
A Nested Chinese Restaurant Topic Model for Short Texts with Document Embeddings



Abstract
:1. Introduction
- Firstly, our model aggregates short texts into latent long documents according to document embeddings. Document embedding information provides similarities of short texts and can avoid incorporating non-semantic word co-occurrence information.
- Secondly, we change document embeddings into global and local semantic information to discard noisy information. Global information is the similarity probability distribution across all short texts and local information is the distances of similar short texts. Our model adopts the nested Chinese restaurant process to incorporate these two kinds of information in two steps.
- Thirdly, we compare our model to several state-of-the-art models. By generating topics on four real-world short texts corpus, the experimental results demonstrate that our model outperforms other methods in terms of topic coherence and classification accuracy.
2. Related Works
2.1. Models with Auxiliary Information
2.2. Models without Auxiliary Information
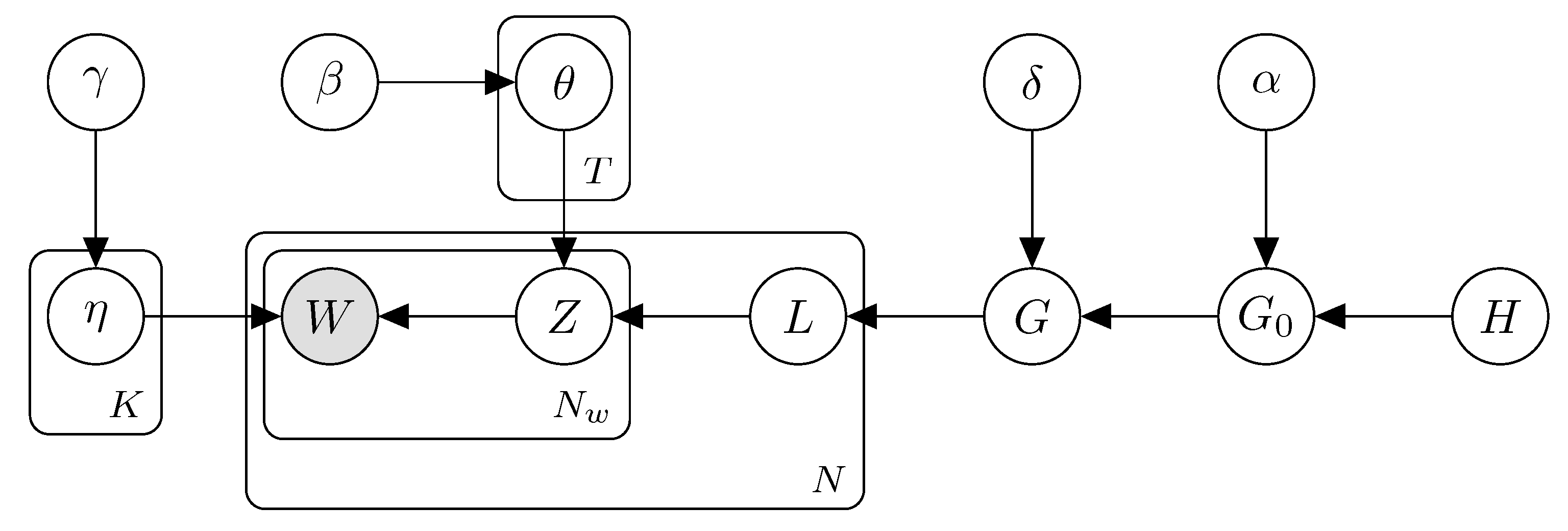
3. Model and Inference
3.1. Overview
- Sample
- Sample
- For each topic zSample
- For each latent long document lSample
- For each short text i
- (a)
- Sample a long document
- (b)
- For each word in short text
- i.
- Sample a topic
- ii.
- Sample the word
3.2. Nested Chinese Restaurant Process
- 1.
- Produce a Chinese restaurant r with unlimited number of tables
- 2.
- The first customer sits at the first table
- 3.
- The customer c sits at
- (a)
- The table k with probability
- (b)
- A new table with probability
- 4.
- For each table k with customers in restaurant r
- (a)
- Produce a Chinese restaurant with unlimited number of tables
- (b)
- The first customer in sits at the first table
- (c)
- The customer in sits at
- i.
- The table with probability
- ii.
