
Dense Robust 3D Reconstruction and Measurement for 3D Printing Process Based on Vision


Abstract
:1. Introduction
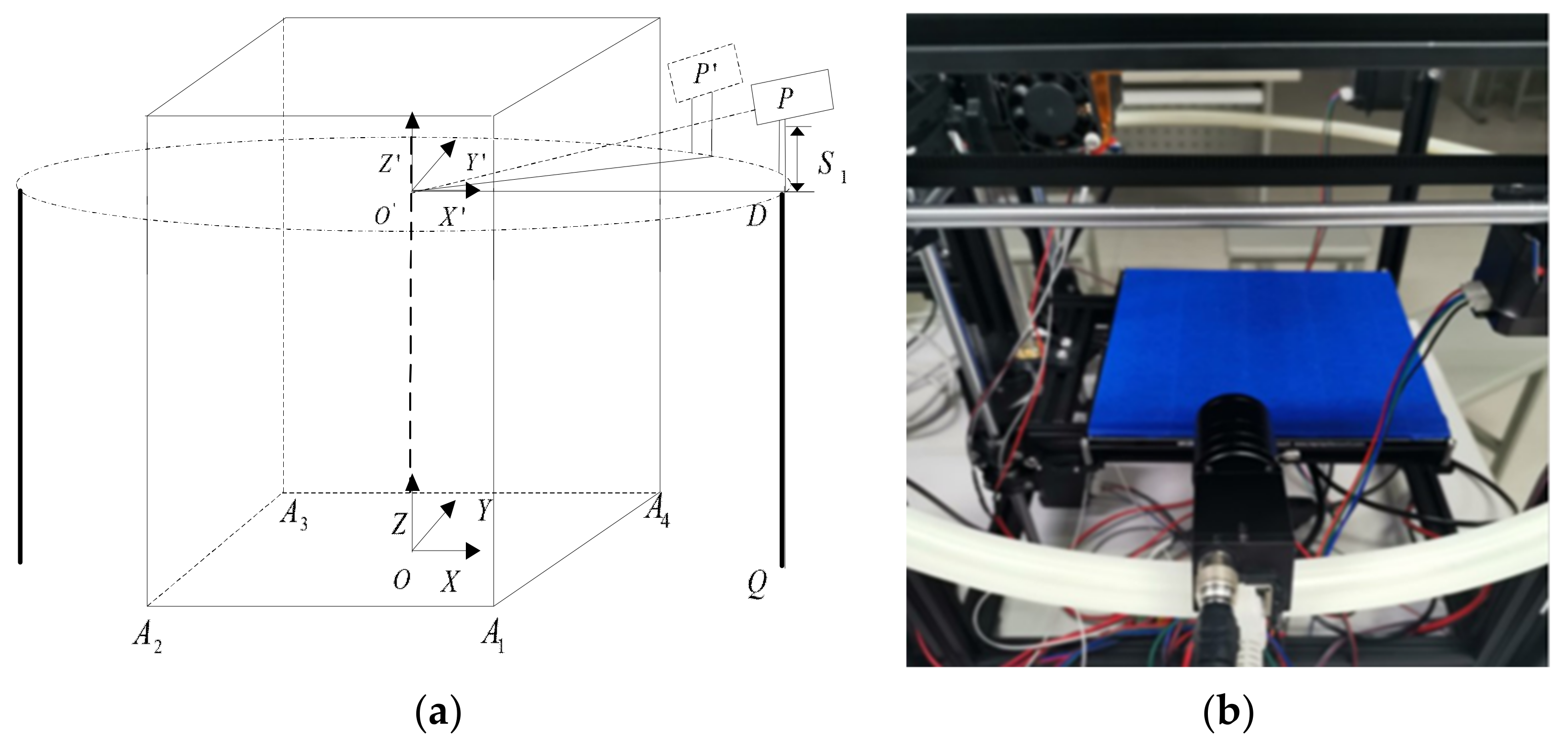
2. Image Acquisition and Preprocessing in 3D Printing Process
3. The Matching Method Based on the FFT-SIFT-AKAZE
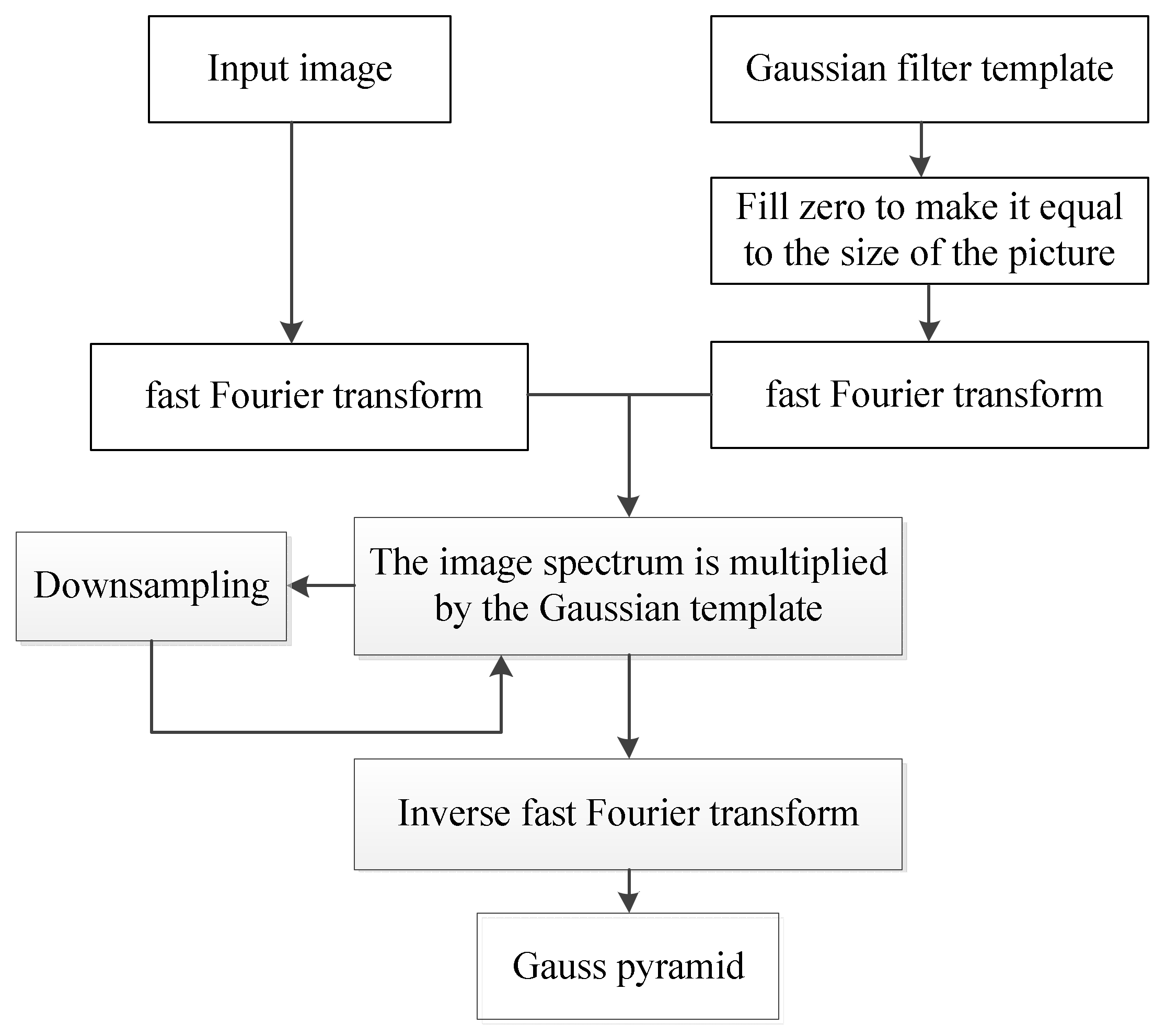
3.1. Improved SIFT Algorithm Based on Fast Fourier Transform (FFT-SIFT)
3.2. Feature Extraction Based on AKAZE Algorithm
- (1)
- The change of image brightness in different scale space can be described by nonlinear diffusion filter, and the divergence factor of flow function is used to control the change of image brightness:In the formula, the symbol ∇ and div represent the solution of gradient and divergence operation respectively, the L matrix represents the brightness of the image, and the conduction diffusion function is represented by c, so that the image can obtain the diffusion self-adaptability of local structure. The fast display diffusion method FFD is used to accelerate the solution of nonlinear partial differential equations.
