
Action Classification for Partially Occluded Silhouettes by Means of Shape and Action Descriptors


Abstract
:1. Introduction
2. Related Works on Action Recognition and the Problem of Object Occlusion
2.1. Selected Related Works
2.2. Action Recognition under Occlusion
3. Proposed Approach for Extraction and Classification of Action Descriptors
3.1. Database and Preprocessing
- Aerobic exercise, e.g., running, walking, skipping, jumping jack (activities in which the body’s large muscles move in a rhythmic manner);
- Balance training, e.g., galloping sideways, jumping in place, jumping forward on two legs (activities increasing lower body strength);
- Flexibility exercise, e.g., one or two-hand waving, bending (activities preserving or extending motion range around joints).
3.2. Extracting Motion Information and Adding Occlusion
3.3. Shape Description
3.4. Action Representation
3.5. Action Classification
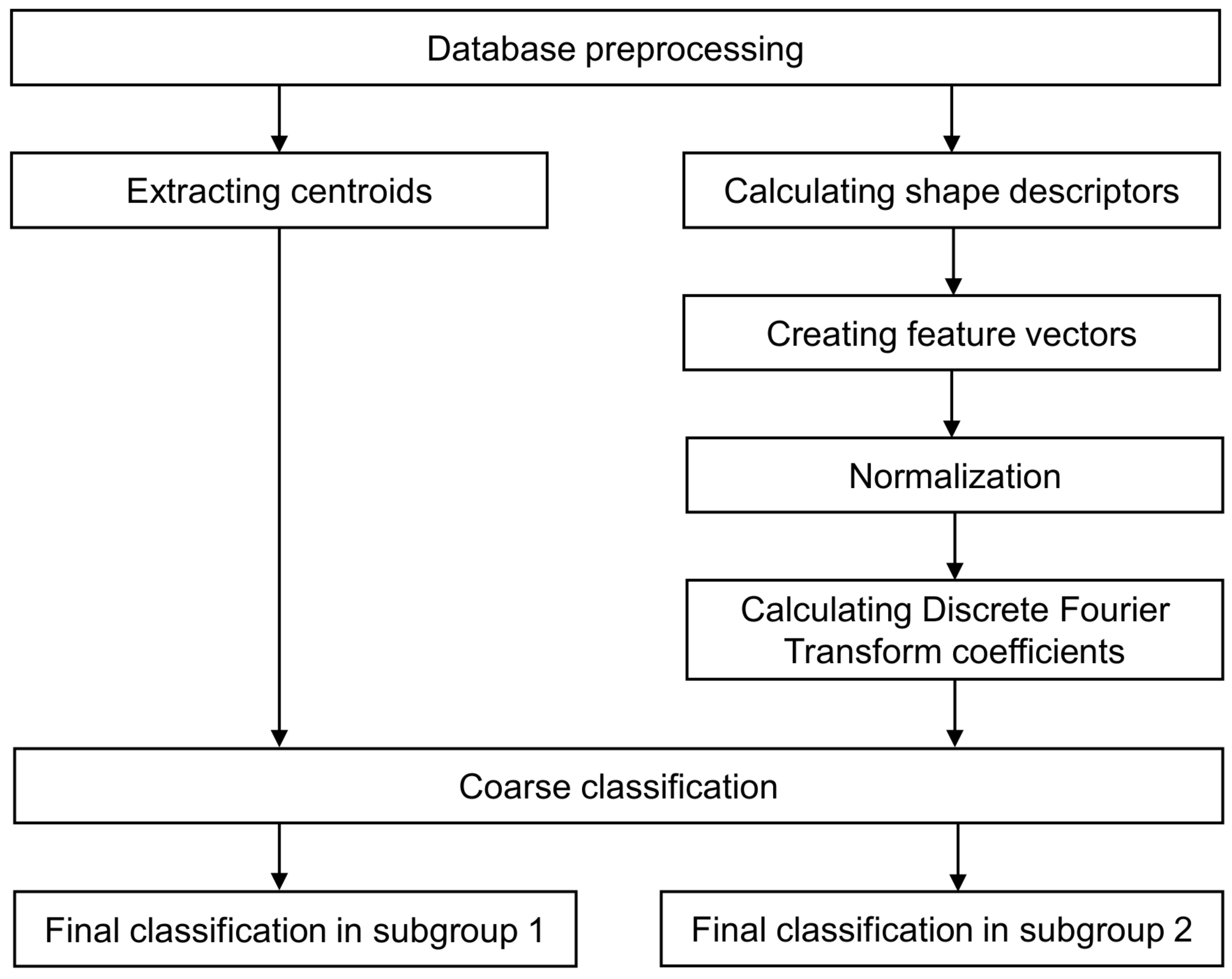
3.6. List of Processing Steps
- The database is preprocessed as explained in Section 3.1, and occlusion is added based on Section 3.2.
- Motion and shape features are extracted from all sequences. A sequence is composed of binary foreground masks and represented by a vector with normalized shape descriptors, , where n is the number of frames. Shape descriptors are based on the Minimum Bounding Rectangle measurements which are explained in Section 3.3. To collect motion information, centroid locations are stored as trajectories (Section 3.2). Centroid coordinates are calculated as an average of coordinates of all points included in the shape area.
- Each vector is transformed into action representation using the Discrete Fourier Transform (Section 3.4). The one-dimensional DFT of an exemplary vector of length t (; T is a period of t) is as follows [42]:Then, a selected number of absolute coefficients is used for classification.
