
Application of Machine Learning Methods for Pallet Loading Problem


Abstract
:1. Introduction
2. Literature Review
3. Methodology
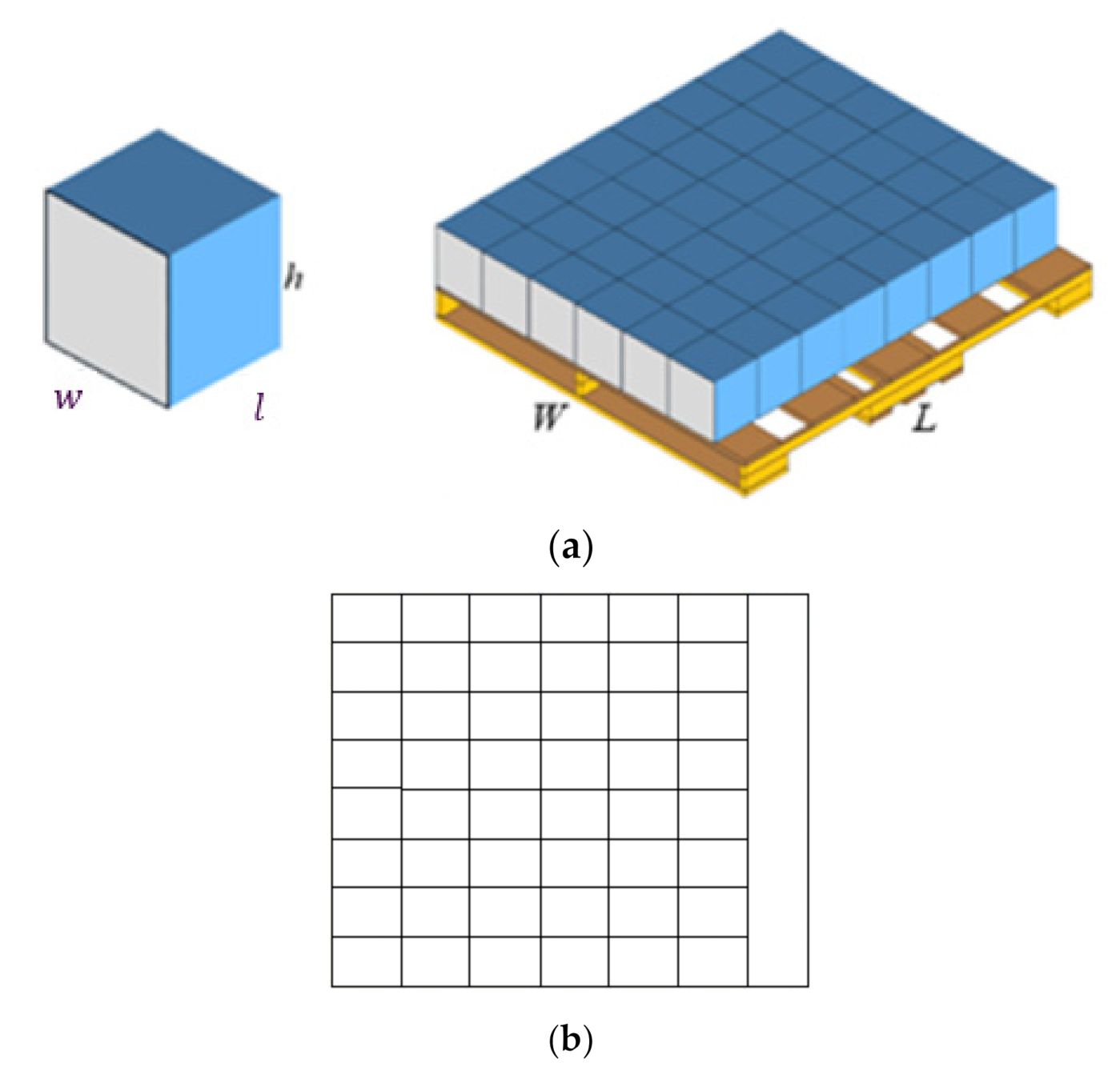
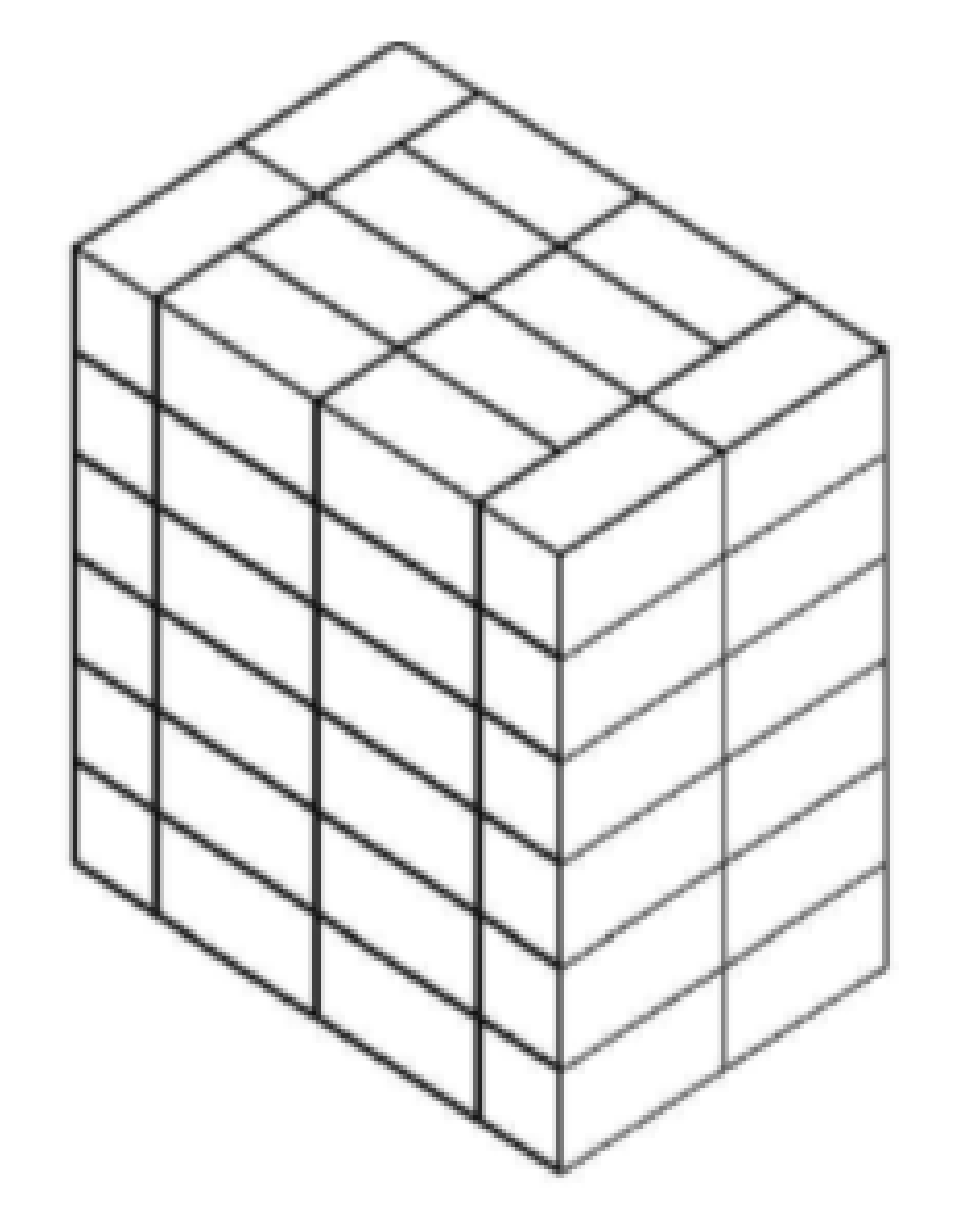
3.1. Number of the Boxes Loaded onto the Pallet
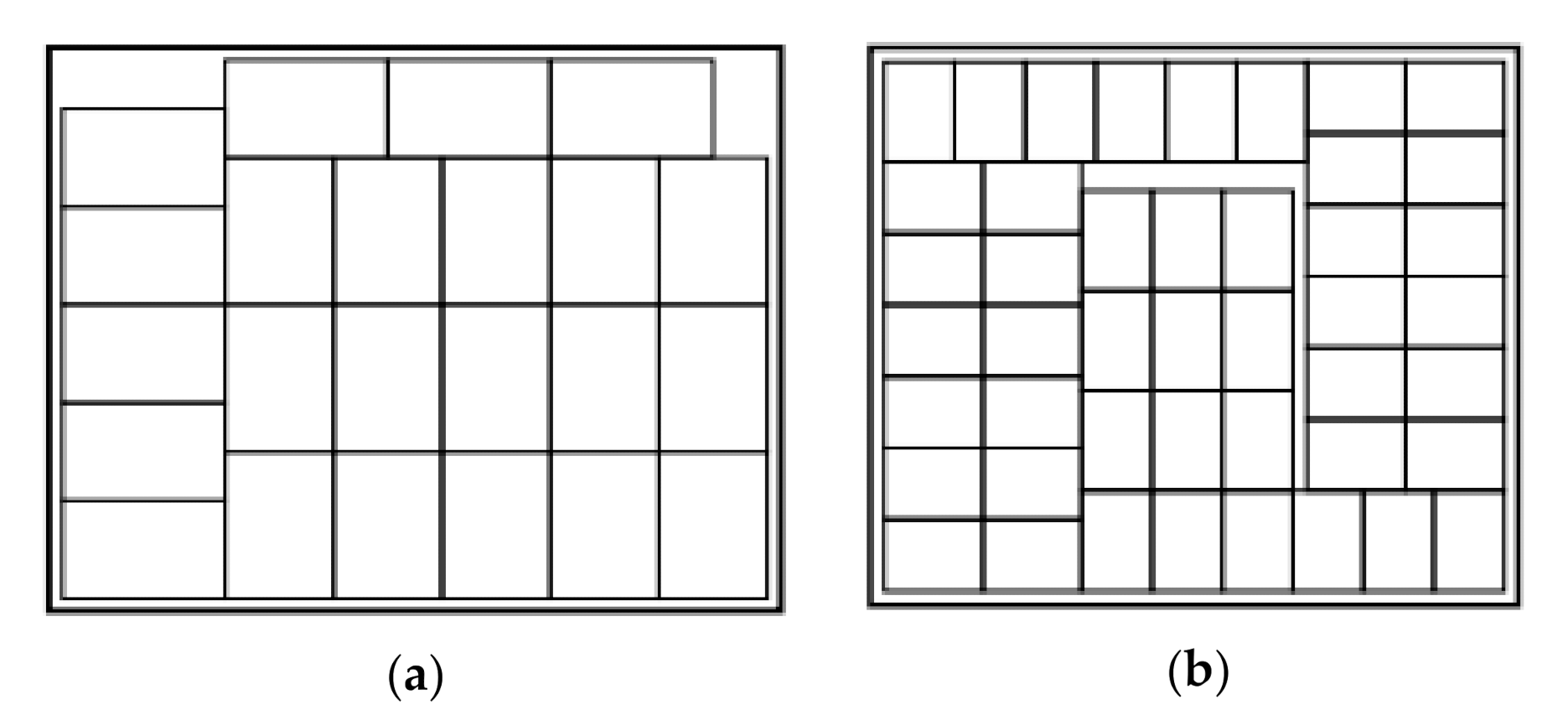
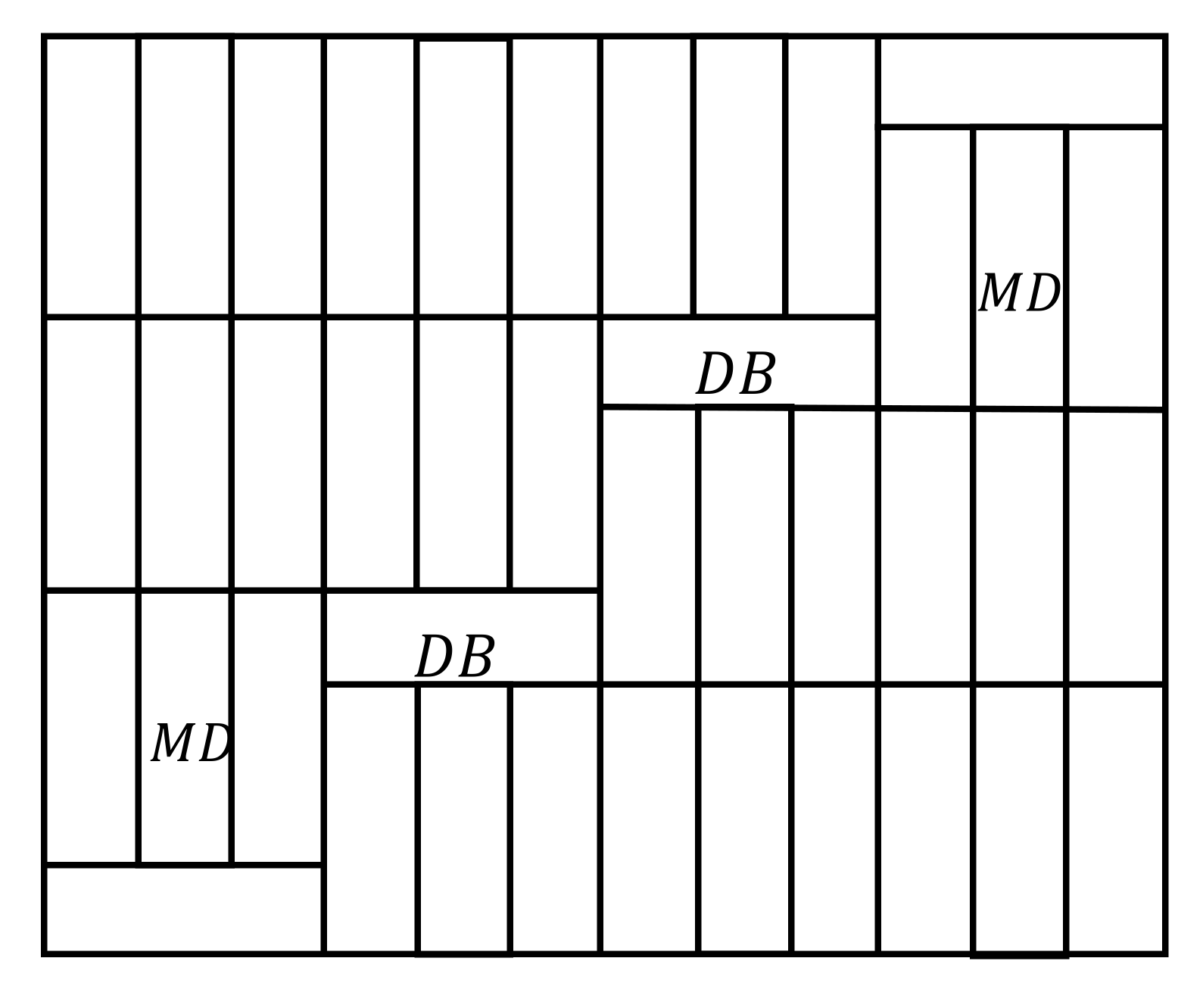
3.1.1. Phase I: Determining the Box Arrangement on a Horizontal Layer
3.1.2. Phase II: Computing the Number of Horizontal Layers on the Basis of the
- NHL: The maximum number of horizontal layers
- BDPB: Box’s dimension perpendicular to the base
3.2. Machine Learning Methods for Classification
3.3. Evaluation Metrics
- Matthews Correlation Coefficient for multi-class classification:
- Cohen’s Kappa for multi-class cases:
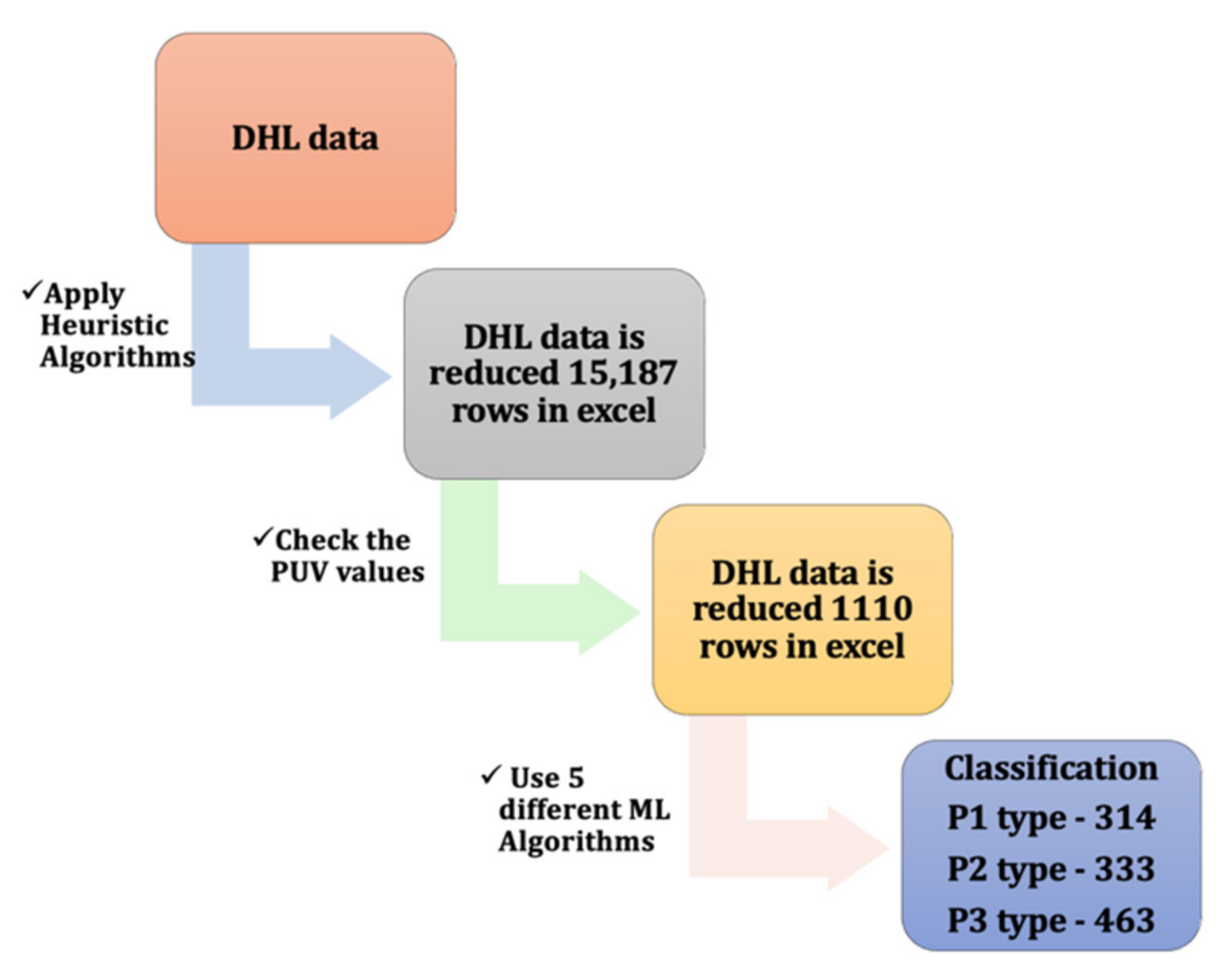
4. Application and Dataset Description
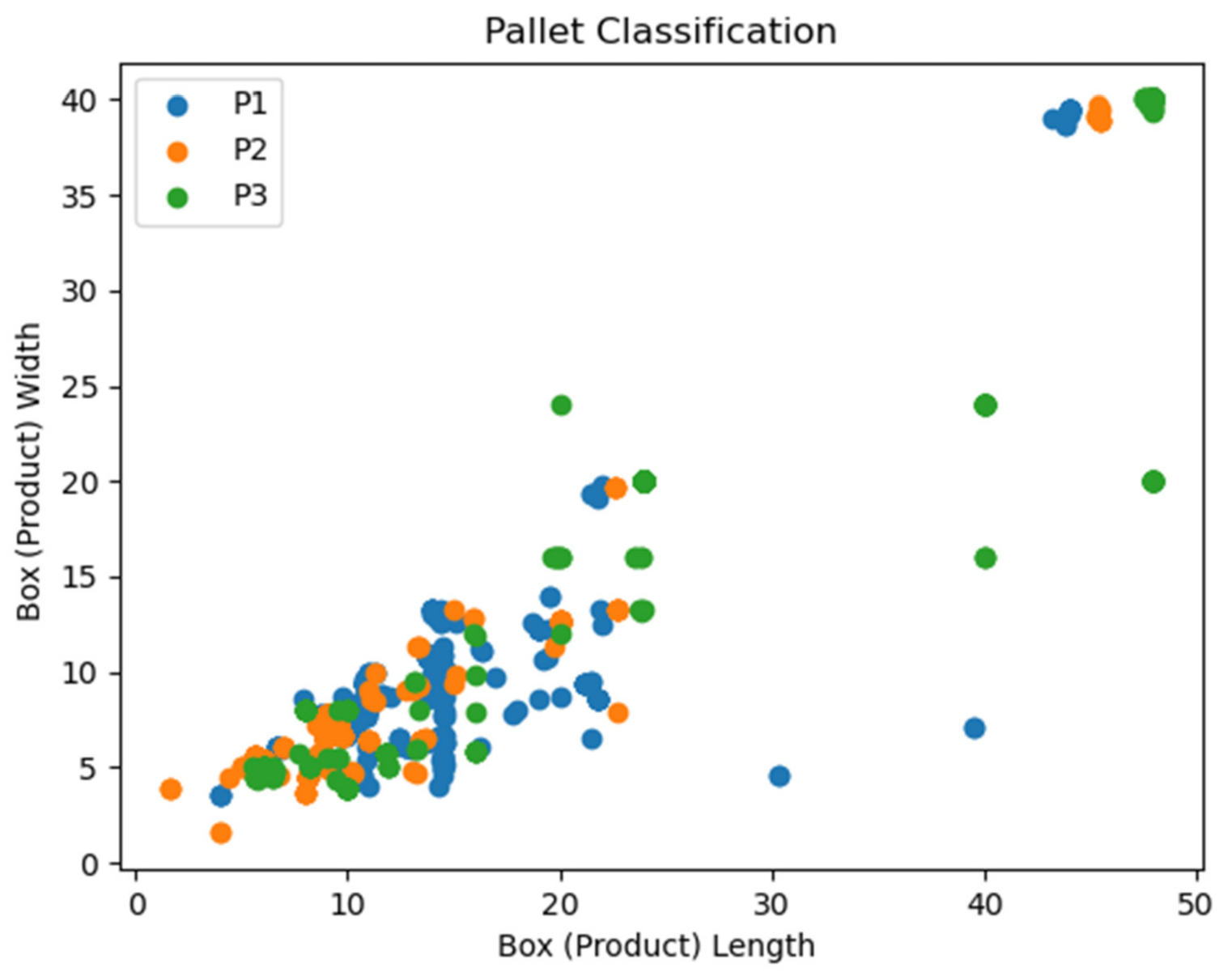
4.1. Dataset
4.2. Implementation Details
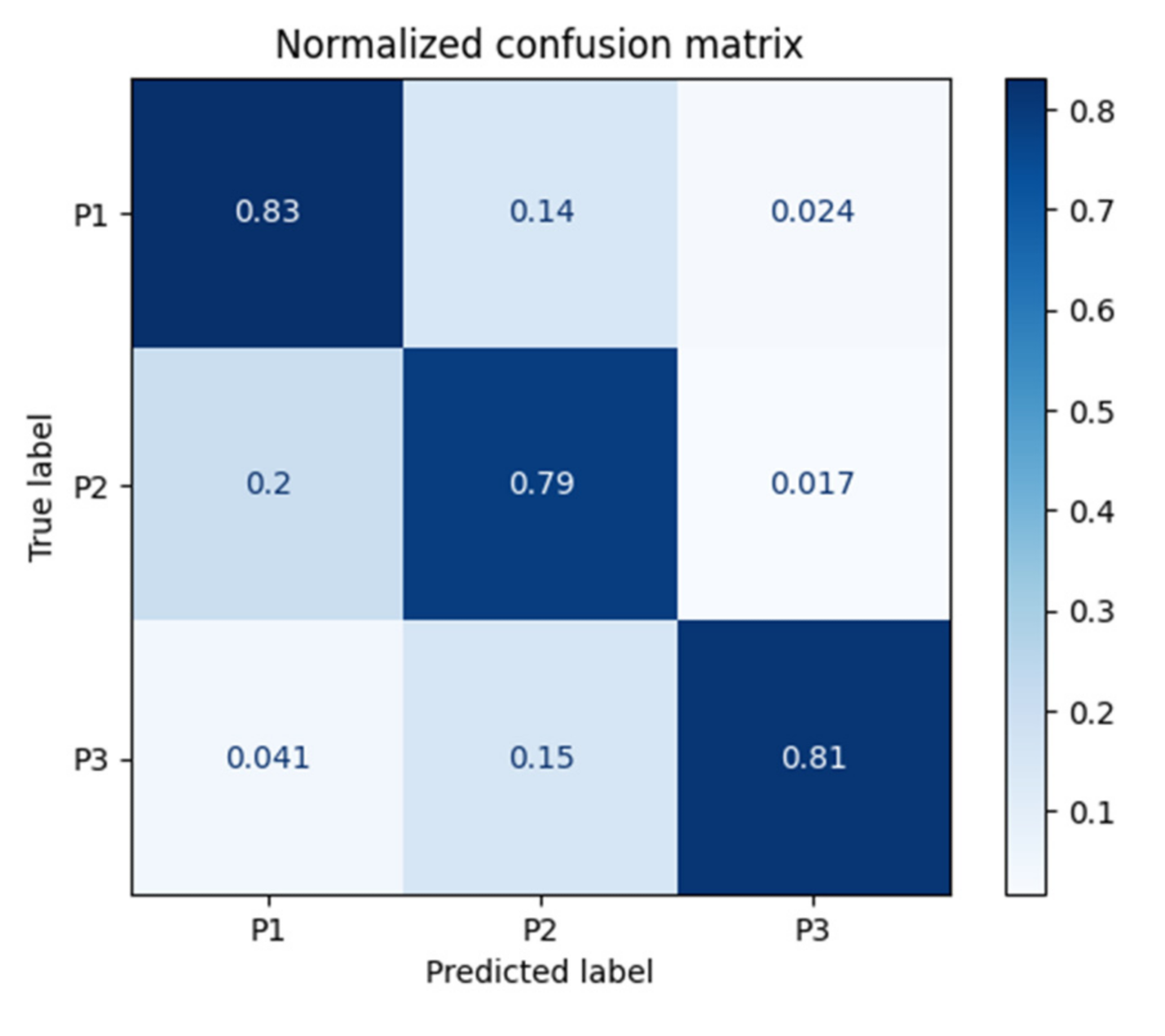
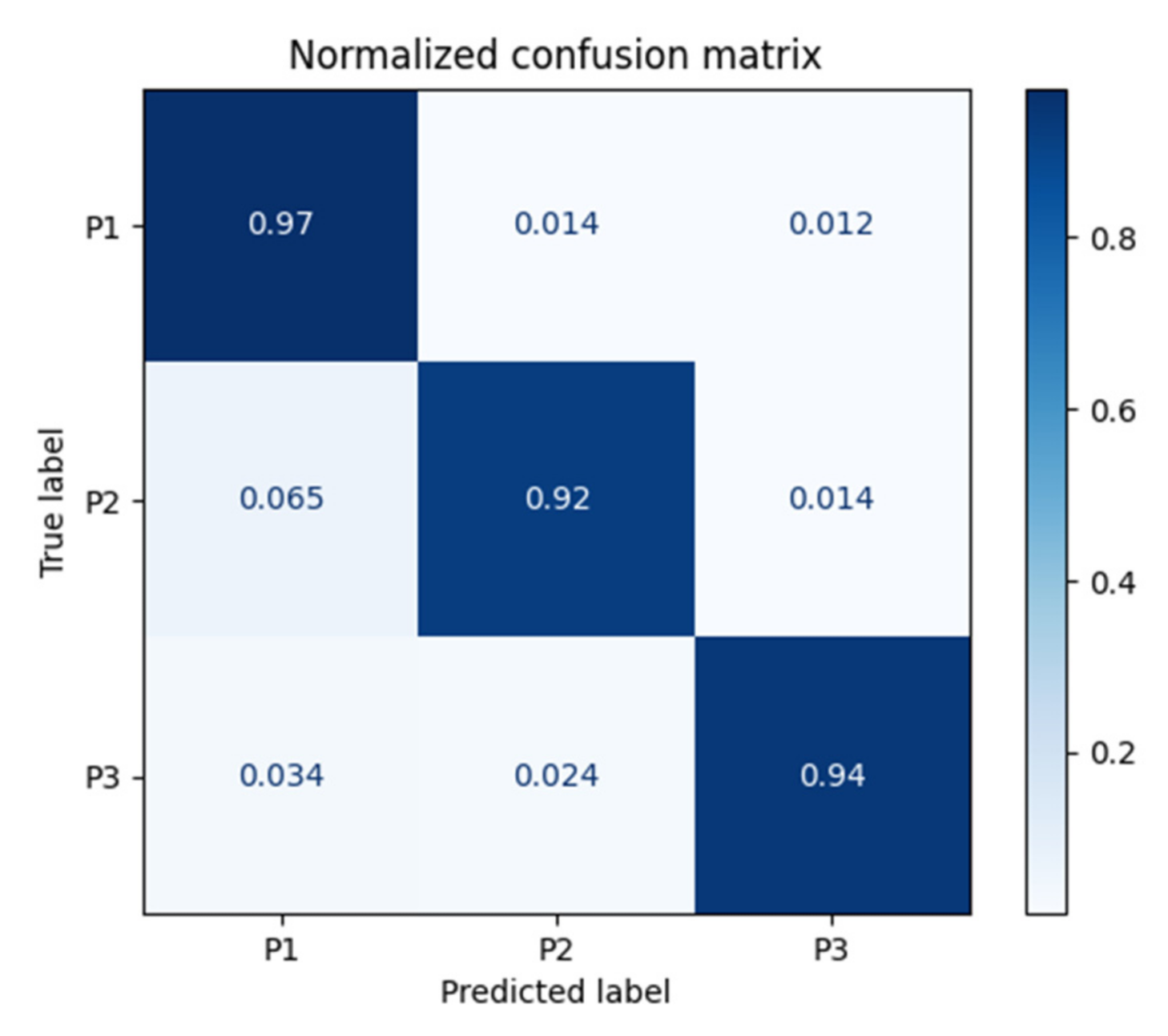
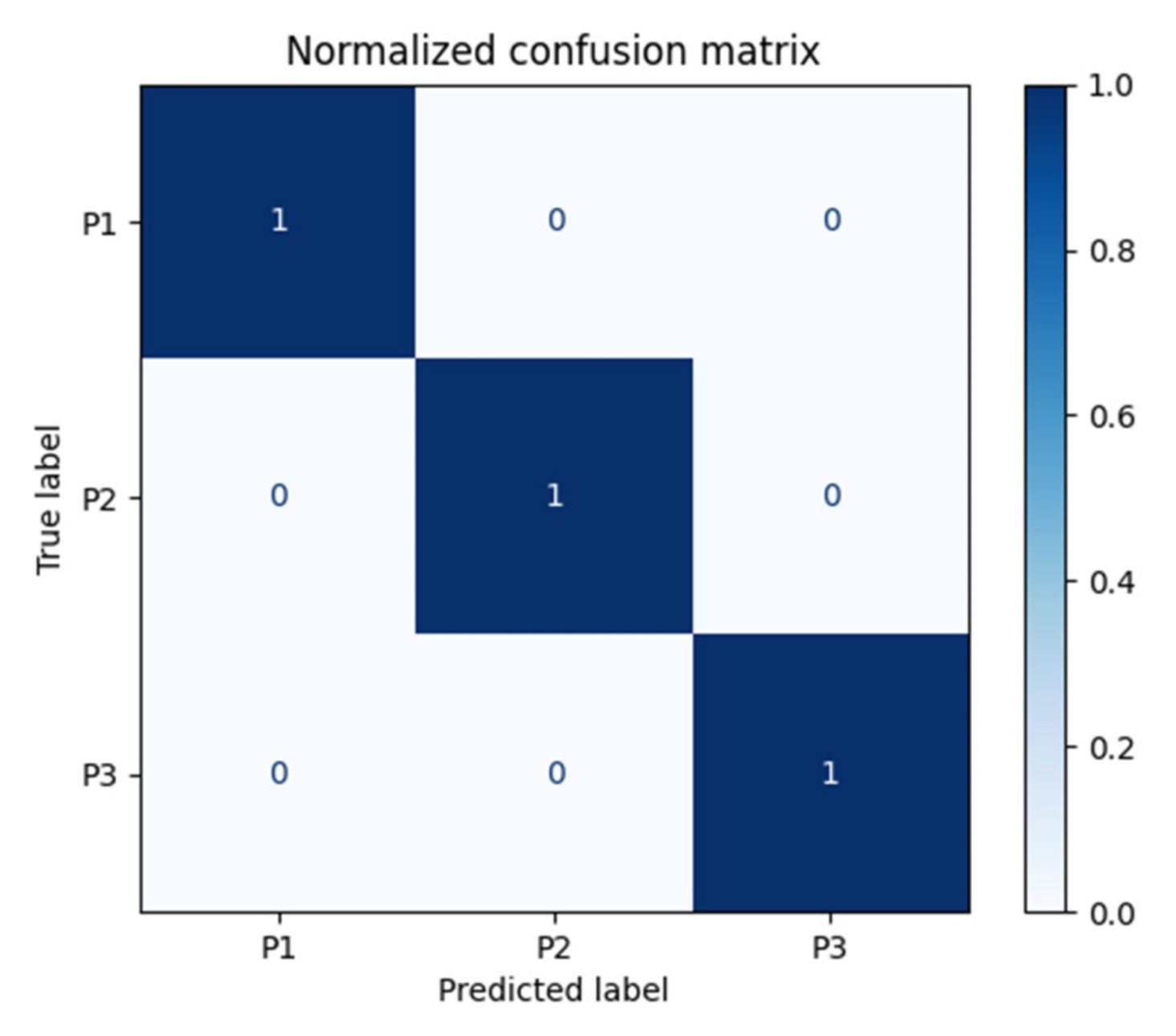
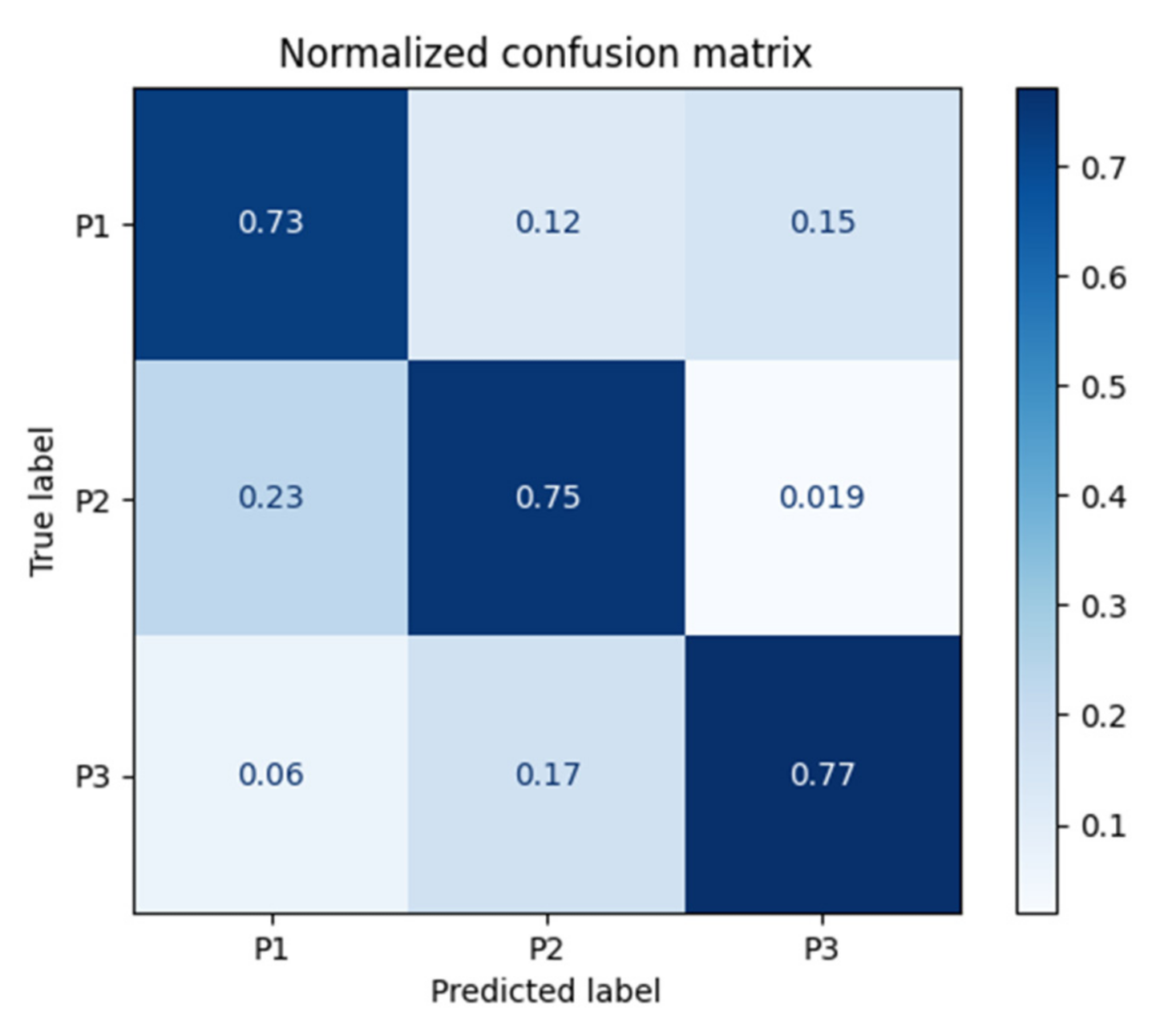
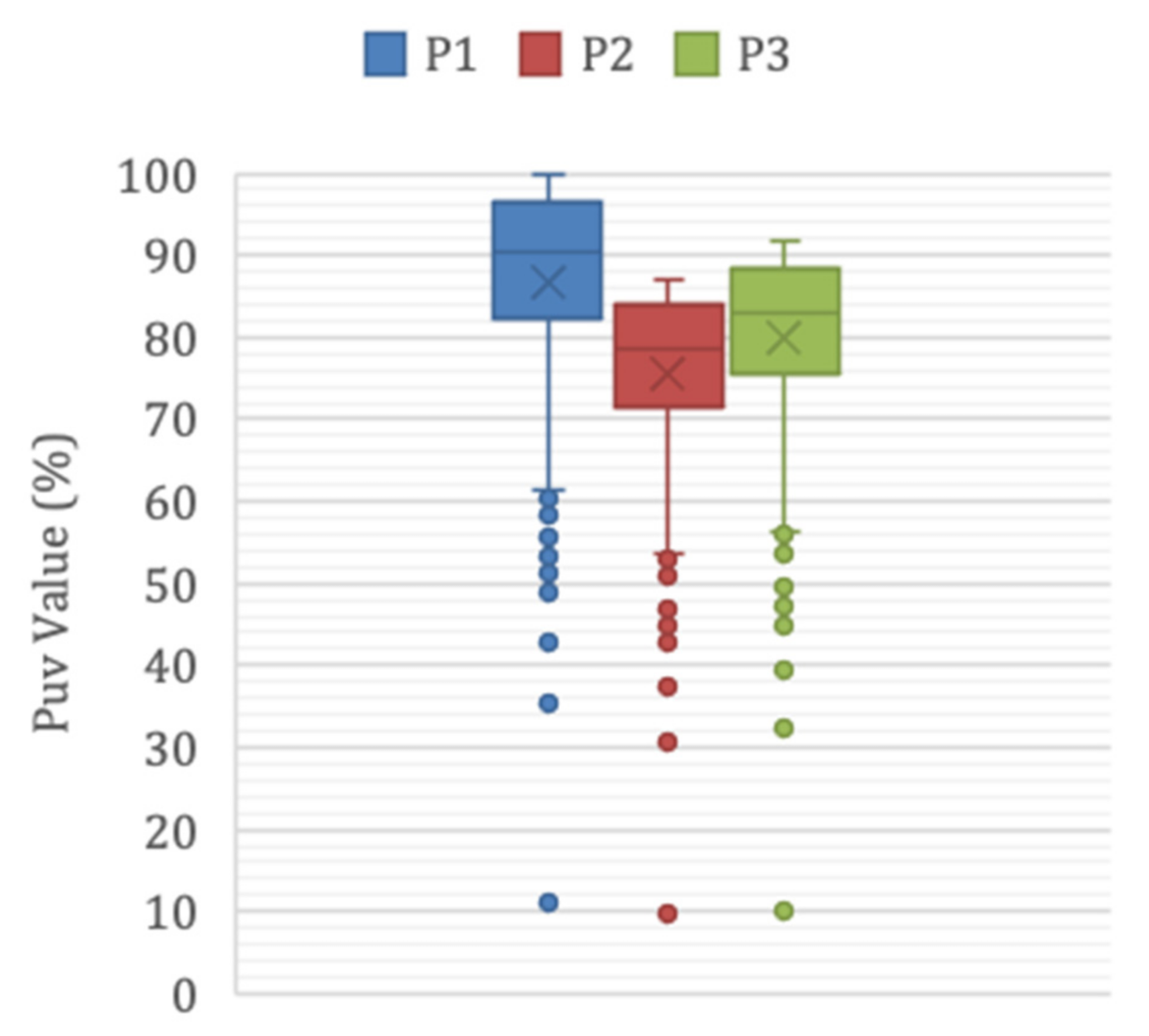
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Terno, J.; Scheithauer, G.; Sommerweiß, U.; Riehme, J. An efficient approach for the multi-pallet loading problem. Eur. J. Oper. Res. 2000, 123, 372–381. [Google Scholar] [CrossRef]
- Hodgson, T.J. A Combined Approach to the Pallet Loading Problem. AIIE Trans. 1982, 14, 175–182. [Google Scholar] [CrossRef]
- Davies, A.P.; Bischoff, E.E. Weight distribution considerations in container loading. Eur. J. Oper. Res. 1999, 114, 509–527. [Google Scholar] [CrossRef]
- Gonçalves, J.F.; Resende, M.G.C. A parallel multi-population biased random-key genetic algorithm for a container loading problem. Comput. Oper. Res. 2012, 39, 179–190. [Google Scholar] [CrossRef]
