1. Introduction
With the advent of sequence-to-sequence models [
1,
2], response generation in open domain dialogues has made great progress. Nevertheless, most current response generators often make very general and unattractive responses such as “I don’t know” or “What are you talking about?” [
3,
4], since such responses are appropriate to any query. The same response to any query harms the reliability of dialogue-based systems, and thus it is regarded as one of the most critical problems in response generation.
Some previous studies noticed that the traditional loss functions, such as maximum likelihood, assign a high probability to
safe responses. One solution to avoid safe responses is to inject external knowledge into response generator. Ghazvininejad et al. adopted unstructured text knowledge [
5] and Wu et al. chose structured graph knowledge [
6] as external knowledge. However, this approach takes a great amount of memory and searching time during inference because appropriate external knowledge to a given query should be extracted from a knowledge base.
Another approach to creating diverse responses is to define a special loss function. The benefit of this approach is that it does not require any external knowledge. Li et al. showed that the bidirectional influence between a query and its response leads to the generation of more diverse and interesting responses [
7]. Thus, they proposed the maximum mutual information as a loss function to model the bidirectional influence. On the other hand, Wu et al. found out that general responses overwhelm specific ones in most dialogue corpora and thus they are preferred by response generators [
8]. As a solution to this problem, they proposed the max-marginal ranking loss to highlight the impact of less common but more relevant tokens in a query. However, since these loss functions focus only on the relation among tokens, they fail in capturing the entire context of a response.
This paper proposes a novel response generator—Response Generator with Response Weight (RGRW)—which reflects the importance of each token in a query with respect to the whole response. The proposed generator is an encoder–decoder model of which the encoder is pre-trained Bidirectional Encoder Representations from Transformers (BERT) [
9] and the decoder is a pre-trained Generative Pre-Training of a language model-2 (GPT-2) [
10]. In addition to them, it includes a
response weight, which captures the importance of every query token with respect to a response [
11]. Even though the BERT-encoder is trained to reflect a response, it fails in capturing whole key tokens of a query with respect to the response because it focuses on encompassing the information within a query. Thus, the response weight delivers the relevancy of each query token toward a response for the decoder, that is, it identifies the key query tokens for generating a response. Then, the decoder reflects the response weight in the response generation by paying more attention to the query tokens relevant to the generating response.
The effectiveness of the proposed response weight is proved with the short-text keyword detection task [
12]. For the experiment, the MAUI twitter data set, which consists of data pairs with short sentences and keywords of sentences, is used. Even if the response weight is not a direct keyword extractor, its performance on the MAUI twitter data set is competitive against those of direct keyword extractors. Especially, it outperforms the keyword extractor trained with non-MAUI twitter data. The performance of the response generation by RGRW is verified with the Reddit data set, an open-domain singleton dialogue data set [
13]. According to the experimental results, RGRW shows the highest score among the baselines in Distinct-
n and word-level Entropy, which implies that RGRW generates diverse and informative responses by focusing more on the tokens that are important for generating the response. Additionally, RGRW outperforms the state-of-the-art models, such as the Commonsense Knowledge-Aware Dialogue generation model (ConKADI).
The rest of this paper is organized as follows.
Section 2 explains the previous studies to generate diverse responses.
Section 3 introduces the need for the response weight and how to train it.
Section 4 describes the proposed model, RGRW.
Section 5 reports the experimental results on the MAUI Twitter data set and Reddit data set. Finally,
Section 6 draws conclusions.
2. Related Work
A number of efforts have been made to minimize the generation of general responses since the sequence-to-sequence model was introduced to response generation. Xu et al. tried to produce diverse responses by adopting a generative adversarial network (GAN) in which a discriminative classifier distinguishes machine-generated responses from human-made ones [
14]. Zhoa et al. defined response generation as a one-to-many mapping at the discourse level [
15]. Thus, they applied a conditional variational autoencoder (CVAE) in which a latent variable captures discourse-level variations. On the other hand, Li et al. distilled dialogue data to control the response specificity [
16]. They trained a sequence-to-sequence model with dialogue data to respond a query. Then, they removed the training examples from the data that are close to common responses, and then re-trained the model with the remaining data. Since their method produces multiple sequence-to-sequence models for different levels of specificity, they also trained a reinforcement learning system for choosing a model with the best specificity.
