
A Payload Based Malicious HTTP Traffic Detection Method Using Transfer Semi-Supervised Learning


Abstract
:1. Introduction
2. Related work
2.1. Malicious Network Traffic Detection
2.2. Small Data Learning
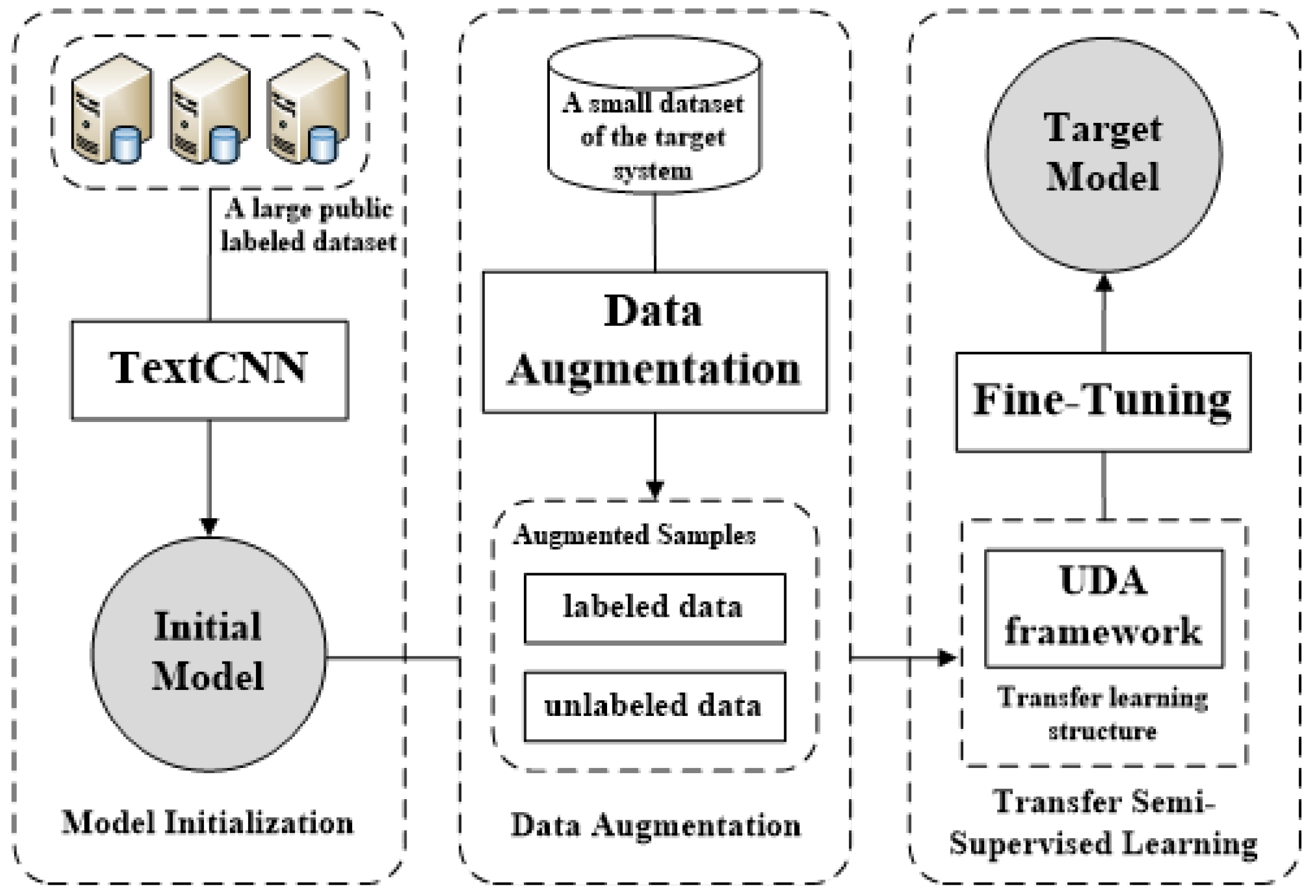
3. Methodology
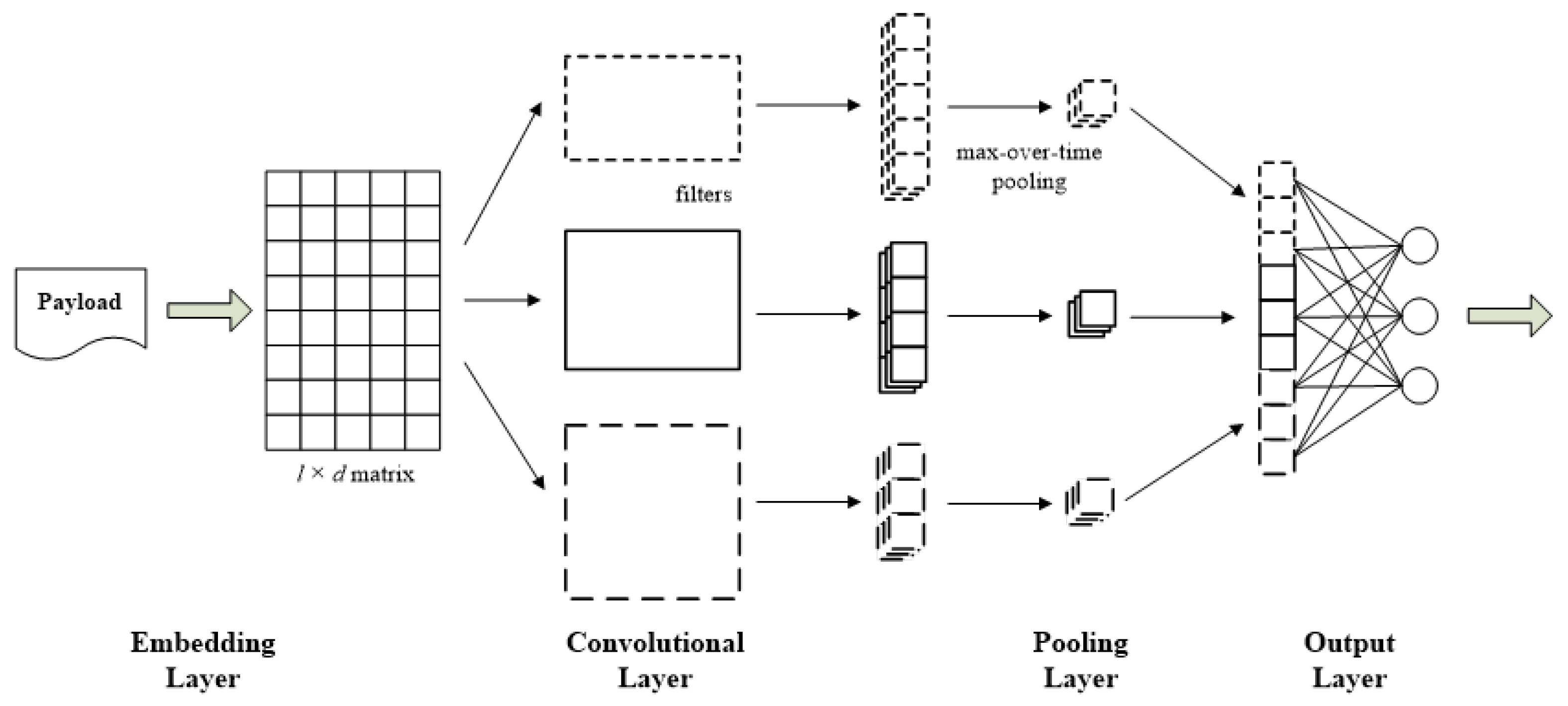
3.1. Preliminary
3.2. Model Initialization
3.3. Data Augmentation
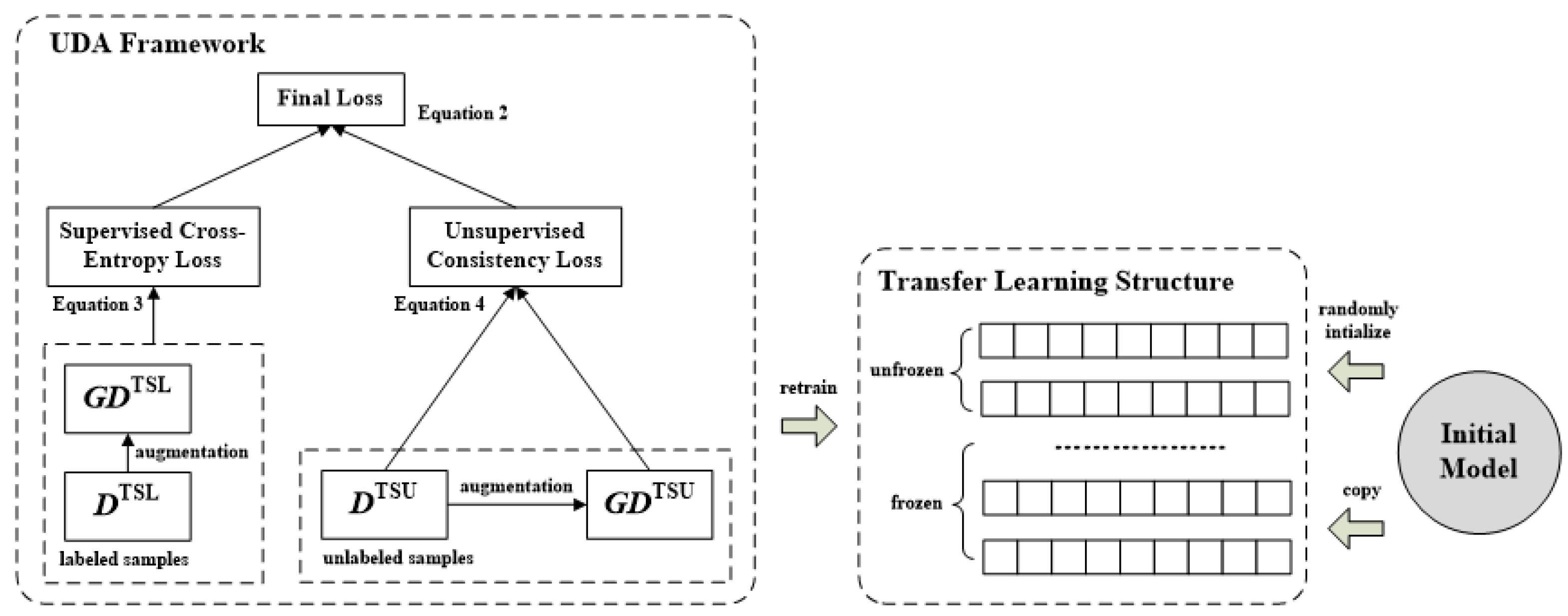
3.4. Transfer Semi-Supervised Learning
| Algorithm 1: DeepPTSD |
| Input: The public labeled dataset, The labeled dataset of the target system, The unlabeled dataset of the target system, The number of frozen layers, n The trade-off weight, Output: The detection model of the target system, 1: Train an initial TextCNN classifier (denoted as ) with 2: Generate an augmented dataset from (denoted as ) 3: Generate an augmented dataset from (denoted as ) 4: Initialize the TextCNN classifier of the target system (denoted as TM), by copying the parameters of to 5: Freeze the first n layers of and retrain based on , and by following Equation (2) |
4. Experiment
4.1. Experiment Setup
4.1.1. Dataset
4.1.2. Evaluation Strategy
4.1.3. Parameter Settings
4.2. Experiment 1: The Evaluation of Different Payload Segmentation Strategies
4.3. Experiment 2: Ablation Experiment
- (1)
- NoAug: It corresponded to the variant that no payload data augmentation was performed.