- A new table with probability
3.3. Incorporating Document Embeddings
- If , then
- Else , then
- The first short texts samples the first long document
- For each short text i
- (a)
- For each long document
- (a)
- Sampling long document with probability
- (b)
- Sampling a new document with probability
- For each long document with short texts set
- (a)
- The first short texts in samples the first long document
- (b)
- For each short text
- i.
- For each long document l
- i.
- Sampling long document l with probability
- ii.
- Sampling a new document with probability
4. Inference
4.1. Sampling Long Documents Assignments
4.2. Sampling Long Documents Assignments l
4.3. Sampling Topics Assignments z
4.4. DESTM Gibbs Sampling Process
| Algorithm 1: DESTM Sampling Process |
 |
5. Experimental Results
5.1. Experimental Setup
5.1.1. Datasets
5.1.2. Methods
5.1.3. Evaluation Measures
PMI Score
Classification Accuracy
5.1.4. Parameter Settings
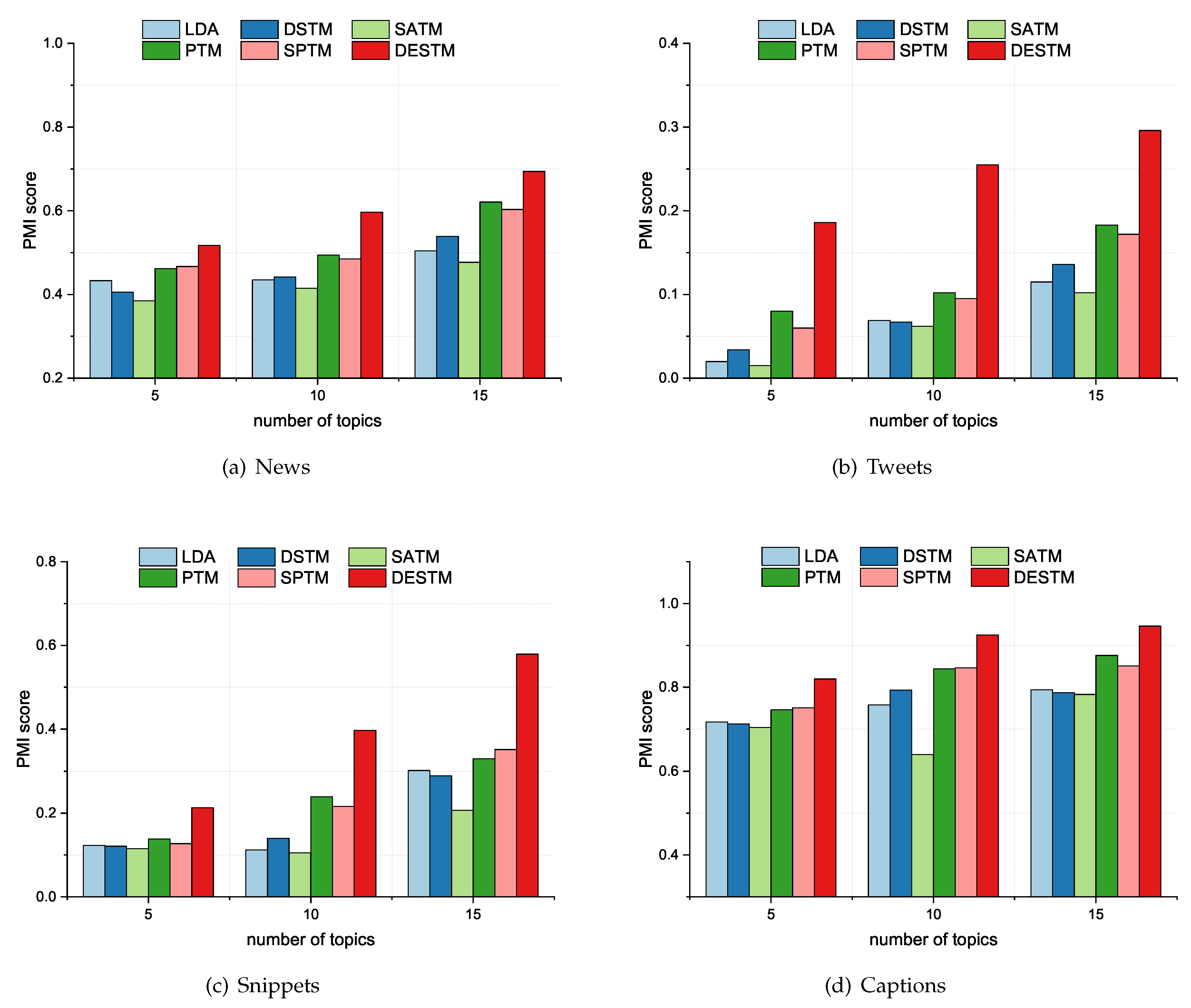
5.2. Topic Evaluation by Topic Coherence
5.3. Topic Evaluation by Classification Accuracy
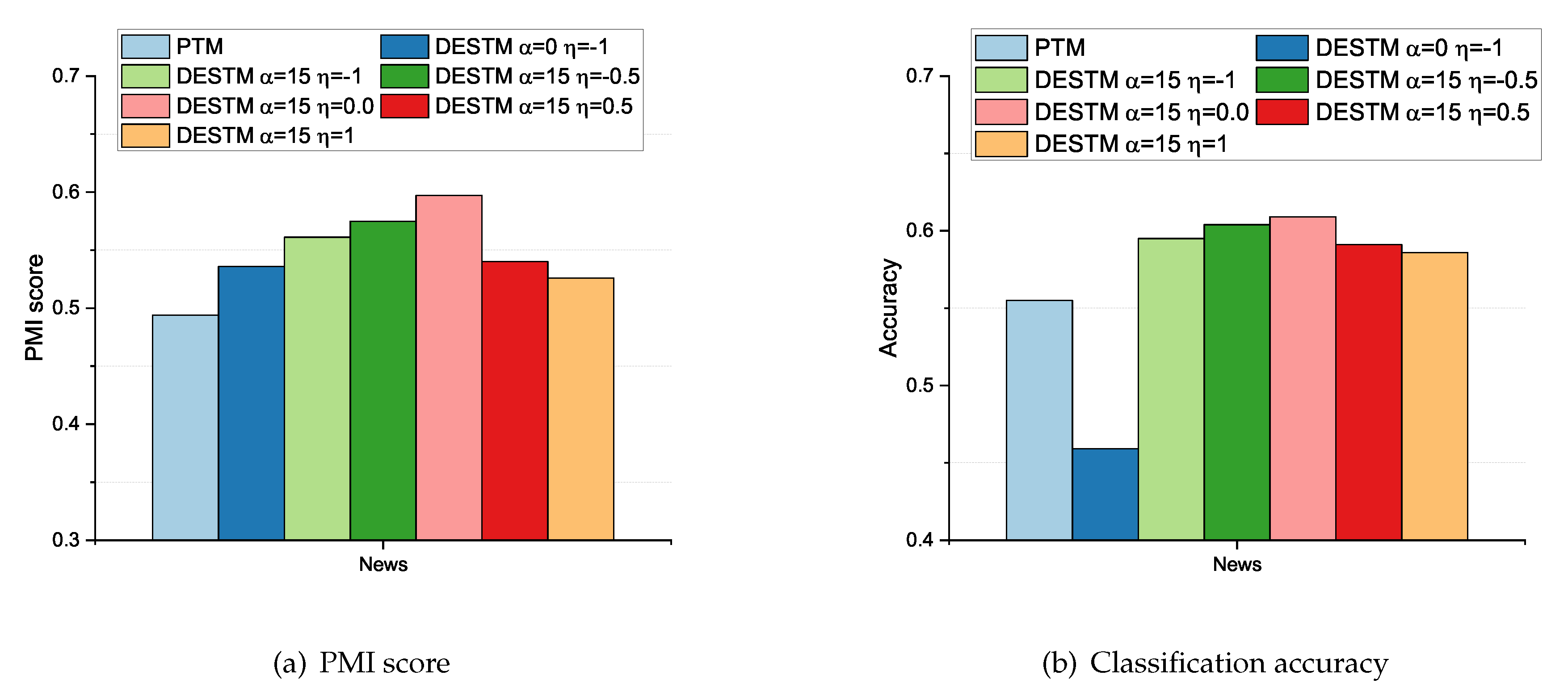
5.4. Experimental Results for Complete and Partial Document Embeddings
5.5. Semantic Explanations of Topic Demonstrations
5.6. Efficiency Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical Dirichlet Processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Wang, X.; McCallum, A. Topics over time: A non-markov continuous-time model of topical trends. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 20–23 August 2006; pp. 424–433. [Google Scholar]
- Zhao, W.X.; Jiang, J.; Weng, J.; He, J.; Lim, E.P.; Yan, H.; Li, X. Comparing twitter and traditional media using topic models. In European Conference on Information Retrieval; Springer: Berlin, Germany, 2011; pp. 338–349. [Google Scholar]
