
Lightweight Convolutional Neural Networks with Model-Switching Architecture for Multi-Scenario Road Semantic Segmentation


Abstract
:1. Introduction
- Mutual suppression between weights, which occurs in a single-model CNN, is addressed using a multi-model CNN with model-switching architecture for semantic segmentation given diverse road situations.
- Through the use of lightweight processes in the CNN, the model size and computational load were reduced to increase the execution speed.
2. Related Work
3. Proposed Lightweight CNN with an MSA
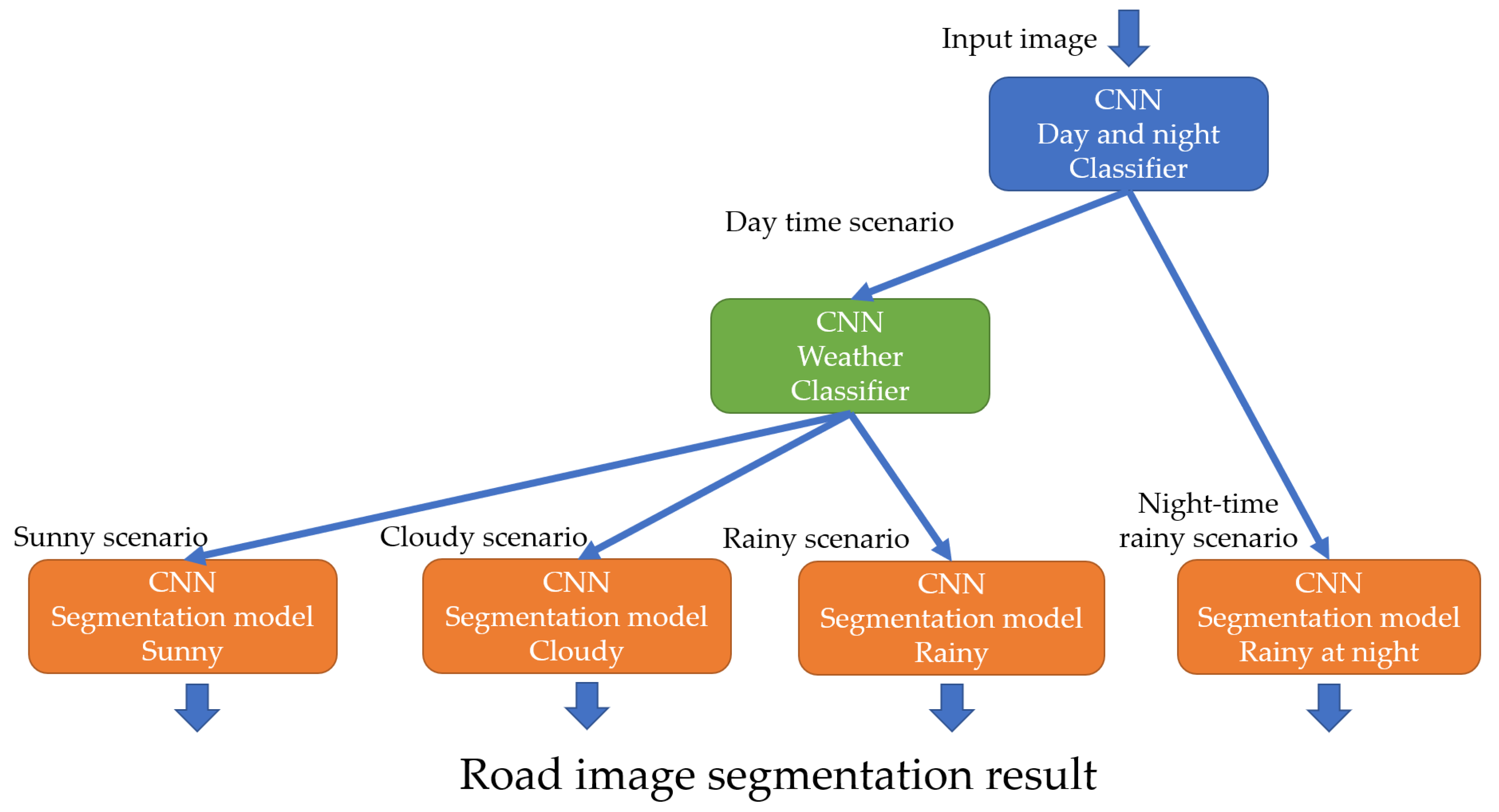
3.1. Model-Switching Architecture
3.2. Lightweight Processes
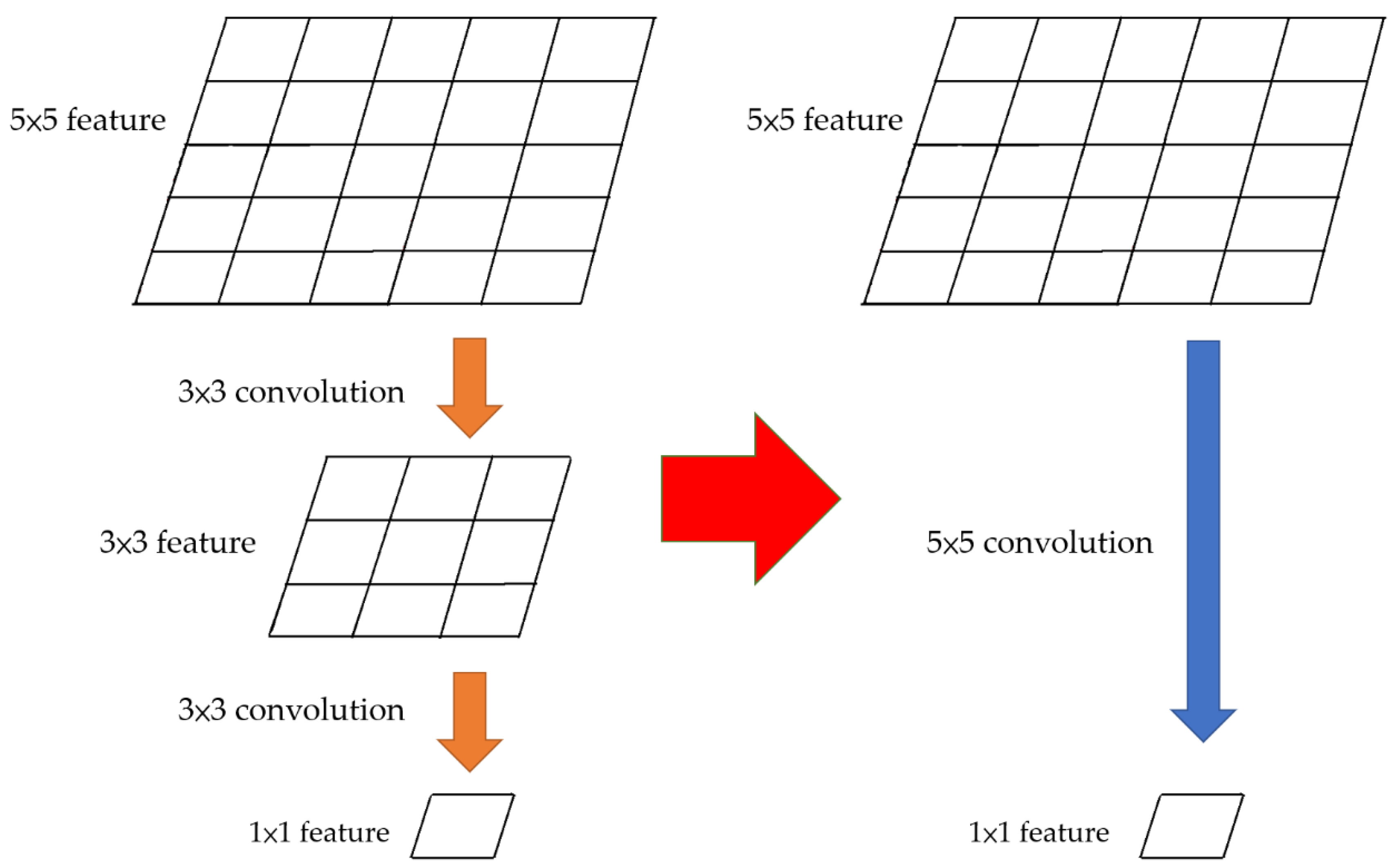
3.2.1. Separable Convolution
3.2.2. Reduction in Convolutional Layers
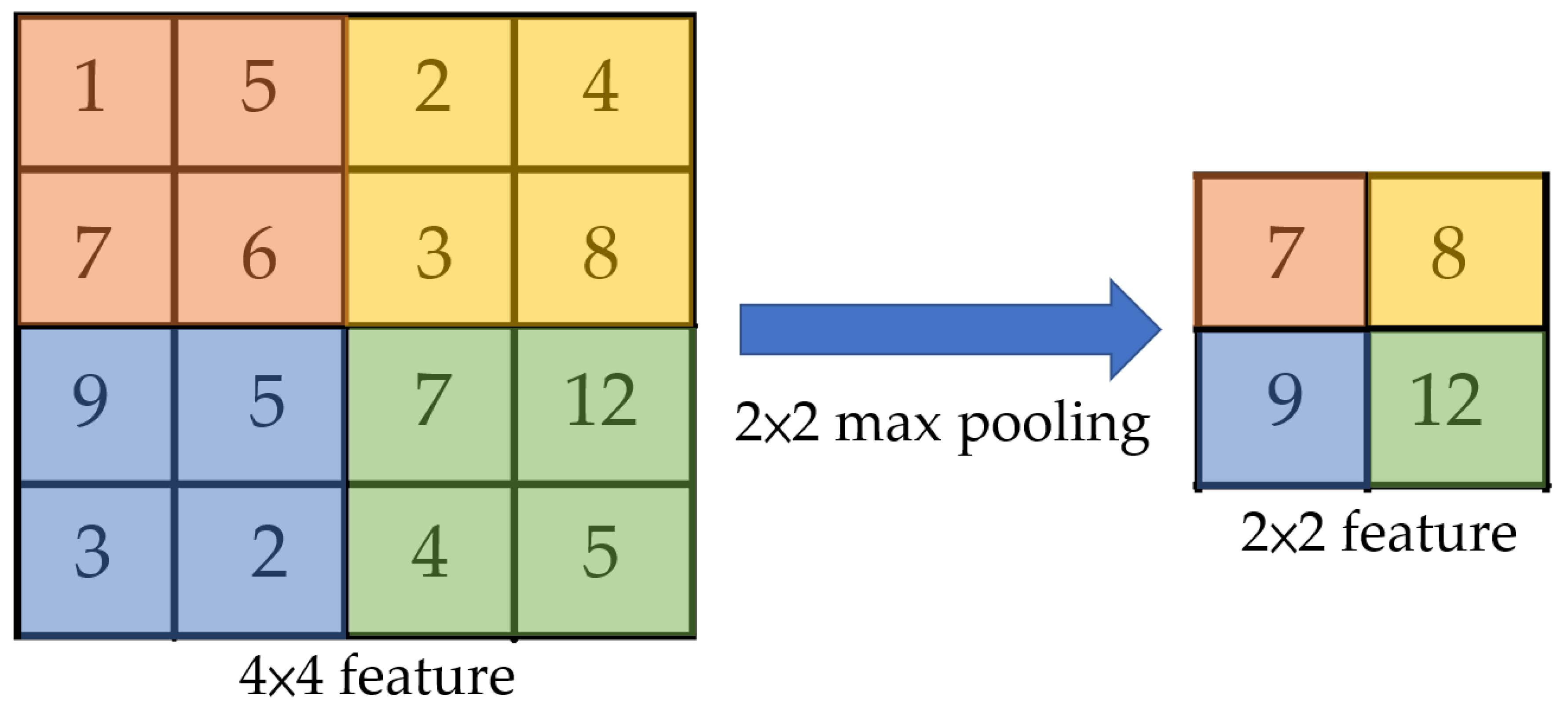
3.2.3. Remove Max Pooling and Maintain Output Size
4. Experiment
4.1. Hardware and Software Platform
4.2. Model-Switching Architecture with Classifiers
4.3. Lightweight Fully Convolutional Neural Network
4.4. Experimental Results
4.4.1. Comparison of Various Methods in Semantic Segmentation
4.4.2. Multi-Scenario Road Semantic Segmentation with Model-Switching Architecture
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alex, K.; Ilya, S.; Geoffrey, E.H. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2017, arXiv:1611.05431v2. [Google Scholar]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Philip, T. Res2Net: A New Multi-scale Backbone Architecture. arXiv 2019, arXiv:1904.01169v3. [Google Scholar] [CrossRef] [Green Version]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578v2. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. arXiv 2018, arXiv:1707.07012v4. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Li, F.F.; Yuille, A.; Huang, J.; Murphy, K. Progressive Neural Architecture Search. arXiv 2018, arXiv:1712.00559v3. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. arXiv 2019, arXiv:1807.11626v3. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861v1. [Google Scholar]
