
A Hybrid Multi-Objective Evolutionary Algorithm-Based Semantic Foundation for Sustainable Distributed Manufacturing Systems




Abstract
:1. Introduction
- How can supervised machine-learning models be employed to find an efficient method for supplier classification, categorizing suppliers based on specific tasks?
- What type of mathematical model can be developed considering the optimization of various conflicting objectives such as completion time, energy consumption, interoperability, machine utilization rate, service utilization, and utility?
- In what way can evolutionary algorithms be utilized to optimize scheduling and planning?
- What are the benefits of the proposed approach on the considered problem, and how would these effects influence the manufacturing system in a real-time environment?
- How can the effectiveness of the proposed Hybridized evolutionary (HMFO) algorithm be validated?
- Proposing an integrated text-mining assisted process planning framework for distributed manufacturing systems;
- Employing a machine-learning-based text-mining method to identify the potential enterprises and sharing of resources effectively across the network and tested its feasibility with various other machine-learning algorithms;
- A multi-objective evolutionary algorithm-based Hybridized Moth Flame Optimization Algorithm (HMFO) is used to solve the considered problem in the scenario of distributed gear manufacturing industries;
2. Literature Review
3. Problem Description
- Job pre-emption is prohibited.
- Until the previous job is completed, the successive job cannot be processed.
- Only one job can be processed in an enterprise at a time.
- The reliability of a machine with respect to time is constant, and its value is the same for that particular machine for every operation while processing a job.
- At time t = 0, all machines and jobs are concurrently available.
- The operations of every job and its respective sequence consisting of future processing tasks need to be pre-defined.
- Xvp 1 The pth alternative process plan of job v is selected
- 0 Under other conditions
- Yvkpwtur 1 The operation Qvkp preceding over the operation Qwtu on given machine r
- 0 Under other conditions
- Zvkpr 1 If given machine r is selected for Qvkp
- 0 Under other conditions
3.1. Objectives
3.2. Subject to Constraints
4. A Framework of the Proposed Classifier-Assisted Evolutionary Algorithm Approach
5. Experimentation Part Text-Mining
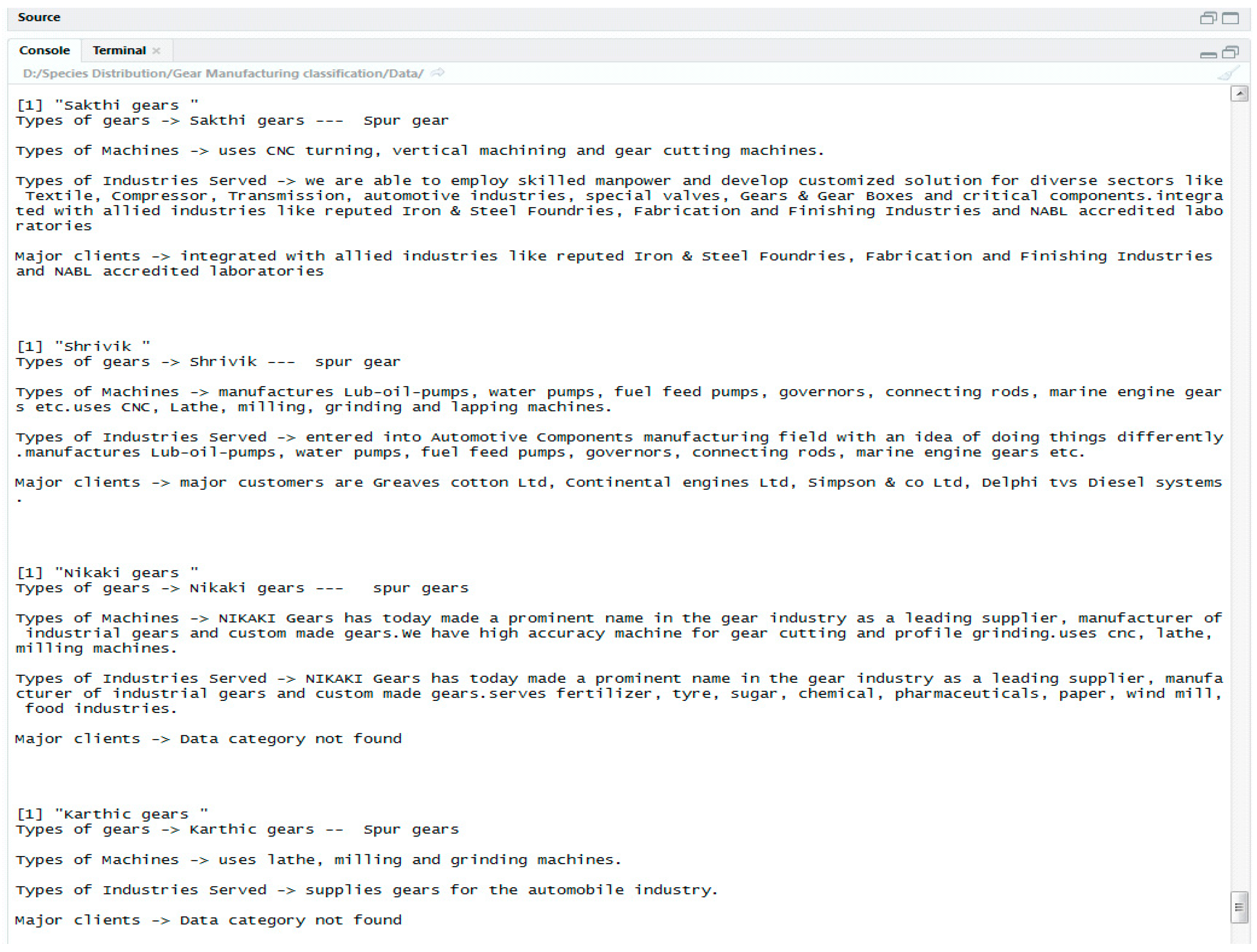
5.1. Task-Specific Supplier Classification through Supervised Machine-Learning Algorithms Based on Text Mining
- Step 1.
