
Privacy Preserving Classification of EEG Data Using Machine Learning and Homomorphic Encryption

Abstract
:1. Introduction
2. Methods
2.1. Encoding Scheme
2.2. Optimization Formulation
2.3. Use Case 1—Seizure Detection
2.4. Use Case 2—Predisposition to Alcoholism
3. Results
3.1. Synthetic Data
3.2. Use Case 1—Seizure Detection
- Using all 178 initial data points in each sample as input.
- Using all 178 initial data points in each sample and the 178 corresponding quadratic terms (356 features overall).
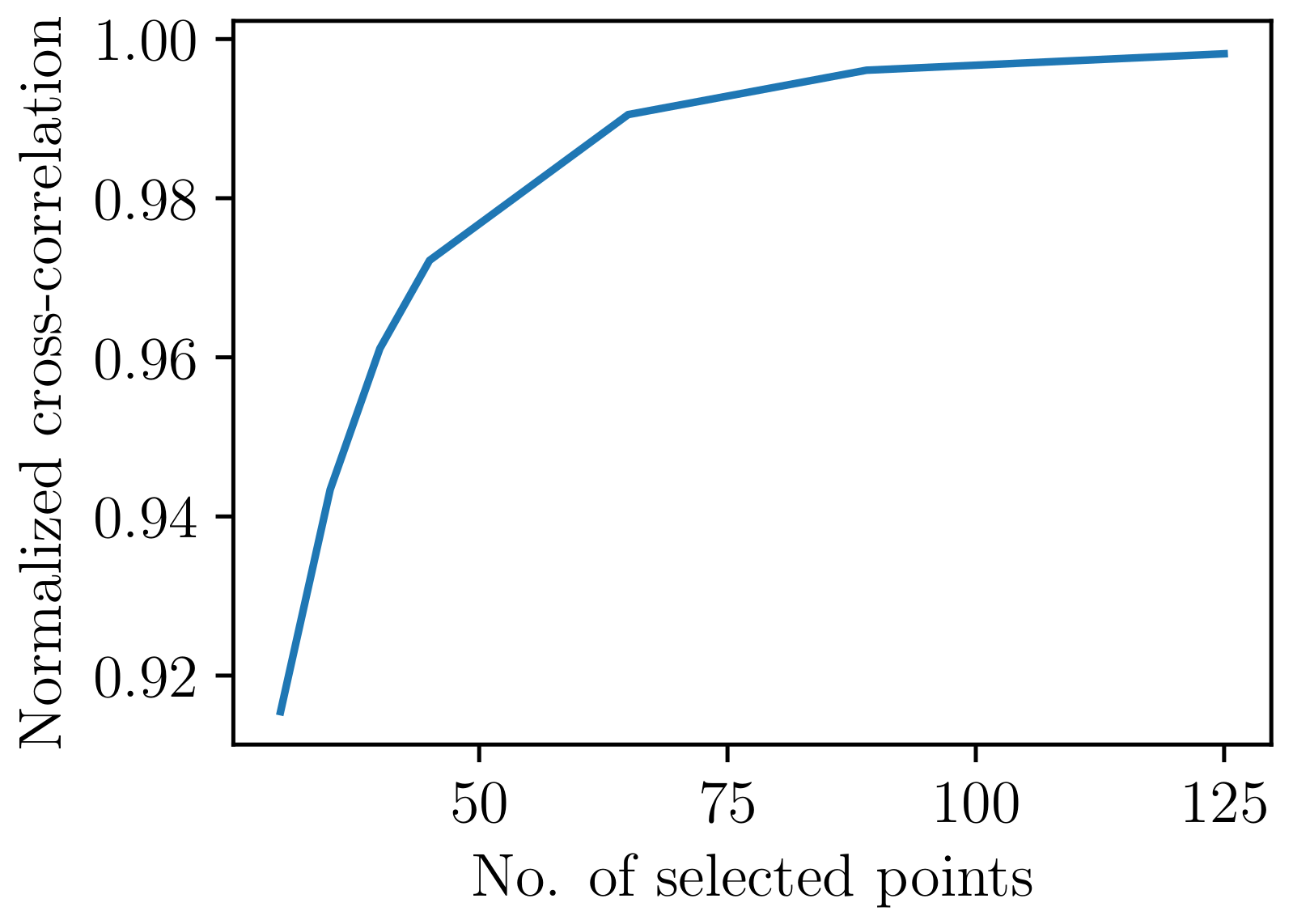
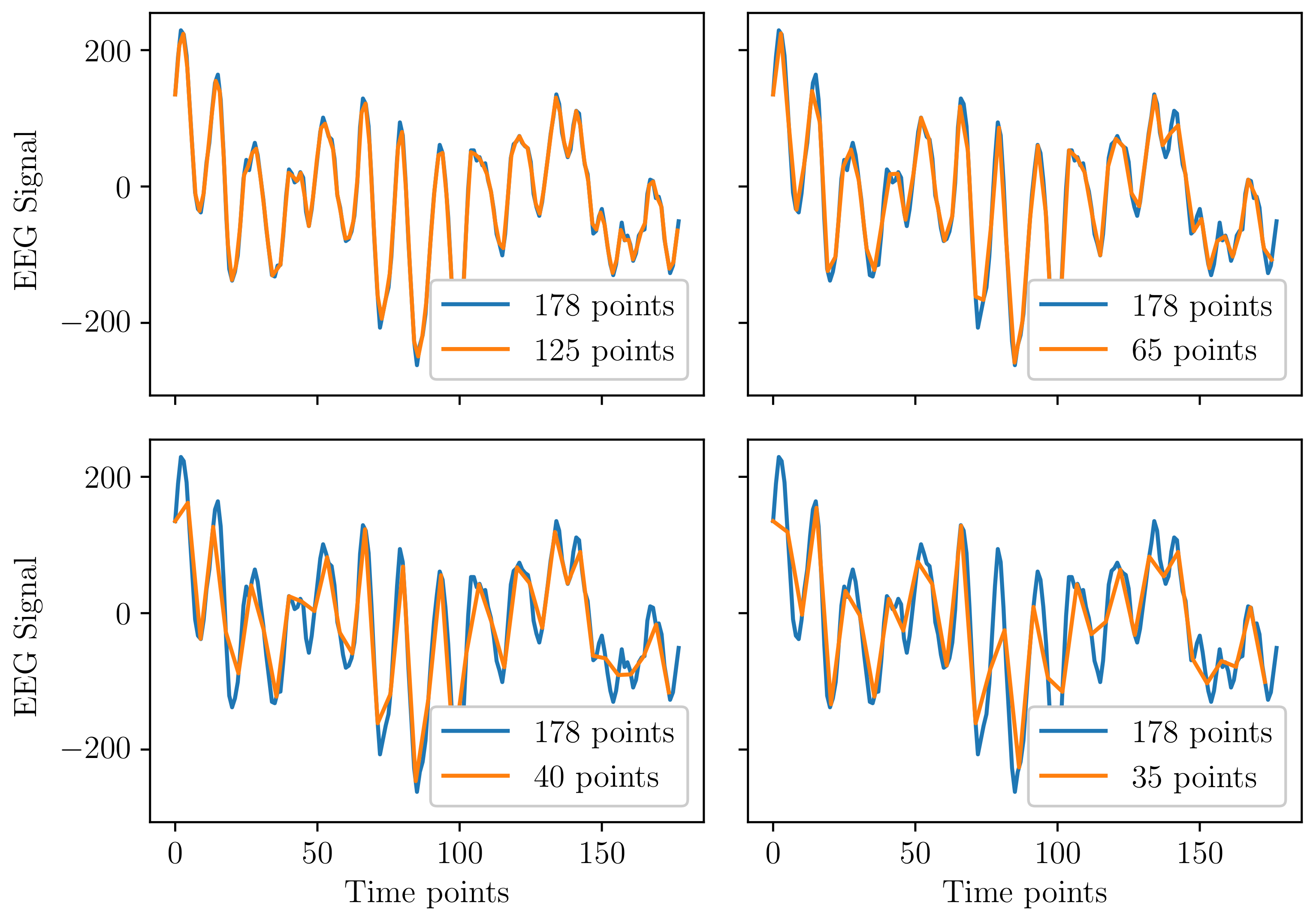
- Using a downsampled version of each sample. The number of data points was gradually reduced from 178, and the mean NCC over the entire dataset was computed for each downsampled version. We selected the downsampled version with the smallest number of data points for which the average NCC was still larger than 0.95. The selected downsampled version had 40 features (instead of the initial 178) and the corresponding quadratic terms were added, leading to a total of 80 features per sample. Figure 1 displays the variation of the mean NCC as a function of the number of samples. Figure 2 displays, for one signal, the original sample and the resampled sample for different numbers of data points.