One of the main reasons for the preference for safe responses is the lack of background knowledge in a response generator. One representative approach to solve this problem is to provide extra information to a response generator [
17,
18]. For instance, an unstructured text was used as external knowledge for a fully data-driven neural dialogue system [
5], and a knowledge graph was adopted to provide common knowledge as external information [
6,
13]. Another way to provide background knowledge is to use a dialogue corpus with additional information [
19]. Zhang et al. and Rashkin et al. used a corpus with personal and empathetic information, respectively, to train their conversational agents [
20,
21]. However, it is very expensive in memory usage and requires a much longer inference time to use additional information. On the other hand, Jiang et al. noticed that the cross-entropy loss prefers high-frequent tokens to low-frequent ones [
22]. Thus, they proposed the frequency-aware cross-entropy loss to balance the number of identical tokens appearing in a response.
Some previous studies attempted to leverage the response quality by exploiting keywords in a query [
23]. Xing et al. obtained topic-related keywords from a pre-trained LDA model, and increased the probability of topic-related keywords through a joint attention mechanism [
24]. However, since they focused only on a query to obtain keywords, the keywords do not deliver any information residing on a response. Tang et al. extracted a keyword from a query to control the intended content of a response [
25]. Their method predicts a keyword from an entire dialogue history. As a result, the direct meaning of a current query is not reflected sufficiently. In addition, since their method extracts a single keyword from a query, it often misses the whole context of the query.
3. Learning Response Weight
The response weight aims at providing a decoder with the relatedness between a response and each token in a query.
Table 1 shows that it enhances the quality of a response to identify key tokens in a query under the response context and reflect them into response generation. In this table,
Q and
R indicate a query and its response, respectively. The bold words in the queries are the key tokens that are related highly with a response, and the underlined words are the tokens highlighted by the attention of a transformer encoder–decoder. In the first example, the encoder–decoder attention focuses only on ‘
orange or gold’, but the response contains the word ‘
choice’ due to the word ‘
pick’ in the query. All other examples also show a similar phenomenon. The expressions of ‘
