
Deep Feature Fusion Based Dual Branch Network for X-ray Security Inspection Image Classification



Abstract
:1. Introduction
- The perplexing background of scanned images will affect the detection speed of security personnel;
- The rare occurrence of problematic baggage and the fatigue of security personnel are most likely to cause mistakes and misses;
- Long-term repetitive work is not conducive to the physical and mental health of security personnel.
- Proposes a CNN model based on deep feature fusion. Ablation experiments show its effectiveness on classification performance versus backbone;
- Introduces focal loss, which can alleviate the class imbalance of the dataset, thereby improving the classification performance of the network;
- Through integrating the deep feature fusion model and focal loss function, proposes a dual branch convolutional neural network architecture. It further improves the classification performance of the network by the supervision of the training process of one branch on the other.
2. Related Works
2.1. Automatic Prediction of Prohibited Items in X-ray Scanned Images
- Personal items are often placed casually, which leads to randomly stacked and overlapped objects. Consequently, prohibited items are often occluded by the background;
- In X-ray images, objects composed of the same material will be assigned similar colors, which leads to indistinguishability between prohibited items and background;
- X-ray security inspection image itself relates to the privacy of the inspected person.
2.2. Deep Feature Fusion
2.3. Class Imbalance and Its Treatment
3. Method
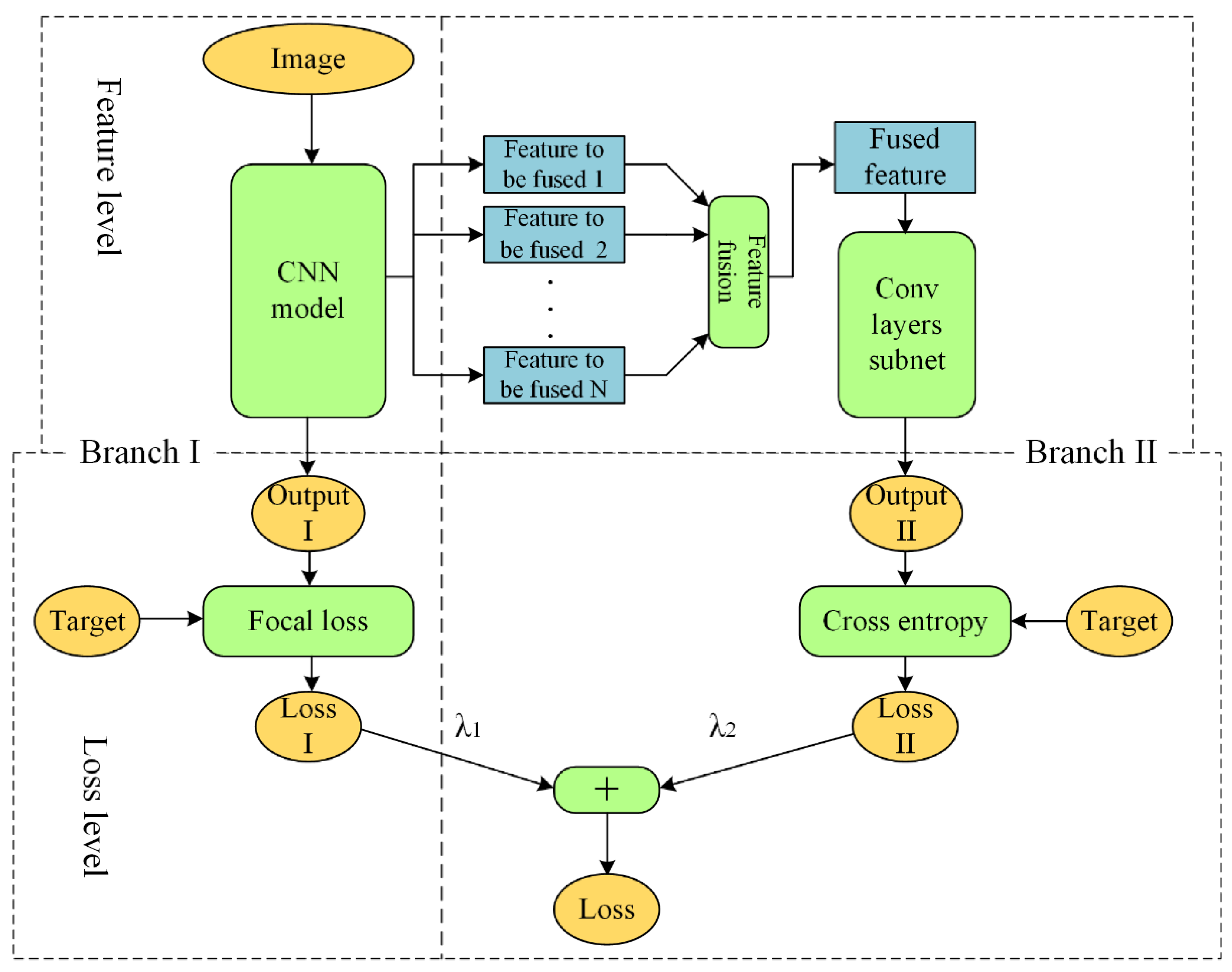
3.1. Dual Branch Network Architecture
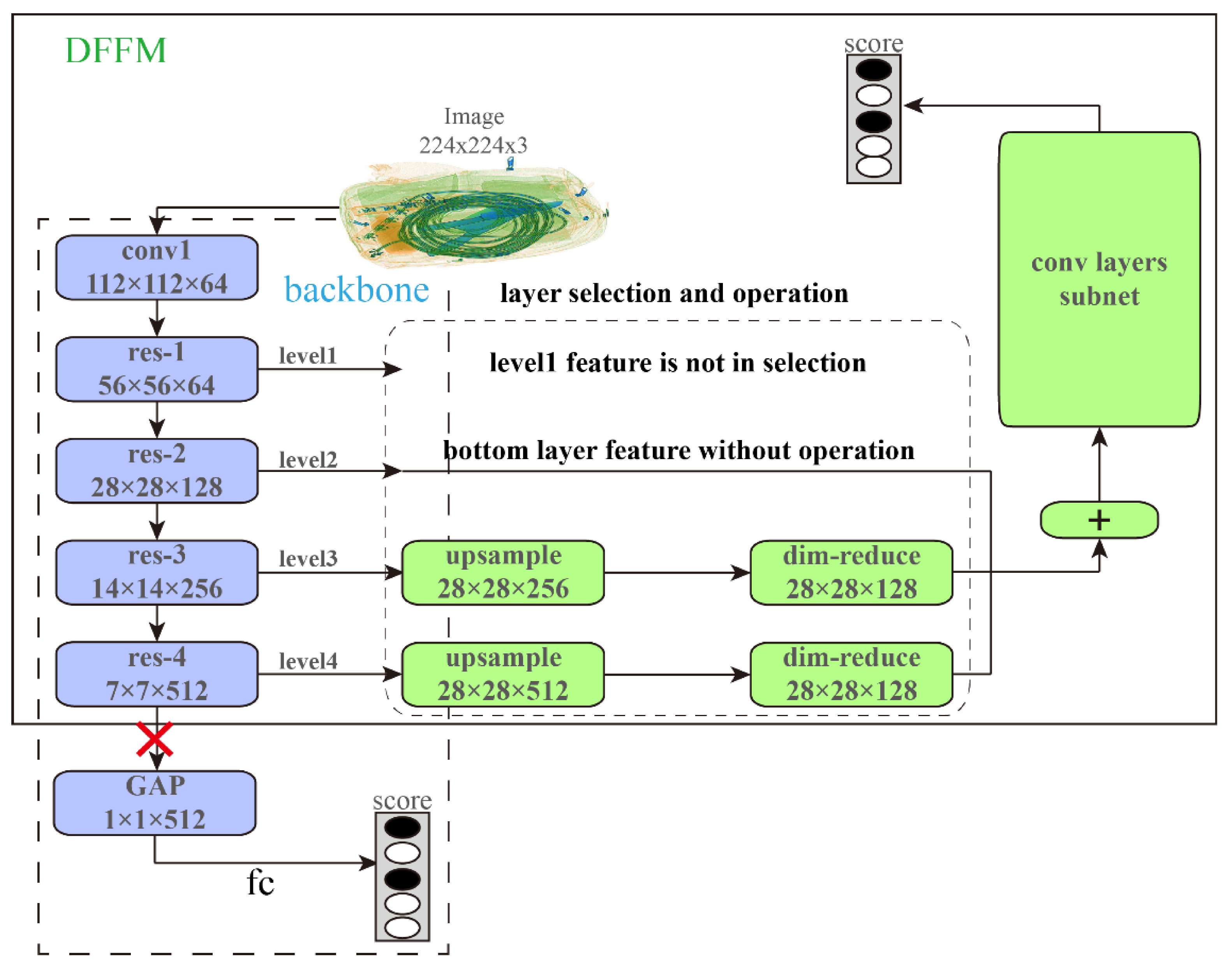
3.2. Feature Fusion Model
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.2.1. Baseline
4.2.2. Preprocessing of Images
- Resize to 256 × 256 pixels;
- Random cropping to 224 × 224 pixels;
- Random horizontal flipping with probability of 0.5.