- Mark, S.; Andrew, H.; Zhu, M.; Andrey, Z.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381v4. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244v5. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083v2. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164v1. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946v3. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298v3. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation, Computing. arXiv 2015, arXiv:1411.4038v2. [Google Scholar]
- Vijay, B.; Alex, K.; Roberto, C. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2015, arXiv:1511.00561v3. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597v1. [Google Scholar]
- Fausto, M.; Nassir, N.; Ahmadi, S. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. arXiv 2016, arXiv:1606.04797v1. [Google Scholar]
- Zhou, Z.; Siddiquee, M.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Jiang, L.; Jia, J.; Philip, T.; Vladlen, K. Point Transformer. arXiv 2020, arXiv:2012.09164v1. [Google Scholar]
- Guo, M.; Cai, J.; Liu, Z.; Mu, T.; Ralph, R.M.; Hu, S. PCT: Point cloud transformer. arXiv 2021, arXiv:2012.09688v4. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030v1. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. arXiv 2017, arXiv:1612.01105v2. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFS. arXiv 2016, arXiv:1412.7062v4. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017, arXiv:1606.00915v2. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587v3. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611v3. [Google Scholar]
- Caio, C.; Vincent, F.; Denis, F. Vision-Based Road Detection using Contextual Blocks. arXiv 2015, arXiv:1509.01122v1. [Google Scholar]
- Rahul, M. Deep Deconvolutional Networks for Scene Parsing. arXiv 2014, arXiv:1411.4101v1. [Google Scholar]
