
A New Computational Method for Arabic Calligraphy Style Representation and Classification


Abstract
:1. Introduction
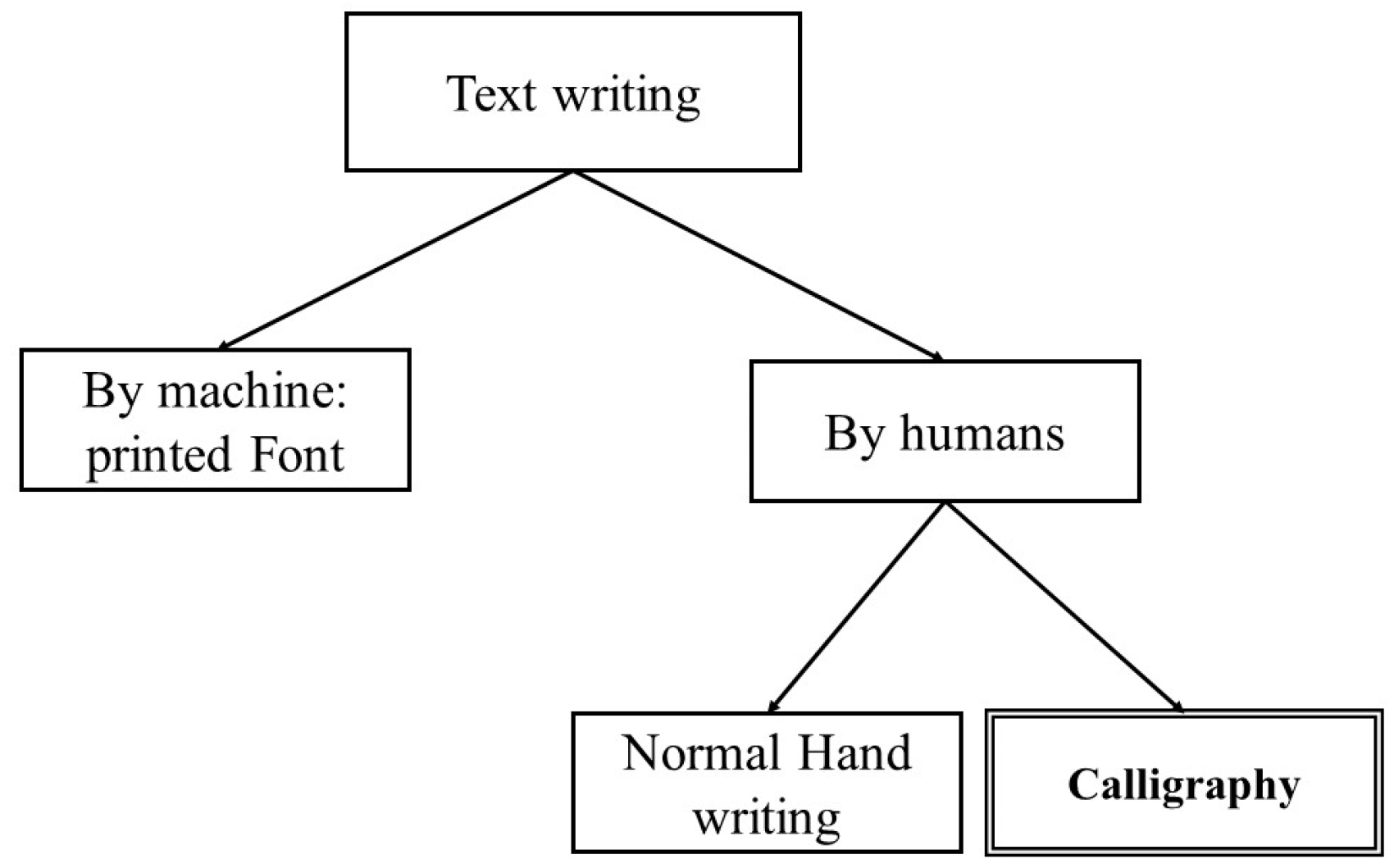
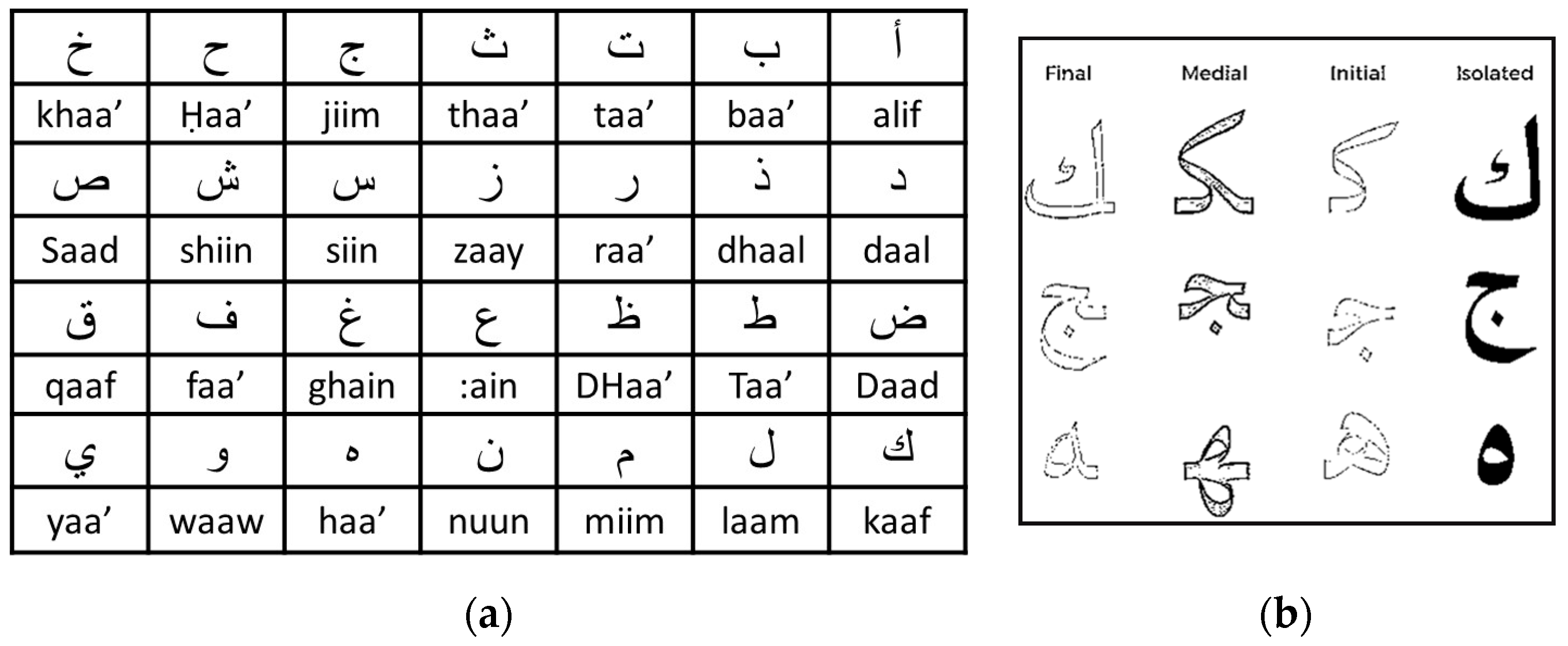
2. Characteristics of Arabic Handwritten Calligraphy and Its Complexity
Arabic Calligraphy Styles
3. Related Work
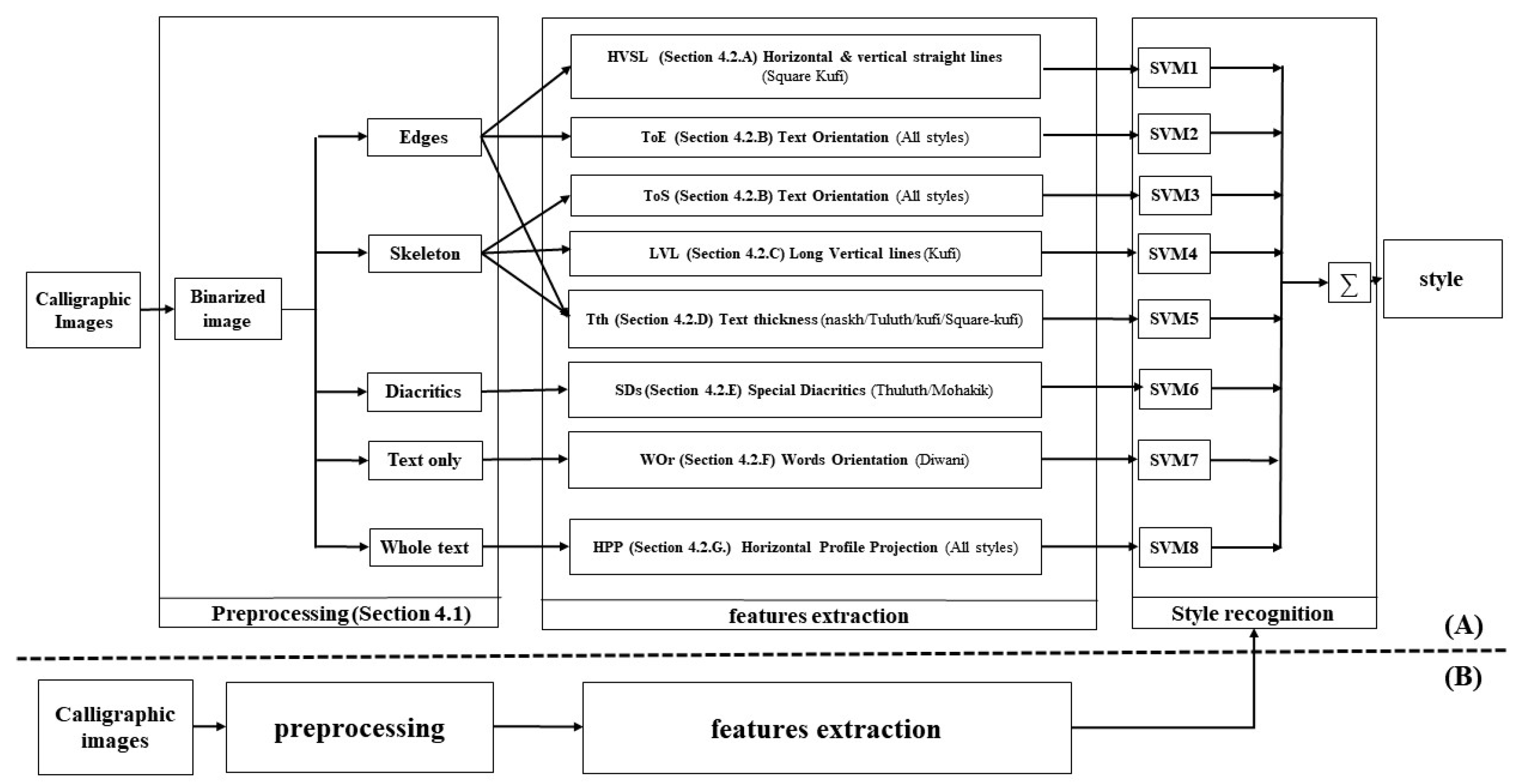
4. Proposed Method
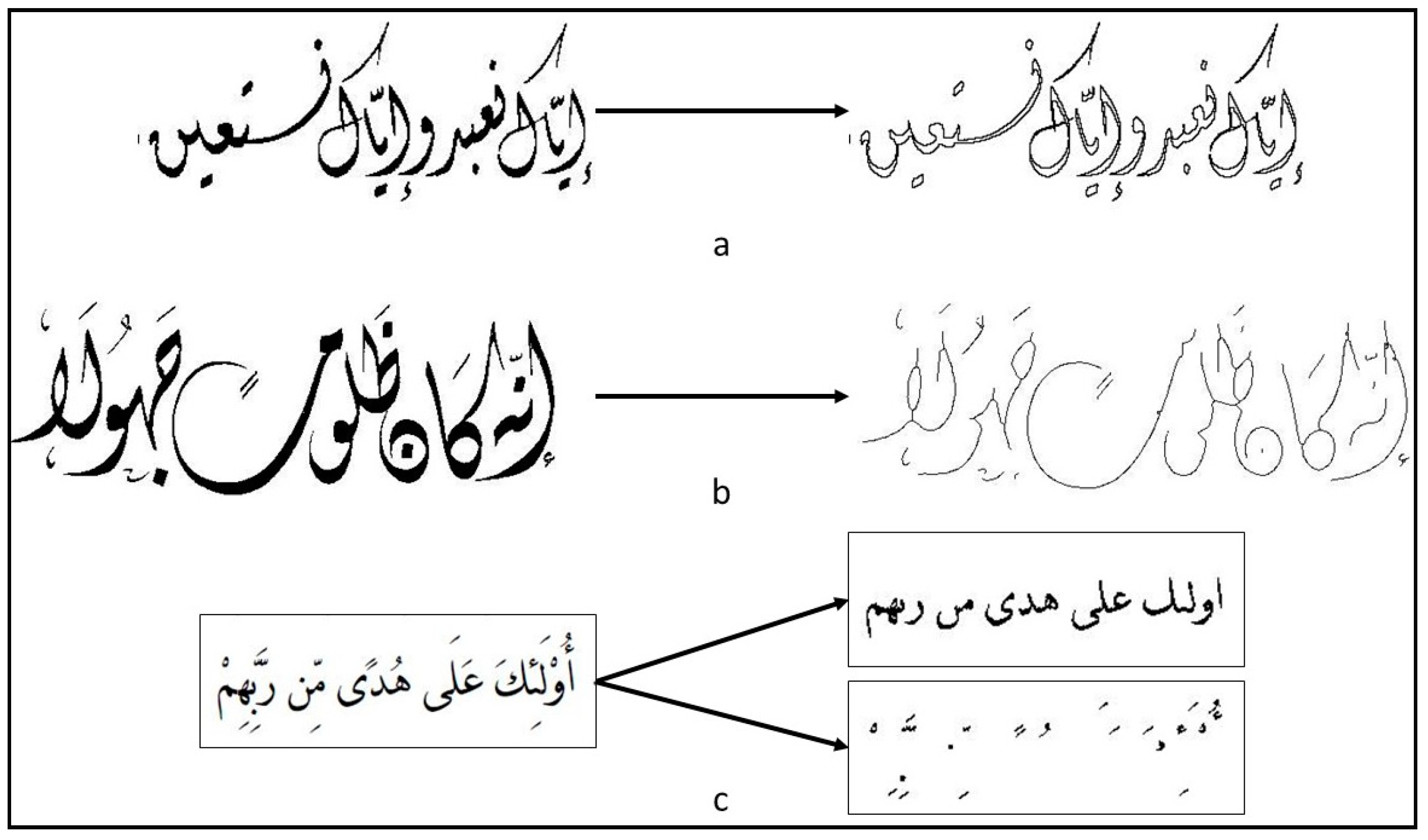
4.1. Preprocessing
4.2. Feature Extraction
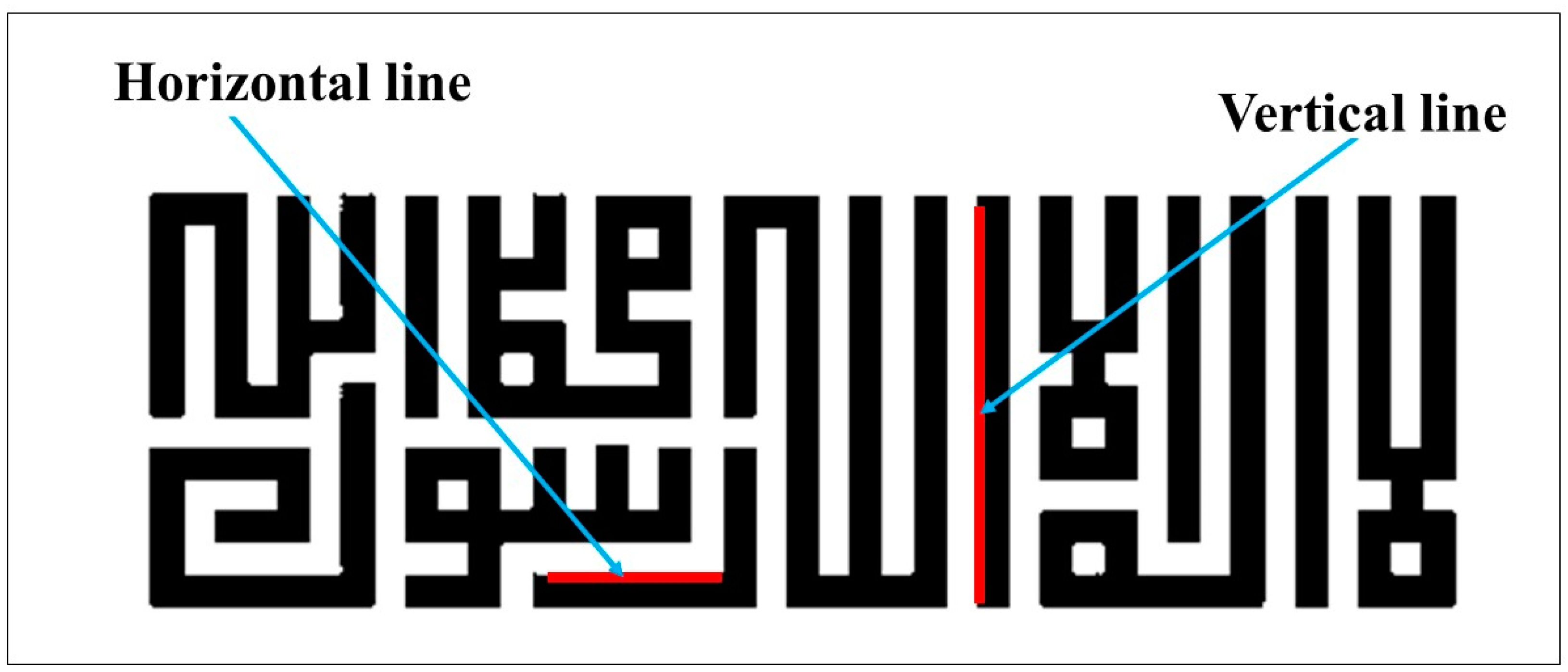
4.2.1. Horizontal and Vertical Straight Lines (HVSL)