4.2.3. Training Parameters
4.3. Evaluation Metric
4.4. Ablation Studies
4.4.1. Parameter Setting on Focal Loss
4.4.2. Level Selection of Features to Be Fused
4.4.3. Loss Weight Setting of Dual Branch Network
4.4.4. Results of Ablation Studies
- As for the class imbalance dataset, it is of the highest urgency to balance importance on positive and negative samples;
- As for the deep feature fusion module, the considerable optimization on model performance also validates its effectiveness.
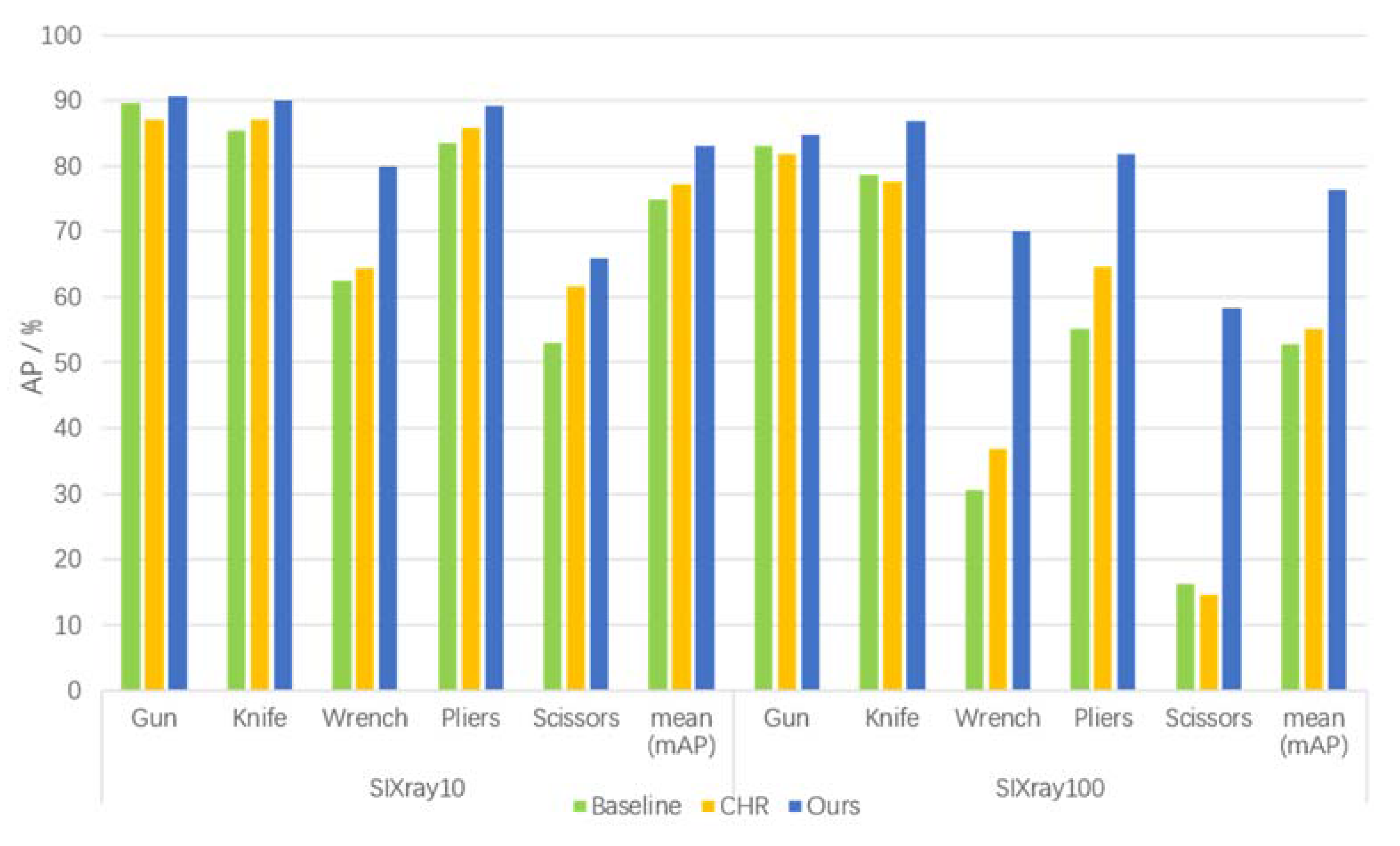
4.5. Overall Performance Study
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.Q.; Zhang, L.; Jin, X. Recent progress on X-ray security inspection technologies. Chin. Sci. Bull. 2017, 62, 1350–1364. [Google Scholar] [CrossRef] [Green Version]
- Mery, D. X-ray testing by computer vision. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 360–367. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Honolulu, HI, USA, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Baştan, M.; Yousefi, M.R.; Breuel, T.M. Visual words on baggage X-ray images. In Computer Analysis of Images and Patterns, Proceedings of the 2011 International Conference on Computer Analysis of Images and Patterns, Seville, Spain, 29–31 August 2011; Berciano, A., Díaz-Pernil, D., Kropatsch, W., Molina-Abril, H., Real, P., Eds.; Springer: Berlin, Germany, 2011; pp. 360–368. [Google Scholar]
- Turcsany, D.; Mouton, A.; Breckon, T.P. Improving feature-based object recognition for X-ray baggage security screening using primed visual words. In Proceedings of the 2013 IEEE International Conference on Industrial Technology, Portland, OR, USA, 25–28 February 2013; pp. 1140–1145. [Google Scholar]
- Kundegorski, M.E.; Akçay, S.; Devereux, M.; Mouton, A.; Breckon, T.P. On using feature descriptors as visual words for object detection within X-ray baggage security screening. In Proceedings of the 7th International Conference on Imaging for Crime Detection and Prevention, London, UK, 23–25 November 2016; pp. 1–6. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Akcay, S.; Breckon, T. Towards automatic threat detection: A survey of advances of deep learning within X-ray security imaging. arXiv 2020, arXiv:2001.01293. [Google Scholar]
- Mery, D.; Svec, E.; Arias, M. Object recognition in baggage inspection using adaptive sparse representations of X-ray images. In Image and Video Technology, Proceedings of the 2015 Pacific-Rim Symposium on Image and Video Technology, Auckland, New Zealand, 25–27 November 2015; Bräunl, T., McCane, B., Rivera, M., Yu, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 709–720. [Google Scholar]