try’ and ‘
still waiting’ appear at the responses because ‘
shot’ and ‘
haven’t received’ in the queries are response-related. Therefore, it helps to generate diverse responses to identify such key tokens in a query.
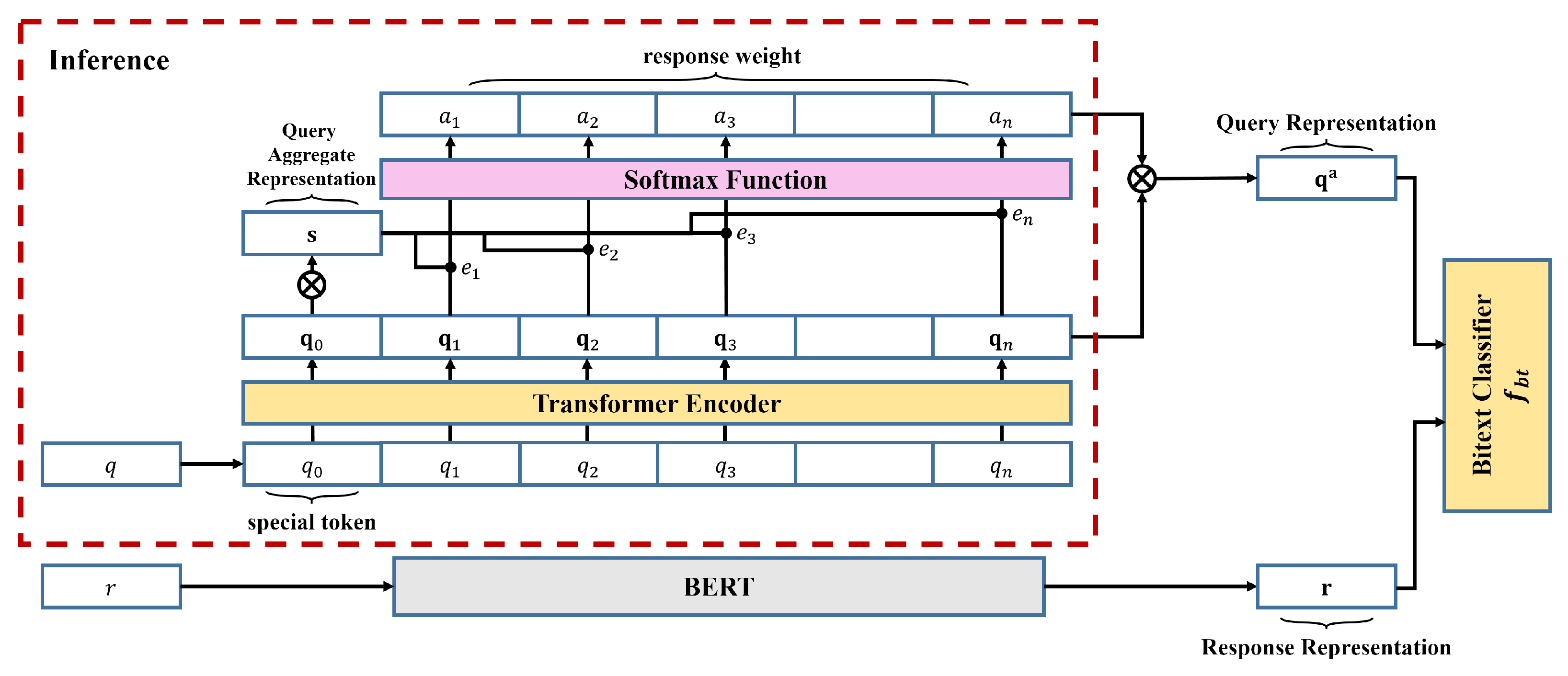
Figure 1 shows the overall architecture for computing the response weight. The response weight is obtained while representing a query
q into a query vector
with a transformer encoder so that
can reflect a potential response of
q. The transformer encoder is trained with a bitext classification task whose goal is to predict whether a query
q entails a response
r. In
Figure 1, the bitext classification is solved by the
bitext classifier which is implemented as a bilinear function, that is, the bitext classifier
determines the entailment between
q and
r by the following:
where
and
are vector representations of
q and
r, respectively, and
is a trainable weight matrix. This classifier is trained to maximize the log-likelihood by optimizing
and the parameters of the transformer encoder with the Adam optimizer [
26].
Note that is encoded by the transformer encoder. Thus, the transformer encoder is trained to express , similar to when q and r are a conversation pair from a real corpus. On the contrary, it encodes differently from , when q and r are from negatively-sampled data.
The representation of
q into
is done as follows. Denote
as a query composed of
n tokens. A special token
is added at the beginning of
q, and it plays a similar role to the
[cls] token of BERT. Thus, the output of the transformer encoder becomes
, where
aggregates the sequence representation of the query. To obtain a richer representation,
is linearly transformed to
s as follows:
where
and
are trainable parameters. Since
is a summary of the query
q, the importance of each query token
with respect to
is computed by
. Then, the final weight
is obtained by applying the softmax to
, that is, the weight is the following:
where
The final query representation
is computed by a weighted sum of
and
s, that is, the following:
The response
r is encoded as a vector
r by the BERT [
9] finetuned with only the responses of dialogue dataset. Then, the transformer encoder is trained to reflect the classification result of the bitext classifier.
At the inference time, the response
r is not available. Thus, only the transformer encoder boxed with red dotted lines in
Figure 1 is used to compute the response weight
a in Equation (
3) from a query
q. Since the transformer encoder is trained to reflect the response into encoding
q, the vector
is called the
response weight.
