
Early-, Late-, and Very Late-Term Prediction of Target Lesion Failure in Coronary Artery Stent Patients: An International Multi-Site Study

 ,
,
Abstract
:1. Introduction
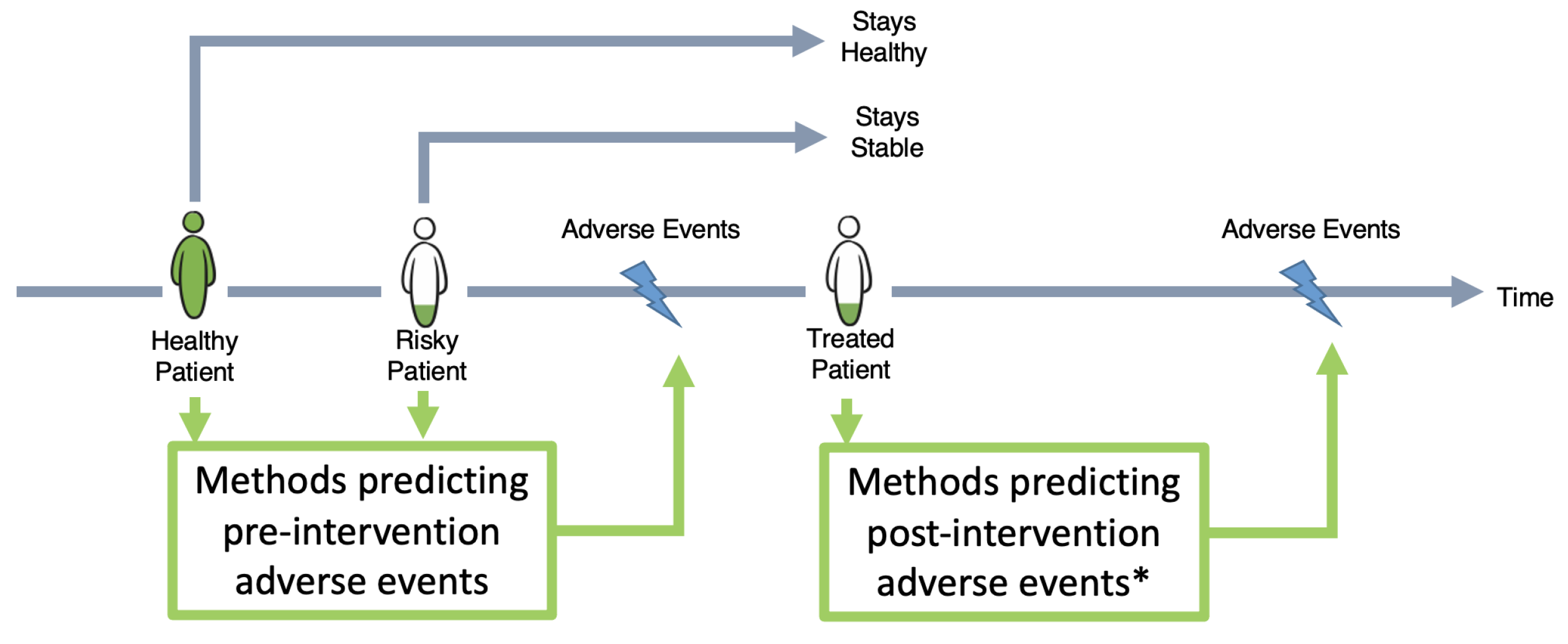
- The development of a novel ML method for the identification of patients at risk of TLF. This model can predict the onset of TLF at any time point after discharge from hospital. To the best of our knowledge, such an analysis on TLF is the first of its kind.
- Training and validation are performed with our international, multi-site cohort, with comprehensive variables collected during treatment and 5 years of frequent follow-ups. Data were collected from 120 medical centers in over 25 countries across the globe.
- In addition, we evaluate our model against five state of the art models via multiple sets of experiments.
