1. Introduction
The world’s population living in urban areas will increase by 13% by 2050 [
1]. On the other hand, with the current agricultural production method, the capacity of the Earth is already exceeded [
2]. Therefore, improving agricultural production and feeding the world without exceeding natural sources such as water remains the main problem in agriculture.
Agricultural production depends on water. It is also the largest consumer of water as it consumes on average 70% of all freshwater [
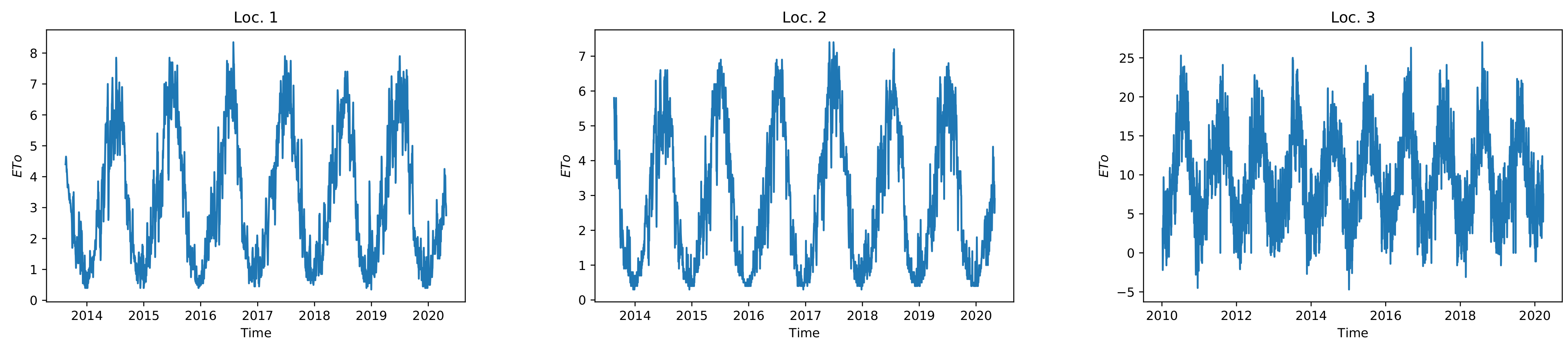
3]. Therefore, it is essential to optimize irrigation and make irrigation systems more efficient, especially in arid regions. Many factors need to be considered when scheduling irrigation. The amount of water available in the soil and reference evapotranspiration (ETo) are two critical factors [
4,
5]. Evapotranspiration is the amount of water that evaporates from the Earth and plant surface. Solar radiation, wind speed, temperature, and relative humidity all influence daily ET, and this effect is highly nonlinear. The Penman–Monteith equation recommended by the Food and Agriculture Organization (FAO) is the most commonly used equation for calculating ET [
6].
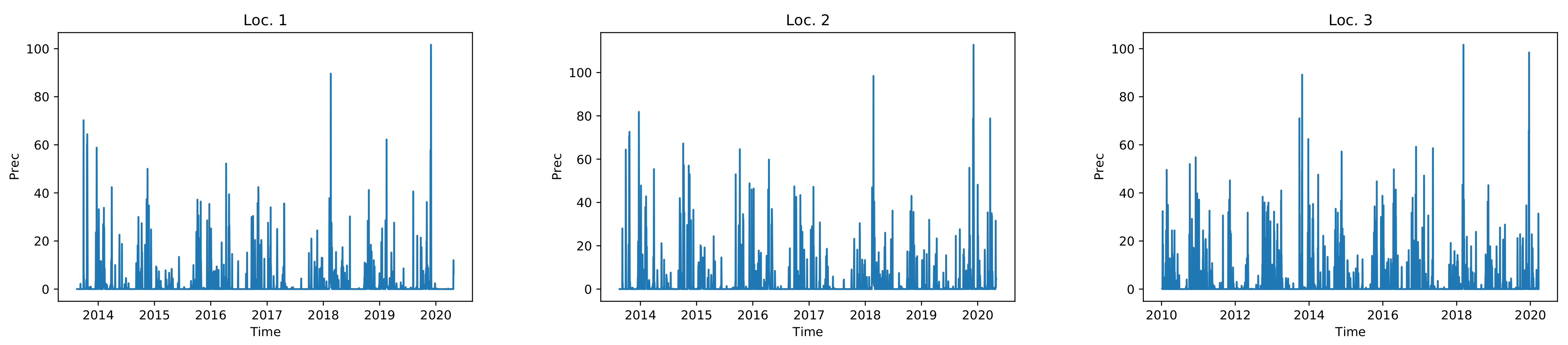
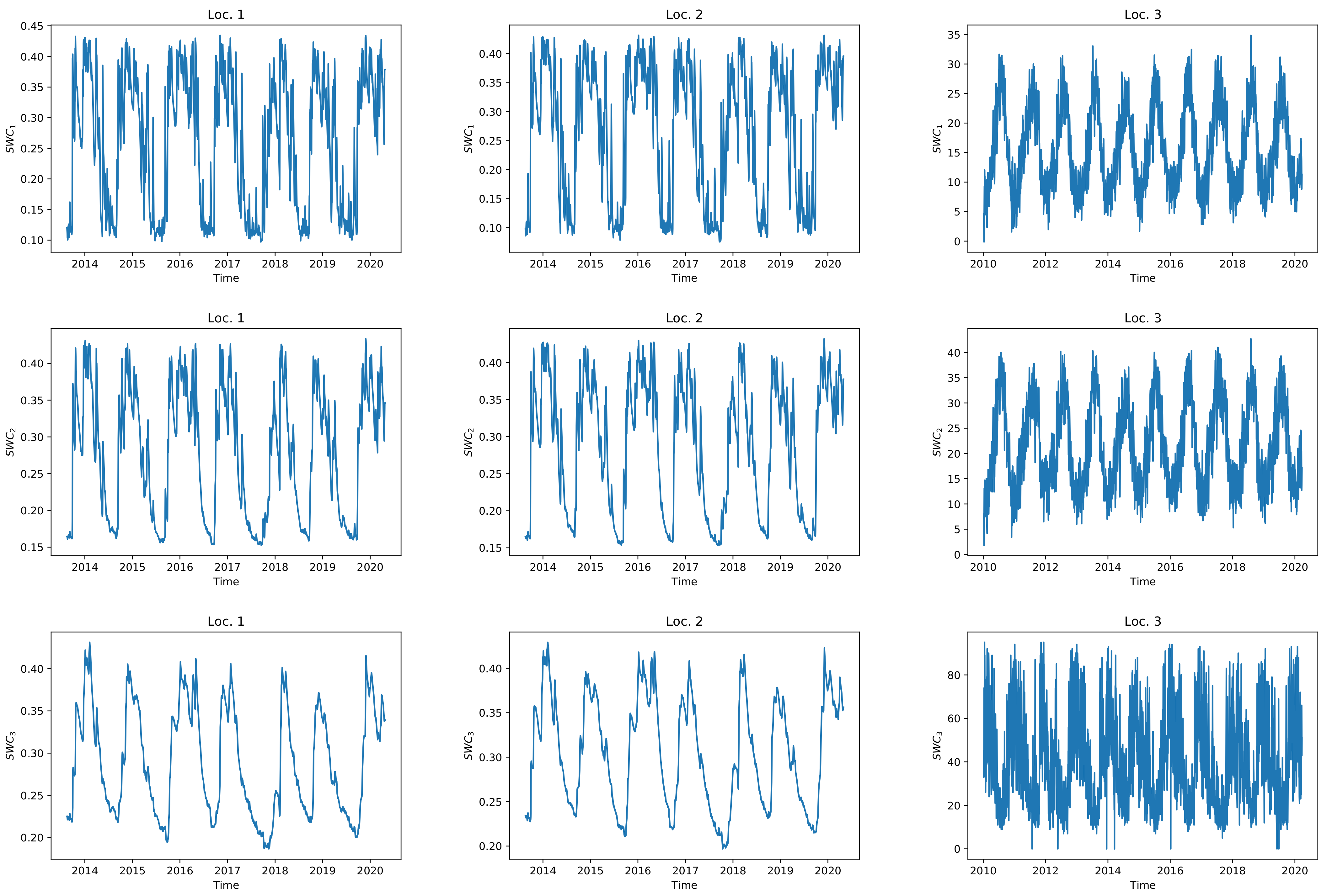
Soil Water Content (SWC) is the volume of water per unit volume of soil. It can be measured by weighing a soil sample, drying the sample to remove the water, and then weighing the dried soil or by remote sensing methods. Measuring SWC is important for studying the statistics of available water and scheduling irrigation [
5]. ET and SWC can be measured by remote sensing methods. Jimenez et al. [
7] lists some advantages and disadvantages of some remote sensing methods, for example, Clulow et al. [
8] used Eddy Covariance (EC) Systems in South Africa to determine evapotranspiration in a forested area. The system EC uses sensors (such as an anemometer, Infrared Sensor, quality air sensor, precision flowmeter, or vapor flow meter) to collect data from the field and calculate evapotranspiration. The study points out some disadvantages of using this system in remote areas, such as the relatively high power requirement, which requires careful and frequent attention, and the verification, correction, and analysis of the data for complete