- (2)
- In the process of constructing the nonlinear scale space, the images processed at different levels in each group of AKAZE have the same resolution as the original images. The FED algorithm is used to calculate the nonlinear diffusion image sequence.
- (3)
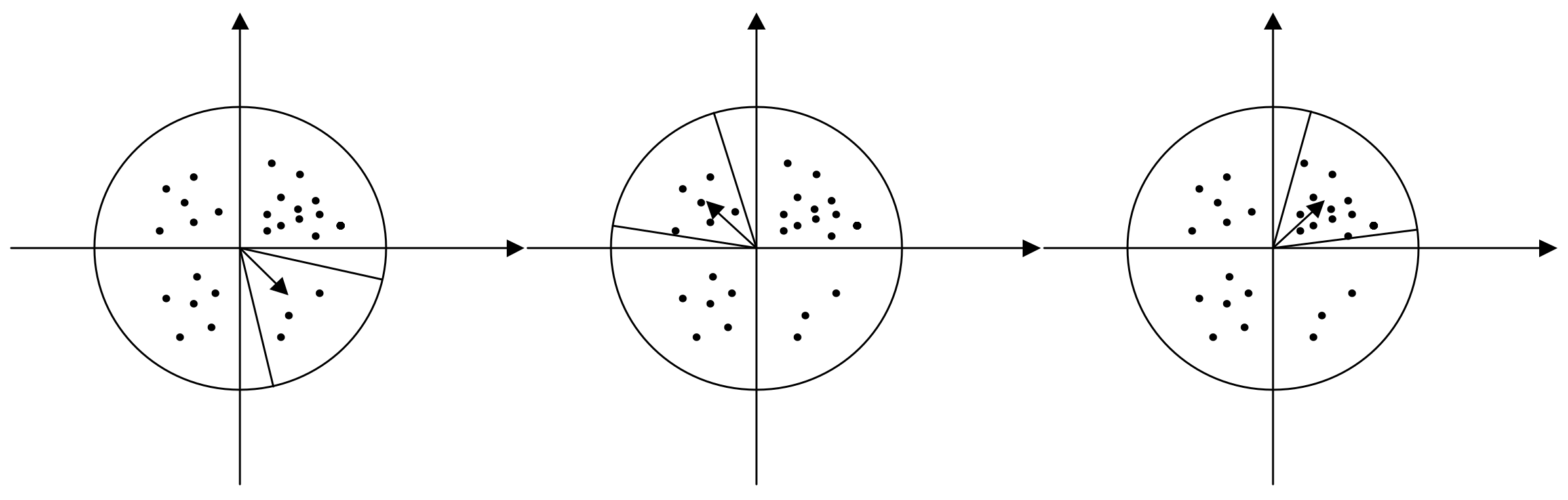
- The generation process of MLDB descriptor is as follows. Firstly, the main direction of the feature point is determined. The feature points centered within the radius of 6σ, the neighborhood of the point at which a first order differential Lx and Ly are Gaussian weighted. The neighborhood of the feature point is traversed in a 60° sector. Accumulation of all of the weighted vectors will accumulate and the highest fan area direction as the main direction of feature points, as shown in Figure 3. The surrounding area of the feature points in accordance with the grid division, and the main direction of the feature points based on neighborhood rotate operation, after the rotation to interval within the grid resampling discrete point value, and through the calculation of horizontal and vertical direction of the scatter of grey value and gradient values, generate descriptor with rotation invariance.