- Creation of Supplier Corpus.
- Step 2.
- Pre-Processing of Text Corpus and Creation of Document Term Matrix.
- Step 3.
- Classification into Task-Specific Suppliers.
5.2. Proposed Multi-Objective Evolutionary Algorithms
- Step 1.
- In HMFO, potential solutions are represented as moths and variables are represented as position in the moth space. A matrix consists of all the moths (n), and their dimension is d.
| M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | M9 | M10 | M11 | M12 | |
| O1 | [12 | 18 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O2 | 14 | 9 | 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O3 | 11 | 16 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0]; |
- Step 2.
| M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | M9 | M10 | M11 | M12 | |
| O1 | [175 | 312 | 198 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O2 | 400 | 234 | 330 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O3 | 325 | 429 | 352 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0; |
| O5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0]; |
- Step 3.
- A score function is defined that helps to select a suitable process plan, and it is shown in Equation (12), where a higher score value indicates that the probability of selecting the process plan is lesser. The lower the score value, the better the process plan. The formula for the score function is shown below.
- Step 4.
- A matrix CL is formed considering all the moths into the objective functions that are stored in FK represented below.
- Step 5.
- After an appropriate process plan is selected, we consider the rows as individual light sources through which we find the minimum values.
- Step 6.
- The matrices are explored row-wise to find a minimum entry in their respective rows once the required inputs are received and the search space is clearly initialized.
- Step 7.
- Moths maintain the best solution by updating its position Equation (13) by moving around the flag that is dropped by themselves during the search process. Update the position of the moth with respect to one flame. The spiral motion follows the Equation (13) represented as
- Step 8.
- After finding the minimum entry in the summed matrix and converting all ∞’s to 0s, the sum of all the values is found in their respective objective function matrices.
- Step 9.
- Finally, we solve the function to generate optimal values for all objectives.
6. Discussion and Results
6.1. Validation of Proposed HMFO Algorithm with the Experimental Instances
6.2. Evolution of Proposed HMFO with Practical Instances
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Srai, J.S.; Graham, G.; Hennelly, P.; Phillips, W.; Kapletia, D.; Lorentz, H. Distributed manufacturing: A new form of localised production? Int. J. Oper. Prod. Manag. 2020, 40, 697–727. [Google Scholar] [CrossRef]
- Ur-Rahman, N.; Harding, J.A. Textual data mining for industrial knowledge management and text classification: A business-oriented approach. Expert Syst. Appl. 2012, 39, 4729–4739. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Gao, L.; Chan, F.T.; Li, P. A holonic architecture of the concurrent integrated process planning system. J. Mater. Process. Technol. 2003, 139, 267–272. [Google Scholar] [CrossRef]
- Kumar, M.; Rajotia, S. Integration of scheduling with computer aided process planning. J. Mater. Process. Technol. 2003, 138, 297–300. [Google Scholar] [CrossRef]
- Choudhary, A.; Oluikpe, P.; Harding, J.; Carrillo, P. The needs and benefits of text mining applications on post-project reviews. Comput. Ind. 2009, 60, 728–740. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Wu, D. Using text mining and sentiment analysis for online forums hotspot detection and forecast. Decis. Support. Syst. 2010, 48, 354–368. [Google Scholar] [CrossRef]
- Kucheria, P.B.; Shaikh, I.R. Ontology Based Text Mining. Corpus ID: 212474163. Available online: https://www.semanticscholar.org/paper/Ontology-based-Text-Mining-Kucheria-Shaikh/ec8e69e2250eb5916e7aa1c782a9689bce985876 (accessed on 19 May 2021).