3.3. Use Case 2—Predisposition to Alcoholism
- — The machine learning models were trained on the original dataset (153,600 samples and 64 features).
- — The machine learning models were trained on 10,000 balanced samples. The number of features was unchanged: 64. This is the baseline experiment to be conducted also on the ciphertext data ( cannot be run on ciphertext since the number of samples is too large).
- — The machine learning models were trained on the entire dataset (153,600 samples) and all polynomial combinations of features with degrees less than or equal to 2 were considered, leading to a total of 2145 features. The idea is to determine whether increasing the model complexity leads to better performance. Due to the large number of features, it is not feasible to run this experiment on ciphertext data.
- — The machine learning models were trained on 10,000 balanced samples with 128 features (the original 64 and their quadratic terms). Considering the computational overhead introduced by the encoding and encryption steps, represents a suitable trade-off solution.
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Briefings Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef] [PubMed]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Mohassel, P.; Zhang, Y. Secureml: A system for scalable privacy-preserving machine learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private recurrent language models. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Phan, N.; Wang, Y.; Wu, X.; Dou, D. Differential privacy preservation for deep auto-encoders: An application of human behavior prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Orlandi, C.; Piva, A.; Barni, M. Oblivious neural network computing via homomorphic encryption. EURASIP J. Inf. Secur. 2007, 2007, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 201–210. [Google Scholar]
- Bos, J.W.; Lauter, K.; Loftus, J.; Naehrig, M. Improved security for a ring-based fully homomorphic encryption scheme. In Proceedings of the IMA International Conference on Cryptography and Coding, Oxford, UK, 17–19 December 2013; pp. 45–64. [Google Scholar]
- Hesamifard, E.; Takabi, H.; Ghasemi, M. Cryptodl: Deep neural networks over encrypted data. arXiv 2017, arXiv:1711.05189. [Google Scholar]
- Fan, J.; Vercauteren, F. Somewhat practical fully homomorphic encryption. IACR Cryptol. ePrint Arch. 2012, 2012, 144. [Google Scholar]
- Microsoft Research. Microsoft SEAL (Release 3.6); Microsoft Research: Redmond, WA, USA, 2020; Available online: https://github.com/Microsoft/SEAL (accessed on 14 April 2021).
