For illustrative purposes, we first present a simple example of calculating the association-based dissimilarities between two values in a categorical variable using an artificial dataset. Secondly, we demonstrate the development of the mutual
k-nearest neighbor graph with various
k values. Then, finally, we conducted experiments to study the characteristics of the proposed method (CGD) and compared it with other conventional categorical distance measures in the literature: Gower distance (GD) [
5], association-based dissimilarity (AD) [
8], and a variant of the geodesic distance using Gower distance (hereafter, Gower-based geodesic distance (GGD)).
4.2. Mutual k-Nearest Neighbor Graph with Various k Values
The following example demonstrates the development of the mutual
k-nearest neighbor graph with various
k values.
Table 3 shows a fragment of the Mushroom dataset from UCI Machine Learning Repository (
http://archive.ics.uci.edu, accessed on 5 May 2021). Let us assume that there is a dataset with 12 observations, which consist of five categorical variables; Cap-shape, Cap-surface, Cap-color, Bruises, and Odor.
Figure 1,
Figure 2 and
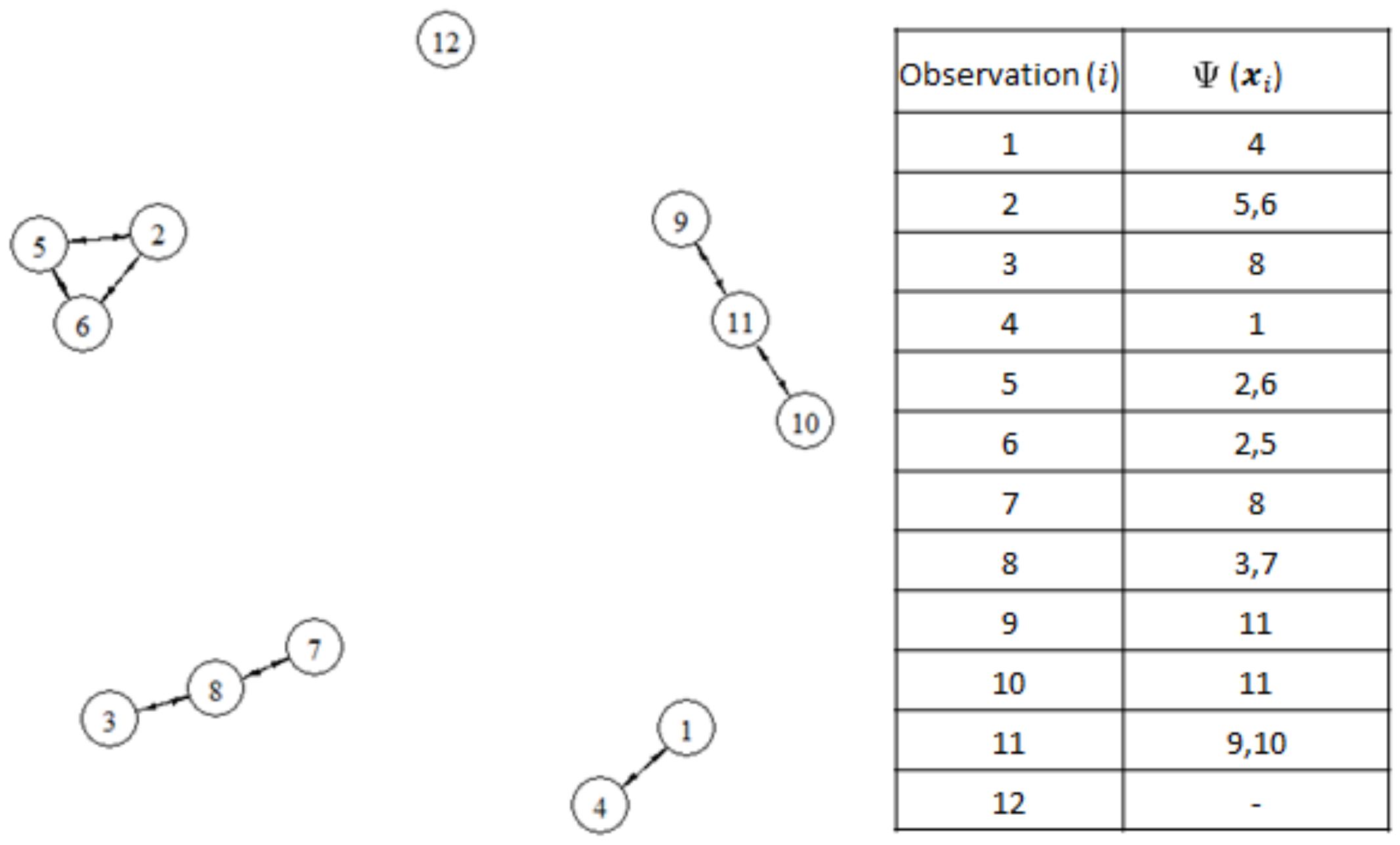
Figure 3 illustrate the results of mutual neighborhood sets and the corresponding mutual neighborhood graphs when
k is 3, 6, or 9, respectively. The neighborhood links between nodes (observations) are represented by the arrows. For example, no node belongs to the 3-mutual nearest neighbors of node
in
Figure 1. The 6-mutual nearest neighbors of node
are node
,
,
, and
in
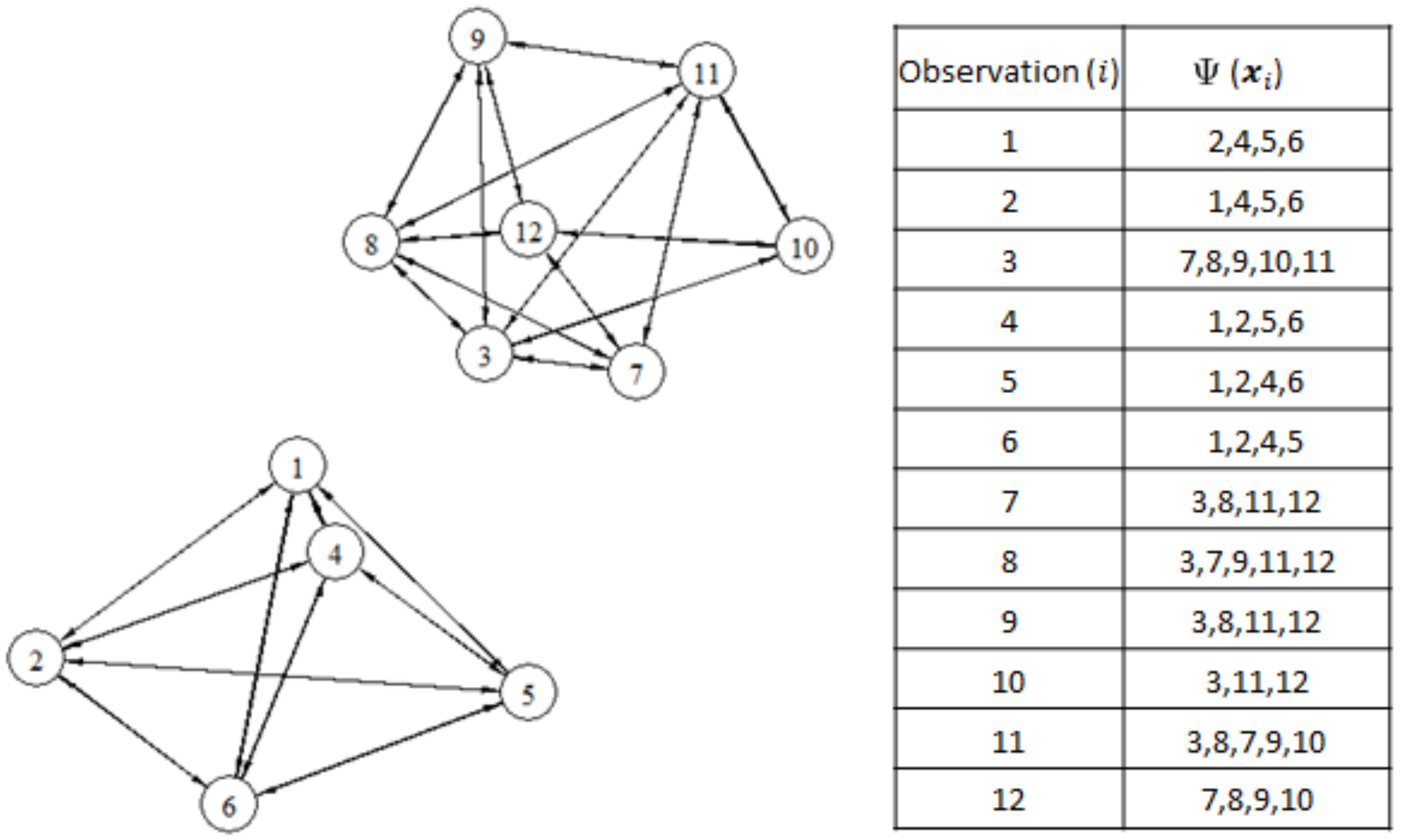
Figure 2. The 9-mutual nearest neighbors of node
are nodes
,
,
,
,
,
,
, and
in
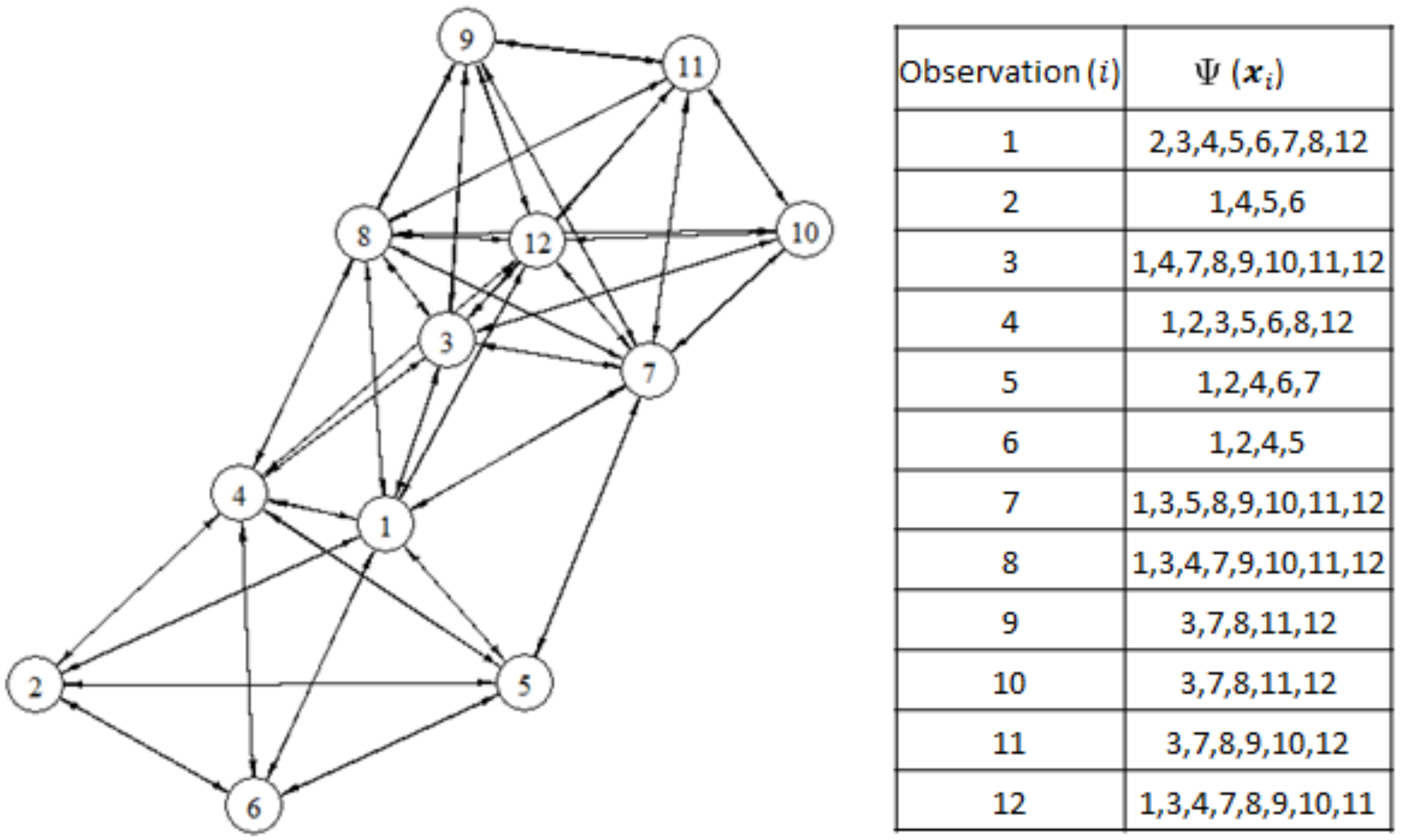
Figure 3. Thus, the structure of the graph depends on the parameter
k. When
k increases, the size of the mutual neighborhood set of a node increases. As mentioned previously, the mutual
k-nearest neighbor graph itself can produce clusters, and the number of clusters depends on the parameter
k. However, if we intend to produce a larger number of clusters, the proposed context-based geodesic dissimilarity (CGD) measure between the objects in a graph is still required.
4.3. Comparative Study Using Real-Life Datasets