- Kwon, H.; Yoon, H.; Park, K.W. Multi-targeted backdoor: Indentifying backdoor attack for multiple deep neural networks. IEICE Trans. Inf. Syst. 2020, 103, 883–887. [Google Scholar] [CrossRef]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The database of X-ray images for nondestructive testing. J. Nondestruct. Eval. 2015, 34, 1–12. [Google Scholar] [CrossRef]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using Deep Convolutional Neural Network Architectures for Object Classification and Detection Within X-Ray Baggage Security Imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef] [Green Version]
- Dhiraj; Jain, D.K. An evaluation of deep learning-based object detection strategies for threat object detection in baggage security imagery. Pattern Recognit. Lett. 2019, 120, 112–119. [Google Scholar] [CrossRef]
- Ding, J.W.; Chen, S.Y.; Lu, G.R. X-ray security inspection method using active vision based on Q-learning algorithm. J. Comput. Appl. 2018, 38, 3414–3418. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. SIXray: A large-scale security inspection X-ray benchmark for prohibited item discovery in overlapping images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2114–2123. [Google Scholar]
- Rong, T.; Cai, H.; Xiong, Y. An Enhanced Prohibited Items Recognition Model. arXiv 2021, arXiv:2102.12256. [Google Scholar]
- Hu, B.; Zhang, C.; Wang, L.; Zhang, Q.; Liu, Y. Multi-label X-ray Imagery Classification via Bottom-up Attention and Meta Fusion. In Proceedings of the Asian Conference on Computer Vision, Tokyo, Japan, 30 November–4 December 2020. [Google Scholar]
- Hassan, T.; Shafay, M.; Akçay, S.; Khan, S.; Bennamoun, M.; Damiani, E.; Werghi, N. Meta-Transfer Learning Driven Tensor-Shot Detector for the Autonomous Localization and Recognition of Concealed Baggage Threats. Sensors 2020, 20, 6450. [Google Scholar] [CrossRef] [PubMed]
- Dumagpi, J.K.; Jeong, Y.J. Evaluating GAN-Based Image Augmentation for Threat Detection in Large-Scale Xray Security Images. Appl. Sci. 2021, 11, 36. [Google Scholar] [CrossRef]
- Wei, Y.; Tao, R.; Wu, Z.; Ma, Y.; Zhang, L.; Liu, X. Occluded prohibited items detection: An x-ray security inspection benchmark and de-occlusion attention module. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 138–146. [Google Scholar]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep Feature Fusion for VHR Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Boston, MA, USA, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. ExFuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 273–288. [Google Scholar]
- Wei, X.N.; Li, Y.H.; Wang, Z.Y.; Li, H.Z.; Wang, H.Z. Methods of training data augmentation for medical image artificial intelligence aided diagnosis. J. Comput. Appl. 2019, 39, 2558–2567. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In COMPSTAT’2010, Proceedings of the 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; Physica-Verlag HD: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Output Size | Description |
