Carbon-Efficient Virtual Machine Placement Based on Dynamic Voltage Frequency Scaling in Geo-Distributed Cloud Data Centers


Abstract
:1. Introduction
2. Related Works
- Selection of data centers and clusters is performed based on the PUE and CO2 emission rate, aiming to reduce the overall carbon footprints of the data centers;
- Load balancing is done by identifying a feasible server with a minimal operating frequency for the current workload with the required quality of service, aiming to reduce hot spots in CPU heat dissipation, which have a direct impact on hardware lifetime and performance;
- The impacts of static and dynamic power usage effectiveness (PUE) on placement decisions are analyzed, along with cooling load power impacts.
3. System Overview
3.1. Power Model
3.2. System Model
- Resource Management System: The resource management system contains information about the cluster list, PUE, CFR, total utility power, current IT load, and other metadata information related to the data centers.
- Management Node (MN): The Resource Allocation Management (RAM) algorithm is a daemon that is executed in the management node. It is updated with the cluster list, host list, PUE, carbon footprint rate, and other information related to the clusters in the data center. It activates the scheduling algorithm for VM-to-PM mapping and the resource deallocation algorithm to perform resource recovery, and updates target virtual machine queue (TargetVMQ) with VM-to-PM mapping information.
- Cluster Manager (CM): A node in the cluster is nominated as the head node to function as the cluster manager. The overall utilization of the cluster, number of machines in on and off states, maximum and minimum utilization, number of VMs operating in the cluster, and power consumption are maintained by the cluster manager and updated by the management node.
- Physical Machine Manager (PMM): The PM details related to available memory and CPU capacity, current operating frequency, power consumption, percentage of CPU utilization, number of active VMs, and other PM-related information are maintained by the PMM and updated by the CM in the head node.
- Virtual Machine Manager (VMM): The VMM is a daemon that is executed in each PM. It is responsible for maintaining the VMs executing in PM. VM resource utilization, percentage of CPU time utilized, submission time, placement time, active and idle states, remaining execution time, power consumption, and other VM details are maintained by the VMM.
4. Problem Formulation
4.1. Objective Function
4.1.1. Server Power
4.1.2. Cooling Power
5. Evaluated Algorithms
5.1. RAMAlgorithm
| Algorithm 1: High-level overview of the algorithm approach |
| Input: Hostlist, VM instancelist |
| Output: TargetVMQ |
| 1 for interval do |
| 2 ReqQ←Get VMs from VM instance list; |
| 3 HostQ←Get Hosts from HostList; |
| 4 TargetVMQ←Call placement algorithm (presented in Section 5.2, Section 5.3, Section 5.4, Section 5.5 and Section 5.6); |
| 5 if interval >min-exe-time then |
| 6 Completedlist←Get VMs with active time completion from TargetVMQ; |
| 7 for completedlistdo |
| 8 Deallocate resources associated with the VM; |