In our experiments, a clustering algorithm is applied to four benchmark datasets: (1) Breast cancer, (2) Soybean, (3) Lymphography, and (4) Mushroom, which were from the UCI Machine Learning Repository [
35]. All datasets, except the Lymphography dataset, have missing values. In this study, we simply eliminate the observations with missing values. Furthermore, the Lymphography dataset is originally composed of eighteen variables in total, including three continuous variables and fifteen categorical (nominal) variables so that three of these continuous variables are forcibly discretized into categorical (ordinal) variables.
Table 4 summarizes these datasets, including the results of the dependency analysis. Before we conducted the experiments of applying a clustering algorithm to those four benchmark datasets, we performed a dependency analysis in the same manner in [
8] to find how significantly correlated several categorical variables are. For each dataset
x, we evaluate the categorical data dependency using the dependency factor
, which is the proportion of the number of dependent categorical variable pairs in the total number of categorical variable pairs. The dependency factor is calculated by the following equation
where
p is the number of variables. To test the dependency of two categorical variables, we used the chi-square statistic with a significance level of 0.05. The dependency factor has a value of 0–1, where 0 indicates that all categorical variable pairs are independent, and 1 indicates that all categorical variable pairs are dependent at the significance level of 0.05. Most of the categorical variables in the selected real-life datasets are correlated, as shown in
Table 4. We believe that these real-life datasets can adequately illustrate the usefulness of the proposed method.
For clustering, we used the Partition Around Medoid (PAM) clustering algorithm [
36] to study the performance of the proposed method.
The PAM algorithm is the most well-known heuristic solution for the
k-medoids clustering [
14,
37]. The
k-medoids clustering is more robust to outliers than the
k-means clustering algorithms [
38] and can work using a dissimilarity matrix, which is defined by any dissimilarity measure (our proposed method provides only a dissimilarity matrix, not the node (observation) coordinates). Hence, the PAM algorithm is used to compare our proposed method with the existing ones.