- Likhitha, S.; Harish, B.; Kumar, H.K. A detailed survey on topic modeling for document and short text data. Int. J. Comput. Appl. 2019, 178, 1–9. [Google Scholar] [CrossRef]
- Hong, L.; Davison, B.D. Empirical study of topic modeling in twitter. In Proceedings of the First Workshop on Social Media Analytics, Washington DC, USA, 25–28 July 2010; pp. 80–88. [Google Scholar]
- Mehrotra, R.; Sanner, S.; Buntine, W.; Xie, L. Improving LDA Topic Models for Microblogs via Tweet Pooling and Automatic Labeling; Association for Computing Machinery: Stroudsburg, PA, USA, 2013; pp. 889–892. [Google Scholar]
- Tang, J.; Zhang, M.; Mei, Q. One theme in all views: Modeling consensus topics in multiple contexts. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; Association for Computing Machinery: Stroudsburg, PA, USA, 2013; pp. 5–13. [Google Scholar]
- Nguyen, D.Q.; Billingsley, R.; Du, L.; Johnson, M. Improving Topic Models with Latent Feature Word Representations. Trans. Assoc. Comput. Linguist. 2015, 3, 299–313. [Google Scholar] [CrossRef]
- Das, R.; Zaheer, M.; Dyer, C. Gaussian lda for topic models with word embeddings. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 795–804. [Google Scholar]
- Li, C.; Wang, H.; Zhang, Z.; Sun, A.; Ma, Z. Topic Modeling for Short Texts with Auxiliary Word Embeddings; Association for Computing Machinery: Stroudsburg, PA, USA, 2016; pp. 165–174. [Google Scholar]
- Liang, W.; Feng, R.; Liu, X.; Li, Y.; Zhang, X. GLTM: A global and local word embedding-based topic model for short texts. IEEE Access 2018, 6, 43612–43621. [Google Scholar] [CrossRef]