records. However, the machine learning algorithm is able to extract the feature from the raw data and calculate ET and SWC without any further effort. In recent years, many studies have been conducted on the use of machine learning methods for irrigation scheduling. Support vector machine, single-layer neural network, and deep neural network are the most commonly used methods for simulating soil moisture, and ET [
7,
9,
10,
11,
12,
13]. Achieng [
5] used machine learning techniques including three support vector regressions (Radial Basis Function (RBF), linear and polynomial kernel SVM), a single-layer Artificial Neural Network (ANN), and eight multilayer Deep Neural Networks (DNN) to simulate soil water content. The results showed that the RBF-based SVR outperformed the other models to simulate soil water content. Tseng et al. [
14] used CNN to predict soil moisture status from images. The experimental result on the test images showed that CNN performed best with a normalized mean absolute error of 3.4% compared to SVM, RF, and two-layer Neural Networks. Song et al. [
15] used a Macroscopic Cellular Automata (MCA) model by combining the deep belief network (DBN) to predict the SWC. Compared to the multilayer perceptron, the DBN-MCA model resulted in an 18% reduction in mean squared error. Adamala [
16] developed a generalized wavelet neural network (WNN)-based model to estimate the reference evapotranspiration. The proposed models were compared with ANN, linear regression (LR), wavelet regression (WR), and HG methods. The WNN and ANN models performed better compared to the LR, WR, and HG methods. Saggi and Jain [
17] used a Deep Learning-Multilayer Perceptron (MLP) to determine the daily ETo for Hoshiarpur and Patiala Districts from Punjab. The performance of the MLP was compared with machine learning algorithms such as Random Forest (RF), Generalized Linear Models (GLM), and Gradient Boosting Machine (GBM). The MLP model had the best performance, with the mean square error ranging from 0.0369 to 0.1215. De Oliveira e Lucas et al. [
18] used three CNNs with different structures to make daily predictions for ETo. Comparisons were made between the CNN, the seasonal ARIMA (SARIMA), and Seasonal Naive (SNAIVE). The CNN model performed better in terms of variance, accuracy, and computational cost.