- Yazdizadeh, P.; Ameri, F. A text mining technique for manufacturing supplier classification. In Proceedings of the ASME 2015 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Boston, MA, USA, 2–5 August 2015. [Google Scholar]
- Morariu, C.; Morariu, O.; Răileanu, S.; Borangiu, T. Machine learning for predictive scheduling and resource allocation in large scale manufacturing systems. Comput. Ind. 2020, 120, 103244. [Google Scholar] [CrossRef]
- Park, K.; Kremer, G.O. Text mining-based categorization and user perspective analysis of environmental sustainability indicators for manufacturing and service systems. Ecol. Indic. 2017, 72, 803–820. [Google Scholar] [CrossRef]
- Akhtar, M.D.; Manupati, V.K.; Varela, M.L.R.; Putnik, G.D.; Madureira, A.M.; Abraham, A. Manufacturing services classification in a decentralized supply chain using text mining. In Advances in Intelligent Systems and Computing; Kacprzyk, J., Ed.; Springer Science and Business Media LLC: Warangal, India, 2018; pp. 186–193. [Google Scholar]
- Bianchi, G.; Bruni, R.; Scalfati, F. Identifying e-commerce in enterprises by means of text mining and classification algorithms. Math. Probl. Eng. 2018, 2018, 7231920. [Google Scholar] [CrossRef]
- Shao, X.; Li, X.; Gao, L.; Zhang, C. Integration of process planning and scheduling—A modified genetic algorithm-based approach. Comput. Oper. Res. 2009, 36, 2082–2096. [Google Scholar] [CrossRef]
- Chryssolouris, G.; Chan, S.; Cobb, W. Decision making on the factory floor: An integrated approach to process planning and scheduling. Robot. Comput. Manuf. 1984, 1, 315–319. [Google Scholar] [CrossRef]
- Chryssolouris, G.; Chan, S.; Suh, N. An integrated approach to process planning and scheduling. CIRP Ann. 1985, 34, 413–417. [Google Scholar] [CrossRef]
- Montreuil, B.; Frayret, J.-M.; D’Amours, S. A strategic framework for networked manufacturing. Comput. Ind. 2000, 42, 299–317. [Google Scholar] [CrossRef]
- Wang, Y.H.; Yin, C.W.; Zhang, Y. A multi-agent and distributed ruler based approach to production scheduling of agile manufacturing systems. Int. J. Comput. Integr. Manuf. 2003, 16, 81–92. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.-L. A novel disruptive innovation-like algorithm for single-machine scheduling with sequence-dependent family setup times. Appl. Sci. 2021, 11, 986. [Google Scholar] [CrossRef]
- Tursi, A.; Panetto, H.; Morel, G.; Dassisti, M. Ontological approach for products-centric information system interoperability in networked manufacturing enterprises. Annu. Rev. Control. 2009, 33, 238–245. [Google Scholar] [CrossRef] [Green Version]
- Dehghani, M.; Montazeri, Z.; Dehghani, A.; Malik, O.; Morales-Menendez, R.; Dhiman, G.; Nouri, N.; Ehsanifar, A.; Guerrero, J.M.; Ramirez-Mendoza, R.A. Binary spring search algorithm for solving various optimization problems. Appl. Sci. 2021, 11, 1286. [Google Scholar] [CrossRef]
- Manupati, V.; Thakkar, J.; Wong, K.; Tiwari, M. Near optimal process plan selection for multiple jobs in networked based manufacturing using multi-objective evolutionary algorithms. Comput. Ind. Eng. 2013, 66, 63–76. [Google Scholar] [CrossRef]
- Ehm, J.; Freitag, M.; Frazzon, E.M. A heuristic optimisation approach for the scheduling of integrated manufacturing and distribution systems. Procedia CIRP 2016, 57, 357–361. [Google Scholar] [CrossRef]
- Al-Shayea, A.; Fararah, E.; Nasr, E.A.; Mahmoud, H.A. Model for integrating production scheduling and maintenance planning of flow shop production system. IEEE Access 2020, 8, 208826–208835. [Google Scholar] [CrossRef]
- Manupati, V.; Deo, S.; Cheikhrouhou, N.; Tiwari, M. Optimal process plan selection in networked based manufacturing using game-theoretic approach. Int. J. Prod. Res. 2012, 50, 5239–5258. [Google Scholar] [CrossRef]
