1. Introduction
Traditional supervised learning methods aim to estimate a mapping function from input features to output labels. To train such a function, a set of samples (named the training set) is commonly obtainable, and an expert annotates each instance to the absolute ground truth (gold standard). Nonetheless, in many real-world scenarios, such a ground truth is not available because the process to acquire it is expensive, infeasible, or the given label corresponds to a subjective assessment [
1]. As an illustrative example, let us consider a cancer detection task based on medical images. The correct label for a specific region, e.g., the presence of cancer or not in that region, must be obtained from a biopsy, which is a risky and expensive procedure [
2]. As an alternative, the labeling process can be assigned to multiple heterogeneous annotators, who label part of the whole dataset providing their subjective version of the unknown ground truth [
3]. Recently, one of the most common ways to obtain labels from multiple experts is through crowdsourcing platforms (
www.mturk.com;
labelme2.csail.mit.edu/, (accessed on 19 April 2021)). The attractiveness of crowdsourcing lies in getting suitable quality labels at a low cost [
4,
5]. In this sense, in a multi-labeler scenario, each instance is paired to a set of labels given by multiple annotators with different and unknown expertise [
6], being difficult to apply traditional supervised learning algorithms [
7].
Accordingly, the area of learning from multiple annotators has been introduced to face supervised learning settings in the presence of multiple annotators from both frequentist (regularized) and Bayesian perspectives. In turn, the approaches mainly fit the labels from multiple labelers or adjust the supervised learning schema [
8]. The well-known “label aggregation” or “ground truth inference” calculates a single hard label per instance to feed a supervised learning algorithm [
9]. The most straightforward strategy is majority voting (MV), which uses the most voted label as ground truth estimation (or the average in regression settings). This method has been used in several multi-labelers problems because of its simplicity [