- Chen, Z.; Chen, Z. RBNet: A Deep Neural Network for Unified Road and Road Boundary Detection. In Proceedings of the 24th International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017. [Google Scholar]
- Caio, C.; Vincent, F.; Denis, F. Exploiting Fully Convolutional Neural Networks for Fast Road Detection. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Marvin, T.; Michael, W.; Marius, Z.; Roberto, C.; Raquel, U. MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium, Changshu, China, 26–30 June 2018. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards Real-Time Semantic Segmentation for Autonomous Vehicles with Multi-Spectral Scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Sun, J.Y.; Kim, S.W.; Lee, S.W.; Kim, Y.W.; Ko, S.J. Reverse and Boundary Attention Network for Road Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Shinzato, P.Y.; Denis, F.W.; Christoph, S. Road Terrain Detection: Avoiding Common Obstacle Detection Assumptions Using Sensor Fusion. In Proceedings of the IEEE Intelligent Vehicles Symposium, Dearborn, MI, USA, 8–11 June 2014. [Google Scholar]
- Xiao, L.; Dai, B.; Liu, D.; Hu, T.; Wu, T. CRF based Road Detection with Multi-Sensor Fusion. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June–1 July 2015. [Google Scholar]
- Gu, S.; Zhang, Y.; Tang, J.; Yang, J.; Kong, H. Road Detection through CRF based LiDAR-Camera Fusion. In Proceedings of the International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Luca, C.; Mauro, B.; Lennart, S.; Mattias, W. LIDAR-Camera Fusion for Road Detection Using Fully Convolutional Neural Networks. arXiv 2018, arXiv:1809.07941v1. [Google Scholar]
- Gu, S.; Zhang, Y.; Yang, J.; Jose, M.A.; Kong, H. Two-View Fusion based Convolutional Neural Network for Urban Road Detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, The Venetian Macao, Macau, China, 4–8 November 2019. [Google Scholar]