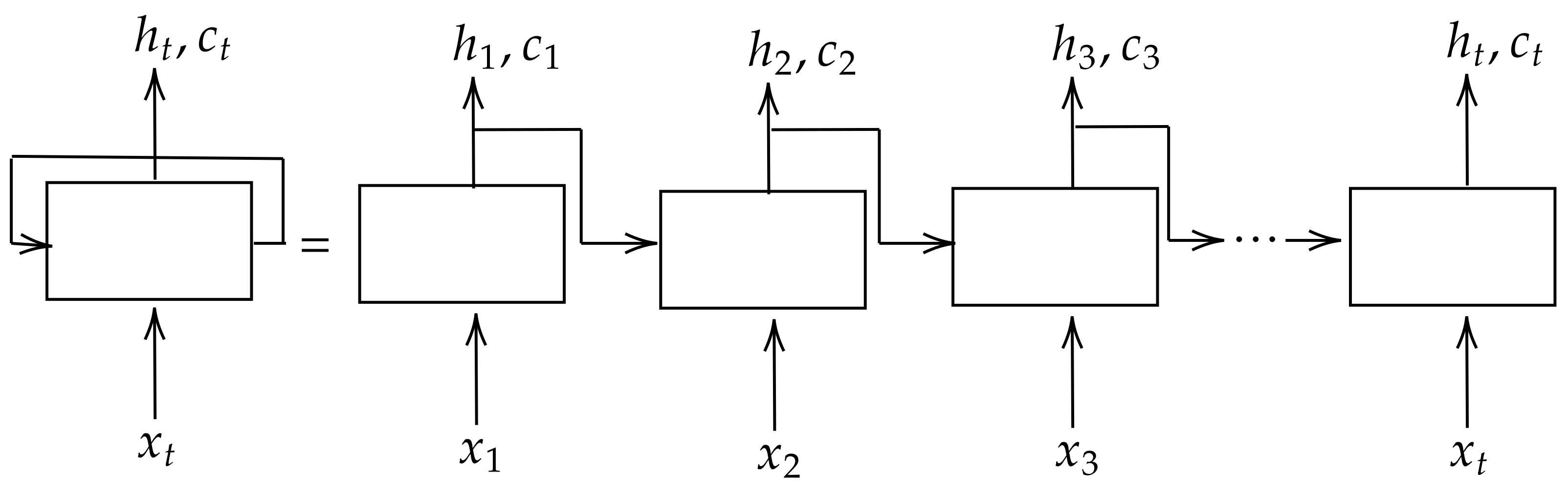
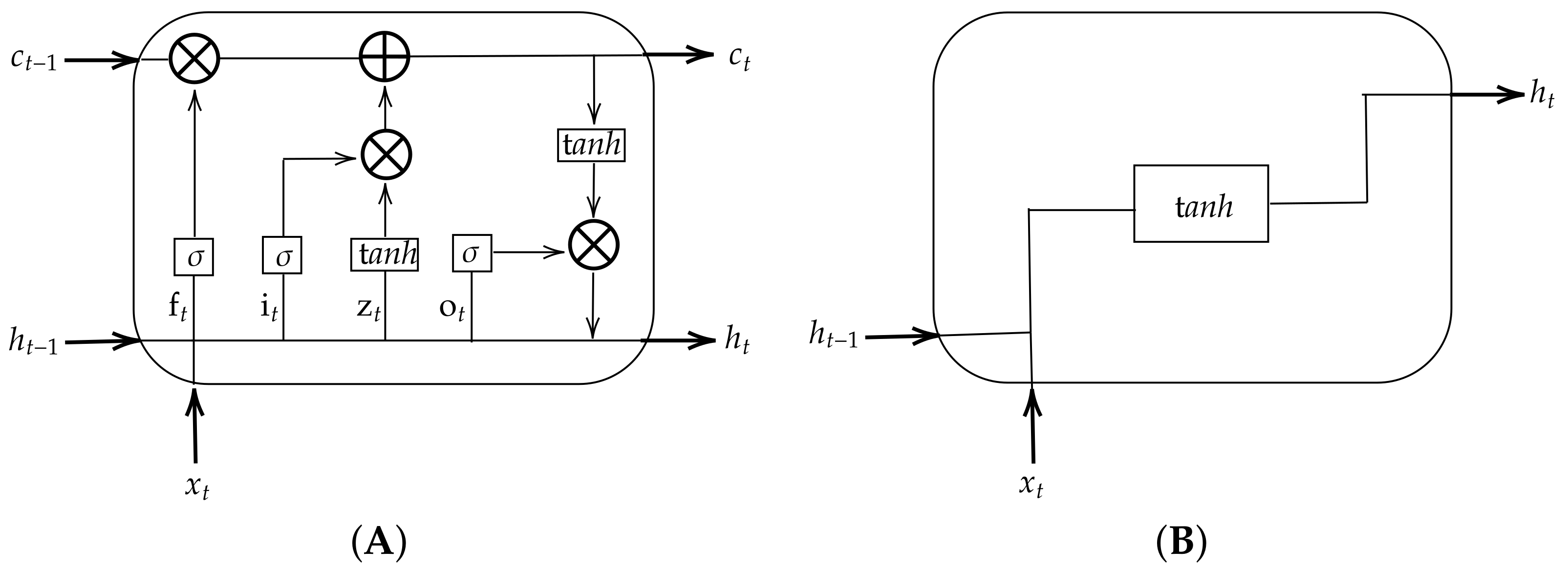
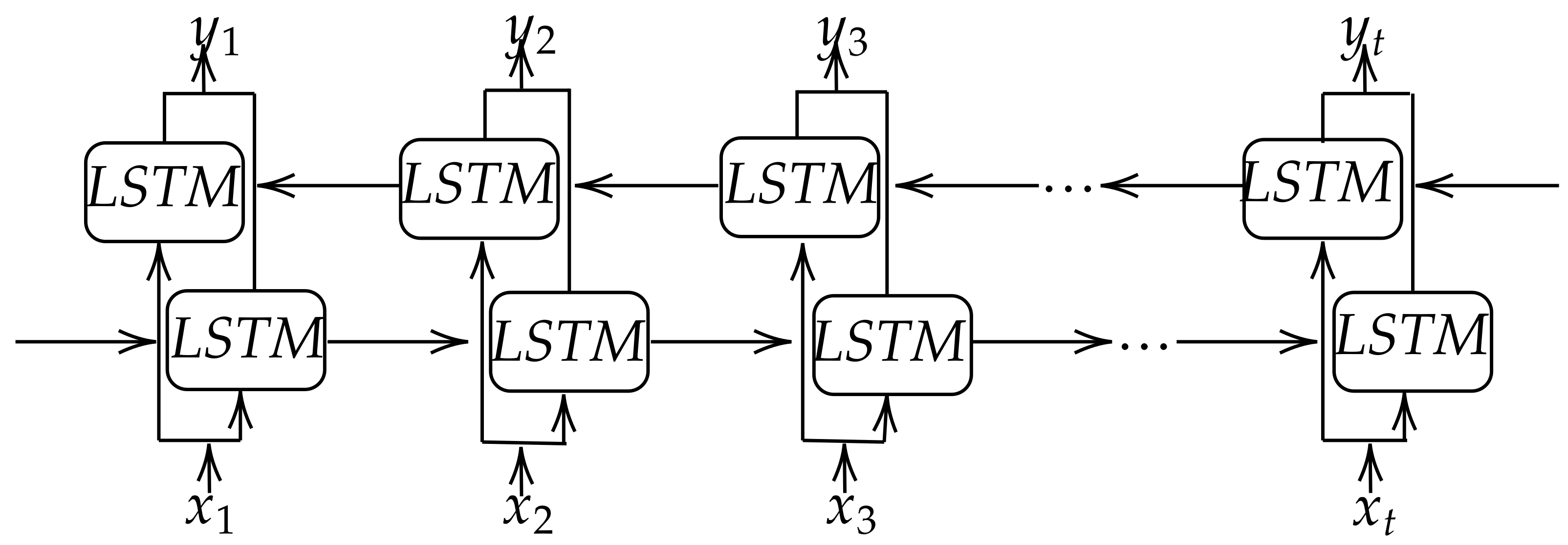
However, traditional machine learning cannot store and learn from the past observations of a time series. Under deep learning, LSTM models are designed to model time series data. Adeyemi et al. [
11] developed a Neural Network approach to model temporal soil moisture. In the model evaluation, a value of
above 0.94 was obtained at all test sites. Zhang et al. [
19] used an LSTM model to predict agricultural water table elevation. They used 14 years of time-series data such as water diversion, precipitation, reference evapotranspiration, temperature, and water table depth. The proposed model achieved higher values of
than the model Feed-Forward Neural Network (FFNN) in predicting water table depth. As indicated earlier, measuring reference evapotranspiration volume and soil water volume is time and labor-intensive.
In this paper, a Long Short-Term Memory (LSTM) was developed to predict these two critical parameters. The model forecasts one day- ahead ET and SWC using eight days of historical data. The various evaluation metrics such as Mean Square Error (MSE), Root Mean Square Error (RMSE), Mean Absolute Error (MAE), Mean Bias Error (MBE), and
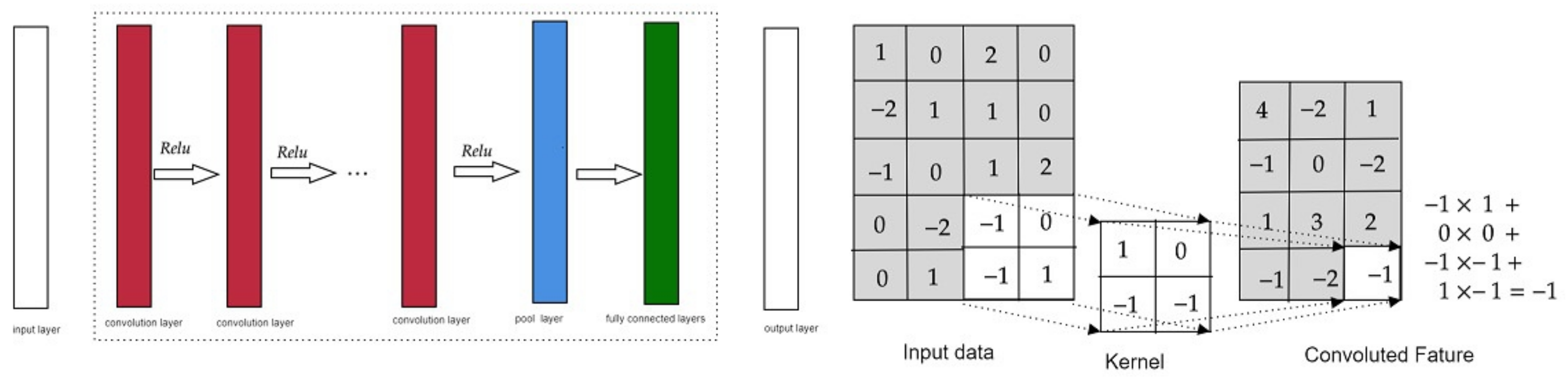
were used to demonstrate the effectiveness of the models. Each metric has its advantages and disadvantages, and as the results of this paper will show, using only one metric can lead to misleading results. The Convolutional Neural Network (CNN) is capable of extracting features from raw data [