- Lau, H.C.W.; Chan, T.M.; Tsui, W.T.; Ho, G.T.S.; Choy, K.L. An AI approach for optimizing multi-pallet loading operations. Expert Syst. Appl. 2009, 36, 4296–4312. [Google Scholar] [CrossRef]
- Barros, H.; Pereira, T.; Ramos, A.G.; Ferreira, F.A. Complexity Constraint in the Distributor’s Pallet. Mathematics 2021, 9, 1742. [Google Scholar] [CrossRef]
- Dell’Amico, M.; Magnani, M. Solving a Real-Life Distributor’s Pallet Loading Problem. Math. Comput. Appl. 2021, 26, 53. [Google Scholar] [CrossRef]
- Dias Saraiva, R.; Nepomuceno, N.; Pinheiro, P.R. A Two-Phase Approach for Single Container Loading with Weakly Heterogeneous Boxes. Algorithms 2019, 12, 67. [Google Scholar] [CrossRef] [Green Version]
- Tkaczyk, S.; Drozd, M.; Kędzierski, Ł.; Santarek, K. Study of the Stability of Palletized Cargo by Dynamic Test Method Performed on Laboratory Test Bench. Sensors 2021, 21, 5129. [Google Scholar] [CrossRef]
- Singh, M.; Almasarwah, N.; Süer, G. A Two-Phase Algorithm to Solve a 3-Dimensional Pallet Loading Problem. Procedia Manuf. 2019, 39, 1474–1481. [Google Scholar] [CrossRef]
- Chen, F.F.; Huang, J.; Centeno, M.A. Intelligent scheduling and control of rail-guided vehicles and load/unload operations in a flexible manufacturing system. J. Intell. Manuf. 1999, 10, 405–421. [Google Scholar] [CrossRef]
- Li, J.; Xiong, N.; Park, J.H.; Liu, C.; Ma, S.; Cho, S. Intelligent model design of cluster supply chain with horizontal cooperation. J. Intell. Manuf. 2012, 23, 917–931. [Google Scholar] [CrossRef]
- Pandian, A.P. Artificial intelligence application in smart warehousing environment for automated logistics. J. Artif. Intell. Res. Cap. Net. 2019, 1, 63–72. [Google Scholar] [CrossRef]
- Hiremath, N.C.; Sahu, S.; Tiwari, M.K. Multi objective outbound logistics network design for a manufacturing supply chain. J. Intell. Manuf. 2013, 24, 1071–1084. [Google Scholar] [CrossRef]
