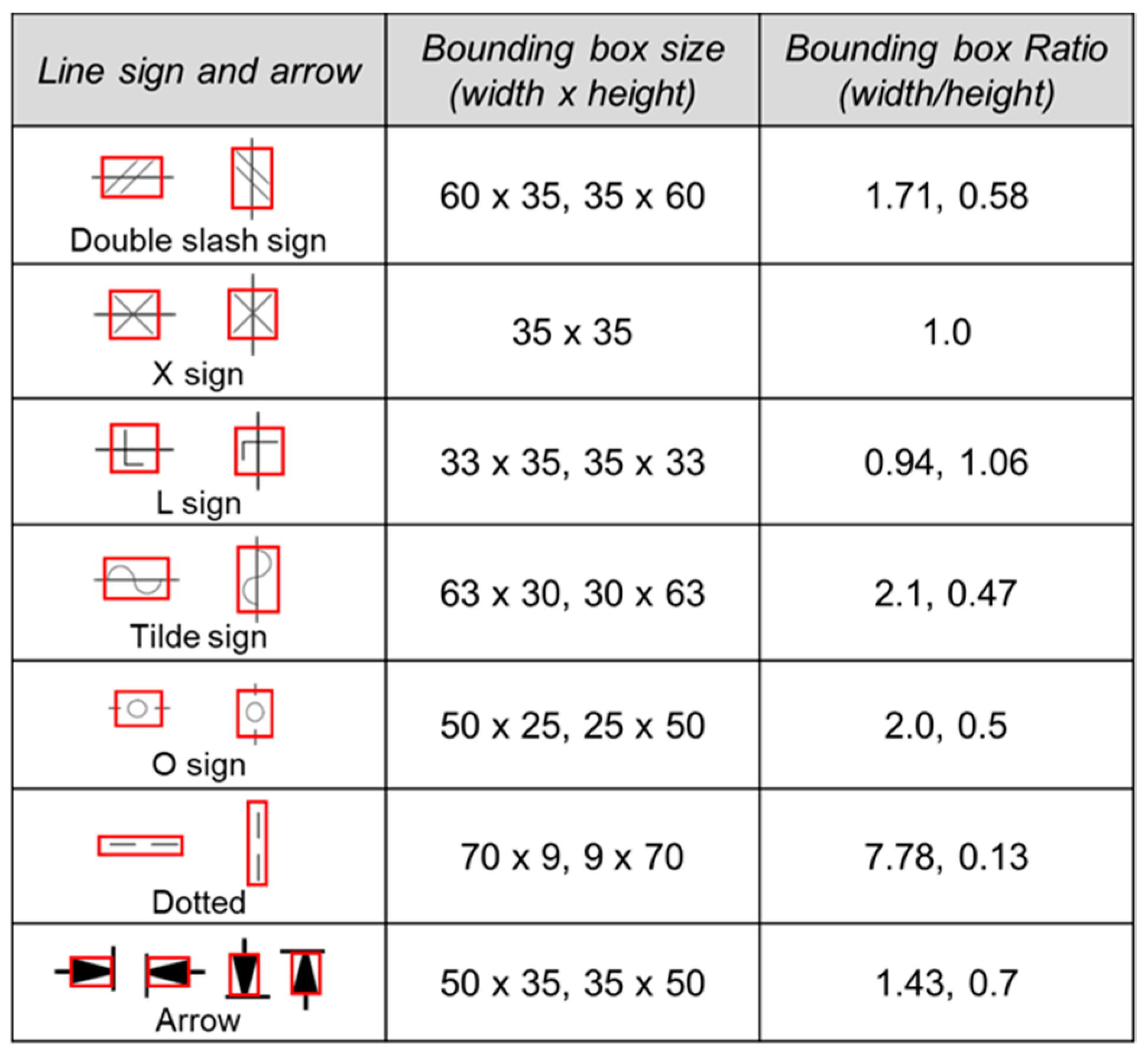
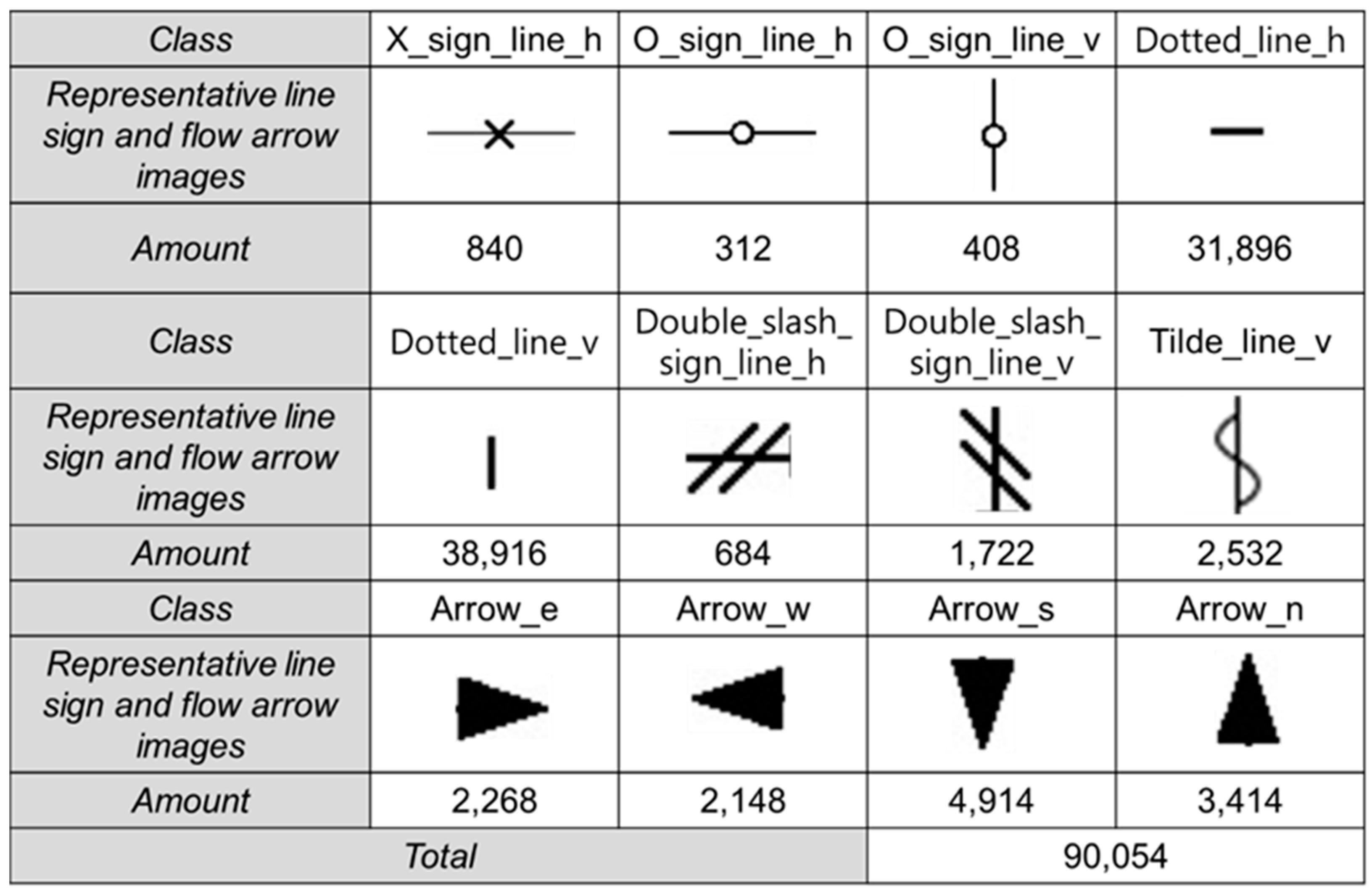
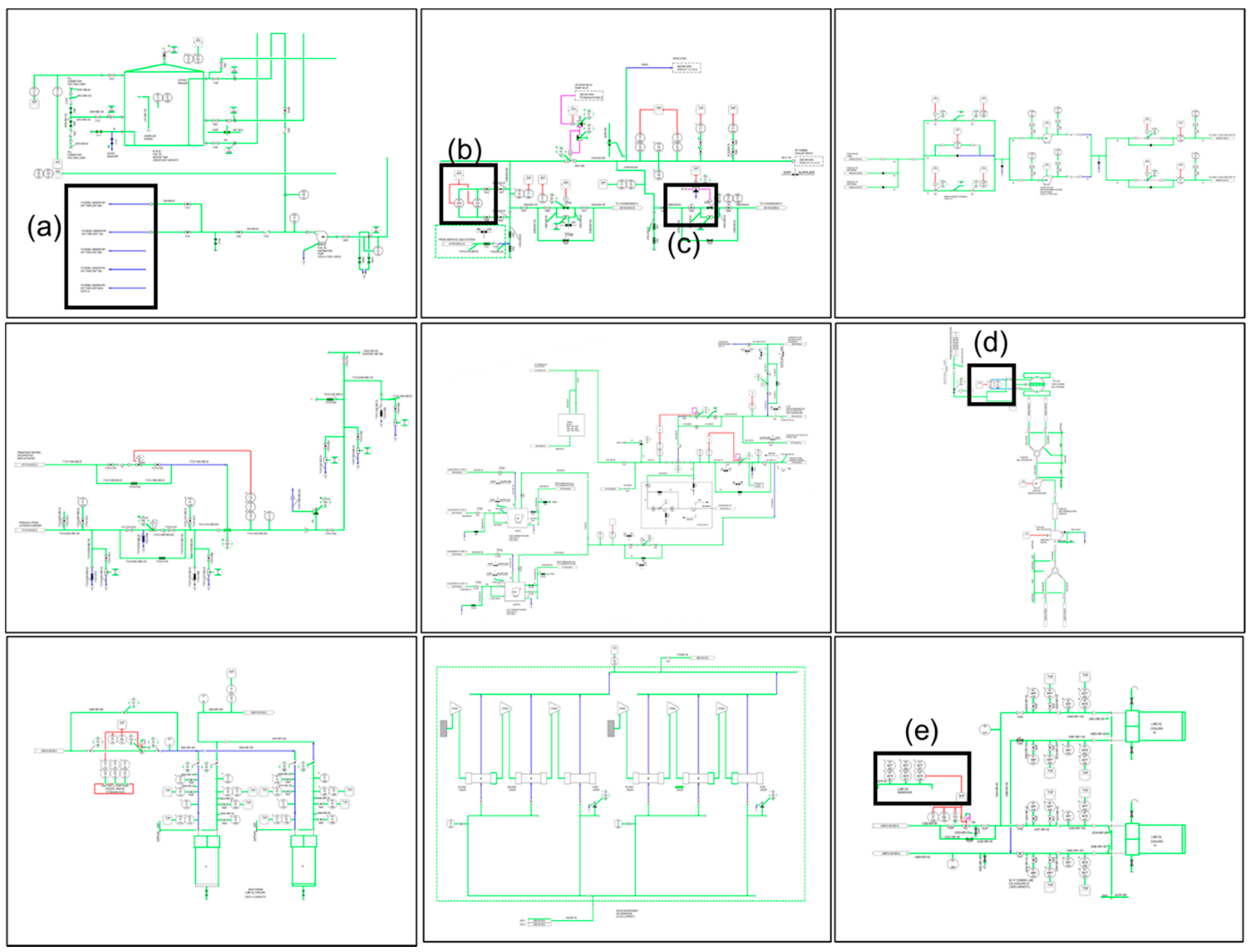
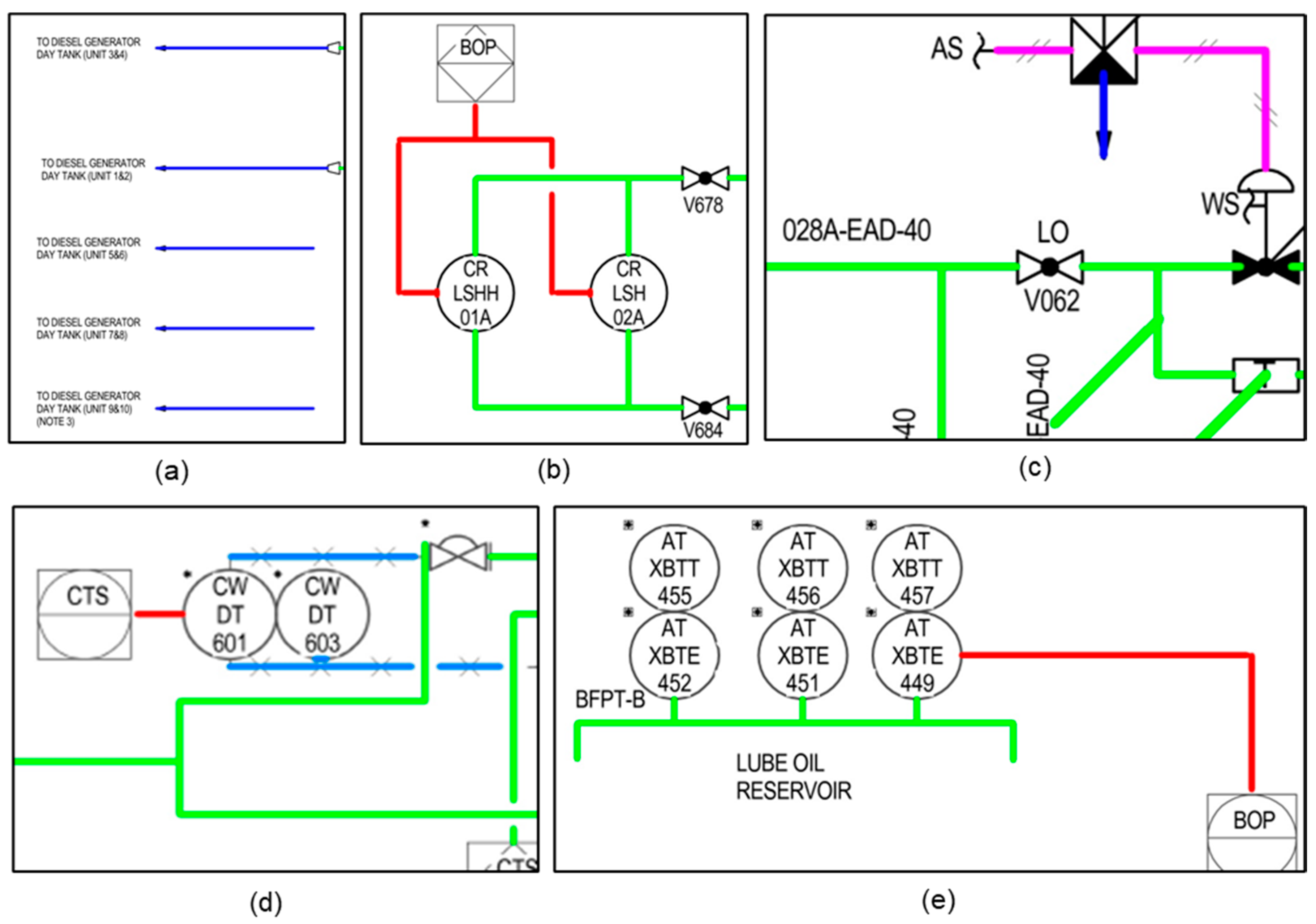
3.1. Line Objects to Be Recognized in P&ID
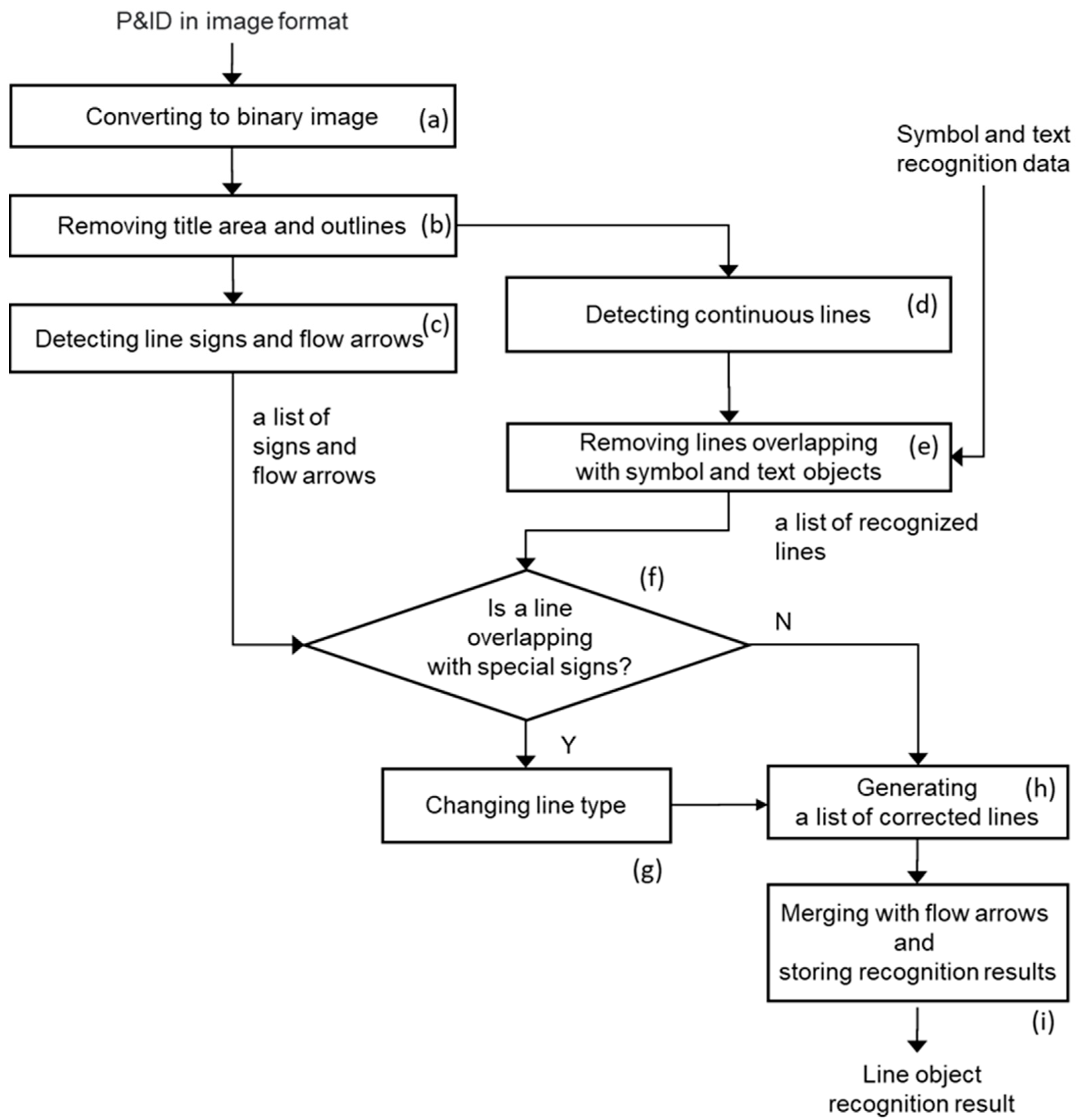
3.2. Method of Recognizing Line Objects
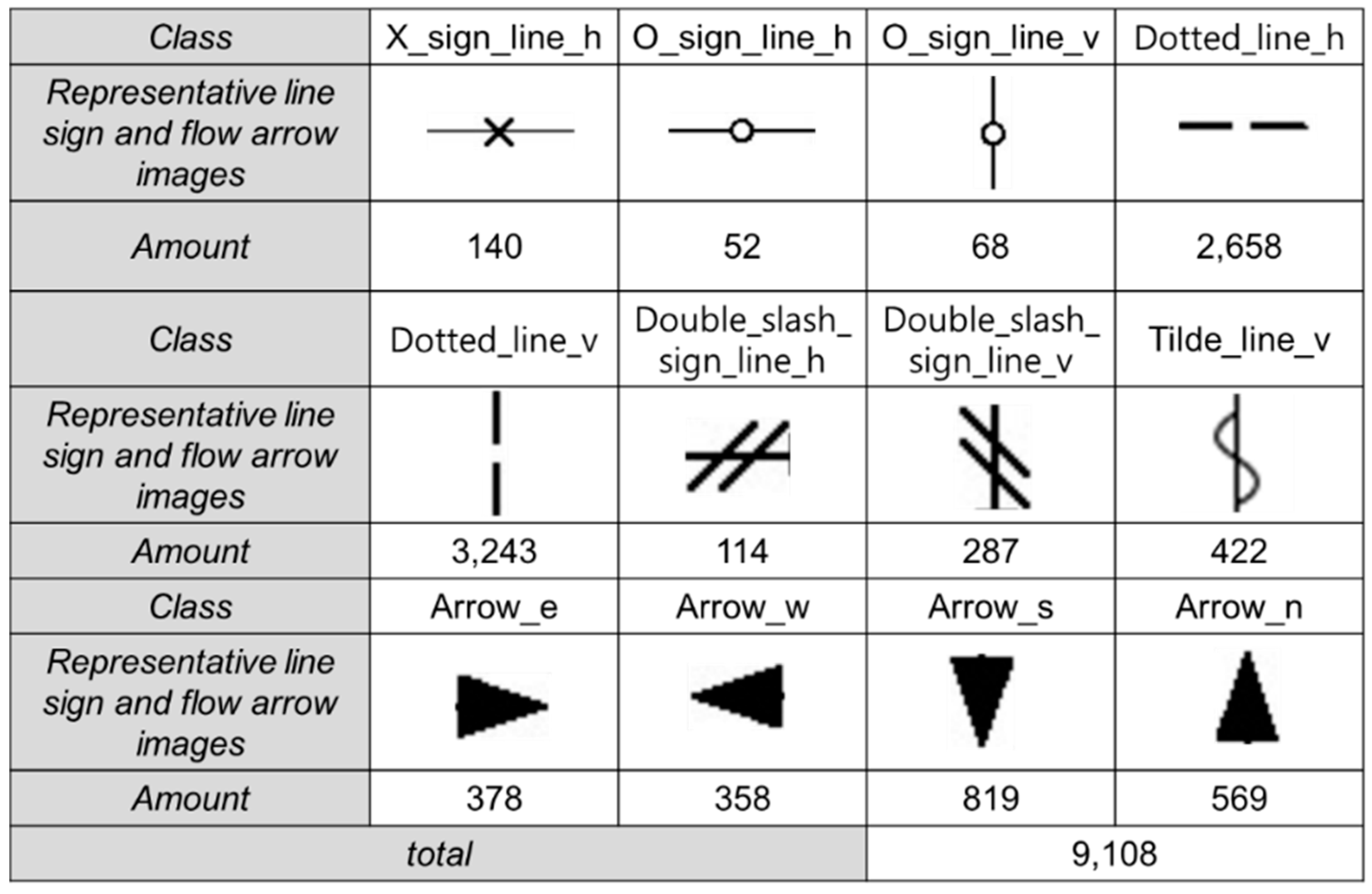
4. Training Dataset Construction for Line Recognition
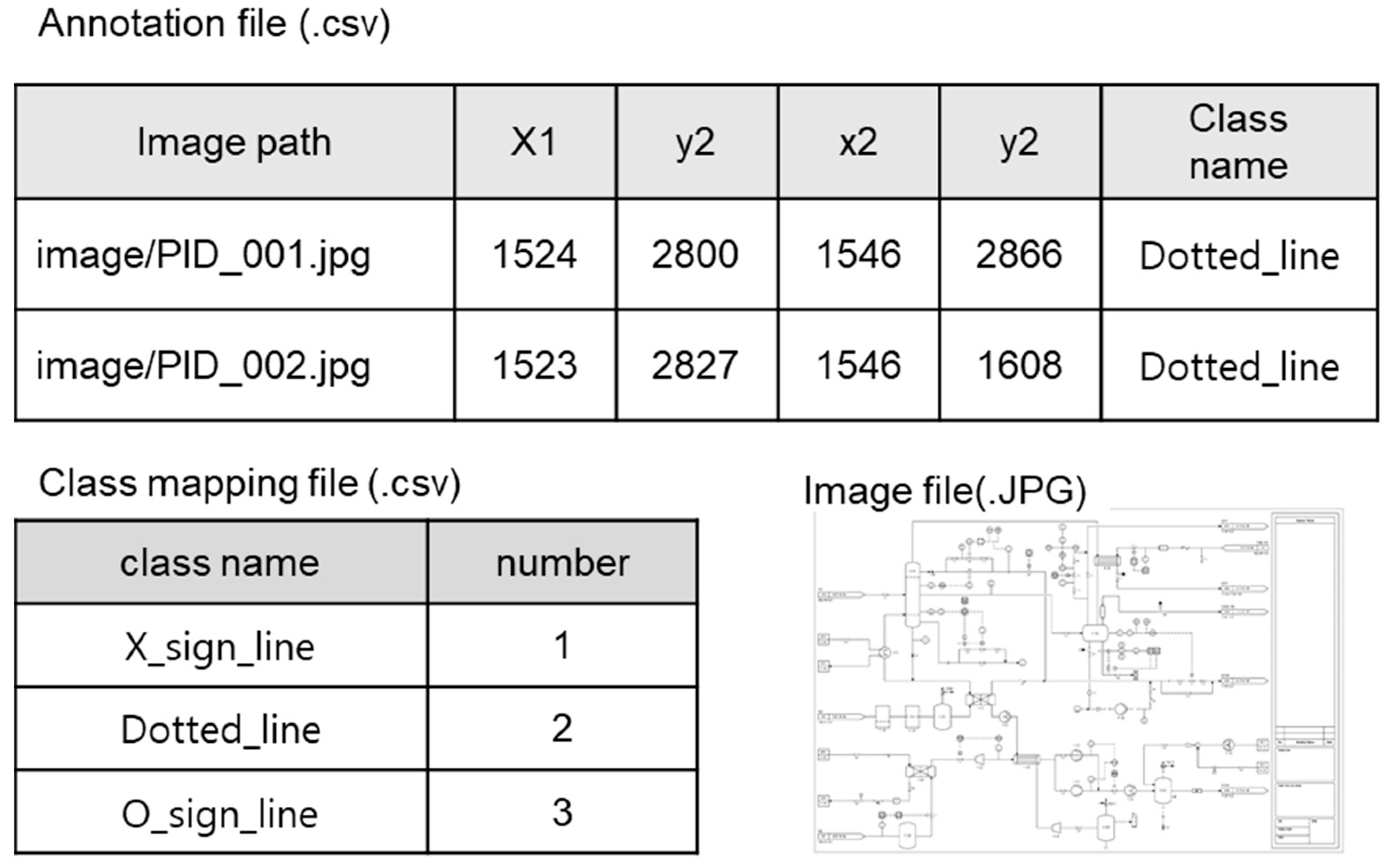
4.1. Preparation of Initial Training Dataset
4.2. Augmentation of the Training Dataset
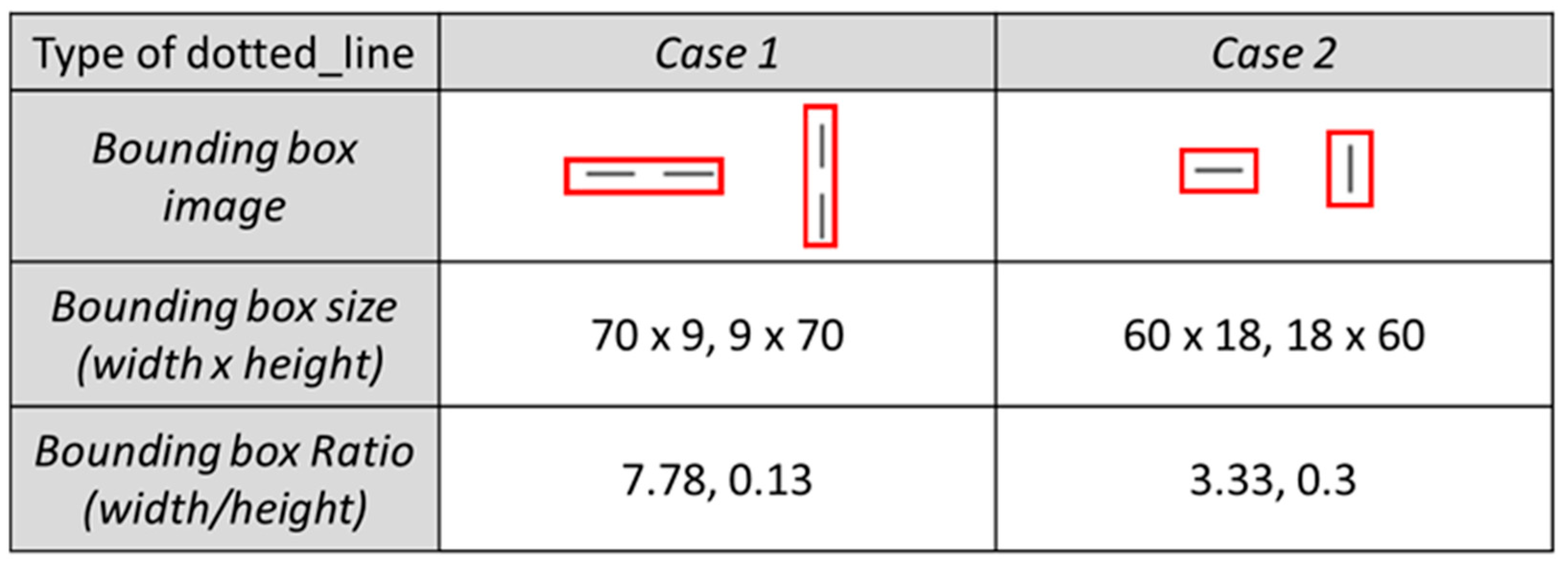
4.2.1. Change of Bounding Box Size for the Dotted Line
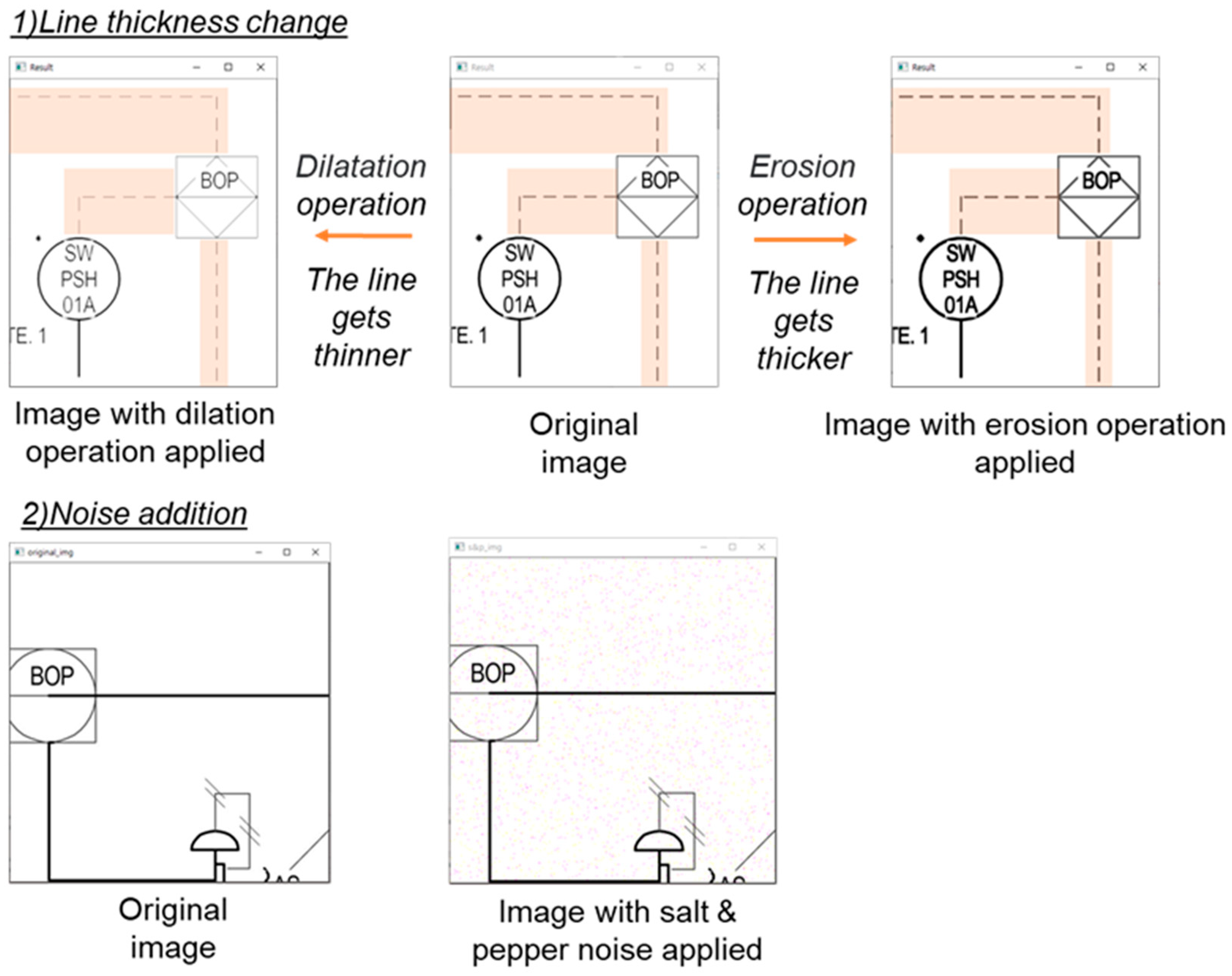
4.2.2. Data Augmentation
5. Element Technologies for Line Recognition
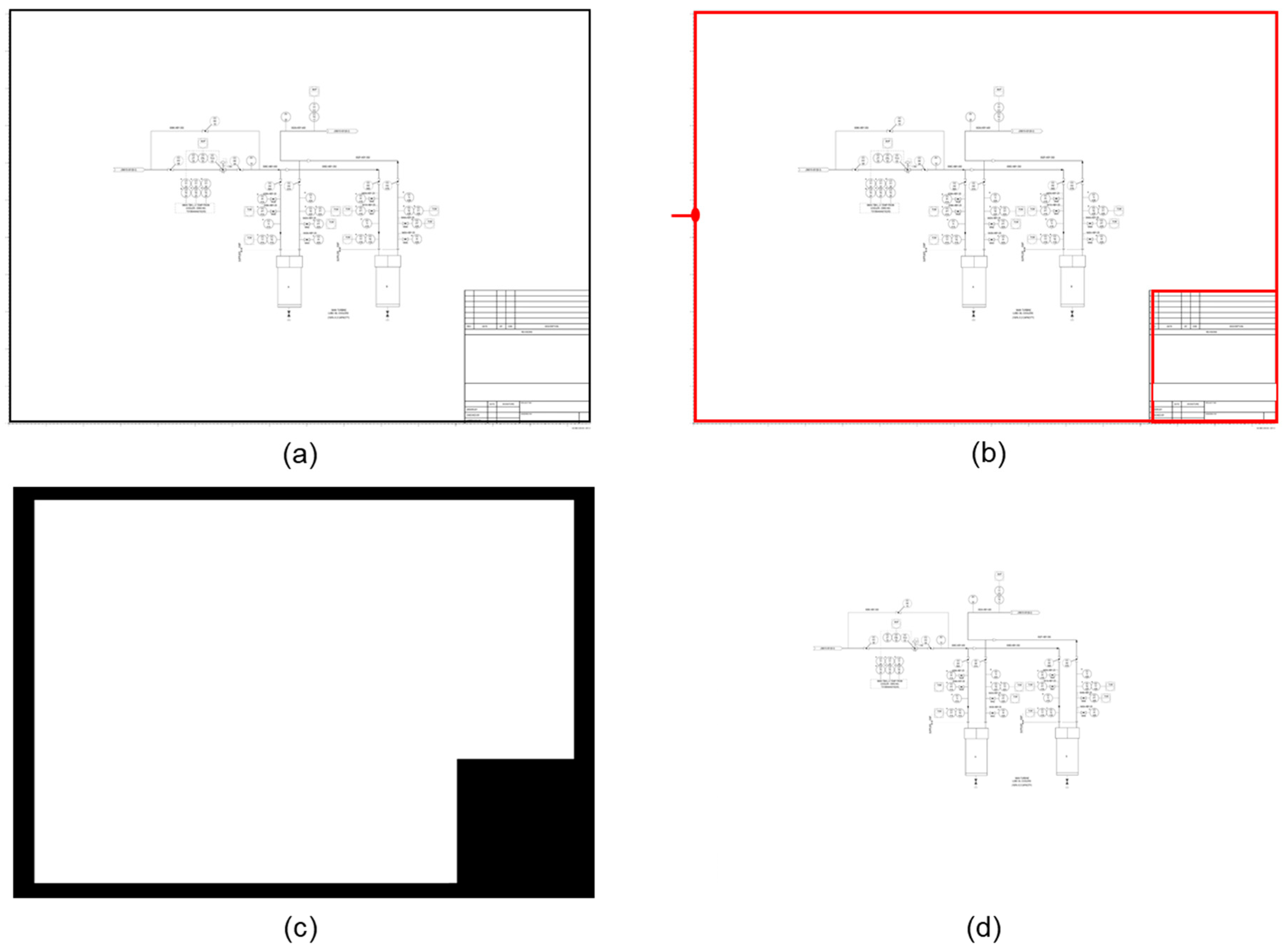
5.1. Removal of P&ID Title and Outer Border
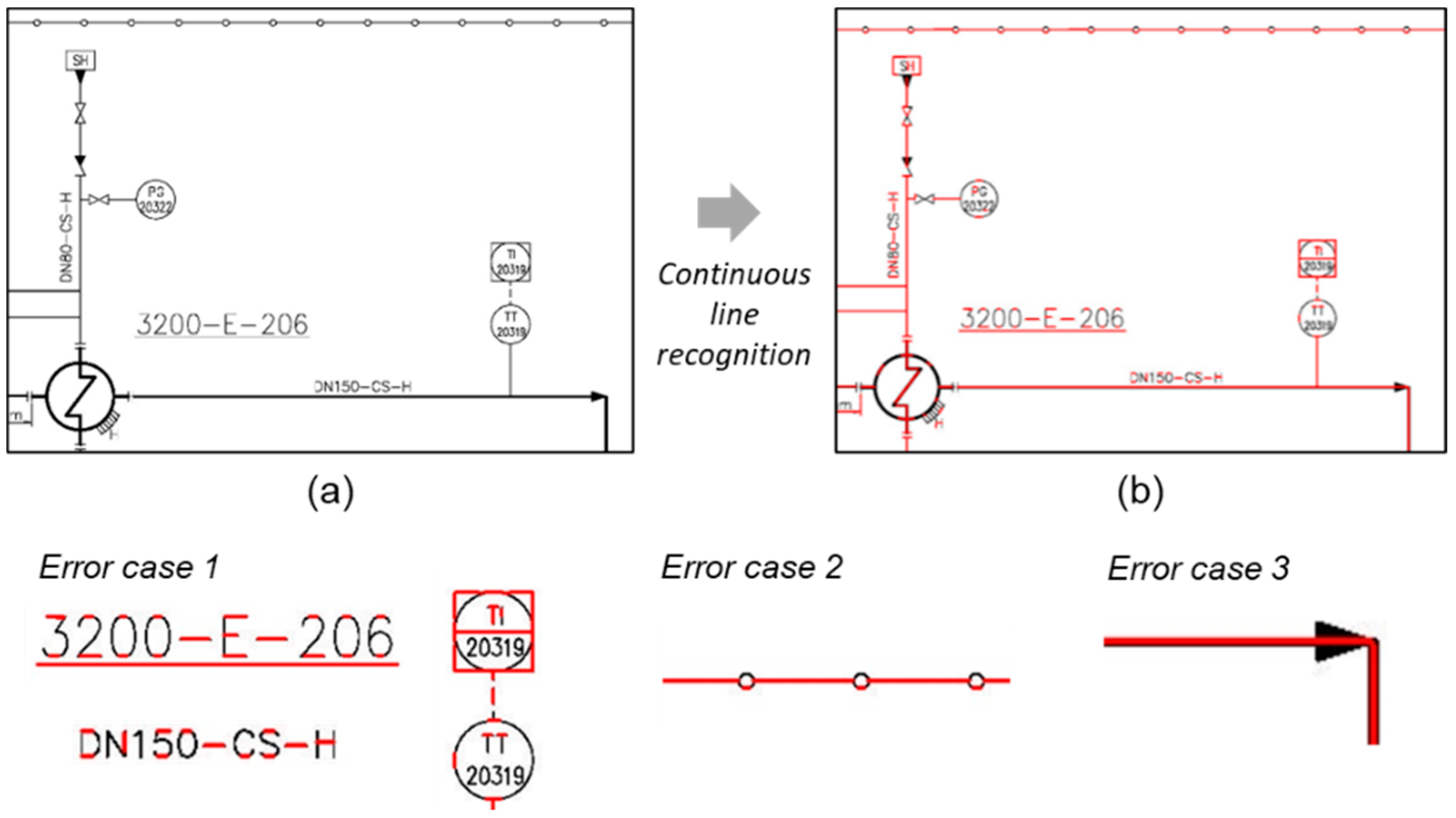
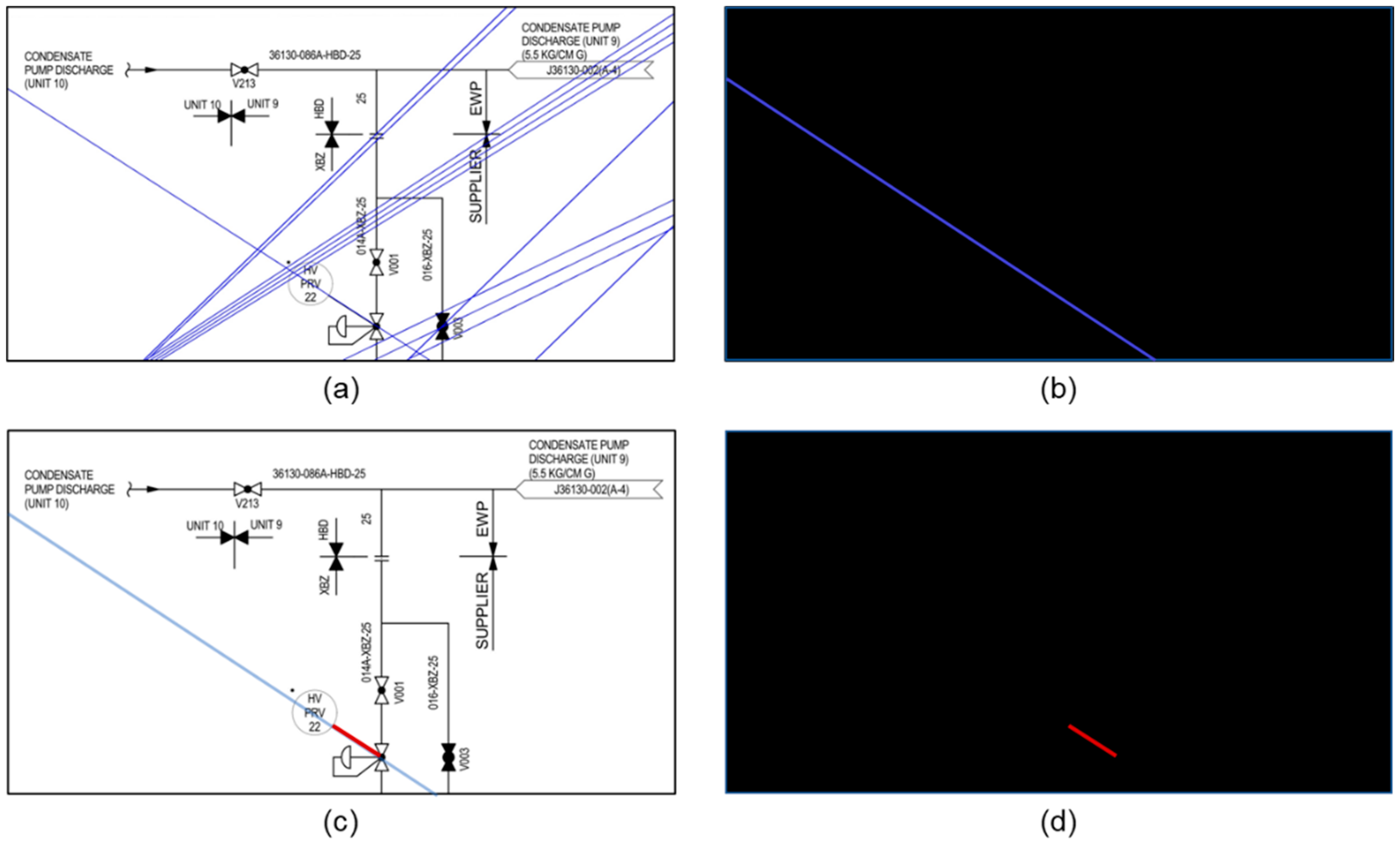
5.2. Detection of Continuous Lines in a Diagram
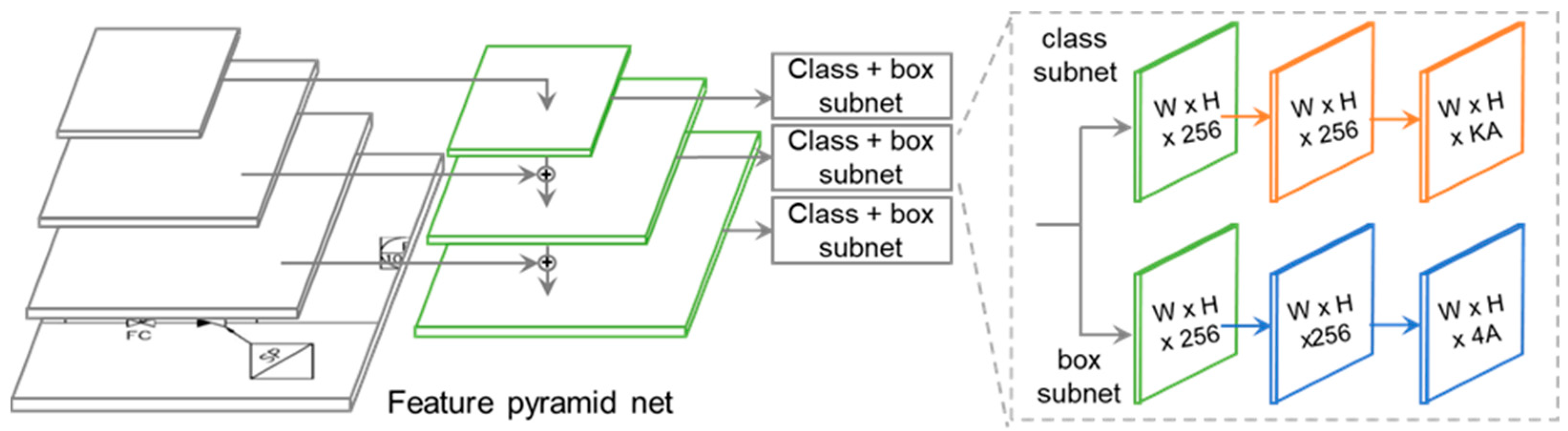
5.3. Detecting Line Signs and Flow Arrows in a Diagram and Determining Line Types
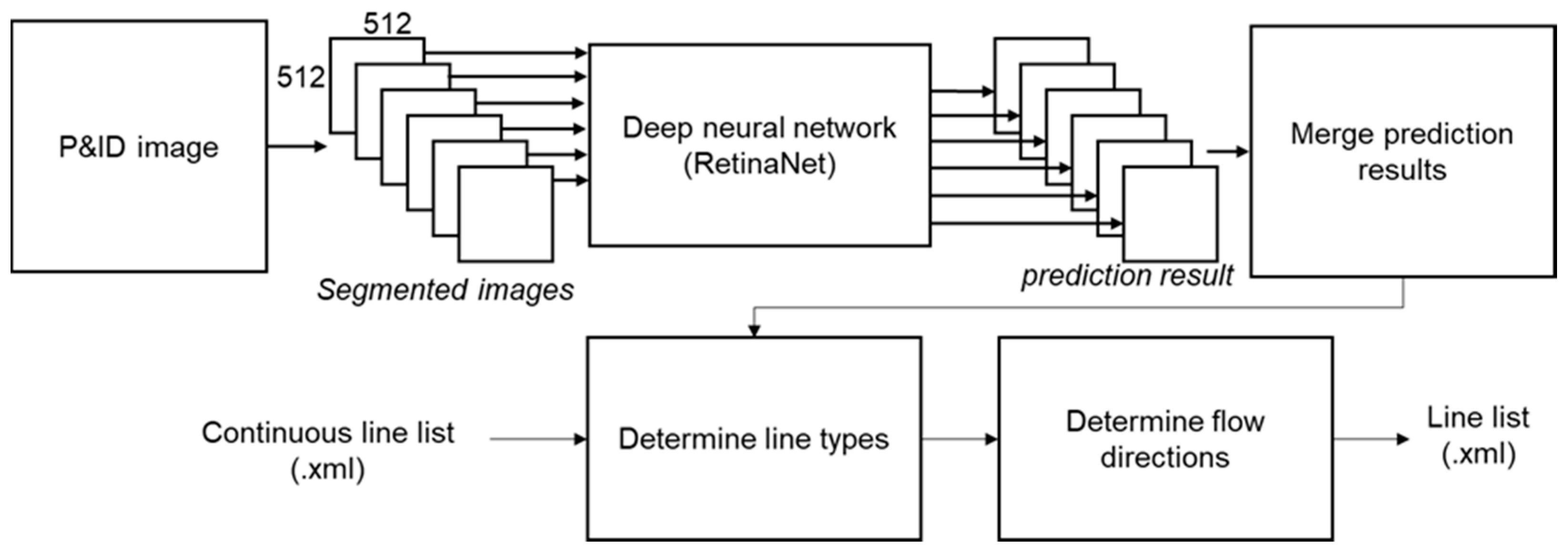
5.3.1. Deep Neural Network for Line Sign Recognition in a Diagram