- Petrović, M.; Mitić, M.; Vuković, N.; Miljković, Z. Chaotic particle swarm optimization algorithm for flexible process planning. Int. J. Adv. Manuf. Technol. 2016, 85, 2535–2555. [Google Scholar] [CrossRef]
- Mohammadi, S.; Al-E-Hashem, S.M.; Rekik, Y. An integrated production scheduling and delivery route planning with multi-purpose machines: A case study from a furniture manufacturing company. Int. J. Prod. Econ. 2020, 219, 347–359. [Google Scholar] [CrossRef]
- Barzanji, R.; Naderi, B.; Begen, M.A. Decomposition algorithms for the integrated process planning and scheduling problem. Omega 2020, 93, 102025. [Google Scholar] [CrossRef]
- Ertogral, K.; Öztürk, F.S. An integrated production scheduling and workforce capacity planning model for the maintenance and repair operations in airline industry. Comput. Ind. Eng. 2019, 127, 832–840. [Google Scholar] [CrossRef]
- Li, X.; Gao, L.; Wang, W.; Wang, C.; Wen, L. Particle swarm optimization hybridized with genetic algorithm for uncertain integrated process planning and scheduling with interval processing time. Comput. Ind. Eng. 2019, 135, 1036–1046. [Google Scholar] [CrossRef]
- Cao, Y.; Zhang, H.; Li, W.; Zhou, M.; Zhang, Y.; Chaovalitwongse, W.A. Comprehensive learning particle swarm optimization algorithm with local search for multimodal functions. IEEE Trans. Evol. Comput. 2019, 23, 718–731. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, L.; Sarker, B.R.; Laili, Y.; Ren, L. An event-triggered dynamic scheduling method for randomly arriving tasks in cloud manufacturing. Int. J. Comput. Integr. Manuf. 2018, 31, 318–333. [Google Scholar] [CrossRef]
- Maturana, F.P.; Norrie, D.H. A generic mediator for multi-agent coordination in a distributed manufacturing system. In Proceedings of the 1995 IEEE International Conference on Systems, Man and Cybernetics. Intelligent Systems for the 21st Century, Vancouver, BC, Canada, 22–25 October 2002; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2002; pp. 952–957. [Google Scholar]
- Sohrabi, M.K.; Azgomi, H. A Survey on the combined use of optimization methods and game theory. Arch. Comput. Methods Eng. 2018, 27, 59–80. [Google Scholar] [CrossRef]
- Jia, H.; Fuh, J.; Nee, A.; Zhang, Y. Integration of genetic algorithm and Gantt chart for job shop scheduling in distributed manufacturing systems. Comput. Ind. Eng. 2007, 53, 313–320. [Google Scholar] [CrossRef]
- Shen, W.; Wang, L.; Hao, Q. Agent-based distributed manufacturing process planning and scheduling: A state-of-the-art survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2006, 36, 563–577. [Google Scholar] [CrossRef]
- Gao, J.; Smyrnakis, M.; Gao, H.T.; Xu, Y.; Barreiro-Gomez, J.; Ndong, M.; Smyrnakis, M.; Tembine, H. Distributionally Robust Optimization. Optim. Algorithms Ex. 2018. [Google Scholar] [CrossRef]
- Liu, B.; Wang, K.; Zhang, R. Variable neighborhood based memetic algorithm for distributed assembly permutation flowshop. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 1682–1686. [Google Scholar] [CrossRef]
- Kesen, S.E.; Das, S.K.; Güngör, Z. A genetic algorithm based heuristic for scheduling of virtual manufacturing cells (VMCs). Comput. Oper. Res. 2010, 37, 1148–1156. [Google Scholar] [CrossRef]
- Sortrakul, N.; Nachtmann, H.; Cassady, C. Genetic algorithms for integrated preventive maintenance planning and production scheduling for a single machine. Comput. Ind. 2005, 56, 161–168. [Google Scholar] [CrossRef]
- Li, W.D.; McMahon, C.A. A simulated annealing-based optimization approach for integrated process planning and scheduling. Int. J. Comput. Integr. Manuf. 2007, 20, 80–95. [Google Scholar] [CrossRef] [Green Version]