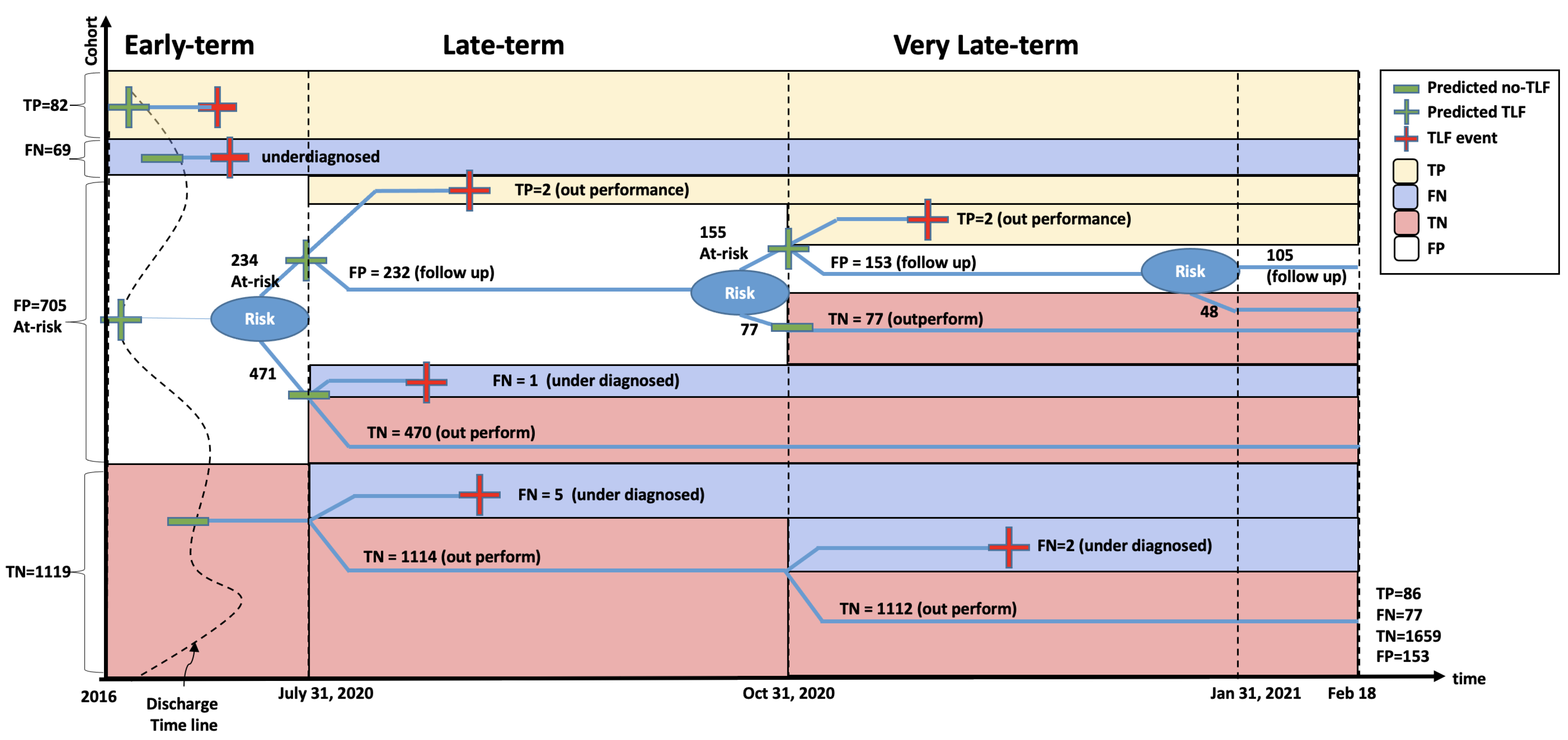
- We demonstrate a successful retrospective and prospective evaluation of our model in three time frames (early-, late-, and very late-term prediction).
2. Background

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Outcome | Data | Method | Metric | |
|---|---|---|---|---|---|
| Singh, 2004 (PRESTO-1, PRESTO-2) [11,20] | SR | Cohort name | PRESTO trial | Multi-class LR | AUC-ROC |
| # Patients | 1312 | ||||
| Ethnicity | Heterogeneous worldwide, 224 hospitals | ||||
| Outcome ratio | 45.4% | ||||
| Medical device | BMS | ||||
| Features | Baseline demographic, procedural, and follow-up angiographic information | ||||
| D’Agostino Sr, 2008 (Framingham Risk Score) [12] | CAD | Cohort name | Framingham study | Cox proportional-hazards regression | C-index |
| # Patients | 8491 | ||||
| Ethnicity | Participants from one city (Framingham, Massachusetts) | ||||
| Features | Baseline demographic and socioeconomic, CAD phenotype (incl. genetic biomarkers), procedural, and follow-up angiographic information | ||||
| Stolker, 2010 (EVENT) [21] | TLR | Cohort name | EVENT registry | Multi-class LR | C-index |
| # Patients | 5863 | ||||
| Ethnicity | Heterogeneous from USA | ||||
| Outcome ratio | 4.1% | ||||
| Medical device | DES | ||||
| Features | Demographic, clinical, and treatment features | ||||
| Cassese, 2014 [22] | SR | # Patients | 10,004 | Fisher’s exact test, test | p-value |
| Ethnicity | Homogeneous German, two hospitals | ||||
| Outcome ratio | 26.4% | ||||
| Medical device | BMS or 1st/2nd-generation DES | ||||
| Features | Baseline demographic, procedural, and follow-up angiographic information | ||||
| Alaa, 2019 [16] | CAD | Cohort name | UK Biobank | SCL | AUC-ROC |
| # Patients | 423,604 | ||||
| Ethnicity | Homogeneous from UK, 22 hospitals | ||||
| Outcome ratio | 1.1% | ||||
| Features | Baseline demographics, procedural, and follow-up angiographic information | ||||
| Konigstein, 2019 [15] | TLF | Cohort name | Pool from six randomized controlled trials | Cox proportional-hazards regression | C-index |
| # Patients | 10,072 | ||||
| Ethnicity | Heterogeneous, worldwide | ||||
| Outcome ratio | 10.1% | ||||
| Medical device | Contemporary DES | ||||
| Features | Baseline demographic, procedural, and follow-up angiographic information | ||||
| Anadol, 2020 [14] | TLF | Cohort name | MICAT project | Cox proportional-hazards regression | C-index |
| # Patients | 512 | ||||
| Ethnicity | Heterogeneous, worldwide (14 countries) | ||||
| Outcome ratio | 17.9% | ||||
| Medical device | BRS (Abbott Vascular) | ||||
| Features | Baseline demographic, procedural, and follow-up angiographic information | ||||
| Sampedo-Gómez, 2020 [17] | SR | Cohort name | GRACIA-3 study | SCL | AUC-PRC |
| # Patients | 263 | ||||
| Ethnicity | Homogeneous Spanish | ||||
| Outcome ratio | 8.9% | ||||
| Medical device | DES | ||||