20]. A CNN model is superimposed on the LSTM model to investigate the performance of CNN- LSTM models compared to LSTM. The performance of the model is also compared with CNN and traditional machine learning algorithms such as Support Vector Regression (SVR) and Random Forest [
21,
22]. Finally, the impact of the loss function on the training of the model is investigated. The most commonly used loss functions for regression problems are selected, including MSE, RMSE, MAE, and the Huber function. The Huber function is basically MAE, which becomes MSE when the error is small. Unlike MAE, the Huber function is differentiable at 0 and is less sensitive to outliers in the data than MSE [
23]. Each of these functions yields a different error for the same prediction and affects the performance of the model on the test set.
3. Results and Discussion
The experimental environment configuration consists of an Intel Core i5-4200H CPU, an NVIDIA GEFORCE GTX 950M graphics card, and 6.144 GB RAM. The models were implemented using the Tensorflow framework and the Keras library [
42,
43].
The dataset was divided into training, validation, and test set (70%, 20%, and 10%, respectively). The model predicted SWC and ETo for one day ahead, considering eight days of historical data, including minimum temperature (
), maximum temperature (
), average humidity (
), average wind speed (
), and solar radiation (
), daily ETo and SWC. Mean square error and Adam optimization method [
44] were used for the loss function and optimization method.
