A Novel Approach for Software Defect prediction Based on the Power Law Function

Abstract
:1. Introduction
2. Fundamental Characteristics of Power Law Function and Software Defects
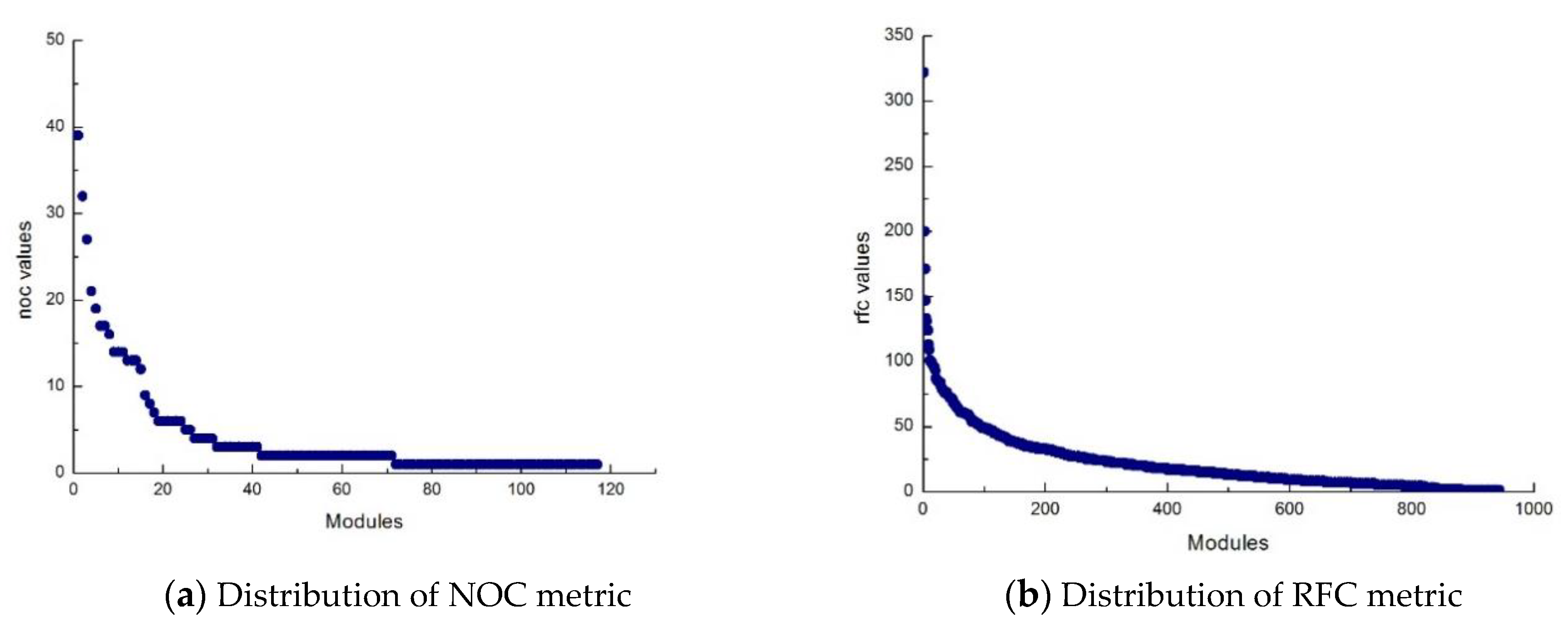
2.1. Correlation and Characteristics
2.2. Power Law Function Curvature
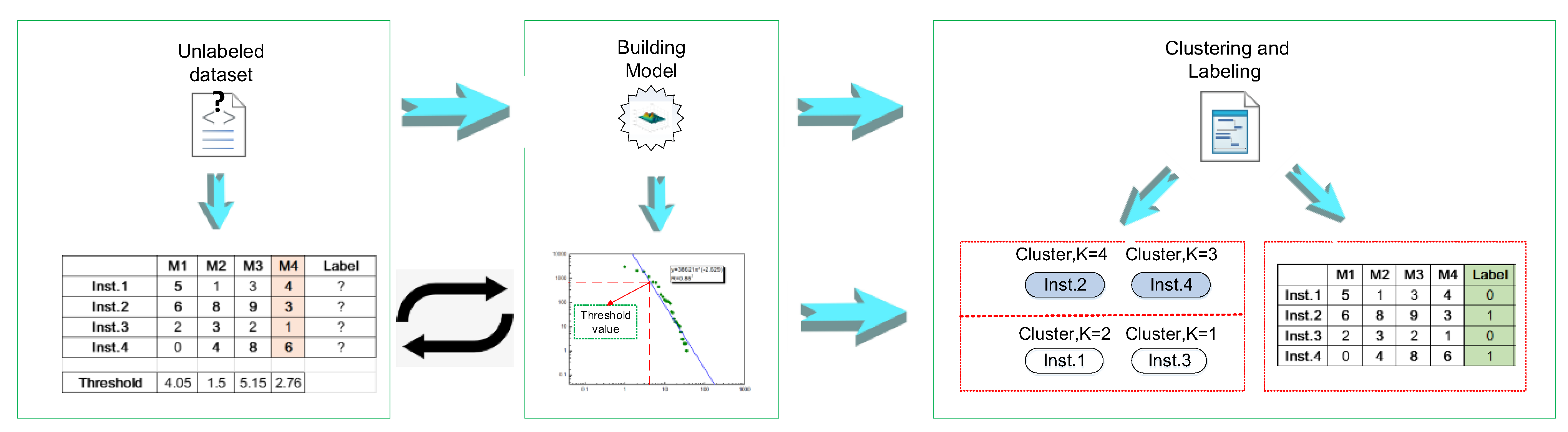
2.3. Approach for Software Defect Prediction Based on Power Law Function
| Algorithm 1. Software defect prediction based on power-law function |
| Input |
| D ← Original unlabeled datasets |
| Inst. ← Instances in datasets |
| M ← Each metric in dataset D |
| MV ← Each value of the metric in dataset D |
| 1 for M in All M do |
| 2 for i = 1 to number of M do |
| 3 Building power-law function for each M |
| 4 According to Equation (14), |
| compute transformation value in maximal curvature point T |
| 5 if MVi. Insti > T |
| 6 MVi. Insti is higher value, MVi. Insti = 1 |
| 7 else |
| 8 MVi. Insti is normal value, MVi. Insti = 0 |
| 9 end if |
| 10 end for |
| 11 for each Insti in Inst. |
| 12 Calculate the total number K of each Insti in the D with MVi. Insti = 1 |
| 13 Sort values of K, clustering into two groups, a top half and a bottom half. |
| 14 for i = 1 to number of Inst. do |
| 15 compare each K value in Inst. |
| 16 if K values in top half |
| 17 Inst.i is defect-proneness |
| 18 else |
| 19 Inst.i is defect-free tendency |
| 20 end if |
| 21 end for |
| Output |
| Dataset with defect label |
3. Experimental
3.1. Case Study
3.2. Performance Evaluation
3.3. Comparative Experiment
4. Complexity Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
| Metrics | Description |
| wmc | Weighted methods per class |
| dit | The maximum distance from a given class to the root of an inheritance tree |
| noc | Number of children of a given class in an inheritance tree |
| cbo | Number of classes that are coupled to a given class |
| rfc | Number of distinct methods invoked by code in a given class |
| lcom | Number of method pairs in a class that do not share access to any class attributes |
| ca | Afferent coupling, which measures the number of classes that depend on a given class |
| ce | Efferent coupling, which measures the number of classes that a given class depends on |
| npm | Number of public methods in a given class |
| lcom3 | Another type of the lcom metric proposed by Henderson–Sellers |
| loc | Number of lines of code in a given class |
| dam | The ratio of the number of private/protected attributes to the total number of attributes in a given class |
| moa | Number of attributes in a given class that are of user-defined types |
| mfa | Number of methods inherited by a given class divided by the total number of methods that can be accessed by the member methods of the given class |
| cam | The ratio of the sum of the number of different parameter types of every method in a given class to the product of the number of methods in the given class and the number of different method parameter types in the whole class |