- Berry, T.M.; Ambaw, A.; Defraeye, T.; Coetzee, C.; Opara, U.L. Moisture adsorption in palletised corrugated fibreboard cartons under shipping conditions: A CFD modelling approach. Food Bioprod. Process. 2019, 114, 43–59. [Google Scholar] [CrossRef]
- Goliberenko, D. Analysis of a Particular Logistics Systems: DHL Case. Bachelor’s Thesis, University of Finance and Administration, Prague, Czech Republic, 2019. [Google Scholar]
- Ahn, S.; Park, C.; Yoon, K. An improved best-first branch and bound algorithm for the pallet-loading problem using a staircase structure. Expert Syst. Appl. 2015, 42, 7676–7683. [Google Scholar] [CrossRef]
- Dowsland, K.A. An exact algorithm for the pallet loading problem. Eur. J. Oper. Res. 1987, 31, 78–84. [Google Scholar] [CrossRef]
- Chen, C.S.; Sarin, S.; Ram, B. The pallet packing problem for non-uniform box sizes. Int. J. Prod. Res. 1991, 29, 1963–1968. [Google Scholar] [CrossRef]
- Tarnowski, A.G.; Terno, J.; Scheithauer, G. A Polynomial Time Algorithm for the Guillotine Pallet Loading Problem. INFOR Inf. Syst. Oper. Res. 1994, 32, 275–287. [Google Scholar] [CrossRef]
- Ahn, S.; Yoon, K.; Park, J. A best-first branch and bound algorithm for the pallet-loading problem. Int. J. Prod. Res. 2015, 53, 835–849. [Google Scholar] [CrossRef]
- Schuster, M.; Bormann, R.; Steidl, D.; Reynolds-Haertle, S.; Stilman, M. Stable stacking for the distributor’s pallet packing problem. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3646–3651. [Google Scholar]
- Chan, F.T.S.; Bhagwat, R.; Kumar, N.; Tiwari, M.K.; Lam, P. Development of a decision support system for air-cargo pallets loading problem: A case study. Expert Syst. Appl. 2006, 31, 472–485. [Google Scholar] [CrossRef]
