
Zernike Coefficient Prediction Technique for Interference Based on Generation Adversarial Network

 ,
,
Abstract
:1. Introduction
2. Methods
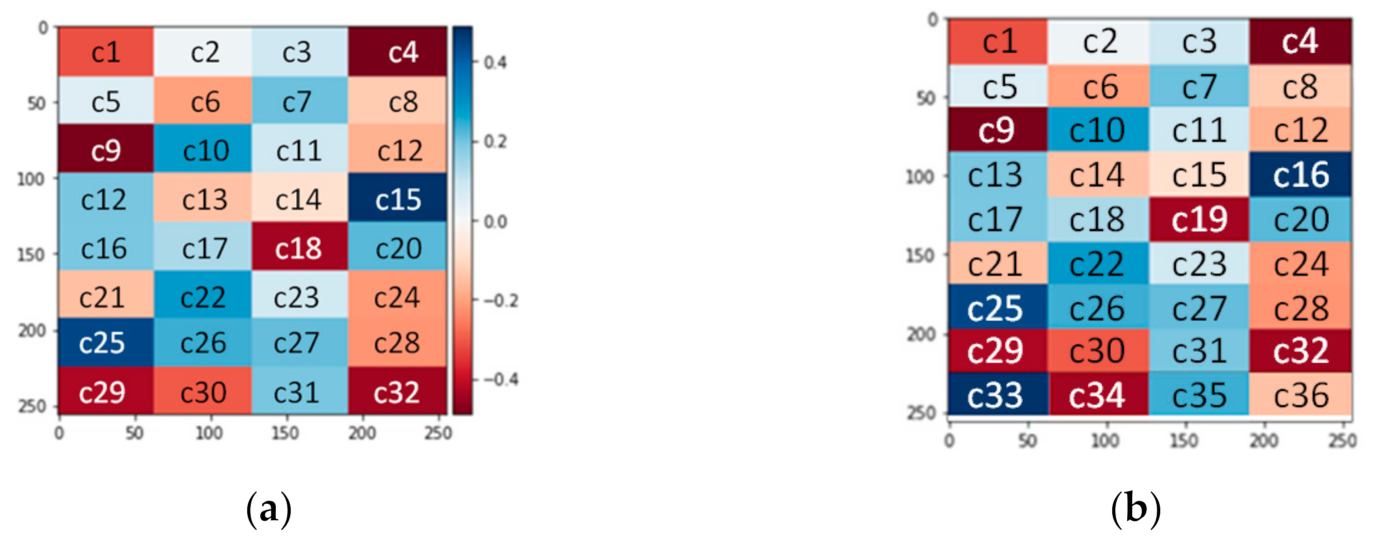
2.1. Datasets for GAN Model
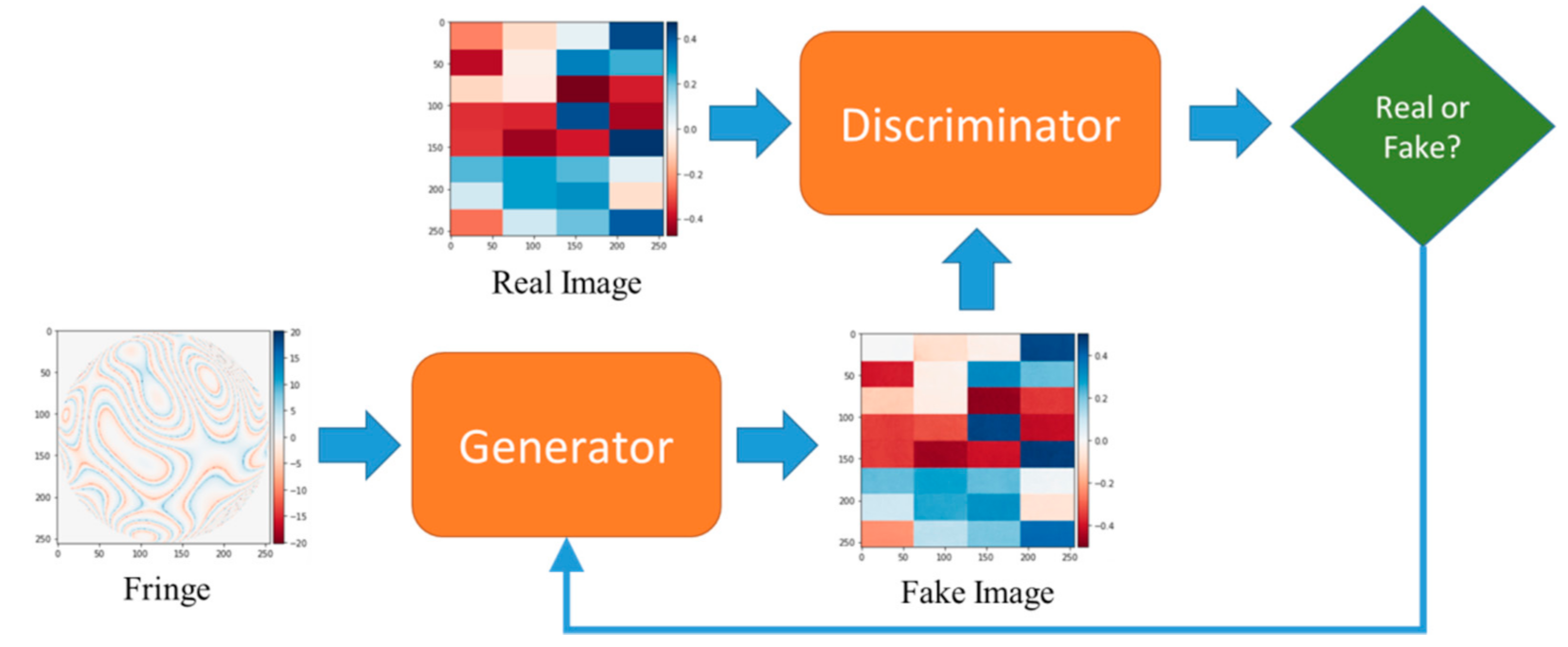
2.2. Generative Adversarial Network (GAN)
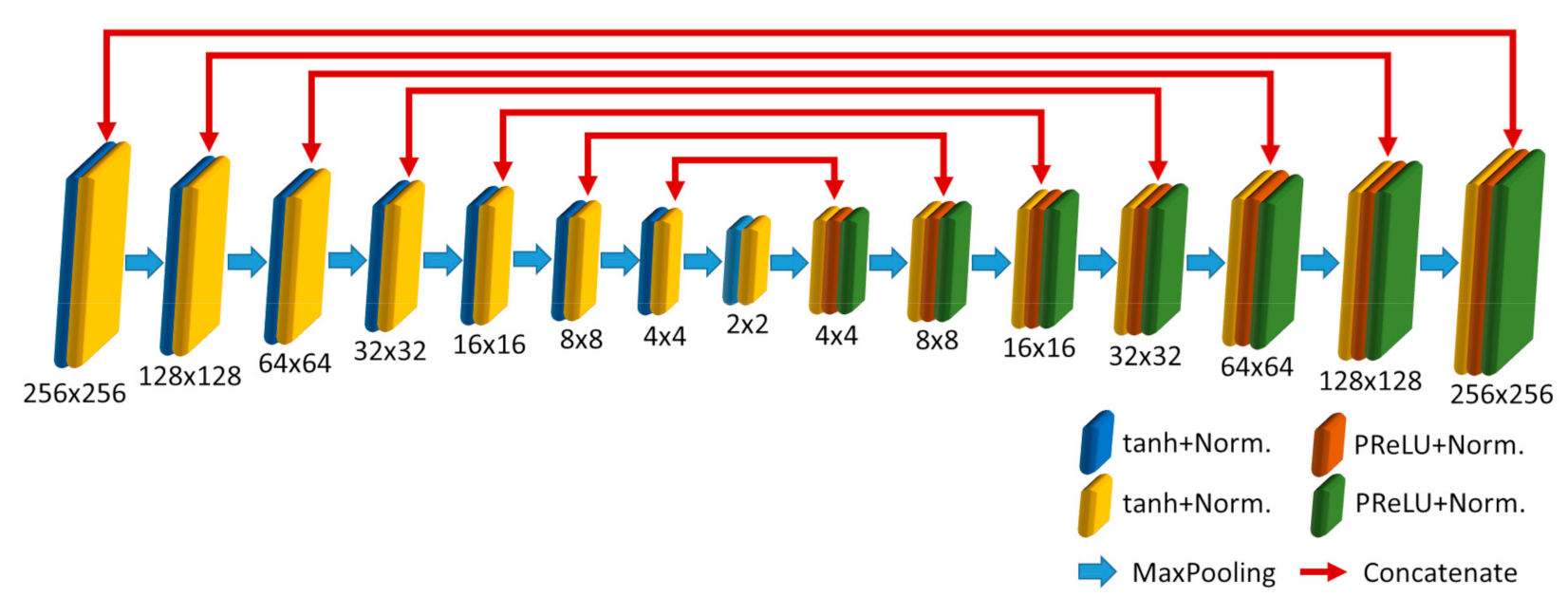
2.2.1. The Generator Network
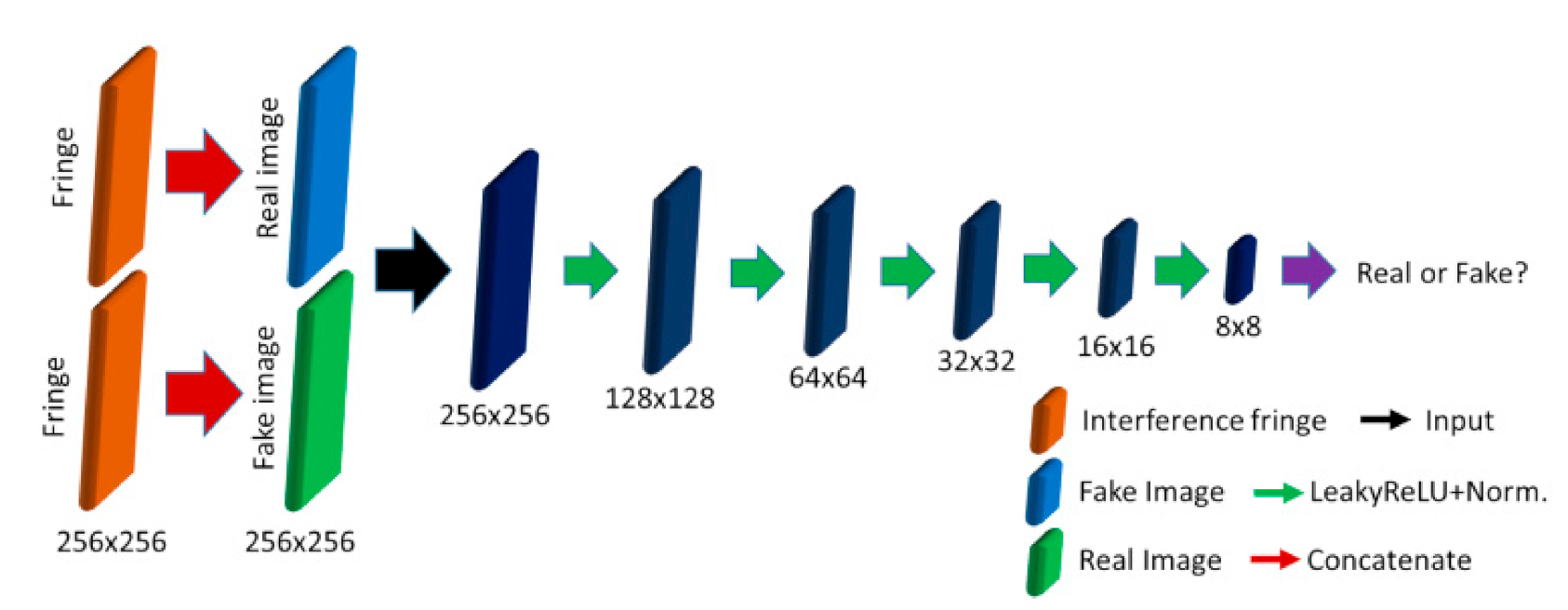
2.2.2. The Discriminator Network
2.2.3. Training GAN Model
2.2.4. Testing GAN Model
2.3. The Architecture of Experimental
3. Results
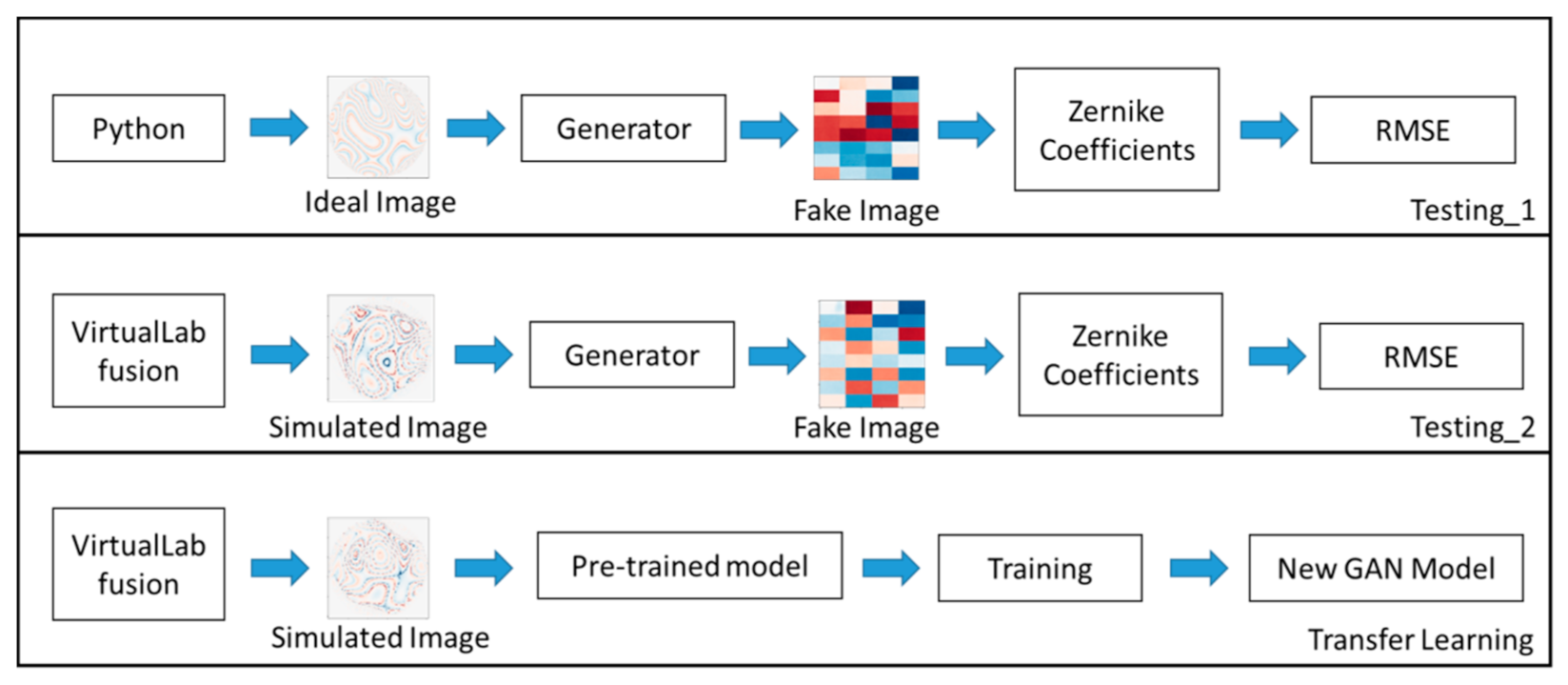
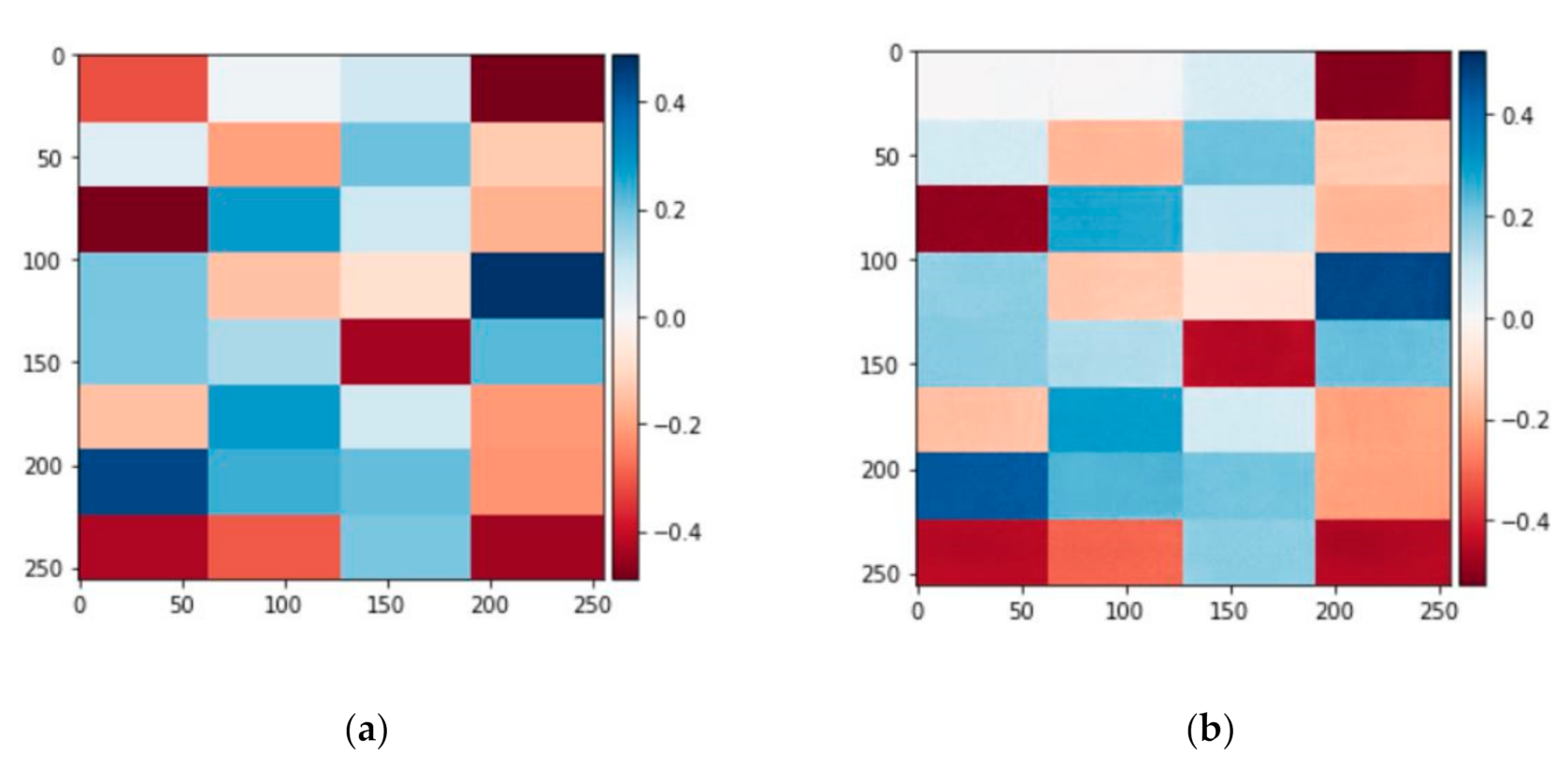
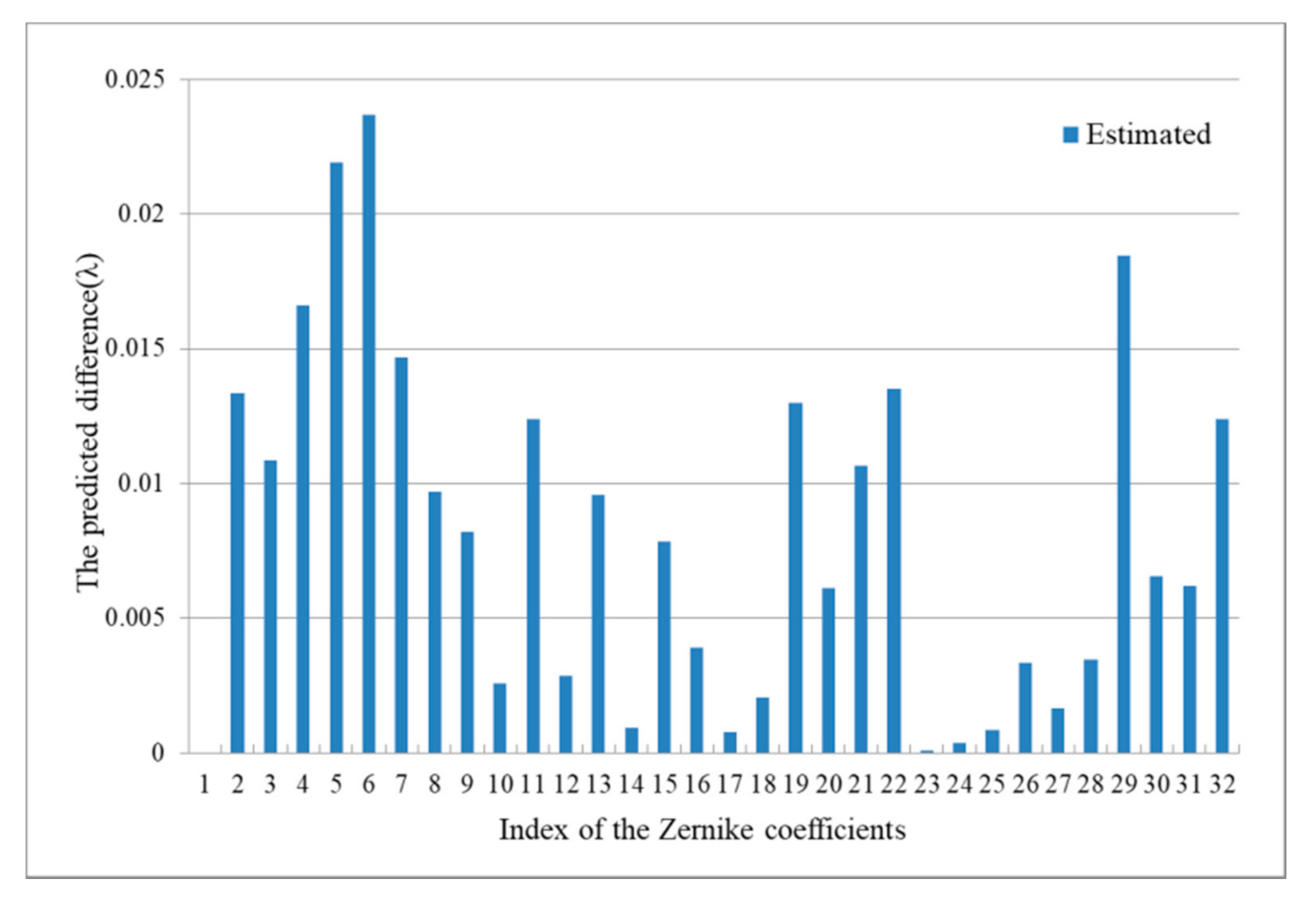
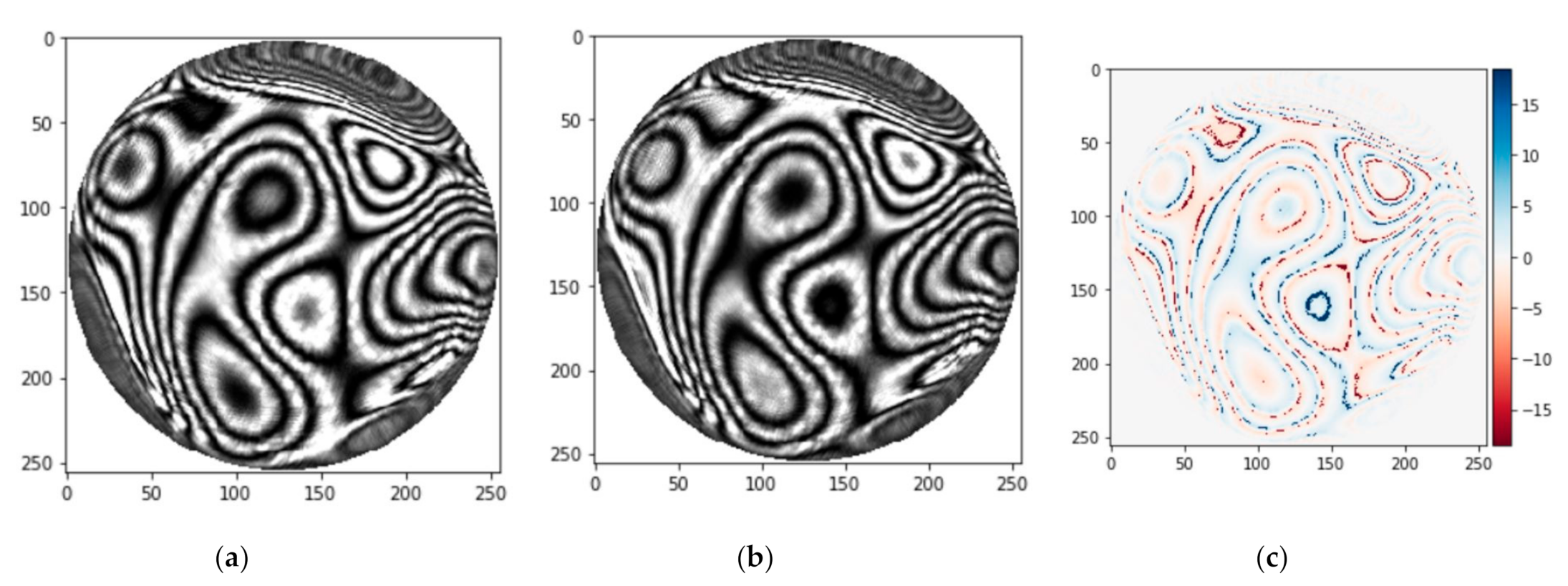
3.1. Testing_1 with Ideal Images
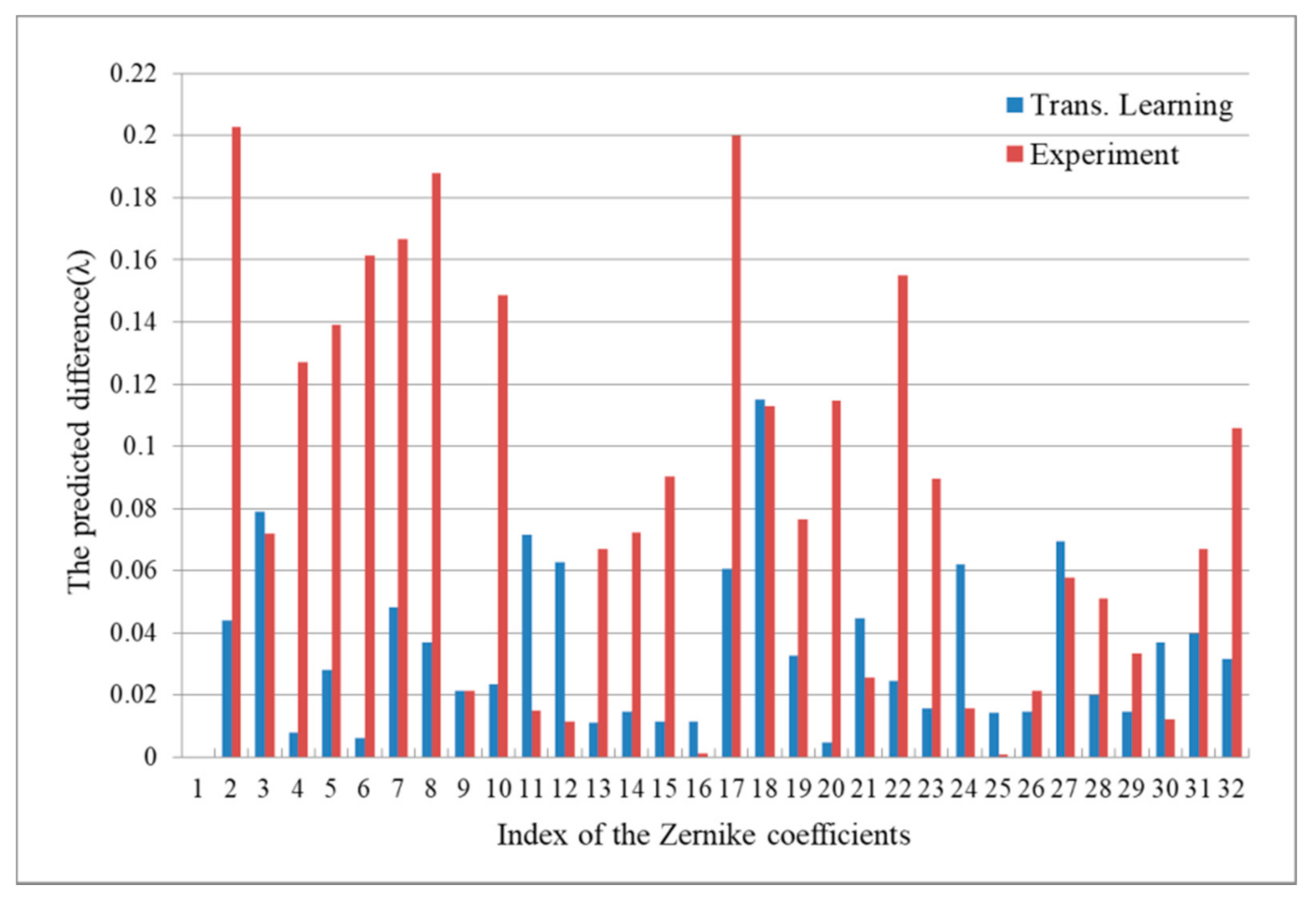
