An Unsupervised Deep Learning System for Acoustic Scene Analysis


Abstract
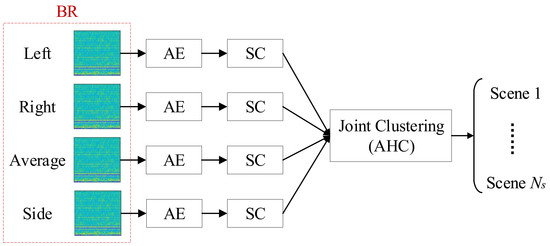
:
1. Introduction
- The auto-encoder network extracts bottleneck features in an unsupervised way for a compact audio representation;
- The binaural representation is applied to utilize the spatial information of stereo audio for the unsupervised acoustic scene analysis;
- A joint clustering algorithm with the binaural representation is proposed for multi-channel audio data.
2. The Proposed Method
2.1. Binaural Representation
2.2. Auto-Encoder Network
2.3. Spectral Clustering
2.4. Joint Clustering
3. Experiments
3.1. Datasets
3.2. Comparison Methods and Parameter Setting
3.3. Evaluation Criteria
3.4. Main Results
3.5. Effect of the Dimension of Bottleneck Feature
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Barchiesi, D.; Giannoulis, D.; Stowell, D.; Plumbley, M.D. Acoustic scene classification: Classifying environments from the sounds they produce. IEEE Signal Process. Mag. 2015, 32, 16–34. [Google Scholar] [CrossRef]
- Green, M.C.; Murphy, D. EigenScape: A Database of Spatial Acoustic Scene Recordings. Appl. Sci. 2017, 7, 1204. [Google Scholar] [CrossRef] [Green Version]
- Ye, J.; Kobayashi, T.; Toyama, N.; Tsuda, H.; Murakawa, M. Acoustic Scene Classification Using Efficient Summary Statistics and Multiple Spectro-Temporal Descriptor Fusion. Appl. Sci. 2018, 8, 1263. [Google Scholar] [CrossRef] [Green Version]
- Battaglino, D.; Lepauloux, L.; Pilati, L.; Evans, N. Acoustic context recognition using local binary pattern codebooks. In Proceedings of the 2015 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 18–21 October 2015. [Google Scholar]
- Rakotomamonjy, A.; Gasso, G. Histogram of gradients of time-frequency representations for audio scene classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 142–153. [Google Scholar]
- Park, S.; Mun, S.; Lee, Y.; Ko, H. Score Fusion of Classification Systems for Acoustic Scene Classification; Tech. Rep.; DCASE2016 Challenge: Budapest, Hungary, 2016. [Google Scholar]
- Han, Y.; Park, J. Convolutional Neural Networks with Binaural Representations and Background Subtraction for Acoustic Scene Classification; Tech. Rep.; DCASE2017 Challenge: Munich, Germany, 2017. [Google Scholar]
- Chen, H.; Liu, Z.; Liu, Z.; Zhang, P.; Yan, Y. Integrating the Data Augmentation Scheme with Various Classifiers for Acoustic Scene Modeling; Tech. Rep.; DCASE2019 Challenge: Tokyo, Japan, 2019. [Google Scholar]
- Li, S.; Gu, Y.; Luo, Y.; Chambers, J.; Wang, W. Enhanced streaming based subspace clustering applied to acoustic scene data clustering. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Misra, D.; Dilokthanakul, N.; Mediano, P.; Garnelo, M.; Lee, M.; Salimbeni, H.; Arulkumaran, K.; Shanahan, M. Deep unsupervised clustering with Gaussian mixture variational autoencoders. arXiv 2016, arXiv:1611.02648. [Google Scholar]
- Smieja, M.; Wolczyk, M.; Tabor, J.; Geiger, B. SeGMA: Semi-Supervised Gaussian Mixture Auto-Encoder. arXiv 2019, arXiv:1906.09333v1. [Google Scholar]
- Xue, J.; Wichern, G.; Thornburg, H.; Spanias, A. Fast query by example of environmental sounds via robust and efficient cluster-based indexing. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Las Vegas, NV, USA, 31 March–4 April 2008. [Google Scholar]
- Cai, R.; Lu, L.; Hanjalic, A. Co-clustering for auditory scene categorization. IEEE Trans. Multimed. 2008, 10, 596–606. [Google Scholar] [CrossRef] [Green Version]
- Rychtrikov, M.; Vermeir, G. Acoustical categorization of urban public places by clustering method. In Proceedings of the International Conference on Acoustics NAG/DAGA, Rotterdam, The Netherlands, 23–26 March 2009. [Google Scholar]
- Li, S.; Wang, W. Randomly sketched sparse subspace clustering for acoustic scene clustering. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018. [Google Scholar]
- Eghbal, H.; Lehner, B.; Widmer, G. A hybrid approach with multi-channel i-vectors and convolutional neural networks for acoustic scene classification. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, D.; Seltzer, M.L. Improved bottleneck features using pretrained deep neural networks. In Proceedings of the INTERSPEECH-2011, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Ng, A.; Jordan, I.M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems; Dietterich, T.G., Becker, S., Ghahramani, Z., Eds.; MIT Press: Cambridge, MA, USA, 2002; pp. 849–856. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. TUT database for acoustic scene classification and sound event detection. In Proceedings of the 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016. [Google Scholar]
- Strehl, A.; Ghosh, J. Cluster ensembles—A knowledge reuse framework for combining multiple partitions. J. Mach. Learn. Res. 2003, 3, 583–617. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: Original Features-576 | |
|---|---|
| Encoder | Dense-500-BN-Mish |
| Dense-500-BN-Mish | |
| Dense-40-Sigmoid | |
| Decoder | Dense-500-BN-Mish |
| Dense-500-BN-Mish | |
| Dense-576 | |
| Output: Reconstructed features | |
| Methods | SSC [15] | OLRSC [9] | MAESC (Ours) | JOLRSC [9] | JAESC (Ours) |
|---|---|---|---|---|---|
| ACC (%) | 25.31 | 43.64 | 45.60 | 45.84 | 49.47 |
| Left | Right | Average | Side | JAESC | |
|---|---|---|---|---|---|
| ACC (%) | 42.95 | 41.09 | 45.60 | 43.59 | 49.47 |
| NMI (%) | 45.13 | 46.00 | 48.01 | 45.40 | 53.20 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Zhang, X.-L.; Rahardja, S. An Unsupervised Deep Learning System for Acoustic Scene Analysis. Appl. Sci. 2020, 10, 2076. https://doi.org/10.3390/app10062076
Wang M, Zhang X-L, Rahardja S. An Unsupervised Deep Learning System for Acoustic Scene Analysis. Applied Sciences. 2020; 10(6):2076. https://doi.org/10.3390/app10062076
Chicago/Turabian StyleWang, Mou, Xiao-Lei Zhang, and Susanto Rahardja. 2020. "An Unsupervised Deep Learning System for Acoustic Scene Analysis" Applied Sciences 10, no. 6: 2076. https://doi.org/10.3390/app10062076