5.3.2. Changing of Line Types and Merging of Lines of the Same Types
5.4. Storing Line Recognition Results
6. Implementation and Experiment
6.1. Experimental Setup
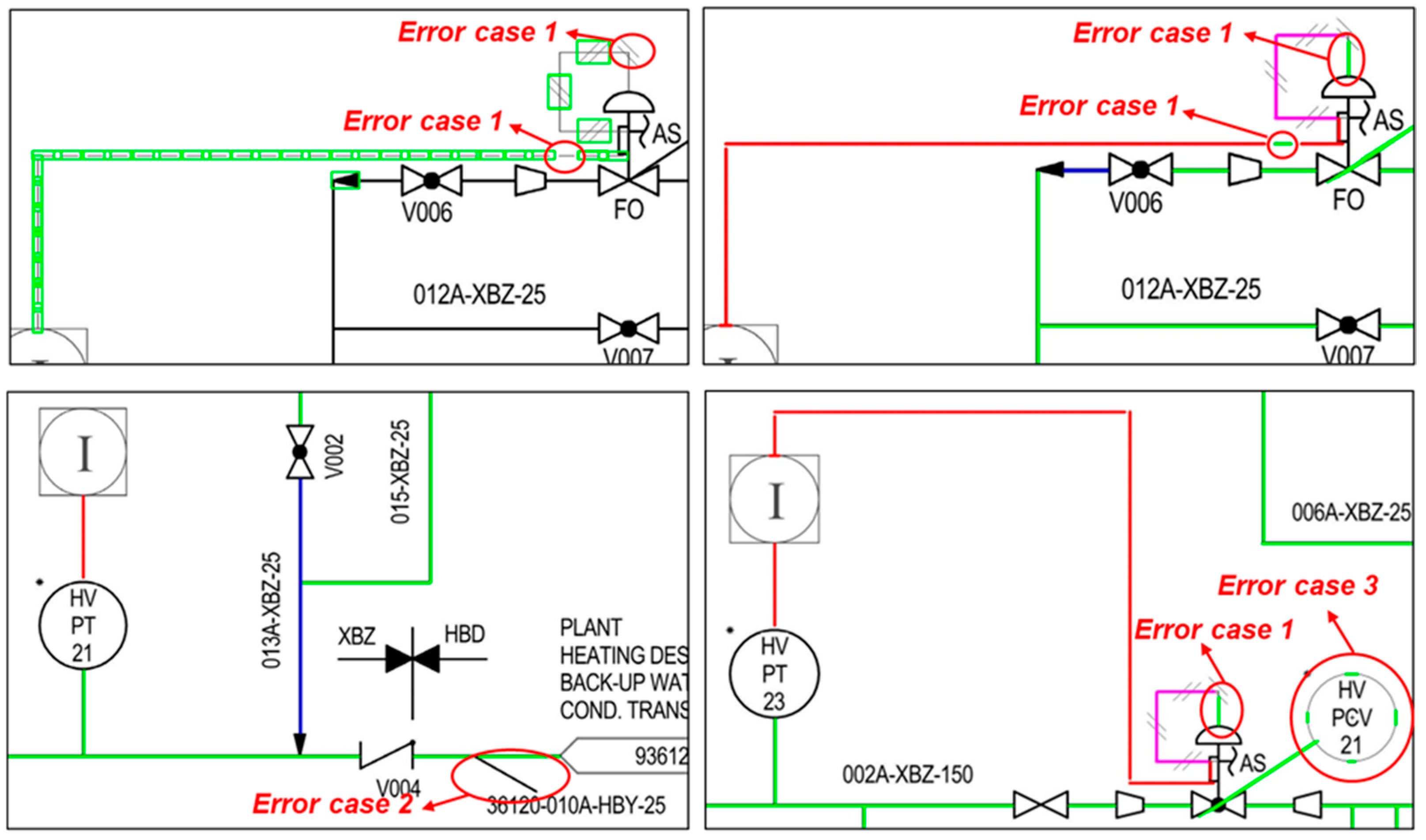
6.2. Experimental Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Tanzi, L.; Vezzetti, E.; Moreno, R.; Aprato, A.; Audisio, A.; Massè, A. Hierarchical fracture classification of proximal femur X-ray images using a multistage deep learning approach. Eur. J. Radiol. 2020, 133, 109373. [Google Scholar] [CrossRef]
- Nonis, F.; Barbiero, P.; Cirrincione, G.; Olivetti, E.C.; Marcolin, F.; Vezzetti, E. Understanding Abstraction in Deep CNN: An Application on Facial Emotion Recognition. In Progresses in Artificial Intelligence and Neural Systems; Springer: Singapore, 2021; pp. 281–290. [Google Scholar]
- Quiroz, I.A.; Alférez, G.H. Image recognition of Legacy blueberries in a Chilean smart farm through deep learning. Comput. Electron. Agric. 2020, 168, 105044. [Google Scholar] [CrossRef]
- Ejiri, M.; Kakumoto, S.; Miyatake, T.; Shimada, S.; Iwamura, K. Automatic recognition of engineering drawings and maps. In Image Analysis Applications; CRC Press: Boca Raton, FL, USA, 2020; pp. 73–126. [Google Scholar]