| 9 Endfor |
| 10 Endif |
| 11 Endfor |
| 12 Return Target VMQ. |
5.2. Carbon- and Power-Efficient Optimal Frequency VM Placement (C-PEF)
| Algorithm 2: CPEF Carbon and Power-Efficient Optimal Frequency VM Placement |
 |
5.3. Carbon-Aware First-Fit Optimal Frequency VM Placement (C-FFF)
5.4. Carbon- and Power-Efficient VM Placement (C-PE)
5.5. Carbon-Aware First-Fit Least-Empty VM Placement (C-FFLE)
| Algorithm 3: C-FFF Carbon-Aware First-Fit Least-Empty VM Placement |
 |
5.6. Carbon-Aware First-Fit VM Placement (C-FF)
6. Experimental Environment and Assumptions
Physical Machine and VM Reservation Modeling
7. Results and Discussions
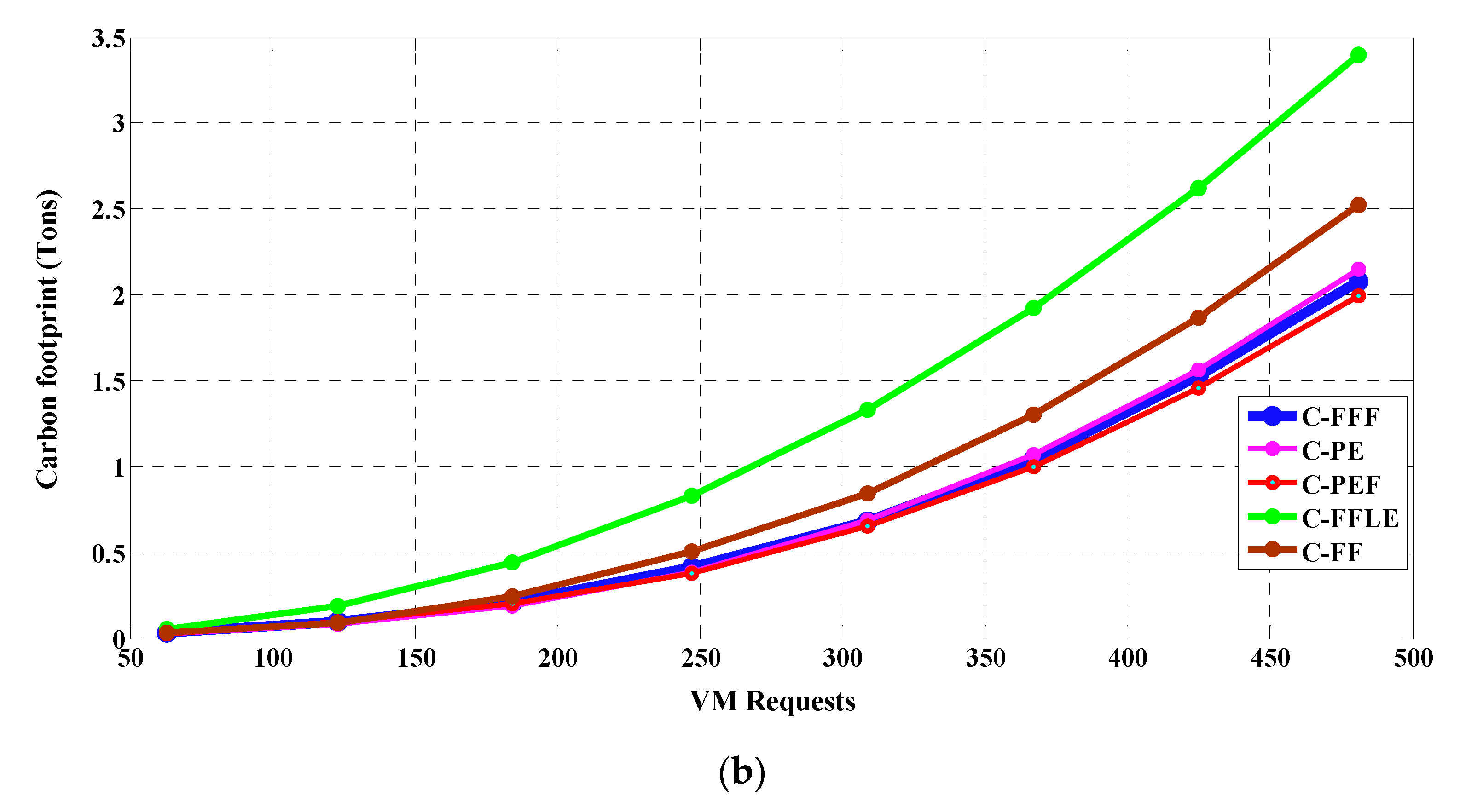
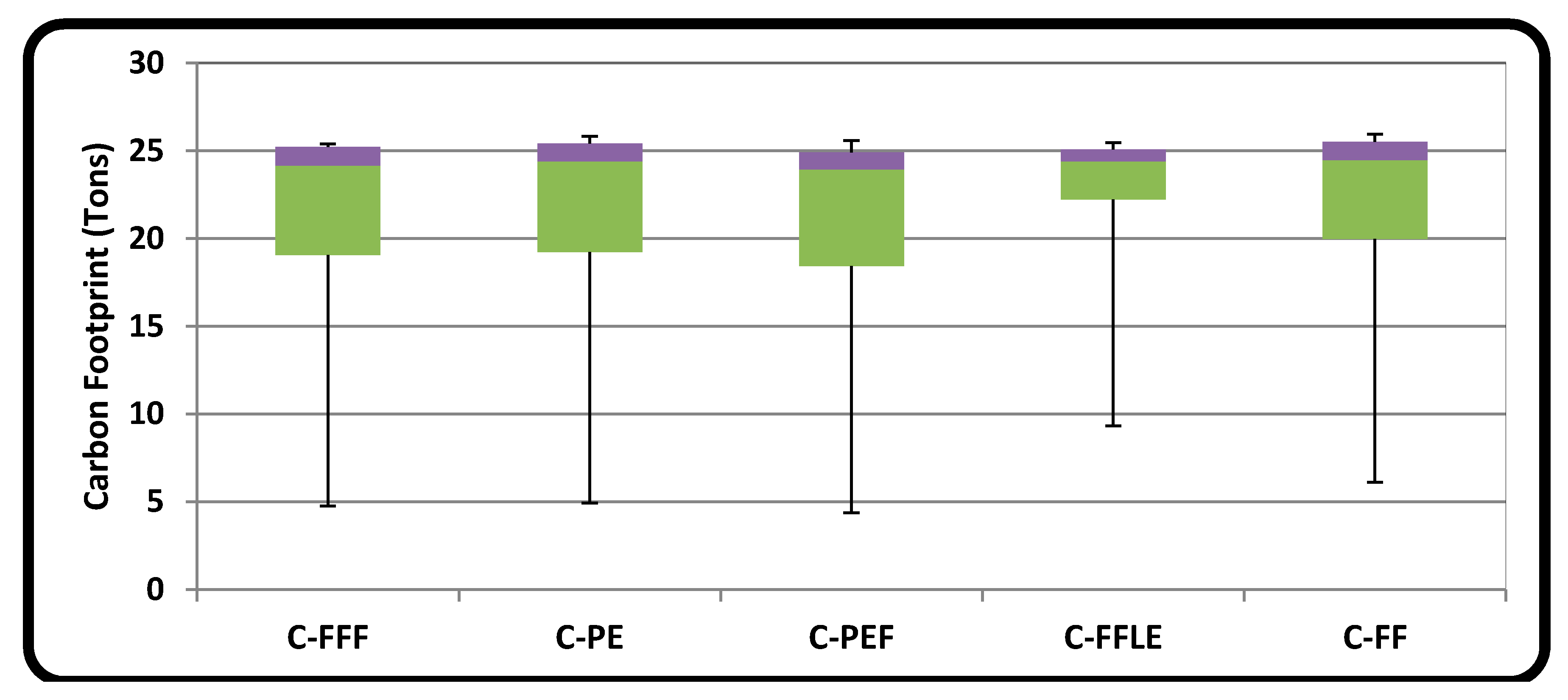
- Reduction in Overall Carbon Footprint
- The ratio of VM acceptance (RVA)
7.1. Scenario-I: Energy-Efficient Mapping of VMs to PMs with StaticPUE
7.2. Scenario-II: Energy-Efficient Mapping of VMs to PMs with DynamicPUE
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Foster, I.; Zhao, Z.; Raicu, I.; Lu, S. Cloud Computing and Grid Computing 360-Degree Compared; Grid Computing Environments Workshop: Austin, TX, USA, 2008. [Google Scholar] [CrossRef] [Green Version]
- Ghatikar, G. Demand Response Opportunities and Enabling Technologies for Datacenters: Findings from Field Studies. Available online: https://escholarship.org/uc/item/7bh6n6kt (accessed on 9 December 2019). [CrossRef] [Green Version]
- Patel, P.; Ranabahu, A.H.; Sheth, A.P. Service Level Agreementin Cloud Computing. 2009. Available online: https://corescholar.libraries.wright.edu/knoesis/78/ (accessed on 9 December 2019).
- Liu, H. A measurement study of server utilization in public clouds. In Proceedings of the 2011 IEEE Ninth International Conference on Dependable, Autonomic and Secure Computing, Sydney, Australia, 12–14 December 2011; pp. 435–442. [Google Scholar] [CrossRef]
- Varasteh, A.; Goudarzi, M. Server consolidation techniques in virtualized data centers: A survey. IEEE Syst. J. 2015, 11, 772–783. [Google Scholar] [CrossRef]
- Gholami, M.F.; Daneshgar, F.; Low, G.; Beydoun, G. Cloud migration process—A survey, evaluation framework, and open challenges. J. Syst. Softw. 2016, 120, 31–69. [Google Scholar] [CrossRef]
- Buyya, R.; Beloglazov, A.; Abawajy, J. Energy-efficient management of data center resources for cloud computing: A vision, architectural elements, and openchallenges. In Proceedings of the 2010 International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA 2010), Las Vegas, NV, USA, 12–15 July 2010. [Google Scholar]
- Jin, Y.; Wen, Y.; Chen, Q.; Zhu, Z. An empirical investigation of the impact of server virtualization on energy efficiency for green data center. Comput. J. 2013, 56, 977–990. [Google Scholar] [CrossRef]
- Lu, Z.; Takashige, S.; Sugita, Y.; Morimura, T.; Kudo, Y. An analysis and comparison of cloud data center energy efficient resource management technology. Int. J. Serv. Comput. 2014, 2, 32–51. [Google Scholar] [CrossRef]
- Panneerselvam, J.; Liu, L.; Hardy, J.; Antonopoulos, N. Analysis, Modelling and Characterisation of Zombie Servers in Large-Scale Cloud Data centres. IEEE Access 2017, 5, 15040–15054. [Google Scholar] [CrossRef]