- (2)
- RandomAug: It corresponded to the variant that the noises were added to all the tokens without retraining the keywords. Note that the special characters (e.g., %, @, #) were retained.
- (3)
- AugByDic: It corresponded to the variant that the keywords needed to be retrained were predefined in a dictionary instead of being extracted from the dataset.
- (1)
- DeepPTSD_None: It referred to the standard deep learning model. Specifically, it trained the target detection model on based on TextCNN (in Section 3.2).
- (2)
- DeepPTSD_T: It referred to the transfer learning model with augmented labeled data. Specifically, it trained the initial detection model on , and fine-tuned it on to get the target detection model based on the transfer learning structure (in Section 3.4). Here, the first two layers of the initial detection model were frozen and we fine-tuned it to minimize the loss function in Equation (3).
- (3)
- DeepPTSD_S: It referred to the semi-supervised learning model with augmented labeled and unlabeled data. Specifically, it trained the target detection model on based on the UDA framework (in Section 3.4).
4.4. Experiment 3: Comparison Experiment
- (1)
- SVM_C: It corresponded to the character-level feature based method. Specifically, it first segmented each HTTP traffic sample into characters, and built a feature vector to reflect the character distribution based on VSM (vector space model). Then, it trained a SVM (support vector machine) classifier based on the character feature vectors.
- (2)
- SVM_W: It corresponded to the word-level feature based method [18]. Specifically, it first segmented each HTTP traffic sample into words based on the approach proposed in Section 3.2, and built a feature vector to reflect the word distribution based on VSM. Then, it trained a SVM classifier based on the word feature vectors.
- (3)
- CNN: It trained the detection model based on the TextCNN model [14]. Here, a HTTP traffic sample was segmented based on the approach proposed in Section 3.2.
- (4)
- RNN: It trained the detection model based on a BiLSTM model [22]. Here, a HTTP traffic sample was also segmented based on the approach proposed in Section 3.2.
- (5)
- AE: It corresponded to the autoencoder based method [12]. Specifically, it first trained an autoencoder on in an unsupervised manner to map each HTTP traffic sample into a unified latent feature space. Then, it trained a MLP (multi-layer perceptron) classifier based on the latent feature vectors.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rotsos, C.; Van Gael, J.; Moore, A.W.; Ghahramani, Z. Probabilistic graphical models for semi-supervised traffic classification. In Proceedings of the 6th International Wireless Communications and Mobile Computing Conference, Caen, France, 28 June–2 July 2010; pp. 752–757. [Google Scholar]
- Jadidi, Z.; Muthukkumarasamy, V.; Sithirasenan, E.; Singh, K. Flow-based anomaly detection using semisupervised learning. In Proceedings of the 2015 9th International Conference on Signal Processing and Communication Systems (ICSPCS), Cairns, QLD, Australia, 14–16 December 2015; pp. 1–5. [Google Scholar]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Bapat, R.; Mandya, A.; Liu, X.; Abraham, B.; Brown, D.E.; Kang, H.; Veeraraghavan, M. Identifying malicious botnet traffic using logistic regression. In Proceedings of the 2018 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018; pp. 266–271. [Google Scholar]
- Shekhawat, A.S.; Di Troia, F.; Stamp, M. Feature analysis of encrypted malicious traffic. Expert Syst. Appl. 2019, 125, 130–141. [Google Scholar] [CrossRef]
- Zhenqi, W.; Xinyu, W. Netflow based intrusion detection system. In Proceedings of the 2008 International Conference on Multimedia and Information Technology, Yichang, China, 30–31 December 2008; pp. 825–828. [Google Scholar]
- Nguyen, T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Machlica, L.; Bartos, K.; Sofka, M. Learning detectors of malicious web requests for intrusion detection in network traffic. arXiv 2017, arXiv:1702.02530. [Google Scholar]