- Zuo, Y.; Li, C.; Lin, H.; Wu, J. Topic Modeling of Short Texts: A Pseudo-Document View with Word Embedding Enhancement. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Shi, T.; Kang, K.; Choo, J.; Reddy, C.K. Short-text topic modeling via non-negative matrix factorization enriched with local word-context correlations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1105–1114. [Google Scholar]
- Yin, J.; Wang, J. A dirichlet multinomial mixture model-based approach for short text clustering. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 233–242. [Google Scholar]
- Li, C.; Duan, Y.; Wang, H.; Zhang, Z.; Sun, A.; Ma, Z. Enhancing topic modeling for short texts with auxiliary word embeddings. ACM Trans. Inf. Syst. (TOIS) 2017, 36, 1–30. [Google Scholar] [CrossRef]
- Lin, T.; Tian, W.; Mei, Q.; Cheng, H. The dual-sparse topic model: Mining focused topics and focused terms in short text. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 539–550. [Google Scholar]
- Cheng, X.; Yan, X.; Lan, Y.; Guo, J. BTM: Topic Modeling over Short Texts. IEEE Trans. Knowl. Data Eng. 2014, 26, 2928–2941. [Google Scholar] [CrossRef]
- Zuo, Y.; Zhao, J.; Xu, K. Word network topic model: A simple but general solution for short and imbalanced texts. Knowl. Inf. Syst. 2016, 48, 379–398. [Google Scholar] [CrossRef] [Green Version]
- Quan, X.; Kit, C.; Ge, Y.; Pan, S.J. Short and Sparse Text Topic Modeling via Self-Aggregation. 2015, pp. 2270–2276. Available online: https://www.aaai.org/ocs/index.php/IJCAI/IJCAI15/paper/viewFile/10847/10978 (accessed on 5 September 2021).
- Zuo, Y.; Wu, J.; Zhang, H.; Lin, H.; Wang, F.; Xu, K.; Xiong, H. Topic Modeling of Short Texts: A Pseudo-Document View. 2016, pp. 2105–2114. Available online: https://dl.acm.org/doi/10.1145/2939672.2939880 (accessed on 5 September 2021).