- Neliβen, J. How to use structural constraints to compute an upper bound for the pallet loading problem. Eur. J. Oper. Res. 1995, 84, 662–680. [Google Scholar] [CrossRef]
- Bischoff, E.E.; Janetz, F.; Ratcliff, M.S.W. Loading pallets with non-identical items. Eur. J. Oper. Res. 1995, 84, 681–692. [Google Scholar] [CrossRef]
- Young-Gun, G.; Kang, M.-K. A fast algorithm for two-dimensional pallet loading problems of large size. Eur. J. Oper. Res. 2001, 134, 193–202. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Roy, R.; Bhattacharya, S. An exact depth-first algorithm for the pallet loading problem. Eur. J. Oper. Res. 1998, 110, 610–625. [Google Scholar] [CrossRef]
- Martins, G.H.A.; Dell, R.F. Solving the pallet loading problem. Eur. J. Oper. Res. 2008, 184, 429–440. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhang, F.; Wan, Z.; Sun, J.; Ke, L.G.; Zuo, J.; Li, K. Design of an optimized forklift routes for a four-door dangerous goods monolayer warehouse through genetic particle swarm optimization algorithm. Int. J. Ind. Eng. 2020, 27, 276–287. [Google Scholar]
- Sahin-Arslan, A.; Ertem, M.A. A warehouse design with containers for humanitarian logistics: A real-life implementation from Turkey. Int. J. Ind. Eng. 2019, 26, 139–155. [Google Scholar]
- Martins, G.H.A.; Dell, R.F. The minimum size instance of a Pallet Loading Problem equivalence class. Eur. J. Oper. Res. 2007, 179, 17–26. [Google Scholar] [CrossRef] [Green Version]
- Neliβen, J. New Approaches to the Pallet Loading Problem. Schriften zur Informatik und Angewandten Mathematik 1993, 155, 1–43. [Google Scholar]
- Liu, F.-H.F.; Hsiao, C.J. A three-dimensional pallet loading method for single-size boxes. J. Oper. Res. Soc. 1997, 48, 726–735. [Google Scholar] [CrossRef]
- Bischoff, E.; Dowsland, W.B. An Application of the Micro to Product Design and Distribution. J. Oper. Res. Soc. 1982, 33, 271–280. [Google Scholar] [CrossRef]