A brief explanation of the PAM can be provided as follows; given
K initial medoids that create
K clusters, each node becomes assigned to one of the
K medoids that is nearest to the node. A medoid can be defined as the node of a cluster whose average dissimilarity to all nodes in the cluster is minimal. The PAM minimizes the objective function by iteratively swapping all non-medoid points and medoids until convergence [
36]. The objective function of the PAM is to minimize the sum of the dissimilarities from a node to its cluster medoids.
To quantify the PAM clustering performance, the clustering validity measure is required. Based on the available knowledge about the true class membership of the dataset, the whole clustering validity measures can be divided into two sets; internal and external validity measures [
39]. Internal validity measures only exploit the distribution of the dataset. On the other hand, external validity measures assume some external information, such as class membership information. It is obvious that external validity measures give less vague results than the internal validity measures as the association of the cluster points with the class membership is assumed to be known in the case of external validity measures. In our study, since the main contribution that we intend to make is to investigate the potential of using our proposed dissimilarity measure, we assume that the class information and class correspondence of the observations are already known, and the number of true clusters
K is known to be equal to the number of true classes. In [
39], they compared five external validity measures (namely Rand index, Jaccard index, Folkes–Mallows index, Rogers–Tanimoto index and Kulczynski index) to observe the performance of different clustering validity measures as the number of attributes increased for the same algorithm when others such as the number of instances and the number of classes were almost invariant. As a conclusion, the external validity measures were all consistent [
39]. The authors reported that all of the external validity measures produced different values but the same ranks. In the same manner as in [
39], we applied all five external validity measures (Rand index, Jaccard index, Folkes–Mallows index, Rogers–Tanimoto index and Kulczynski index) for our comparison study, as shown in Table 6. The results were consistent with [
39], that is, the ranks of each dissimilarity measure were identical no matter which external validity measure is used. Therefore, here we explain only the Rand index among the external validity measures, which is the most popular external validity measure.
The Rand index (RI) [
40] has been widely used to calculate the clustering performance [
41,
42,
43]. The RI is basically a measure of the similarity between two clusterings results. Let us assume that two clustering results share a cluster membership; then the similarity between two clustering results is calculated as follows
where
a is the number of pairs of nodes with the common cluster memberships,
b is the number of pairs of nodes with nonidentical cluster memberships, and
n is the number of nodes. The RI has a value of 0–1, where 0 implies that the two results do not agree on any pair of clustering memberships, and 1 indicates that the two clustering memberships are exactly identical. If the dataset has a true cluster membership, this true cluster membership becomes a reference membership. Therefore, the RI evaluates the agreement between the true cluster membership and the PAM clustering results [
44]. A large RI indicates that the true cluster membership can be correctly recovered by the PAM clustering results.
To apply the PAM with a geodesic distance framework such as the GGD and the proposed CGD, two parameters must be predetermined, such as the parameter
k for the mutual
k-nearest neighbor graph construction and
K for the number of clusters. As mentioned earlier, we assumed that the number of true clusters
K is known to be equal to the number of true classes. However, there is no concrete guideline for selecting the optimal parameters
k. Hence, we attempted to heuristically decide only the parameter
k, in a similar manner used in Yu and Kim [
14]. They varied the values of
k from 3 to 30 and determined the parameter
k that yielded the best performance. Thus, we focus on only determining a proper
k that yields the largest RI while varying the values of
k. In our study, the RI was calculated by changing
k from 3 to 60. The smallest
k obtained from the largest RI is summarized in
Table 5.