- Tiwari, A.; Chang, P.-C.; Tiwari, M.K.; Kandhway, R. A Hybrid Territory Defined evolutionary algorithm approach for closed loop green supply chain network design. Comput. Ind. Eng. 2016, 99, 432–447. [Google Scholar] [CrossRef]
- Li, Y.; Tao, F.; Cheng, Y.; Zhang, X.; Nee, A. Complex networks in advanced manufacturing systems. J. Manuf. Syst. 2017, 43, 409–421. [Google Scholar] [CrossRef] [Green Version]
- Tang, D.; Dai, M.; Salido, M.A.; Giret, A. Energy-efficient dynamic scheduling for a flexible flow shop using an improved particle swarm optimization. Comput. Ind. 2016, 81, 82–95. [Google Scholar] [CrossRef]
- Hou, Y.; Wu, N.; Zhou, M.; Li, Z. Pareto-optimization for scheduling of crude oil operations in refinery via genetic algorithm. IEEE Trans. Syst. Man, Cybern. Syst. 2015, 47, 517–530. [Google Scholar] [CrossRef]
- Wang, X.; Xing, K.; Yan, C.B.; Zhou, M. A novel MOEA/D for multiobjective scheduling of flexible manufacturing systems. Complexity 2019, 2019, 5734149. [Google Scholar] [CrossRef]
- Lin, L.; Hao, X.-C.; Gen, M.; Jo, J.-B. Network modeling and evolutionary optimization for scheduling in manufacturing. J. Intell. Manuf. 2011, 23, 2237–2253. [Google Scholar] [CrossRef]
- Piroozfard, H.; Wong, K.Y.; Hassan, A. A hybrid genetic algorithm with a knowledge-based operator for solving the job shop scheduling problems. J. Optim. 2016, 2016, 7319036. [Google Scholar] [CrossRef] [Green Version]
- Klement, N.; Abdeljaouad, M.A.; Porto, L.; Silva, C. Lot-sizing and scheduling for the plastic injection molding industry—A hybrid optimization approach. Appl. Sci. 2021, 11, 1202. [Google Scholar] [CrossRef]
- Beckham, C.; Hall, M.; Frank, E. WekaPyScript: Classification, regression, and filter schemes for WEKA implemented in Python. J. Open Res. Softw. 2016, 4, e33. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Tang, D.; Dai, M. Energy-efficient approach to minimizing the energy consumption in an extended job-shop scheduling problem. Chin. J. Mech. Eng. 2015, 28, 1048–1055. [Google Scholar] [CrossRef]
- Jin, L.; Zhang, C.; Fei, X. Realizing energy savings in integrated process planning and scheduling. Processes 2019, 7, 120. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.-Y.; Li, S.-F.; Ying, K.-C.; Liu, Y.-H. Scheduling jobs of two competing agents on a single machine. IEEE Access 2019, 7, 98702–98714. [Google Scholar] [CrossRef]
- Ying, K.-C.; Lin, S.-W.; Wan, S.-Y. Bi-objective reentrant hybrid flowshop scheduling: An iterated Pareto greedy algorithm. Int. J. Prod. Res. 2014, 52, 5735–5747. [Google Scholar] [CrossRef]
- Lin, S.-W.; Ying, K.-C. A multi-point simulated annealing heuristic for solving multiple objective unrelated parallel machine scheduling problems. Int. J. Prod. Res. 2014, 53, 1065–1076. [Google Scholar] [CrossRef]
- Audet, C.; Bigeon, J.; Cartier, D.; Le Digabel, S.; Salomon, L. Performance indicators in multiobjective optimization. Eur. J. Oper. Res. 2021, 292, 397–422. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Imada, R.; Setoguchi, Y.; Nojima, Y. How to specify a reference point in hypervolume calculation for fair performance comparison. Evol. Comput. 2018, 26, 411–440. [Google Scholar] [CrossRef] [PubMed]
- Haber, R.E.; Beruvides, G.; Quiza, R.; Hernandez, A. A Simple multi-objective optimization based on the cross-entropy method. IEEE Access 2017, 5, 22272–22281. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, H.; Yang, K.; Bäck, T.; Emmerich, M. SMS-EMOA with multiple dynamic reference points. In Proceedings of the 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2016; pp. 282–288. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| E | The number of all the available jobs |