| Features | Baseline demographic, procedural, and follow-up angiographic information | ||||
3. Data and Cohort
4. Methodology
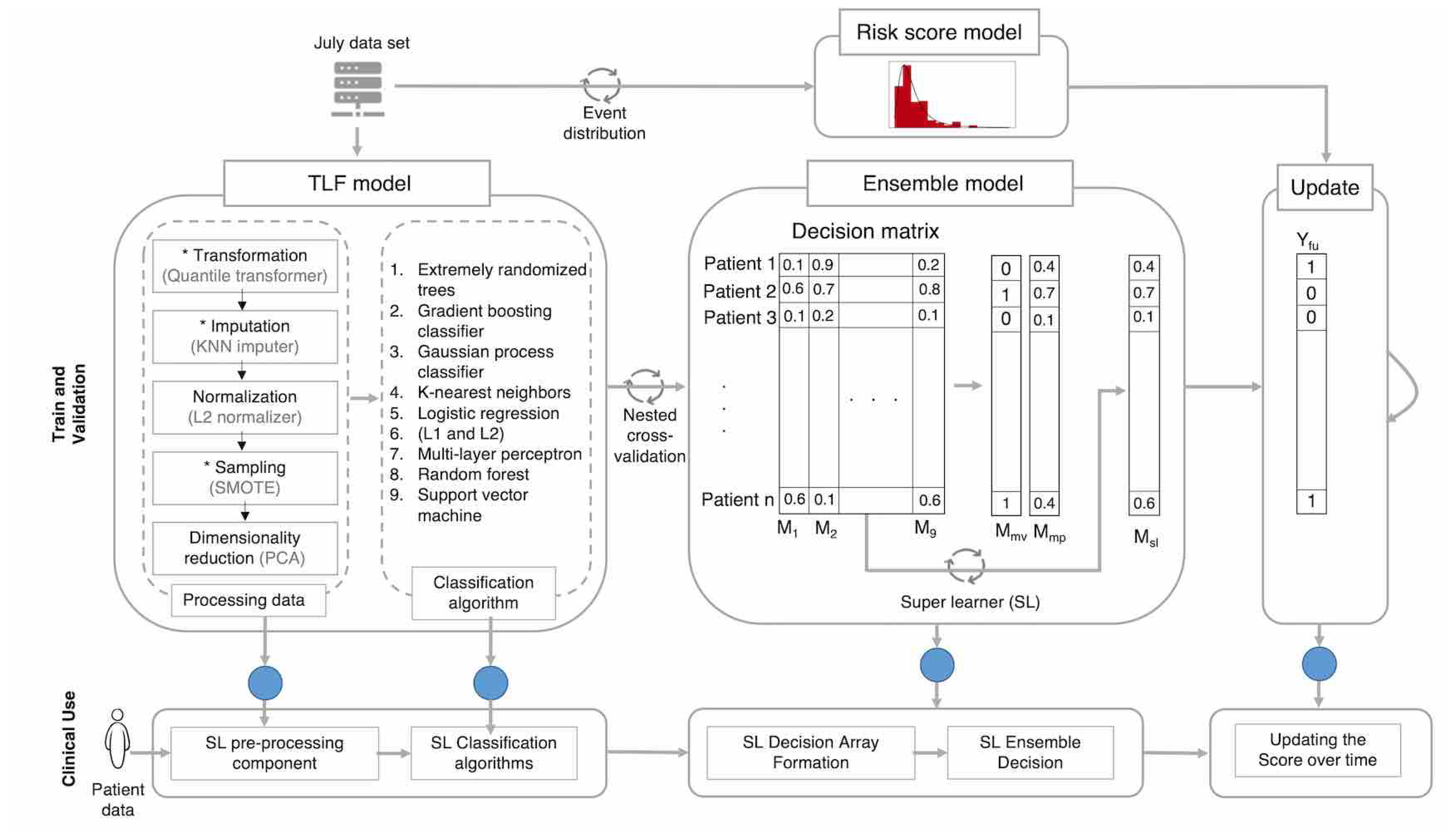
4.1. TLF Prediction Component
4.2. Ensemble Predictions
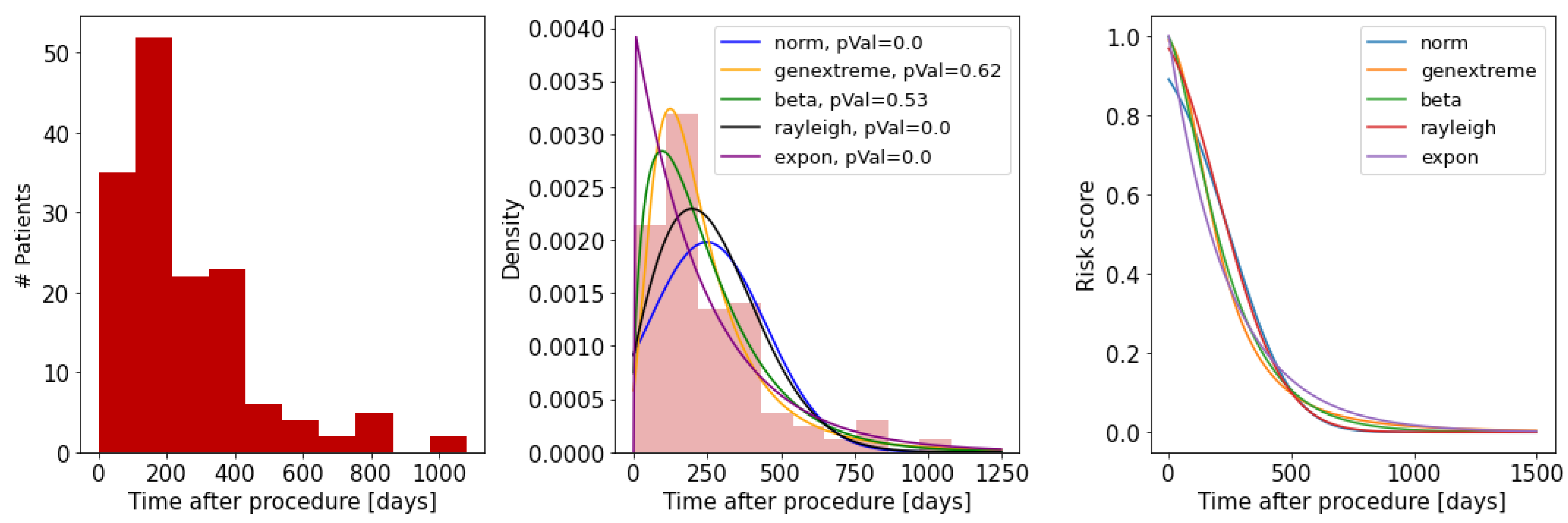
4.3. Risk Score Component
4.4. Update Component
5. Model Evaluation
5.1. Evaluation of Our Models
5.2. Evaluation of State of the Art Models
6. Results and Discussion
6.1. Performance of Our Models
6.2. Performance of the State of the Art Models
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO. The Top 10 Causes of Death. 2018. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 27 July 2012).
- Lam, C.S.P.; Voors, A.A.; de Boer, R.A.; Solomon, S.D.; van Veldhuisen, D.J. Heart failure with preserved ejection fraction: From mechanisms to therapies. Eur. Heart J. 2018, 39, 2780–2792. [Google Scholar] [CrossRef]
- Baumbach, A.; Bourantas, C.V.; Serruys, P.W.; Wijns, W. The year in cardiology: Coronary interventions: The year in cardiology 2019. Eur. Heart J. 2020, 41, 394–405. [Google Scholar] [CrossRef]
- Huber, K.; Ulmer, H.; Lang, I.M.; Mühlberger, V. Coronary interventions in Austria, Germany, and Switzerland. Eur. Heart J. 2020, 41, 2599–2600. [Google Scholar] [CrossRef]
- Argulian, E.; Sud, K.; Vogel, B.; Bohra, C.; Garg, V.P.; Talebi, S.; Lerakis, S.; Narula, J. Right Ventricular Dilation in Hospitalized Patients With COVID-19 Infection. JACC Cardiovasc. Imaging 2020, 13, 2459–2461. [Google Scholar] [CrossRef]
- Kolossváry, M.; Karády, J.; Szilveszter, B.; Kitslaar, P.; Hoffmann, U.; Merkely, B.; Maurovich-Horvat, P. Radiomic Features Are Superior to Conventional Quantitative Computed Tomographic Metrics to Identify Coronary Plaques With Napkin-Ring Sign. Circ. Cardiovasc. Imaging 2017, 10, e006843. [Google Scholar] [CrossRef]
- Le, E.P.V.; Rundo, L.; Tarkin, J.M.; Evans, N.R.; Chowdhury, M.M.; Coughlin, P.A.; Pavey, H.; Wall, C.; Zaccagna, F.; Gallagher, F.A.; et al. Assessing robustness of carotid artery CT angiography radiomics in the identification of culprit lesions in cerebrovascular events. Sci. Rep. 2021, 11, 3499. [Google Scholar] [CrossRef]
- Militello, C.; Rundo, L.; Toia, P.; Conti, V.; Russo, G.; Filorizzo, C.; Maffei, E.; Cademartiri, F.; La Grutta, L.; Midiri, M.; et al. A semi-automatic approach for epicardial adipose tissue segmentation and quantification on cardiac CT scans. Comput. Biol. Med. 2019, 114, 103424. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garcia, H.M.; McFadden, E.P.; Farb, A.; Mehran, R.; Stone, G.W.; Spertus, J.; Onuma, Y.; Morel, M.A.; van Es, G.A.; Zuckerman, B.; et al. Standardized End Point Definitions for Coronary Intervention Trials: The Academic Research Consortium-2 Consensus Document. Circulation 2018, 137, 2635–2650. [Google Scholar] [CrossRef] [PubMed]