Various machine learning algorithms have certain values that should be set before starting the learning process. These values are called hyperparameters and are used to configure the training process. The validation set is used to set the hyperparameters. The hyperparameters of the proposed model are learning rate, batch size, dropout size, number of layers in the model, and number of nodes per layer. The number of hidden layers and the number of nodes per layer were selected manually, and then Bayesian optimization was used to set the remaining hyperparameters. Unlike neural networks, LSTM does not require a deep network to obtain accurate results [
20]. Changing the number of nodes per layer has been shown to have a greater impact on results than changing the number of layers [
20]. In this work, the number of LSTM layers stayed between 2 and 4 for BLSTM less than 3 and kept the number of nodes per layer below 513. Finally, the network architectures were tested with two, three, and four LSTM layers, with one and two BLSTM layers, and 64, 128, 256, and 512 nodes per layer. The MSE was calculated for the validation dataset with all combinations of the number of layers and the number of nodes, and the results for the different sites are shown in
Table 3. Increasing the number of LSTM layers to four and the number of BLSTM layers to two increased the MSE on the validation dataset, showing the overfitting of the models. Keeping the LSTM layers of two and three for Loc. 1 and Loc. 2 and increasing the number of LSTM nodes per layer, the network accuracy on the validation dataset first increases and then decreases, and the best network accuracy is achieved with 256 nodes. The best accuracy for Loc. 3 was achieved with a single-layer BLSTM with 512 nodes. In the end, the mean error for each architecture was calculated on three datasets, and the single-layer BLSTM with 512 nodes had the best performance with a mean of 0.01536. Among the simple LSTM models, the double-layer LSTM with 256 nodes performed better than the other models.
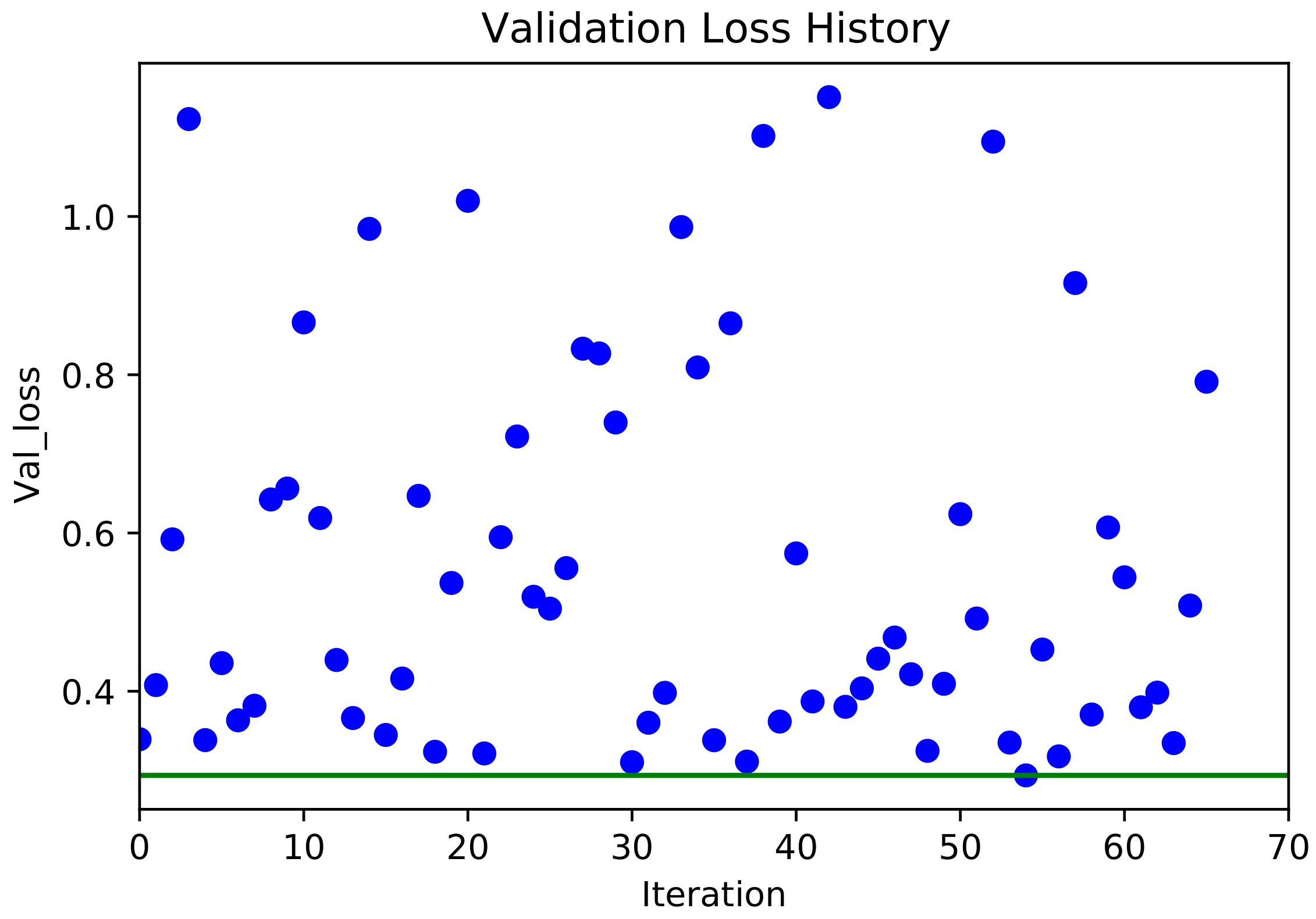
Optimizing the hyperparameters of a machine learning model is simply a minimization problem that seeks the hyperparameters with the least validation loss. Tuning hyperparameters using Bayesian optimization can reduce the time required to find the optimal set of hyperparameters. In this paper, the validation loss in terms of the learning rate, batch size, decay, and dropout size was minimized using Bayesian optimization [
40]. Ten steps of random exploration and 60 iterations of Bayesian optimization were performed. Random exploration can help by diversifying the exploration space [
40]. The learning rate and decay were kept between
and
, and the batch size and dropout size were kept in the range of
and
, respectively. For each iteration of the Bayesian optimization algorithm, the network was run for 50 epochs. In the first ten iterations, the algorithm randomly selected the hyperparameters, calculated the validation loss, and then attempted to minimize the validation loss with respect to the hyperparameters (see
Figure 7). The validation loss and the selected value for each hyperparameter were stored after each iteration. At the end of 70 iterations, the set of hyperparameters with minimal validation loss was selected. These selected values are shown in
Table 4. For simplicity, the decay and learning rates were modified to a power of 10.