- Gandhi, A.; Harchol-Balter, M.; Das, R.; Lefurgy, C. Optimal power allocation in server farms. In ACMSIGMETRICS Performance Evaluation Review; Association for Computing Machinery: New York, NY, USA, 2009; Volume 37, pp. 157–168. [Google Scholar] [CrossRef] [Green Version]
- Aydin, H.; Yang, Q. Energy-aware partitioning for multi processor real-time systems. In Proceedings of the International Parallel and Distributed Processing Symposium, Nice, France, 22–26 April 2003; pp. 9–12. [Google Scholar] [CrossRef] [Green Version]
- LeSueur, E.; Heiser, G. Dynamic voltage and frequency scaling: The laws of diminishing returns. In Proceedings of the 2010 International Conference on Power Aware Computing and Systems, Atlanta, GA, USA, 19–23 April 2010; pp. 1–8. [Google Scholar]
- Yang, C.Y.; Chen, J.J.; Kuo, T.W.; Thiele, L. An approximation scheme for energy-efficient scheduling of real-time task sin heterogeneous multiprocessor systems. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition, Nice, France, 20–24 April 2009; pp. 694–699. [Google Scholar] [CrossRef] [Green Version]
- Barroso, L.A.; Clidaras, J.; Hölzle, U. The data center as a computer: An introduction to the design of warehouse-scale machines. Synth. Lect. Comput. Archit. 2009, 4, 1–108. [Google Scholar] [CrossRef]
- Khargharia, B.; Hariri, S.; Szidarovszky, F.; Houri, M.; El-Rewini, H.; Khan, S.U.; Ahmad, I.; Yousif, M.S. Autonomic power & performance management for large-scale data centers. In Proceedings of the 2007 IEEE International Parallel and Distributed Processing Symposium, Rome, Italy, 26–30 March 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Mastroleon, L.; Bambos, N.; Kozyrakis, C.; Economou, D. Automatic power management schemes for internet servers and data centers. In Proceedings of the GLOBECOM’05 IEEE Global Telecommunications Conference, St. Louis, MO, USA, 28 November–2 December 2005; pp. 5–10. [Google Scholar] [CrossRef]
- Raghavendra, R.; Ranganathan, P.; Talwar, V.; Wang, Z.; Zhu, X. No power struggles: Coordinated multi-level power management for the data center. In Proceedings of the ACMSIGOPS Operating Systems Review 2008, Seattle, WA, USA, 1–5 March 2008; Volume 42, pp. 48–59. [Google Scholar] [CrossRef]
- Le, K.; Bianchini, R.; Martonosi, M.; Nguyen, T.D. Cost-and energy-aware load distribution across data centers. Proc. Hot Power 2009, 1–5. [Google Scholar]
- Berral, J.L.; Goiri, Í.; Nou, R.; Julià, F.; Guitart, J.; Gavaldà, R.; Torres, J. Towards energy-aware scheduling in data centers using machine learning. In Proceedings of the 1st International Conference on Energy-Efficient Computing and Networking, Passau, Germany, 13–15 April 2010; pp. 215–224. [Google Scholar] [CrossRef] [Green Version]
- Kolodziej, J.; Khan, S.U.; Xhafa, F. Genetic algorithms for energy-aware scheduling in computational grids. In Proceedings of the International Conferenceon P2P, Parallel, Grid, Cloud and Internet Computing, Barcelona, Catalonia, Spain, 26–28 October 2011; pp. 17–24. [Google Scholar] [CrossRef]