3.2. Testing_2 and Transfer Learning with Simulated Images
3.3. Summary
3.4. The Advantage of the GAN Model
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kidger, M. Importance of aberration theory in understanding lens design. In Proceedings of the Fifth International Topical Meeting on Education and Training in Optics, Delft, The Netherlands, 19–21 August 1997; Volume 3190, pp. 26–33. [Google Scholar]
- Lakshminarayanan, V.; Fleck, A. Zernike polynomials: A guide. J. Mod. Opt. Opt. 2011, 58, 545–561. [Google Scholar] [CrossRef]
- Gurov, I.; Volynsky, M. Interference fringe analysis based on recurrence computational algorithms. Opt. Lasers Eng. 2012, 50, 514–521. [Google Scholar] [CrossRef]
- Malacara-Hernandez, D.; Carpio-Valadez, M.; Sanchez-Mondragon, J.J. Wavefront fitting with discrete orthogonal polynomials in a unit radius circle. Opt. Eng. 1990, 29, 672–676. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. Deep Learning and Representation Learning Workshop. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the International Conference on Computer Vision (ICCV), Lido di Venezia, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. arXiv 2017, arXiv:1703.00848v6. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, Y.; Lu, Z.; Shao, Z.; Ran, M.; Zhou, J.; Fang, L.; Zhang, Y. Simultaneous denoising and super-resolution of optical coherence tomography images based on generative adversarial network. Opt. Express 2019, 27, 12289–12307. [Google Scholar] [CrossRef]