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; pp. 409–437. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International conference on the theory and applications of cryptographic techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- ElGamal, T. A public key cryptosystem and a signature scheme based on discrete logarithms. IEEE Trans. Inf. Theory 1985, 31, 469–472. [Google Scholar] [CrossRef]
- Chen, H.; Laine, K.; Player, R.; Xia, Y. High-precision arithmetic in homomorphic encryption. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 16–20 April 2018; pp. 116–136. [Google Scholar]
- Chen, H.; Laine, K.; Player, R. Simple encrypted arithmetic library-SEAL v2. 1. In Proceedings of the International Conference on Financial Cryptography and Data Security, Sliema, Malta, 3–7 April 2017; pp. 3–18. [Google Scholar]
- Arita, S.; Nakasato, S. Fully homomorphic encryption for point numbers. In Proceedings of the International Conference on Information Security and Cryptology, Beijing, China, 4–6 November 2016; pp. 253–270. [Google Scholar]
- Dowlin, N.; Gilad-Bachrach, R.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Manual for using homomorphic encryption for bioinformatics. Proc. IEEE 2017, 105, 552–567. [Google Scholar] [CrossRef]
- Fouque, P.A.; Stern, J.; Wackers, G.J. Cryptocomputing with rationals. In Proceedings of the International Conference on Financial Cryptography, Southampton, Bermuda, 11–14 March 2002; pp. 136–146. [Google Scholar]
- Moon, S.; Lee, Y. An efficient encrypted floating-point representation using HEAAN and TFHE. Secur. Commun. Netw. 2020, 2020, 1250295. [Google Scholar] [CrossRef] [Green Version]
- Jäschke, A.; Armknecht, F. (Finite) field work: Choosing the best encoding of numbers for FHE computation. In Proceedings of the International Conference on Cryptology and Network Security, Hong Kong, China, 30 November–2 December 2017; pp. 482–492. [Google Scholar]
- Jäschke, A.; Armknecht, F. Accelerating homomorphic computations on rational numbers. In Proceedings of the International Conference on Applied Cryptography and Network Security, London, UK, 19–22 June 2016; pp. 405–423. [Google Scholar]
- Lin, C.F.; Shih, S.H.; Zhu, J.D. Chaos based encryption system for encrypting electroencephalogram signals. J. Med. Syst. 2014, 38, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, M.; Farooq, O.; Datta, S.; Sohail, S.S.; Vyas, A.L.; Mulvaney, D. Chaos-based encryption of biomedical EEG signals using random quantization technique. In Proceedings of the 2011 4th International Conference on Biomedical Engineering and Informatics (BMEI), Shanghai, China, 15–17 October 2011; Volume 3, pp. 1471–1475. [Google Scholar]
- Liu, Y.; Huang, H.; Xiao, F.; Malekian, R.; Wang, W. Classification and recognition of encrypted EEG data based on neural network. J. Inf. Secur. Appl. 2020, 54, 102567. [Google Scholar] [CrossRef]
- Xiang, G.; Chen, X.; Zhu, P.; Ma, J. A method of homomorphic encryption. Wuhan Univ. J. Nat. Sci. 2006, 11, 181–184. [Google Scholar]
- Sathya, S.S.; Vepakomma, P.; Raskar, R.; Ramachandra, R.; Bhattacharya, S. A review of homomorphic encryption libraries for secure computation. arXiv 2018, arXiv:1812.02428. [Google Scholar]
- Babyak, M.A. What you see may not be what you get: A brief, nontechnical introduction to overfitting in regression-type models. Psychosom. Med. 2004, 66, 411–421. [Google Scholar] [PubMed] [Green Version]
- Alomari, M.H.; AbuBaker, A.; Turani, A.; Baniyounes, A.M.; Manasreh, A. EEG mouse: A machine learning-based brain computer interface. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 193–198. [Google Scholar]
- Shenoy, H.V.; Vinod, A.P.; Guan, C. Shrinkage estimator based regularization for EEG motor imagery classification. In Proceedings of the 2015 10th International Conference on Information, Communications and Signal Processing (ICICS), Singapore, 2–4 December 2015; pp. 1–5. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 061907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 21 March 2021).
