
AUDD: Audio Urdu Digits Dataset for Automatic Audio Urdu Digit Recognition



Abstract
:1. Introduction
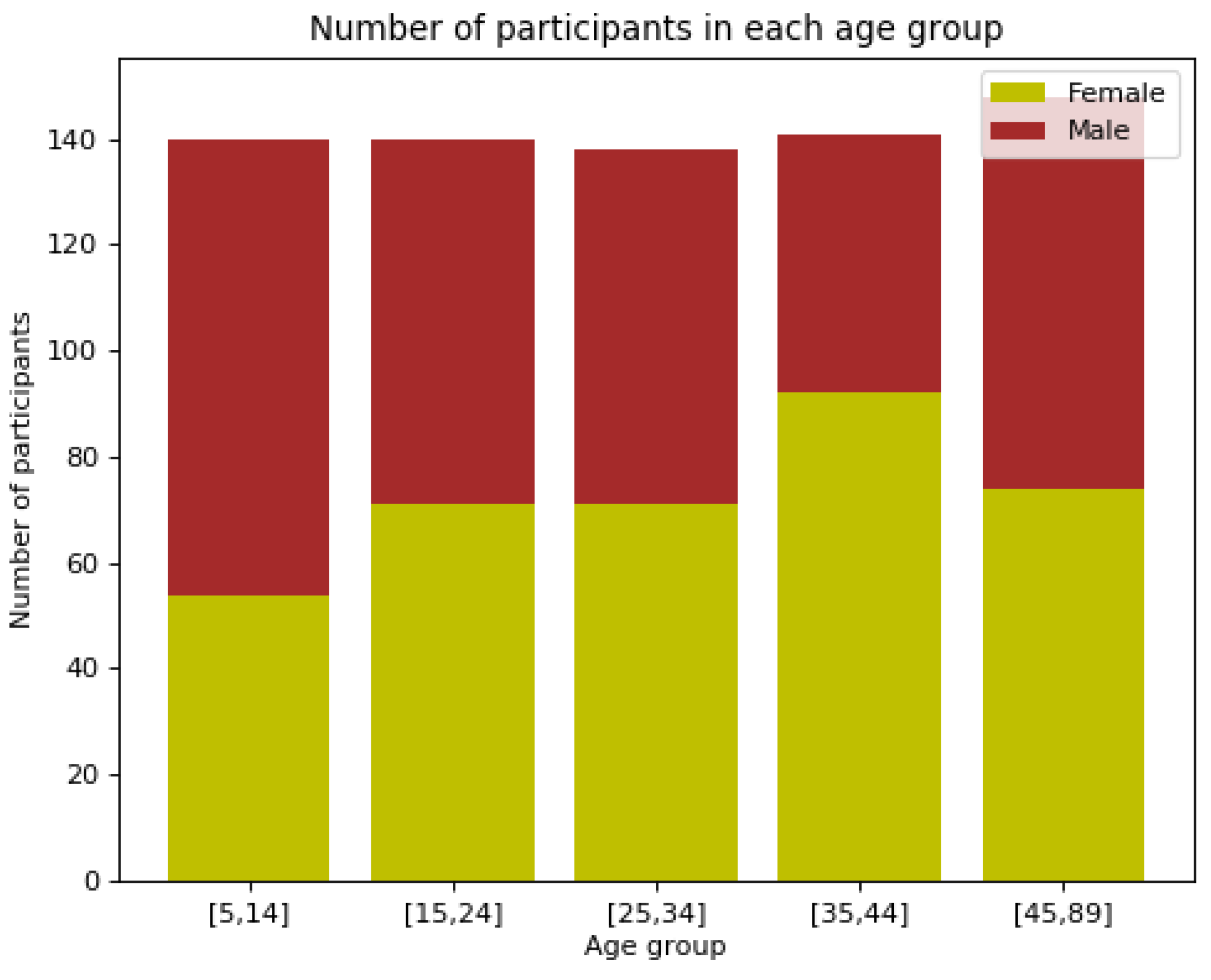
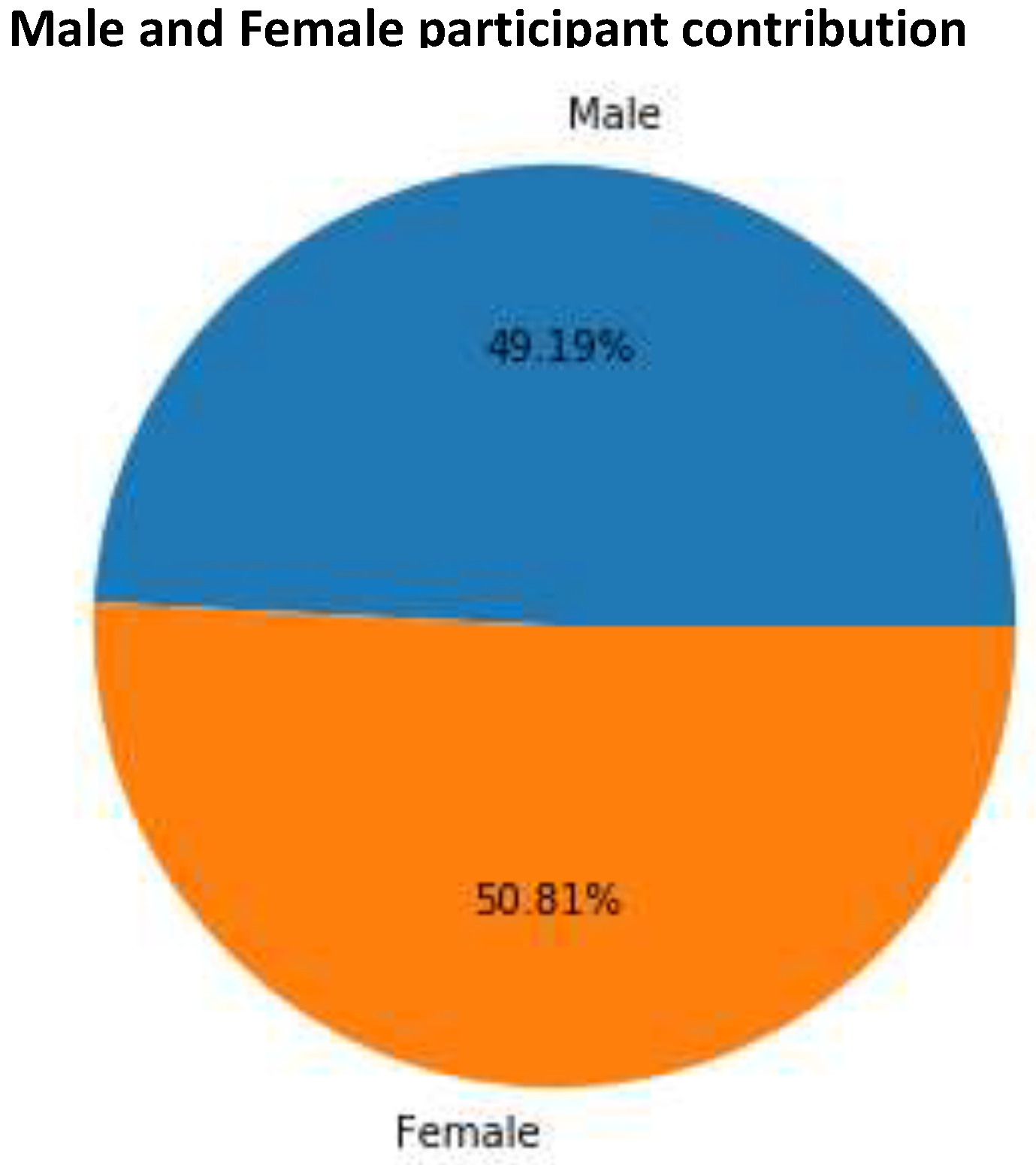
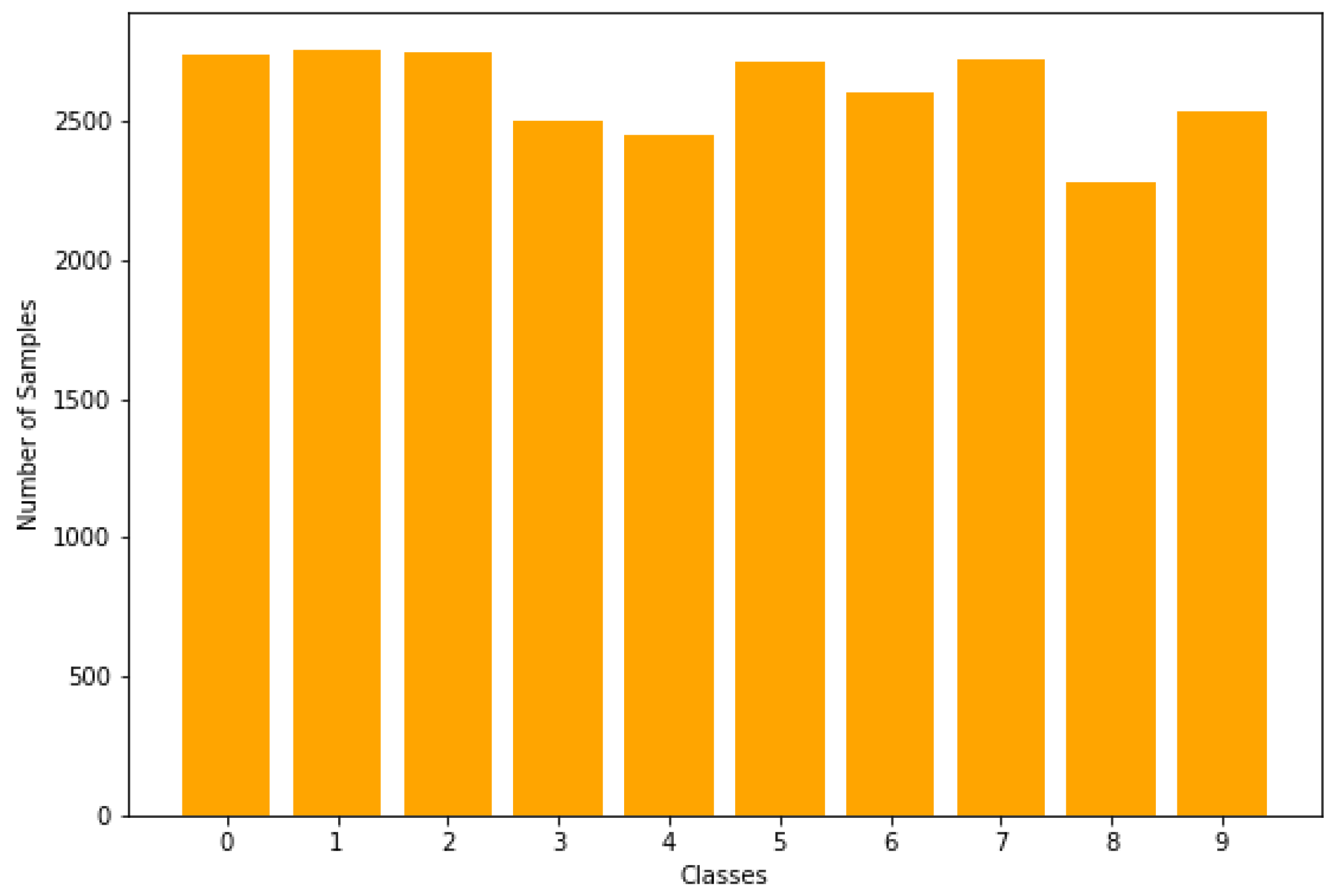
- We present an AUDD for Urdu digits that comprises 0–9. We have collected these voice samples from 740 people. These people were of different age groups ranging from 5 to 89 years.
- We perform extensive experiments for different networks to provide classification accuracy that will serve as baseline accuracy.
- We propose a convolutional neural network (CNN) for classification that shows impressive performance being a simple CNN compared to complex flavors of efficientNet.
2. Related Work
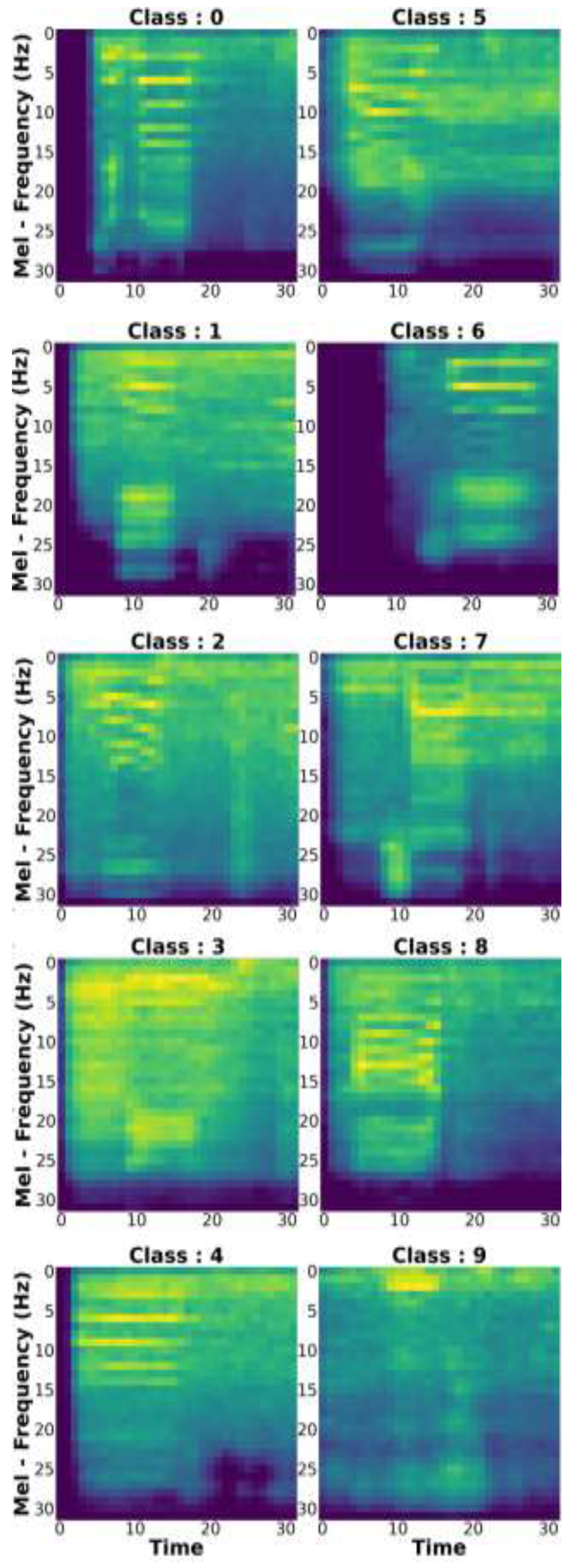
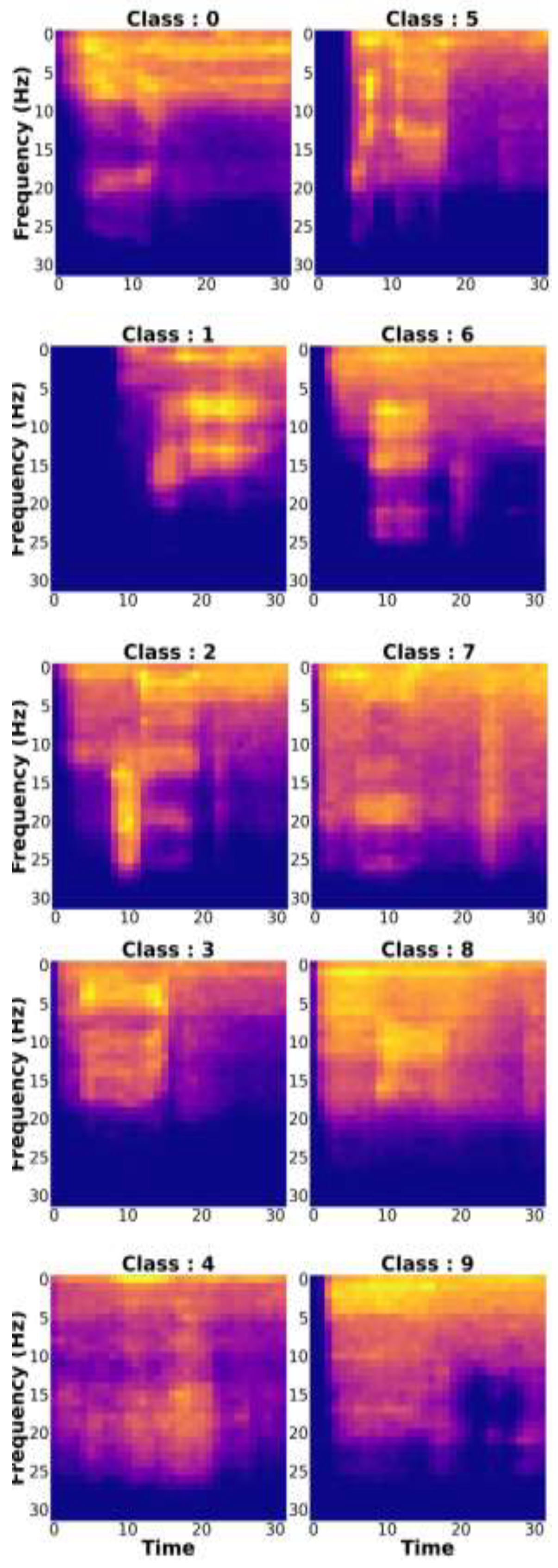
3. Data Collection
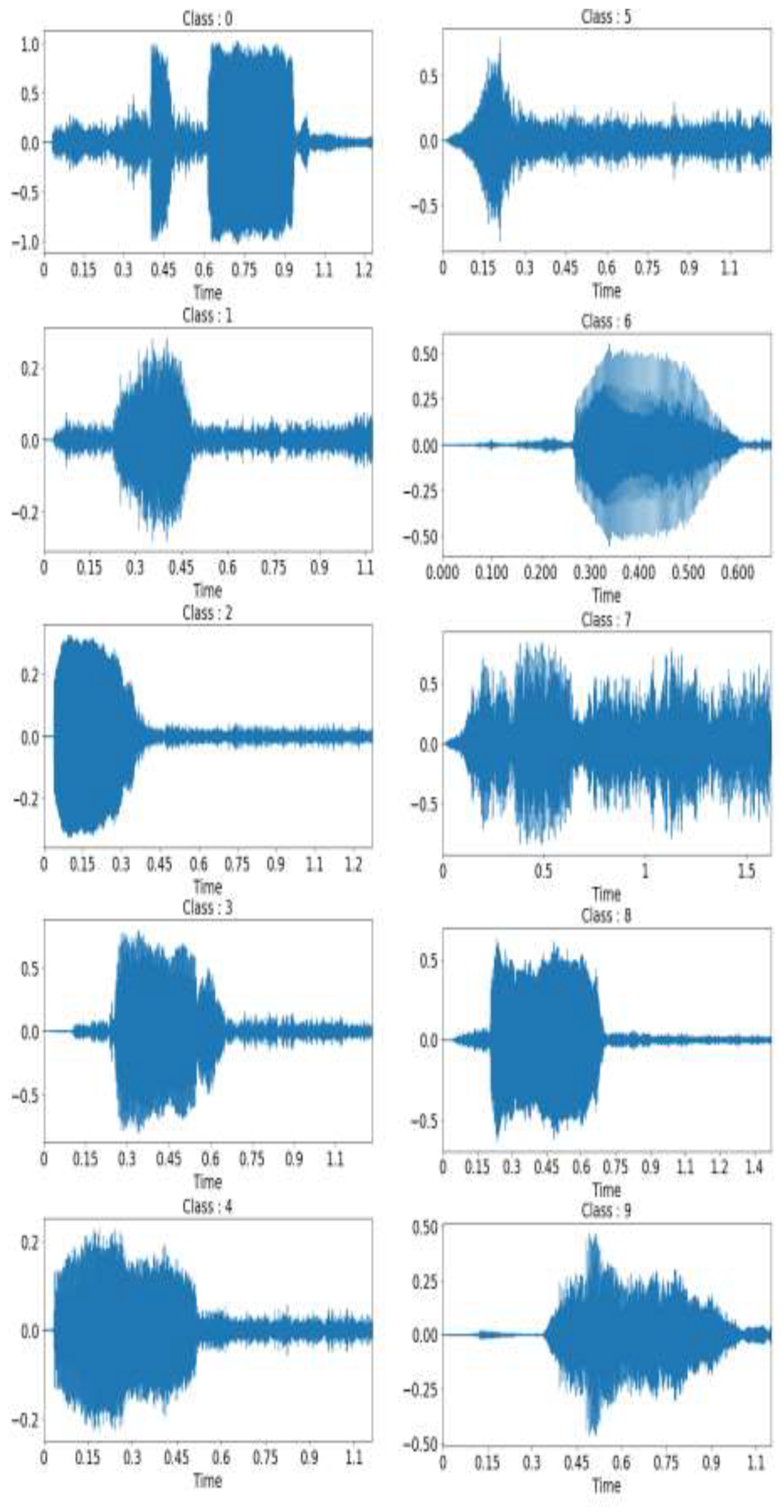
Visualization
4. Models
4.1. Support Vector Machine
4.2. Multilayer Perceptron
4.3. EfficientNet
5. Experiments
5.1. Preprocessing
5.2. Training Setup
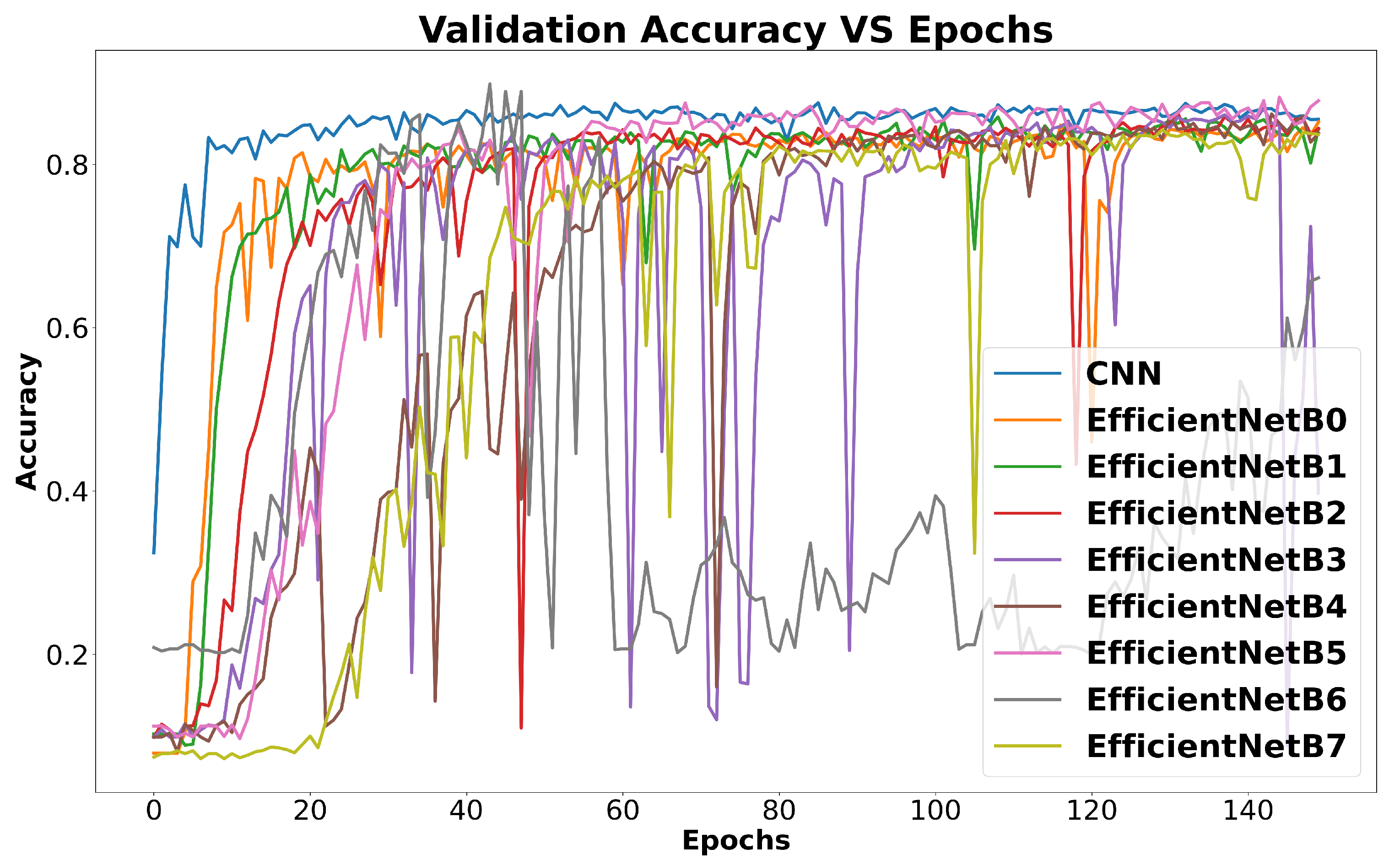
5.3. Classification Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Khan, L.; Saad, W.; Han, Z.; Hong, C. Dispersed federated learning: Vision, taxonomy, and future directions. arXiv 2020, arXiv:2008.05189. [Google Scholar]