- Barbagallo, D.; DiNitto, E.; Dubois, D.J.; Mirandola, R. Abio-inspired algorithm for energy optimization in a self-organizing data center. In Proceedings of the International Worksh opon Self-Organizing Architecture, Cambridge, UK, 14–17 September 2009; pp. 127–151. [Google Scholar] [CrossRef]
- Mazzucco, M.; Dyachuk, D.; Deters, R. Maximizing cloud providers’ revenues via energy aware allocation policies. In Proceedings of the IEEE 3rd International Conference on Cloud Computing, Miami, FA, USA, 5–16 July 2010; pp. 131–138. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, A.; Garg, S.K.; Buyya, R. Energy and carbon-efficient placement of virtual machines in distributed cloud data centers. In Proceedings of the European Conference on Parallel Processing, Aachen, Germany, 26–30 August 2013; pp. 317–328. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Zhu, G.; Cui, C.; Tang, H.; Dou, Y.; He, C. Energy-efficient migration and consolidation algorithm of virtual machines in data centers for cloud computing. Computing 2016, 98, 303–317. [Google Scholar] [CrossRef]
- Beloglazov, A.; Buyya, R. Energy efficient allocation of virtual machines in cloud data centers. In Proceedings of the IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, Melbourne, Australia, 17–20 May 2010; pp. 577–578. [Google Scholar] [CrossRef]
- Borgetto, D.; Casanova, H.; DaCosta, G.; Pierson, J.M. Energy-aware service allocation. Future Gener. Comput. Syst. 2012, 28, 769–779. [Google Scholar] [CrossRef]
- Mastelic, T.; Oleksiak, A.; Claussen, H.; Brandic, I.; Pierson, J.M.; Vasilakos, A.V. Cloud computing: Survey on energy efficiency. ACM Comput. Surv. 2014, 47, 1–36. [Google Scholar] [CrossRef]
- Strunk, A.; Dargie, W. Does live migration of virtual machines cost energy? In Proceedings of the IEEE 27th International Conference on Advanced Information Networking and Applications (AINA), Barcelona, Spain, 25–28 March 2013; pp. 514–521. [Google Scholar] [CrossRef]
- Strunk, A. A light weight model for estimating energy cost of live migration of virtual machines. In Proceedings of the IEEE Sixth International Conference on Cloud Computing, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 510–517. [Google Scholar] [CrossRef]
- Ye, K.; Jiang, X.; Huang, D.; Chen, J.; Wang, B. Live migration of multiple virtual machines with resource reservation in cloud computing environments. In Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing, Washington, DC, USA, 4–9 July 2011; pp. 267–274. [Google Scholar] [CrossRef]
- Wu, C.M.; Chang, R.S.; Chan, H.Y. A green energy-efficient scheduling algorithm using the DVFS technique for cloud data centers. Future Gener. Comput. Syst. 2014, 37, 141–147. [Google Scholar] [CrossRef]
- Wu, G.; Tang, M.; Tian, Y.C.; Li, W. Energy-efficient virtual machine placement in data centers by genetic algorithm. In Proceedings of the 19th International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012; pp. 315–323. [Google Scholar] [CrossRef] [Green Version]
- Dong, J.; Jin, X.; Wang, H.; Li, Y.; Zhang, P.; Cheng, S. Energy-saving virtual machine placement in cloud data centers. In Proceedings of the 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing, Delft, The Netherlands, 13–16 May 2013; pp. 618–624. [Google Scholar] [CrossRef]