- Verheye, S.; Wlodarczak, A.; Montorsi, P.; Torzewski, J.; Bennett, J.; Haude, M.; Starmer, G.; Buck, T.; Wiemer, M.; Nuruddin, A.A.B.; et al. BIOSOLVE-IV-registry: Safety and performance of the Magmaris scaffold: 12-month outcomes of the first cohort of 1075 patients. Catheter. Cardiovasc. Interv. 2021, 98, E1–E8. [Google Scholar] [CrossRef]
- Singh, M.; Gersh, B.J.; McClelland, R.L.; Ho, K.K.; Willerson, J.T.; Penny, W.F.; Holmes, D.R. Clinical and Angiographic Predictors of Restenosis After Percutaneous Coronary Intervention. Circulation 2004, 109, 2727–2731. [Google Scholar] [CrossRef] [PubMed]
- D’Agostino, R.B.; Vasan, R.S.; Pencina, M.J.; Wolf, P.A.; Cobain, M.; Massaro, J.M.; Kannel, W.B. General Cardiovascular Risk Profile for Use in Primary Care. Circulation 2008, 118, e86. [Google Scholar] [CrossRef] [Green Version]
- Piepoli, M.F.; Hoes, A.W.; Agewall, S.; Albus, C.; Brotons, C.; Catapano, A.L.; Cooney, M.T.; Corrà, U.; Cosyns, B.; Deaton, C.; et al. 2016 European Guidelines on cardiovascular disease prevention in clinical practice: The Sixth Joint Task Force of the European Society of Cardiology and Other Societies on Cardiovascular Disease Prevention in Clinical Practice (constituted by representatives of 10 societies and by invited experts) Developed with the special contribution of the European Association for Cardiovascular Prevention & Rehabilitation (EACPR). Atherosclerosis 2016, 252, 207–274. [Google Scholar] [PubMed] [Green Version]
- Anadol, R.; Mühlenhaus, A.; Trieb, A.K.; Polimeni, A.; Münzel, T.; Gori, T. Five Years Outcomes and Predictors of Events in a Single-Center Cohort of Patients Treated with Bioresorbable Coronary Vascular Scaffolds. J. Clin. Med. 2020, 9, 847. [Google Scholar] [CrossRef] [Green Version]
- Konigstein, M.; Madhavan, M.V.; Ben-Yehuda, O.; Rahim, H.M.; Srdanovic, I.; Gkargkoulas, F.; Mehdipoor, G.; Shlofmitz, E.; Maehara, A.; Redfors, B.; et al. Incidence and predictors of target lesion failure in patients undergoing contemporary DES implantation: Individual patient data pooled analysis from 6 randomized controlled trials. Am. Heart J. 2019, 213, 105–111. [Google Scholar] [CrossRef]
- Alaa, A.M.; Bolton, T.; Di Angelantonio, E.; Rudd, J.H.F.; van der Schaar, M. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423,604 UK Biobank participants. PLoS ONE 2019, 14, e0213653. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sampedro-Gómez, J.; Dorado-Díaz, P.I.; Vicente-Palacios, V.; Sánchez-Puente, A.; Jiménez-Navarro, M.; Alberto, J.; Galindo-Villardón, P.; Sanchez, P.L.; Fernández-Avilés, F. Machine learning to predict stent restenosis based on daily demographic, clinical, and angiographic characteristics. Can. J. Cardiol. 2020, 36, 1624–1632. [Google Scholar] [CrossRef] [PubMed]
- Dorado-Diaz, P.I.; Sampedro-Gomez, J.; Vicente-Palacios, V.; Sanchez, P.L. Applications of Artificial Intelligence in Cardiology. The Future is Already Here. Rev. Esp. Cardiol. (Engl. Ed.) 2019, 72, 1065–1075. [Google Scholar] [CrossRef] [PubMed]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine Learning in Medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef] [PubMed]