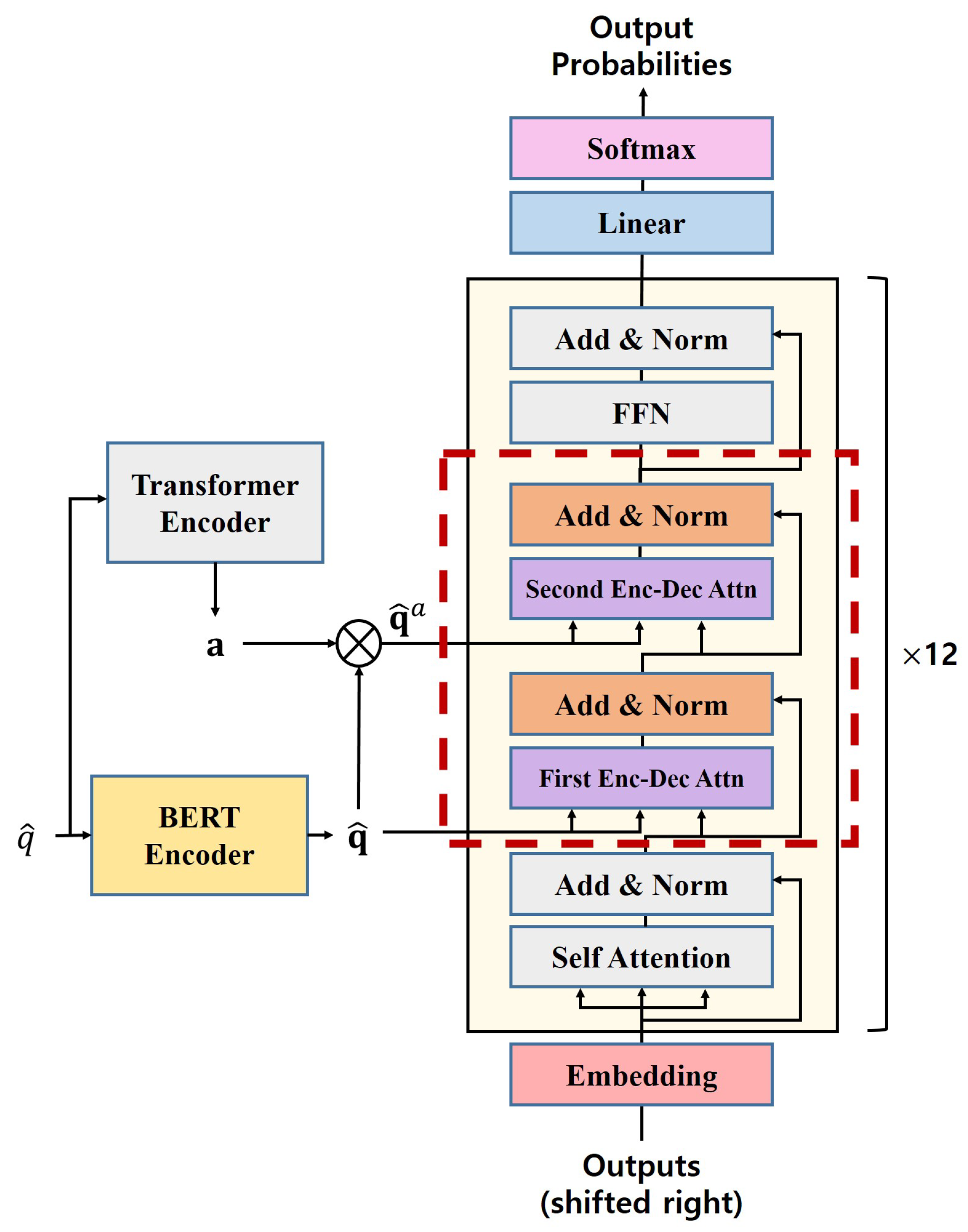
4. Response Generation with Response Weight
The proposed RGRW has a sequence-to-sequence architecture composed of a BERT encoder and a GPT-2 decoder as shown in
Figure 2. The key feature of the generator is that the decoder is given a response weight
as well as the vector representation
of a query
. As a result, the generator can make a response that follows both query and response contexts.
The encoder is a pre-trained BERT, and it takes a query
as an input and then outputs its vector representation
. The decoder has a transformer structure, but the main difference between the decoder and the standard transformer is that it takes two kinds of inputs:
and
. When a decoder has multiple encoding inputs, their concatenation is often used as a single input [
27,
28]. However, the concatenation of
and
makes it difficult to grasp the key context of
since the concatenation becomes just a lengthened representation of two similar encodings. Therefore, the proposed decoder has two individual attention layers that process
and
sequentially.