- Sun, Y.; Zuo, W.; Liu, M. RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Fan, R.; Wang, H.; Cai, P.; Liu, M. SNE-RoadSeg: Incorporating Surface Normal Information into Semantic Segmentation for Accurate Freespace Detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Chen, Z.; Zhang, J.; Tao, D. Progressive LiDAR Adaptation for Road Detection. J. Autom. Sin. 2019, 6, 693–702. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- Kowsari, K.; Heidarysafa, M.; Brown, D.E.; Meimandi, K.J.; Barnes, L.E. RMDL: Random Multimodel Deep Learning for Clas-sification. arXiv 2018, arXiv:1805.01890v2. [Google Scholar]
- Tommasi, T.; Orabona, F.; Caputo, B. Learning Categories From Few Examples With Multi Model Knowledge Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 928–941. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, Q.; Zhang, R.; Shao, X. CNN and RNN mixed model for image classification. MATEC 2019, 277, 02001. [Google Scholar] [CrossRef]
- Ding, C.; Tao, D. Robust Face Recognition via Multimodal Deep Face Representation. IEEE Trans. Multimed. 2015, 17, 2049–2058. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classi-fication. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567v3. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Seg-mentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C. Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation. arXiv 2020, arXiv:2004.02147v1. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | |
|---|---|
| GPU | RTX2080TI |
| CPU | Intel Xeon E5-2620 |
| Motherboard | X79 |
| Memory | DDR3 64 GB 1333 Hz |
| Operation system | Ubuntu 18.04 |
| Programing language | Python 3.6 |
| Machine learning library | TensorFlow 1.14 |
| Method | Input | Max F1-Score | Avg PRE | Max PRE | REC |
|---|---|---|---|---|---|
| VGG16 FCN | Image | 0.9243 | 0.9810 | 1.0000 | 0.8779 |
| StixelNet II | Image | 0.9488 | 0.8775 | 0.9297 | 0.9687 |
| MultiNet | Image | 0.9488 | 0.9371 | 0.9484 | 0.9491 |