- Yu, Z.; Zhong, Y.; Gong, R.H.; Xie, H. Filling the binary images of draped fabric with pix2pix convolutional neural network. J. Eng. Fibers Fabr. 2020, 15, 1–6. [Google Scholar] [CrossRef]
- Barbastathis, G.; Ozcan, A.; Situ, G. On the use of deep learning for computational imaging. Optica 2019, 6, 8. [Google Scholar] [CrossRef]
- Wang, M.; Guo, W.; Yuan, X. Single-shot wavefront sensing with deep neural. Opt. Express 2021, 29, 3467–3478. [Google Scholar]
- Yu, F.; Wang, L.; Fang, X.; Zhang, Y. The Defense of Adversarial Example with Conditional Generative Adversarial Networks. Secur. Commun. Netw. 2020, 2020, 3932584. [Google Scholar] [CrossRef]
- Sargent, G.C.; Ratliff, B.M.; Asari, V.K. Conditional generative adversarial network demosaicing strategy for division of focal plane polarimeters. Opt. Express 2020, 28, 38419–38443. [Google Scholar] [CrossRef]
- Moon, I.; Jaferzadeh, K.; Kim, Y.; Javidi, B. Noise-free quantitative phase imaging in Gabor holography with conditional generative adversarial network. Opt. Express 2020, 28, 26284–26301. [Google Scholar] [CrossRef]
- Zhang, H.; Zhu, T.; Chen, X.; Zhu, L.; Jin, D.; Fei, P. Super-resolution generative adversarial network (SRGAN) enabled on-chip contact microscopy. J. Phys. D Appl. Phys. 2021, 54, 394005. [Google Scholar] [CrossRef]
- Saha, D.; Schmidt, U.; Zhang, Q.; Barbotin, A.; Hu, Q.; Ji, N.; Booth, M.J.; Weigert, M.; Myers, E.W. Practical sensorless aberration estimation for 3D microscopy with deep learning. Opt. Express 2020, 28, 29044–29053. [Google Scholar] [CrossRef]