- Dowsland, K.A. The Three-Dimensional Pallet Chart: An Analysis of the Factors Affecting the Set of Feasible Layouts for a Class of Two-Dimensional Packing Problems. J. Oper. Res. Soc. 1984, 35, 895–905. [Google Scholar] [CrossRef]
- Frank, B. Corrugated Box Compression—A Literature Survey. Packag. Technol. Sci. 2014, 27, 105–128. [Google Scholar] [CrossRef]
- Cape Pack User Guide. 2012. Available online: http://docs.esko.com/docs/en-us/cape/2.13/userguide/cp213_retail_user_guide-master.pdf (accessed on 10 May 2021).
- Corrugated Compression Strength. (14 February 2014). Retrieved 15 March 2017. Available online: https://wiki.esko.com/display/KBA/KB82221048%3A+Cape+Pack+-+Compression+Strength+Program (accessed on 15 May 2021).
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Biing-Hwang, J.; Wu, H.; Chin-Hui, L. Minimum classification error rate methods for speech recognition. IEEE Trans. Audio Speech Lang. Process. 1997, 5, 257–265. [Google Scholar] [CrossRef] [Green Version]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Manevitz, L.M.; Malik, Y. Nouvelles Acquisitions Dans L’Etude Des Orgasmes Feminins. J. Mach. Learn. Res. 2001, 2, 139–154. [Google Scholar]
- Mathur, A.; Foody, G.M. Multiclass and Binary SVM Classification: Implications for Training and Classification Users. IEEE Geosci. Remote. Sens. Lett. 2008, 5, 241–245. [Google Scholar] [CrossRef]
- Antipov, G.; Berrani, S.-A.; Dugelay, J.-L. Minimalistic CNN-based ensemble model for gender prediction from face images. Pattern Recognit. Lett. 2016, 70, 59–65. [Google Scholar] [CrossRef]
- Cruz, J.A.; Wishart, D.S. Applications of Machine Learning in Cancer Prediction and Prognosis. Cancer Inform. 2006, 2, 59–77. [Google Scholar] [CrossRef]