|---|---|---|
| input | 28 × 28 × 128 | Fused feature |
| conv1 | 14 × 14 × 256 | conv: 3 × 3, stride 2, 128→256; batchnorm, relu |
| conv2 | 7 × 7 × 512 | conv: 3 × 3, stride 2, 256→512; batchnorm, relu |
| pool | 1 × 1 × 512 | Global average pooling (GAP) |
| fc | 5 × 1 | Fully connected (fc), 512→5 |
| Gun | Knife | Wrench | Pliers | Scissors | Hammer | Total |
|---|---|---|---|---|---|---|
| 3131 | 1943 | 2199 | 3961 | 983 | 60 | 8929 |
| SIXray10 | SIXray100 | ||||
|---|---|---|---|---|---|
| γ | α | mAP/% | γ | α | mAP/% |
| -- | -- | 74.83 | -- | -- | 52.74 |
| 0 | 0.5 | 82.02 1 | 0 | 0.5 | 73.05 |
| 0 | 0.75 | 81.35 | 0 | 0.75 | 72.94 |
| 0.2 | 0.75 | 80.72 | 0.2 | 0.75 | 76.09 |
| 0.5 | 0.5 | 76.21 | 0.5 | 0.5 | 73.28 |
| 1 | 0.25 | 74.29 | 1 | 0.25 | 72.90 |
| 2 | 0.25 | 67.18 | 2 | 0.25 | 69.80 |
| Levels of Features to Be Fused | mAP/% |
|---|---|
| Baseline (without fusion) | 74.83 |
| level4/level3 | 79.22 |
| level4/level3/level2 | 81.07 |
| level4/level3/level2/level1 | 81.27 |
| mAP/% | mAP/% | ||||
|---|---|---|---|---|---|
| 1 | 0.25 | 79.52 | 1 | 0.25 | 81.28 |
| 0.5 | 80.09 | 0.5 | 80.83 | ||
| 1 | 82.52 | 1 | 82.52 | ||
| 2 | 81.92 | 2 | 81.73 | ||
| 3 | 83.10 | 3 | 81.78 | ||
| 5 | 81.92 | 5 | 82.05 |
| Backbone | Feature Fusion | Focal Loss | mAP/% | |
|---|---|---|---|---|
| Baseline | ResNet34 | 74.83 | ||
| Ours | ResNet34 | √ | 81.07 | |
| √ | 82.02 | |||
| √ | √ | 83.10 |
| Dataset | AP/% | Baseline | CHR [21] | Ours |
|---|---|---|---|---|
| SIXray10 | Gun | 89.71 | 87.16 | 90.66 |
| Knife | 85.46 | 87.17 | 89.99 | |
| Wrench | 62.48 | 64.31 | 79.90 | |
| Pliers | 83.50 | 85.79 | 89.14 | |
| Scissors | 52.99 | 61.58 | 65.79 | |
| mean (mAP) | 74.83 | 77.20 | 83.10 | |
| SIXray100 | Gun | 83.06 | 81.96 | 84.84 |
| Knife | 78.75 | 77.70 | 86.98 | |
| Wrench | 30.49 | 36.85 | 70.00 | |
| Pliers | 55.24 | 64.56 | 81.92 | |
| Scissors | 16.14 | 14.49 | 58.36 | |
| mean (mAP) | 52.74 | 55.11 | 76.42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Wei, J. Deep Feature Fusion Based Dual Branch Network for X-ray Security Inspection Image Classification. Appl. Sci. 2021, 11, 7485. https://doi.org/10.3390/app11167485
Xu Y, Wei J. Deep Feature Fusion Based Dual Branch Network for X-ray Security Inspection Image Classification. Applied Sciences. 2021; 11(16):7485. https://doi.org/10.3390/app11167485
Chicago/Turabian StyleXu, Yingda, and Jianming Wei. 2021. "Deep Feature Fusion Based Dual Branch Network for X-ray Security Inspection Image Classification" Applied Sciences 11, no. 16: 7485. https://doi.org/10.3390/app11167485