- Holmes, D.R.; Savage, M.; LaBlanche, J.M.; Grip, L.; Serruys, P.W.; Fitzgerald, P.; Fischman, D.; Goldberg, S.; Brinker, J.A.; Zeiher, A.M.; et al. Results of Prevention of REStenosis with Tranilast and its Outcomes (PRESTO) trial. Circulation 2002, 106, 1243–1250. [Google Scholar] [CrossRef] [Green Version]
- Stolker, J.M.; Kennedy, K.F.; Lindsey, J.B.; Marso, S.P.; Pencina, M.J.; Cutlip, D.E.; Mauri, L.; Kleiman, N.S.; Cohen, D.J. Predicting restenosis of drug-eluting stents placed in real-world clinical practice: Derivation and validation of a risk model from the EVENT registry. Circ. Cardiovasc. Interv. 2010, 3, 327–334. [Google Scholar] [CrossRef] [Green Version]
- Cassese, S.; Byrne, R.A.; Tada, T.; Pinieck, S.; Joner, M.; Ibrahim, T.; King, L.A.; Fusaro, M.; Laugwitz, K.L.; Kastrati, A. Incidence and predictors of restenosis after coronary stenting in 10004 patients with surveillance angiography. Heart 2014, 100, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Ki, Y.J.; Park, K.W.; Kang, J.; Kim, C.H.; Han, J.K.; Yang, H.M.; Kang, H.J.; Koo, B.K.; Kim, H.S. Safety and Efficacy of Second-Generation Drug-Eluting Stents in Real-World Practice: Insights from the Multicenter Grand-DES Registry. J. Interv. Cardiol. 2020, 2020, 3872704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Onuma, Y.; Ormiston, J.; Serruys, P.W. Bioresorbable Scaffold Technologies. Circ. J. 2011, 75, 509–520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rizik, D.G.; Hermiller, J.B.; Kereiakes, D.J. The ABSORB bioresorbable vascular scaffold: A novel, fully resorbable drug-eluting stent: Current concepts and overview of clinical evidence. Catheter. Cardiovasc. Interv. 2015, 86, 664–677. [Google Scholar] [CrossRef]
- Forrestal, B.; Case, B.C.; Yerasi, C.; Musallam, A.; Chezar-Azerrad, C.; Waksman, R. Bioresorbable scaffolds: Current technology and future perspectives. Rambam Maimonides Med. J. 2020, 11, e0016. [Google Scholar] [CrossRef]
- Rapetto, C.; Leoncini, M. Magmaris: A new generation metallic sirolimus-eluting fully bioresorbable scaffold: Present status and future perspectives. J. Thorac. Dis. 2017, 9, S903. [Google Scholar] [CrossRef] [Green Version]
- Haude, M.; Ince, H.; Kische, S.; Abizaid, A.; Toelg, R.; Alves Lemos, P.; Van Mieghem, N.M.; Verheye, S.; von Birgelen, C.; Christiansen, E.H.; et al. Safety and clinical performance of a drug eluting absorbable metal scaffold in the treatment of subjects with de novo lesions in native coronary arteries: Pooled 12-month outcomes of BIOSOLVE-II and BIOSOLVE-III. Catheter. Cardiovasc. Interv. 2018, 92, E502–E511. [Google Scholar] [CrossRef] [Green Version]
- Wlodarczak, A.; Garcia, L.A.I.; Karjalainen, P.P.; Komocsi, A.; Pisano, F.; Richter, S.; Lanocha, M.; Rumoroso, J.R.; Leung, K.F. Magnesium 2000 postmarket evaluation: Guideline adherence and intraprocedural performance of a sirolimus-eluting resorbable magnesium scaffold. Cardiovasc. Revasc. Med. 2019, 20, 1140–1145. [Google Scholar] [CrossRef]