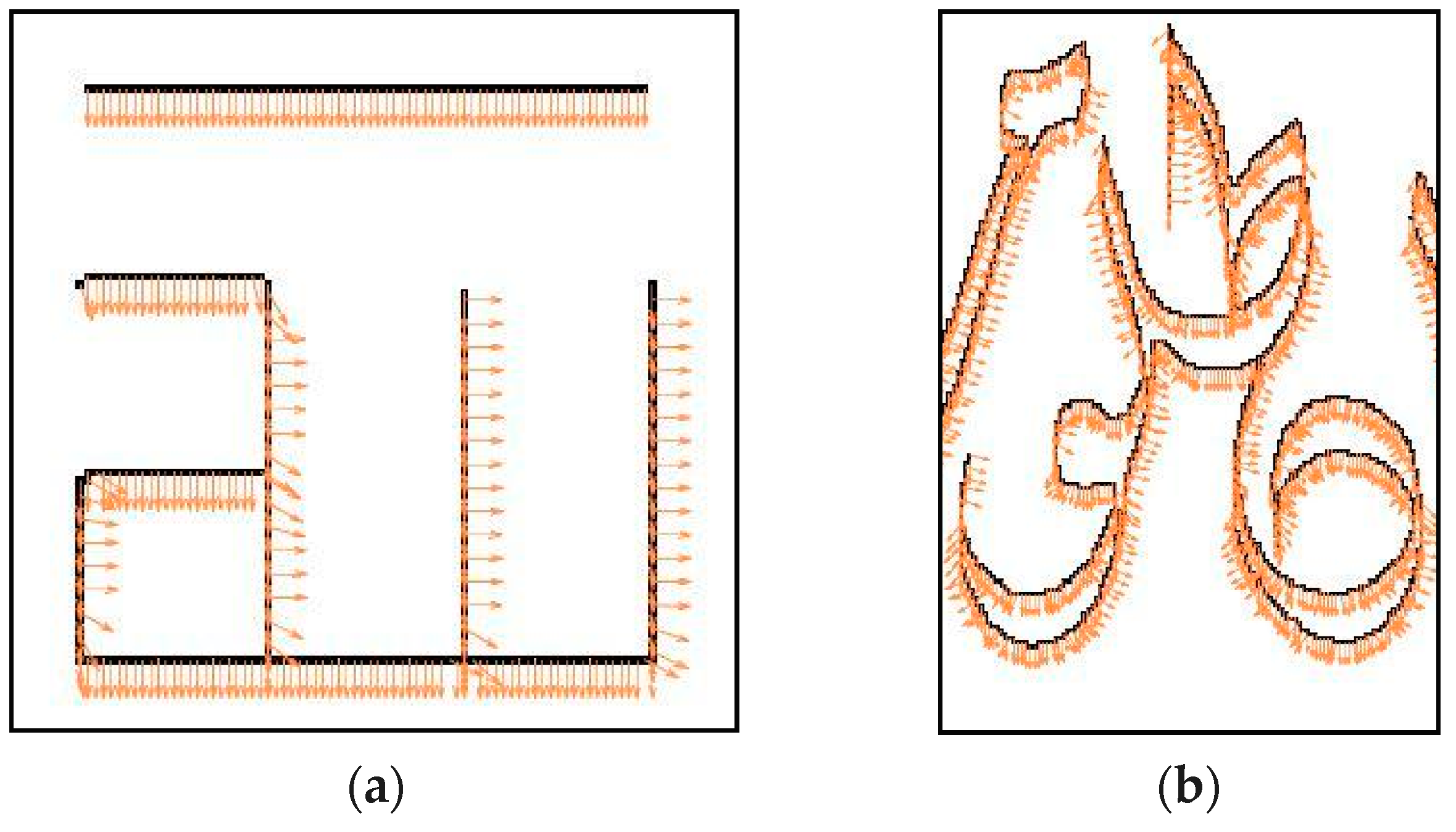
4.2.2. Text Orientation from Edge/Skeleton (ToE/ToS)
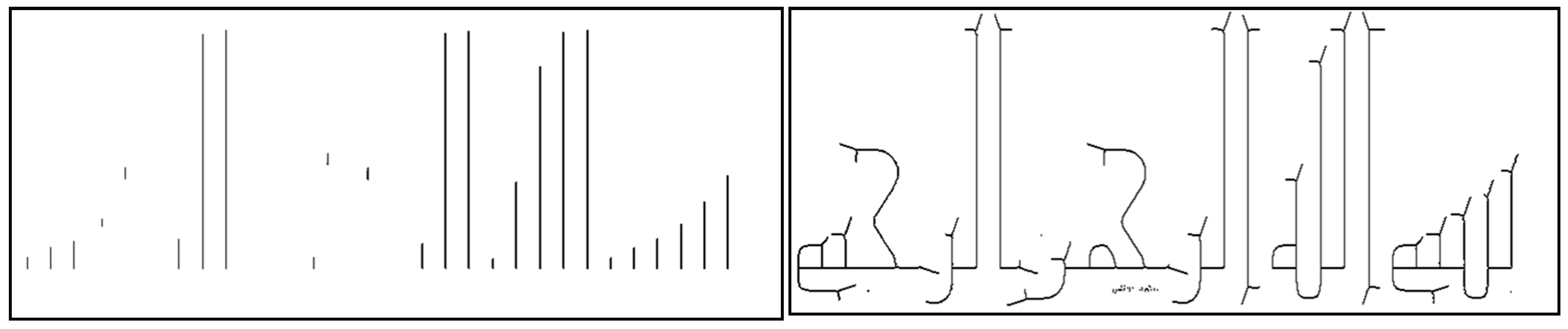
4.2.3. Long Vertical Lines (LVL)
4.2.4. Text Thickness (Tth)
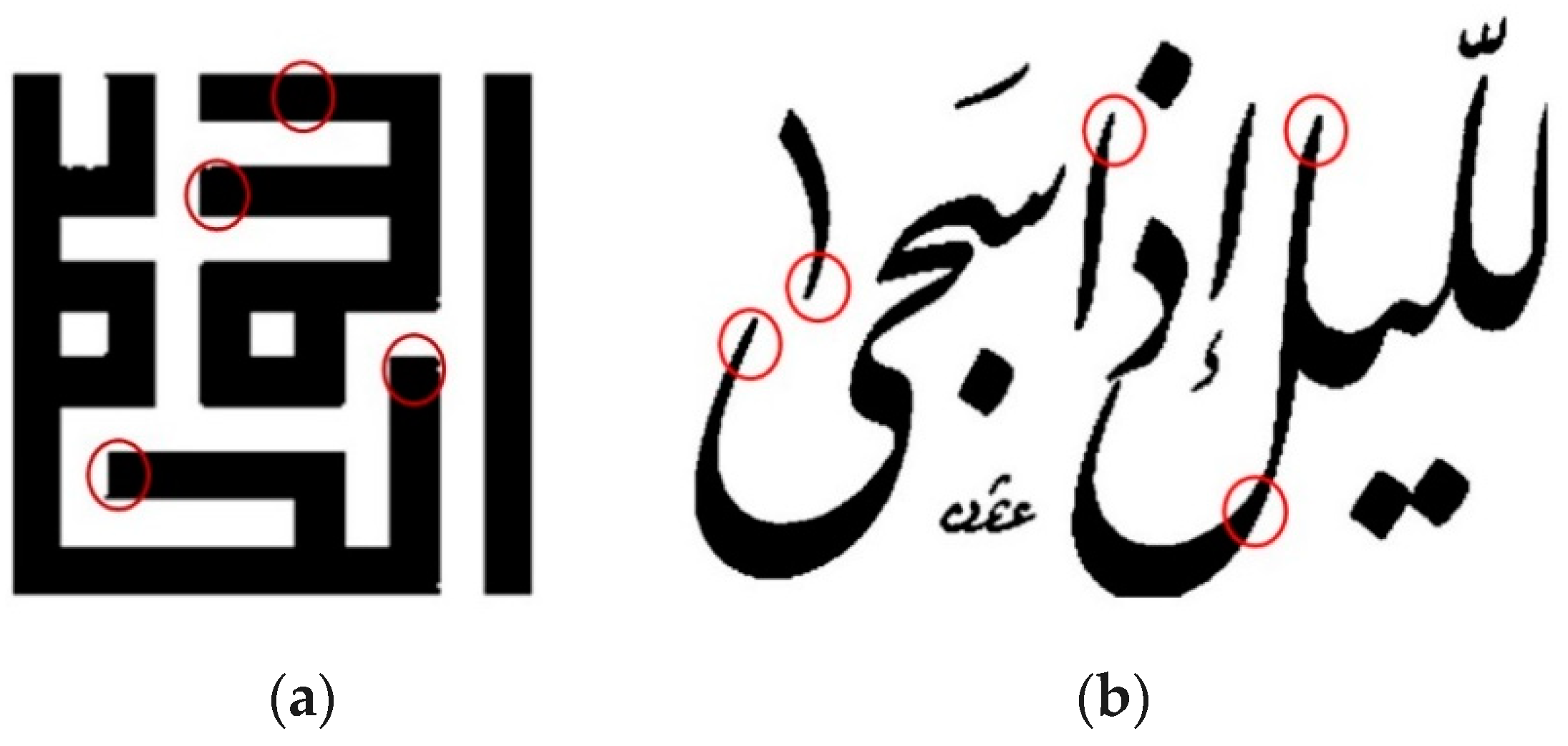
4.2.5. Special Diacritics (SDs)
4.2.6. Word’s Orientation (WOr)
4.2.7. Horizontal Profile Projection (HPP)
5. Experimental Results and Discussion
- Classification: For image classification, we use the well-known classifier Support Vector Machine (SVM). Support Vector Machine classifier is a supervised machine learning