Video Forensics: Identifying Colorized Images Using Deep Learning


Abstract
:Featured Application
Abstract
1. Introduction
- Copy/move: consisting of copying a part of the image and pasting it over the same image. In this way, a specific area of the image can be hidden (for example, a weapon).
- Cut/paste and splicing: consisting of cutting an object from one image and copying it to another image or creating an image with the contents obtained from two different images, respectively. It has the same effect of hiding a specific area of the image as copy/move or even creating a new scene.
- Retouching: this method alters certain characteristics of the image, through techniques such as blurring. An object may appear blurry in the edited image, making it difficult to identify.
- Colorization: unlike the previous types of manipulation, the original objects in the image are not hidden, blurred or new, but their color intensities are modified. The impact on the forensic video field is that the version of a witness may differ from the tampered evidence, for example, in clothing colors, skin color or vehicle color, among others.
- A custom architecture and a transfer-learning-based model for the classification of colorized images are proposed.
- The impact of the training dataset is evaluated. Three options are used, one with a single and small public dataset and the other mixing two public datasets but varying the number of images.
- Detailed results related to classifier performance for different image sizes, optimizers, and dropout values are provided.
- In addition, the results of the custom model are compared with a VGG-16-based model (transfer learning) in terms of evaluation metrics as well as training, and inference times.
2. Proposed Models
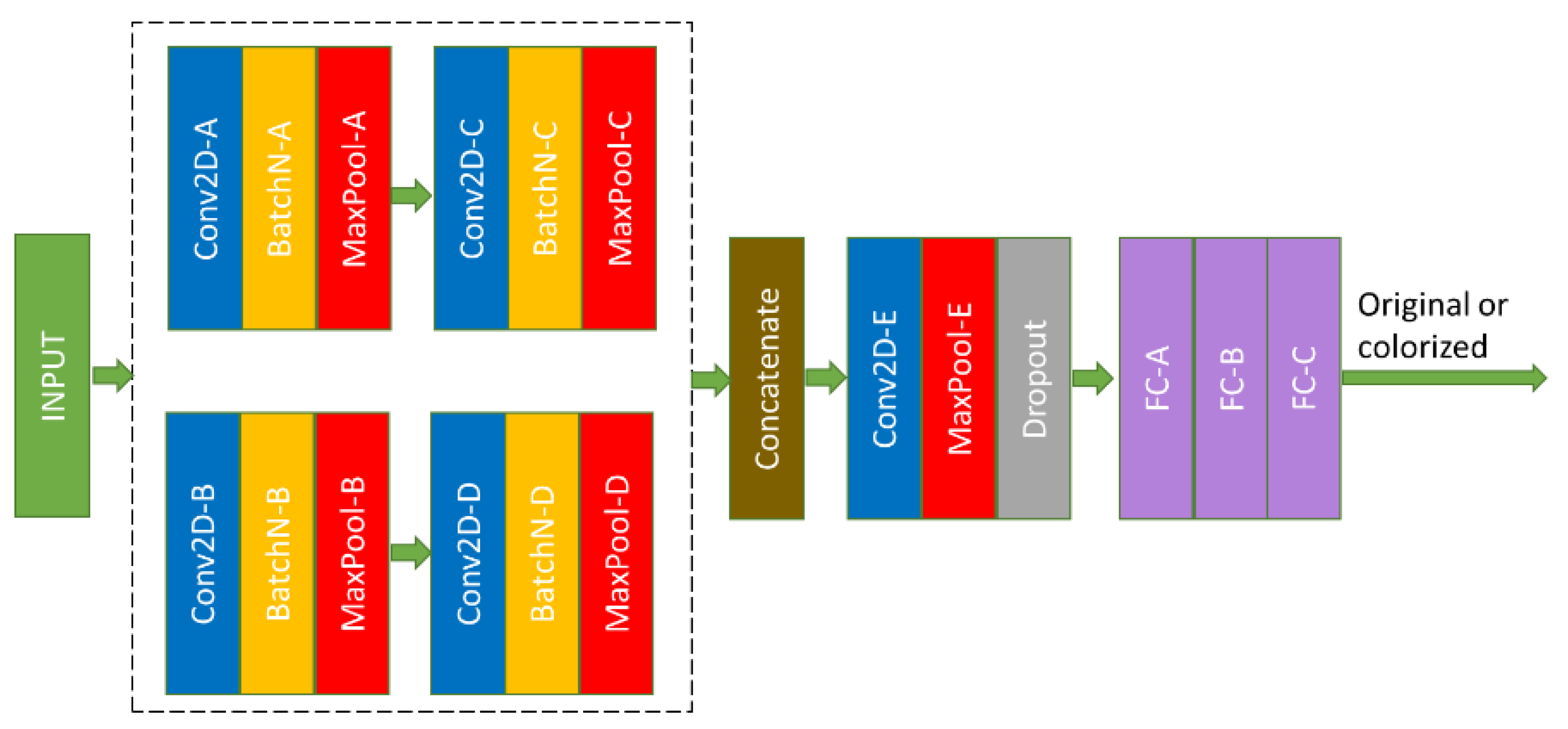
2.1. The Proposed Custom Model
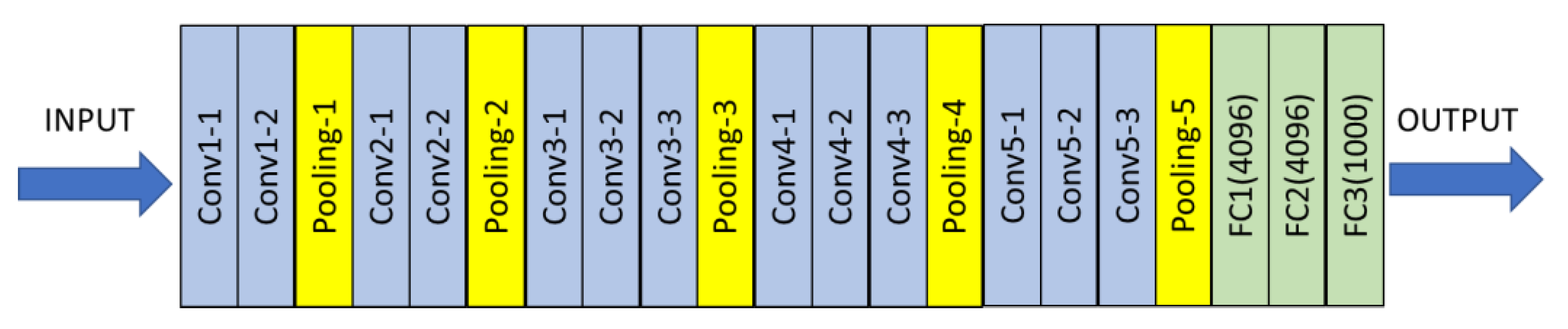
2.2. The Proposed Transfer-Learning-Based Model
3. Experiments