| ic | Number of parent classes that a given class is coupled to |
| cbm | Total number of new or overwritten methods that all inherited methods in a given class are coupled to |
| amc | The average size of methods in a given class |
| max_cc | The maximum McCabe’s cyclomatic complexity (CC) score of methods in a given class |
| avg_cc | The arithmetic mean of McCabe’s cyclomatic complexity (CC) scores of methods in a given class |
References
- Ekanayake, J.; Tappolet, J.; Gall, H.C.; Bernstein, A. Tracking concept drift of software projects using defect prediction quality. In Proceedings of the 6th International Working Conference on Mining Software Repositories, MSR 2009 (Co-located with ICSE), Vancouver, BC, Canada, 16–17 May 2009. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Lessmann, S.; Baesens, B. Evaluating software defect prediction performance: An Updated Benchmarking Study. SSRN Electron. J. 2019, arXiv:1901.01726. [Google Scholar] [CrossRef] [Green Version]
- Balogun, A.O.; Basri, S.; Abdulkadir, S.J.; Hashim, A.S. Performance Analysis of Feature Selection Methods in Software Defect Prediction: A Search Method Approach. Appl. Sci. 2019, 9, 2764. [Google Scholar] [CrossRef] [Green Version]
- Nam, J.; Kim, S. CLAMI: Defect prediction on unlabeled datasets (T). In Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 452–463. [Google Scholar] [CrossRef]
- Zimmermann, T.; Nagappan, N.; Gall, H.; Giger, E.; Murphy, B. Cross-project defect prediction: A large scale experiment on data vs. domain vs. process. In Proceedings of the Joint Meeting of the European Software Engineering Conference on the Foundations of Software Engineering, Amsterdam, The Netherland, 24–28 August 2009; pp. 91–100. [Google Scholar]
- Chen, X.; Wang, L.P.; Gu, Q.; Wang, Z.; Ni, C.; Liu, W.S.; Wang, Q.P. A survey on cross-project software defect prediction methods. Chin. J. Comput. 2018, 41, 254–274. [Google Scholar] [CrossRef]
- Qiu, S.; Lu, L.; Jiang, S.; Guo, Y. An investigation of imbalanced ensemble learning methods for cross-project defect prediction. Int. J. Pattern Recogn. 2019. [Google Scholar] [CrossRef]
- Mao, F.G.; Li, B.W.; Shen, B.J. Cross-project software defect prediction based on instance transfer. J. Comput. Sci. Tech.-Ch. 2016, 10, 43–55. [Google Scholar] [CrossRef]
- Jureczko, M.; Nguyen, N.T.; Szymczyk, M.; Unold, O. Towards implementing defect prediction in the software development process. J. Intell. Fuzzy Syst. 2019, in press. [Google Scholar] [CrossRef]
- Malhotra, R.; Khanna, M. Prediction of change prone classes using evolution-based and object-oriented metrics. J. Intell. Fuzzy Syst. 2018, 34, 1755–1766. [Google Scholar] [CrossRef]