- Wlodarczak, A.; Starmer, G.; Torzewski, J.; Bennett, J.; Wiemer, M.; Nguyen, M.; Sabate, M.; der Schaaf, R.V.; Montorsi, P.; Eeckhout, E.; et al. Safety and Performance of the Resorbable Magnesium Scaffold, Magmaris in a Real-World Setting: Analyses of the First Cohort Subjects at 12-Month Follow-up of the BIOSOLVE-IV Registry. J. Am. Coll. Cardiol. 2020, 76, B117. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019. [Google Scholar]
- Beretta, L.; Santaniello, A. Nearest neighbor imputation algorithms: A critical evaluation. BMC Med. Inform. Decis. Mak. 2016, 16 (Suppl. S3), 74. [Google Scholar] [CrossRef] [Green Version]
- Wulff, J.N.; Jeppesen, L.E. Multiple imputation by chained equations in praxis: Guidelines and review. Electron. J. Bus. Res. Methods 2017, 15, 41–56. [Google Scholar]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minka, T. Automatic choice of dimensionality for PCA. Adv. Neural Inf. Process. Syst. 2000, 13, 598–604. [Google Scholar]





| Timeline | Supplementary References | Features |
|---|---|---|
| Pre-intervention | Table S2 | Demographic information (age, gender), EQ5D questionnaire (mobility, self-care, usual activities, pain/discomfort, anxiety/depression), MI information (prior MI, type of most recent MI), prior stroke/TIA, diseases and complications (renal, hepatic, respiratory, hypertension, hypercholesteremia, diabetes mellitus, congestive heart failure), history of cancer, number of prior PCIs, ischemic status (STEMI, NSTEMI, CCS class of stable angina, unstable angina, silent ischemia, LVEF class) |
| Intra-operation | Table S3 | Procedure details (duration, residual stenosis before implantation), device (Magmaris scaffold) details (number of implanted devices, maximum pressure applied, residual stenosis after implantation, device deficiency prior to/during procedure), pre-dilatation balloon details (number of balloons, diameter, length, number of inflations, maximum pressure), post-dilatation balloon details (same as for pre-dilatation) |
| Lesion and Stent | Table S4 | Lesion information (location, ACC/AHA characterization, moderate/severe calcification, eccentric lesions, length), vessel information (location, moderate/severe angulation, moderate/excessive tortuosity, reference diameter), pre-procedure TIMI flow, bifurcation, thrombus, stenosis pre-procedure |
| Medications | Table S5 | ASA (prior to procedure, loading dose), heparin (bolus injection prior to procedure, during procedure), anti-platelet medication (prior to procedure, loading dose) |
| Discharge Information | Table S6 | Troponin (if clinically significant, if out of normal range), ischemic status (CCS class of stable angina, unstable angina, silent ischemia) |
| Follow-up | Figure S1 | TLF defined as combination of TLR, MI, CABG, and ST |