10]. Still, it assumes homogeneity in the annotator’s performance that is hardly feasible for real-world scenarios, e.g., experts vs. spammers. Conversely, more elaborated models have been considered to improve the actual label’s estimation through the expectation maximization (EM) framework or by facing the imbalanced labeling issue [
11]. Other strategies jointly estimate the annotators’ parameters (related to their behavior) and train a given supervised learning algorithm. This kind of approach has shown better results than the ones related to label aggregation. Thereby, the features used to train the learning algorithm provide valuable information to calculate the hidden ground truth [
9]. Concerning this, the fundamental work presented in [
2] introduces an EM-based framework to jointly estimate the annotators’ sensitivity and specificity while training a logistic regression classifier. This approach has inspired several models to deal with multi-labelers tasks, such as: regression [
12,
13], binary classification [
14,
15,
16], multi-class classification [
1,
17], and sequence labeling [
18]. Moreover, some works have extended such ideas for deep learning methods, where a new layer is included to codify the information from multiple labelers [
19,
20].
Overall, two main issues arise when building a multiple annotators method: (i) the labelers’ behavior is supposed to be homogeneous across the input feature space, and (ii) the independence constraint is assumed over the experts’ outputs. The former challenge is viewed in approaches where the annotators’ parameters (related to their performance) are assumed homogeneous across the input space. Indeed, fixed-point [
16,
20] and stochastic modeling [
9] have been proposed in the literature. On this point, it is worth mentioning that experts make decisions based not only on his or her expertise but also on the features observed from raw data [
2]. The latter issue (independence constraint for the annotators’ responses) arises to reduce the complexity of the model [
21], and it is based on the fact that each labeler performs the annotations individually [
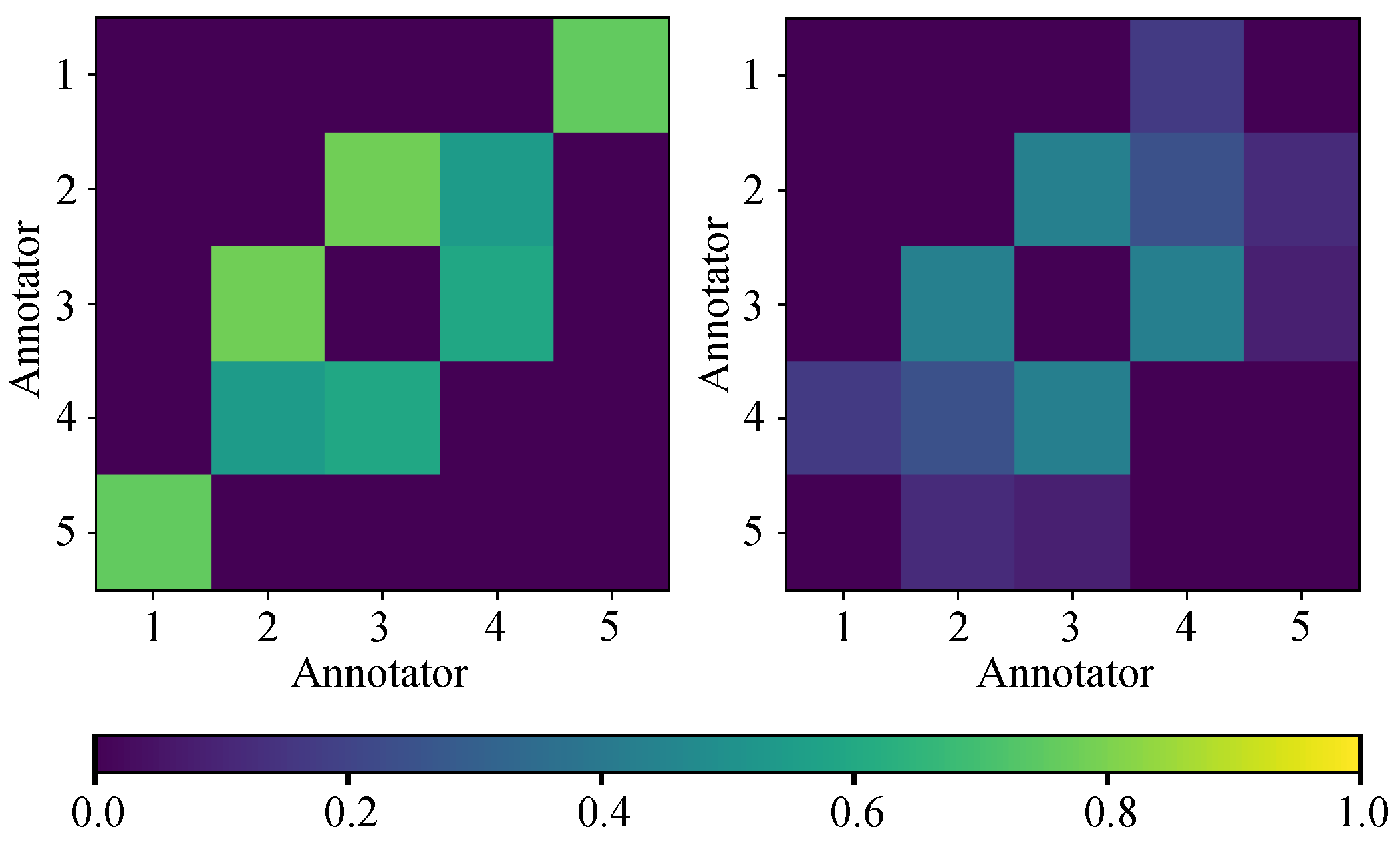
22]. Nevertheless, there may exist correlations among the labelers, especially if the annotations are captured from human experts [
23]. Namely, the independence assumption is hardly plausible because knowledge is a social construction; people’s decisions will be correlated because they share information or belong to a particular school of thought [
24].