- Coarse classification is performed based on trajectory length. The database is divided into two subgroups.
- Final classification (Section 3.5) is performed in each subgroup separately using the leave-one-sequence-out procedure and one of the following matching measures—Euclidean distance [41] or C1 correlation [40]. The respective formulas for two compared vectors and are:
4. Experimental Conditions and Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
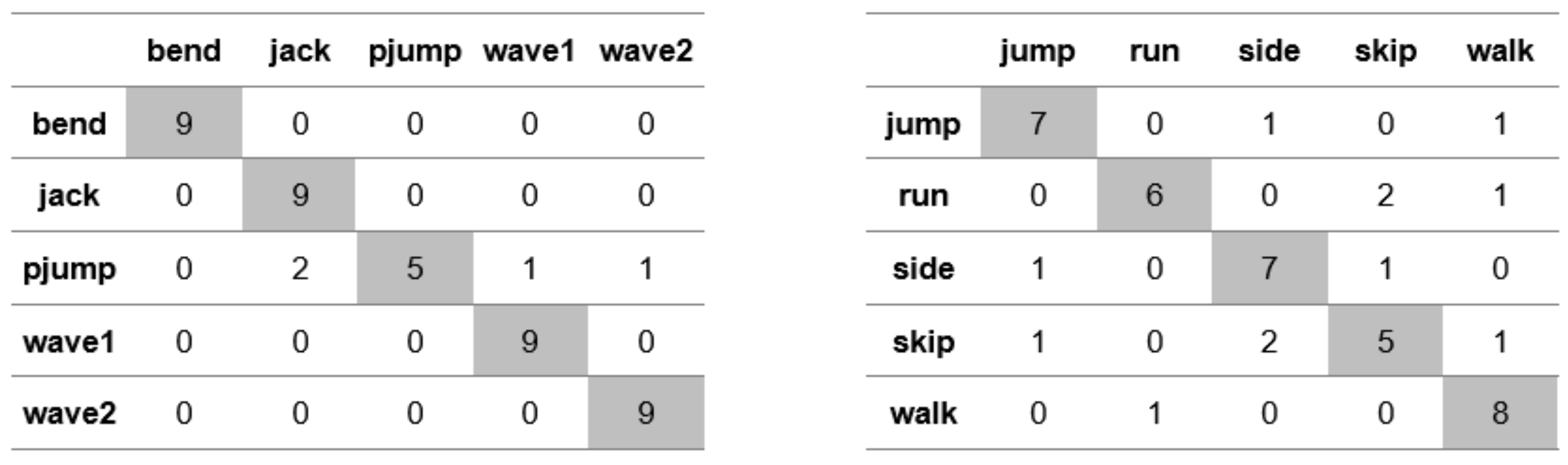
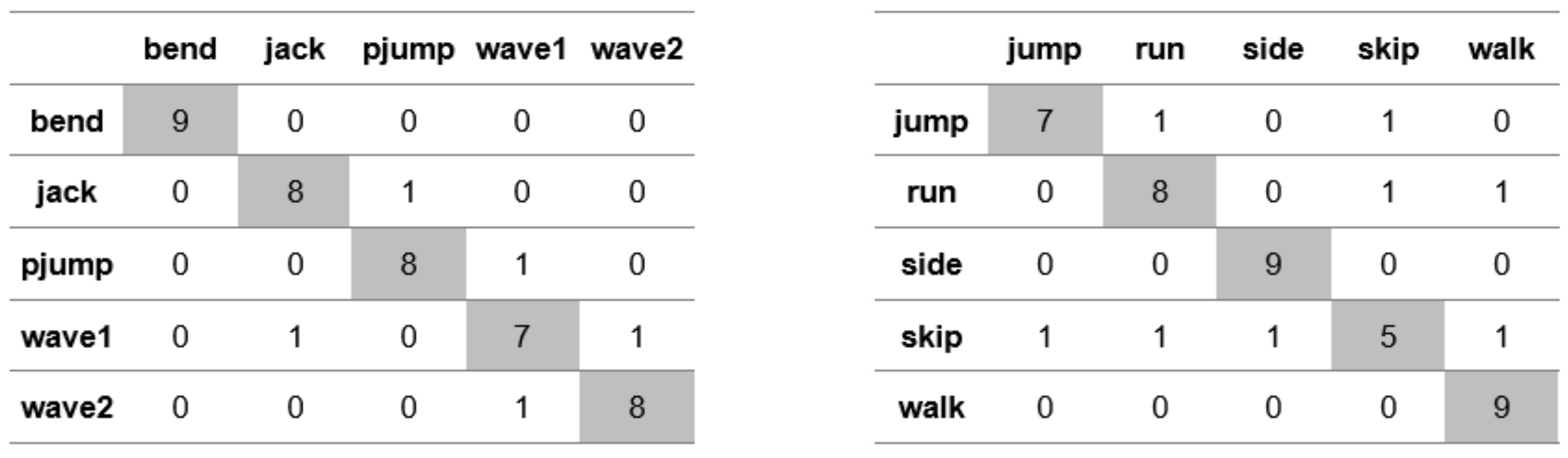
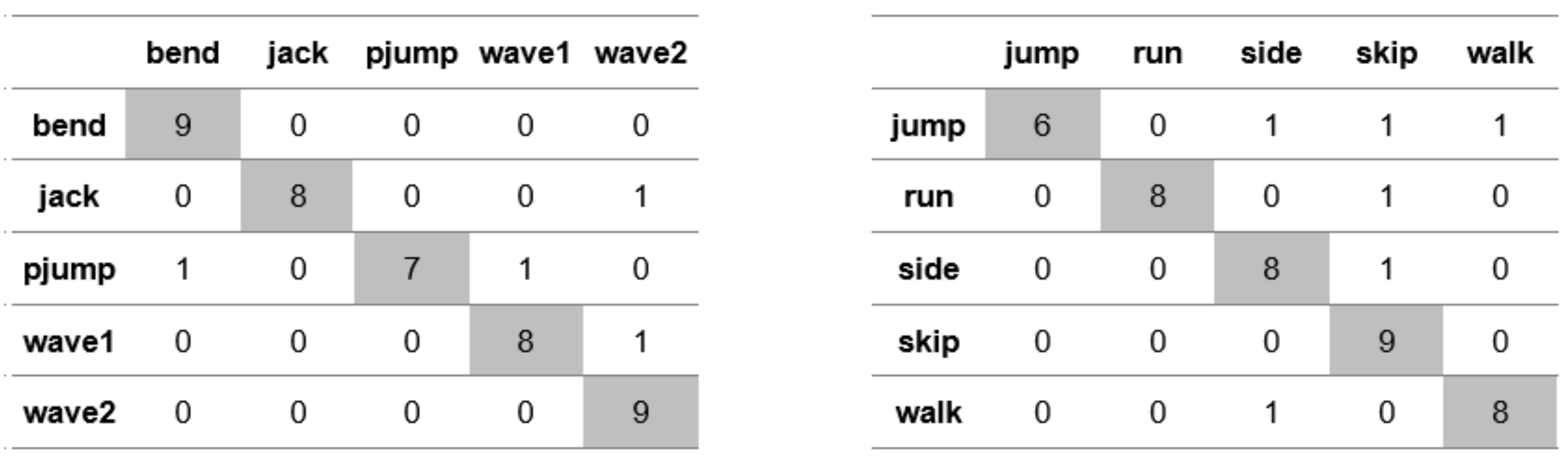
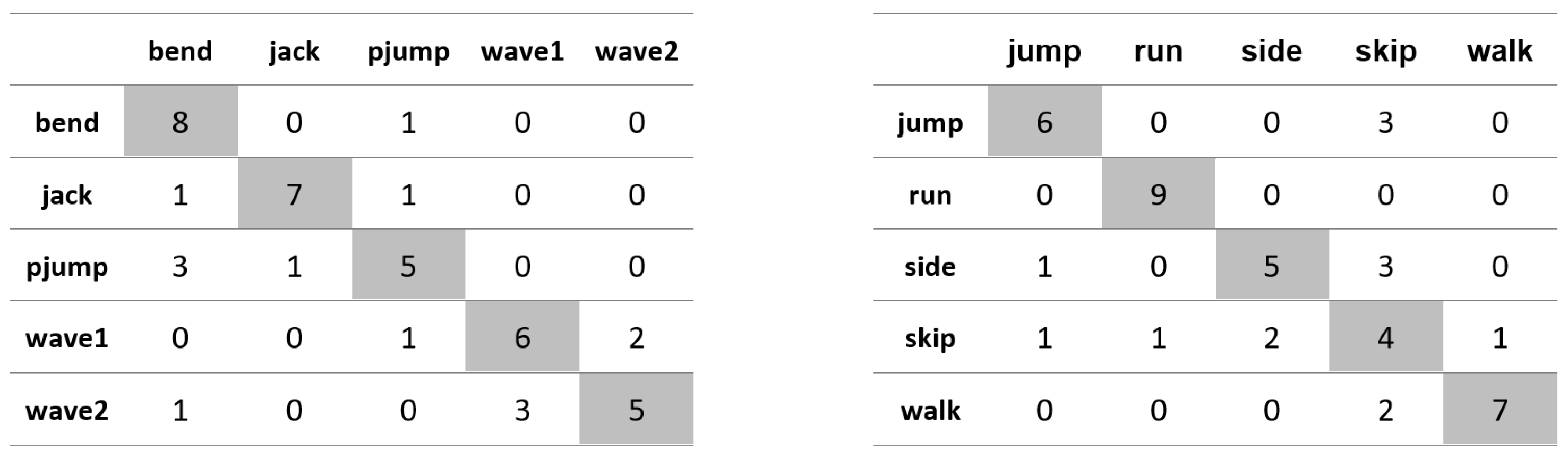
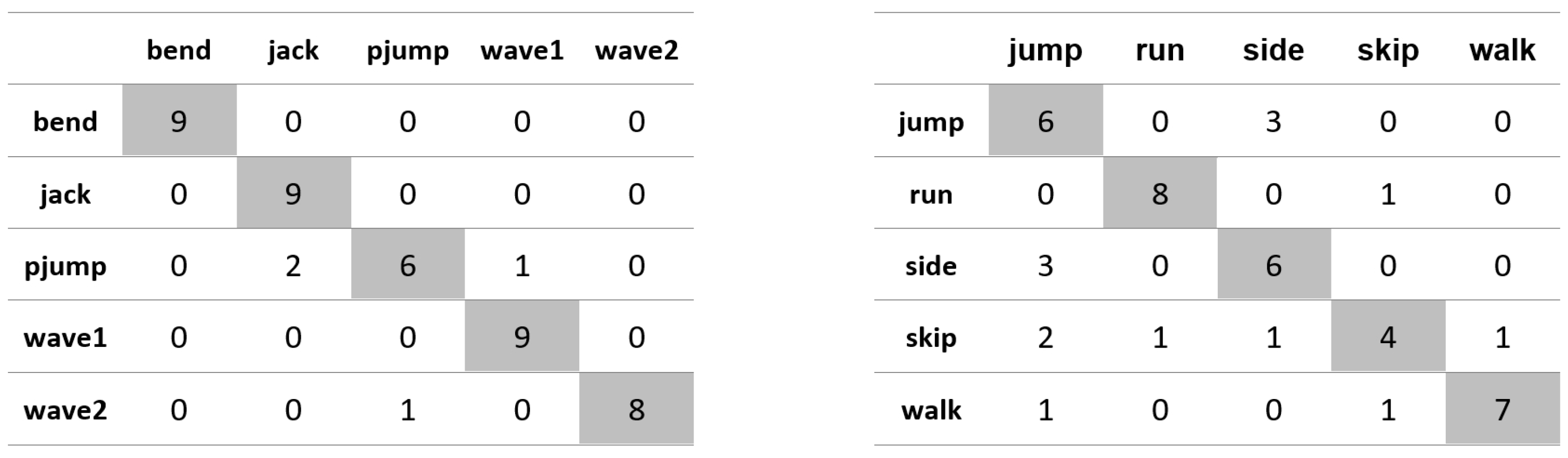
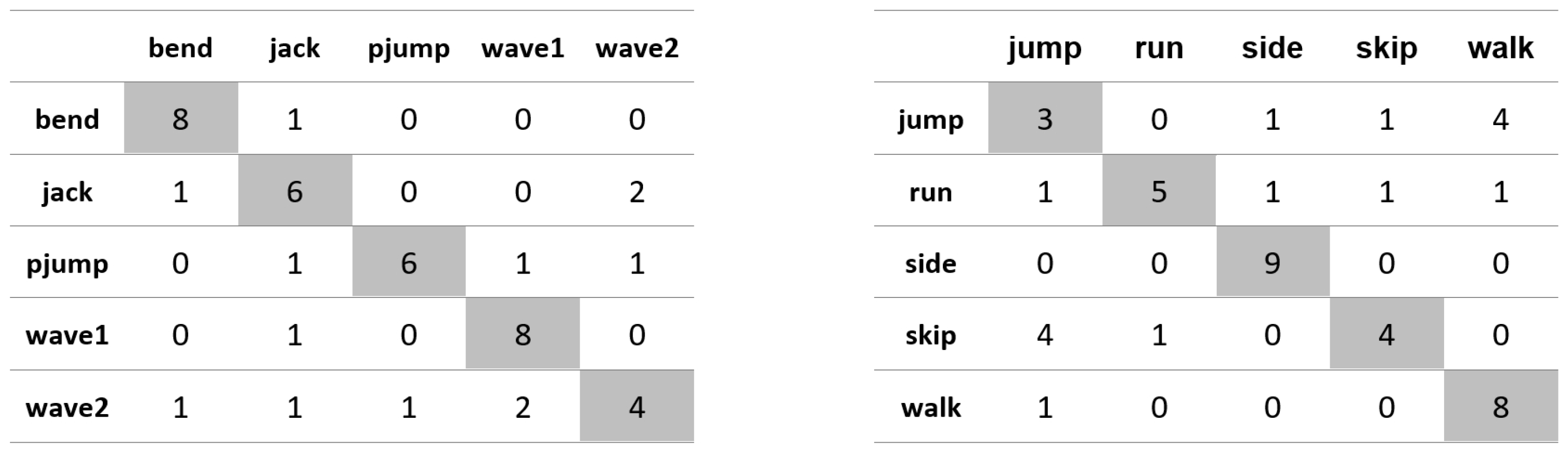
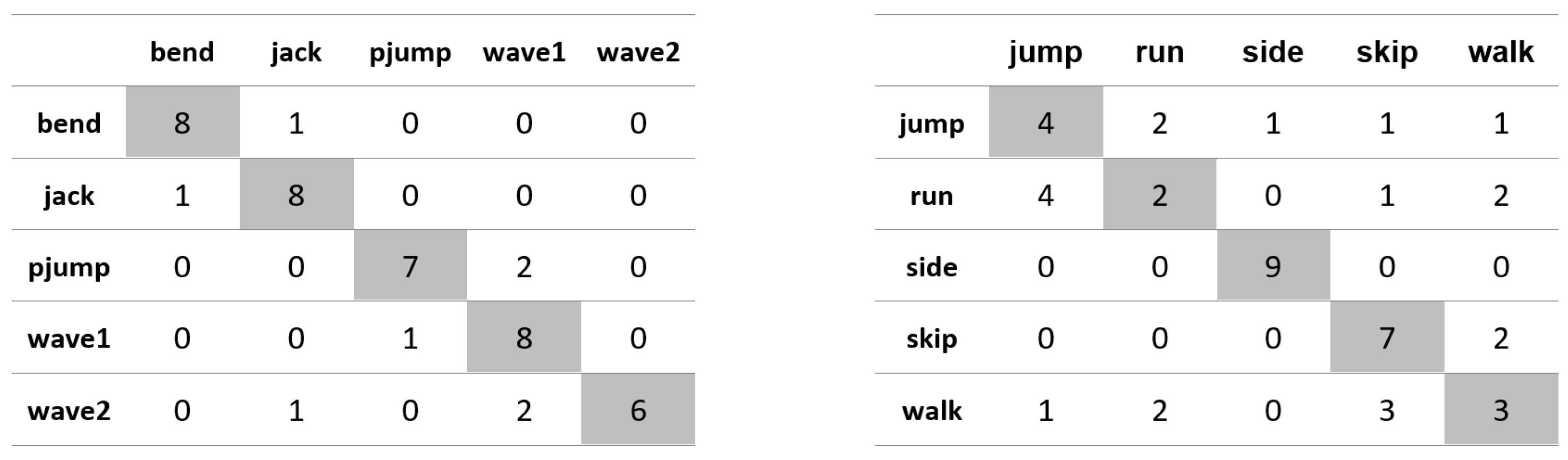
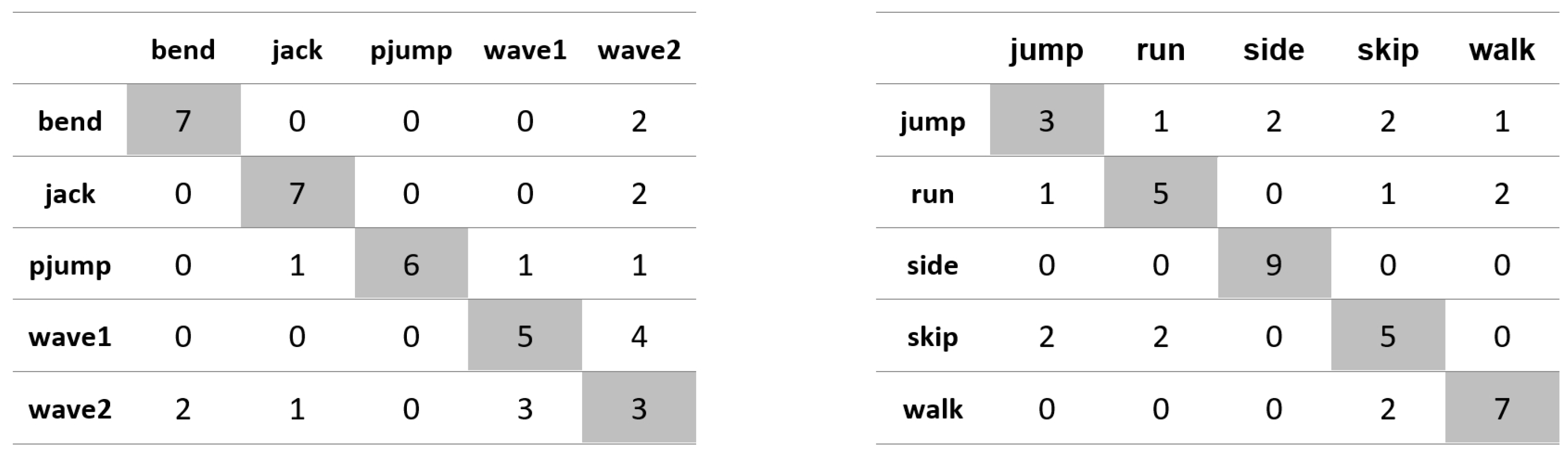
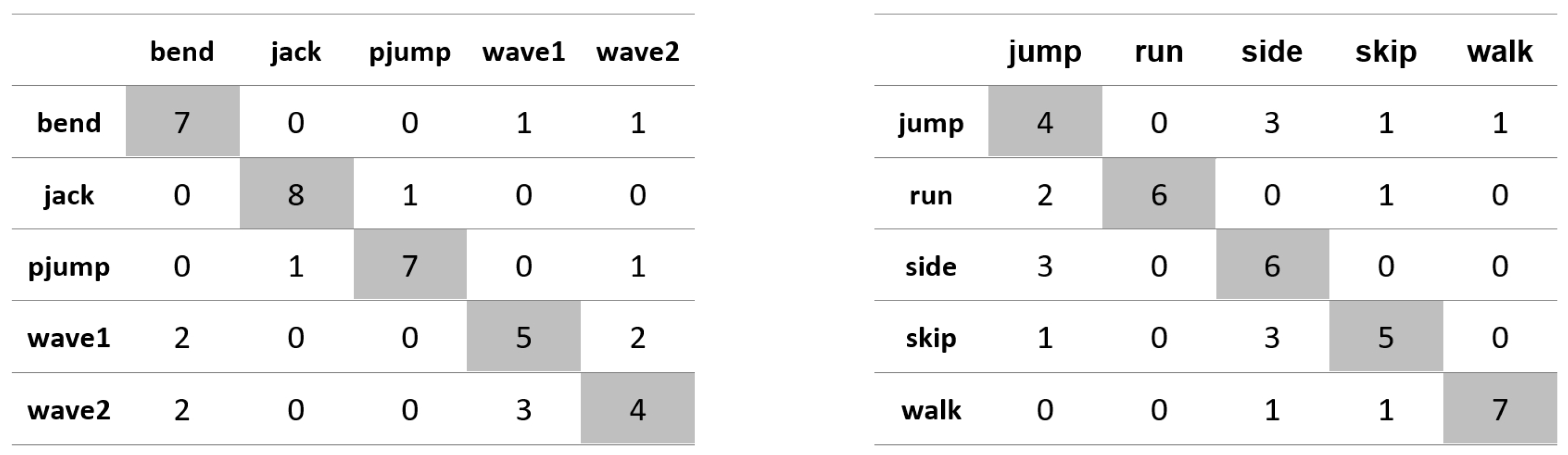
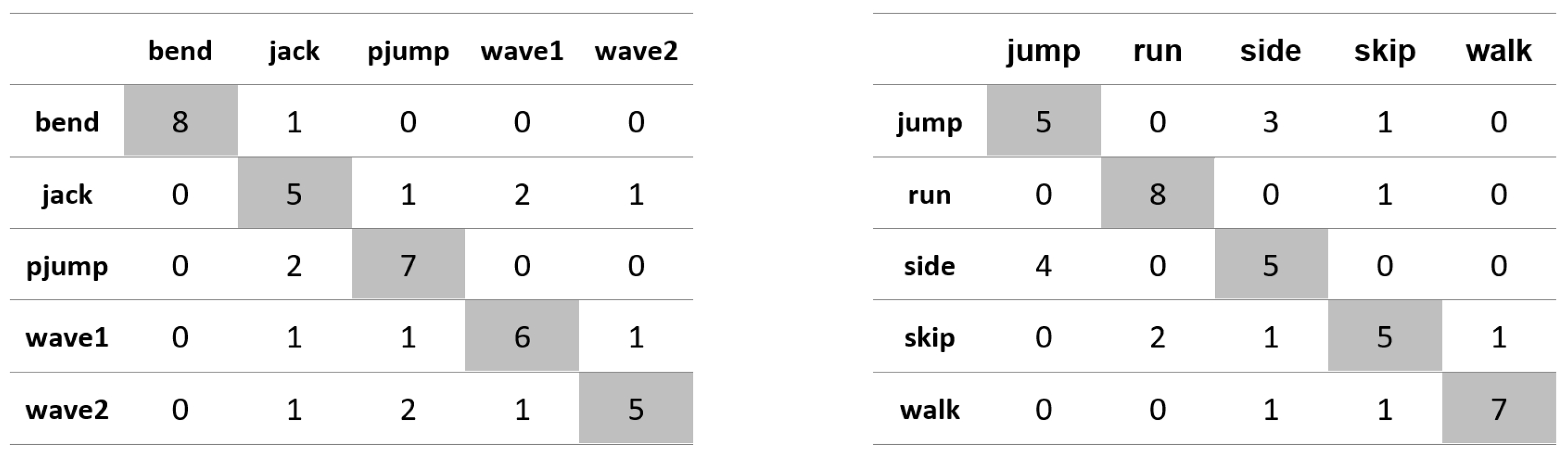
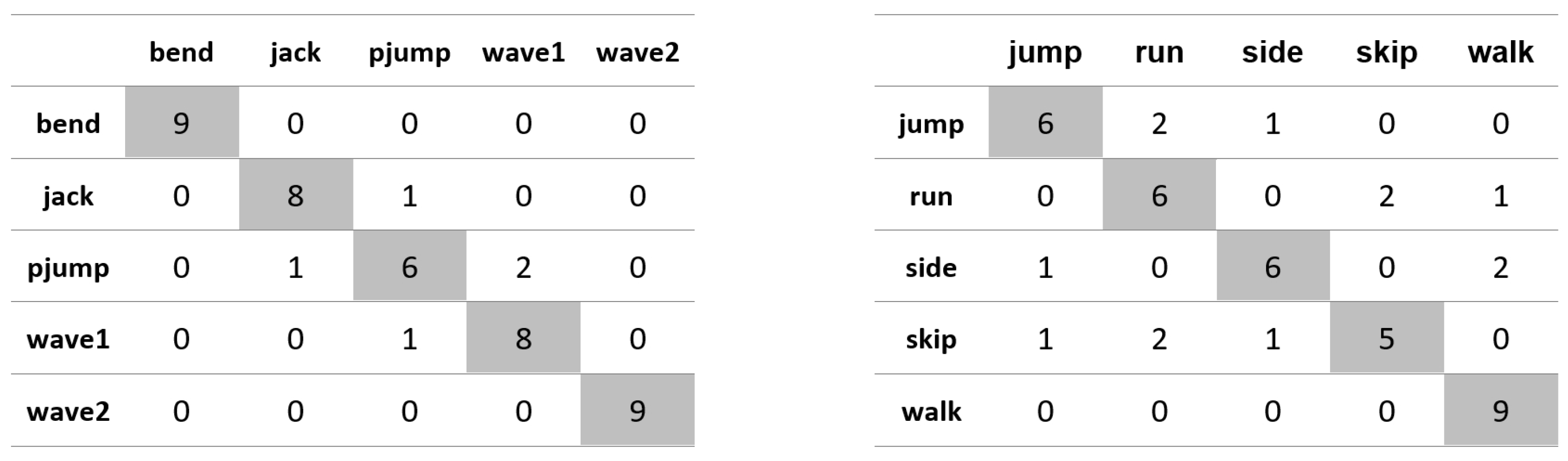