- Sun, M.; Gu, W.; Zhang, X.; Shi, H.; Zhang, W. A matrix transformation algorithm for virtual machine placement in cloud. In Proceedings of the 12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, Melbourne, Australia, 16–18 July 2013; pp. 1778–1783. [Google Scholar] [CrossRef]
- Pires, F.L.; Barán, B. A virtual machine placement taxonomy. In Proceedings of the 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Shenzhen, China, 4–7 May 2015; pp. 159–168. [Google Scholar] [CrossRef]
- Beloglazov, A.; Abawajy, J.; Buyya, R. Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing. Future Gener. Comput. Syst. 2012, 28, 755–768. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Qian, Z.; Lu, S.; Wu, J. Energy efficient virtual machine placement algorithm with balanced and improved resource utilization in a datacenter. Math. Comput. Model. 2013, 58, 1222–1235. [Google Scholar] [CrossRef]
- Tseng, F.H.; Wang, X.; Chou, L.D.; Chao, H.C.; Leung, V.C. Dynamic resource prediction and allocation for cloud data center using the multi objective genetic algorithm. IEEE Syst. J. 2017, 12, 1688–1699. [Google Scholar] [CrossRef]
- Alharbi, F.; Tian, Y.C.; Tang, M.; Zhang, W.Z.; Peng, C.; Fei, M. An ant colony system for energy-efficient dynamic virtual machine placement in data centers. Expert Syst. Appl. 2019, 120, 228–238. [Google Scholar] [CrossRef]
- Gu, L.; Zeng, D.; Barnawi, A.; Guo, S.; Stojmenovic, I. Optimal task placement with QoS constraints in geo-distributed data centers using DVFS. IEEE Trans. Comput. 2014, 64, 2049–2059. [Google Scholar] [CrossRef]
- Gu, L.; Zeng, D.; Guo, S. QoS-Aware Task Placement in Geo-distributed Data Centers with Low OPEX Using Dynamic Frequency Scaling. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013; pp. 80–84. [Google Scholar] [CrossRef]
- Le, K.; Bianchini, R.; Nguyen, T.D.; Bilgir, O.; Martonosi, M. Capping the brown energy consumption of internet services at low cost. In Proceedings of the International Conference on Green Computing, Chicago, IL, USA, 15–18 August 2010; pp. 3–14. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Wang, K.; Jia, W.; Guo, M. Reinforcement learning-based adaptive resource management of differentiated services in geo-distributed data centers. In Proceedings of the 2017 IEEE/ACM 25th International Symposium on Quality of Service (IWQoS), VilanovaIla Geltrú, Spain, 14–16 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Jonardi, E.; Oxley, M.A.; Pasricha, S.; Maciejewski, A.A.; Siegel, H.J. Energy cost optimization for geo graphically distributed heterogeneous data centers. In Proceedings of the 2015 Sixth International Green and Sustainable Computing Conference (IGSC), Las Vegas, NV, USA, 14–16 December 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Smart City Cluster Collaboration. Existing Data Centres Energy Metrics—Task1; Smart City Cluster Collaboration. 2014. Available online: http://www.dolfin-fp7.eu/wp-content/uploads/2014/01/Task-1-List-of-DC-Energy-Related-Metrics-Final.pdf (accessed on 9 December 2019).