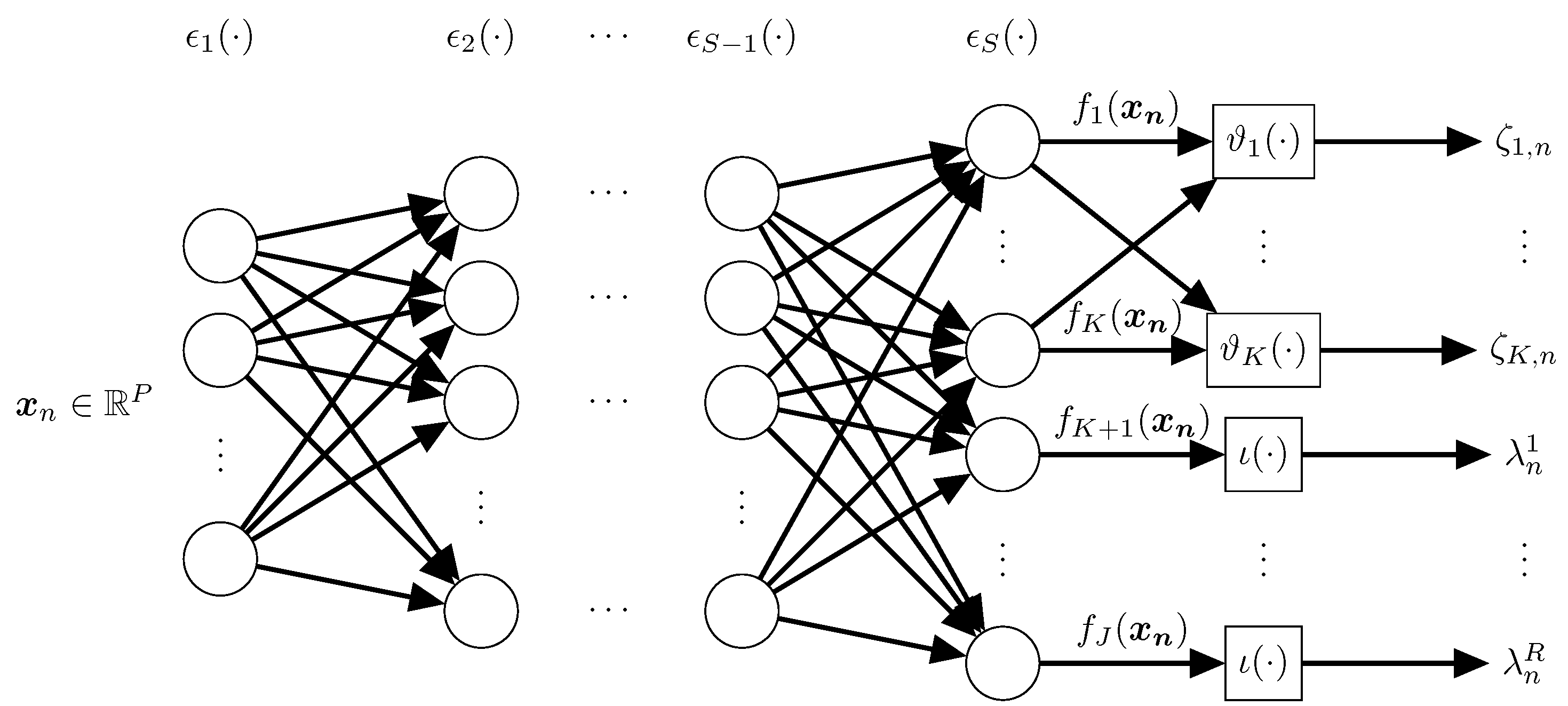
This paper introduces a regularized chained deep neural network for multiple annotators, termed RCDNN, to jointly estimate the ground truth label and the annotators’ performance. RCDNN is inspired in the chained Gaussian processes model (CGP) [
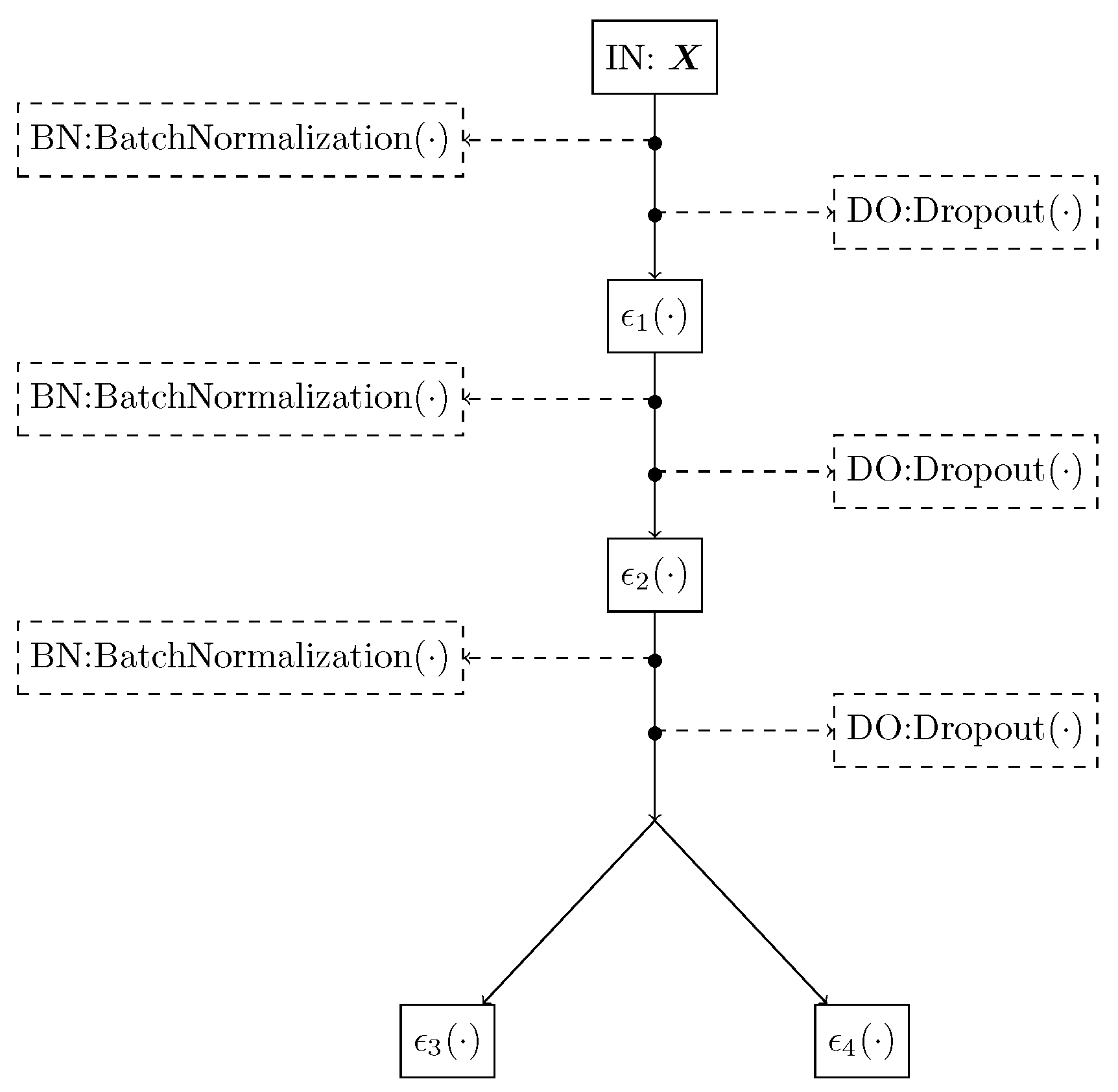
25], where each parameter in a given likelihood is coded with multiple independent Gaussian processes–(GP) priors (one GP prior per parameter). Unlike CGP, our method considers that the last layer models the parameters of an arbitrary likelihood. Thus, in a multi-labeler scenario, the annotators’ parameters are coded as a function of the input space. Moreover, since each output in a deep model is computed as a linear combination of previous layers’ outputs, our RCDNN can code interdependencies among the annotators. Besides, l1, l2, and Monte-Carlo Dropout-based regularizers are coupled within our method to deal with the over-fitting issue in deep learning models. Achieved results, using both simulated and real-world data, show how our method can deal with classification problems from multi-labelers data.
The agenda is as follows:
Section 2 summarizes the related work.
Section 3 describes the methods.
Section 4 and
Section 5 present the experiments and discuss the results. Finally,
Section 6 outlines the conclusions and future work.
2. Related Work
As analyzed by the authors in [
26], there exists an increasing interest in developing models to deal with multi-labeler data. However, it is possible to identify some problems that are not entirely solved: (i) to code the relationship between the labelers’ performance and the input space, and (ii) to identify annotators’ interdependencies.
In [