The first encoder–decoder attention layer uses
for both the key and value and the output of the self-attention layer for query. On the other hand, the second encoder–decoder attention layer uses a scalar multiple of
by an element of
for both the key and value, that is, when the length of a query
is
m, the key and value of the second encoder–decoder attention layer is the following:
where
. The query of this layer is the output of the first encoder-decoder attention layer. Therefore, the decoder grasps the overall context of
in the first encoder–decoder attention layer, and catches the response-related tokens of the query in the second encoder–decoder attention layer.
RGRW has twelve decoder blocks as shown in
Figure 2. Because the proposed structure is partially the same as that of GPT-2 [
10], the parameters of the pre-trained GPT-2 are borrowed to avoid excessive resource consumption. That is, only the two encoder–decoder attention layers boxed with red dotted lines in the figure are optimized during the training time, while other layers are all fixed. The AdamW optimizer [
29] is used for optimizing the response generator with the cross entropy loss.
5. Experiments
5.1. Experimental Settings
In order to train the proposed response weight and bitext classifier, the pairs of a query and a response are needed. Dailydialog [
30] is used for this purpose, as this data set contains open-domain multi-turn dialogue pairs. Since RGRW does not target multi-turn dialogues, the dialogue pairs in Dailydialog are converted into single-turn dialogue pairs by regarding the odd-numbered utterances and the even-numbered utterances as queries and responses, respectively.
The performance of the response weight is verified through
keyword detection. For this task, the MAUI Twitter data set [
31] is used, since the tweets are relatively short and the keywords are labeled at the tweets of this set by crowd-sourcing. The average tweet length is 78.55, and the average number of keywords per tweet is 3.92. Even if this data set has its own training and validation sets, only the test set is used in the experiments since the proposed response weight and bitext classifier are trained with Dailydialog.
The Reddit data set [
13] is adopted for the experiments of the response generator. The data set also consists of open-domain dialogues, but the dialogues are single-turn pairs. The queries and the responses that are shorter than four words or longer than 20 words are excluded from the data set following the study of Wu et al. [
6].
Table 2 summarizes the statistics on the data sets after pre-processing.
The hyper-parameters for the transformer encoder of the response weight are equivalent to those of the transformer base model. The dimension of embedding vector is 512, and that of the inner-layers of feed-forward networks is 2048. The number of heads in multi-head attention is eight, and the number of transformer encoder layers is six. The batch size of training and validation sets is 32, and the learning rate is 0.0001. In addition, label smoothing [
32] of
= 0.1 is used.
The encoder of the response generator is the pre-trained BERT base model, and the transformer decoder setting for response generation is similar to GPT-2. The embedding vector dimension is 768, and the inner-layers of feed-forward networks have 3072 dimensions. The number of heads in the multi-head attention is 12, and the number of transformer encoder layers is six. The batch size of training and validation sets is 32, and the learning rate is 6.25 ×.
5.2. Response Weight
Since the response weight aims at finding the importance of each query token, its performance is verified with a
keyword detection task. The proposed response weight is compared with five variations of MAUI [
31,
33], a strong keyword detection system trained with various features. MAUI-df is a default MAUI model trained with a decision tree and tf-idf, while MAUI-wv and MAUI-br use the structured skip-n-gram [
34] and the Brown cluster feature [
35] as well as the features of MAUI-df. MAUI-brwv uses all features stated above, and MAUI-out has the same structure as MAUI-brwv but is trained with the news articles used in the work of Marujo et al. [
36]. Note that MAUI-out is the only variant that is not trained with the MAUI Twitter data.
Table 3 summarizes the evaluation results. RW in this table is the proposed response weight. Since the proposed response weight is not a direct keyword detector, the words in a query are chosen as keywords when their
in Equation (
4) is greater than 0.3. All performances are measured for four extracted keywords. While MAUI-brwv shows the highest performance on F1-score, the proposed model ranks third. Note that RW is trained with Dailydialog, not with MAUI twitter data. Thus, it is difficult to compare the performance of RW directly with those of MAUI variants. Nevertheless, it outperforms MAUI-df, MAUI-wv, and MAUI-out. In particular, the fact that RW achieves higher performance than MAUI-out, another model trained with non-MAUI twitter data, proves the effectiveness of RW to identify keywords from a query.
