
Generation and Annotation of Simulation-Real Ship Images for Convolutional Neural Networks Training and Testing


Abstract
:1. Introduction
2. Methodology
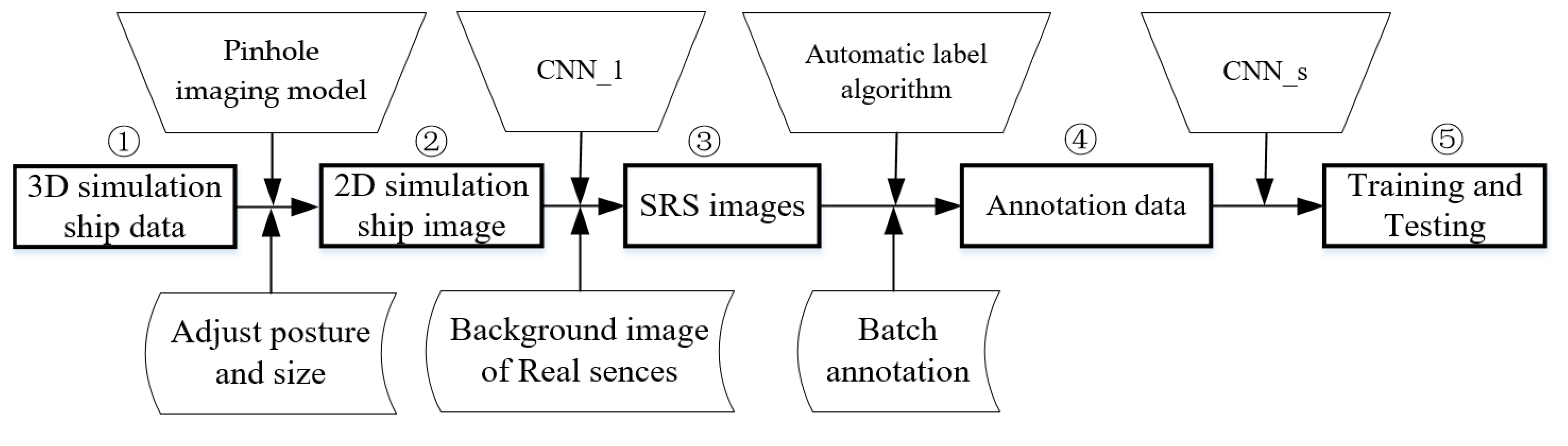
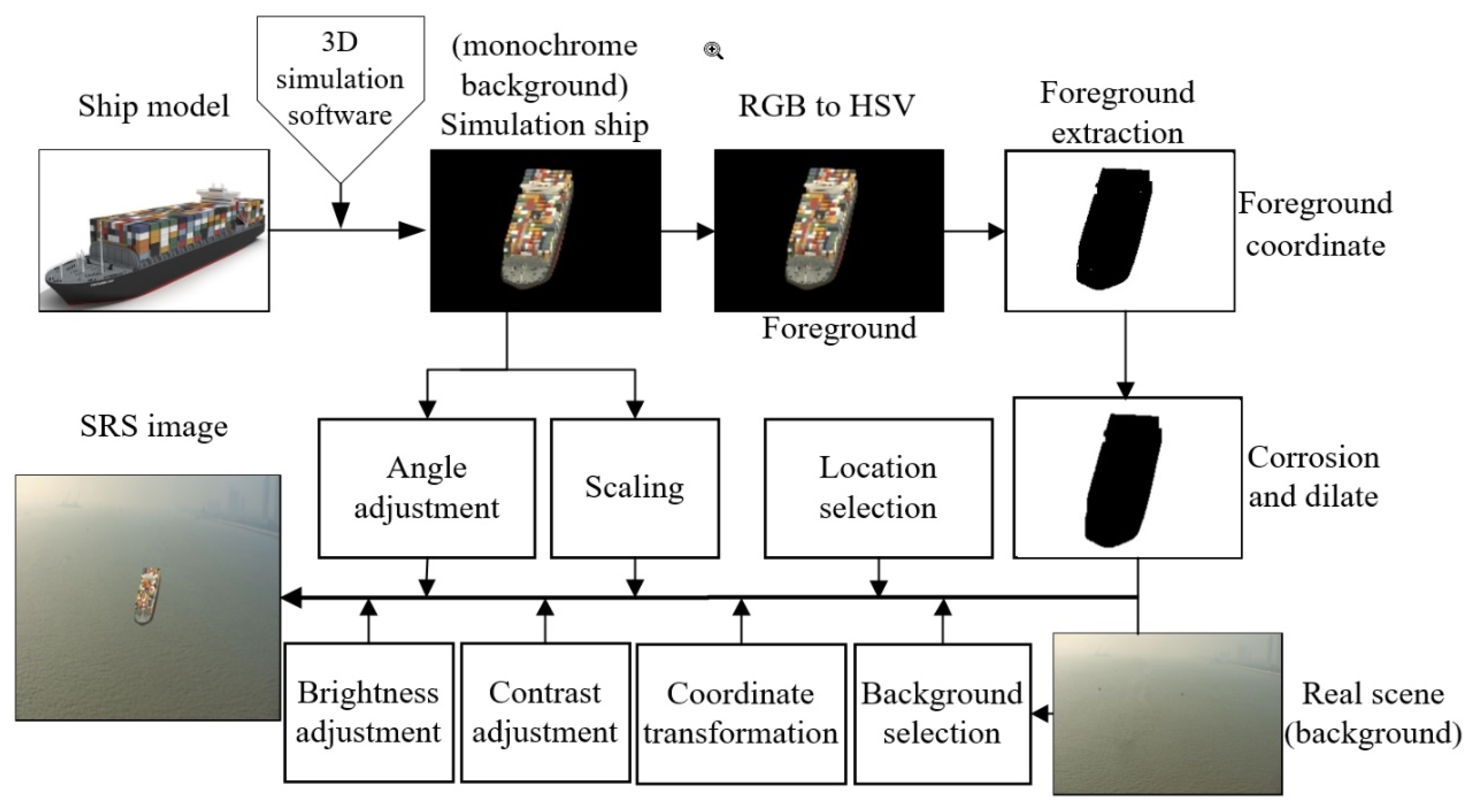
2.1. The Proposed Method of SRS Images Generation