23], the authors introduced a binary classification algorithm for multiple labelers, where the input data are represented by Gaussian mixture model (GMM)-based clusters. This approach assumes that each annotator exhibits a particular performance concerning a given cluster. Nevertheless, such a model does not consider the information from multiple annotators as an input for the GMM, leading to variations in the labelers’ parameters. In [
27], the authors propose a binary classification algorithm employing two distributions to compute the annotators’ achievement as a function of the input space, namely, Gaussian and Bernoulli. The parameters of such distributions are computed via logistic regression optimization. Still, a linear dependence is assumed between the labeler’s expertise and the input space, which may not be appropriate in the presence of non-linear data structures. For example, if we take into account online annotators assessing documents, they may show different labeling accuracies depending on if they are more familiar with some specific topic [
28].
On the other hand, the work in [
29] uses a multivariate Gaussian distribution to model the annotations, and the experts’ interdependencies are coded in the covariance matrix. Besides, in [
16], the authors introduce a binary classification method based on a weighted combination of classifiers. The weights are computed using a centered kernel alignment (CKA)-based loss to measure the similarities among the input features and the labels from multiple annotators. Similarly, the authors in [
1] proposed a localized kernel alignment-based method, termed LKAAR, to build a classification approach with multiple annotators. However, unlike the work in [
16], LKAAR modifies the CKA-based loss to measure the similarities among each input instance and its corresponding set of labels. Thereby, LKAAR measures the annotators’ performance as a function of the input space while considering interdependencies among the experts.