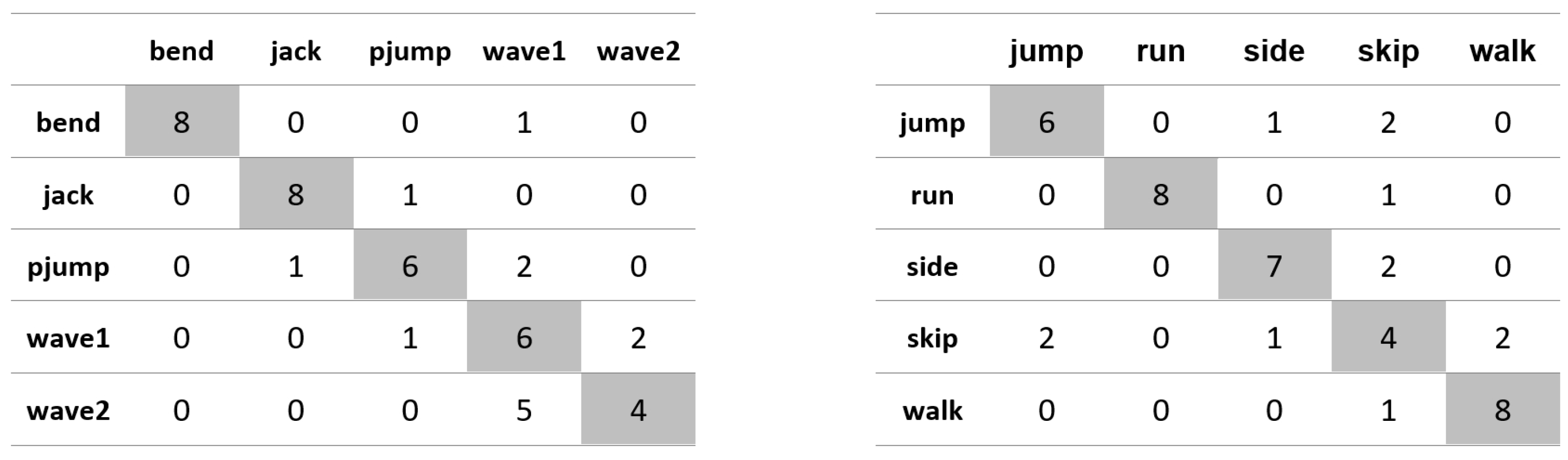
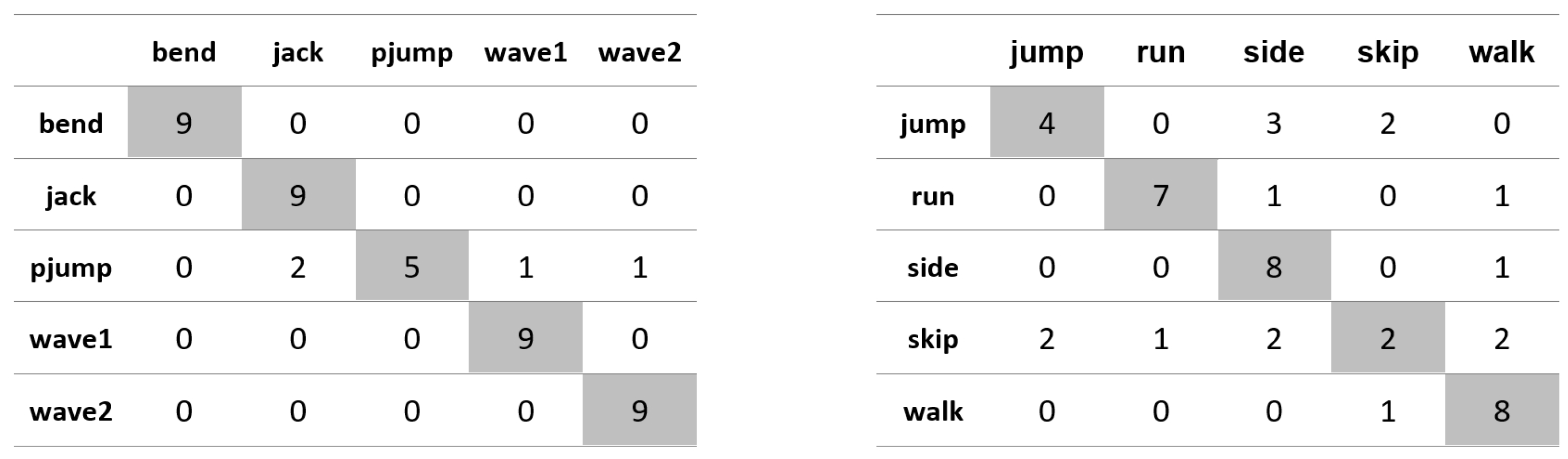
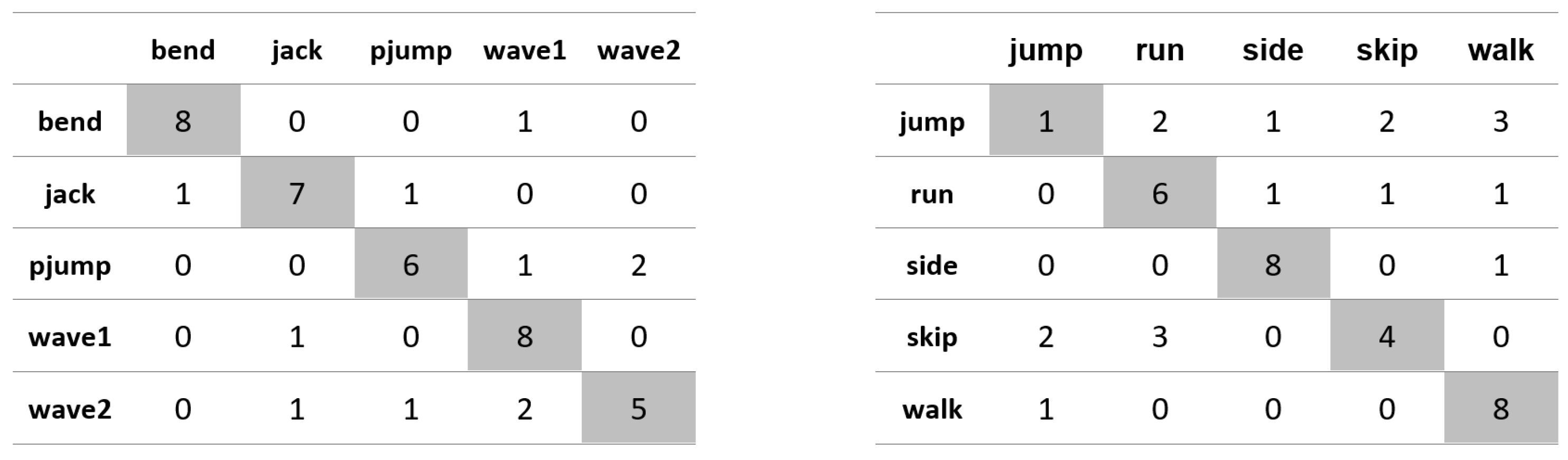
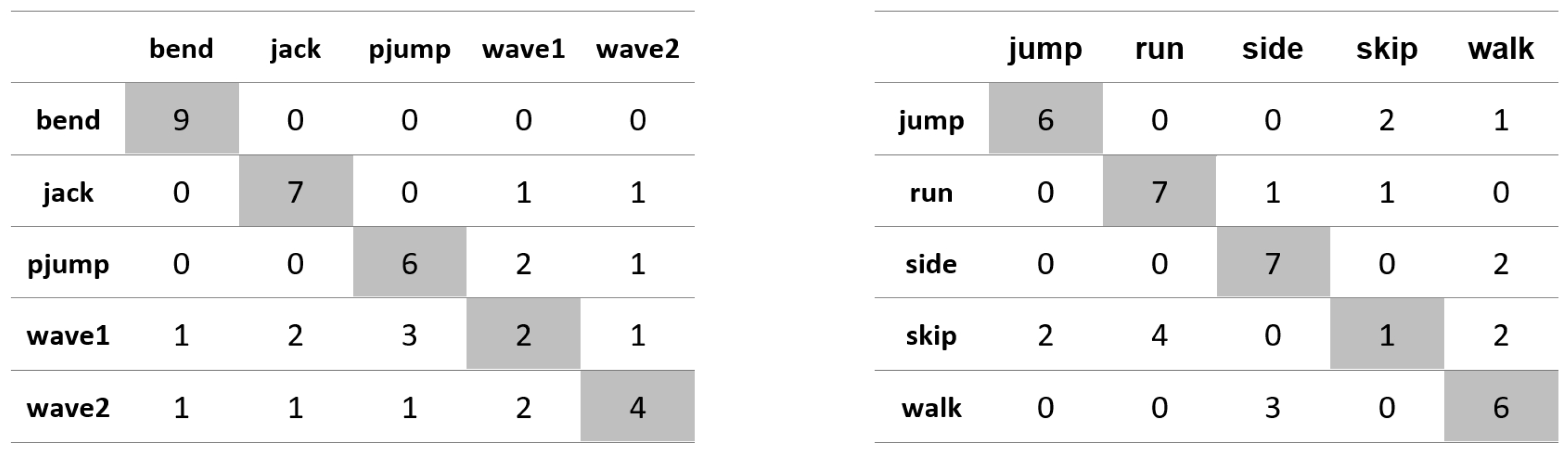
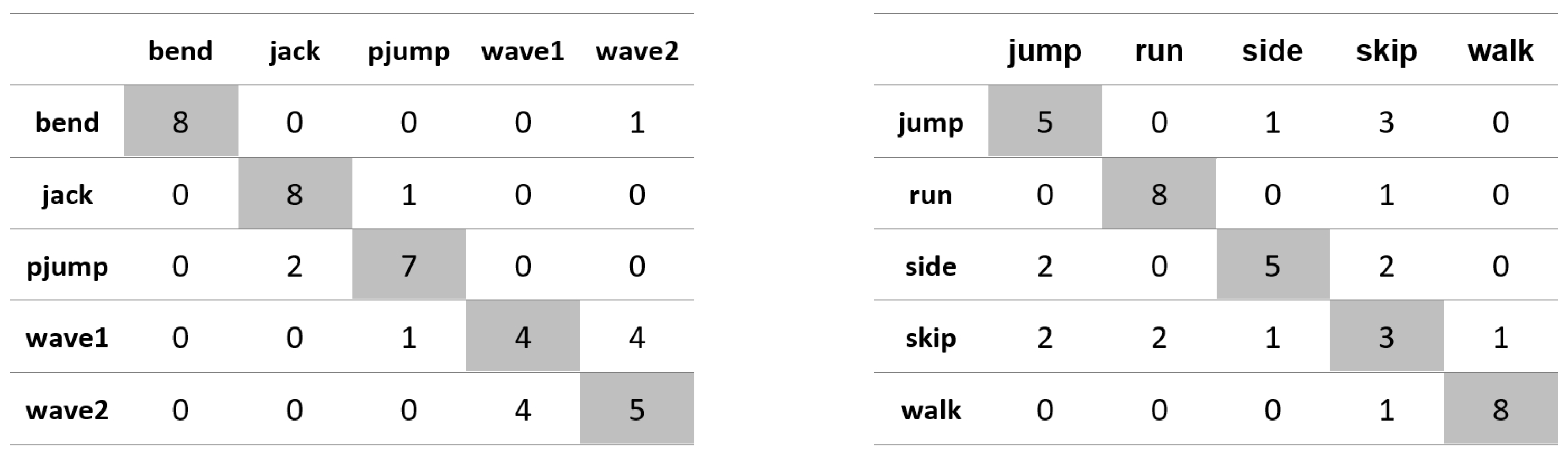
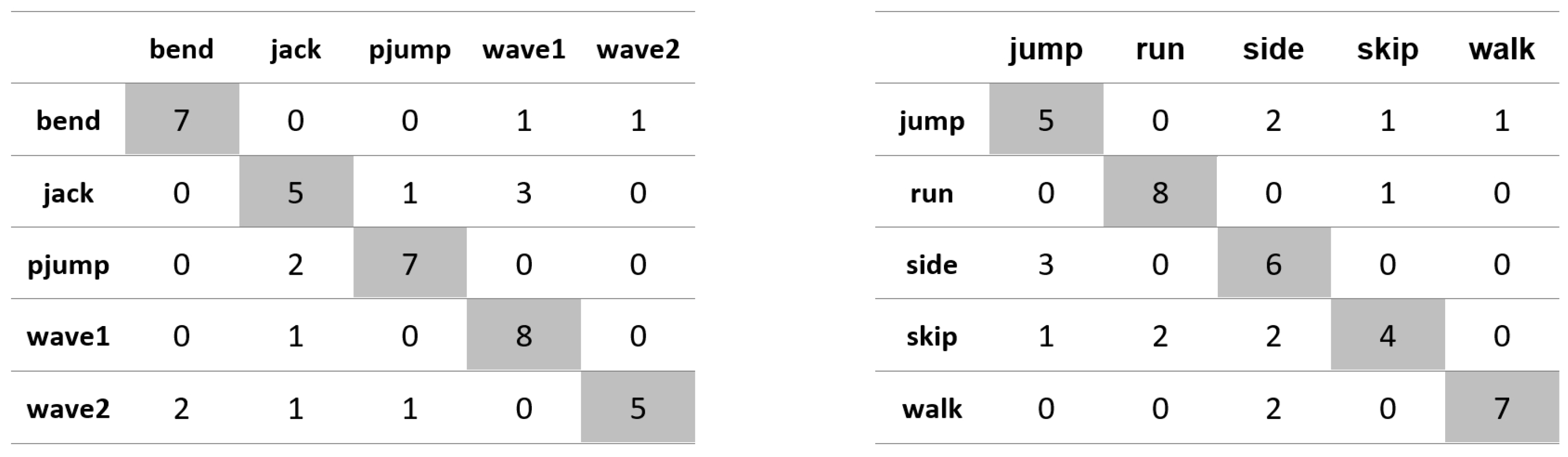
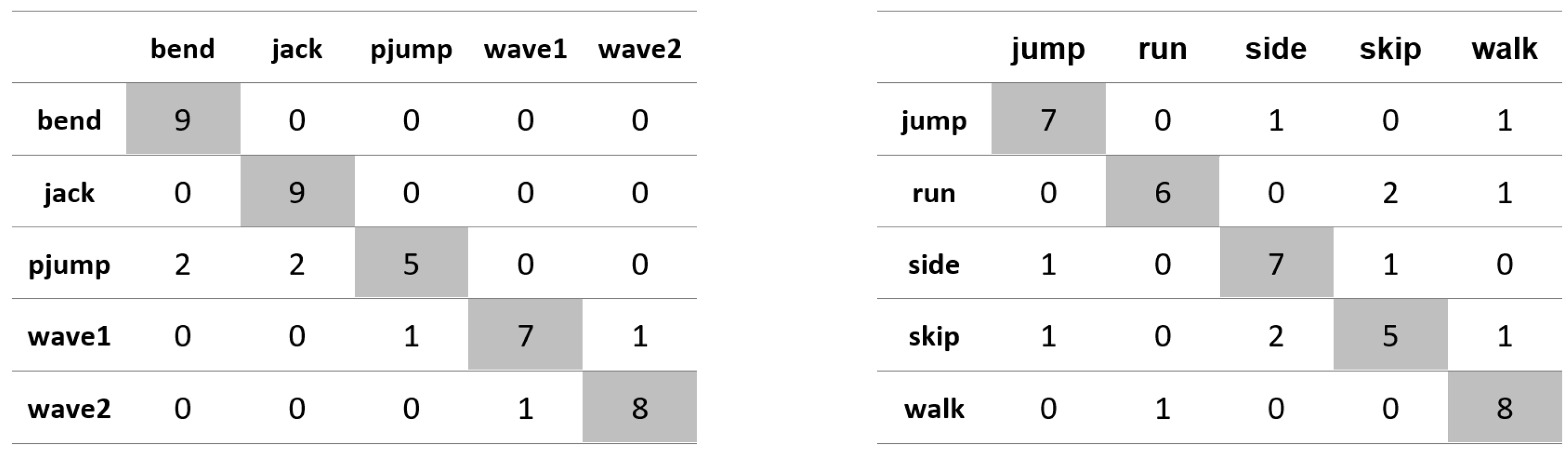
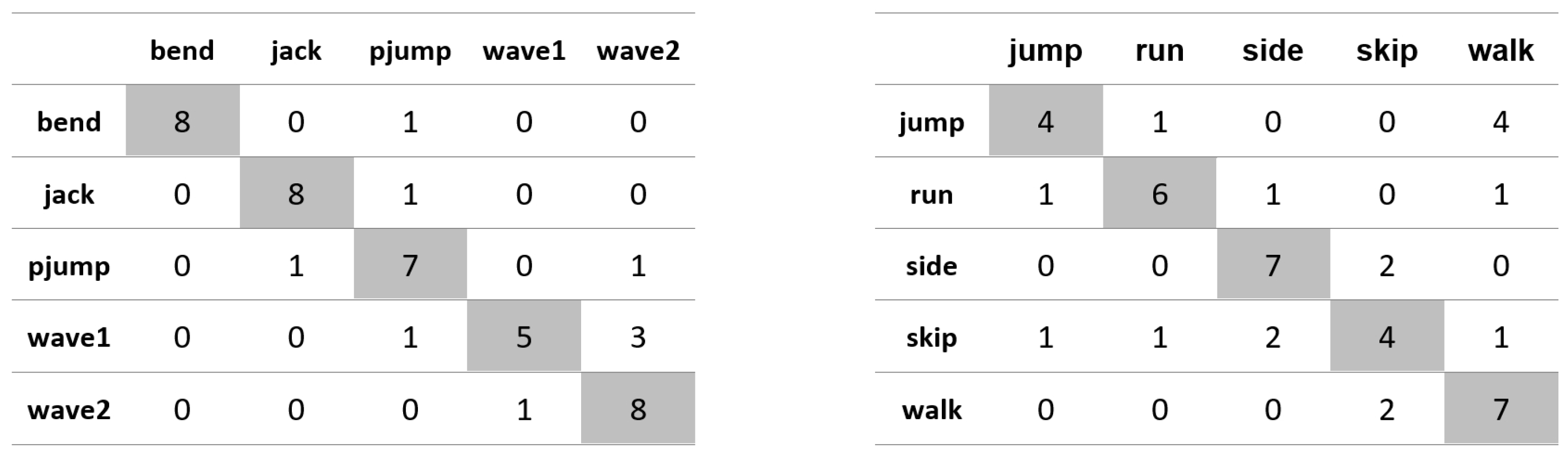
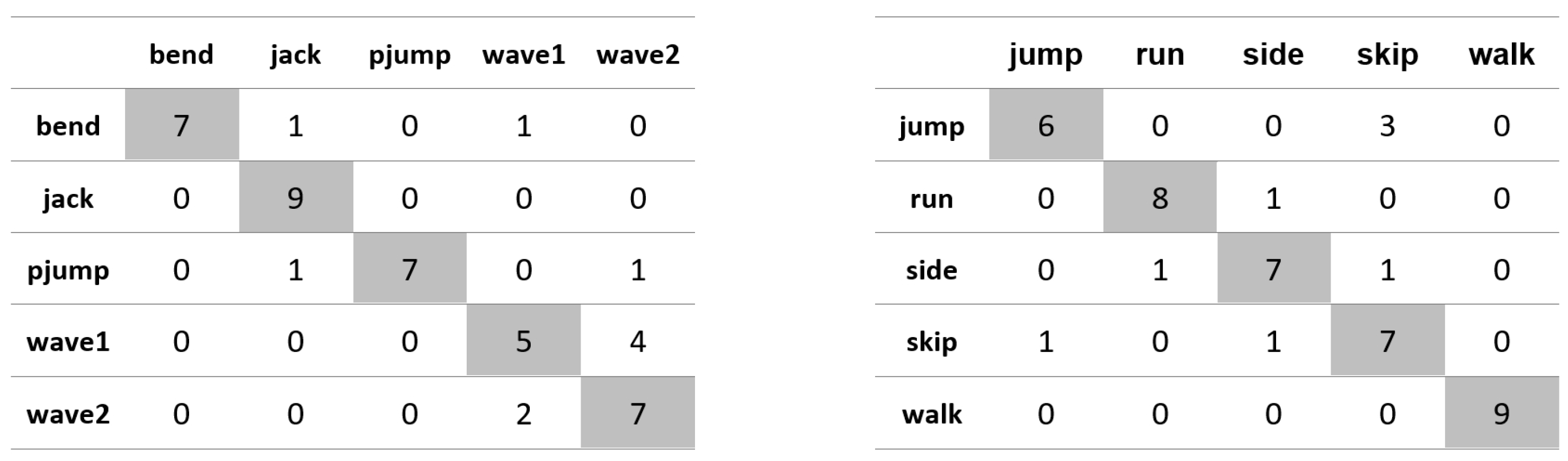
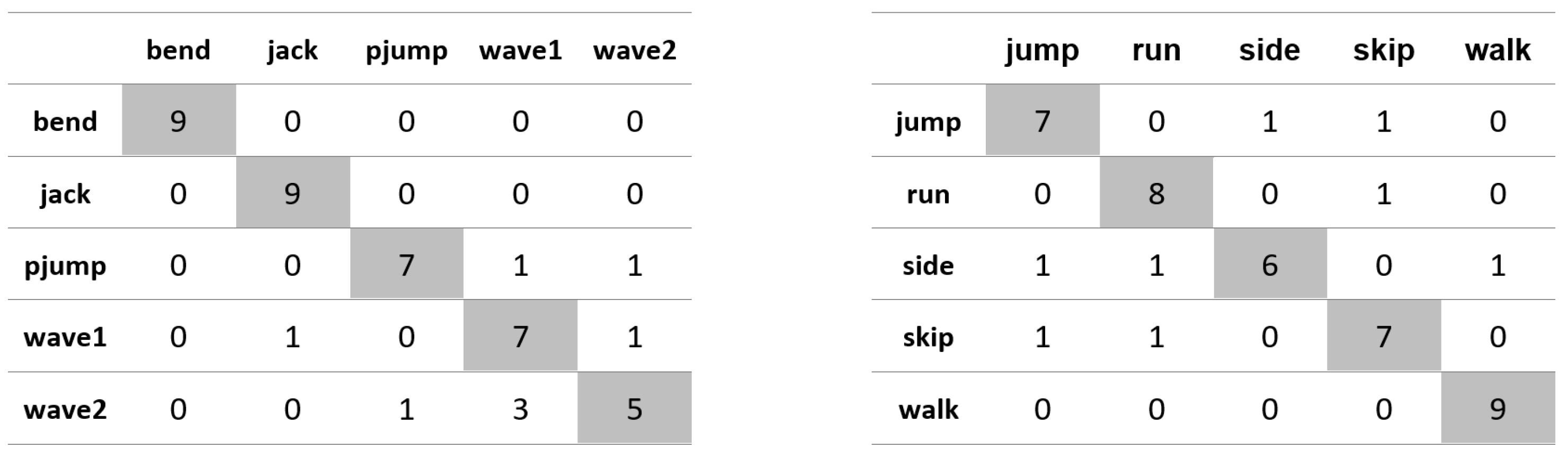
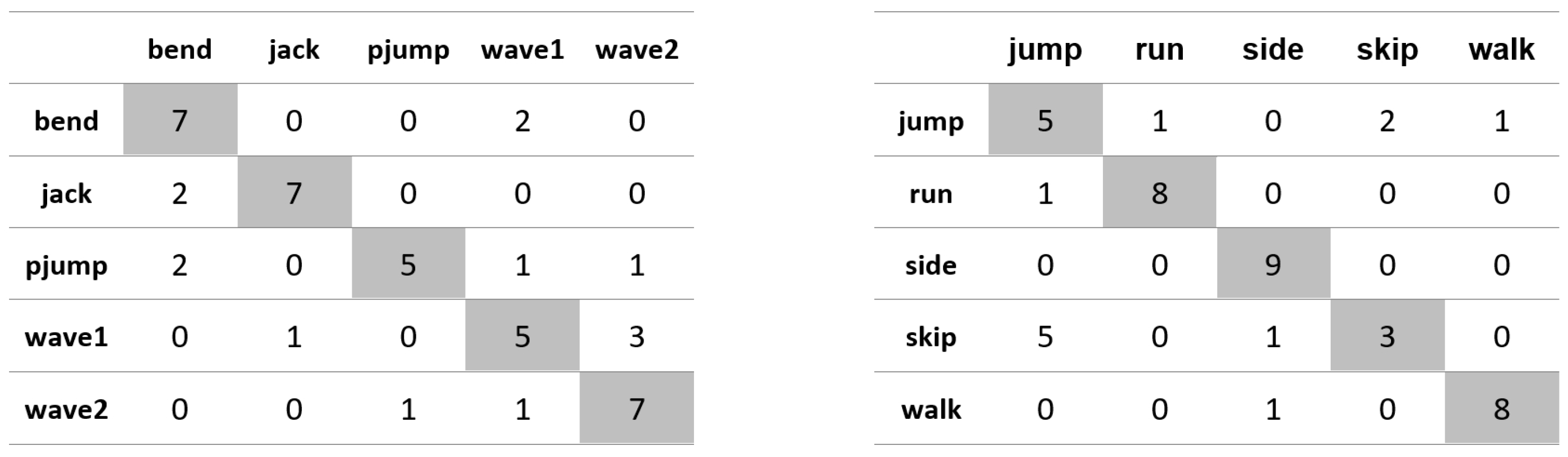
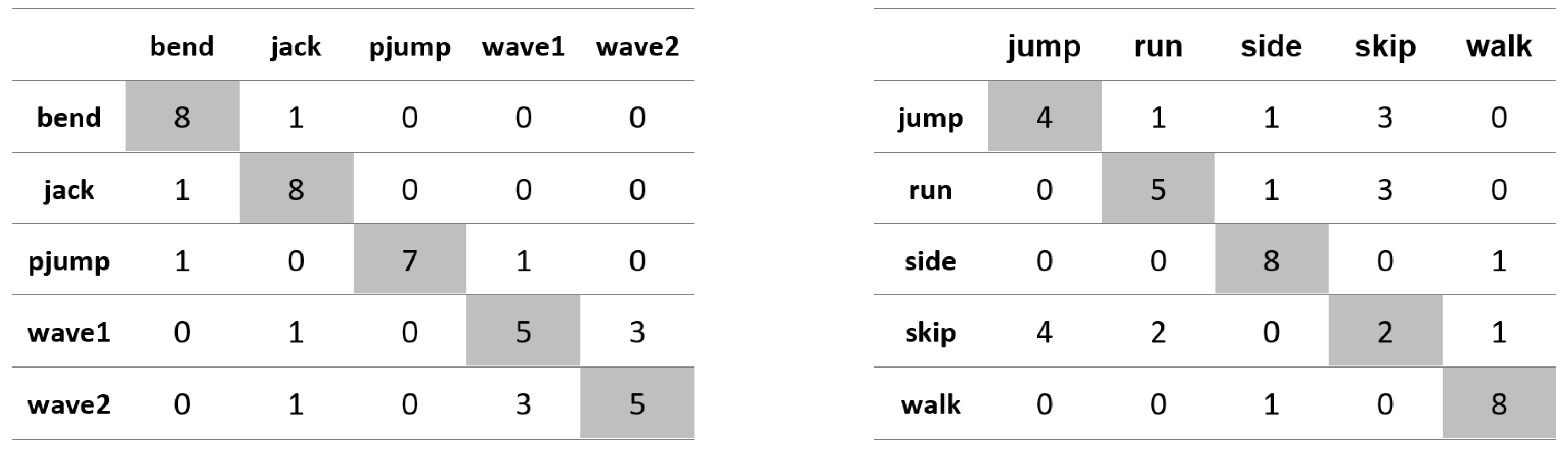
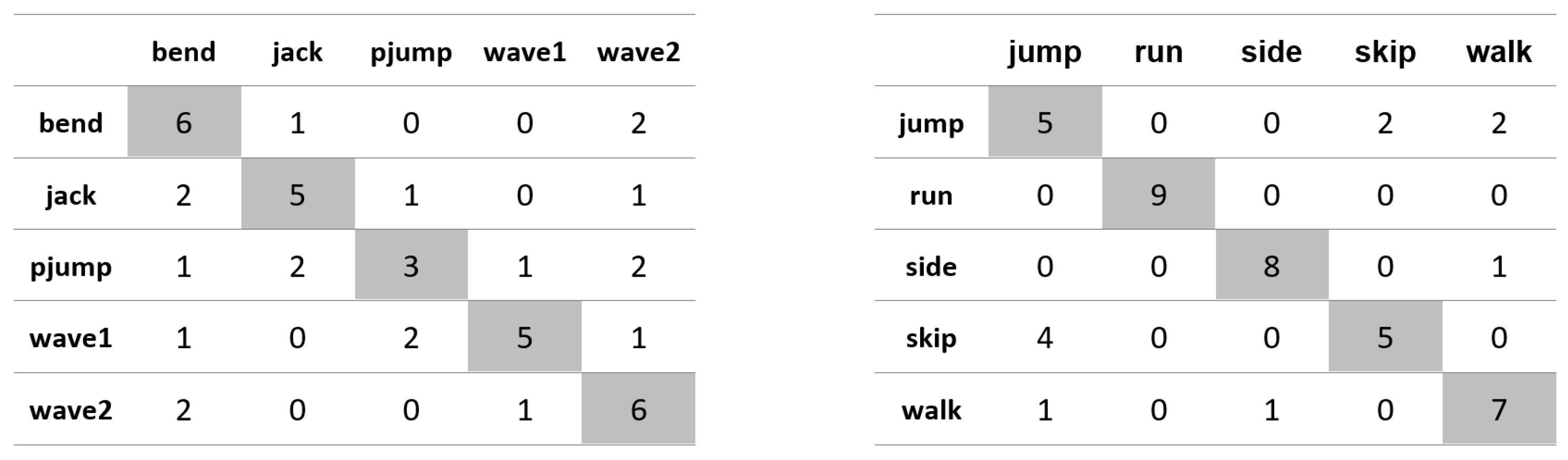
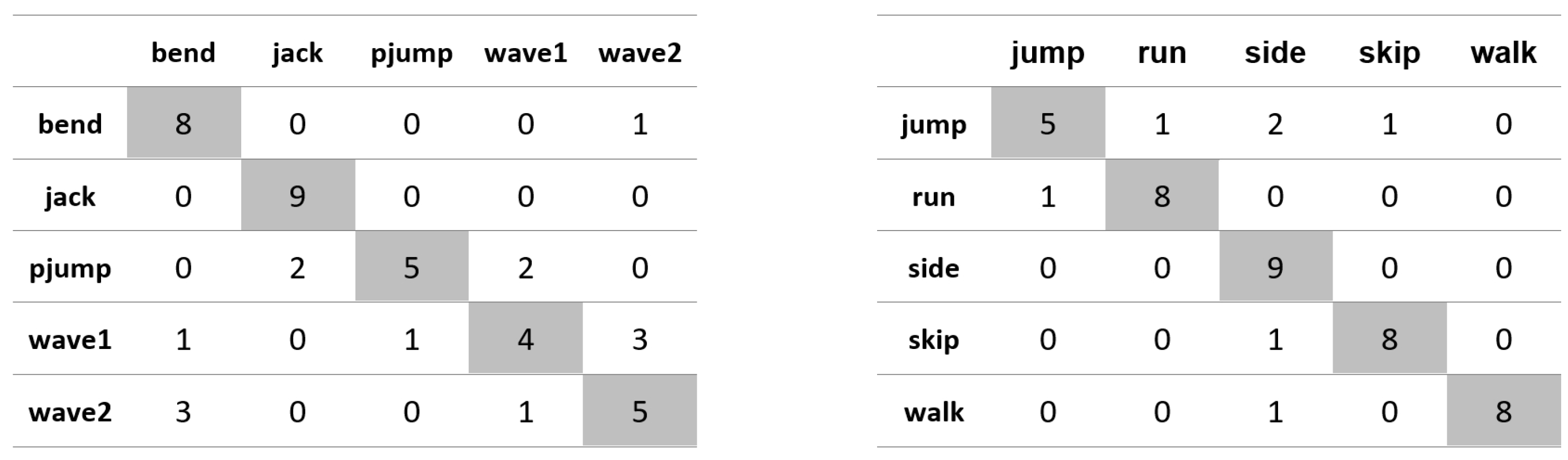
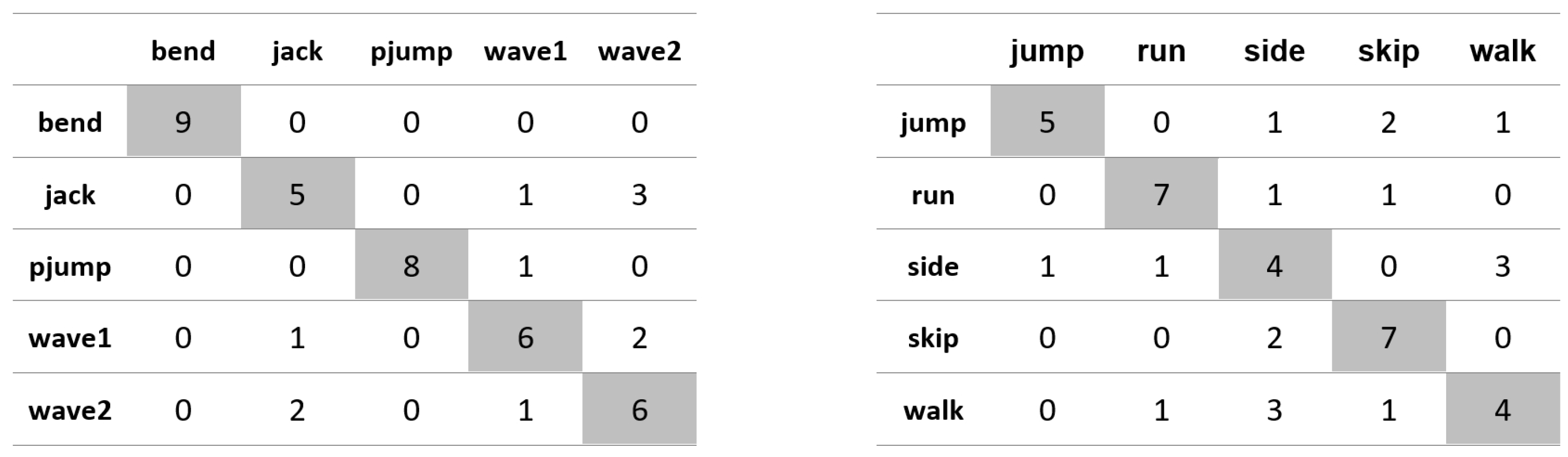
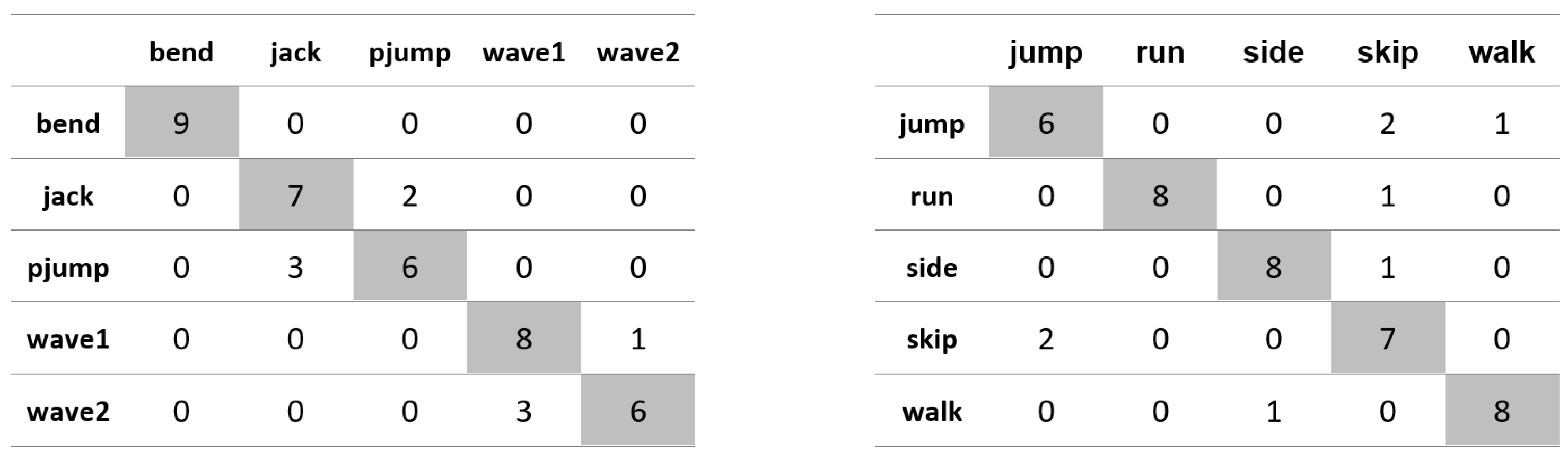
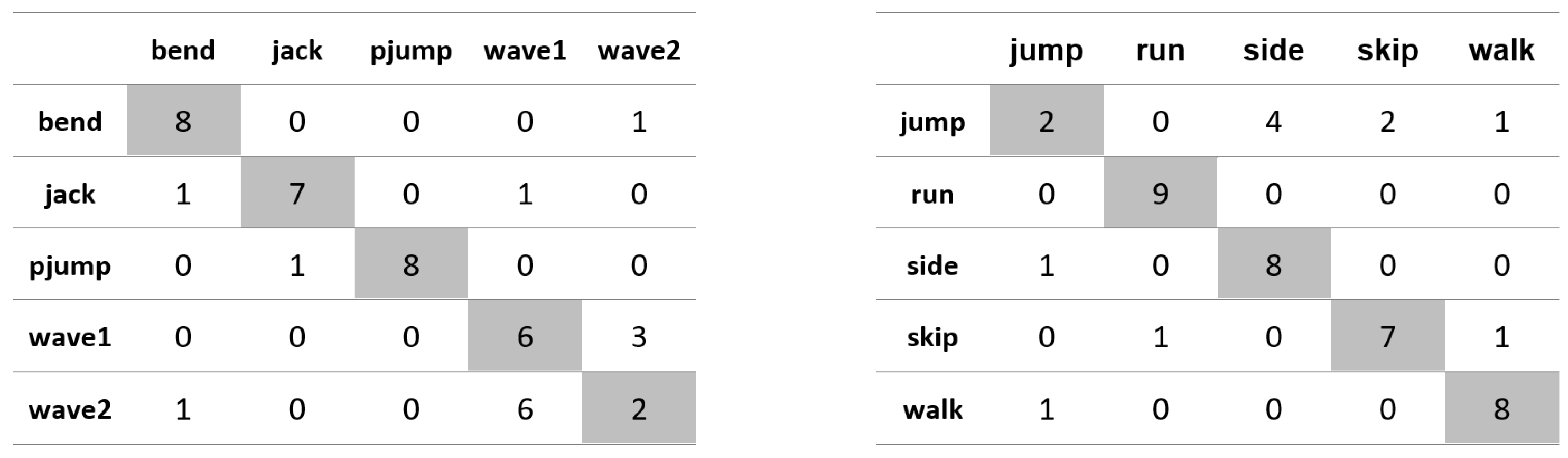
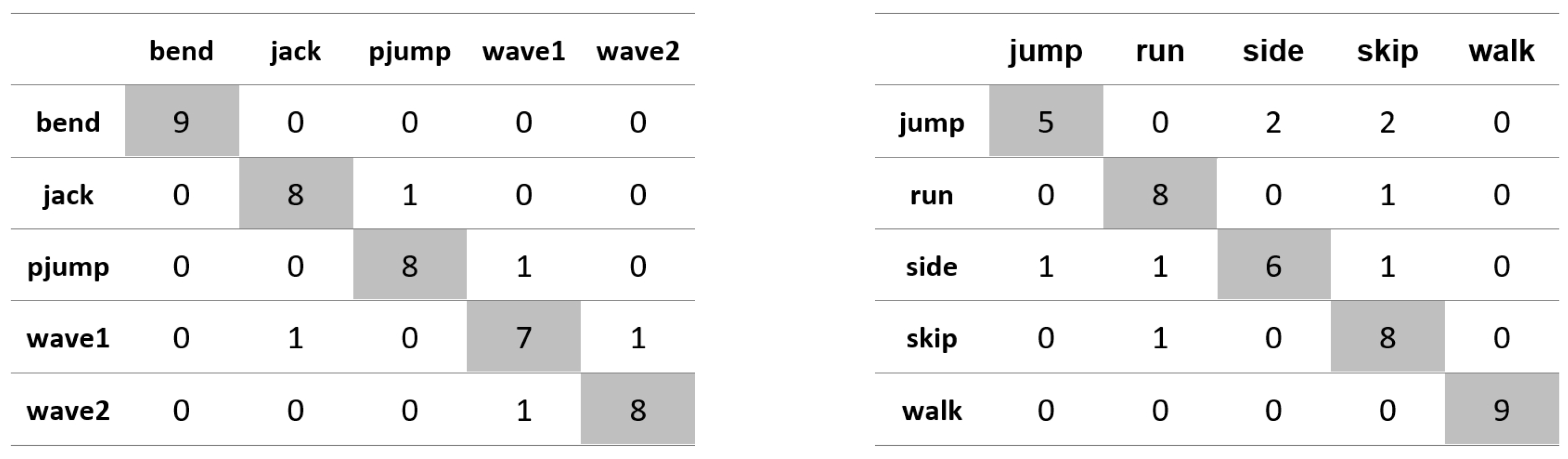
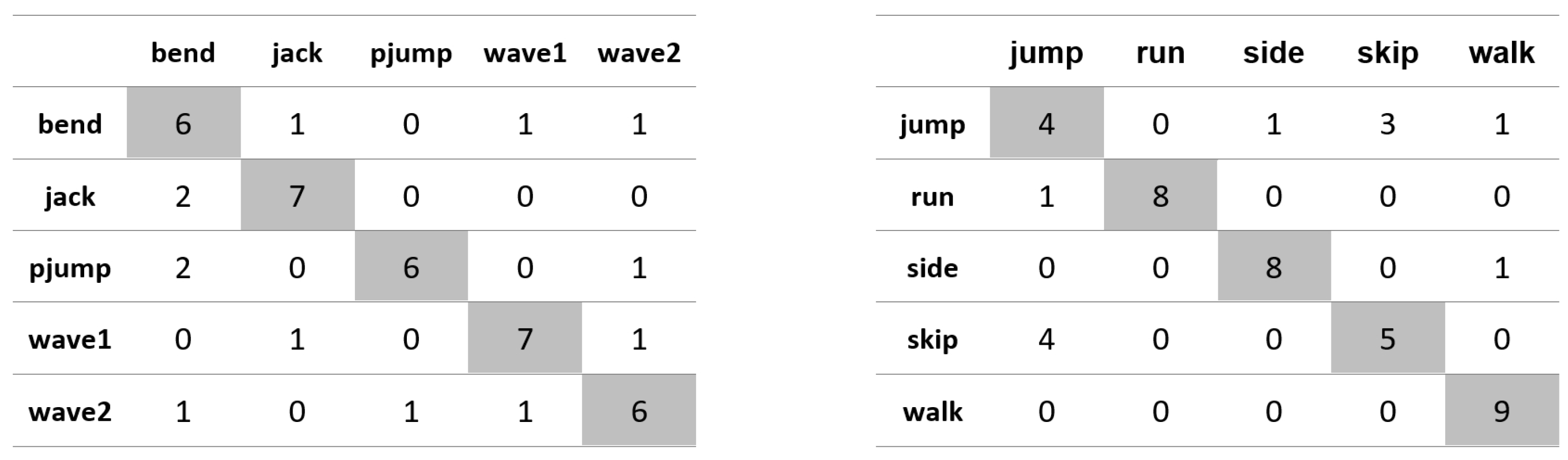
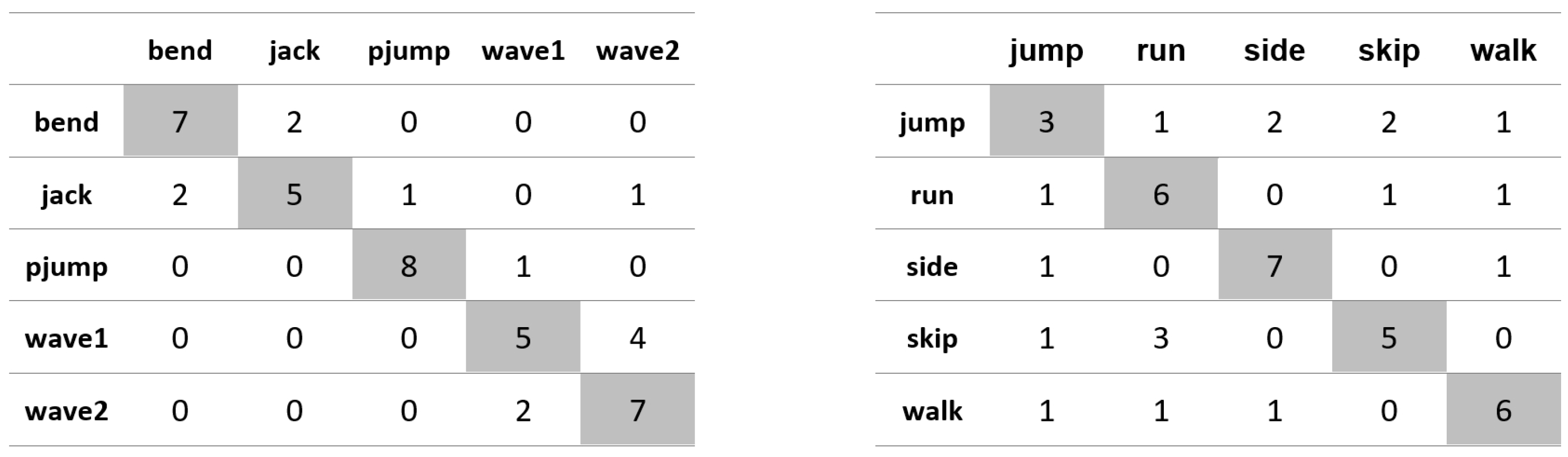
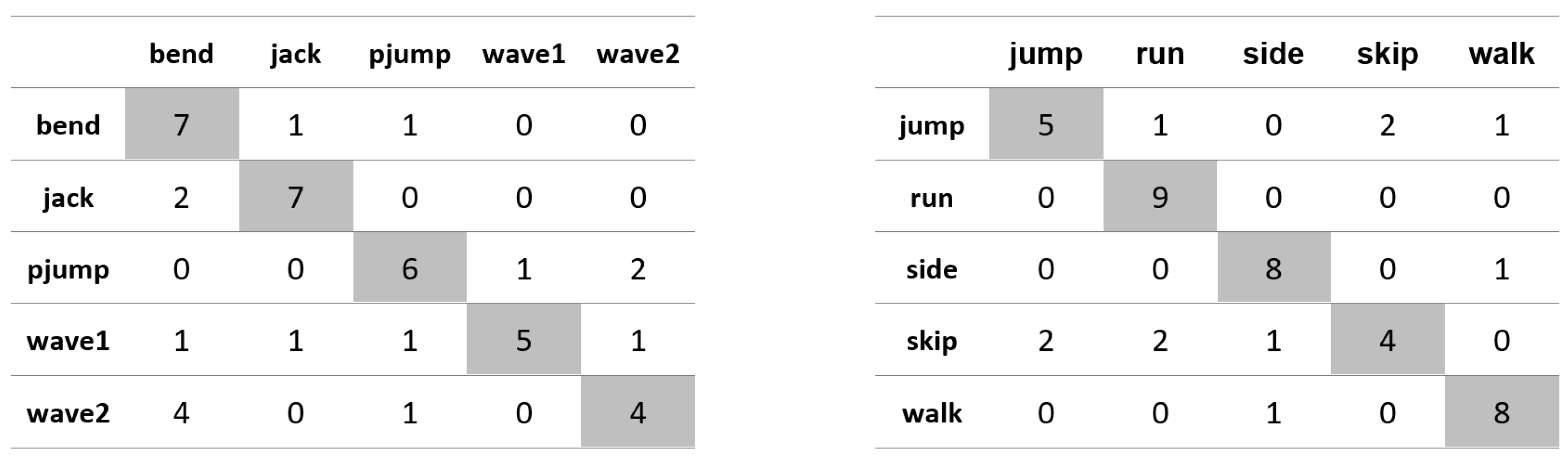
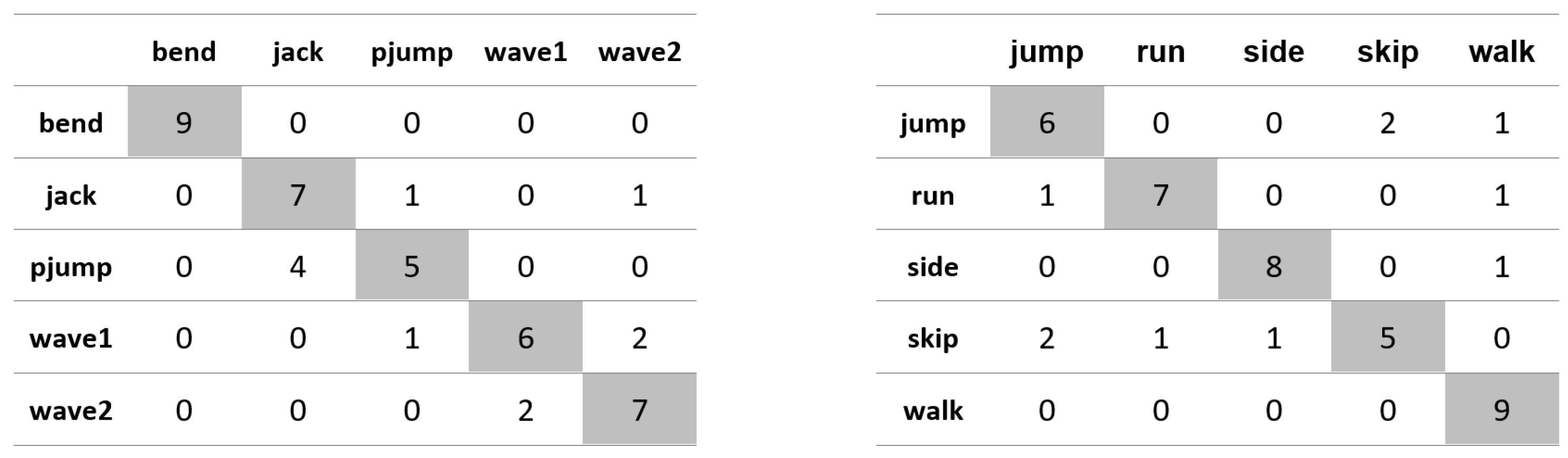
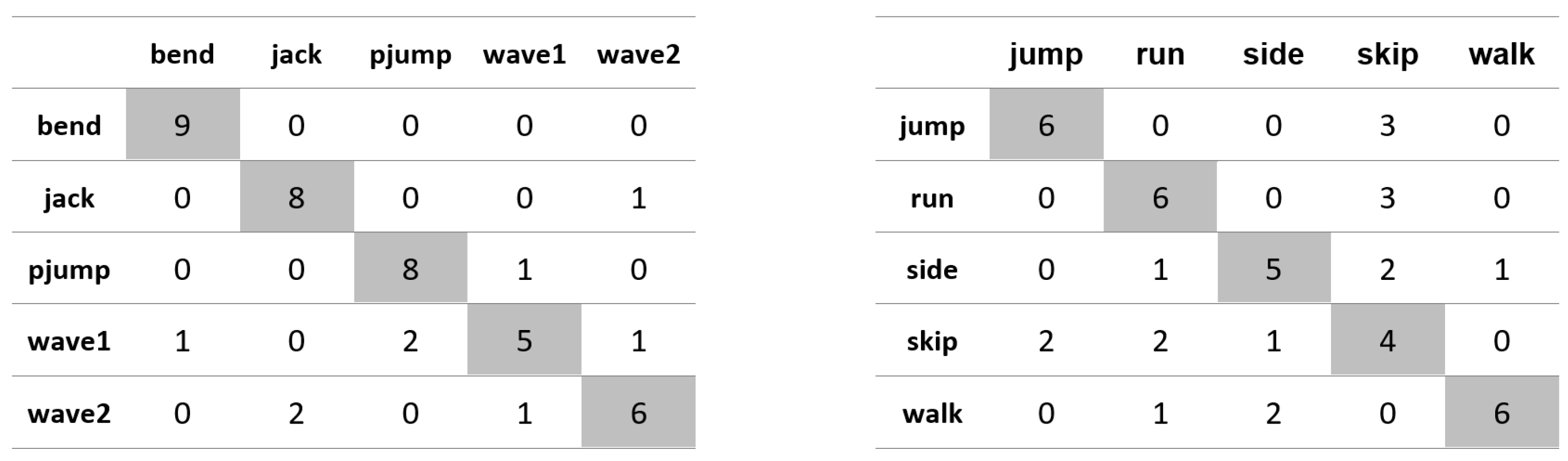