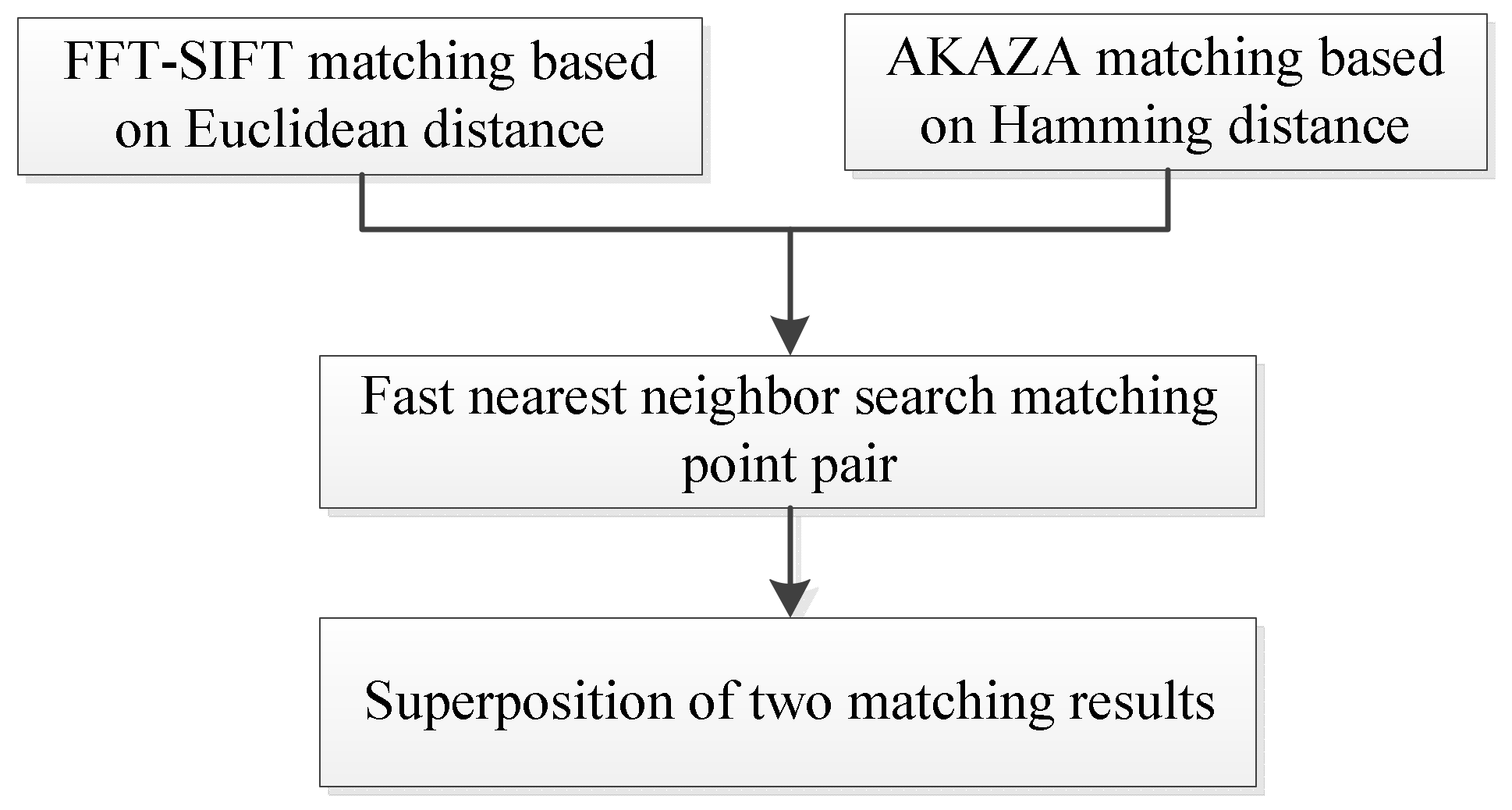
3.3. Strategy and Method of FFT-SIFT-AKAZE Feature Matching
4. Dense 3D Reconstruction of Point Clouds and Surface Texture Reconstruction in 3D Printing Process
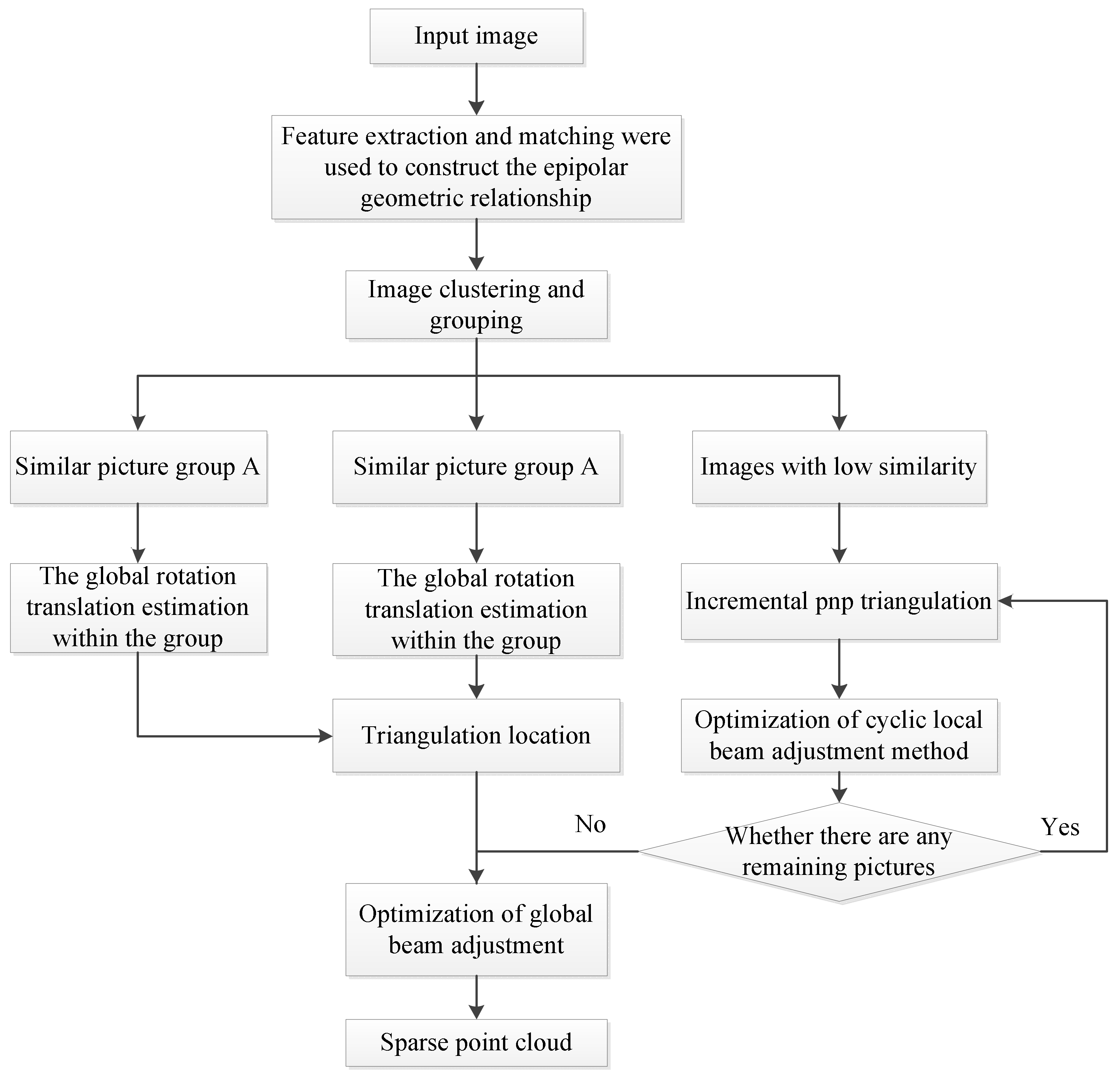
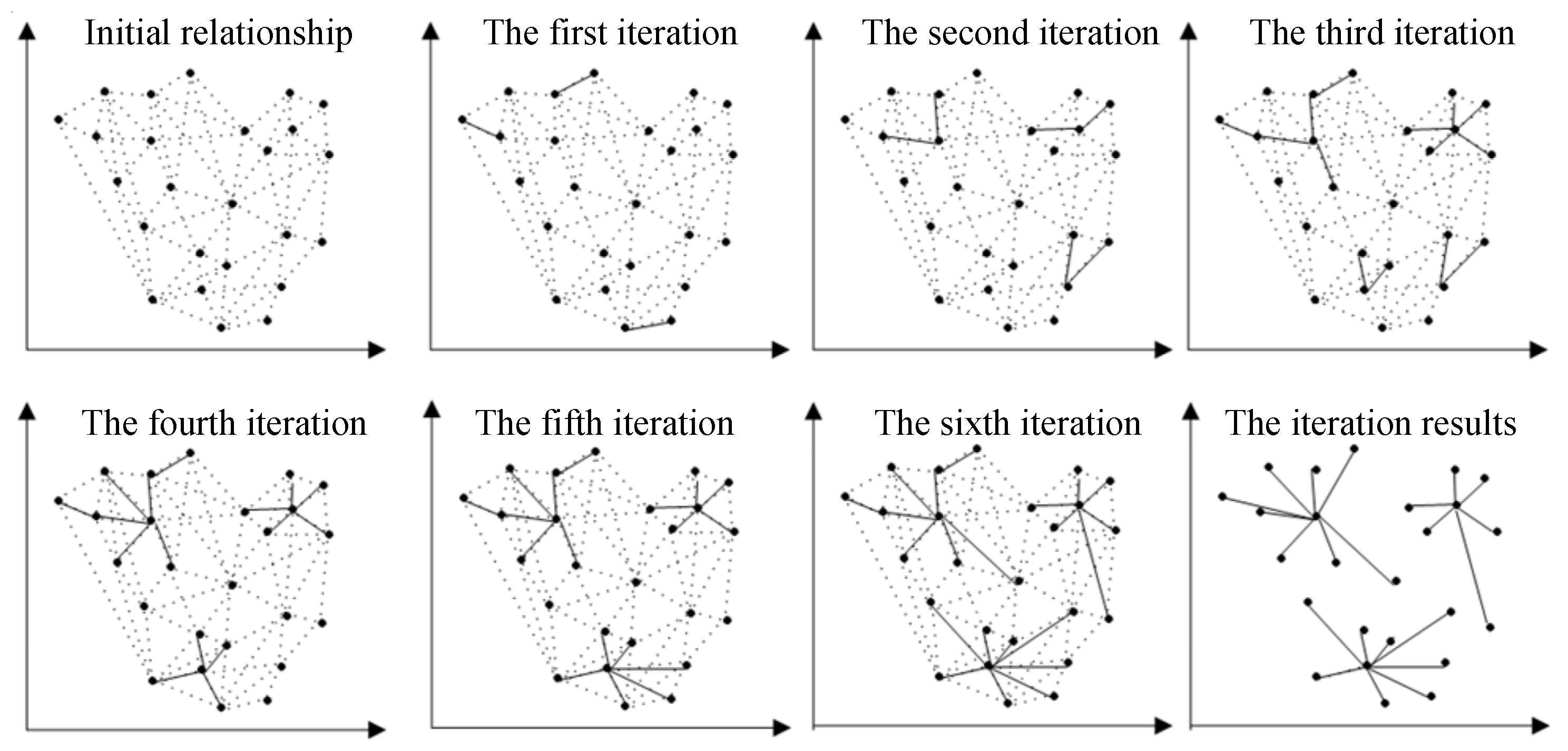
4.1. Sparse Point Cloud Reconstruction with Integrated SFM
4.2. Dense Reconstruction of Point Cloud and 3D Reconstruction of Surface
5. Comparison and Analysis of 3D Reconstruction Experiments in 3D Printing Process
5.1. Experimental and Comparative Analysis of FFT-SIFT Algorithm for Feature Point Extraction
- (1)
- The construction time of Gaussian difference pyramid is reduced, and the speed of feature point extraction is accelerated as a whole.
- (2)
- Not only the speed is accelerated, but also the number of feature points is not reduced.
- (1)
- Compared with the traditional SIFT algorithm, the extraction speed of feature points is faster, and the extraction speed is increased by 25.0% in the application of this system
- (2)
- The number of feature points extraction does not change while accelerating the speed of feature points extraction.
5.2. Experimental Comparison and Analysis of Feature Point Extraction and Matching Based on FFT-SIFT-AKAZE Algorithm
5.3. Experimental and Comparative Analysis of Integerated SFM
5.4. Accuracy Analysis of 3D Reconstruction Results
- (1)
- When photographing the target object from the front, the distance between the measuring camera and the target object is d.
- (2)
- Set the front-shot image as the standard view angle, set the translation vector of the perspective as 0, and set its rotation matrix as the unit matrix. After the above processing, the origin of the perspective will be aligned with the origin of the world coordinate system.
- (3)
- In the subsequent reconstruction process, V1 was always taken as the basic view angle and the dual-view reconstruction is carried out. In the subsequent optimization of the beam adjustment method, the external parameters of the camera are not changed.
6. Conclusions
- (1)
- The impact on the print results for lowering and rising the printing platform (print bed) during the printing process.