- Scherr, S.; Arendt, F.; Frissen, T.; Oramas, M.J. Detecting intentional self-harm on Instagram: Development, testing, and validation of an automatic image-recognition algorithm to discover cutting-related posts. Soc. Sci. Comput. Rev. 2020, 38, 673–685. [Google Scholar] [CrossRef]
- Wu, C.; Jiang, P.; Ding, C.; Feng, F.; Chen, T. Intelligent fault diagnosis of rotating machinery based on one-dimensional convolutional neural network. Comput. Ind. 2019, 108, 53–61. [Google Scholar] [CrossRef]
- Boyat, A.K.; Joshi, B.K. A review paper: Noise models in digital image processing. arXiv 2015, arXiv:1505.03489. [Google Scholar] [CrossRef]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 345–360. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Froba, B.; Ernst, A. Face detection with the modified census transform. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 91–96. [Google Scholar]
- Wang, L. (Ed.) Support Vector Machines: Theory and Applications; Springer: New York, NY, USA, 2015; Volume 177, pp. 1–47. [Google Scholar]
- Li, X.; Wang, L.; Sung, E. AdaBoost with SVM-based component classifiers. Eng. Appl. Artif. Intell. 2008, 21, 785–795. [Google Scholar] [CrossRef] [Green Version]
- Zhiqiang, W.; Jun, L. A review of object detection based on convolutional neural network. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 11104–11109. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep Neural Networks for Object Detection. In Proceedings of the 26th Neural Information Processing Systems Conference (NIPS 2013), Stateline, NV, USA, 5–10 December 2013; pp. 2553–2561. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Illingworth, J.; Kittler, J. A survey of the Hough transform. Comput. Vis. Graph. Image Process. 1988, 44, 87–116. [Google Scholar] [CrossRef]
- Narote, S.P.; Bhujbal, P.N.; Narote, A.S.; Dhane, D.M. A review of recent advances in lane detection and departure warning system. Pattern Recognit. 2018, 73, 216–234. [Google Scholar] [CrossRef]
- Zhang, T.Y.; Suen, C.Y. A fast parallel algorithm for thinning digital patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Tang, J.; Li, S.; Liu, P. A Review of Lane Detection Methods based on Deep Learning. Pattern Recognit. 2020, 111, 107623. [Google Scholar] [CrossRef]