| G | The number of all the available machines |
| Hv | The number of all the available alternative process plans of job v. |
| Qvpk | pth alternative process plan for kth operation of job v |
| Svp | The number of all the available operations in the pth alternative process plan of the job v |
| L | Maximum completion time of vth job from the all the available process plans |
| Dvkpr | For operation Qvkp corresponding processing time of the on machine r |
| B | An arbitrary Integer which is a very large positive integer. |
| Cv | The completion time till the processing of job v |
| Cvkpr | The earliest completion time till the operation Qvkp on machine r |
| Evkr | Indicates energy consumption for processing kth operation of job v on machine r |
| Relvk | Indicates reliability of the kth operation of job v |
| Category 1 | Bevel gear |
| Category 2 | Helical and worm |
| Category 3 | Helical gear |
| Category 4 | Spur gear |
| Category 5 | Worm gear |
| Category 6 | All types of gear |
| Types of machines (CNC, LATHE) |
| Types of operations (milling, drilling, and grinding) |
| Types of gears (spur, helical, and bevel) |
| Types of materials (steel, aluminum, bronze, and brass) |
| Types of certifications (ISO 9000, ISO 14000 |
| Types of manufacturing process (casting, forging, and extrusion) |
| Decision Tree (J48) | ||||||||
| TP Rate | FP Rate | Precession | Recall | F-Measure | MCC | ROC Area | PRC Area | Class |
| 0.400 | 0.000 | 1.000 | 0.400 | 0.571 | 0.604 | 0.881 | 0.694 | All types |
| 1.000 | 0.033 | 0.857 | 1.000 | 0.923 | 0.910 | 0.983 | 0.857 | Bevel gear |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Helical and worm gear |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Helical gear |
| 1.000 | 0.071 | 0.800 | 1.000 | 0.889 | 0.862 | 0.991 | 0.950 | Spur gear |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Worm gear |
| 0.917 | 0.021 | 0.932 | 0.917 | 0.903 | 0.899 | 0.979 | 0.923 | Weighted Avg. |
| Naïve Bayes | ||||||||
| TP Rate | FP Rate | Precession | Recall | F-Measure | MCC | ROC Area | PRC Area | Class |
| 0.200 | 0.097 | 0.250 | 0.200 | 0.222 | 0.114 | 0.490 | 0.181 | All types |
| 0.833 | 0.033 | 0.833 | 0.833 | 0.833 | 0.800 | 0.978 | 0.897 | Bevel gear |
| 0.500 | 0.125 | 0.333 | 0.500 | 0.400 | 0.316 | 0.672 | 0.573 | Helical and worm gear |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Helical gear |
| 0.875 | 0.000 | 1.000 | 0.875 | 0.933 | 0.919 | 0.938 | 0.920 | Spur gear |
| 0.714 | 0.069 | 0.714 | 0.714 | 0.714 | 0.645 | 0.808 | 0.723 | Worm gear |
| 0.722 | 0.046 | 0.738 | 0.722 | 0.727 | 0.681 | 0.838 | 0.750 | Weighted Avg. |
| Random Forest | ||||||||
| TP Rate | FP Rate | Precession | Recall | F-Measure | MCC | ROC Area | PRC Area | Class |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.771 | 0.435 | All types |
| 1.000 | 0.067 | 0.750 | 1.000 | 0.857 | 0.837 | 1.000 | 1.000 | Bevel gear |
| 0.500 | 0.063 | 0.500 | 0.500 | 0.500 | 0.438 | 0.969 | 0.817 | Helical and worm gear |
| 1.000 | 0.033 | 0.857 | 1.000 | 0.923 | 0.910 | 1.000 | 1.000 | Helical gear |
| 0.875 | 0.036 | 0.875 | 0.875 | 0.875 | 0.839 | 0.996 | 0.986 | Spur gear |
| 1.000 | 0.069 | 0.778 | 1.000 | 0.875 | 0.851 | 1.000 | 1.000 | Worm gear |
| 0.778 | 0.045 | 0.669 | 0.778 | 0.717 | 0.692 | 0.964 | 0.898 | Weighted Avg. |
| Support Vector Machines | ||||||||
| TP Rate | FP Rate | Precession | Recall | F-Measure | MCC | ROC Area | PRC Area | Class |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.500 | 0.139 | All types |
| 0.667 | 0.033 | 0.800 | 0.667 | 0.727 | 0.683 | 0.817 | 0.589 | Bevel gear |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.500 | 0.111 | Helical and worm gear |