- (2)
- Accuracy of reconstruction system
Author Contributions
Funding
Conflicts of Interest
References
- Alvarez, A.G.; Evans, P.L.; Dovgalski, L.; Goldsmith, I. Design, additive manufacture and clinical application of a patient-specific titanium implant to anatomically reconstruct a large chest wall defect. Rapid Prototyp. J. 2021, 27, 304–310. [Google Scholar] [CrossRef]
- Hussin, R.B.; Sharif, S.B.; Rahim, S.Z.B.A.; Bin Mohd Khushairi, M.T.; Abdellah EL-Hadj, A.; Shuaib, N.A.B. The potential of metal epoxy composite (MEC) as hybrid mold inserts in rapid tooling application: A review. Rapid Prototy. J. 2021, in press. [Google Scholar] [CrossRef]
- Kumar, M.; Sharma, V. Additive manufacturing techniques for the fabrication of tissue engineering scaffolds: A review. Rapid Prototyp. J. 2021, in press. [Google Scholar] [CrossRef]
- Palmer, C. 3D Printing Advances on Multiple Fronts. Engineering 2020, 6, 15–20. [Google Scholar] [CrossRef]
- Taborda LL, L.; Maury, H.; Pacheco, J. Design for additive manufacturing: A comprehensive review of the tendencies and limitations of methodologies. Rapid Prototyp. J. 2021, 27, 918–966. [Google Scholar] [CrossRef]
- Ghomi, E.R.; Eshkalak, S.K.; Singh, S.; Chinnappan, A.; Ramakrishna, S.; Narayan, R. Fused filament printing of specialized biomedical devices: A state-of-the art review of technological feasibilities with PEEK. Rapid Prototyp. J. 2021, 27, 592–616. [Google Scholar] [CrossRef]
- Li, S.; Wei, Z.; Du, J.; Pei, W.; Lu, B. A numerical analysis on the metal droplets impacting and spreading out on the substrate. Rare Met. Mater. Eng. 2017, 46, 893–898. [Google Scholar]
- Lis, L.; Yangl, X.; Lub, H. Analysis of different occlusal modes and bite force of mandible. Trans. China Weld. Inst. 2020, 41, 54–61, 82, 100. [Google Scholar]
- Wang, L.; Du, W.; Zhang, F.; Zhang, H.; Gao, B.; Dong, S. Research on topology optimization and 3d printing manufacturing of four-branches cast-steel joint. J. Build. Struct. 2021, 42, 37–49. [Google Scholar]
- Bud, E.S.; Bocanet, V.I.; Muntean, M.H.; Vlasa, A.; Bucur, S.M.; Pacurar, M.; Dragomir, B.R.; Olteanu, C.D.; Bud, A. Accuracy of Three-Dimensional (3D) Printed Dental Digital Models Generated with Three Types of Resin Polymers by Extra-Oral Optical Scanning. J. Clin. Med. 2021, 10, 1908. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ge, J.Y.; Xue, X.W.; Wang, S.F.; Li, F.Q. Path planning for complex thin-walled structures in 3D printing: An improved Q-learning method. Comput. Eng. Appl. 2021, 1–8. [Google Scholar]
- Lai, X.W.; Zheng, Y. 3D printing slice algorithm and partition scanning strategy for numerical control machining system. Trans. Chin. Soc. Agric. Eng. 2019, 35, 58–64. [Google Scholar]
- Chi, D.; Ma, Z.; Cheng, Y.; Zhao, Z.; Tang, Z. Defect testing for 3D printed hollow structure using X ray CT technique. Trans. China Weld. Inst. 2018, 39, 22–26. [Google Scholar]
- Wen, Y.; Gao, T.; Zhang, Y. 3D Visualization Method for Complex Lattice Structure Defects in 3D Printing. Acta Metrol. Sin. 2020, 41, 1077–1081. [Google Scholar]
- Straub, J. Initial work on the characterization of additive manufacturing (3D printing) using software image analysis. Machines 2015, 3, 55–71. [Google Scholar] [CrossRef] [Green Version]
- Sitthi-Amorn, P.; Ramos, J.E.; Wangy, Y.; Lan, J.; Wang, W. MultiFab: A machine vision assisted platform for multi-material 3D printing. Acm Trans. Graph. 2015, 34, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. Kaze features. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 214–227. [Google Scholar]
- Yao, Y.; Luo, Z.X.; Li, S.W.; Shen, T.; Long, Q. Recurrent MVSNet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5525–5534. [Google Scholar]
- Song, R.; Liu, Y.H.; Zhao, Y.T.; Martin, R.; Rosin, P. An evaluation method for multi-view surface reconstruction algorithms. In Proceedings of the Second International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 387–394. [Google Scholar]
- He, Y.; Deng, G.; Wang, Y.; Wei, L.; Yang, J.; Li, X.; Zhang, Y. Optimization of SIFT algorithm for fast-image feature extraction in line-scanning ophthalmoscope—Science Direct. Optik 2018, 152, 21–28. [Google Scholar] [CrossRef]
- Fast Explicit Diffusion for Accelerated Features in Nonlinear Scale Spaces. In Proceedings of the British Machine Vision Conference (BMVC), Bristol, UK, 9–13 September 2013.