- Bressert, E. SciPy and NumPy: An Overview for Developers; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Sun, Y.; Ye, N.; Xu, X. EEG analysis of alcoholics and controls based on feature extraction. In Proceedings of the 2006 8th International Conference on Signal Processing, Guilin, China, 16–20 November 2006; Volume 1. [Google Scholar]
- Snodgrass, J.G.; Vanderwart, M. A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. J. Exp. Psychol. Hum. Learn. Mem. 1980, 6, 174. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Data 178 Features | Quadratic Data 356 Features | Resampled Data 80 Features | |||||
|---|---|---|---|---|---|---|---|
| PR | SVM | PR | SVM | PR Plaintext | PR Ciphertext | SVM | |
| Accuracy | 80.59 | 95.78 | 89.22 | 95.86 | 92.26 | 92.26 | 95.85 |
| Sensitivity | 34.25 | 98.82 | 84.40 | 98.60 | 86.56 | 86.56 | 98.70 |
| Specificity | 92.17 | 95.02 | 90.43 | 95.17 | 93.68 | 93.68 | 95.14 |
| PPV | 52.46 | 83.23 | 68.81 | 83.62 | 77.44 | 77.44 | 83.54 |
| NPV | 84.86 | 99.69 | 95.86 | 99.63 | 95.54 | 95.54 | 99.65 |
| Plaintext | Ciphertext | Ciphertext Parallelized | |
|---|---|---|---|
| Training runtime/fold | 0.0119 s | 23.60 h | 7.05 h |
| Inference runtime/sample | 1.73 × 10 s | 0.012 s |
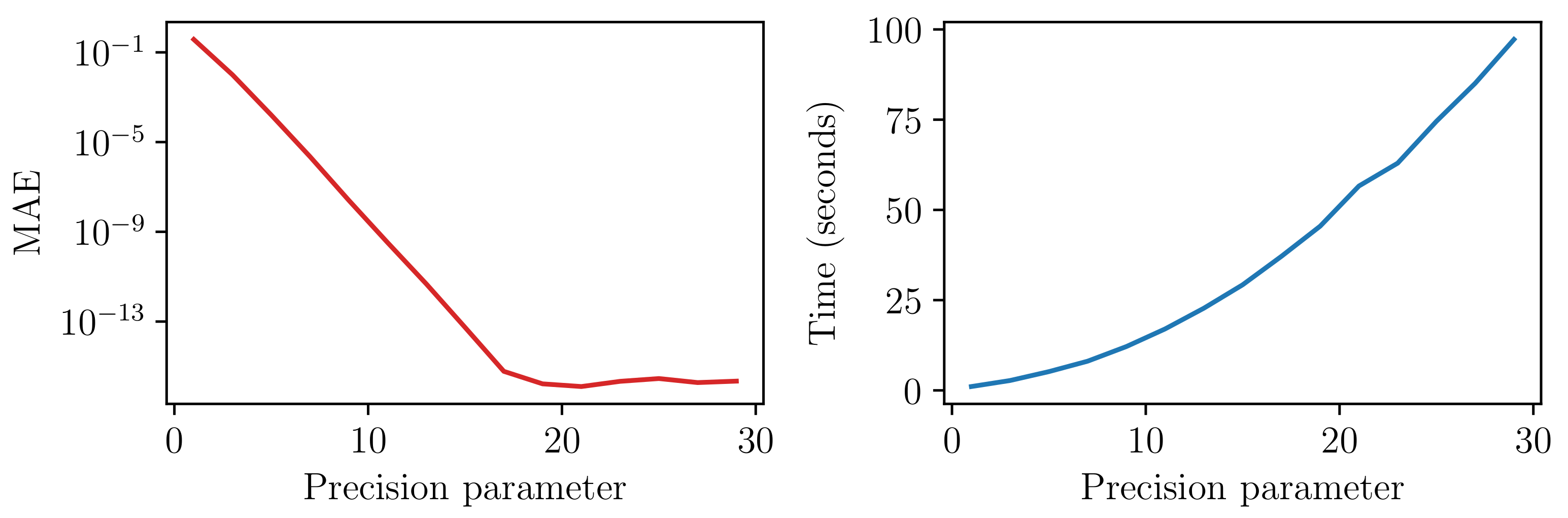
| Precision Parameter (Number of Terms) | |||||||
|---|---|---|---|---|---|---|---|
| 35 | 32 | 29 | 26 | 23 | 21 | 20 | |
| Loss in accuracy | 0 | 0 | 0 | 0 | 0 | 0 | 1.66 |
| Runtime/fold (hours) | 7.05 | 6.02 | 4.69 | 3.89 | 2.97 | 2.41 | 2.16 |
(153,600, 64) | (10,000, 64) | (153,600, 2145) | (10,000, 128) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PR | SVM | PR | SVM | PR | SVM | PR Plain Text | PR Ciphertext | SVM | |
| Accuracy | 57.34 | 87.46 | 57.27 | 79.33 | 83.92 | 84.27 | 68.52 | 68.52 | 79.08 |
| Sensitivity | 57.26 | 89.06 | 61.20 | 80.15 | 83.81 | 83.97 | 68.45 | 68.45 | 79.22 |
| Specificity | 57.43 | 85.86 | 53.35 | 78.51 | 84.03 | 84.57 | 68.59 | 68.59 | 78.94 |
| PPV | 57.35 | 86.30 | 56.74 | 78.86 | 84.00 | 84.48 | 68.55 | 68.55 | 79.00 |