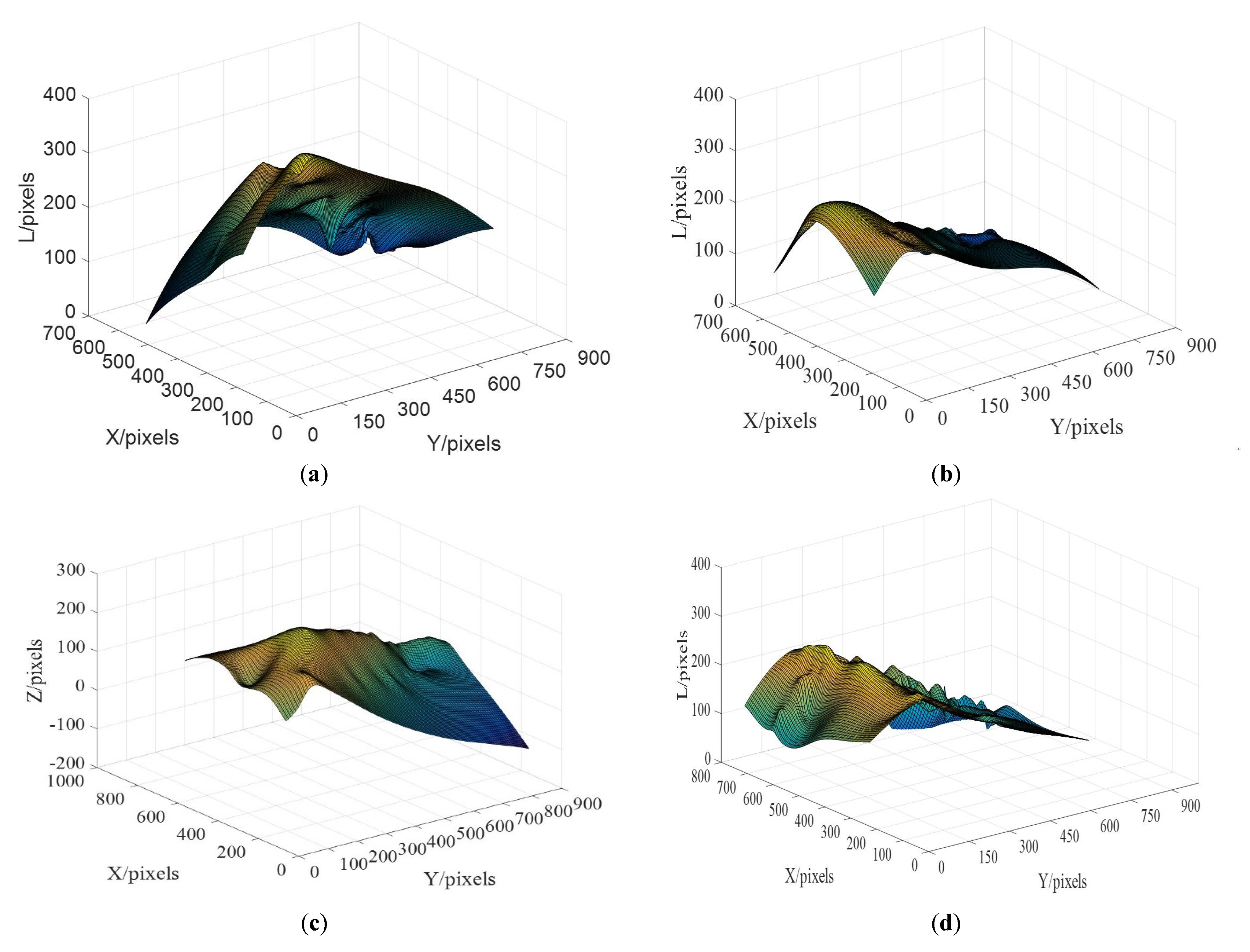
2.1.1. 2D Ship Image Generation from 3D Ship Model
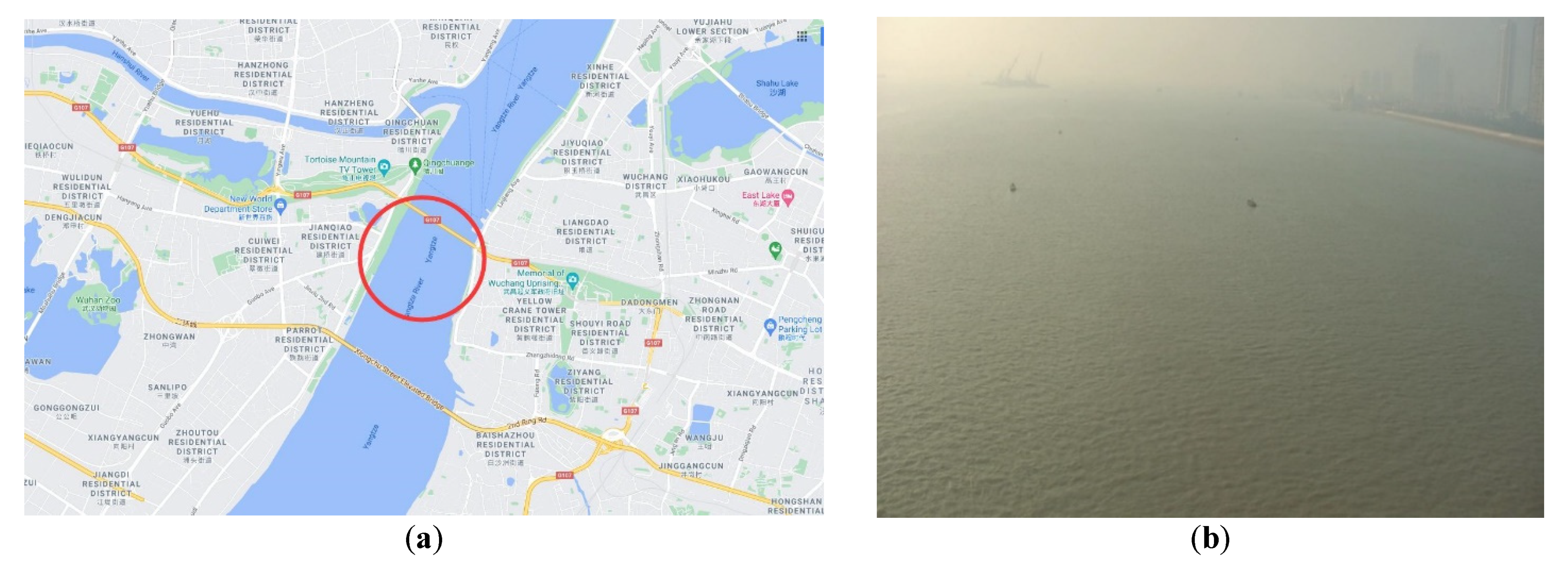
2.1.2. Selection of the Background Images
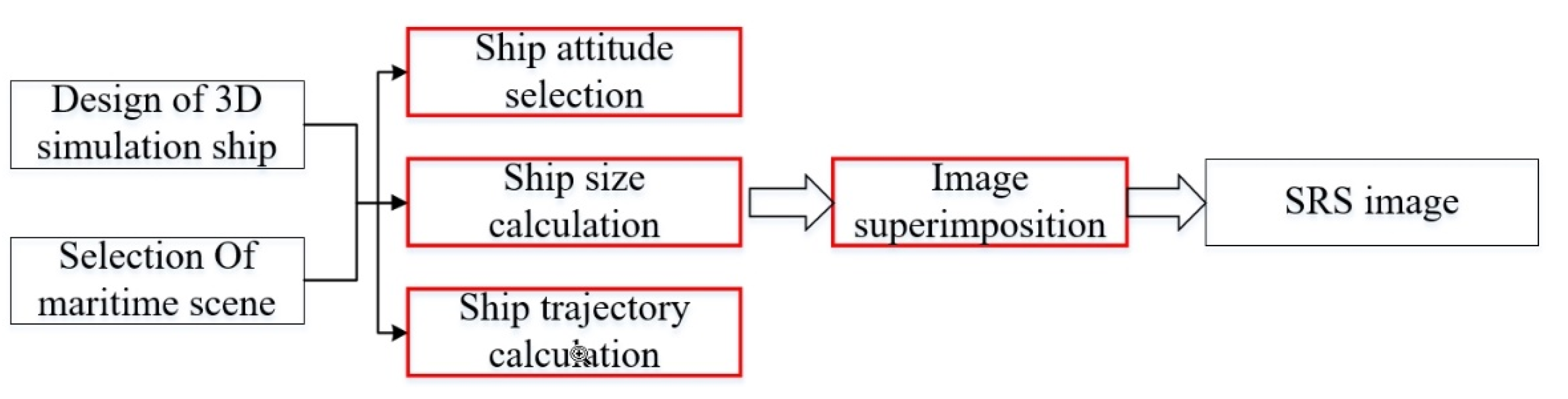
2.1.3. SRS Image Generation
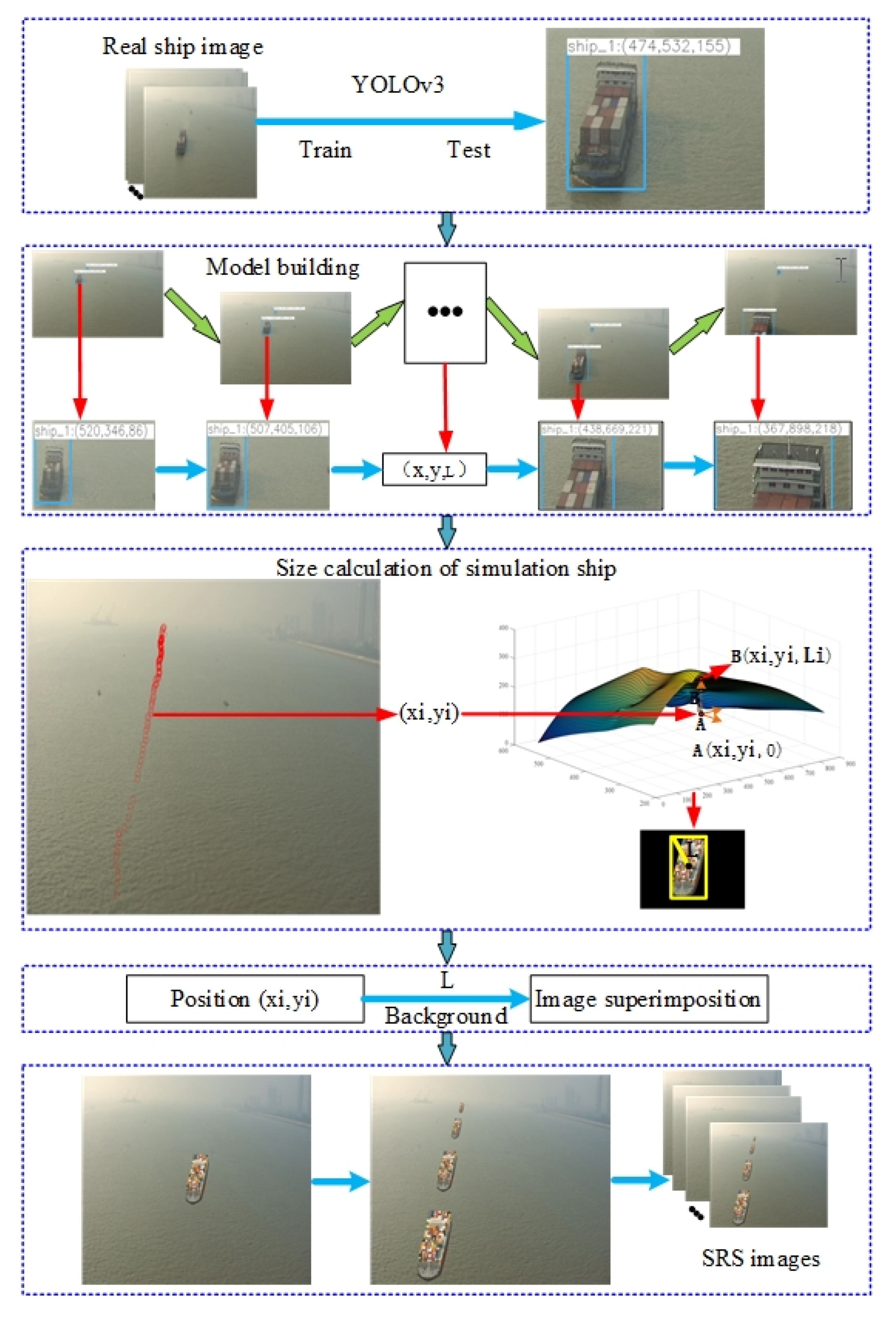