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, PMLR. 2014, pp. 1188–1196. Available online: http://proceedings.mlr.press/v32/le14.html (accessed on 5 September 2021).
- Hu, Y.; John, A.; Wang, F.; Kambhampati, S. Et-lda: Joint topic modeling for aligning events and their twitter feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 26. [Google Scholar]
- Zhao, W.X.; Wang, J.; He, Y.; Nie, J.Y.; Wen, J.R.; Li, X. Incorporating social role theory into topic models for social media content analysis. IEEE Trans. Knowl. Data Eng. 2014, 27, 1032–1044. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Wang, F. Author topic model for co-occurring normal documents and short texts to explore individual user preferences. Inf. Sci. 2021, 570, 185–199. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Yi, F.; Jiang, B.; Wu, J. Topic modeling for short texts via word embedding and document correlation. IEEE Access 2020, 8, 30692–30705. [Google Scholar] [CrossRef]
- Mai, C.; Qiu, X.; Luo, K.; Chen, M.; Zhao, B.; Huang, Y. TSSE-DMM: Topic Modeling for Short Texts Based on Topic Subdivision and Semantic Enhancement; PAKDD (2); Springer: Berlin, Germany, 2021; pp. 640–651. [Google Scholar]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Phan, X.H.; Nguyen, L.M.; Horiguchi, S. Learning to classify short and sparse text & web with hidden topics from large-scale data collections. In Proceedings of the 17th International Conference on World Wide Web, Beijing China, 21–25 April 2008; pp. 91–100. [Google Scholar]
- Finegan-Dollak, C.; Coke, R.; Zhang, R.; Ye, X.; Radev, D. Effects of creativity and cluster tightness on short text clustering performance. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 654–665. [Google Scholar]
- Newman, D.; Lau, J.H.; Grieser, K.; Baldwin, T. Automatic evaluation of topic coherence. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 100–108. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection; IJCAI: Montreal, QC, Canada, 1995; Volume 14, pp. 1137–1145. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | Models |
|---|---|
| Models with auxiliary data | Incorporating metadata [7,8,9,24,25,26] |
| Incorporating a long document set [10,11,12,13,14,29,30] | |
| Models without auxiliary data | Limiting topics correspond to each text [16,17,18] |
| Using global word co-occurrence information [19,20] | |
| Aggregating short texts automatically [21,22] |
| DataSet | D | V | Len | C |
|---|---|---|---|---|
| News | 3000 | 10,906 | 12 | 7 |
| Tweets | 2500 | 4981 | 8 | 100 |
| Snippets | 3000 | 4705 | 14 | 8 |
| Captions | 4834 | 3165 | 5 | 20 |
| Topic | Top-10 Words |
|---|---|
| Topic1 | game coach season year scored night team big points boston |
| Topic2 | billion group bank financial deal company international chief fund companies |
| Topic3 | oil prices year percent high rose growth economic demand fell |
| Topic4 | japan nuclear power health study earthquake plant government crisis world |
| Topic5 | air officials libyan city nato muammar country people military killed |
| Topic6 | open world final french year champion championship week players national |
| Topic7 | president court state obama federal minister judge prime year election |
| Topic8 | american long online video apple weekend internet music million year |
| Topic9 | president al killed security country forces government people bin laden |
| Topic10 | show life years news tv star play broadway wedding making |
| Models | Time of Initialization (ms) | Average Time per Iteration (ms) |
|---|---|---|
| LDA | 15 | 15 |
| DSTM | 71 | 2631 |
| SATM | 16 | 815 |
| PTM | 15 | 193 |
| SPTM | 16 | 237 |
| DESTM | 310 | 442 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, Y.; Zhang, H.; Li, J. A Nested Chinese Restaurant Topic Model for Short Texts with Document Embeddings. Appl. Sci. 2021, 11, 8708. https://doi.org/10.3390/app11188708
Niu Y, Zhang H, Li J. A Nested Chinese Restaurant Topic Model for Short Texts with Document Embeddings. Applied Sciences. 2021; 11(18):8708. https://doi.org/10.3390/app11188708
Chicago/Turabian StyleNiu, Yue, Hongjie Zhang, and Jing Li. 2021. "A Nested Chinese Restaurant Topic Model for Short Texts with Document Embeddings" Applied Sciences 11, no. 18: 8708. https://doi.org/10.3390/app11188708