| RBNet | Image | 0.9497 | 0.9149 | 0.9494 | 0.9501 |
| LidCamNet | Image + LiDAR | 0.9603 | 0.9393 | 0.9623 | 0.9583 |
| NF2CNN | Image + LiDAR | 0.9670 | 0.8993 | 0.9537 | 0.9807 |
| PSPNet | Image | 0.9629 | 0.9371 | 0.9622 | 0.9635 |
| PLARD+ | Image + LiDAR | 0.9703 | 0.9403 | 0.9719 | 0.9688 |
| SNE-RoadSeg+ | RGB-D | 0.9740 | 0.9401 | 0.9801 | 0.9749 |
| LWF-VGG FCN tiny | Image | 0.9741 | 0.973 | 0.978 | 0.9751 |
| LWF-VGG FCN | Image | 0.9745 | 0.9655 | 1.0000 | 0.9845 |
| NTUT Sunny | Size | Avg IOU | Avg REC | Avg PRE | Avg F1-Score | FPS |
|---|---|---|---|---|---|---|
| MultiNet | 1.2 GB | 0.971 | 0.962 | 0.975 | 0.979 | 0.91 |
| VGG16-FCN | 1.6 GB | 0.987 | 0.980 | 0.980 | 0.980 | 0.87 |
| BiSeNet | 207 MB | 0.908 | 0.894 | 0.921 | 0.907 | 2.89 |
| BiSeNet V2 | 45.9 MB | 0.956 | 0.942 | 0.925 | 0.955 | 3.09 |
| LWF-VGG FCN tiny | 29 MB | 0.985 | 0.979 | 0.981 | 0.977 | 2.87 |
| LWF-VGG-FCN | 226 MB | 0.987 | 0.980 | 0.980 | 0.981 | 1.77 |
| NTUT cloudy | ||||||
| MultiNet | 1.2 GB | 0.959 | 0.948 | 0.961 | 0.964 | 0.91 |
| VGG16-FCN | 1.6 GB | 0.967 | 0.976 | 0.976 | 0.976 | 0.87 |
| BiSeNet | 207 MB | 0.890 | 0.906 | 0.904 | 0.912 | 2.89 |
| BiSeNet V2 | 45.9 MB | 0.937 | 0.954 | 0.952 | 0.961 | 3.09 |
| LWF-VGG FCN tiny | 29 MB | 0.970 | 0.974 | 0.977 | 0.975 | 2.87 |
| LWF-VGG-FCN | 226 MB | 0.972 | 0.978 | 0.981 | 0.980 | 1.77 |
| NTUT rainy | ||||||
| MultiNet | 1.2 GB | 0.795 | 0.778 | 0.802 | 0.811 | 0.91 |
| VGG16-FCN | 1.6 GB | 0.850 | 0.780 | 0.913 | 0.831 | 0.87 |
| BiSeNet | 207 MB | 0.774 | 0.792 | 0.806 | 0.809 | 2.89 |
| BiSeNet V2 | 45.9 MB | 0.815 | 0.804 | 0.811 | 0.852 | 3.09 |
| LWF-VGG FCN tiny | 29 MB | 0.942 | 0.944 | 0.940 | 0.936 | 2.87 |
| LWF-VGG-FCN | 226 MB | 0.945 | 0.945 | 0.941 | 0.939 | 1.77 |
| NTUT night rainy | ||||||
| MultiNet | 1.2 GB | 0.933 | 0.912 | 0.934 | 0.941 | 0.91 |
| VGG16-FCN | 1.6 GB | 0.940 | 0.959 | 0.959 | 0.965 | 0.87 |