- Khan, L.; Saad, W.; Han, Z.; Hossain, E.; Hong, C. Federated learning for internet of things: Recent advances, taxonomy, and open challenges. IEEE Commun. Surv. Tutor. 2021, 23, 1759–1799. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Jindal, R.; Malhotra, R.; Jain, A. Techniques for text classification: Literature review and current trends. Webology 2015, 12, 2. [Google Scholar]
- Piczak, K. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Diez Gaspon, I.; Saratxaga, I.; Ipiña, K. Deep Learning For Natural Sound Classification. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference Proceedings, Madrid, Spain, 16–19 June 2019; Volume 259, pp. 5683–5692. [Google Scholar]
- Lu, H.; Zhang, H.; Nayak, A. A deep neural network for audio classification with a classifier attention mechanism. arXiv 2020, arXiv:2006.09815. [Google Scholar]
- Heaton, J. Applications of deep neural networks. arXiv 2020, arXiv:2009.05673. [Google Scholar]
- Meng, J.; Zhang, J.; Zhao, H. Overview of the speech recognition technology. In Proceedings of the 2012 Fourth International Conference on Computational And Information Sciences, Chongqing, China, 17–19 August 2020; pp. 199–202. [Google Scholar]
- Ali, H.; Ahmad, N.; Hafeez, A. Urdu speech corpus and preliminary results on speech recognition. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016; pp. 317–325. [Google Scholar]
- Ashraf, J.; Iqbal, N.; Khattak, N.; Zaidi, A. Speaker independent Urdu speech recognition using HMM. In Proceedings of the 2010 the 7th International Conference on Informatics And Systems (INFOS), Cairo, Egypt, 28–30 March 2010; pp. 1–5. [Google Scholar]
- Ahad, A.; Fayyaz, A.; Mehmood, T. Speech recognition using multilayer perceptron. In Proceedings of the IEEE Students Conference (ISCON’02 Proceedings), Lahore, Pakistan, 16–17 August 2002; Volume 1, pp. 103–109. [Google Scholar]
- Sarfraz, H.; Hussain, S.; Bokhari, R.; Raza, A.; Ullah, I.; Sarfraz, Z.; Pervez, S.; Mustafa, A.; Javed, I.; Parveen, R. Speech corpus development for a speaker independent spontaneous Urdu speech recognition system. In Proceedings of the O-COCOSDA, Kathmandu, Nepal, 24 November 2010. [Google Scholar]
- Raza, A.; Hussain, S.; Sarfraz, H.; Ullah, I.; Sarfraz, Z. Design and development of phonetically rich Urdu speech corpus. In Proceedings of the 2009 Oriental COCOSDA International Conference on Speech Database and Assessments, Urumqi, China, 10–12 August 2009; pp. 38–43. [Google Scholar]