- Train and validate the custom architecture and the transfer-learning-based model with three different data sets.
- Measure the impact of some hyperparameters (image size, optimizer and dropout) on the performance of the custom model.
- Transfer learning from a VGG-16 pre-trained model with new fixed FC layers but varying the optimizer.
- Calculate the training and inference times of the custom model as well as the transfer-learning-based model.
3.1. Datasets
3.2. Evaluation Metrics
3.3. Experimental Hyperparameters of the Custom Model and the VGG-16-Based Model
- SGD (i.e., stochastic gradient descent) is one of the most widely used optimizers in machine learning algorithms. However, it has difficulties in terms of time requirements for large datasets.
- RMSProp is part of the optimization algorithms with an adaptive learning rate (α), which divides it by an exponentially decaying average of squared gradients.
- Adam is one of the most widely used algorithms in deep learning-based applications. It calculates individual α for different parameters. Unlike SGD, it is computationally efficient [24].
4. Dataset and Hyperparameter Selection
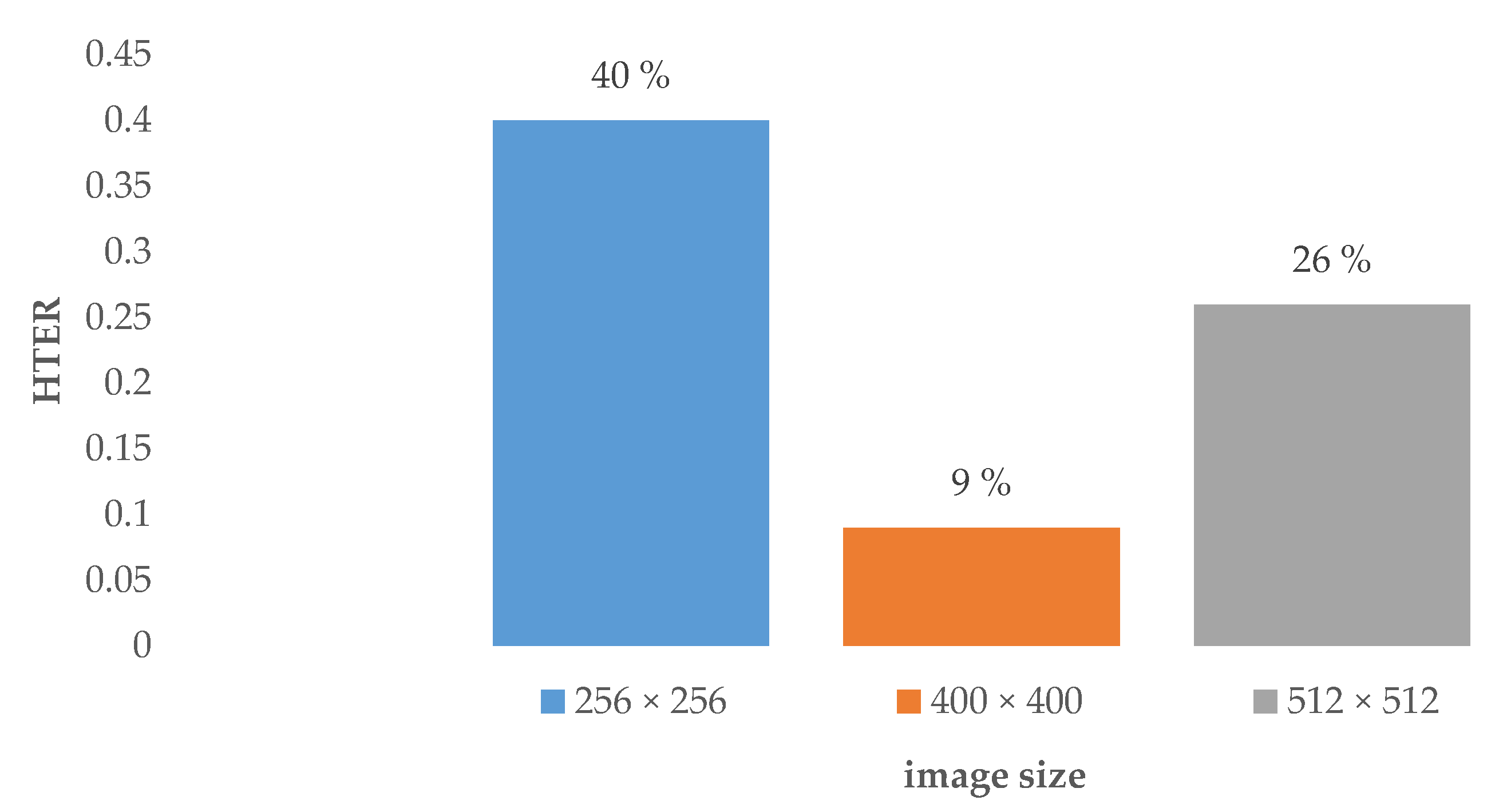
4.1. Impact of the Dataset
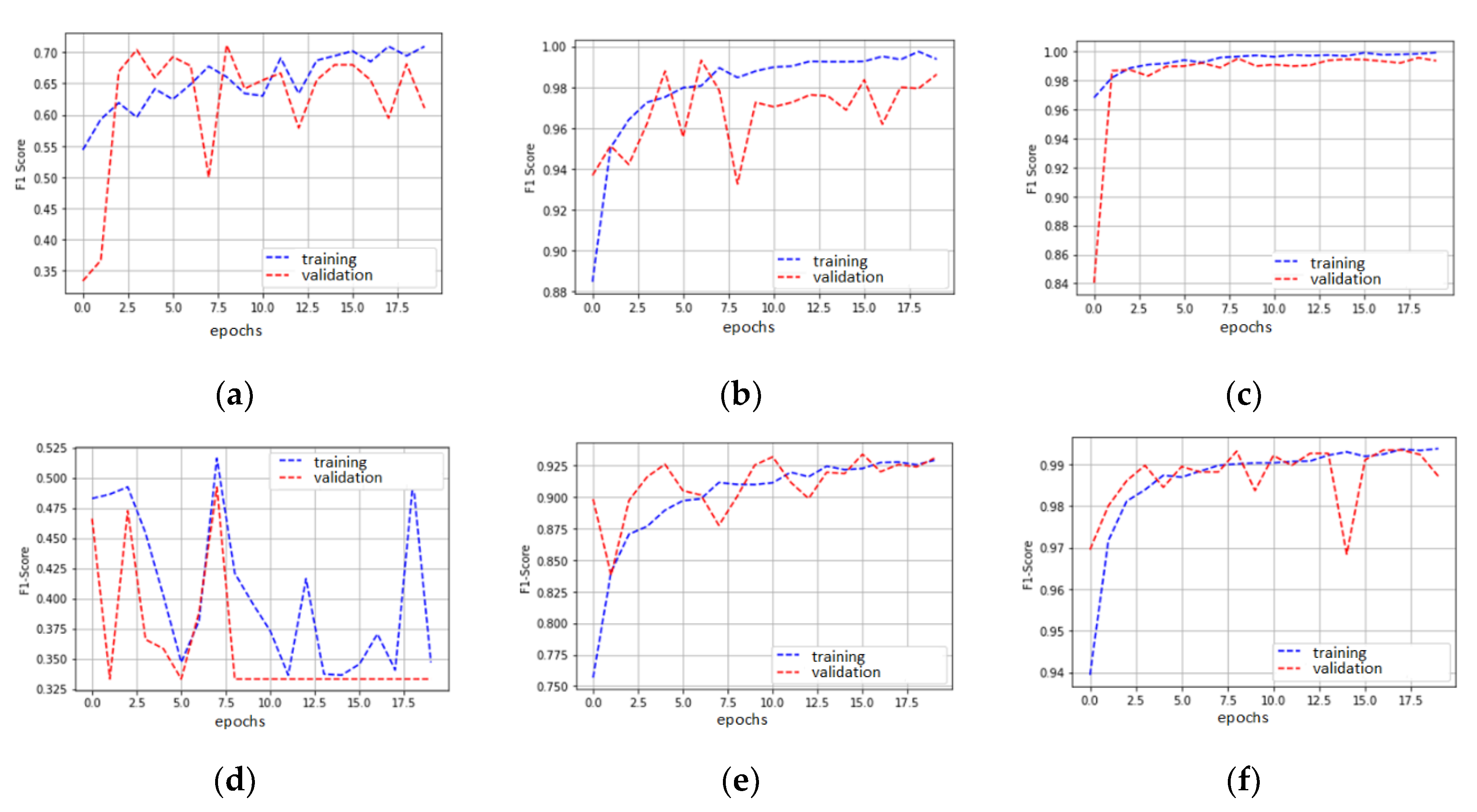
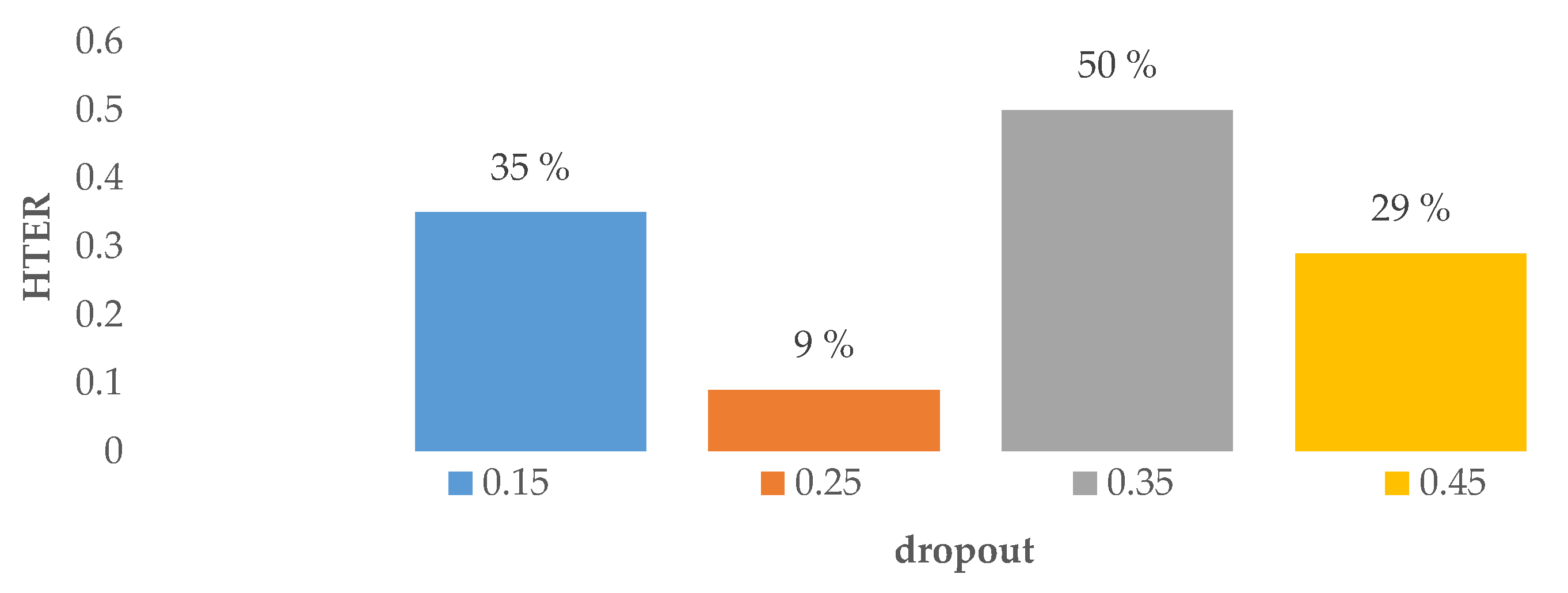
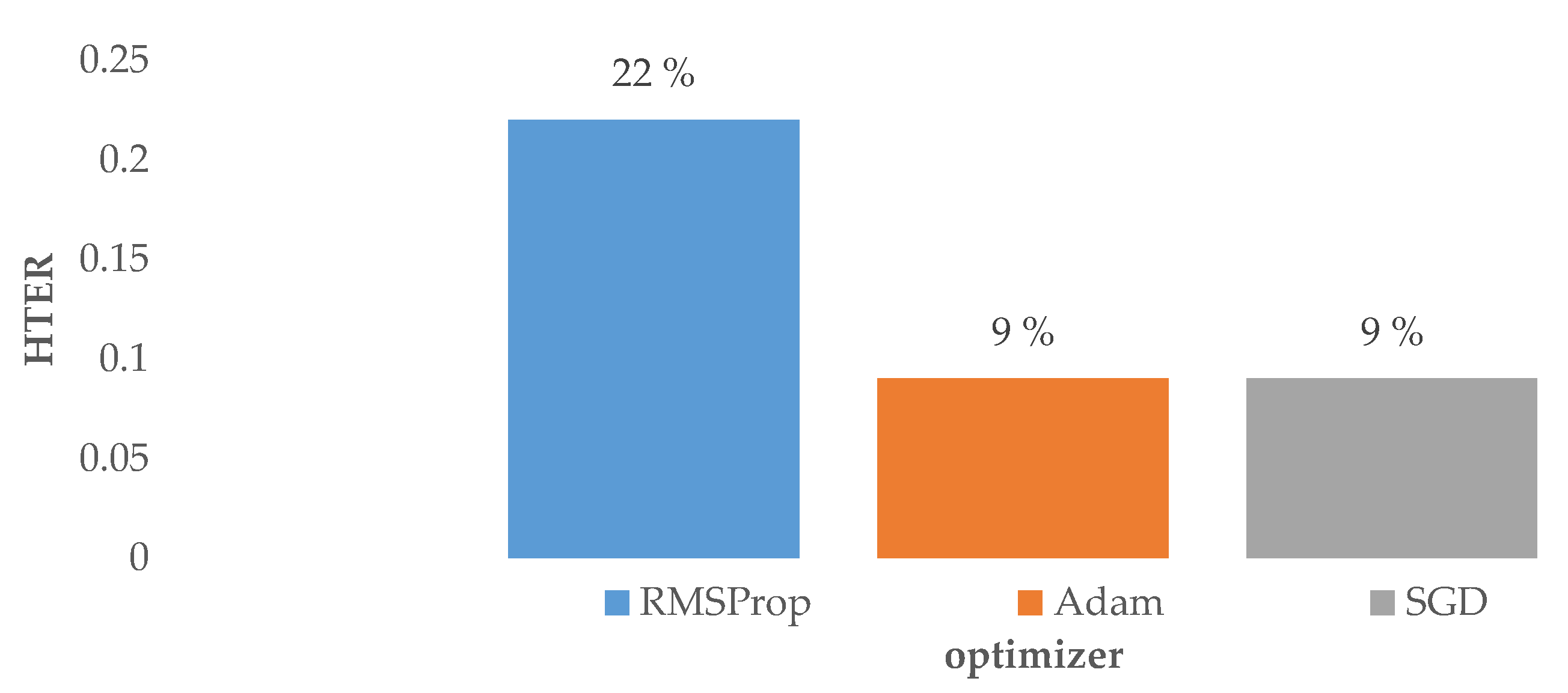