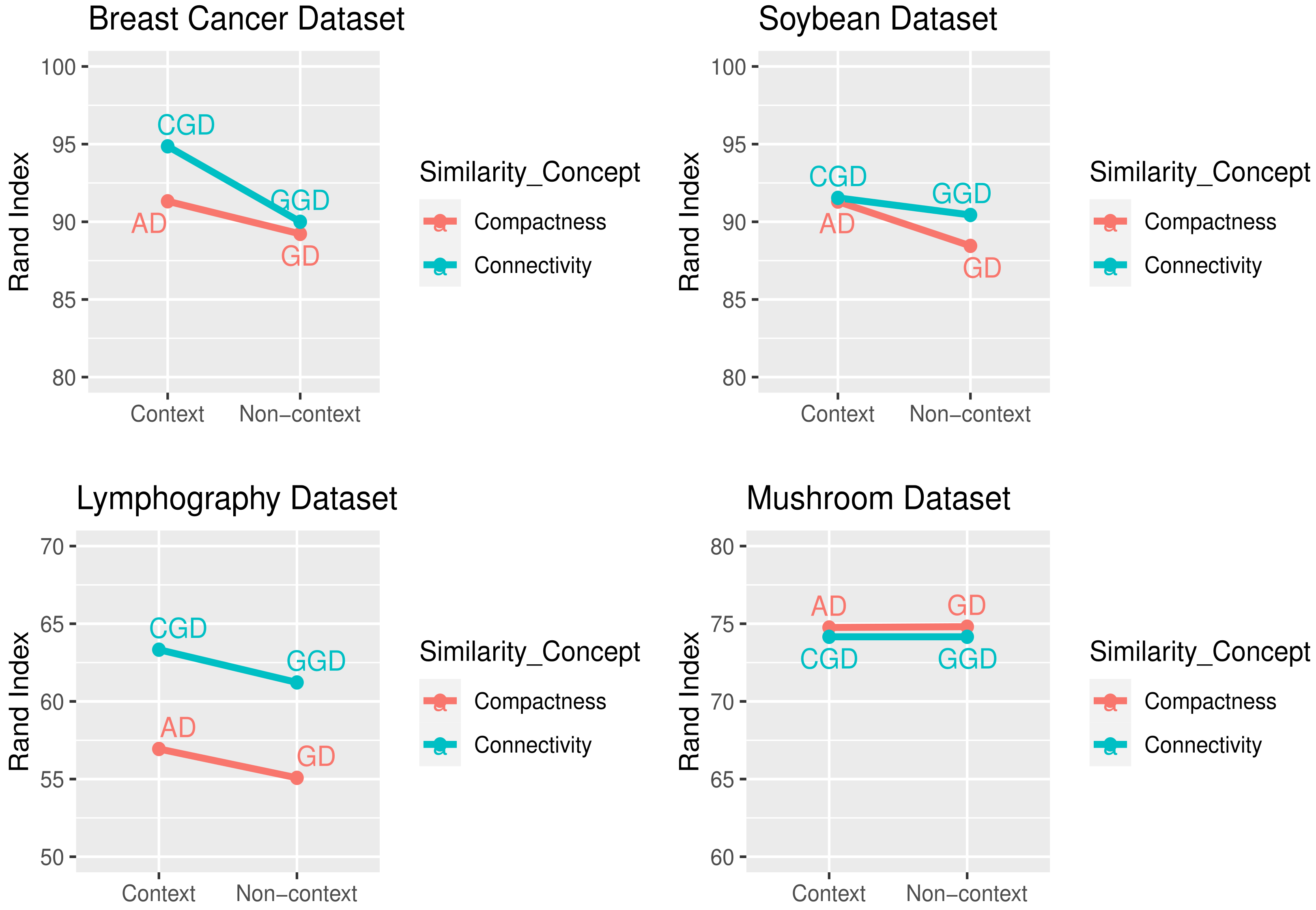
Table 6 shows the comparative results of the PAM algorithms in terms of five different external validity measures using various distance/dissimilarity measures (GD, AD, GGD, and CGD). The results shown in
Table 6 will be discussed in the following section.








{kind=link}
{kind=link}
{kind=link}
{kind=link}