- Ko, Y.; Jun, J.; Ko, D.; Jeon, M. Key points estimation and point instance segmentation approach for lane detection. arXiv 2020, arXiv:2002.06604. [Google Scholar]
- Qu, Z.; Jin, H.; Zhou, Y.; Yang, Z.; Zhang, W. Focus on Local: Detecting Lane Marker from Bottom Up via Key Point. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–24 June 2021; pp. 14122–14130. [Google Scholar]
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-to-down Lane Detection Framework Based on Conditional Convolution. arXiv 2021, arXiv:2105.05003. [Google Scholar]
- Tornbre, K. Technical drawing recognition and understanding: From pixels to semantics. In Proceedings of the Workshop on Machine Vision and Application, Tokyo, Japan, 7–9 December 1992; pp. 393–401. [Google Scholar]
- Fahn, C.S.; Wang, J.F.; Lee, J.Y. A topology-based component extractor for understanding electronic circuit diagrams. Comput. Vis. Graph. Image Process. 1988, 44, 119–138. [Google Scholar] [CrossRef]
- Lee, S.W.; Kim, J.H.; Groen, F.C. Translation-, rotation-and scale-invariant recognition of hand-drawn symbols in schematic diagrams. Int. J. Pattern Recognit. Artif. Intell. 1990, 4, 1–25. [Google Scholar] [CrossRef]