4.2. Impact of Hyperparameters in the Custom Model
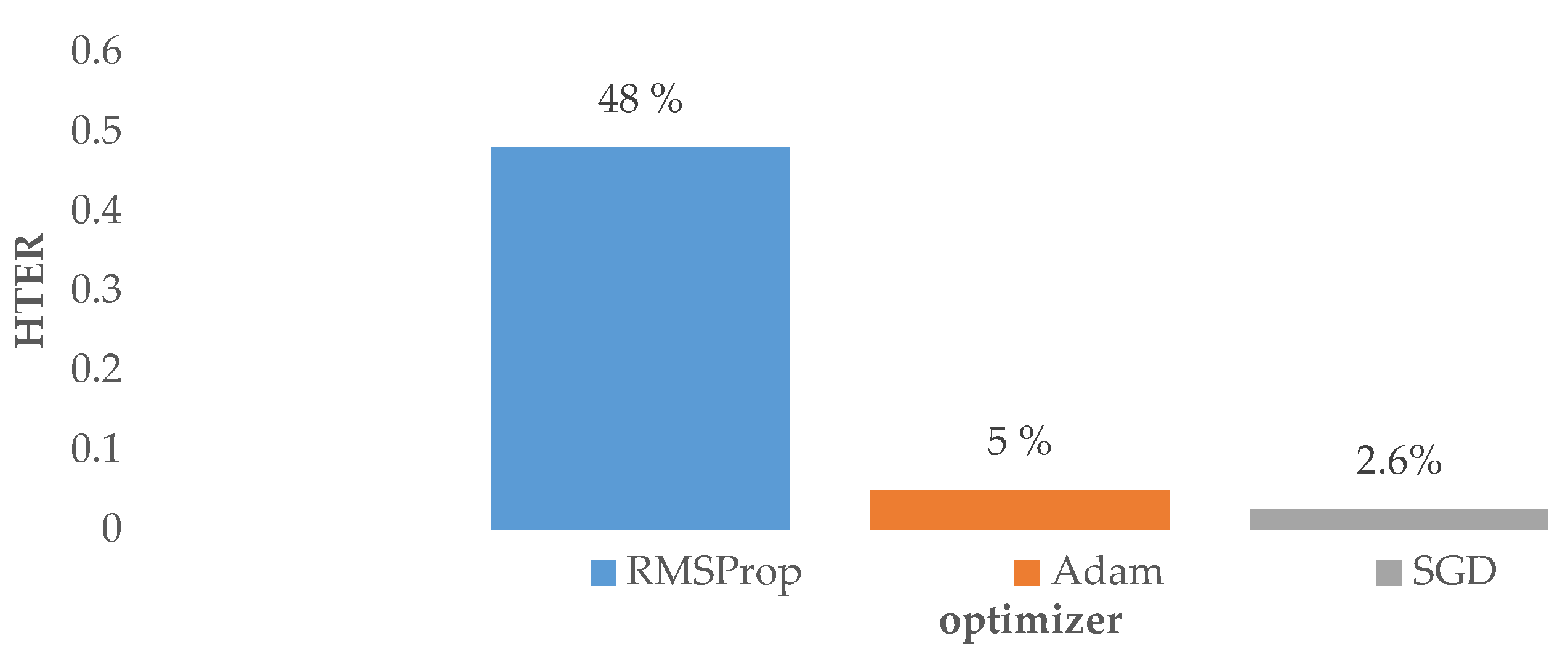
4.3. Impact of the Optimizer in the VGG-16-Based Model
5. Results and Comparison with Other Models
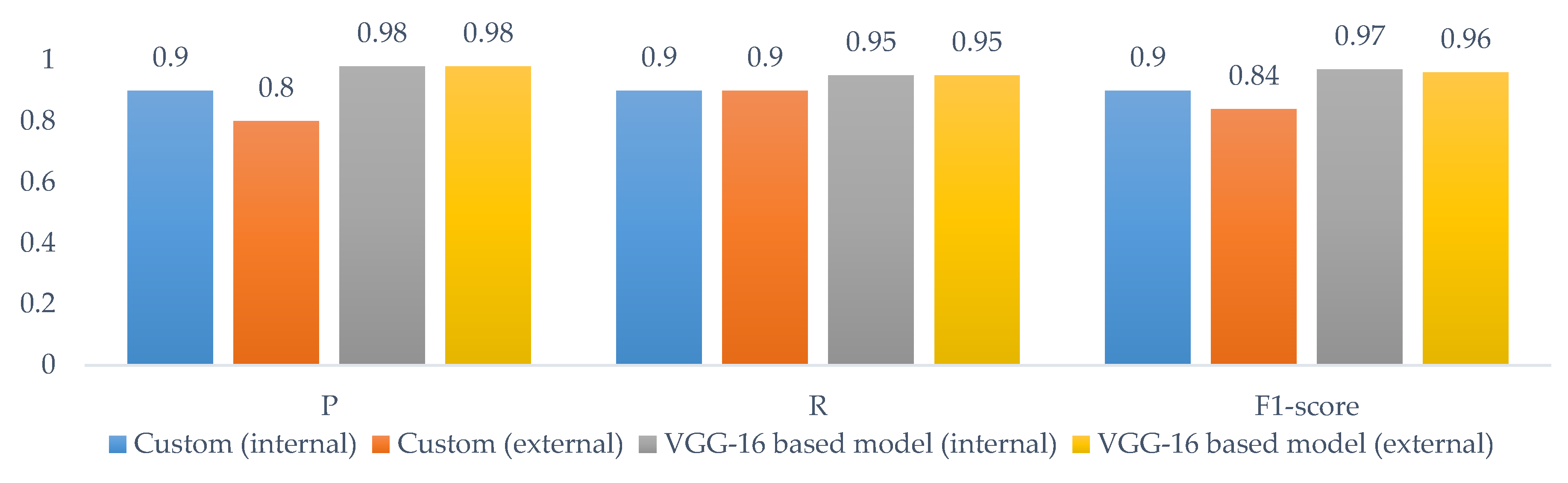
5.1. Performance of the Custom Model vs. the VGG-16-Based Model
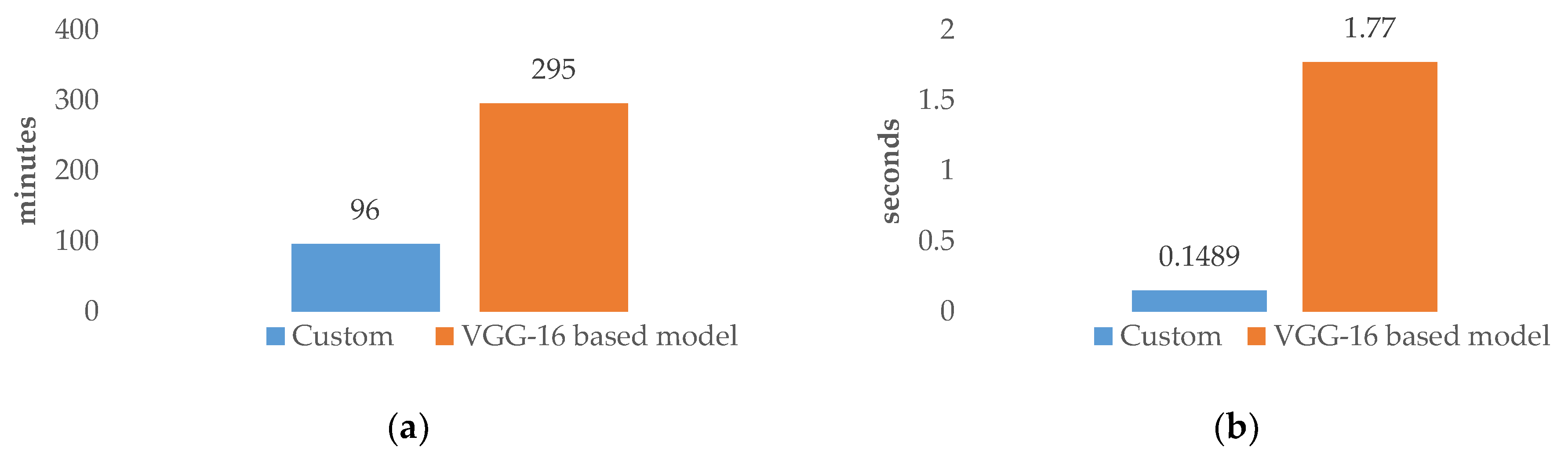
5.2. Inference Time of the Custom Model vs. the VGG-16-Based Model
5.3. Comparison with State-of-the-Art Works
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- How Many Photos Will Be Taken in 2020? Available online: https://focus.mylio.com/tech-today/how-many-photos-will-be-taken-in-2020 (accessed on 17 December 2020).