- Kando, D.; Tomioka, S.; Miyamoto, N.; Ueda, R. Phase Extraction from Single Interferogram Including Closed-Fringe Using Deep Learning. Appl. Sci. 2019, 9, 3529. [Google Scholar] [CrossRef] [Green Version]
- Yan, K.; Yu, Y.; Huang, C.; Sui, L.; Qian, K.; Asundi, A. Fringe pattern denoising based on deep learning. Opt. Commun. 2019, 437, 148–152. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Li, Q.; Li, B. Fringe projection profilometry by conducting deep learning from its digital twin. Opt. Express 2020, 28, 36568–36583. [Google Scholar] [CrossRef]
- Feng, S.; Zuo, C.; Zhang, L.; Yin, W.; Chen, Q. Generalized framework for non-sinusoidal fringe analysis using deep learning. Photonics Res. 2021, 9, 1084–1098. [Google Scholar] [CrossRef]
- Whang, A.J.W.; Chen, Y.Y.; Chang, C.M.; Liang, Y.C.; Yang, T.H.; Lin, C.T.; Chou, C.H. Prediction technique of aberration coefficients of interference fringes and phase diagrams based on convolutional neural network. Opt. Express 2020, 28, 37601–37611. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Jin, Y.; Chen, J.; Wu, C.; Chen, Z.; Zhang, X.; Shen, H.L.; Gong, W.; Si, K. Wavefront reconstruction based on deep transfer learning for microscopy. Opt. Express 2020, 28, 20738–20747. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GoogLeNet [25] | GAN | |
|---|---|---|
| RMSE(λ) | 0.055 ± 0.021 | 0.0182 ± 0.0035 |
| GoogLeNet (VL) [25] | GAN (VL) | GAN (TL) | |
|---|---|---|---|
| RMSE(λ) | 0.095 ± 0.018 | 0.101 ± 0.0263 | 0.0586 ± 0.0183 |
| GoogLeNet [25] | GAN | |
|---|---|---|
| RMSE(λ) | 0.055 ± 0.021 | 0.0182 ± 0.0035 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Whang, A.J.-W.; Chen, Y.-Y.; Yang, T.-H.; Lin, C.-T.; Jian, Z.-J.; Chou, C.-H. Zernike Coefficient Prediction Technique for Interference Based on Generation Adversarial Network. Appl. Sci. 2021, 11, 6933. https://doi.org/10.3390/app11156933
Whang AJ-W, Chen Y-Y, Yang T-H, Lin C-T, Jian Z-J, Chou C-H. Zernike Coefficient Prediction Technique for Interference Based on Generation Adversarial Network. Applied Sciences. 2021; 11(15):6933. https://doi.org/10.3390/app11156933
Chicago/Turabian StyleWhang, Allen Jong-Woei, Yi-Yung Chen, Tsai-Hsien Yang, Cheng-Tse Lin, Zhi-Jia Jian, and Chun-Han Chou. 2021. "Zernike Coefficient Prediction Technique for Interference Based on Generation Adversarial Network" Applied Sciences 11, no. 15: 6933. https://doi.org/10.3390/app11156933