- Hanson, H.; Keckler, S.W.; Ghiasi, S.; Rajamani, K.; Rawson, F.; Rubio, J. Thermal response to DVFS: Analysis with an Intel Pentium M. In Proceedings of the 2007 International Symposium on Low Power Electronics and Design (ISLPED’07), Portland, OR, USA, 27–29 August 2007; pp. 219–224. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, T.; Chen, M.; Wei, T.; Zhou, J.; Hu, S.; Buyya, R. Energy-aware virtual machine allocation for cloud with resource reservation. J. Syst. Softw. 2019, 147. [Google Scholar] [CrossRef]
- Mukherjee, T.; Tang, Q.; Ziesman, C.; Gupta, S.K.; Cayton, P. Software architecture for dynamic thermal management in data centers. In Proceedings of the 2007 2nd International Conference on Communication Systems Software and Middleware, Bangalore, India, 7–12 January 2007; pp. 1–11. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, Y.; Bash, C.; Wierman, A.; Gmach, D.; Wang, Z.; Marwah, M.; Hyser, C. Renewable and cooling aware work load management for sustainable data centers. In Proceedings of the ACMSIGMETRICS Performance Evaluation Review, London, UK, 11–15 June 2012; Volume 40, pp. 175–186. [Google Scholar] [CrossRef] [Green Version]
- Moore, J.D.; Chase, J.S.; Ranganathan, P.; Sharma, R.K. Making Scheduling “Cool”: Temperature-Aware Work load Placement in Data Centers. In Proceedings of the USENIX Annual Technical Conference, Marriott Anaheim, CA, USA, 10–15 April 2005; pp. 61–75. [Google Scholar]
- Wang, L.; Khan, S.U.; Dayal, J. Thermal aware work load placement with task-temperature profiles in a data center. J. Supercomput. 2012, 61, 780–803. [Google Scholar] [CrossRef]
- Standard Performance Evaluation Corporation. SPEC Power 2008; Standard Performance Evaluation Corporation: Gainesville, VA, USA, 2008; Available online: http://www.spec.org/power_ssj2008 (accessed on 9 December 2019).
- Sawyer, R. Calculating Total Power Requirements for Data Centers. White Paper, American Power Conversion. 2004. Available online: http://accessdc.net/Download/Access_PDFs/pdf1/Calculating%20Total%20Power%20Requirements%20for%20Data%20Centers.pdf (accessed on 9 December 2019).
- Available online: http://cloud.agroclimate.org/tools/deprecated/carbonFootprint/references/Electricity_emission_factor.pdf. (accessed on 2 February 2020).