| Study | Trained Model | Features |
|---|---|---|
| EVENT | LR | Age < 60 years, prior PCI, Left main PCI *, SVG location *, minimum stent diameter ≤ 2.5 mm, total stent length ≥ 40 mm |
| PRESTO-1 | LR | Lesion length > 20 mm, ACC/AHA type C lesion, previous PCI, treated diabetes mellitus, non-smoker, vessel size (evaluated w.r.t. 3, 3.5, and 5 mm), unstable angina, gender |
| PRESTO-2 | LR | Treated diabetes mellitus, non-smoker, vessel size < 3 mm, length of the lesion (evaluated w.r.t. 10 and 20 mm), ostial length *, previous PCI |
| Konigstein | None | Stent length, moderate/severe calcification, post-procedural diameter stenosis, vessel diameter, hypertension, diabetes, prior coronary artery bypass grafting *, prior PCI |
| GRACIA-3 | ERT | Demographic data (age, weight *, height *, systolic/diastolic blood pressure *, smoking, alcohol consumption *), clinical data (diabetes mellitus, hypertension, dyslipidemia *, family history of cardiovascular diseases *, previous angina, previous MI, previous PCI), medications (ACE/RAA inhibitors *, betablockers *, calcium antagonists *, nitroglycerin *, aspirin *, clopidogrel), angiographic data (vessel disease, drug-eluting stent *, number of implanted stents, tirofiban use *, satisfactory PCI result *, non-reflow *, pre- and post-PCI thrombus/TIMI flow/TMPG */minimal luminal diameter */percent stenosis diameter, percent area stenosis, lesion length), left ventricle function data (end diastolic/systolic volume *, ejection function *), biochemical data (CK, CK-MB, total/LDL cholesterol *, platelets *, leucocytes *, hemoglobin *, hematocrit *, creatinine *) |
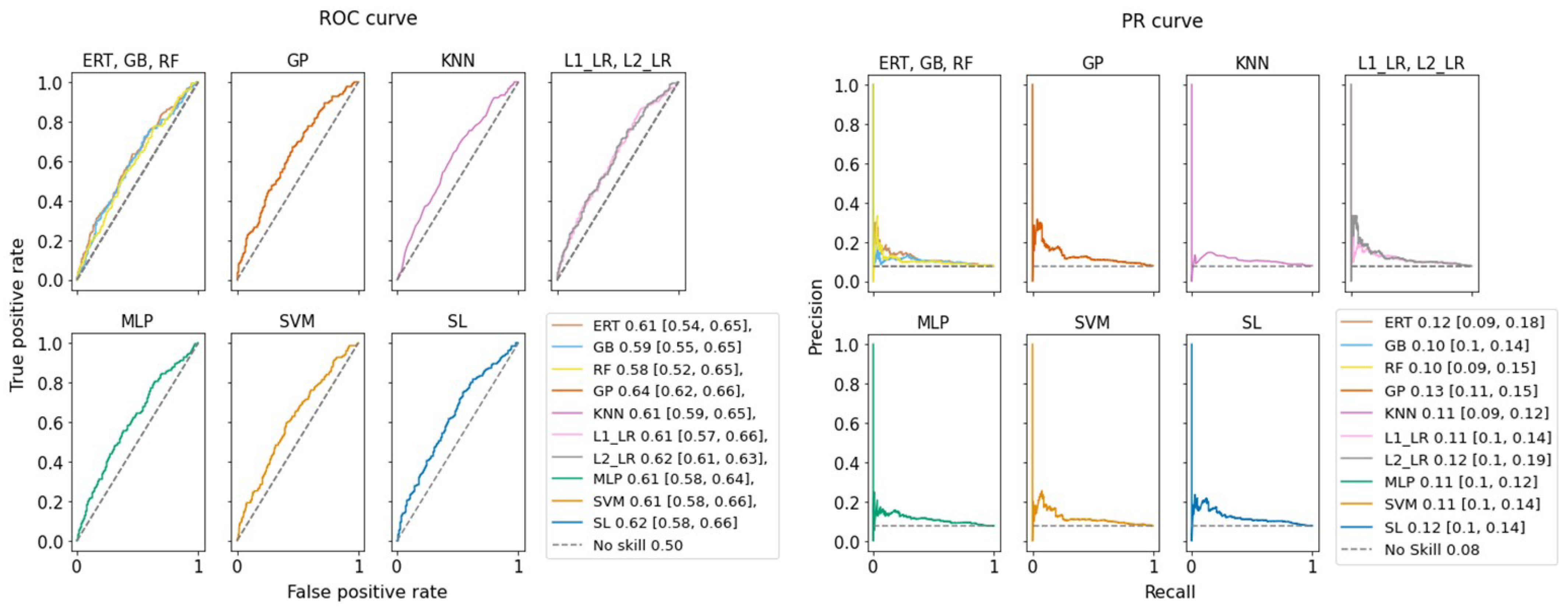
| Model | TNR Specificity | FPR | FNR | TPR Recall Sensitivity | Precision | F1 | AUC-ROC |
|---|---|---|---|---|---|---|---|
| ERT | 0.81 ± 0.02 | 0.19 ± 0.02 | 0.66 ± 0.07 | 0.34 ± 0.07 | 0.13 ± 0.02 | 0.18 ± 0.03 | 0.62 ± 0.01 |
| GMB | 0.9 ± 0.02 | 0.1 ± 0.02 | 0.82 ± 0.06 | 0.18 ± 0.06 | 0.12 ± 0.02 | 0.14 ± 0.03 | 0.62 ± 0.01 |
| GP | 0.77 ± 0.03 | 0.23 ± 0.03 | 0.6 ± 0.07 | 0.4 ± 0.07 | 0.12 ± 0.01 | 0.19 ± 0.02 | 0.63 ± 0.01 |
| KNN | 0.21 ± 0.02 | 0.79 ± 0.02 | 0.09 ± 0.04 | 0.91 ± 0.04 | 0.09 ± 0.01 | 0.16 ± 0.01 | 0.62 ± 0.01 |
| L1-LR | 0.86 ± 0.03 | 0.14 ± 0.03 | 0.76 ± 0.03 | 0.24 ± 0.03 | 0.13 ± 0.02 | 0.17 ± 0.02 | 0.62 ± 0.01 |
| L2-LR | 0.62 ± 0.04 | 0.38 ± 0.04 | 0.48 ± 0.05 | 0.52 ± 0.05 | 0.1 ± 0.01 | 0.17 ± 0.01 | 0.63 ± 0.01 |
| MLP | 0.82 ± 0.08 | 0.18 ± 0.08 | 0.69 ± 0.1 | 0.31 ± 0.1 | 0.13 ± 0.02 | 0.18 ± 0.02 | 0.62 ± 0.01 |
| RF | 0.94 ± 0.02 | 0.06 ± 0.02 | 0.89 ± 0.03 | 0.11 ± 0.03 | 0.13 ± 0.04 | 0.11 ± 0.03 | 0.63 ± 0.01 |
| SVM | 0.76 ± 0.05 | 0.24 ± 0.05 | 0.65 ± 0.08 | 0.35 ± 0.08 | 0.11 ± 0.01 | 0.16 ± 0.01 | 0.62 ± 0.01 |
| Majority voting * | 0.81 | 0.19 | 0.66 | 0.34 | 0.13 | 0.19 | 0.62 ± 0.01 |
| Mean probability * | 0.80 | 0.20 | 0.66 | 0.34 | 0.12 | 0.18 | 0.63 ± 0.01 |