Calculate the Size of the Simulation Ships
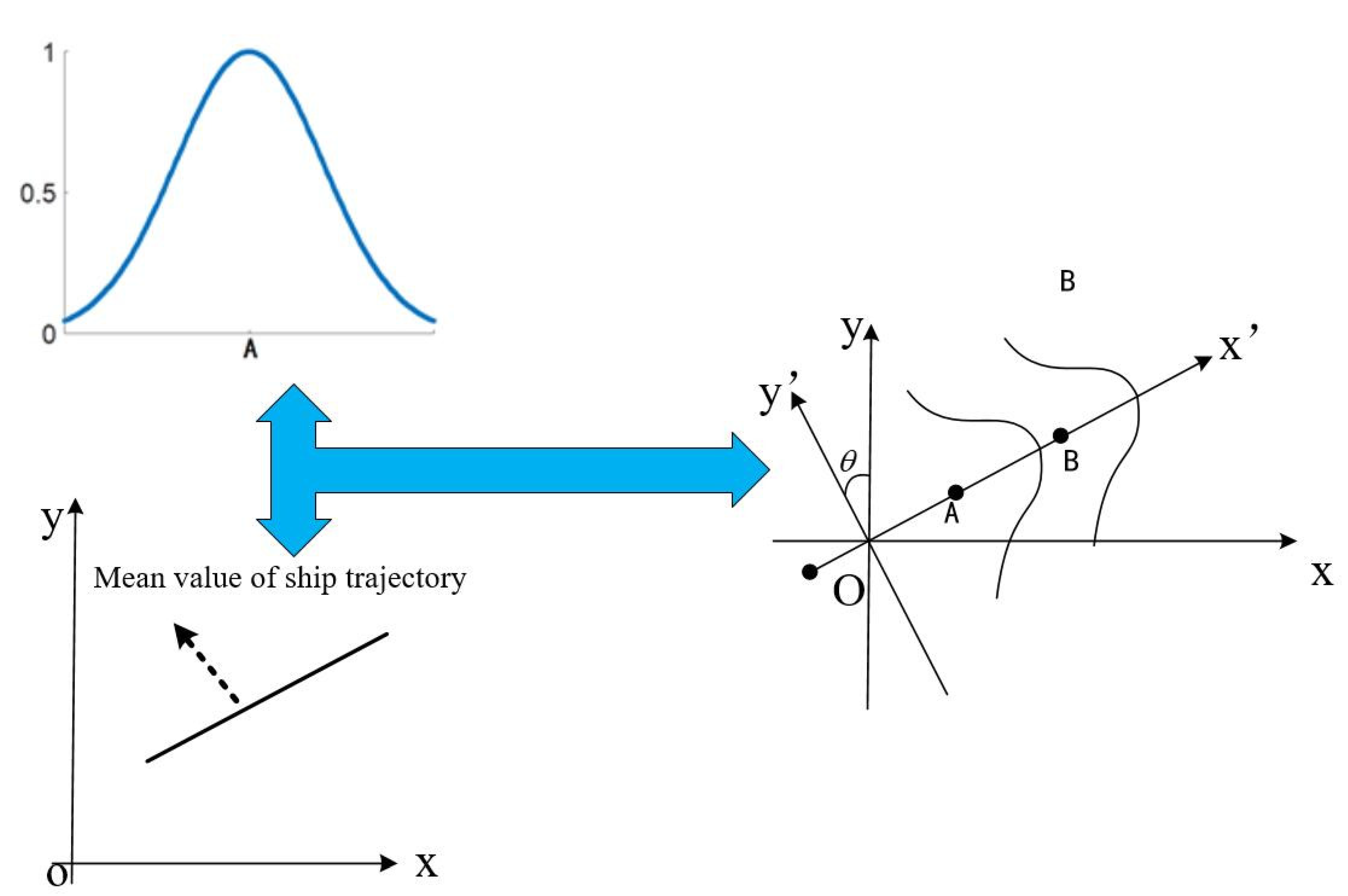
Calculate the Trajectory of Simulation Ships
Generation of SRS Images
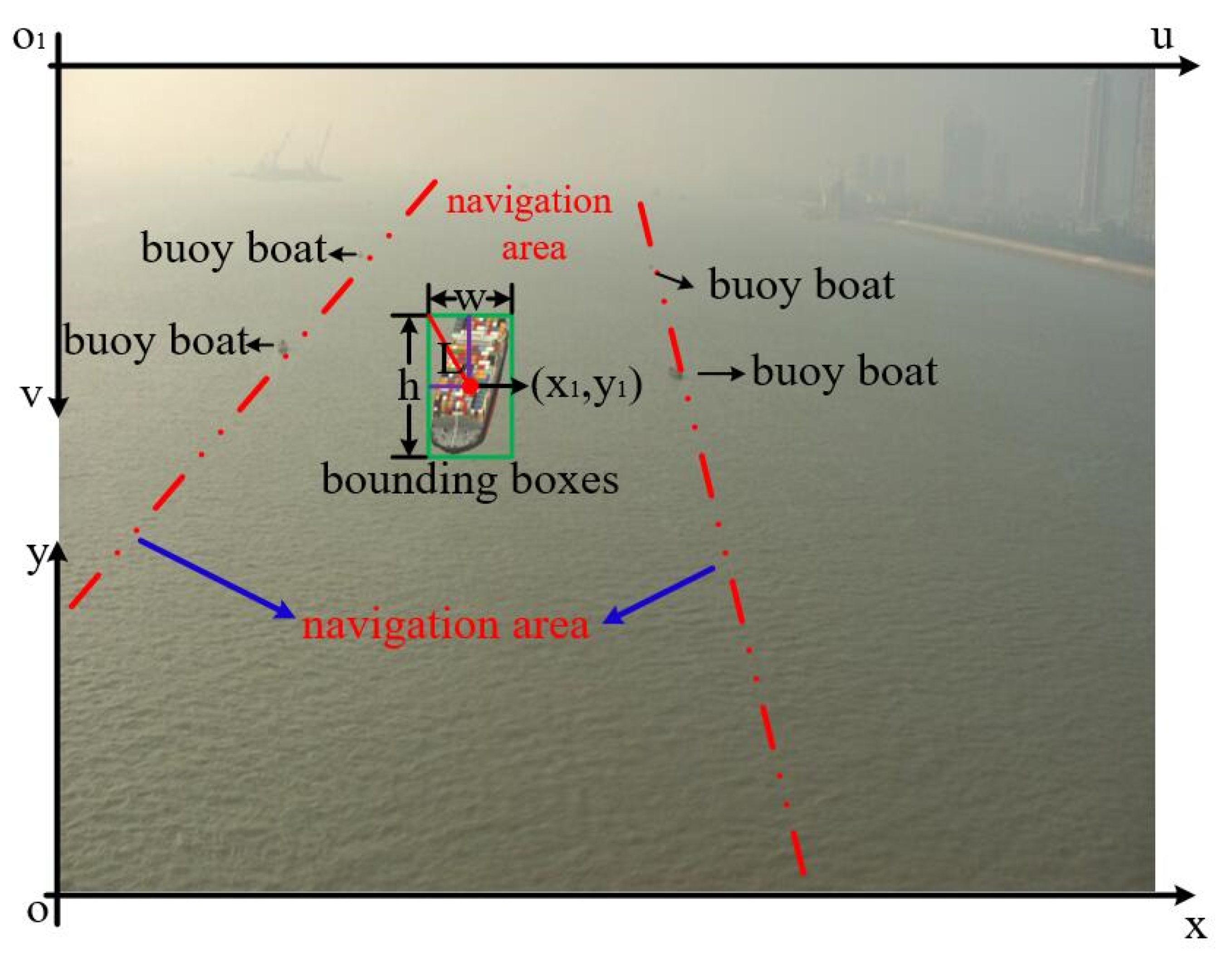
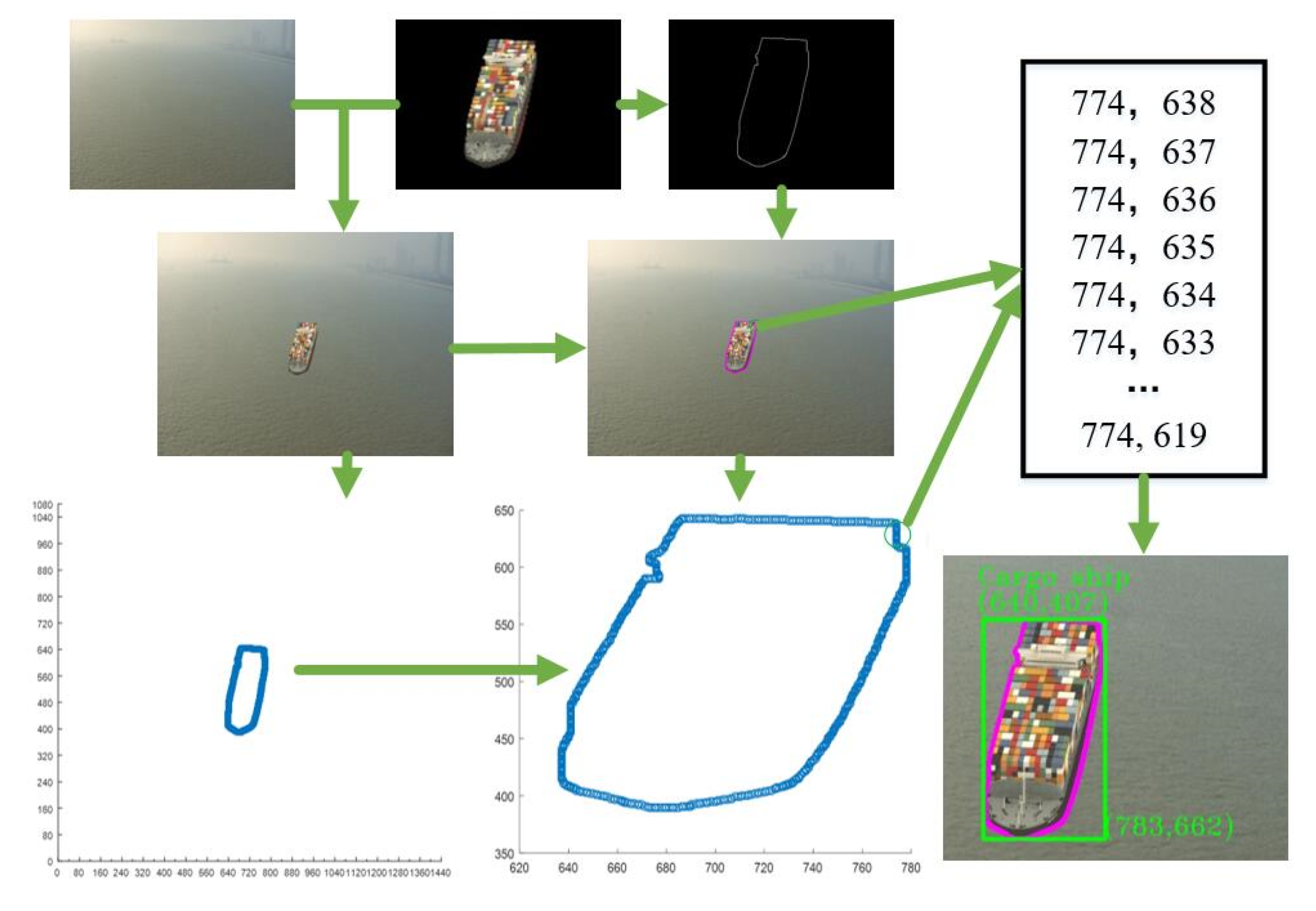
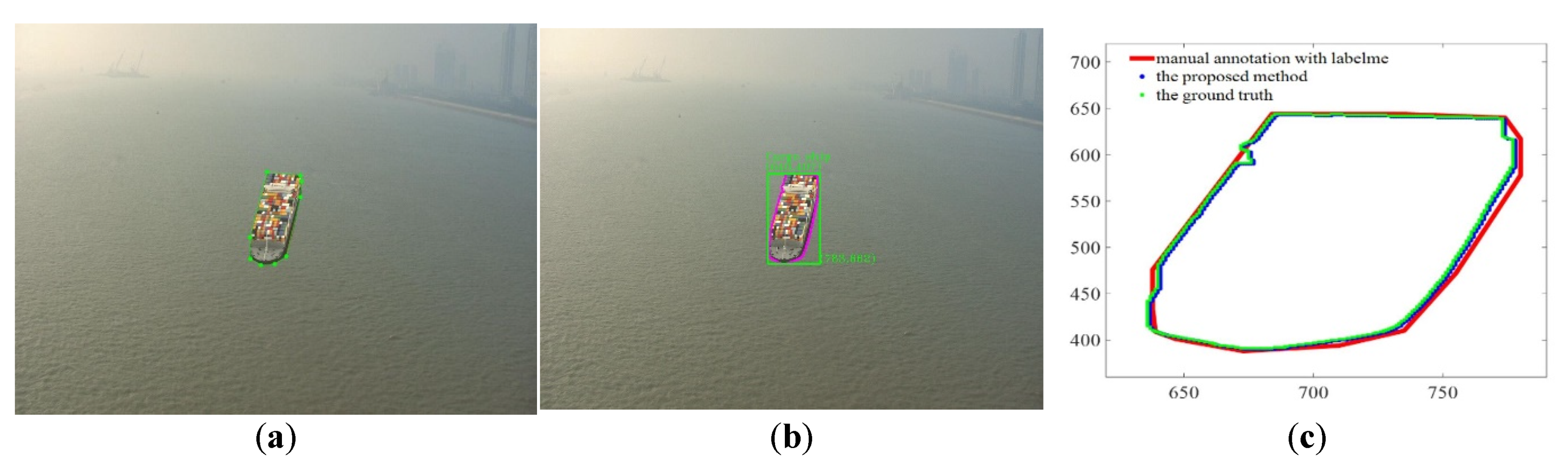
2.2. Automatic Annotation of Target Ship