technique. The main goal of this supervised method is to find a function in a multidimensional space that is able to separate training data with known class labels. SVM can be used for linear as well as nonlinear data classification. In our case, we use the Polynomial Kernel. This choice is a result of the outperformance SVM showed compared to other classifiers. To avoid overfitting, 3-fold cross-validation has been adopted.
- Metrics: To validate our model, we use four metrics, namely: Recall (R), Precision (P), F1-score, and Accuracy given by the following formulas.
- Scenario 1. Experimenting with each descriptor individually:
- Scenario 2: combine the descriptors
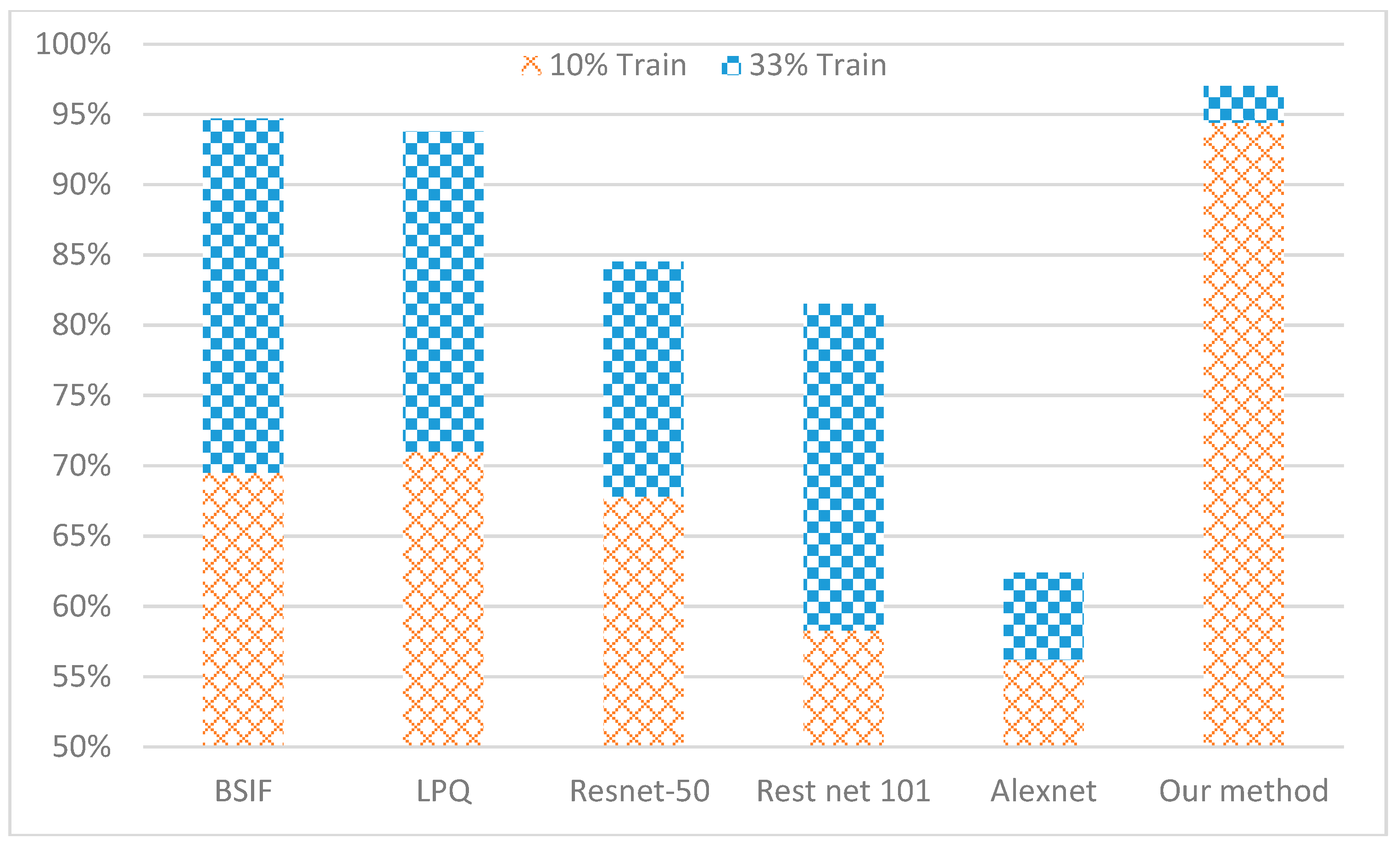
- Scenario 3: Compare to other texture and deep learning methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Binmakhashen, G.M.; Mahmoud, S.A. Document Layout Analysis: A Comprehensive Survey. ACM Comput. Surv. 2019, 52, 109. [Google Scholar] [CrossRef] [Green Version]
- Stauffer, M.; Maergner, P.; Fischer, A.; Riesen, K. A Survey of State of the Art Methods Employed in the Offline Signature Verification Process. In New Trends in Business Information Systems and Technology: Digital Innovation and Digital Business Transformation; Dornberger, R., Ed.; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2020; pp. 17–30. [Google Scholar]
- Rehman, A.; Naz, S.; Razzak, M.I. Writer identification using machine learning approaches: A comprehensive review. Multimed. Tools Appl. 2019, 78, 10889–10931. [Google Scholar] [CrossRef]
- Available online: https://www.worldatlas.com/articles/the-world-s-most-popular-writing-scripts.html (accessed on 10 May 2021).