- Kang, S.O.; Lee, E.B.; Baek, H.K. A Digitization and Conversion Tool for Imaged Drawings to Intelligent Piping and Instrumentation Diagrams (P&ID). Energies 2019, 12, 2593. [Google Scholar]
- Fu, L.; Kara, L.B. From engineering diagrams to engineering models: Visual recognition and applications. Comput. Aided Des. 2011, 43, 278–292. [Google Scholar] [CrossRef]
- Rahul, R.; Paliwal, S.; Sharma, M.; Vig, L. Automatic Information Extraction from Piping and Instrumentation Diagrams. arXiv 2019, arXiv:1901.11383. [Google Scholar]
- Yu, E.S.; Cha, J.M.; Lee, T.; Kim, J.; Mun, D. Features recognition from piping and instrumentation diagrams in image format using a deep learning network. Energies 2019, 12, 4425. [Google Scholar] [CrossRef] [Green Version]
- Yun, D.Y.; Seo, S.K.; Zahid, U.; Lee, C.J. Deep Neural Network for Automatic Image Recognition of Engineering Diagrams. Appl. Sci. 2020, 10, 4005. [Google Scholar] [CrossRef]
- Kim, H.; Lee, W.; Kim, M.; Moon, Y.; Lee, T.; Cho, M.; Mun, D. Deep learning-based recognition of symbols and texts at an industrially applicable level from high-density piping and instrumentation diagram images. Expert Syst. Appl. 2021, 183, 115337. [Google Scholar] [CrossRef]