| NPV | 58.85 | 88.70 | 57.90 | 79.82 | 83.85 | 84.07 | 68.49 | 68.49 | 79.16 |
(153,600, 64) | (10,000, 64) | (153,600, 2145) | (10,000, 128) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PR | SVM | PR | SVM | PR | SVM | PR Plain Text | PR Ciphertext | SVM | |
| Accuracy | 59.66 | 96.66 | 60.16 | 94.16 | 95.50 | 93.66 | 79.83 | 79.83 | 96.16 |
| Sensitivity | 63.00 | 98.00 | 65.33 | 95.66 | 97.33 | 95.33 | 77.66 | 77.66 | 97.66 |
| Specificity | 56.33 | 95.33 | 55.00 | 92.66 | 93.66 | 92.00 | 82.00 | 82.00 | 94.66 |
| PPV | 50.06 | 95.45 | 59.21 | 92.88 | 93.89 | 92.25 | 81.18 | 81.18 | 94.82 |
| NPV | 60.35 | 97.94 | 61.33 | 95.53 | 97.23 | 95.17 | 78.59 | 78.59 | 97.59 |
| Plaintext | Ciphertext | Ciphertext Parallelized | |
|---|---|---|---|
| Training | 0.0286 s | 59.69 h | 32.28 h |
| Inference | 3.46 × 10 s | 0.018 s |
| Precision Parameter (Number of Terms) | ||||||||
|---|---|---|---|---|---|---|---|---|
| 35 | 32 | 29 | 26 | 23 | 20 | 17 | 14 | |
| Loss in accuracy | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.41 |
| Runtime (hours) | 32.28 | 26.53 | 22.17 | 17.91 | 13.02 | 10.90 | 8.16 | 5.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Popescu, A.B.; Taca, I.A.; Nita, C.I.; Vizitiu, A.; Demeter, R.; Suciu, C.; Itu, L.M. Privacy Preserving Classification of EEG Data Using Machine Learning and Homomorphic Encryption. Appl. Sci. 2021, 11, 7360. https://doi.org/10.3390/app11167360
Popescu AB, Taca IA, Nita CI, Vizitiu A, Demeter R, Suciu C, Itu LM. Privacy Preserving Classification of EEG Data Using Machine Learning and Homomorphic Encryption. Applied Sciences. 2021; 11(16):7360. https://doi.org/10.3390/app11167360
Chicago/Turabian StylePopescu, Andreea Bianca, Ioana Antonia Taca, Cosmin Ioan Nita, Anamaria Vizitiu, Robert Demeter, Constantin Suciu, and Lucian Mihai Itu. 2021. "Privacy Preserving Classification of EEG Data Using Machine Learning and Homomorphic Encryption" Applied Sciences 11, no. 16: 7360. https://doi.org/10.3390/app11167360