- Akram, M.; Arif, M. Design of an Urdu Speech Recognizer based upon acoustic phonetic modeling approach. In Proceedings of the 8th International Multitopic Conference, (Proceedings of INMIC 2004), Lahore, Pakistan, 24–26 December 2004; pp. 91–96. [Google Scholar]
- Hasnain, S.; Awan, M. Recognizing spoken Urdu numbers using fourier descriptor and neural networks with Matlab. In Proceedings of the 2008 Second International Conference on Electrical Engineering, Lahore, Pakistan, 25–26 March 2008; pp. 1–6. [Google Scholar]
- Ittoo, A.; Bouma, G.; Maruster, L.; Wortmann, H. Extracting meronymy relationships from domain-specific, textual corporate databases. In Proceedings of the International Conference on Application of Natural Language to Information Systems, Cardiff, UK, 23–25 June 2010; pp. 48–59. [Google Scholar]
- Ali, H.; Ahmad, N.; Zhou, X.; Iqbal, K.; Ali, S. DWT features performance analysis for automatic speech recognition of Urdu. SpringerPlus 2014, 3, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Faisal, M.; Manzoor, S. Deep learning for lip reading using audio-visual information for urdu language. arXiv 2018, arXiv:1802.05521. [Google Scholar]
- Ali, H.; Jianwei, A.; Iqbal, K. Automatic speech recognition of Urdu digits with optimal classification approach. Int. J. Comput. Appl. 2015, 118, 1–5. [Google Scholar] [CrossRef]
- Azam, S.; Mansoor, Z.; Mughal, M.; Mohsin, S. Urdu spoken digits recognition using classified MFCC and backpropgation neural network. In Proceedings of the Computer Graphics, Imaging and Visualisation (CGIV 2007), Bangkok, Thailand, 14–17 August 2007; pp. 414–418. [Google Scholar]
- Zia, T.; Zahid, U. Long short-term memory recurrent neural network architectures for Urdu acoustic modeling. Int. J. Speech Technol. 2019, 22, 21–30. [Google Scholar] [CrossRef]
- Messer, K.; Matas, J.; Kittler, J.; Jonsson, K.; Luettin, J.; Maître, G. XM2VTSDB: The extended M2VTS database. In Proceedings of the Second International Conference on Audio and Video-Based Biometric Person Authentication, Washington, DC, USA, 22–23 March 1999; pp. 965–966. [Google Scholar]
- Bailly-Bailliére, E.; Bengio, S.; Bimbot, F.; Hamouz, M.; Kittler, J.; Mariéthoz, J.; Matas, J.; Messer, K.; Popovici, V.; Porée, F.; et al. The BANCA database and evaluation protocol. In Proceedings of the International Conference on Audio-and Video-Based Biometric Person Authentication, Guildford, UK, 9–11 June 2003; pp. 625–638. [Google Scholar]