- De Marsico, M.; Petrosino, A.; Ricciardi, S. Iris recognition through machine learning techniques: A survey. Pattern Recognit. Lett. 2016, 82, 106–115. [Google Scholar] [CrossRef]
- Saritas, M.M.; Yasar, A. Performance Analysis of ANN and Naive Bayes Classification Algorithm for Data Classification. Int. J. Intell. Syst. Appl. Eng. 2019, 7, 88–91. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Jianchang, M.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Furey, T.S.; Cristianini, N.; Duffy, N.; Bednarski, D.W.; Schummer, M.; Haussler, D. Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics 2000, 16, 906–914. [Google Scholar] [CrossRef]
- Hu, L.-Y.; Huang, M.-W.; Ke, S.-W.; Tsai, C.-F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramírez-Gallego, S.; Krawczyk, B.; García, S.; Woźniak, M.; Benítez, J.M.; Herrera, F. Nearest Neighbor Classification for High-Speed Big Data Streams Using Spark. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2727–2739. [Google Scholar] [CrossRef]
- Dai, Q.Y.; Zhang, C.P.; Wu, H. Research of decision tree classification algorithm in data mining. Int. J. Database Theory Appl. 2016, 9, 1–8. [Google Scholar] [CrossRef]
- Shahbazi, F. Using Decision Tree Classification Algorithm to Design and Construct the Credit Rating Model for Banking Customers. IOSR J. Bus. Manag. 2020, 21, 24–28. [Google Scholar] [CrossRef]
- Akar, Ö.; Güngör, O. Integrating multiple texture methods and NDVI to the Random Forest classification algorithm to detect tea and hazelnut plantation areas in northeast Turkey. Int. J. Remote Sens. 2015, 36, 442–464. [Google Scholar] [CrossRef]
- Lakshmanaprabu, S.K.; Shankar, K.; Ilayaraja, M.; Nasir, A.W.; Vijayakumar, V.; Chilamkurti, N. Random forest for big data classification in the internet of things using optimal features. Int. J. Mach. Learn. Cybern. 2019, 10, 2609–2618. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Chai, K.E.K.; Anthony, S.; Coiera, E.; Magrabi, F. Using statistical text classification to identify health information technology incidents. J. Am. Med. Inform. Assoc. 2013, 20, 980–985. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, A.; Tatbul, N.; Marcus, R.; Zhou, S.; Lee, I.; Gottschlich, J. Class-weighted evaluation metrics for imbalanced data classification. arXiv 2020, arXiv:2010.05995. [Google Scholar]
- Haghighi, S.; Jasemi, M.; Hessabi, S.; Zolanvari, A. PyCM: Multiclass confusion matrix library in Python. J. Open Source Softw. 2018, 3, 729l. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Yates, A.; Etzioni, O. Unsupervised Methods for Determining Object and Relation Synonyms on the Web. J. Artif. Intell. Res. 2009, 34, 255–296. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Lemaitre, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
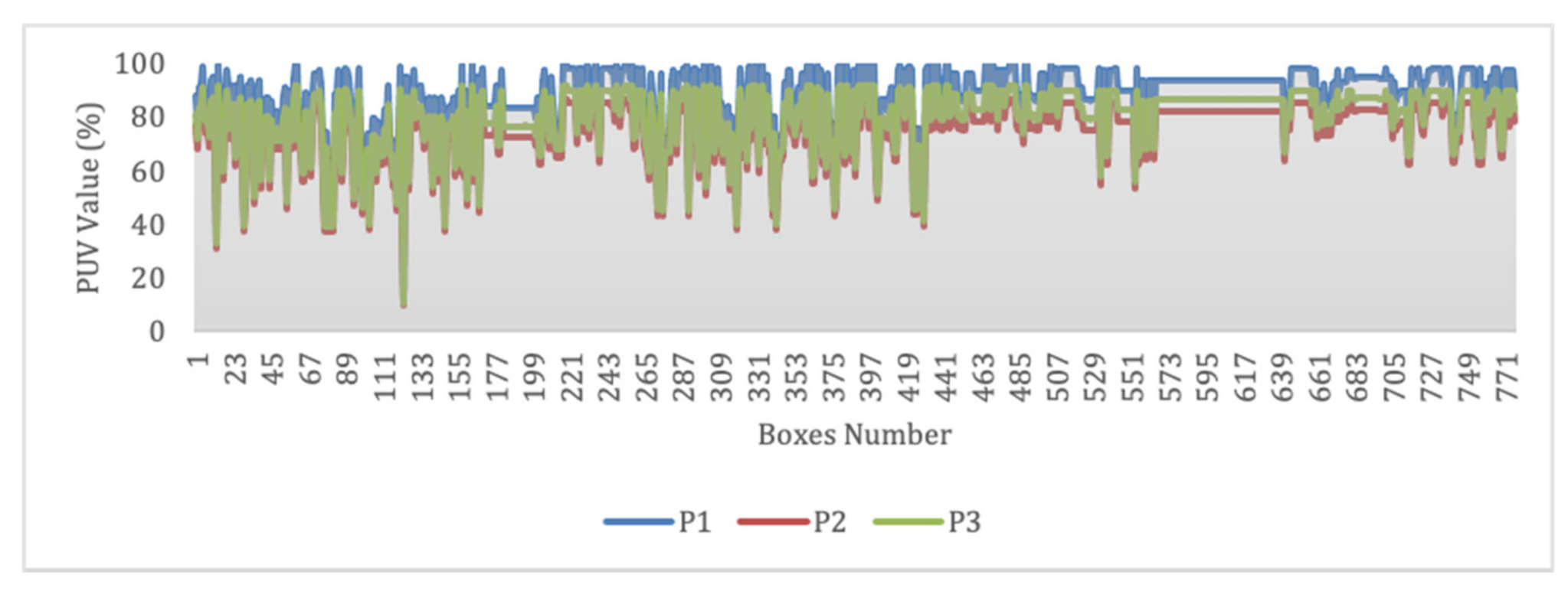{kind=link}
| 0 | 1 | 0–0.45 | 1.1 | Yes | 0.92 | Yes | 0.60 | 1st Shortest Dimension of Box | 1 |
| 1–3 | 0.7 | 0.45–0.55 | 1 | No | 1 | No | 1 | 2nd Shortest Dimension of Box | 0.9 |
| 4–10 | 0.65 | 0.55–0.65 | 0.9 | Longest Dimension of Box | 0.8 | ||||
| 11–30 | 0.6 | 0.65–0.75 | 0.8 | ||||||
| 31–90 | 0.55 | 0.75–0.85 | 0.7 | ||||||
| 91–120 | 0.5 | 0.85–1 | 0.5 | ||||||
| 121–300 | 0.45 | ||||||||
| Total Data Points | Data Points after Pre-Processing | P1 Pallets | P2 Pallets | P3 Pallets | |||
|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | ||
| 15,187 | 1110 | 283 | 31 | 299 | 34 | 417 | 46 |
| Method | Accuracy | Overall Balanced Accuracy | Cohen’s Kappa | Matthew’s Correlation Coefficient | Cross Entropy |
|---|---|---|---|---|---|
| ANN | 0.76 | 0.76 | 0.64 | 0.66 | 1.66 |
| Decision Tree | 0.88 | 0.87 | 0.82 | 0.83 | 1.61 |
| KNN | 0.82 | 0.81 | 0.73 | 0.74 | 1.65 |
| Random Forest | 0.89 | 0.88 | 0.84 | 0.84 | 1.61 |