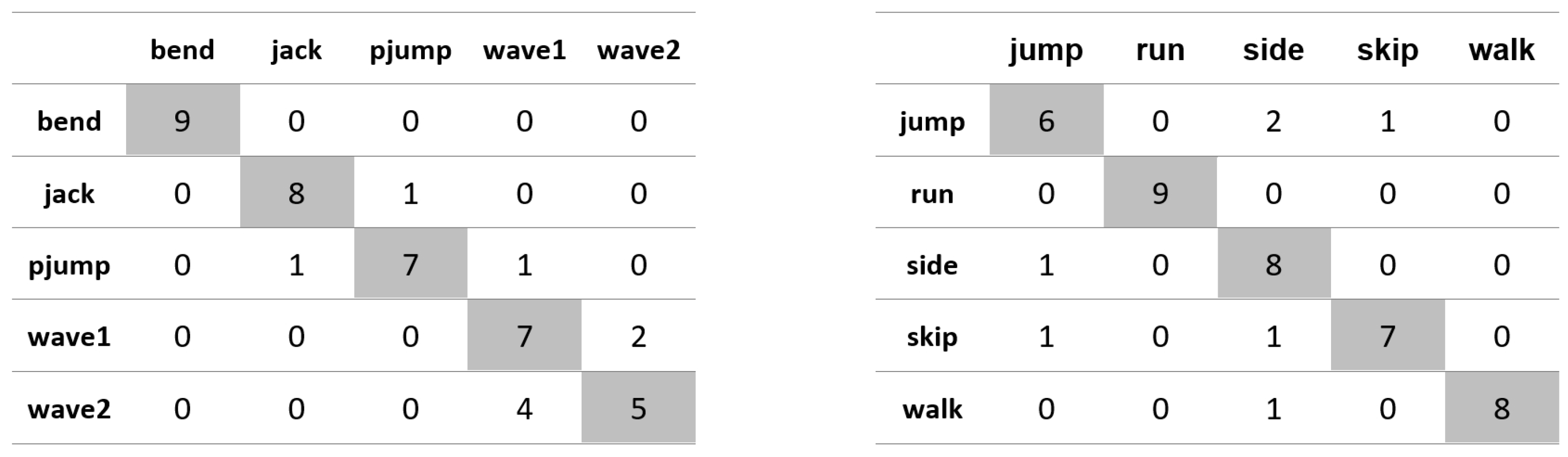
Appendix A. Figures Presenting Confusion Matrices for the Experiments the Results of Which Are Given in Table 1 and Table 2




































References
- Lin, W.; Sun, M.T.; Poovandran, R.; Zhang, Z. Human activity recognition for video surveillance. In Proceedings of the 2008 IEEE International Symposium on Circuits and Systems, Seattle, WA, USA, 18–21 May 2008; pp. 2737–2740. [Google Scholar] [CrossRef] [Green Version]
- Vishwakarma, S.; Agrawal, A. A survey on activity recognition and behavior understanding in video surveillance. Vis. Comput. 2013, 29, 983–1009. [Google Scholar] [CrossRef]
- Duchenne, O.; Laptev, I.; Sivic, J.; Bach, F.; Ponce, J. Automatic annotation of human actions in video. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1491–1498. [Google Scholar] [CrossRef] [Green Version]