- Catal, C.U.; Sevim, U.; Diri, B. Clustering and metrics thresholds based software fault prediction of unlabeled program modules. In Proceedings of the 6th International Conference on Information Technology: New Generations, Las Vegas, NV, USA, 27–29 April 2009; pp. 199–204. [Google Scholar] [CrossRef]
- Catal, C.; Sevim, U.; Diri, B. Software fault prediction of unlabeled program modules. Lect. Notes Eng. Comput. Sci. 2009, 2176, 199–204. [Google Scholar] [CrossRef]
- Abaei, G.; Rezaei, Z.; Selamat, A. Fault prediction by utilizing self-organizing map and threshold. In Proceedings of the 2013 IEEE International Conference on control system, Mindeb, Malaysia, 29 November–1 December 2013; pp. 465–470. [Google Scholar] [CrossRef]
- Yang, B.; Yin, Q.; Xu, S.; Guo, P. Software quality prediction using affinity propagation algorithm. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 2161–4393. [Google Scholar] [CrossRef]
- Bishnu, P.S.; Bhattacherjee, V. Application of k-medoids with kd-tree for software fault prediction. ACM Sigsoft Softw. Eng. Notes 2011, 36, 1–6. [Google Scholar] [CrossRef]
- Bishnu, P.S.; Bhattacherjee, V. Software fault prediction using quad tree-based k-means clustering algorithm. IEEE Trans. Knowl. Data Eng. 2012, 24, 1146–1150. [Google Scholar] [CrossRef]
- Zhong, S.; Khoshgoftaar, T.M.; Seliya, N. Unsupervised learning for expert-based software quality estimation. IEEE Int. Symp. High Assur Syst. Eng. 2004, 149–155. [Google Scholar] [CrossRef]
- Park, M.; Hong, E. Software fault prediction model using clustering algorithms determining the number of clusters automatically. Int. J. Softw. Eng. Appl. 2014, 8, 199–204. [Google Scholar]
- Lu, Z.F. Software Defect Prediction Research for Unlabeled Datasets. Master’s Thesis, Chongqing University, Chongqing, China, 2016. [Google Scholar]
- Newman, M.E.J. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar] [CrossRef] [Green Version]
- Adamic, L.A.; Huberman, B.A.; Barabási, A.L.; Albert, R.; Jeong, H.; Bianconi, G. Power-law distribution of the world wide web. Science 2000, 287, 2115. [Google Scholar] [CrossRef] [Green Version]
- Levy, M.; Solomon, S. New evidence for the power-law distribution of wealth. Physica A 1997, 242, 90–94. [Google Scholar] [CrossRef]
- Pareto, V. The new theories of economics. J. Political Econ. 1897, 5, 485–502. [Google Scholar] [CrossRef]
- Gabriel, S.B.; Feynman, J. Power-law distribution for solar energetic proton events. Sol. Phys. 1996, 165, 337–346. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Han, T.L.; Lang, B.H.; Li, Y.; Lai, F.W. Detection and extraction of shockwave signal in noisy environments. J. Intell. Fuzzy Syst. 2019, in press. [Google Scholar] [CrossRef]
- Bredenoord, A.J.; Smout, A.J.P.M. Oesophageal pH has a power-law distribution in control and gastro-oesophageal reflux disease subjects. Alimen. Pharm. Ther. 2005, 21, 917. [Google Scholar] [CrossRef]
- Zhang, S.Z.; Wei, Y.D.; Liang, X. Research on power-law distribution and identification of Kinship in mobile social network. J. Chin. Inf. Process. 2018, 32, 14–122. [Google Scholar]