- Beloglazov, A.; Buyya, R. Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers. Concurr. Comput. Pract. Exp. 2012, 24, 1397–1420. [Google Scholar] [CrossRef]
- Lublin, U.; Feitelson, D.G. The work load on parallel supercomputers: Modeling the characteristics ofrigid jobs. J. Parallel Distrib. Comput. 2003, 63, 1105–1122. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machines | Frequency(GHz) | No. of Cores | Power Model | Memory(GB) | Storage (GB) | Network Bandwidth (Mbps) |
|---|---|---|---|---|---|---|
| M1 | 2 | 2 | 1 | 16 | 2000 | 1000 |
| M2 | 4 | 4 | 1 | 32 | 6000 | 1000 |
| M3 | 4 | 8 | 2 | 32 | 7000 | 2000 |
| M4 | 8 | 8 | 2 | 64 | 7000 | 4000 |
| M5 | 16 | 8 | 2 | 128 | 9000 | 4000 |
| Power Model | Idle | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 60 | 63 | 66.8 | 71.3 | 76.8 | 83.2 | 90.7 | 100 | 111.5 | 125.4 | 140.7 |
| 2 | 41.6 | 46.7 | 52.3 | 57.9 | 65.4 | 73 | 80.7 | 89.5 | 99.6 | 105 | 113 |
| Name | ECU | Core Speed(GHz) | Memory(MB) | Storage(GB) | Network Band Width(Mbps) | Probability |
|---|---|---|---|---|---|---|
| M1.small | 1 | 1 | 1740 | 160 | 500 | 0.25-BT |
| M1.large | 2 | 4 | 7680 | 850 | 500 | 0.25-BT/0.12-WR |
| M1.xlarge | 4 | 8 | 15,360 | 1000 | 1000 | 0.08-WR |
| M2xlarge | 2 | 6.5 | 17,510 | 1000 | 1000 | 0.12-WR |
| M22.xlarge | 4 | 13 | 35,020 | 1000 | 1000 | 0.08-WR |
| C1.median | 2 | 5 | 1740 | 500 | 500 | 0.1-BT |
| Data Center | Carbon Footprint Rate (CFR) in Tons/MWh | PUE |
|---|---|---|
| DC1 | 0.124, 0.147 | 1.56 |
| DC2 | 0.350, 0.658 | 1.7 |
| DC3 | 0.466, 0.782 | 1.9 |
| DC4 | 0.678, 0.730 | 2.1 |
| Interval (300 s) | Active VMs | Power Consumption (kW) | Total Active PMs | Total CPU Utilization % | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C-PEF | C-PE | C-FFF | C-FFLE | C-FF | C-PEF | C-PE | C-FFF | C-FFLE | C-FF | |||
| 1 | 64 | 1512.53 | 1436.84 | 1626.45 | 2070.33 | 1954.24 | 50 | 36 | 56 | 60 | 56 | 10.94 |
| 2 | 123 | 2596.98 | 2624.79 | 2879.36 | 3624.09 | 3185.06 | 89 | 74 | 98 | 106 | 91 | 20.90 |
| 3 | 181 | 3646.54 | 4106.17 | 4003.47 | 5360.29 | 4935.64 | 111 | 116 | 123 | 151 | 136 | 29.34 |
| 4 | 237 | 4997.41 | 5505.73 | 5272.04 | 6951.47 | 6278.71 | 141 | 152 | 153 | 196 | 172 | 38.46 |
| 5 | 288 | 6228.52 | 6717.20 | 6270.41 | 8246.13 | 7189.17 | 175 | 186 | 175 | 231 | 199 | 47.02 |
| 6 | 334 | 7056.55 | 7453.36 | 7207.61 | 9257.91 | 8179.25 | 198 | 208 | 203 | 258 | 227 | 54.36 |
| 7 | 381 | 8010.12 | 8428.66 | 8295.90 | 10295.59 | 9043.74 | 227 | 238 | 238 | 289 | 252 | 63.09 |
| 8 | 420 | 8770.99 | 9264.71 | 8951.71 | 11077.27 | 9856.81 | 253 | 262 | 258 | 312 | 276 | 69.76 |
| Reservation Interval | Minimum CPU Utilization % | Number of Hosts with 100% CPU Utilization | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| C-PEF | C-PE | C-FFF | C-FFLE | C-FF | C-PEF | C-PE | C-FFF | C-FFLE | C-FF | |
| 1 | 40.625 | 50 | 25 | 50 | 50 | 17 | 23 | 17 | 35 | 33 |
| 2 | 31.25 | 62.5 | 25 | 50 | 62.5 | 19 | 42 | 27 | 62 | 56 |
| 3 | 40.625 | 50 | 40.625 | 62.5 | 62.5 | 56 | 75 | 64 | 96 | 91 |
| 4 | 62.5 | 62.5 | 40.625 | 50 | 62.5 | 91 | 101 | 94 | 127 | 118 |
| 5 | 62.5 | 50 | 50 | 50 | 62.5 | 113 | 121 | 117 | 152 | 138 |
| 6 | 50 | 40.625 | 40.625 | 62.5 | 62.5 | 125 | 146 | 135 | 173 | 159 |