The model was trained on different datasets. Once the model was trained on all datasets (70% of each dataset). The other time, the model was trained on two datasets and tested on the third dataset. Each model was trained for a maximum number of 500 iterations (epoch = 500). Early stopping was used to avoid overfitting. Early stopping is a regularization strategy that determines how many epochs can be run before overfitting begins [
31]. In our implementation, the validation error was monitored during training, and if it did not improve after a maximum of ten epochs, training was stopped.
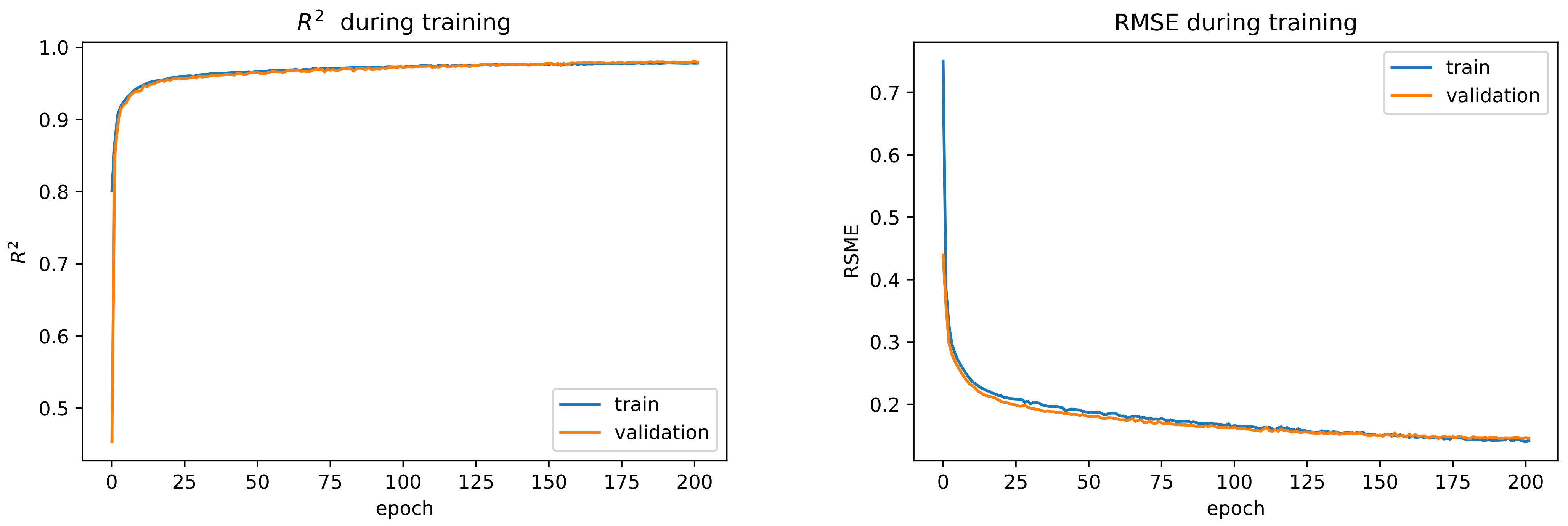
Figure 8 shows the
and RMSE during training on the training set and the validation set. The error improved after 200 epochs on the training set but did not improve again on the validation set.
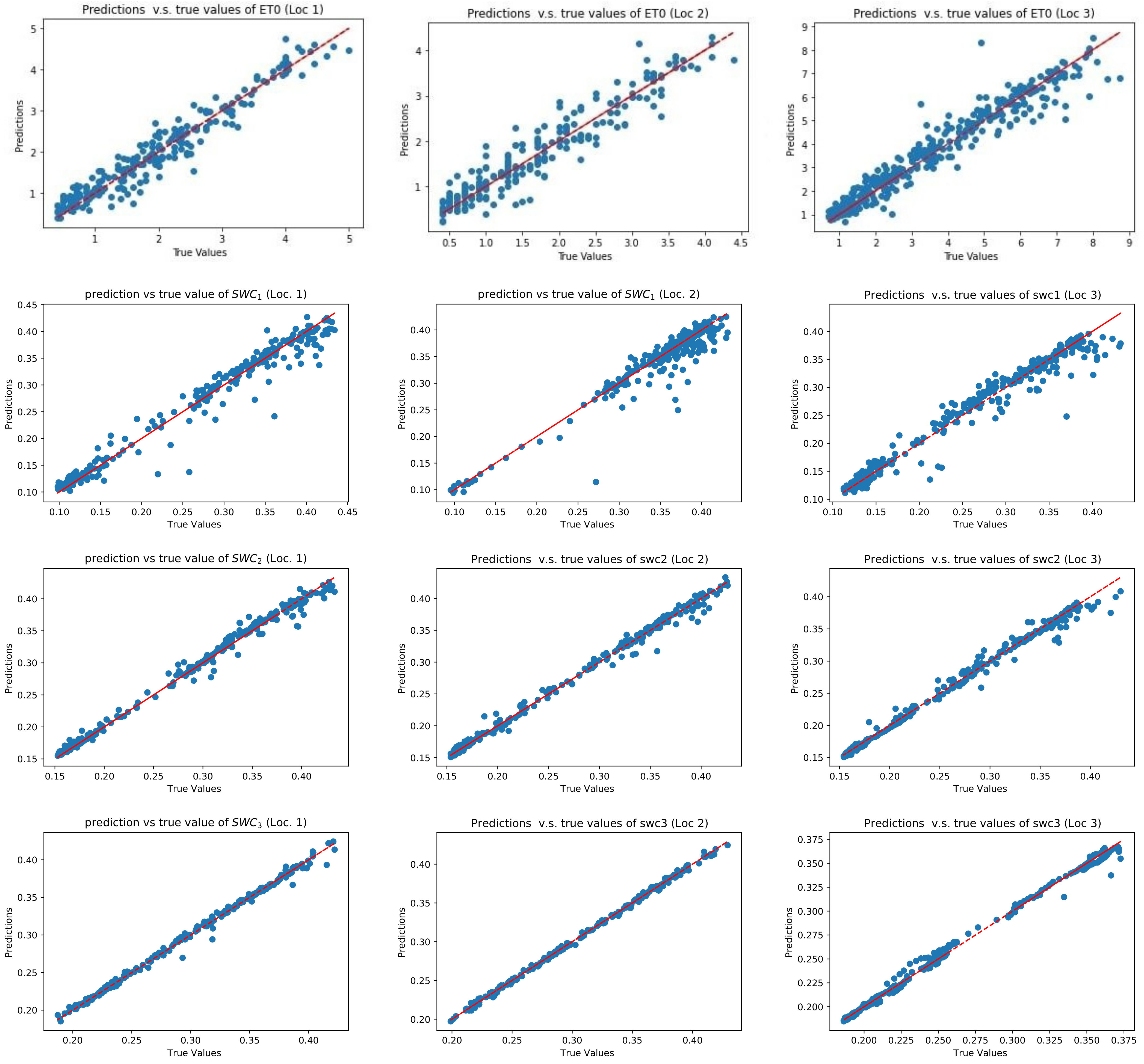
Table 5 and
Table 6 and
Figure 9 show the evaluation of the model on the test set and the predicted value compared to the true values of the SWC and ETo, respectively. The results indicated that although the MSE (the variance of the error) at Loc. 2 was lower than the MSE at Loc. 3, the
- score (the variance explained by the model over the total variance) improved at Loc. 3. Therefore, it is not sufficient to use only one metric to evaluate a model.
As
Figure 9 and
Table 5 show, the best accuracy in predicting ETo and SWC was achieved with the dataset of Loc. 2 and Loc. 3, respectively. ET was underestimated with the model in Loc. 2 and Loc. 3 but overestimated in Loc. 1. The results also show that as the depth of the soil increases, the accuracy of the model for predicting SWC increases. This could be due to the fact that the range and standard deviation of SWC decrease as the soil depth increases. Adding some other variables to the input of the model, such as irrigation amount, and adding the real data to the simulated dataset may improve the accuracy of the predicted value of SWC in the upper layer (see