- Jiang, B.; Yang, C.; Wang, L.; Li, R.G. Mining multiplex power-law distributions and retweeting patterns on twitter. J. Intell. Fuzzy Syst. 2016, 31, 1009–1016. [Google Scholar] [CrossRef]
- Louridas, P.; Spinellis, D.; Vlachos, V. Power laws in software. ACM Trans. on Softw. Eng. Methodol. 2008, 18, 1–26. [Google Scholar] [CrossRef]
- Concas, G.; Marchesi, M.; Pinna, S.; Serra, N. Power-laws in a large object-oriented software system. IEEE Trans. Softw. Eng. 2007, 33, 687–708. [Google Scholar] [CrossRef]
- Hatton, L. Power-law distributions of component size in general software systems. IEEE Trans. Softw. Eng. 2009, 35, 566–572. [Google Scholar] [CrossRef]
- Shatnawi, R.; Althebyan, Q. An empirical study of the effect of power law distribution on the interpretation of OO metrics. Isrn Softw. Eng. 2013, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Wheeldon, R.; Counsell, S. Power law distributions in class relationships. In Proceedings of the IEEE International Workshop on Source Code Analysis and Manipulation, Amsterdam, The Netherlands, 26–27 September 2003; pp. 45–54. [Google Scholar] [CrossRef] [Green Version]
- Andersson, C.; Runeson, P. A replicated quantitative analysis of fault distributions in complex software systems. IEEE Trans. Softw. Eng. 2007, 33, 273–286. [Google Scholar] [CrossRef]
- Mitzenmacher, M. A brief history of generative models for power law and lognormal distributions. Internet Mathematics. 2004, 1, 226–251. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A.; Shalizi, C.R.; Newman, M.E.J. Power-law distributions in empirical data. Siam Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Pan, W.W.; Zhu, S.Z.; Yin, H.Y. An improved semi-supervised learning method for software defect prediction. J. Intell. Fuzzy Syst. 2014, 27, 2473–2480. [Google Scholar] [CrossRef]
- Xiao, X.H.; Yu, M. Advanced Mathematics, 5th ed.; Higher Education Press: Beijing, China, 2006; pp. 167–170. [Google Scholar]
- Zhang, F.; Zheng, Q.; Zou, Y.; Hassan, A.E. Cross-project defect prediction using a connectivity-based unsupervised classifier. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 14–22 May 2016; pp. 309–320. [Google Scholar] [CrossRef]
- Ambros, M.D.; Lanza, M.; Robbes, R. Evaluating defect prediction approaches: A benchmark and an extensive comparison. Empir. Softw. Eng. 2012, 17, 531–577. [Google Scholar] [CrossRef]
- Gaffney, J.E. Estimating the number of faults in code. IEEE Trans. Softw. Eng. 1984, 10, 459–464. [Google Scholar] [CrossRef]
- Hassan, A.E. Predicting faults using the complexity of code changes. In Proceeding of the 2009 IEEE 31st International Conference on Software Engineering, Vancouver, BC, Canada, 16–24 May 2009; pp. 78–88. [Google Scholar] [CrossRef]