Our proposal follows the line of the works in [
19,
20] in the sense that RCDNN uses a deep-based approach to build a supervised learning model in the context of multiple annotators. However, while such approaches code the annotators’ parameters as fixed points, we model them as functions to consider dependencies between the input features and the labelers’ behavior. RCDNN is also similar to the LKAAR model introduced in [
1]. Both approaches model the annotators’ performance as a function of the input instances and consider interdependencies among the labelers. Nonetheless, unlike LKAAR, where it is necessary to use as many classifiers as annotators, our approach only needs to train a single classifier from a deep learning representation, which is advantageous for a large number of labelers. As an illustrative summary,
Table 1 shows the key insights of our RCDNN and relevant state-of-the-art works.
6. Conclusions
This paper introduces a novel regularized chained deep neural network classifier, termed RCDNN, to deal with multiple annotator scenarios. Our method is built based on the ideas of the chained Gaussian processes [
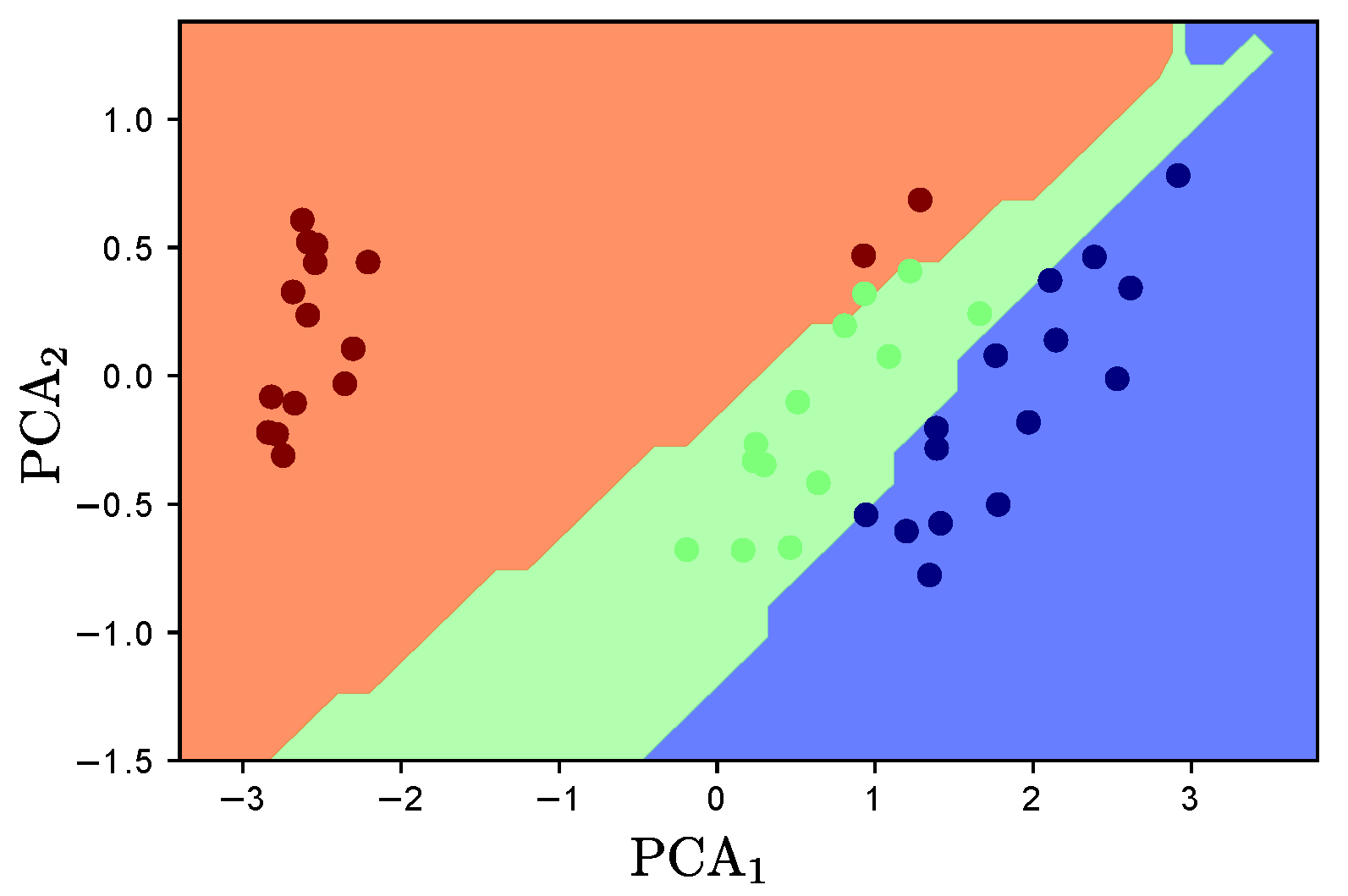
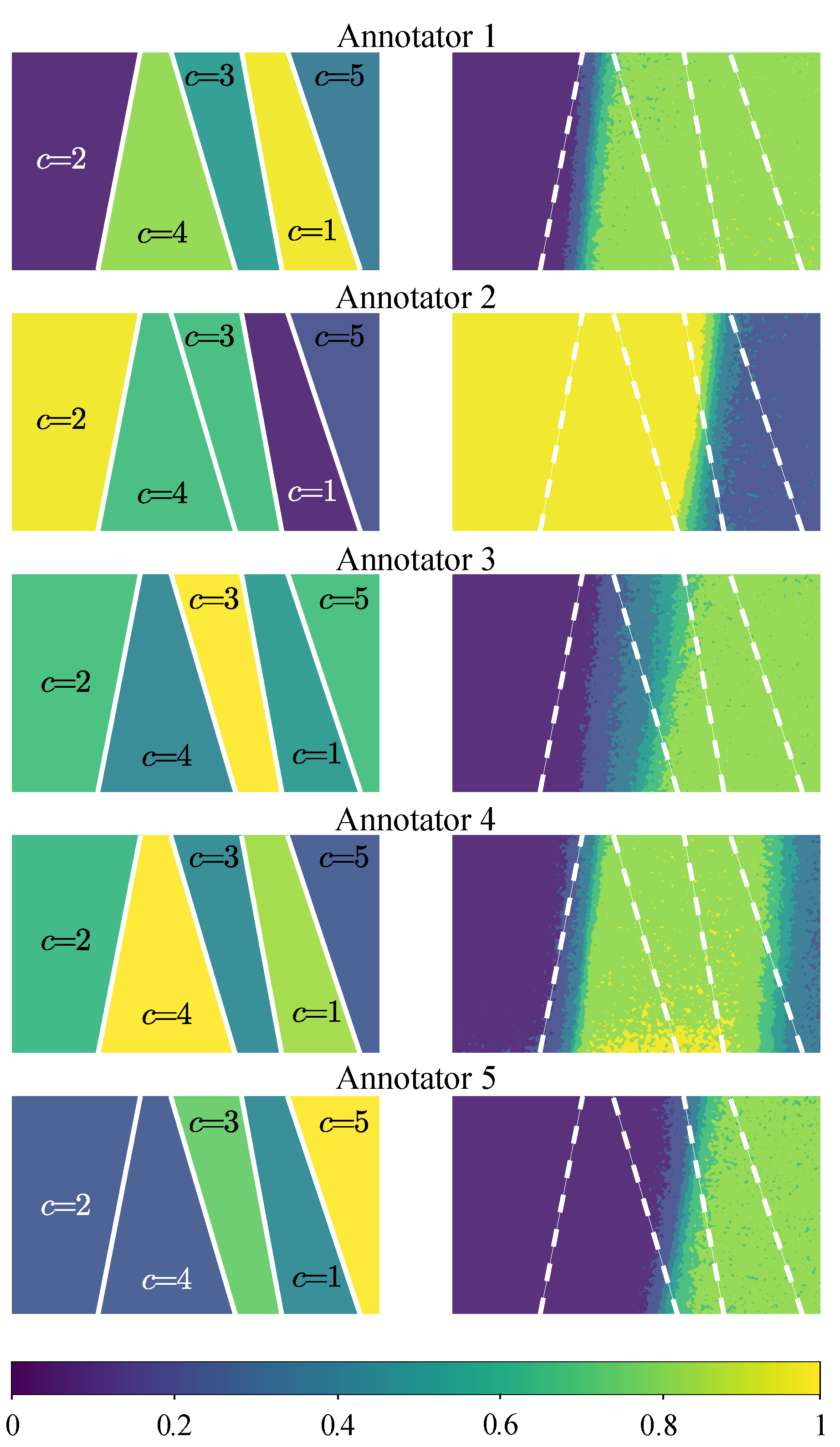
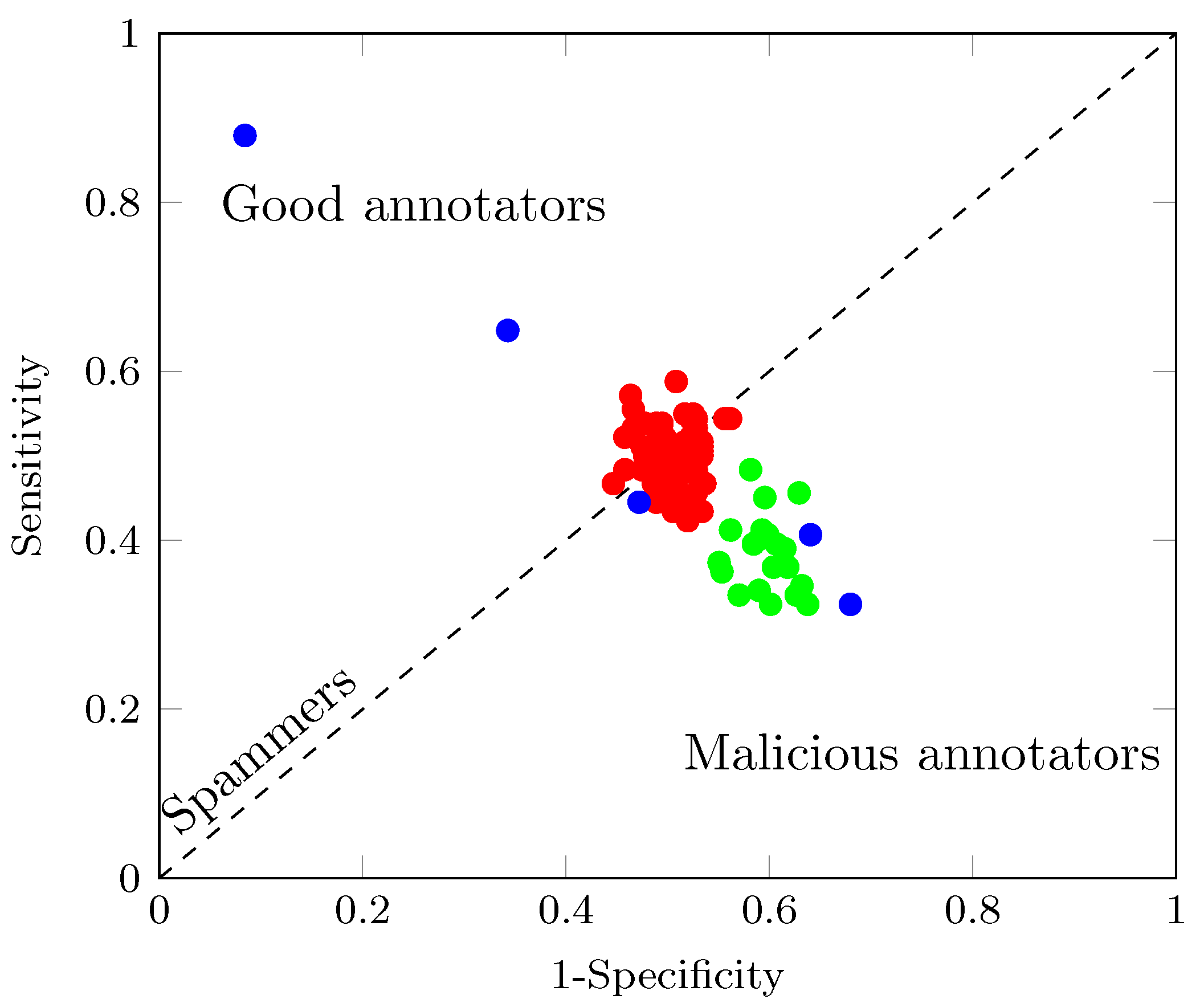
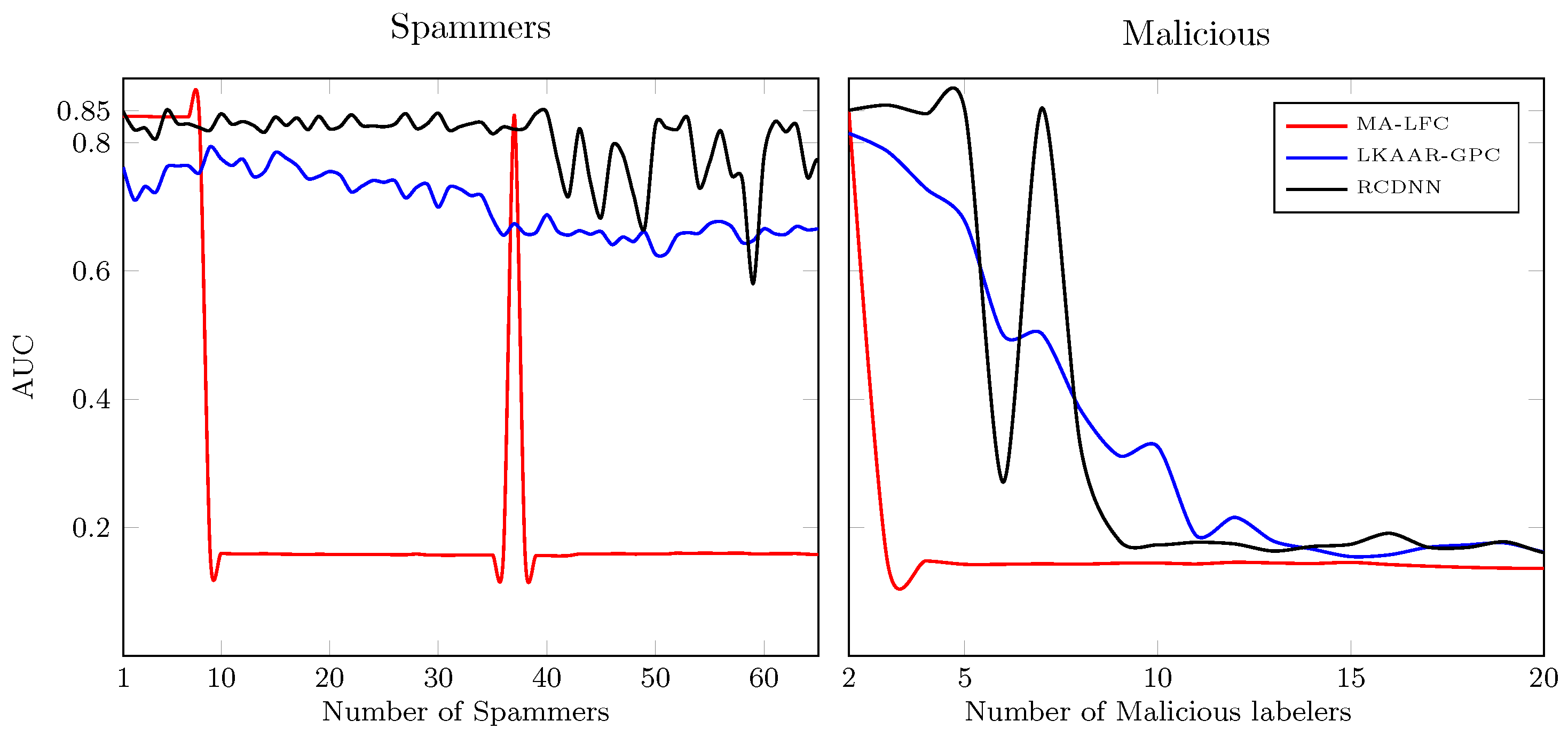
25], where each parameter in a multi-labeler likelihood is modeled by using the outputs of a deep neural network. In such a way, RCDNN codes the annotators’ expertise as a function of the input data and the dependencies among the labelers from the last hidden layer’s weights. Besides, l1, l2, and Monte-Carlo Dropout regularization strategies are coupled within our RCDNN architecture and predictor to contract the over-fitting challenge of deep models. The proposal is tested using different scenarios concerning the provided annotations: synthetic, semi-synthetic, and real-world experts. According to the results, RCDNN achieves robust predictive properties for the studied datasets even in the presence of Spammers and Malicious labelers, outperforming state-of-the-art methods while providing an estimation of each labeler’s reliability and the dependencies among annotators.
As future work, extending RCDNN for regression tasks is an exciting research line, i.e., based on the model introduced in [
12]. Next, the authors plan to use other deep structures, i.e., Convolutional and Recurrent layers and different activation functions, to apply our approach in more complex tasks such as computer vision or natural language processing. Finally, as RCDNN was tested on the Western dataset, which comprises building a system to diagnose an engine’s status, the authors plan to focus on that topic to build an automatic system to identify internal combustion engines’ conditions from multiple annotators.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}