| SL * (early-term) | 0.61 | 0.39 | 0.46 | 0.54 | 0.10 | 0.17 | 0.62 ± 0.01 |
| SL * (late-term) | 0.87 | 0.13 | 0.47 | 0.53 | 0.27 | 0.36 | NA |
| SL * (very late-term) | 0.92 | 0.08 | 0.47 | 0.53 | 0.36 | 0.43 | NA |
| Variables | EVENT | PRESTO-1 | PRESTO-2 | |||
|---|---|---|---|---|---|---|
| Test-Only | Retrained | Test-Only | Retrained | Test-Only | Retrained | |
| Patient age < 60 y | 0.401 | 0.143 | - | - | - | - |
| Left main PCI | 1.144 | NA | - | - | - | - |
| SVG location | 0.876 | NA | - | - | - | - |
| Minimum stent diameter mm | 0.430 | 0.175 | - | - | - | - |
| Total stent length mm | 0.577 | 0.911 | - | - | - | - |
| Prior (previous) PCI | 0.604 | 0.344 | 0.048 | - | - | |
| ACC/AHA type C lesion | - | - | 0.593 | - | - | |
| Treated diabetes mellitus | - | - | 0.344 | 0.146 | 0.372 | 0.241 |
| Unstable angina | - | - | 0.174 | 0.327 | - | - |
| Female gender | - | - | 0.140 | - | - | |
| Non-smoker | - | - | 0.329 | 0.293 | 0.493 | |
| Ostial length | - | - | - | - | 0.600 | NA |
| Lesion length ≥ 20 mm | - | - | 0.728 | 0.859 | 0.050 | |
| Vessel size | ||||||
| ≤3 mm | - | - | 0.565 | 0.321 | 0.278 | 0.014 |
| 3–3.5 mm | - | - | 0.365 | 0.266 | - | - |
| 3.5–4 mm | - | - | 0.166 | 0.0178 | - | - |
| >4 mm | - | - | 0.000 | 0.000 | - | - |
| Model intercept | - | 0.093 | - | 0.048 | - | |
| Model | TLR Prediction | TLF Prediction | |||
|---|---|---|---|---|---|
| Test-Only | Retrain | Test-Only | Retrain | ||
| EVENT | AUC-ROC Precision | 0.51 ± 0.01 0.062 | 0.54 ± 0.06 0.066 | 0.51 ± 0.01 0.076 | 0.54 ± 0.06 0.081 |
| PRESTO-1 | AUC-ROC Precision | 0.51 ± 0.01 0.065 | 0.55 ± 0.05 0.070 | 0.51 ± 0.01 0.079 | 0.56 ± 0.03 0.083 |
| PRESTO-2 | AUC-ROC Precision | 0.52 ± 0.01 0.063 | 0.54 ± 0.07 0.066 | 0.51 ± 0.01 0.077 | 0.52 ± 0.02 0.077 |
| Konigstein | AUC-ROC Precision | NA | 0.54 ± 0.07 0.064 | NA | 0.49 ± 0.06 0.074 |
| GRACIA-3 | AUC-ROC Precision | NA | 0.61 ± 0.06 0.072 | NA | 0.58 ± 0.03 0.091 |
| SL (early-term) | AUC-ROC Precision | 0.64 ± 0.02 0.067 | 0.62 ± 0.01 0.077 | NA | 0.62 ± 0.01 0.091 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pachl, E.; Zamanian, A.; Stieler, M.; Bahr, C.; Ahmidi, N. Early-, Late-, and Very Late-Term Prediction of Target Lesion Failure in Coronary Artery Stent Patients: An International Multi-Site Study. Appl. Sci. 2021, 11, 6986. https://doi.org/10.3390/app11156986
Pachl E, Zamanian A, Stieler M, Bahr C, Ahmidi N. Early-, Late-, and Very Late-Term Prediction of Target Lesion Failure in Coronary Artery Stent Patients: An International Multi-Site Study. Applied Sciences. 2021; 11(15):6986. https://doi.org/10.3390/app11156986
Chicago/Turabian StylePachl, Elisabeth, Alireza Zamanian, Myriam Stieler, Calvin Bahr, and Narges Ahmidi. 2021. "Early-, Late-, and Very Late-Term Prediction of Target Lesion Failure in Coronary Artery Stent Patients: An International Multi-Site Study" Applied Sciences 11, no. 15: 6986. https://doi.org/10.3390/app11156986