- Ramakrishnan, S. Probabilistic cost model for nearest neighbor search in image retrieval. Comput. Rev. 2013, 54, 113. [Google Scholar]
- Chatterjee, A.; Govindu, V.M. Efficient and robust large-scale rotation averaging. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 521–528. [Google Scholar]
- Ozyesil, O.; Singer, A. Robust camera location estimation by convex programming. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2674–2683. [Google Scholar]
- Hata, J.; Ito, K.; Aoki, T. A 3D reconstruction method using PMVS for a limited number of view points. Int. Workshop Adv. Image Technol. (IWAIT) 2019, 11049, 1104942. [Google Scholar]
- Feng, L.; Alliez, P.; Busé, L.; Delingette, H.; Desbrun, M. Curved optimal delaunay triangulation. ACM Trans. Graph. 2018, 37, 16. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Sequence Number of the Picture | The Number of Feature Points Extracted | Time Consumption of SIFT Algorithm to Extract Feature Points | Time Consumption of Feature Points Extraction by FFT-SIFT Algorithm |
|---|---|---|---|
| a1 | 2634 | 4.31 s | 3.21 s |
| a2 | 1927 | 3.62 s | 2.87 s |
| a3 | 2879 | 4.43 s | 3.34 s |
| a4 | 2015 | 3.98 s | 3.12 s |
| a5 | 2960 | 4.51 s | 3.57 s |
| The Image Set Corresponds to the Print Progress | Time Consumption of SIFT Algorithm to Extract Feature Points | Time Consumption of Feature Points Extraction by FFT-SIFT Algorithm |
|---|---|---|
| 23% | 98.18 s | 74.91 s |
| 36% | 99.54 s | 75.61 s |
| 63% | 97.23 s | 73.37 s |
| 85% | 102.35 s | 74.17 s |
| 100% | 93.36 s | 70.25 s |
| Feature Extraction Algorithm | Average Number of Feature Points Extracted | Time Consuming of Feature Point Extraction (s) | Time Consuming of Feature Point Matching (s) | Average Matching Number of Feature Points |
|---|---|---|---|---|
| FFT-SIFT | 2578.2 | 73.67 | 24.89 | 263.5 |
| AKAZE | 1396.7 | 70.39 | 16.67 | 215.1 |
| The algorithm in this paper | 3974.9 | 75.35 | 25.58 | 453.3 |
| The Print Progress of the Photo Collection | TI (s) | eI | TG (s) | EG | TH (s) | eH |
|---|---|---|---|---|---|---|
| 23% | 97.38 | 0.5857 | × | × | 73.28 | 0.6384 |
| 36% | 108.81 | 0.5527 | 55.31 | 0.9183 | 66.54 | 0.5946 |
| 63% | 113.53 | 0.5679 | 54.32 | 0.8841 | 71.85 | 0.5594 |
| 85% | 119.73 | 0.5879 | × | × | 67.23 | 0.6487 |
| 100% | 138.20 | 0.5931 | 59.73 | 0.9354 | 72.16 | 0.6197 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, N.; Wang, C.; Qiao, Y.; Zhang, Y. Dense Robust 3D Reconstruction and Measurement for 3D Printing Process Based on Vision. Appl. Sci. 2021, 11, 7961. https://doi.org/10.3390/app11177961
Lv N, Wang C, Qiao Y, Zhang Y. Dense Robust 3D Reconstruction and Measurement for 3D Printing Process Based on Vision. Applied Sciences. 2021; 11(17):7961. https://doi.org/10.3390/app11177961
Chicago/Turabian StyleLv, Ning, Chengyu Wang, Yujing Qiao, and Yongde Zhang. 2021. "Dense Robust 3D Reconstruction and Measurement for 3D Printing Process Based on Vision" Applied Sciences 11, no. 17: 7961. https://doi.org/10.3390/app11177961