- Zlocha, M.; Dou, Q.; Glocker, B. Improving RetinaNet for CT lesion detection with dense masks from weak RECIST labels. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 402–410. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | |
|---|---|---|
| Diagram resolution | 9933 × 7016 | |
| Segmentation resolution | 512 × 512 | |
| Segmentation stride | 300 | |
| Epoch, step | 50, 2500 | |
| Anchor | Size | 322, 642, 1282, 2562, 5122 |
| Stride | 8, 16, 32, 64, 128 | |
| Ratio | 0.289, 0.581, 1.0, 1.721, 3.457 | |
| Scale | 0.949, 1.182, 1.543 | |
| Threshold score | 0.5 | |
| IOU threshold | 0.5 | |
| Test P&ID | Precision | Recall |
|---|---|---|
| 1 | 0.9657 | 0.9038 |
| 2 | 0.9732 | 0.9316 |
| 3 | 0.9787 | 0.9150 |
| 4 | 0.9531 | 0.8592 |
| 5 | 0.9709 | 0.9009 |
| 6 | 0.9183 | 0.8654 |
| 7 | 0.9771 | 0.8649 |
| 8 | 0.9412 | 0.9195 |
| 9 | 0.9750 | 0.8931 |
| Average | 0.9614 | 0.8959 |
| Test P&ID | Object Number in Training Dataset | Precision | Recall | Rank |
|---|---|---|---|---|
| X_sign_line_h | 840 | 1.0 | 1.0 | 1 |