- Abhilash, J.; Rathna, G.N. Visual speech recognition for isolated digits using discrete cosine transform and local binary pattern features. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2019; pp. 368–372. [Google Scholar]
- Brahme, A.; Bhadade, U. Marathi digit recognition using lip geometric shape features and dynamic time warping. In Proceedings of the TENCON 2017—2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 974–979. [Google Scholar]
- Wazir, A.S.M.B.A.; Chuah, H.J. Spoken arabic digits recognition using deep learning. In Proceedings of the 2019 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Selangor, Malaysia, 29 June 2019; pp. 339–344. [Google Scholar]
- Dalsaniya, N.; Mankad, S.H.; Garg, S.; Shrivastava, D. Development of a novel database in Gujarati language for spoken digits classification. In Proceedings of the International Symposium on Signal Processing and Intelligent Recognition Systems, Trivandrum, India, 18–21 December 2019; pp. 208–219. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Mathur, A.; Foody, G. Multiclass and binary SVM classification: Implications for training and classification users. IEEE Geosci. Remote Sens. Lett. 2008, 5, 241–245. [Google Scholar] [CrossRef]
- Zhai, X.; Ali, A.; Amira, A.; Bensaali, F. MLP neural network based gas classification system on Zynq SoC. IEEE Access 2016, 4, 8138–8146. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach Convention & Entertainment Center, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Oo, M.; Oo, L. Fusion of Log-Mel Spectrogram and GLCM feature in acoustic scene classification. In Proceedings of the International Conference on Software Engineering Research, Management and Applications, Honolulu, HI, USA, 29–31 May 2019; pp. 175–187. [Google Scholar]
- Majeed, S.; Husain, H.; Samad, S.; Idbeaa, T. Mel frequency cepstral coefficients (MFCC) feature extraction enhancement in the application of speech recognition: A comparison study. J. Theor. Appl. Inf. Technol. 2015, 79, 38. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobb’S J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. In Proceedings of the ECML PKDD Workshop: Languages for Data Mining and Machine Learning, Prague, Czech Republic, 23–27 September 2013; pp. 108–122. [Google Scholar]
- Chollet, F.; Rahman, F.; Zhu, Q.S.; Lee, T.; Marmiesse, G.D.; Zabluda, O.; Pumperla, M.; Santana, E.; McColgan, T.; Snelgrove, X.; et al. Available online: https://github.com/fchollet/keras (accessed on 20 July 2021).