2.3. Selecting the Typical CNN Algorithm for Training and Testing
3. Results
3.1. Experiment Platform and Parameter Settings
3.2. Generation and Automatic Annotating of SRS Images Data
3.3. Training and Detection with Mask RCNN and FCN
4. Discussion
4.1. Comparative Experiment 1: Comparing Our Annotation Method with the Existing Annotation Method
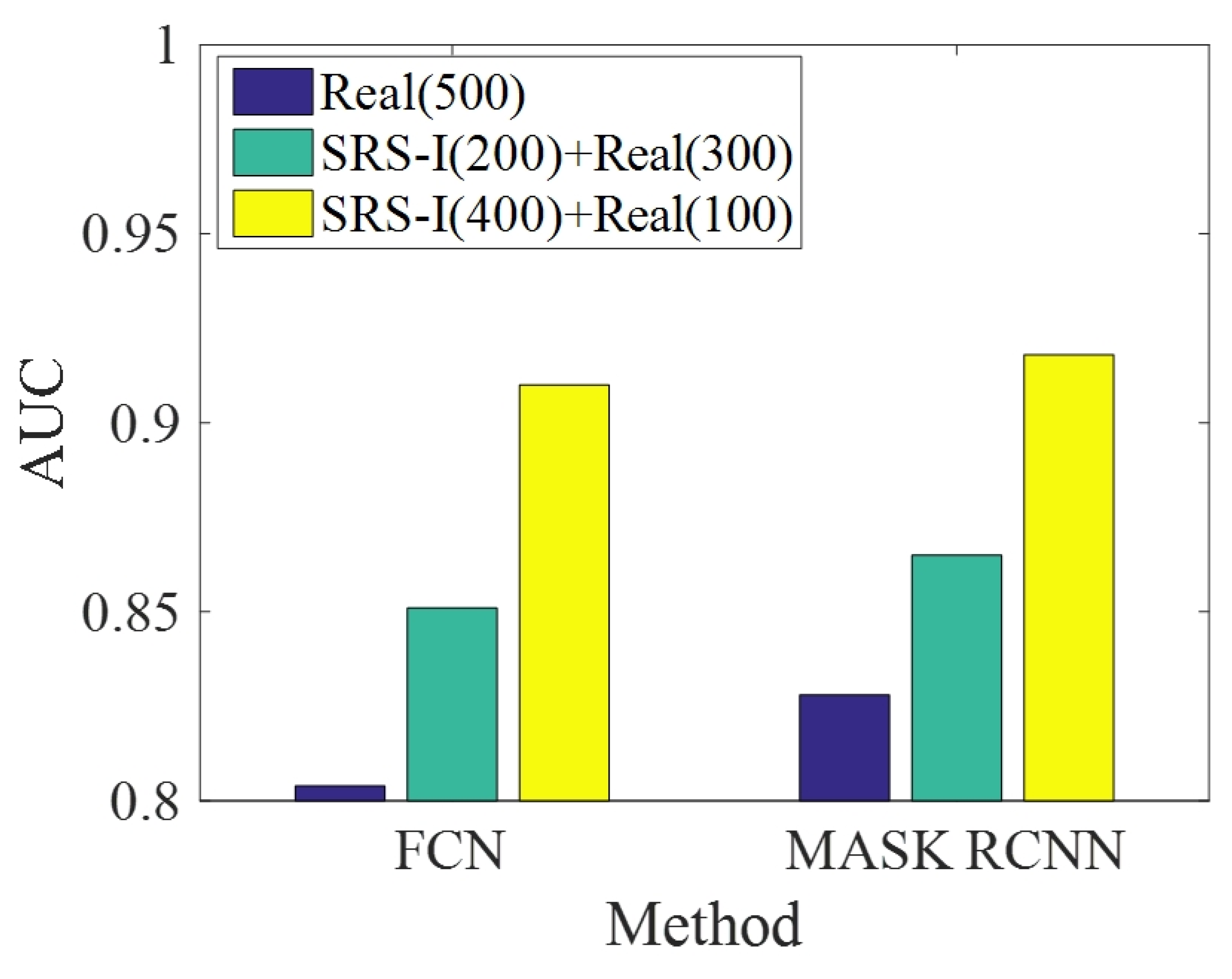
4.2. Comparative Experiment 2: Comparing the SRS Images with the Real Scene Ship Image
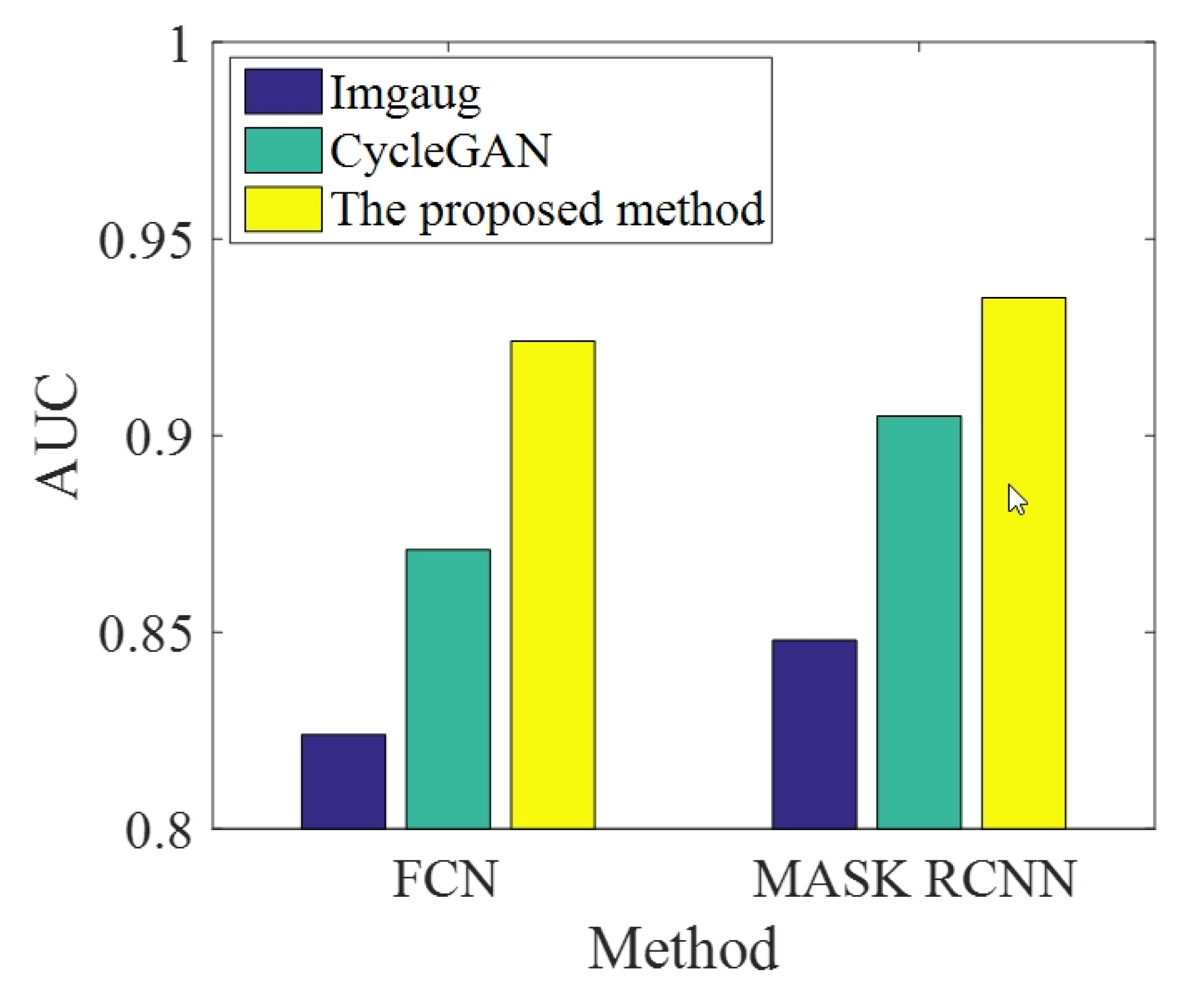
4.3. Comparative Experiment 3: Comparison with the Existing Data Augmentation Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ferdinand, P. Westward ho—The China dream and ‘one belt, one road’: Chinese foreign policy under Xi Jinping. Int. Aff. 2016, 92, 941–957. [Google Scholar] [CrossRef] [Green Version]
- Blanchard, J.-M.F.; Flint, C. The Geopolitics of China’s Maritime Silk Road Initiative. Geopolitics 2017, 22, 223–245. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 20–23 June 2014; pp. 580–587. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. Available online: https://arxiv.org/pdf/1605.06409.pdf (accessed on 25 March 2021).