| 0.500 | 0.000 | 1.000 | 0.500 | 0.667 | 0.674 | 0.750 | 0.583 | Helical gear |
| 0.875 | 0.286 | 0.467 | 0.875 | 0.609 | 0.497 | 0.795 | 0.436 | Spur gear |
| 0.857 | 0.241 | 0.462 | 0.857 | 0.600 | 0.507 | 0.808 | 0.423 | Worm gear |
| 0.483 | 0.093333 | 0.454833 | 0.483 | 0.433 | 0.3935 | 0.695 | 0.380 | Weighted Avg. |
| Process Parameters | HMFEO | NSGA II |
|---|---|---|
| Population Size/No. of Moths | 200 | 200 |
| Number of generations | 1500 | 1500 |
| Mutation Probability | - | 0.07 |
| Cross-Over Probability | - | 0.76 |
| Machine | M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | M9 | M10 | M11 | M12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Energy consumption | 15 | 29 | 32 | 14 | 11 | 12 | 19 | 24 | 14 | 16 | 22 | 11 |
| Reliability | 0.76 | 0.82 | 0.78 | 0.84 | 0.84 | 0.92 | 0.89 | 0.94 | 0.88 | 0.95 | 0.84 | 0.92 |
| Jobs | Machines | Processing Time Range | GA-SA (Instance 1 to 32) GA-MA (Instance 33 to 35) | Proposed HMFO | |||
|---|---|---|---|---|---|---|---|
| Makespan | Energy Consumption | Makespan | Energy Consumption | ||||
| Instance 1 | 3 | 5 | [1, 10] | 41 | 138.1 | 30.8 | 26.3 |
| Instance 2 | 3 | 7 | [1, 10] | 54.1 | 205.4 | 43 | 190.5 |
| Instance 3 | 3 | 10 | [1, 10] | 61.2 | 229.1 | 49.7 | 204 |
| Instance 4 | 3 | 5 | [1, 50] | 190.3 | 708.7 | 171 | 617 |
| Instance 5 | 3 | 7 | [1, 50] | 252.8 | 960.6 | 226.7 | 834 |
| Instance6 | 3 | 10 | [1, 50] | 333.8 | 1273.3 | 301.7 | 1110 |
| Instance7 | 3 | 5 | [1, 100] | 375.4 | 1307.1 | 319.3 | 1134 |
| Instance8 | 3 | 7 | [1, 100] | 531.9 | 1895.4 | 516.7 | 1644.9 |
| Instance9 | 3 | 10 | [1, 100] | 729.1 | 2830.5 | 698 | 2467.5 |
| Instance10 | 5 | 5 | [1, 10] | 35 | 140.4 | 24 | 126.1 |
| Instance11 | 5 | 7 | [1, 10] | 46 | 186.3 | 30 | 169 |
| Instance12 | 5 | 10 | [1, 10] | 51.5 | 199.9 | 43.7 | 177 |
| Instance13 | 5 | 5 | [1, 50] | 165.5 | 671.5 | 149.8 | 583.9 |
| Instance14 | 5 | 7 | [1, 50] | 225.2 | 951.2 | 201.7 | 828 |
| Instance15 | 5 | 10 | [1, 50] | 317 | 1303.6 | 306.8 | 1139 |
| Instance16 | 5 | 5 | [1, 100] | 325.5 | 1253.2 | 311.7 | 1098 |
| Instance17 | 5 | 7 | [1, 100] | 436.9 | 1909 | 410 | 1663 |
| Instance18 | 5 | 10 | [1, 100] | 610.3 | 2587.5 | 598 | 2257 |
| Instance19 | 7 | 5 | [1, 10] | 28.7 | 110.9 | 19.6 | 96.7 |
| Instance20 | 7 | 7 | [1, 10] | 39.3 | 162.2 | 24 | 146 |
| Instance21 | 7 | 10 | [1, 10] | 56.5 | 241.6 | 49 | 218 |
| Instance22 | 7 | 5 | [1, 50] | 159.7 | 607 | 143 | 524 |
| Instance23 | 7 | 7 | [1, 50] | 220.8 | 919.1 | 206 | 846 |
| Instance24 | 7 | 10 | [1, 50] | 304.6 | 1310.5 | 265.002 | 1150.9 |
| Instance25 | 7 | 5 | [1, 100] | 351 | 1422.9 | 305.37 | 1287.9 |
| Instance26 | 7 | 7 | [1, 100] | 426.1 | 1978.3 | 370.7 | 1725 |
| Instance27 | 7 | 10 | [1, 100] | 625.9 | 2664.1 | 544.5 | 2319.7 |
| Instance28 | 10 | 10 | [1, 200] | 939.04 | 9873.2 | 816.96 | 8597.6 |
| Instance29 | 15 | 15 | [1, 200] | 1554.12 | 22,505.2 | 1352.08 | 19,579.5 |
| Instance30 | 20 | 20 | [1, 200] | 4778.07 | 80,577.2 | 4156 | 70,102.16 |
| Instance31 | 20 | 20 | [1, 200] | 7753.04 | 100,073.4 | 6749 | 87,263.8 |
| Instance32 | 20 | 20 | [1, 200] | 15,062.5 | 197,787.5 | 13,115 | 172,975.7 |
| Instance 33 | 18 | 15 | [1, 200] | 531 | 13,340.3 | 502 | 12,986 |
| Instance 34 | 18 | 15 | [1, 200] | 810 | 2036.32 | 739 | 1956 |
| Instance 35 | 18 | 15 | [1, 200] | 680 | 2267.88 | 593 | 1837.6 |
| Case | Process Plans Selected | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Jobs | Machines | J1 | J2 | J3 | J4 | J5 | J6 | J7 | J8 | |
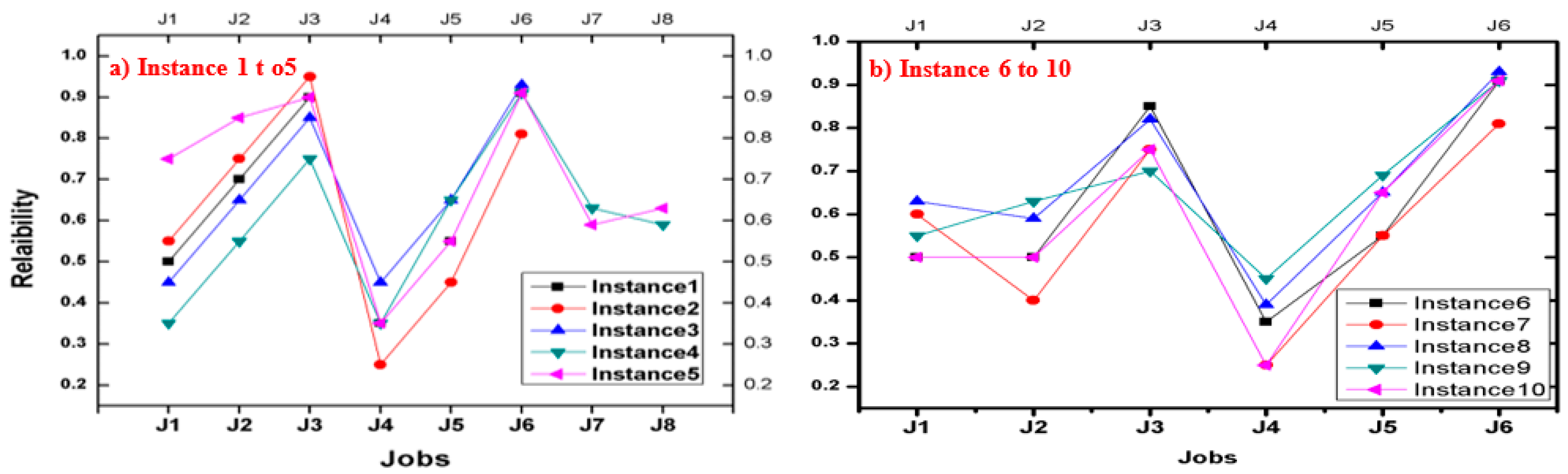
| Instance1 | 6 | 6 | 2 | 2 | 2 | 2 | 2 | 2 | - | - |
| Instance2 | 6 | 6 | 1 | 1 | 2 | 2 | 1 | 2 | - | - |