- Verma, R.; Das, A. What’s in a url: Fast feature extraction and malicious url detection. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics, Scottsdale, AZ, USA, 24 March 2017; pp. 55–63. [Google Scholar]
- Liu, C.; Wang, L.; Lang, B.; Zhou, Y. Finding effective classifier for malicious URL detection. In Proceedings of the 2018 2nd International Conference on Management Engineering, Software Engineering and Service Sciences, Wuhan, China, 13–15 January 2018; pp. 240–244. [Google Scholar]
- Patgiri, R.; Katari, H.; Kumar, R.; Sharma, D. Empirical study on malicious URL detection using machine learning. In Proceedings of the International Conference on Distributed Computing and Internet Technology; Springer: Cham, Switzerland, 2019; pp. 380–388. [Google Scholar]
- Park, S.; Kim, M.; Lee, S. Anomaly detection for HTTP using convolutional autoencoders. IEEE Access 2018, 6, 70884–70901. [Google Scholar] [CrossRef]
- Peng, Y.; Tian, S.; Yu, L.; Lv, Y.; Wang, R. A joint approach to detect malicious URL based on attention mechanism. Int. J. Comput. Intell. Appl. 2019, 18, 1950021. [Google Scholar] [CrossRef]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv 2018, arXiv:1802.03162. [Google Scholar]
- Yang, W.; Zuo, W.; Cui, B. Detecting malicious urls via a keyword-based convolutional gated-recurrent-unit neural network. IEEE Access 2019, 7, 29891–29900. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Guan, X.; Qin, T.; Wang, P.; Tao, J.; Meng, Y.; Liu, J. Addressing the train–test gap on traffic classification combined subflow model with ensemble learning. Knowl. Based Syst. 2020, 204, 106192. [Google Scholar] [CrossRef]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1254. [Google Scholar]
- Yang, J.; Wang, L.; Xu, Z. A novel semantic-aware approach for detecting malicious web traffic. In Proceedings of the International Conference on Information and Communications Security; Springer: Cham, Switzerland, 2017; pp. 633–645. [Google Scholar]
- Yang, J.; Yang, P.; Jin, X.; Ma, Q. Multi-classification for malicious URL based on improved semi-supervised algorithm. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 1, pp. 143–150. [Google Scholar]
- Saxe, J.; Berlin, K. eXpose: A character-level convolutional neural network with embeddings for detecting malicious URLs, file paths and registry keys. arXiv 2017, arXiv:1702.08568. [Google Scholar]
- Yu, Y.; Liu, G.; Yan, H.; Li, H.; Guan, H. Attention-based Bi-LSTM model for anomalous HTTP traffic detection. In Proceedings of the 2018 15th International Conference on Service Systems and Service Management (ICSSSM), Hangzhou, China, 21–22 July 2018; pp. 1–6. [Google Scholar]
- Li, Z.; Yao, H.; Ma, F. Learning with Small Data. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 884–887. [Google Scholar]
- Long, Y.; Liu, L.; Shen, F.; Shao, L.; Li, X. Zero-shot learning using synthesised unseen visual data with diffusion regularisation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2498–2512. [Google Scholar] [CrossRef] [Green Version]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Chen, Z.; Fu, Y.; Zhang, Y.; Jiang, Y.G.; Xue, X.; Sigal, L. Semantic feature augmentation in few-shot learning. arXiv 2018, arXiv:1804.05298. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Davis, E.; Marcus, G. Commonsense reasoning and commonsense knowledge in artificial intelligence. Commun. ACM 2015, 58, 92–103. [Google Scholar] [CrossRef]
- Stewart, R.; Ermon, S. Label-free supervision of neural networks with physics and domain knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Fang, Y.; Xu, Y.; Jia, P.; Huang, C. Providing Email Privacy by Preventing Webmail from Loading Malicious XSS Payloads. Appl. Sci. 2020, 10, 4425. [Google Scholar] [CrossRef]
- Kim, Y. ConvolutionalNeuralNetworksforSentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Google. Word2vec. 2013. Available online: https://code.google.com/p/word2vec/ (accessed on 28 February 2021).