Table A1).
As the results show, the models trained with two datasets showed similar performance to the model trained with all datasets. The results also show that the model trained with datasets from different locations can be generalized to other locations.
CNN models are capable of extracting features from raw data. The convolutional layers were added to the proposed models to investigate the performance of the CNN- LSTM model for predicting ETo and SWC.
Table 7 shows the CNN architectures that were used to stack the LSTM models. First, the input sequence was divided into two subsequences, each with four-time steps. The CNN can interpret each subsequence with four-time steps, and the LSTM used a time series of the interpretations from the subsequences as input. The time-distributed layer wrapped the CNN model and allowed each layer to be applied to each subsequence [
43]. The CNN model contained two convolutional layers with kernel sizes of 3 and 2, respectively, followed by an average pooling layer with a pooling size of 2. The number of filters remained the same as the number of nodes in the proposed BLSTM model, i.e., 512 filters in each convolutional layer.
In this paper, the performance of the models was improved by using the function
and the average pooling layer instead of the layer
or Max Pooling (see
Table 8).
The performance and computational efficiency of the CNN-BLSTM models are shown in
Table 8 and
Table 9. The BLSTM model outperformed the CNN-BLSTM model in terms of model performance and computation time. As shown in
Table 9, the number of trainable parameters tripled in the CNN-BLSTM model compared to the BLSTM. Therefore, the model began to overfit due to the complexity of model.
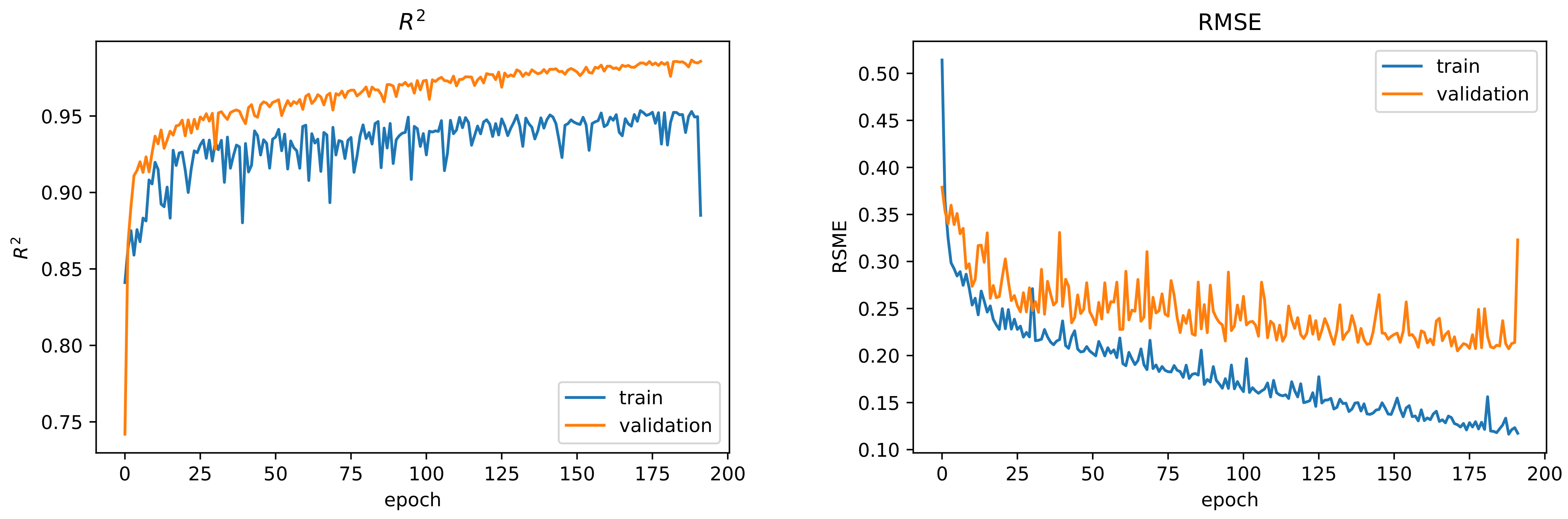
Figure 10 shows the
and
- score during the training of the CNN-LSTM models.