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Nasr, S.; Quwaider, M.; Qureshi, R. Text-independent Speaker Recognition using Deep Neural Networks. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; pp. 517–521. [Google Scholar]
- Jackson, Z.; Souza, C.; Flaks, J.; Pan, Y.; Nicolas, H.; Thite, A. Jakobovski/Free-Spoken-Digit-Dataset: V1. 0.8. 2018. Available online: https://zenodo.org/record/1342401#.YUdDMLhKjIV (accessed on 3 September 2021).
- Oscar, CNNDigitReco-Speakerindependent 2020. Available online: https://www.kaggle.com/saztorralba/cnndigitreco-speakerindependent (accessed on 8 September 2021).
- Inam Ul Haq, Classification on FSDD Using Spectograms. 2021. Available online: https://www.kaggle.com/iinaam/classification-on-fsdd-using-spectograms Inam ur Rehman (accessed on 13 September 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Dimensions | Comments |
|---|---|---|
| input | input layer | |
| CNN | kernel stride 1; relu activation | |
| Max Pool | N.A | |
| BN | default value as given in Keras [39] | |
| CNN | kernel stride 1; relu activation | |
| Max Pool | N.A | |
| BN | default value as given in Keras [39] | |
| CNN | kernel stride 1; relu activation | |
| Max Pool | N.A | |
| BN | default value as given in Keras [39] | |
| Dropout | dropout rate = 0.1 | |
| Flatten | 256 | N.A |
| Fully connected | 512 | N.A |
| Dropout | 512 | dropout rate = 0.1 |
| Fully connected | 128 | N.A |
| Dropout | 512 | dropout rate = 0.1 |
| fully connected | 10 | softmax activation |
| Model Name | Accuracy |
|---|---|
| Support Vector Machine | 0.65 ± 0.0 |
| Multilayer Perceptron | 0.73 ± 0.02 |
| CNN | 0.86 ± 0.02 |
| EfficientNetB0 | 0.84 ± 0.05 |
| EfficientNetB1 | 0.82 ± 0.02 |
| EfficientNetB2 | 0.83 ± 0.04 |
| EfficientNetB3 | 0.84 ± 0.06 |
| EfficientNetB4 | 0.82 ± 0.03 |
| EfficientNetB5 | 0.84 ± 0.04 |
| EfficientNetB6 | 0.81 ± 0.06 |
| EfficientNetB7 | 0.56 ± 0.07 |
| Model Name | Accuracy |
|---|---|
| Gujarati Digits Model [29] | 0.75 |
| Our CNN | 0.97 |
| Model Name | Accuracy |
|---|---|
| CNNDigitReco-speakerindependent [43] | 0.78 |
| Support Vector Machines [44] | 0.90 |
| Random Forest [44] | 0.96 |
| English Digit Model [41] | 0.97 |
| Our CNN | 0.973 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chandio, A.; Shen, Y.; Bendechache, M.; Inayat, I.; Kumar, T. AUDD: Audio Urdu Digits Dataset for Automatic Audio Urdu Digit Recognition. Appl. Sci. 2021, 11, 8842. https://doi.org/10.3390/app11198842
Chandio A, Shen Y, Bendechache M, Inayat I, Kumar T. AUDD: Audio Urdu Digits Dataset for Automatic Audio Urdu Digit Recognition. Applied Sciences. 2021; 11(19):8842. https://doi.org/10.3390/app11198842
Chicago/Turabian StyleChandio, Aisha, Yao Shen, Malika Bendechache, Irum Inayat, and Teerath Kumar. 2021. "AUDD: Audio Urdu Digits Dataset for Automatic Audio Urdu Digit Recognition" Applied Sciences 11, no. 19: 8842. https://doi.org/10.3390/app11198842