| 7 | 62.5 | 62.5 | 40.625 | 50 | 40.625 | 142 | 162 | 153 | 188 | 172 |
| 8 | 31.25 | 62.5 | 31.25 | 40.625 | 62.5 | 156 | 176 | 164 | 204 | 189 |
| Placement Algorithm | Power (kW) | Carbon Footprint(Tons) | Number of VMs Placed |
|---|---|---|---|
| C-FFF | 676,296.2775 | 48.72382575 | 1634 |
| C-PE | 691,256.2894 | 49.87335009 | 1611 |
| C-PEF | 665,341.0031 | 48.28496006 | 1623 |
| C-FFLE | 782,225.6419 | 59.79732901 | 1622 |
| C-FF | 695,623.92 | 50.4902789 | 1598 |
| RVA% Under Different VM Requests | ||||||
|---|---|---|---|---|---|---|
| Algorithm | 481 | 910 | 1276 | 1591 | 1861 | 2000 |
| C-FFF | 100 | 88.68132 | 81.5047 | 81.58391 | 81.30038 | 81.7909 |
| C-PE | 100 | 87.03297 | 80.17241 | 80.32684 | 80.06448 | 80.5903 |
| C-PEF | 100 | 88.35165 | 81.03448 | 81.01823 | 80.65556 | 81.14057 |
| C-FFLE | 100 | 87.25275 | 80.721 | 81.26964 | 80.60183 | 81.14057 |
| C-FF | 100 | 87.03297 | 80.01567 | 80.01257 | 79.36593 | 79.93997 |
| C-FFF | C-PE | C-PEF | C-FFLE | C-FF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | % CPU Utilization | Power (kW) | % CPU Utilization | Power (kW) | % CPU Utilization | Power (kW) | % CPU Utilization | Power (kW) | % CPU Utilization | Power (kW) | |
| Min | 0.1471 | 1626 | 0.1471 | 1437 | 0.1471 | 1513 | 0.1471 | 2070 | 0.1471 | 1954 | |
| Max | 89.12 | 6.76 × 105 | 90.04 | 6.91 × 105 5 | 88.38 | 6.65 × 105 | 92.46 | 7.82 × 105 | 89.87 | 6.96 × 105 | |
| Mean | 48.6 | 4.49 × 105 | 48.91 | 4.58 × 105 | 47.82 | 4.42 × 105 | 50.46 | 5.17 × 105 | 48.97 | 4.64 × 105 | |
| Placement Algorithm | Power(kW) | Carbon Footprint (Tons) | Number of VMs Placed |
|---|---|---|---|
| C-PEF | 564,350.9 | 23.631227 | 1617 |
| C-PE | 628,328.4 | 24.191322 | 1636 |
| C-FFF | 582,335.1 | 24.35445 | 1641 |
| RVA% with Different VM Requests | ||||||
|---|---|---|---|---|---|---|
| Algorithm | 481 | 910 | 1276 | 1591 | 1861 | 2000 |
| C-PEF | 98.96 | 87.14 | 81.42 | 80.95 | 80.65 | 80.89 |
| C-PE | 100 | 88.4 | 81.97 | 82.08 | 81.67 | 82.09 |
| C-FFF | 99.37 | 88.69 | 82.66 | 83.58 | 82.3 | 82.84 |
| C-FFF | C-PE | C-PEF | ||||
|---|---|---|---|---|---|---|
| Metric | %CPU Utilization | Power (kW) | %CPU Utilization | Power (kW) | %CPU Utilization | Power (kW) |
| Min | 0.1471 | 1029 | 0.1471 | 644.5 | 0.1471 | 969 |
| Max | 88.94 | 5.823 × 105 | 89.67 | 6.283 × 105 | 86.69 | 5.644 × 105 |
| Mean | 48.33 | 3.854 × 105 | 48.48 | 4.156 × 105 | 46.25 | 3.74 × 105 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Renugadevi, T.; Geetha, K.; Prabaharan, N.; Siano, P. Carbon-Efficient Virtual Machine Placement Based on Dynamic Voltage Frequency Scaling in Geo-Distributed Cloud Data Centers. Appl. Sci. 2020, 10, 2701. https://doi.org/10.3390/app10082701
Renugadevi T, Geetha K, Prabaharan N, Siano P. Carbon-Efficient Virtual Machine Placement Based on Dynamic Voltage Frequency Scaling in Geo-Distributed Cloud Data Centers. Applied Sciences. 2020; 10(8):2701. https://doi.org/10.3390/app10082701
Chicago/Turabian StyleRenugadevi, T., K. Geetha, Natarajan Prabaharan, and Pierluigi Siano. 2020. "Carbon-Efficient Virtual Machine Placement Based on Dynamic Voltage Frequency Scaling in Geo-Distributed Cloud Data Centers" Applied Sciences 10, no. 8: 2701. https://doi.org/10.3390/app10082701