- Papadopoulos, G.; Axenopoulos, A.; Daras, P. Real-Time Skeleton-Tracking-Based Human Action Recognition Using Kinect Data. In Proceedings of the International Conference on Multimedia Modeling, Dublin, Ireland, 6–10 January 2014; Volume 8325, pp. 473–483. [Google Scholar] [CrossRef]
- Rautaray, S.; Agrawal, A. Vision based Hand Gesture Recognition for Human Computer Interaction: A Survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- El murabet, A.; Abtoy, A.; Touhafi, A.; Tahiri, A. Ambient Assisted living system’s models and architectures: A survey of the state of the art. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 1–10. [Google Scholar] [CrossRef]
- Schrader, L.; Toro, A.; Konietzny, S.; Rüping, S.; Schäpers, B.; Steinböck, M.; Krewer, C.; Mueller, F.; Guettler, J.; Bock, T. Advanced Sensing and Human Activity Recognition in Early Intervention and Rehabilitation of Elderly People. J. Popul. Ageing 2020, 13, 139–165. [Google Scholar] [CrossRef] [Green Version]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine Recognition of Human Activities: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef] [Green Version]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. A review on vision techniques applied to Human Behaviour Analysis for Ambient-Assisted Living. Expert Syst. Appl. 2012, 39, 10873–10888. [Google Scholar] [CrossRef] [Green Version]
- Chandel, H.; Vatta, S. Occlusion Detection and Handling: A Review. Int. J. Comput. Appl. 2015, 120, 33–38. [Google Scholar] [CrossRef]
- Al-Faris, M.; Chiverton, J.; Ndzi, D.; Ahmed, A.I. A Review on Computer Vision-Based Methods for Human Action Recognition. J. Imaging 2020, 6, 46. [Google Scholar] [CrossRef]
- World Health Organization. Global Recomendations on Physical Acitivity. 2011. Available online: https://www.who.int/dietphysicalactivity/physical-activity-recommendations-18-64years.pdf (accessed on 5 July 2021).