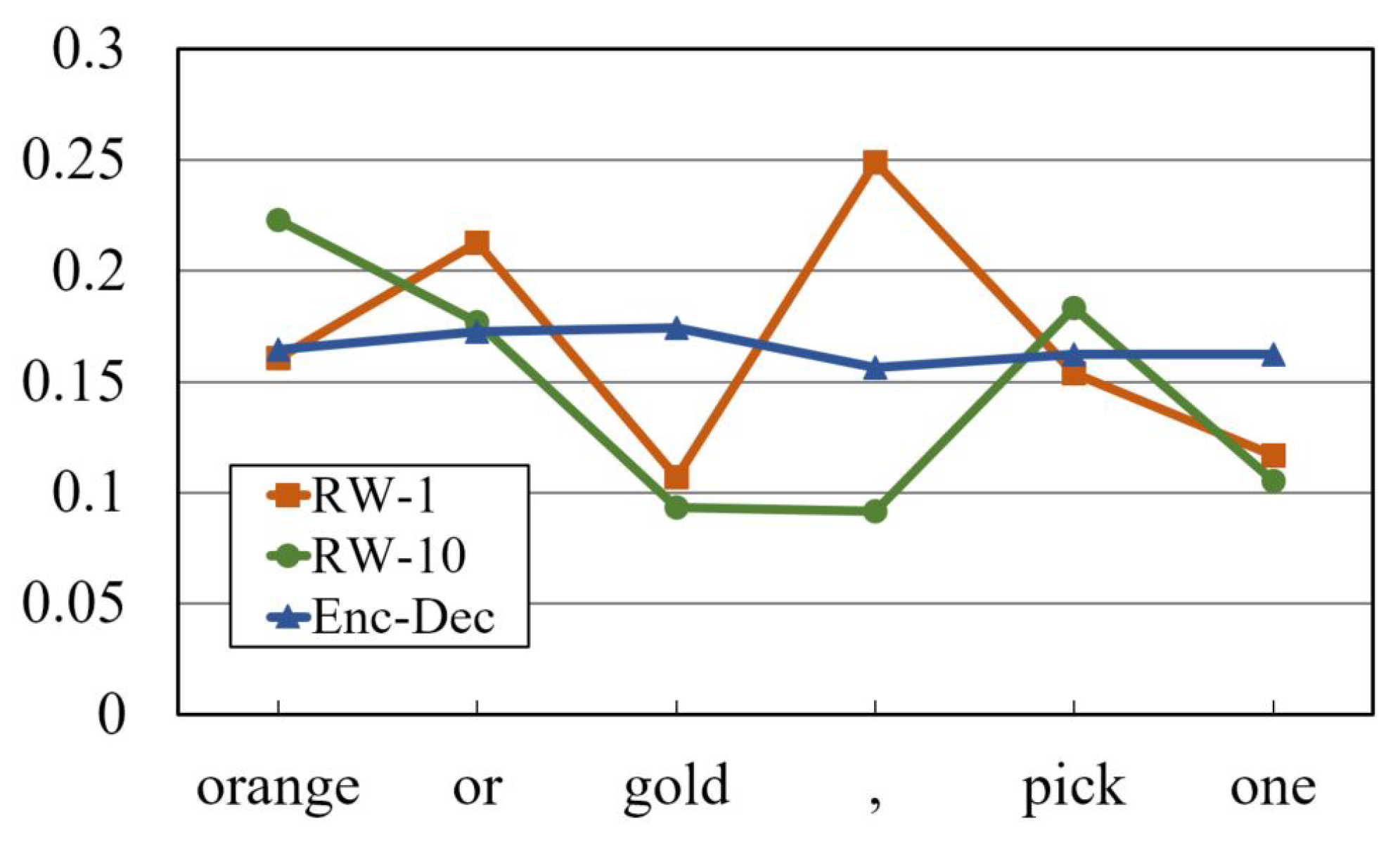
Figure 3 depicts the change of the response weight
during its training when the query is “
Orange or gold, pick one” and the response is “
Orange. Easy choice.” RW-1 and RW-10 in this figure are the response weights after one epoch and ten epochs, respectively, and Enc-Dec is the average attention of all heads in the encoder–decoder attention layer of a standard transformer. When the training of the proposed response weight is at one epoch, the meaningless or general tokens in the query such as ‘
or’ and ‘,’ have high weight. This is because neither the query nor the response is reflected enough to the weight. On the other hand, ‘
orange’ and ‘
pick’ have high attention after 10 epochs, since they are deeply related to ‘
orange’ and ‘
choice’ in the response.