- Hussein, A.K. Fast learning neural network based on texture for Arabic calligraphy identification. Indones. J. Electr. Eng. Comput. Sci. 2021, 21, 1794–1799. [Google Scholar] [CrossRef]
- Luqman, H.; Mahmoud, S.A.; Awaida, S. Arabic and Farsi Font Recognition: Survey. Int. J. Pattern Recognit. Artif. Intell. 2015, 29, 1553002. [Google Scholar] [CrossRef]
- Bar Yosef, I.; Kedem, K.; Dinstein, I.; Beit-Arie, M.; Engel, E. Classification of hebrew calligraphic handwriting styles: Preliminary results. In Proceedings of the First International Workshop on Document Image Analysis for Libraries, Palo Alto, CA, USA, 23–24 January 2004; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2004; pp. 299–305. [Google Scholar]
- Wang, L.; Gong, X.; Zhang, Y.; Xu, P.; Chen, X.; Fang, D.; Zheng, X.; Guo, J. Artistic features extraction from chinese calligraphy works via regional guided filter with reference image. Multimed. Tools Appl. 2018, 77, 2973–2990. [Google Scholar] [CrossRef]
- Pengcheng, G.; Gang, G.; Jiangqin, W.; Baogang, W. Chinese calligraphic style representation for recognition. Int. J. Doc. Anal. Recognit. 2017, 20, 59–68. [Google Scholar] [CrossRef]
- Kallel, F.; Mezghani, A.; Kanoun, S.; Kherallah, M. Arabic Font Recognition Based on Discret Curvelet Transform. In Proceedings of the Third International Afro-European Conference for Industrial Advancement—AECIA 2016; Advances in Intelligent Systems and Computing Series; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; Volume 565, pp. 360–369. [Google Scholar]
- Jaiem, F.K.; Kherallah, M. A novel Arabic font recognition system based on texture feature and dynamic training. Int. J. Intell. Syst. Technol. Appl. 2017, 16, 289. [Google Scholar]
- Jaiem, F.K.; Slimane, F.; Kherallah, M. Arabic font recognition system applied to different text entity level analysis. In Proceedings of the 2017 International Conference on Smart, Monitored and Controlled Cities (SM2C) 2017, Sfax, Tunisia, 17–19 February 2017; pp. 36–40. [Google Scholar]
- Sakr, G.; Mhanna, A.; Demerjian, R. Convolution Neural Networks for Arabic Font Recognition. In Proceedings of the 2019 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Sorento, Italy, 26–29 November 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019; pp. 128–133. [Google Scholar]
- Amer, I.M.; Mostafa, M.G. Deep Arabic Font Family and Font Size Recognition. Int. J. Comput. Appl. 2017, 176, 1–6. [Google Scholar] [CrossRef]
- Kaoudja, Z.; Khaldi, B.; Kherfi, M.L. Arabic Artistic Script Style Identification Using Texture Descriptors. In Proceedings of the 2020 1st International Conference on Communications, Control Systems and Signal Processing (CCSSP), El Oued, Algeria, 16–17 May 2020; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2020; pp. 113–118. [Google Scholar]
- Bataineh, B.; Abdullah, S.N.H.S.; Omar, K. A novel statistical feature extraction method for textual images: Optical font recognition. Expert Syst. Appl. 2012, 39, 5470–5477. [Google Scholar] [CrossRef]
- Bataineh, B.; Abdullah, S.N.H.S.; Omar, K.; Batayneh, A. Arabic-Jawi Scripts Font Recognition Using First-Order Edge Direction Matrix. In Proceedings of the International Multi-Conference on Artificial Intelligence Technology, Shah Alam, Malaysia, 28–29 August 2013; pp. 27–38. [Google Scholar]
- Bataineh, B.; Abdullah, S.N.H.S.; Omar, K. Arabic calligraphy recognition based on binarization methods and de-graded images. In Proceedings of the 2011 International Conference on Pattern Analysis and Intelligent Robotics, ICPAIR 2011, Putrajaya, Malaysia, 28–29 June 2011; pp. 65–70. [Google Scholar]
- Bataineh, B.; Abdullah, S.N.H.S.; Omar, K. Generating an Arabic Calligraphy Text Blocks for Global Texture Analysis. Int. J. Adv. Sci. Eng. Inf. Technol. 2011, 1, 150–155. [Google Scholar] [CrossRef] [Green Version]
- Talab, M.A.; Abdullah, S.N.H.S.; Razalan, M.H.A. Edge direction matrixes-based local binary patterns descriptor for invariant pattern recognition. In Proceedings of the 2013 International Conference on Soft Computing and Pattern Recognition (SoCPaR), Hanoi, Vietnam, 15–18 December 2013; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2013; pp. 13–18. [Google Scholar]
- Azmi, M.S.; Omar, K.; Nasrudin, M.F.; Ghazali, K.W.M.; Abdullah, A.; Abdullah, A. Arabic calligraphy identification for Digital Jawi Paleography using triangle blocks. In Proceedings of the 2011 International Conference on Electrical Engineering and Informatics, Bandung, Indonesia, 17–19 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–5. [Google Scholar]