- Wilke, J.; Mohr, L.; Tenforde, A.S.; Edouard, P.; Fossati, C.; González-Gross, M.; Ramirez, C.S.; Laiño, F.; Tan, B.; Pillay, J.D.; et al. Restrictercise! Preferences Regarding Digital Home Training Programs during Confinements Associated with the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2020, 17, 6515. [Google Scholar] [CrossRef]
- Polero, P.; Rebollo-Seco, C.; Adsuar, J.; Perez-Gomez, J.; Rojo Ramos, J.; Manzano-Redondo, F.; Garcia-Gordillo, M.; Carlos-Vivas, J. Physical Activity Recommendations during COVID-19: Narrative Review. Int. J. Environ. Res. Public Health 2020, 18, 65. [Google Scholar] [CrossRef] [PubMed]
- Füzéki, E.; Schröder, J.; Carraro, N.; Merlo, L.; Reer, R.; Groneberg, D.A.; Banzer, W. Physical Activity during the First COVID-19-Related Lockdown in Italy. Int. J. Environ. Res. Public Health 2021, 18, 2511. [Google Scholar] [CrossRef] [PubMed]
- Robertson, M.; Duffy, F.; Newman, E.; Prieto Bravo, C.; Ates, H.H.; Sharpe, H. Exploring changes in body image, eating and exercise during the COVID-19 lockdown: A UK survey. Appetite 2021, 159, 105062. [Google Scholar] [CrossRef]
- Stockwell, S.; Trott, M.; Tully, M.; Shin, J.; Barnett, Y.; Butler, L.; McDermott, D.; Schuch, F.; Smith, L. Changes in physical activity and sedentary behaviours from before to during the COVID-19 pandemic lockdown: A systematic review. BMJ Open Sport Exerc. Med. 2021, 7, e000960. [Google Scholar] [CrossRef] [PubMed]
- Wolf, S.; Seiffer, B.; Zeibig, J.M.; Welkerling, J.; Brokmeier, L.; Atrott, B.; Ehring, T.; Schuch, F. Is Physical Activity Associated with Less Depression and Anxiety During the COVID-19 Pandemic? A Rapid Systematic Review. Sport. Med. 2021, 51, 1771–1783. [Google Scholar] [CrossRef]
- World Health Organization. #HealthyAtHome—Physical Activity. 2021. Available online: https://www.who.int/news-room/campaigns/connecting-the-world-to-combat-coronavirus/healthyathome/healthyathome—physical-activity (accessed on 5 July 2021).
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions As Space-Time Shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402. [Google Scholar] [CrossRef] [Green Version]
- Bobick, A.; Davis, J. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef] [Green Version]
- Eweiwi, A.; Cheema, M.S.; Thurau, C.; Bauckhage, C. Temporal key poses for human action recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 1310–1317. [Google Scholar] [CrossRef]
- Ahad, M.A.R.; Islam, N.; Jahan, I. Action recognition based on binary patterns of action-history and histogram of oriented gradient. J. Multimodal User Interfaces 2016, 10, 335–344. [Google Scholar] [CrossRef]
- Vishwakarma, D.; Dhiman, A.; Maheshwari, R.; Kapoor, R. Human Motion Analysis by Fusion of Silhouette Orientation and Shape Features. Procedia Comput. Sci. 2015, 57, 438–447. [Google Scholar] [CrossRef] [Green Version]
- Al-Ali, S.; Milanova, M.; Al-Rizzo, H.; Fox, V.L. Human Action Recognition: Contour-Based and Silhouette-Based Approaches. In Computer Vision in Control Systems-2: Innovations in Practice; Favorskaya, M.N., Jain, L.C., Eds.; Springer International Publishing: Cham, Switzerlands, 2015; pp. 11–47. [Google Scholar] [CrossRef]
- Junejo, I.N.; Junejo, K.N.; Aghbari, Z.A. Silhouette-based human action recognition using SAX-Shapes. Vis. Comput. 2014, 30, 259–269. [Google Scholar] [CrossRef]
- Baysal, S.; Kurt, M.C.; Duygulu, P. Recognizing Human Actions Using Key Poses. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1727–1730. [Google Scholar] [CrossRef]
- Chaaraoui, A.; Flórez-Revuelta, F. A Low-Dimensional Radial Silhouette-Based Feature for Fast Human Action Recognition Fusing Multiple Views. Int. Sch. Res. Not. 2014, 2014, 547069. [Google Scholar] [CrossRef] [PubMed]
- Sargano, A.B.; Angelov, P.; Habib, Z. Human Action Recognition from Multiple Views Based on View-Invariant Feature Descriptor Using Support Vector Machines. Appl. Sci. 2016, 6, 309. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, C.H.; Huang, P.; Tang, M.D. Human Action Recognition Using Silhouette Histogram. In Proceedings of the 34th Australasian Computer Science Conference, Perth, Australia, 17–20 January 2011; Volume 113, pp. 11–16. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-based human activity recognition: A survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar] [CrossRef] [Green Version]
- Abe, T.; Fukushi, M.; Ueda, D. Primitive Human Action Recognition Based on Partitioned Silhouette Block Matching. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Li, B., Porikli, F., Zordan, V., Klosowski, J., Coquillart, S., Luo, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 308–317. [Google Scholar] [CrossRef]
- Jargalsaikhan, I.; Direkoglu, C.; Little, S.; O’Connor, N.E. An Evaluation of Local Action Descriptors for Human Action Classification in the Presence of Occlusion. In MultiMedia Modeling; Gurrin, C., Hopfgartner, F., Hurst, W., Johansen, H., Lee, H., O’Connor, N., Eds.; Springer International Publishing: Cham, Switzerlands, 2014; pp. 56–67. [Google Scholar] [CrossRef] [Green Version]
- Gościewska, K.; Frejlichowski, D. The Analysis of Shape Features for the Purpose of Exercise Types Classification Using Silhouette Sequences. Appl. Sci. 2020, 10, 6728. [Google Scholar] [CrossRef]
- Thaxter-Nesbeth, K.; Facey, A. Exercise for Healthy, Active Ageing: A Physiological Perspective and Review of International Recommendations. West Indian Med. J. 2018, 67, 351–356. [Google Scholar] [CrossRef]
- Yang, M.; Kpalma, K.; Ronsin, J. A Survey of Shape Feature Extraction Techniques. In Pattern Recognition Techniques, Technology and Applications; Yin, P.-Y., Ed.; I-Tech: Vienna, Austria, 2008; pp. 43–90. [Google Scholar]
- Rosin, P. Computing global shape measures. In Handbook of Pattern Recognition and Computer Vision; World Scientific: Singapore, 2005; pp. 177–196. [Google Scholar] [CrossRef] [Green Version]
- Brunelli, R.; Messelodi, S. Robust estimation of correlation with applications to computer vision. Pattern Recognit. 1995, 28, 833–841. [Google Scholar] [CrossRef]
- Kpalma, K.; Ronsin, J. An Overview of Advances of Pattern Recognition Systems in Computer Vision. In Vision Systems; Obinata, G., Dutta, A., Eds.; IntechOpen: Rijeka, Croatia, 2007. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Lu, G. A comparative Study of Fourier Descriptors for Shape Representation and Retrieval. In Proceedings of the 5th Asian Conference on Computer Vision, Melbourne, Australia, 22–25 January 2002; pp. 646–651. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shape Descriptor | Actions Performed in Place | Actions with Changing Location of a Silhouette | ||
|---|---|---|---|---|
| EU | C1 | EU | C1 | |
| Rectangularity | 68.89% | 71.11% | 68.89% | 73.33% |
| (68) | (110) | (79) | (84) | |
| Elongation | 91.11% | 91.11% | 68.89% | 64.44% |
| (57) | (55) | (79) | (39) | |
| Eccentricity | 71.11% | 75.56% | 64.44% | 60.00% |
| (88) | (108) | (37) | (38) | |
| Width | 82.22% | 84.44% | 55.56% | 60.00% |
| (54) | (54) | (17) | (57) | |
| Length | 62.22% | 62.22% | 64.44% | 60.00% |
| (41) | (18) | (36) | (65) | |
| Area | 68.89% | 71.11% | 62.22% | 64.44% |
| (39) | (106) | (66) | (70) | |
| LongerMBR | 68.89% | 71.11% | 66.67% | 66.67% |
| (41) | (41) | (68) | (89) | |
| ShorterMBR | 88.89% | 84.44% | 71.11% | 73.33% |
| (55) | (56) | (30) | (71) | |
| Perimeter | 77.78% | 80.00% | 66.67% | 62.22% |
| (52) | (52) | (40) | (39) | |
| Shape Descriptor | Actions Performed in Place | Actions with Changing Location of a Silhouette | ||
|---|---|---|---|---|
| EU | C1 | EU | C1 | |
| Rectangularity | 77.78% | 75.56% | 82.22% | 84.44% |
| (55) | (50) | (28) | (46) | |
| Elongation | 82.22% | 88.89% | 82.22% | 80.00% |
| (47) | (51) | (27) | (28) | |
| Eccentricity | 68.89% | 71.11% | 73.33% | 77.78% |
| (32) | (34) | (41) | (168) | |
| Width | 73.33% | 71.11% | 60.00% | 60.00% |
| (53) | (81) | (39) | (18) | |
| Length | 55.56% | 64.44% | 75.56% | 75.56% |
| (38) | (42) | (40) | (68) | |
| Area | 68.89% | 75.56% | 84.44% | 77.78% |
| (38) | (83) | (70) | (38) | |
| LongerMBR | 75.56% | 80.00% | 60.00% | 60.00% |
| (53) | (58) | (27) | (40) | |
| ShorterMBR | 80.00% | 80.00% | 82.22% | 84.44% |
| (124) | (65) | (18) | (69) | |
| Perimeter | 68.89% | 68.89% | 75.56% | 75.56% |
| (99) | (56) | (93) | (75) | |
| Shape Descriptor | Actions Performed in Place | Actions with Changing Location of a Silhouette | ||
|---|---|---|---|---|
| EU | C1 | EU | C1 | |
| ‘Lower-occlusion’ | Elongation | Elongation | ShorterMBR | ShorterMBR |
| database | 91.11% (57) | 91.11% (55) | 71.11% (30) | 73.33% (71) |
| ‘Upper-occlusion’ | Elongation | Elongation | Area | Rectangularity |
| database | 82.22% (47) | 88.89% (51) | 84.44% (70) | 84.44% (46) |
| Database | ShorterMBR | Perimeter | Area | Area |
| without occlusion | 86.67% (56) | 91.11% (51) | 86.67% (31) | 84.44% (33) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gościewska, K.; Frejlichowski, D. Action Classification for Partially Occluded Silhouettes by Means of Shape and Action Descriptors. Appl. Sci. 2021, 11, 8633. https://doi.org/10.3390/app11188633
Gościewska K, Frejlichowski D. Action Classification for Partially Occluded Silhouettes by Means of Shape and Action Descriptors. Applied Sciences. 2021; 11(18):8633. https://doi.org/10.3390/app11188633
Chicago/Turabian StyleGościewska, Katarzyna, and Dariusz Frejlichowski. 2021. "Action Classification for Partially Occluded Silhouettes by Means of Shape and Action Descriptors" Applied Sciences 11, no. 18: 8633. https://doi.org/10.3390/app11188633