| Support Vector Machine | 0.74 | 0.74 | 0.62 | 0.63 | 1.67 |
| Method | Class (Pallet) | Sensitivity by Class | Specificity by Class | Precision by Class | F1-Macro by Class | Balanced Accuracy by Class | Confusion Entropy by Class |
|---|---|---|---|---|---|---|---|
| ANN | P1 | 0.76 | 0.89 | 0.79 | 0.75 | 0.82 | 0.36 |
| P2 | 0.72 | 0.82 | 0.65 | 0.65 | 0.77 | 0.42 | |
| P3 | 0.79 | 0.94 | 0.91 | 0.84 | 0.86 | 0.28 | |
| Decision Tree | P1 | 0.90 | 0.90 | 0.84 | 0.85 | 0.90 | 0.24 |
| P2 | 0.80 | 0.94 | 0.85 | 0.81 | 0.87 | 0.25 | |
| P3 | 0.92 | 0.96 | 0.95 | 0.93 | 0.94 | 0.15 | |
| KNN | P1 | 0.79 | 0.88 | 0.78 | 0.77 | 0.84 | 0.36 |
| P2 | 0.81 | 0.88 | 0.76 | 0.76 | 0.85 | 0.32 | |
| P3 | 0.84 | 0.96 | 0.94 | 0.87 | 0.90 | 0.20 | |
| Random Forest | P1 | 0.90 | 0.91 | 0.84 | 0.86 | 0.90 | 0.23 |
| P2 | 0.81 | 0.96 | 0.88 | 0.82 | 0.88 | 0.22 | |
| P3 | 0.94 | 0.97 | 0.96 | 0.95 | 0.95 | 0.12 | |
| Support Vector Machine | P1 | 0.73 | 0.86 | 0.72 | 0.70 | 0.79 | 0.44 |
| P2 | 0.71 | 0.85 | 0.69 | 0.64 | 0.78 | 0.39 | |
| P3 | 0.77 | 0.90 | 0.85 | 0.80 | 0.84 | 0.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aylak, B.L.; İnce, M.; Oral, O.; Süer, G.; Almasarwah, N.; Singh, M.; Salah, B. Application of Machine Learning Methods for Pallet Loading Problem. Appl. Sci. 2021, 11, 8304. https://doi.org/10.3390/app11188304
Aylak BL, İnce M, Oral O, Süer G, Almasarwah N, Singh M, Salah B. Application of Machine Learning Methods for Pallet Loading Problem. Applied Sciences. 2021; 11(18):8304. https://doi.org/10.3390/app11188304
Chicago/Turabian StyleAylak, Batin Latif, Murat İnce, Okan Oral, Gürsel Süer, Najat Almasarwah, Manjeet Singh, and Bashir Salah. 2021. "Application of Machine Learning Methods for Pallet Loading Problem" Applied Sciences 11, no. 18: 8304. https://doi.org/10.3390/app11188304