| BiSeNet | 207 MB | 0.904 | 0.914 | 0.907 | 0.913 | 2.89 |
| BiSeNet V2 | 45.9 MB | 0.952 | 0.963 | 0.955 | 0.962 | 3.09 |
| LWF-VGG FCN tiny | 29 MB | 0.970 | 0.974 | 0.980 | 0.976 | 2.87 |
| LWF-VGG-FCN | 226 MB | 0.977 | 0.986 | 0.989 | 0.987 | 1.77 |
| Day and Night | Day | Night | Avg | Model Size | |
|---|---|---|---|---|---|
| VGG16 | 0.9992 | 0.9980 | 0.9986 | 1.6 GB | |
| LWF-VGG-tiny | 0.9976 | 0.9792 | 0.9884 | 32 MB | |
| LWF-VGG | 0.9989 | 0.9984 | 0.9986 | 230 MB | |
| Weather | Sunny | Cloudy | Rainy | ||
| VGG16 | 0.9955 | 0.9981 | 0.969 | 0.9875 | 1.6 GB |
| LWF-VGG-tiny | 0.9940 | 0.9912 | 0.974 | 0.9864 | 32 MB |
| LWF-VGG | 0.9954 | 0.9951 | 0.980 | 0.9902 | 230 MB |
| Multi-Model/Single-Model | Avg IOU | Avg REC | Avg PRE | Avg F1-Score | FPS |
|---|---|---|---|---|---|
| Single-model VGG16 FCN | 0.853 | 0.844 | 0.862 | 0.861 | 0.89 |
| Single-model LWF-VGG FCN tiny | 0.883 | 0.878 | 0.903 | 0.897 | 2.96 |
| Single-model LWF-VGG FCN | 0.891 | 0.884 | 0.902 | 0.903 | 1.80 |
| Multi-model VGG16 FCNs | 0.908 | 0.898 | 0.928 | 0.910 | 0.75 |
| Multi-model LWF-VGG FCNs tiny | 0.937 | 0.953 | 0.947 | 0.947 | 2.51 |
| Multi-model LWF-VGG FCNs | 0.949 | 0.952 | 0.951 | 0.952 | 1.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, P.-W.; Hsu, C.-M. Lightweight Convolutional Neural Networks with Model-Switching Architecture for Multi-Scenario Road Semantic Segmentation. Appl. Sci. 2021, 11, 7424. https://doi.org/10.3390/app11167424
Lin P-W, Hsu C-M. Lightweight Convolutional Neural Networks with Model-Switching Architecture for Multi-Scenario Road Semantic Segmentation. Applied Sciences. 2021; 11(16):7424. https://doi.org/10.3390/app11167424
Chicago/Turabian StyleLin, Peng-Wei, and Chih-Ming Hsu. 2021. "Lightweight Convolutional Neural Networks with Model-Switching Architecture for Multi-Scenario Road Semantic Segmentation" Applied Sciences 11, no. 16: 7424. https://doi.org/10.3390/app11167424