| Instance3 | 6 | 8 | 3 | 1 | 2 | 3 | 3 | 4 | - | - |
| Instance4 | 8 | 8 | 2 | 2 | 2 | 2 | 1 | 2 | 1 | 3 |
| Instance5 | 8 | 8 | 2 | 1 | 2 | 1 | 1 | 1 | 2 | 2 |
| Instance6 | 6 | 12 | 1 | 1 | 1 | 1 | 2 | 1 | - | - |
| Instance7 | 6 | 12 | 2 | 2 | 2 | 3 | 2 | 2 | - | - |
| Instance8 | 6 | 12 | 2 | 2 | 2 | 2 | 2 | 2 | - | - |
| Instance9 | 6 | 12 | 2 | 1 | 1 | 2 | 2 | 1 | - | - |
| Instance10 | 6 | 12 | 2 | 1 | 1 | 3 | 2 | 1 | - | - |
| Jobs | Machines | Proposed HMFO | NSGA-II | |||
|---|---|---|---|---|---|---|
| Makespan | Energy Consumption | Makespan | Energy Consumption | |||
| Instance 1 | 6 | 6 | 30 | 8906 | 35 | 9083 |
| Instance 2 | 6 | 6 | 27 | 8325 | 38 | 8700 |
| Instance 3 | 6 | 8 | 179 | 39,658 | 187 | 44,920 |
| Instance 4 | 8 | 8 | 42 | 13,089 | 50 | 14,040 |
| Instance 5 | 8 | 8 | 50 | 10,129 | 62 | 11,189 |
| Instance6 | 6 | 12 | 986 | 15,553 | 1083 | 17,694 |
| Instance7 | 6 | 12 | 1179 | 15,224.5 | 1256 | 16,785 |
| Instance8 | 6 | 12 | 1026 | 13,881 | 1094 | 14,205.5 |
| Instance9 | 6 | 12 | 669 | 14,298 | 756 | 14,898.5 |
| Instance10 | 6 | 12 | 814 | 14,143.5 | 884 | 14,678 |
| Indicator | Algorithm | Instance | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| α | HMFEO NSGA II | 8.5 8.0 | 10.8 10.5 | 9.7 9.4 | 10.6 10.6 | 8.8 8.6 |
| β | HMFEO NSGA II | 8.1 7.0 | 10.7 9.5 | 9.5 9.3 | 10.6 9.3 | 8.6 8.3 |
| ᵝ/ᵅ | HMFEO NSGA II | 0.9529 0.8750 | 0.9900 0.9047 | 0.9700 0.9893 | 1.0000 0.8773 | 0.9700 0.9651 |
| ϒ | HMFEO NSGA II | 0.5264 0.4736 | 0.5079 0.4921 | 0.6012 0.3988 | 0.5000 0.5000 | 0.5264 0.4736 |
| K | HMFEO NSGA II | 0.0800 0.1250 | 0.0100 0.0953 | 0.0300 0.0107 | 0.0000 0.1227 | 0.0300 0.0349 |
| λ | HMFEO NSGA II | 0.3693 12.123 | 0.0037 9.236 | 0.6289 8.265 | 0.0000 8.6321 | 0.0042 9.5632 |
| π | HMFEO NSGA II | 0.4236 0.4125 | 0.4856 0.5563 | 0.4982 0.6029 | 0.4932 0.6765 | 0.4495 0.5988 |
| HR | HMFEO NSGA II | 0.8526 1.2536 | 0.7445 1.1456 | 0.9538 0.9469 | 0.6984 0.9548 | 0.4495 0.9854 |
| Indicator | Algorithm | Instance | ||||
|---|---|---|---|---|---|---|
| 6 | 7 | 8 | 9 | 10 | ||
| α | HMFEO NSGA II | 12.5 12.0 | 13.8 10.5 | 9.7 9.4 | 16.6 16.6 | 9.8 8.8 |
| β | HMFEO NSGA II | 12.1 11.0 | 12.7 9.2 | 9.5 9.3 | 16.6 15.0 | 9.6 8.3 |
| ᵝ/ᵅ | HMFEO NSGA II | 0.9682 0.9166 | 0.9202 0.8761 | 0.9700 0.9893 | 1.0000 0.9036 | 0.9795 0.9431 |
| Ω | HMFEO NSGA II | 0.5151 0.4848 | 0.5070 0.4929 | 0.5078 0.4922 | 0.5000 0.5000 | 0.5057 0.4942 |
| K | HMFEO NSGA II | 0.0800 0.1250 | 0.0104 0.0835 | 0.0310 0.0307 | 0.0000 0.1027 | 0.0400 0.0349 |
| λ | HMFEO NSGA II | 0.4693 12.123 | 0.0089 9.236 | 0.5259 8.265 | 0.0000 8.6321 | 0.0063 10.5632 |
| π | HMFEO NSGA II | 0.5136 0.4125 | 0.4856 0.4563 | 0.4982 0.5129 | 0.4932 0.5365 | 0.4445 0.5488 |
| HR | HMFEO NSGA II | 0.7415 0.9438 | 0.8556 1.2465 | 0.8629 1.1803 | 0.7875 1.9888 | 0.7589 0.8765 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramakurthi, V.B.; Manupati, V.K.; Machado, J.; Varela, L. A Hybrid Multi-Objective Evolutionary Algorithm-Based Semantic Foundation for Sustainable Distributed Manufacturing Systems. Appl. Sci. 2021, 11, 6314. https://doi.org/10.3390/app11146314
Ramakurthi VB, Manupati VK, Machado J, Varela L. A Hybrid Multi-Objective Evolutionary Algorithm-Based Semantic Foundation for Sustainable Distributed Manufacturing Systems. Applied Sciences. 2021; 11(14):6314. https://doi.org/10.3390/app11146314
Chicago/Turabian StyleRamakurthi, Veera Babu, V. K. Manupati, José Machado, and Leonilde Varela. 2021. "A Hybrid Multi-Objective Evolutionary Algorithm-Based Semantic Foundation for Sustainable Distributed Manufacturing Systems" Applied Sciences 11, no. 14: 6314. https://doi.org/10.3390/app11146314