- Qiu, S.; Xu, B.; Zhang, J.; Wang, Y.; Shen, X.; de Melo, G.; Long, C.; Li, X. EasyAug: An automatic textual data augmentation platform for classification tasks. In Companion Proceedings of the Web Conference 2020; ACM: New York, NY, USA, 2020; pp. 249–252. [Google Scholar]
- Silfverberg, M.; Wiemerslage, A.; Liu, L.; Mao, L.J. Data augmentation for morphological reinflection. In Proceedings of the CoNLL SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection, Vancouver, BC, Canada, 3–4 August 2017; pp. 90–99. [Google Scholar]
- Yu, A.W.; Dohan, D.; Luong, M.T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv 2018, arXiv:1804.09541. [Google Scholar]
- Kobayashi, S. Contextual augmentation: Data augmentation by words with paradigmatic relations. arXiv 2018, arXiv:1805.06201. [Google Scholar]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Zhang, Y.; Gan, Z.; Carin, L. Generating text via adversarial training. In NIPS Workshop on Adversarial Training; Academia.edu: San Francisco, CA, USA, 2016; Volume 21, pp. 21–32. [Google Scholar]
- Miyato, T.; Maeda, S.i.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, M.T.; Le, Q.V. Unsupervised data augmentation for consistency training. arXiv 2019, arXiv:1904.12848. [Google Scholar]
- FSecurify. Using-Machine-Learning-to-Detect-Malicious-URLs. 2017. Available online: http://fsecurify.com/using-machine-learning-detect-malicious-urls/ (accessed on 31 January 2021).




{kind=link}
{kind=link}
{kind=link}
| Rule 1 | Keep all keywords in the keyword library unchanged. |
| Rule 2 | Retain all the special characters (e.g., %, @, #). |
| Rule 3 | Randomize each number in the range of [0,9]. |
| Rule 4 | Change each letter into a random letter. |
| SegAsChar | SegAsNGram | SegAsWord | |
|---|---|---|---|
| Precision | |||
| Recall | |||
| F1-Measure |
| NoAug | RandomAug | AugByDic | AugByKeyword | |
|---|---|---|---|---|
| Precision | ||||
| Recall | ||||
| F1-Measure |
| DeepPTSD_None | DeepPTSD_T | DeepPTSD_S | DeepPTSD | |
|---|---|---|---|---|
| Precision | ||||
| Recall | ||||
| F1-Measure |
| SVM_C | SVM_W | CNN | RNN | AE | DeepPTSD | |
|---|---|---|---|---|---|---|
| Precision | ||||||
| Recall | ||||||
| F1-Measure |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, T.; Chen, Y.; Lv, M.; He, G.; Zhu, T.; Wang, T.; Weng, Z. A Payload Based Malicious HTTP Traffic Detection Method Using Transfer Semi-Supervised Learning. Appl. Sci. 2021, 11, 7188. https://doi.org/10.3390/app11167188
Chen T, Chen Y, Lv M, He G, Zhu T, Wang T, Weng Z. A Payload Based Malicious HTTP Traffic Detection Method Using Transfer Semi-Supervised Learning. Applied Sciences. 2021; 11(16):7188. https://doi.org/10.3390/app11167188
Chicago/Turabian StyleChen, Tieming, Yunpeng Chen, Mingqi Lv, Gongxun He, Tiantian Zhu, Ting Wang, and Zhengqiu Weng. 2021. "A Payload Based Malicious HTTP Traffic Detection Method Using Transfer Semi-Supervised Learning" Applied Sciences 11, no. 16: 7188. https://doi.org/10.3390/app11167188