- Ren, S.Q.; He, K.M.; Girshick, R. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. Available online: https://arxiv.org/pdf/1506.01497.pdf (accessed on 25 March 2021). [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ye, F.; Yang, J. A Deep Neural Network Model for Speaker Identification. Appl. Sci. 2021, 11, 3603. [Google Scholar] [CrossRef]
- Fleet, D.; Pajdla, T.; Schiele, B.; Tuytelaars, T. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. Available online: https://doi.org/10.1007/s11263-020-01316-z (accessed on 25 March 2021). [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R. Imagenet: A large-scale hierarchical image database. In Proceedings of the 22th IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Prasad, D.K.; Prasath, C.K.; Rajan, D. Challenges in video based object detection in maritime scenario using computer vision. arXiv 2016, arXiv:1608.01079. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. arXiv 2016, arXiv:1606.07536. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L.E.O. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D. Self-attention generative adversarial networks. In Proceedings of the 2019 International Conference on Machine Learning(PMLR), Ghent, Belgium, 3–6 July 2019; pp. 7354–7363. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 16–19 June 2019; pp. 4401–4410. [Google Scholar]
- Dewi, C.; Chen, R.C.; Liu, Y.T. Various Generative Adversarial Networks Model for Synthetic Prohibitory Sign Image Gen-eration. Appl. Sci. 2021, 11, 2913. [Google Scholar] [CrossRef]
- Alruwaili, M.; Siddiqi, M.H.; Javed, M.A. A robust clustering algorithm using spatial fuzzy C-means for brain MR images. Egypt. Inform. J. 2020, 21, 51–66. [Google Scholar] [CrossRef]
- Versaci, M.; Morabito, F.C. Image edge detection: A new approach based on fuzzy entropy and fuzzy divergence. Int. J. Fuzzy Syst. 2021, 23, 1–19. [Google Scholar] [CrossRef]
- Jung, A. Imgaug: Image augmentation for machine learning experiments. Accessed 2017, 3, 977–997. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training and Testing Method | Type of Data for Training (Number) | Type of Data for Testing (Number) | Accuracy (%) | TPR (%) | FPR (%) |
|---|---|---|---|---|---|
| FCN | Real(500) | Real(500) | 84.2 | 86.4 | 19.1 |
| Real(300) + SRS-I(200) | 88.5 | 90.8 | 11.8 | ||
| Real(100) + SRS-I(400) | 91.3 | 92.8 | 9.2 | ||
| Mask RCNN | Real(500) | Real(500) | 86.3 | 88.5 | 17.6 |
| Real(300) + SRS-I(200) | 90.6 | 93.2 | 10.6 | ||
| Real(100) + SRS-I(400) | 92.9 | 94.5 | 7.6 |
| Training and Testing Method | Type of Data for Training (Number) | Type of Data for Testing (Number) | Accuracy (%) | TPR (%) | FPR (%) |
|---|---|---|---|---|---|
| FCN | Imgaug [41] | Real(500) | 85.7 | 88.9 | 17.1 |
| CycleGAN [30] | 90.9 | 91.5 | 11.2 | ||
| Our method | 93.2 | 94.4 | 7.1 | ||
| Mask RCNN | Imgaug [41] | Real(500) | 87.3 | 89.5 | 14.6 |
| CycleGAN [30] | 91.7 | 93.1 | 10.5 | ||
| Our method | 94.6 | 95.7 | 5.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, J.; Hu, Z.; Peng, C.; Wang, Z. Generation and Annotation of Simulation-Real Ship Images for Convolutional Neural Networks Training and Testing. Appl. Sci. 2021, 11, 5931. https://doi.org/10.3390/app11135931
You J, Hu Z, Peng C, Wang Z. Generation and Annotation of Simulation-Real Ship Images for Convolutional Neural Networks Training and Testing. Applied Sciences. 2021; 11(13):5931. https://doi.org/10.3390/app11135931
Chicago/Turabian StyleYou, Ji’an, Zhaozheng Hu, Chao Peng, and Zhiqiang Wang. 2021. "Generation and Annotation of Simulation-Real Ship Images for Convolutional Neural Networks Training and Testing" Applied Sciences 11, no. 13: 5931. https://doi.org/10.3390/app11135931