- Azmi, M.S.; Omar, K.; Nasrudin, M.F.; Muda, A.K.; Abdullah, A. Arabic calligraphy classification using triangle model for Digital Jawi Paleography analysis. In Proceedings of the 2011 11th International Conference on Hybrid Intelligent Systems (HIS), Malacca, Malaysia, 5–8 December 2011; pp. 704–708. [Google Scholar]
- Adam, K.; Al-Maadeed, S.; Bouridane, A. Letter-based classification of Arabic scripts style in ancient Arabic manuscripts: Preliminary results. In Proceedings of the 2017 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France, 3–5 April 2017; pp. 95–98. [Google Scholar] [CrossRef]
- Allaf, S.R.; Al-Hmouz, R. Automatic Recognition of Artistic Arabic Calligraphy Types. J. King Abdulaziz Univ. 2016, 27, 3–17. [Google Scholar] [CrossRef]
- Al-Hmouz, R. Deep learning autoencoder approach: Automatic recognition of artistic Arabic calligraphy types. Kuwait J. Sci. 2020, 47, 3. [Google Scholar]
- Khayyat, M.; Elrefaei, L. A Deep Learning Based Prediction of Arabic Manuscripts Handwriting Style. Int. Arab. J. Inf. Technol. 2020, 17, 702–712. [Google Scholar] [CrossRef]
- Kaoudja, Z.; Kherfi, M.L.; Khaldi, B. An efficient multiple-classifier system for Arabic calligraphy style recognition. In Proceedings of the 2019 International Conference on Networking and Advanced Systems (ICNAS), Annaba, Algeria, 26–27 June 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Moghaddam, R.F.; Cheriet, M.; Milo, T.; Wisnovsky, R. A prototype system for handwritten sub-word recognition: Toward Arabic-manuscript transliteration. In Proceedings of the 2012 11th International Conference on Information Science, Signal Processing and their Applications (ISSPA), Montreal, QC, Canada, 2–5 July 2012; pp. 1198–1204. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Cheriet, M.; Kharma, N.; Liu, C.-L.; Suen, C. Character Recognition Systems: A Guide for Students and Practitioners; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Lutf, M.; You, X.; Cheung, Y.-M.; Chen, C.P. Arabic font recognition based on diacritics features. Pattern Recognit. 2014, 47, 672–684. [Google Scholar] [CrossRef]
- Hu, M.-K. Visual pattern recognition by moment invariants. IEEE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar] [CrossRef] [Green Version]
- Khaldi, B.; Aiadi, O.; Kherfi, M.L. Combining colour and grey-level co-occurrence matrix features: A comparative study. IET Image Process. 2019, 13, 1401–1410. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
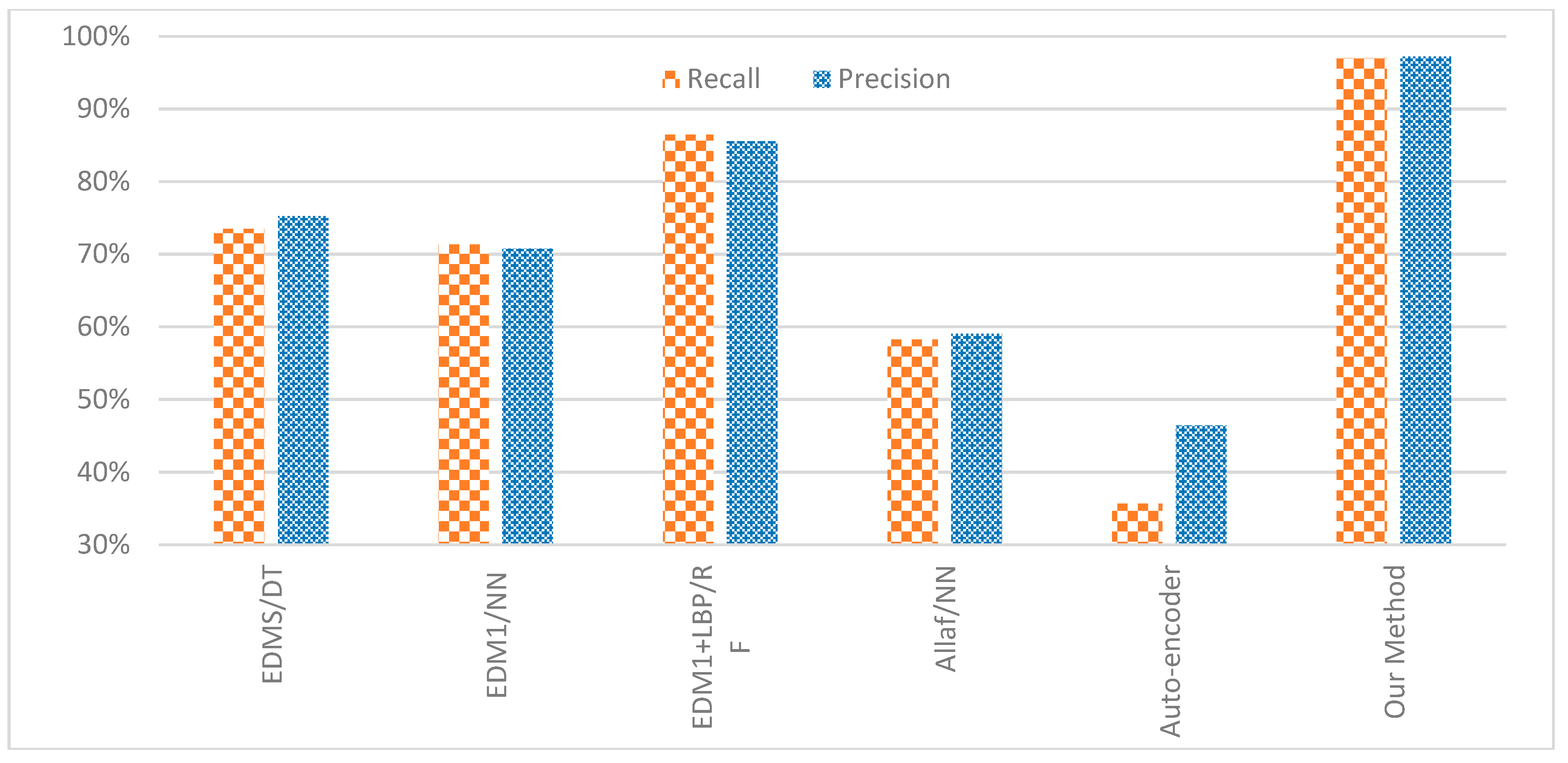{kind=link}
{kind=link}
| AC Style | Example Image | General Characteristics | Cues Used by Experts | Style Source |
|---|---|---|---|---|
| Kufi |  | Composed of geometrical forms such as straight verticals/horizontals lines and distinguishable angles. | - it is angular - thick strokes - long vertical extended strokes | |
| Diwani |  | A cursive script, beautiful, and harmonious. It is characterized by the rounded shape of letters. Words are written skewed descend from right to left. Lines start thick and then attenuate. | - slant words - written with a rounded shape - does not follow a straight line - the style width changes from thick to thin | |
| Farisi |  | Characterized by the letter’s accuracy and extension, and by its ease and clarity and lack of complexity. Farisi (alt., Nasta’liq) is a cursive text. | - simple orientation - does not follow a straight line | |
| Naskh |  | One of the simplest writing types of calligraphy. Its name means “the copy style” because it has been used for copying books. It is recognizable by its balance and its plain clear forms. Nowadays, this script is used primarily in print. | -simple orientation - written on the baseline - slight change in the text thickness | |
| Rekaa |  | Mostly, used without diacritics. known with its clipped letters. Composed of short, straight lines and simple curves, as well as its straight and even lines. It is written above the baseline except for some specific letters. | - simple orientation - written above the baseline - thick stroke | |
| Thuluth |  | It is an elegant, cursive script that has large, elongated, and elegant letters. It has certain roles, but it could be changed according to calligraphers’ needs. It has big letters, which take a big space above the baseline; the big overlapped curves result in big holes that calligraphers fill with artistic diacritics. | - overlapping letters - big rounded letters - high number of diacritics - it does not consider the baseline | |