| Dotted_line_h | 31,896 | 1.0 | 0.9647 | 8 |
| Dotted_line_v | 38,916 | 1.0 | 1.0 | 1 |
| Double_slash_sign_line_h | 684 | 1.0 | 1.0 | 1 |
| Double_slash_sign_line_v | 1722 | 1.0 | 0.8572 | 9 |
| Arrow_e | 2268 | 1.0 | 1.0 | 1 |
| Arrow_w | 2148 | 1.0 | 1.0 | 1 |
| Arrow_s | 4914 | 1.0 | 0.9666 | 7 |
| Arrow_n | 3414 | 1.0 | 1.0 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moon, Y.; Lee, J.; Mun, D.; Lim, S. Deep Learning-Based Method to Recognize Line Objects and Flow Arrows from Image-Format Piping and Instrumentation Diagrams for Digitization. Appl. Sci. 2021, 11, 10054. https://doi.org/10.3390/app112110054
Moon Y, Lee J, Mun D, Lim S. Deep Learning-Based Method to Recognize Line Objects and Flow Arrows from Image-Format Piping and Instrumentation Diagrams for Digitization. Applied Sciences. 2021; 11(21):10054. https://doi.org/10.3390/app112110054
Chicago/Turabian StyleMoon, Yoochan, Jinwon Lee, Duhwan Mun, and Seungeun Lim. 2021. "Deep Learning-Based Method to Recognize Line Objects and Flow Arrows from Image-Format Piping and Instrumentation Diagrams for Digitization" Applied Sciences 11, no. 21: 10054. https://doi.org/10.3390/app112110054