- An, J.; Kpeyiton, K.G.; Shi, Q. Grayscale images colorization with convolutional neural networks. Soft Comput. 2020, 24, 4751–4758. [Google Scholar] [CrossRef]
- Cheng, Z.; Meng, F.; Mao, J. Semi-Auto Sketch Colorization Based on Conditional Generative Adversarial Networks. In Proceedings of the 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019. [Google Scholar] [CrossRef]
- Thakur, R.; Rohilla, R. Recent advances in digital image manipulation detection techniques: A brief review. Forensic Sci. Int. 2020, 312, 110311. [Google Scholar] [CrossRef] [PubMed]
- Castro, M.; Ballesteros, D.M.; Renza, D. A dataset of 1050-tampered color and grayscale images (CG-1050). Data Brief 2020, 28, 104864. [Google Scholar] [CrossRef] [PubMed]
- Castro, M.; Ballesteros, D.M.; Renza, D. CG-1050: Original and tampered images (Color and grayscale). Mendeley Data 2019. [Google Scholar] [CrossRef]
- Johari, M.M.; Behroozi, H. Context-Aware Colorization of Gray-Scale Images Utilizing a Cycle-Consistent Generative Adversarial Network Architecture. Neurocomputing 2020, 407, 94–104. [Google Scholar] [CrossRef]
- Fatima, A.; Hussain, W.; Rasool, S. Grey is the new RGB: How good is GAN-based image colorization for image compression? Multimed. Tools Appl. 2020. [Google Scholar] [CrossRef]
- Zhao, Y.; Po, L.M.; Cheung, K.W.; Yu, W.Y.; Rehman, Y.A.U. SCGAN: Saliency Map-guided Colorization with Generative Adversarial Network. IEEE Trans. Inf. Forensics Secur. 2020. [Google Scholar] [CrossRef]
- Ortiz, H.D.; Renza, D.; Ballesteros, D.M. Tampering detection on digital evidence for forensics purposes. Ing. Cienc. 2018, 14, 53–74. [Google Scholar] [CrossRef]
- Prasad, S.; Pal, A.K. A tamper detection suitable fragile watermarking scheme based on novel payload embedding strategy. Multimed. Tools Appl. 2020, 79, 1673–1705. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 20–22 June 2016; pp. 5–10. [Google Scholar]
- Bayar, B.; Stamm, M.C. Constrained convolutional neural networks: A new approach towards general purpose image manipulation detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Zhuo, L.; Tan, S.; Zeng, J.; Lit, B. Fake colorized image detection with channel-wise convolution based deep-learning framework. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 733–736. [Google Scholar] [CrossRef]
- Quan, W.; Wang, K.; Yan, D.M.; Pellerin, D.; Zhang, X. Impact of data preparation and CNN’s first layer on performance of image forensics: A case study of detecting colorized images. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence-Companion Volume, Thessaloniki, Greece, 14–17 October 2019; pp. 127–131. [Google Scholar] [CrossRef]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 8th IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, UAE, 4–7 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Zhang, W.; Wang, R. Fake colorized image detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1932–1944. [Google Scholar] [CrossRef] [Green Version]
- Oostwal, E.; Straat, M.; Biehl, M. Hidden unit specialization in layered neural networks: ReLU vs. Sigmoidal activation. Physica A 2020, 564, 125517. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Results of ILSVRC. 2014. Available online: http://www.image-net.org/challenges/LSVRC/2014/results (accessed on 11 December 2020).