| Maghribi |  | It has special letterforms which provide it with a unique beauty and make it easy to read, even in long texts. It is marked by descending lines written with very large bowls. | - text orientation - written on the baseline | -Kufi |
| Mohakik |  | Mohakik and Thuluth have almost the same characteristics. However, letters in Mohakik are longer under the baseline. | - special orientation under the baseline - same diacritics as the thuluth style - written on the baseline | -Thuluth |
| Square-Kufi |  | A unique style developed for decorating walls rather than papers. usually designed with mosaic faience, decorative glazed facing tiles, or simple bricks, rather than reed pens and ink. It has two strict rules: (a) evenness of full and empty spaces, and (b) square angles and strict lines. | - strokes with equal thickness - square angles | -Kufi |
| Author (Year) | Language | Dataset | No Styles |
|---|---|---|---|
| Z.Kaoudja et al. (2020) [15] | Arabic | 1685 line image | 9 |
| Batainah et al. (2012) [16] | Arabic jawi | 700 blocks image (privet) | 6 |
| Batainah et al. (2013) [17] | Arabic-jawi | 700 block image (privet) | 7 |
| Batainah et al. (2011) [18] | Arabic | 14 documents images (privet) | Unknown |
| Batainah et al. (2011) [19] | Arabic | 100 line image (privet) | 6 |
| Talab et al.(2011) [20] | Arabic | 700 line images | 7 |
| Azmi et al. (2011) [21] | Arabic-jawi | 100 character image (privet) | 5 |
| Azmi et al. (2011) [22] | Arabic-jawi | 1019 character images (privet) | 4 |
| Adam et al. (2017) [23] | Arabic | 330 character images (privet) | 6 |
| Allaf et al.(2016) [24] | Arabic | 267 line/word images (privet) | 3 |
| Elhmouz et al. (2020) [25] | Arabic | 421 line/word images (privet) | 3 |
| M. Khayyat (2020) [26] | Arabic | 2653 documents images (privet) | 6 |
| Z.Kaoudja et al. (2019) [27] | Arabic | 1685 line image | 9 |
| R.F. Moghaddam et al. (2012) [28] | Arabic | 27709 word image | Unknown |
| Diwani | Naskh | Farisi | Rekaa | Thuluth | Maghribi | Kufi | Mohakik | Square-Kufi | |
|---|---|---|---|---|---|---|---|---|---|
| HVSL (Square-Kufi) | 63% | 62% | 34% | 37% | 83% | 62% | 87% | 74% | 100% |
| ToE (General) | 93% | 88% | 94% | 87% | 88% | 81% | 94% | 86% | 99% |
| ToS (General) | 96% | 88% | 91% | 83% | 90% | 80% | 91% | 86% | 98% |
| LVL (Kufi) | 54% | 77% | 28% | 44% | 49% | 34% | 89% | 25% | 91% |
| Tth (General) | 47% | 61% | 51% | 52% | 66% | 51% | 76% | 43% | 82% |
| SDs (Thuluth + Mohakik) | 13% | 2% | 0% | 10% | 86% | 11% | 17% | 62% | 18% |
| WOr (Diwani) | 85% | 24% | 9% | 21% | 9% | 6% | 8% | 18% | 62% |
| HPP (General) | 76% | 97% | 58% | 76% | 83% | 92% | 97% | 78% | 100% |
| EDMS/Decision Tree [16] | EDM1/NN [17] | EDM1+LBP/Random Forest [20] | Allaf/NN [24] | Auto-Encoder [25] | Our Method | |
|---|---|---|---|---|---|---|
| Diwani | 76% | 75% | 90% | 30% | 35% | 98% |
| Naskh | 92% | 87% | 98% | 81% | 48% | 99% |
| Farisi | 56% | 58% | 80% | 23% | 2% | 97% |
| Rekaa | 54% | 53% | 77% | 45% | 12% | 98% |
| Thuluth | 63% | 56% | 78% | 73% | 43% | 94% |
| Maghribi | 66% | 77% | 75% | 46% | 15% | 97% |
| Kufi | 64% | 72% | 93% | 73% | 14% | 98% |
| Mohakik | 41% | 60% | 79% | 45% | 33% | 94% |
| S-Kufi | 96% | 94% | 97% | 94% | 80% | 99% |
| Style | Diwani | Naskh | Farisi | Rekaa | Thuluth | Maghribi | Kufi | Mohakik | S-Kufi |
|---|---|---|---|---|---|---|---|---|---|
| Diwani | 100% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
| Naskh | 0% | 100% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
| Farisi | 2% | 0% | 96% | 2% | 0% | 0% | 0% | 0% | 0% |
| Rekaa | 0% | 0% | 1% | 98% | 0% | 1% | 0% | 0% | 0% |
| Thuluth | 0% | 0% | 1% | 0% | 95% | 0% | 0% | 3% | 1% |
| Maghribi | 0% | 0% | 1% | 0% | 1% | 99% | 0% | 0% | 0% |
| Kufi | 0% | 0% | 0% | 0% | 0% | 2% | 98% | 0% | 0% |
| Mohakik | 0% | 0% | 0% | 0% | 5% | 0% | 0% | 94% | 1% |
| S-Kufi | 0% | 0% | 0% | 1% | 0% | 0% | 1% | 0% | 99% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaoudja, Z.; Kherfi, M.L.; Khaldi, B. A New Computational Method for Arabic Calligraphy Style Representation and Classification. Appl. Sci. 2021, 11, 4852. https://doi.org/10.3390/app11114852
Kaoudja Z, Kherfi ML, Khaldi B. A New Computational Method for Arabic Calligraphy Style Representation and Classification. Applied Sciences. 2021; 11(11):4852. https://doi.org/10.3390/app11114852
Chicago/Turabian StyleKaoudja, Zineb, Mohammed Lamine Kherfi, and Belal Khaldi. 2021. "A New Computational Method for Arabic Calligraphy Style Representation and Classification" Applied Sciences 11, no. 11: 4852. https://doi.org/10.3390/app11114852