The most important finding in this figure is that RW-10 shows a different weight distribution from Enc-Dec. Enc-Dec pays high attention to ‘gold’, ‘pick’, and ‘one’. Though the transformer reflects responses during its training, Enc-Dec is affected much more by the self-attention of the query. Thus, the word like ‘one’ that is not strongly related with the response is also spotlighted. In addition, the attention difference in Enc-Dec is insignificant. To sum up all these results, better responses can be generated by enhancing the influence of the response through the response weight.
5.3. Response Generator
The performance of RGRW is compared with those of five baselines, which are TS2S, COPY, GenDS, CCM and ConKADI. TS2S is a transformer with six blocks of an encoder and a decoder. COPY is an LSTM-based sequence-to-sequence model with the copy mechanism [
37] and GenDS generates responses from the candidate facts retrieved from a knowledge base [
38]. CCM [
13] and ConKADI [
6] are commonsense knowledge-aware response generators. The responses in the training set are used as posterior knowledge when training ConKADI, but they are not used in CCM.
The performance of the models is measured with eight automatic metrics. Emb
[
39] is the similarity between the average embedding vector of a ground-truth response and that of the generated response, while Emb
measures the similarity between embedding vectors using vector extrema. Bleu-2 and Bleu-3 are the ratio of bi-gram and tri-gram overlaps, respectively [
40], and Dist-1 and Dist-2 are the ratio of distinct uni-grams and bi-grams in all generated responses [
7]. Entropy is the average word-level entropy [
41]. The
is the relative score of a model when the arithmetic mean of metric scores of all other comparison models is set to 1.00 [
6].
The results on these metrics are shown at
Table 4. RGRW achieves the highest scores for all metrics, except Bleu and Emb
. For both Bleu-2 and Bleu-3, RGRW shows the second lowest performance. The generated responses are often acceptable, even if they are different from the ground-truth responses. Thus, the sole measurement with Bleu has a limit to evaluate the quality of responses.
The embedding metric is one of the metrics that solve the limitation of Bleu. It compares the contexts of the generated responses and the ground-truth responses. GenDS shows the highest performance in Emb
, while RGRW achieves the best performance in Emb
. In general, the embedding vectors of general words are located close to the origin and the vectors of contextually important words are far from the origin. Thus, Emb
focuses more on contextually important words than general words [
39]. In other words, the responses generated by RGRW are more similar to the key topics of ground-truth responses than those by other baselines.
Dist-1, Dist-2, and entropy measure how diverse and informative the generated responses are. RGRW shows the best performance for these metrics. One thing to note is that the higher the Bleu score that a model shows, the lower the diversity and informative scores that it achieves. This is because focusing on lexical coincidence with the ground-truth response affects the generation of diverse responses negatively. Finally, RGRW outperforms all baselines in . In particular, it shows 0.07 higher than ConKADI, the best baseline.
Summarizing all the results, RGRW generates a response that is not only lexically similar, but also contextually similar to a ground-truth response. In addition, RGRW generates more diverse and informative responses by adopting the response weight. All these results prove that the response generation through response weight is effective in producing diverse and context-preserving responses.
The effectiveness of the structure with two attention layers is shown by an ablation study with the encoder–decoder attention (EDA) and the response weight (RW).
Table 5 shows the results of the ablation study on the Reddit data set. Without EDA, RGRW is influenced only by RW. As a result, the Dist-2 and entropy of ‘- EDA’ are rather higher than those of RGRW, but its Bleu-2 and
become lower than those of RGRW. This is because the information in a query is not delivered enough to the decoder. Without RW, RGRW is equivalent to a sequence-to-sequence model with a BERT encoder and a GPT-2 decoder. Since the decoder of ‘- RW’ does not receive the response weight, Dist-2 and the entropy of the model are much lower than those of RGRW. One thing to note in this table is that RGRW shows higher
than both ‘- EDA’ and ‘- RW’, which implies that the response weight does not contribute only to the generation of diverse responses, but also helps generate the responses similar to the ground-truth ones.