- Rangasamy, K.; As’ari, M.A.; Rahmad, N.A.; Ghazali, N.F. Hockey activity recognition using pre-trained deep learning model. ICT Express 2020, 6, 170–174. [Google Scholar] [CrossRef]
- Gupta, S.; Ullah, S.; Ahuja, K.; Tiwari, A.; Kumar, A. ALigN: A Highly Accurate Adaptive Layerwise Log_2_Lead Quantization of Pre-Trained Neural Networks. IEEE Access 2020, 8, 118899–118911. [Google Scholar] [CrossRef]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Learning Representations for Automatic Colorization. In Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9908. [Google Scholar] [CrossRef] [Green Version]
- Soydaner, D. A Comparison of Optimization Algorithms for Deep Learning. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2052013. [Google Scholar] [CrossRef]
- Yan, Y.; Ren, W.; Cao, X. Recolored Image Detection via a Deep Discriminative Model. IEEE Trans. Inf. Forensics Secur. 2019, 14, 5–17. [Google Scholar] [CrossRef]
- Quan, W.; Wang, K.; Yan, D.M.; Pellerin, D.; Zhang, X. Improving the Generalization of Colorized Image Detection with Enhanced Training of CNN. In Proceedings of the 11th International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 23–25 September 2019; pp. 246–252. [Google Scholar] [CrossRef]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Let there be color! Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. ACM Trans. Graph. 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Lect. Notes Comput. Sci.; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9907. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
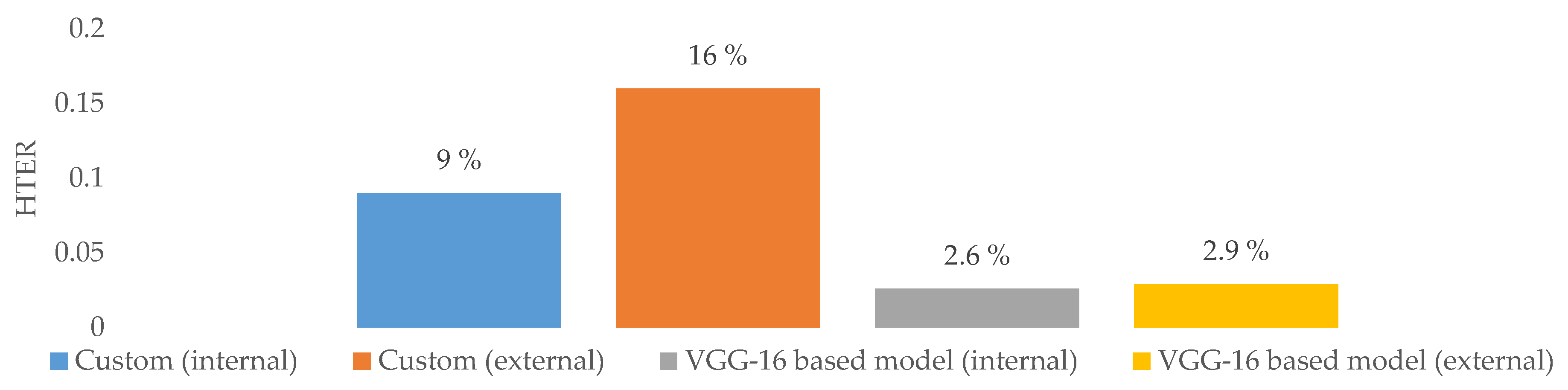{kind=link}
{kind=link}
| Layer | No. of Filters | Kernel Size | Stride |
|---|---|---|---|
| Conv2D-A | 64 | (1,1) | 1 |
| BatchN-A | --------- | --------- | --------- |
| MaxPool-A | --------- | (3,3) | 2 |
| Conv2D-B | 32 | (3,3) | 1 |
| BatchN-B | --------- | --------- | --------- |
| MaxPool-B | --------- | (3,3) | 2 |
| Conv2D-C | 64 | (1,1) | 1 |
| BatchN-C | --------- | --------- | --------- |
| MaxPool-C | --------- | (3,3) | 2 |
| Conv2D-D | 32 | (3,3) | 1 |
| BatchN-D | --------- | --------- | --------- |
| MaxPool-D | --------- | (3,3) | 2 |
| Conv2D-E | 64 | (5,5) | 2 |
| MaxPool-E | --------- | (5,5) | 2 |
| FC-A | 400 | --------- | --------- |
| FC-B | 200 | --------- | --------- |
| FC-C | 2 | --------- | --------- |
| Dataset | Colorization Type | Number of Images (Original vs. Colorized) |
|---|---|---|
| DA | manual | 331 vs. 331 |
| DB | manual and automatic | 4719 vs. 4719 |
| DC | manual and automatic | 9506 vs. 9506 |
| Hyperparameter | Options |
|---|---|
| Image size | 256 × 256, 400 × 400, 512 × 512 |
| Dropout | 0.15, 0.25, 0.35, 0.45 |
| Optimizer | RMSProp, SGD, Adam |
| Method | Dataset | HTER (Internal Validation) | HTER (External Validation) | HTER’s Difference |
|---|---|---|---|---|
| RecDeNet [25] | PASCAL 2012 | 12.6 | 22.3 | +9.7 |
| WISERNet I [14] | [23] + [27] + [28] | 0.95 | 22.5 | +21.55 |
| WISERNet II [15] | [23] + [27] + [28] | 0.89 | 31.7 | +30.81 |
| WISERNet III [26] | [23] + [27] + [28] | 0.89 | 4.7 | +3.81 |
| Custom model | [5] + [23] | 9.00 | 16.0 | +7 |
| VGG-16-based model | [5] + [23] | 2.60 | 2.9 | +0.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ulloa, C.; Ballesteros, D.M.; Renza, D. Video Forensics: Identifying Colorized Images Using Deep Learning. Appl. Sci. 2021, 11, 476. https://doi.org/10.3390/app11020476
Ulloa C, Ballesteros DM, Renza D. Video Forensics: Identifying Colorized Images Using Deep Learning. Applied Sciences. 2021; 11(2):476. https://doi.org/10.3390/app11020476
Chicago/Turabian StyleUlloa, Carlos, Dora M. Ballesteros, and Diego Renza. 2021. "Video Forensics: Identifying Colorized Images Using Deep Learning" Applied Sciences 11, no. 2: 476. https://doi.org/10.3390/app11020476