The performance of the LSTM model was compared with the CNN model and two traditional machine learning models: SVR and Random Forest. The CNN architecture used for the comparison was the same as the CNN architecture built on the LSTM architecture, with the expectation that the time-distributed layers were removed and a dense layer was added in place of the LSTM layers to make the prediction (see
Table 10).
RF is one of the most powerful machine learning methods. The Random Forest consists of several Decision Trees. Each individual tree is a very simple model that has branches, nodes where a condition is checked, and if it is satisfied, the flow goes through one branch, otherwise through the other, and always to the next node until the tree is finished [
22].
Support Vector Regression (SVR) is a supervised learning algorithm used to predict discrete values. The basic idea behind SVR is to find the best fitting line. In SVR, the best fitting line is the hyperplane that has the maximum number of input points [
21]. A kernel in the SVR model is a set of mathematical functions that take data as input and transform it into the desired shape. They are generally used to find a hyperplane in a higher-dimensional space. The most commonly used kernels include Linear, Nonlinear, Polynomial, Radial Base Function (RBF), and Sigmoid. Each of these kernels is used depending on the dataset. In this work, the RBF kernel has been used [
45].
Table 11 shows the performance of each model on the test set. As shown, the LSTM models show better performance on the datasets. The CNN model has achieved the second-best performance.
One of the applications of this model is a decision system that decides when and how much to irrigate in order to avoid water waste without compromising productivity. In future work, a reinforcement learning agent can be trained to select the best amount of irrigation. In deep reinforcement learning algorithms, there is an environment that interacts with an agent. During training, the agent chooses an action based on the current state of the environment, and the environment returns the reward and the next state based on the previous state to the agent. The agent tries to choose the action that maximizes the reward [
46]. In the agricultural domain, the state of the environment can be defined as the climate data and the water content of the soil and ETo; the action is the amount of irrigation, and the reward is the net yield. An agent can be trained to choose the irrigation amount based on the state of the field, and the SWC and ET prediction model can be used as part of the environment of Deep Reinforcement Learning to calculate the next state of the environment. By using the trained model in this paper, the training of the agent can be end-to-end and does not require manual processing.
In the end, the importance of the loss function to train the LSTM models was investigated for Loc. 3. The model was trained using MSE, RMSE, MAE, and Huber loss function. The Huber loss function (
) is the composition of the MAE and MSE and can be calculated by Equation (15):
where
is a hyperparameter that should be set. The Huber function is basically MAE, which becomes MSE when the error is small. Unlike the MAE, the Huber function is differentiable at 0.
Table 12 shows the performance of the model on the validation set using Huber, MAE, RMSE, and MSE as loss function for Loc. 3. The model with MSE as a loss function outperformed the others.
4. Conclusions
The advantage of the recurrent neural network is its ability to process time-series data like agricultural datasets. In this paper, the ability of recurrent neural networks, including LSTM and its extension BLSTM, to model ETo and SWC was investigated. A drawback of deep learning methods is that they require a large amount of data to train. To overcome this problem, the simulated dataset was used for ET and SWC. The BLSTM model outperformed the LSTM model on the validation set, and hence a single layer BLSTM model with 512 nodes was trained. The proposed model achieved MSE in the range of 0.014 to 0.056, and the results show that the BLSTM model has good potential for modeling ETo and SWC. The CNN models are able to extract features from the data. A CNN model was added to the BLSTM model to extract features, and then BLSTM used these features to predict ET and SWC. When a CNN model was added to the LSTM model, and the number of parameters in the CNN-BLSTM was increased by three times, the model began to overfit after 100 epochs, and BLSTM showed better results than the CNN-BLSTM. Therefore, increasing the number of trainable parameters in deep learning algorithms may cause the model to overfit.
The performance of BLSTM was also compared with Random Forest, SVR, and CNN. The best performance was obtained with BLSTM. The second-best performance was obtained with the CNN model. Among the machine learning methods, RF outperformed the SVR model. One disadvantage of BLSTM compared to CNN, SVR, and RF was that the training time of BLSTM was higher than the other models, but when trained, it was more accurate, and the computation time for prediction was almost the same as the other models.
Finally, the importance of choosing a loss function was investigated. The model with MSE as the loss function performed better than the other models with an MSE of 0.056, and the model with as the loss function had the worst performance. These results show that the choice of a loss function depends on the problem and must be chosen carefully.
In future work, the variables such as irrigation amount and groundwater level will be added to the input of the model to make the prediction more accurate. As mentioned earlier, one of the applications of the SWC and ET prediction model is to develop an end-to-end decision support system that automatically decides when and how much to irrigate. Deep reinforcement learning models are used to build such a system. An agent can be trained to select the amount of irrigation based on the condition of the field. Deep reinforcement learning algorithms require an environment that interacts with the agent and tells the agent the next state and reward. The SWC and ET prediction model is used as part of the algorithms’ environment and determines the next state, which is the SWC and ET a day per head.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