5.4. Case Study
Table 6 shows two examples that compare the responses generated with the response weight and those without the attention. If the response weight is removed from RGRW, RGRW becomes equivalent to a sequence-to-sequence model with a BERT-encoder and a GPT-2 decoder. Thus, the responses in ‘Without RW’ in this table are the outputs of the GPT-2 decoder, while those in ‘With RW’ are the outputs of RGRW. In each example, the attention by the BERT-encoder (blue line) and the proposed response weight (red line) are depicted as graphs. In these graphs, the attention weights are expressed per a word unit for easy interpretation, where the attention weight of a word is obtained as an average of the attention weights for the subwords of the word. Note that the values for the response weight are
s in Equation (
4).
According to the table, ‘With RW’ generates responses more similar to the ground-truth ones and less general than the ‘Without RW’ ones. In the first example, ‘love’ and ‘gave’ have high BERT attention weights. As a result, the GPT-2 decoder generates the word ‘have’ in the response of ‘Without RW’, and the response is semantically unrelated with the ground-truth one. On the other hand, all words in the phrase of ‘gave it a shot’ have high values. Since RGRW pays high response weight to ‘gave it a shot’, the response in ‘With RW’ follows the ground-truth one more semantically.
In the second example, ‘them’ and ‘salt’ are stressed on in the BERT attention, which leads to the generation of a very general answer in the response of ‘Without RW’. On the other hand, RGRW focuses on the words ‘cucumber’, ‘them’, and ‘munch’ with high response weight. In particular, the focus on ‘munch’ results in the generation of ‘try’ and ‘taste’ in the response of ‘With RW’. In addition, the generated answer is much less general and semantically similar to the ground-truth response, though the sentiment polarity of the answer is opposite to that of the ground-truth one.
6. Conclusions and Future Work
This paper proposes RGRW, a novel response generator in which the effect of a potential response is reflected strongly through response weight. By adopting the response weight, RGRW is able to reduce generating safe responses and make a response in accordance with a query. In order to obtain an optimal response weight, the bitext classifier is trained to distinguish whether a pair of a query and a response is real or not. Training of the bitext classifier leads to adaptation of the response weight and the transformer encoder to a response. As a result, the response weight is able to reflect a potential response into a query attention.
The proposed generator, RGRW consists of a BERT-encoder and a GPT-2-like decoder, where the decoder has two additional encoder–decoder attention layers to GPT-2. The first attention layer processes the overall context of a query given by the BERT-encoder, and the second attention layer catches the response-related tokens of the query using the response weight. To avoid excessive resource consumption, the parameters of the layers equivalent to GPT-2 are borrowed from the original GPT-2 and fixed, while those of the two attention layers are optimized newly.
The proposed response weight was verified through the short-text keyword detection on the MAUI Twitter data. Even if the response weight is trained on Dailydialog data, it shows competitive keyword extraction performance on the MAUI Twitter data. In particular, it outperforms other keyword extractors trained with non-MAUI data. It was also shown empirically for RGRW to generate more diverse and informative responses than the current state-of-the-art methods on the Reddit data set. RGRW achieves the best Emb, according to the experimental results, which implies that the responses of RGRW are semantically similar to ground-truth ones. In addition, through an ablation study, the effectiveness of the proposed structure of RGRW with two attention layers was proved. Unlike ConKADI, RGRW does not use external knowledge, so it does not require knowledge retrieving time during inference. Therefore, the inference speed is relatively faster than ConKADI. In addition, it takes less training time than a general transformer sequence-to-sequence model because it does not train all parameters of the model.
The RGRW approach has certain limitations. RGRW freezes some layers for efficient transfer learning when fine-tuning. Recently, a transfer learning method in which only low-level filters are transferred and frozen was proposed in the image generation task [
42]. This study is based on research showing that low-level filters capture generality well. On the other hand, RGRW performs the transfer and freezing of all blocks equally without understanding the characteristics of each decoder block. Therefore, as part of future work, we will study how to differentiate the transfer learning by understanding the role of each decoder block.







{kind=link}
{kind=link}
{kind=link}