- Jureczko, M.; Madeyski, L. Towards identifying software project clusters with regard to defect prediction. In Proceedings of the 6th International Conference on Predictive Models in Software Engineering, Promise 2010, Timisoara, Romania, 12–13 September 2010. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Cukic, B.; Ma, Y. Techniques for evaluating fault prediction models. Empir. Softw. Eng. 2008, 13, 561–595. [Google Scholar] [CrossRef]
- Wu, R.; Zhang, H.; Kim, S.; Cheung, S.C. ReLink: Recovering links between bugs and changes. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; pp. 15–25. [Google Scholar] [CrossRef]
- Menzies, T.; Dekhtyar, A.; Distefano, J.; Greenwald, J. Problems with precision: A response to comments on data mining static code attributes to learn defect predictors. IEEE Trans. Softw. Eng. 2007, 33, 637–640. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Power Law Function | Correlation Coefficient | Transformation Value |
|---|---|---|---|
| wmc | 1013.8 | 0.8466 | 41.31 |
| dit | 34.841 | 0.7909 | 13.51 |
| noc | 110.68 | 0.9479 | 10.30 |
| cbo | 915.03 | 0.854 | 45.82 |
| rfc | 4273 | 0.7247 | 66.07 |
| lcom | 34730 | 0.8994 | 58.94 |
| ca | 834.42 | 0.9684 | 27.93 |
| ce | 554.53 | 0.7765 | 35.63 |
| npm | 994.19 | 0.8752 | 36.86 |
| lcom3 | 19.53 | 0.5518 | 9.19 |
| loc | 129509 | 0.6554 | 120.88 |
| dam | 1.3429 | 0.0434 | 1.56 |
| moa | 23.007 | 0.8905 | 9.44 |
| mfa | 2.327 | 0.2977 | 2.73 |
| cam | 6.9114 | 0.6928 | 4.91 |
| ic | 3.5344 | 0.7184 | 3.80 |
| cbm | 68.343 | 0.9308 | 12.73 |
| amc | 463.68 | 0.8869 | 47.49 |
| max_cc | 108.78 | 0.9187 | 18.20 |
| avg_cc | 11.099 | 0.8648 | 7.21 |
| Actual | Predicted | |
|---|---|---|
| True | False | |
| True | TP (true positive) | FN (false negative) |
| False | FP (false positive) | TN (true negative) |
| Group | Dataset | # of instances | # of Metrics | |
|---|---|---|---|---|
| All | Buggy (%) | |||
| Promise | Camel1.6 | 965 | 188 (19.48%) | 20 |
| Forrest-0.8 | 32 | 2 (6.25%) | ||
| Synapse-1.0 | 157 | 16 (10.19%) | ||
| Berek | 43 | 16 (37.21%) | ||
| Intercafe | 27 | 4 (14.81%) | ||
| Termo | 42 | 13 (30.95%) | ||
| Pbean2 | 51 | 10 (19.61%) | ||
| SoftLab | ar1 | 121 | 9 (7.44%) | 29 |
| ar4 | 107 | 20 (18.69%) | ||
| ar5 | 36 | 8 (22.22%) | ||
| ReLink | Apache | 194 | 98 (50.52%) | 26 |
| Safe | 56 | 22 (39.29%) | ||
| Datasets | Methods | ||||
|---|---|---|---|---|---|
| K-Means | CLA | CLAMI | X-Means | Power Law Function Approach | |
| Camel1.6 | 0.146 | 0.247 | 0.247 | 0.256 | 0.276 |
| Forrest-0.8 | 0.040 | 0.076 | 0.070 | 0.071 | 0.125 |
| Synapse-1.0 | 0.033 | 0.189 | 0.029 | 0.034 | 0.194 |
| Berek | 1.000 | 0.636 | 0.632 | 0.385 | 0.778 |
| Intercafe | - | 0.230 | 0.230 | 0.111 | 0.231 |
| Termo | 0.400 | 0.467 | 0.500 | 0.421 | 0.571 |
| Pbeans2 | 0.276 | 0.375 | 0.308 | 0.276 | 0.364 |
| ar1 | 0.138 | 0.115 | 0.107 | 0.250 | 0.119 |
| ar4 | 0.333 | 0.340 | 0.307 | 0.600 | 0.333 |
| ar5 | 0.636 | 0.470 | 0.444 | 0.630 | 0.444 |
| Apache | 0.714 | 0.726 | 0.737 | 0.625 | 0.737 |
| Safe | 0.733 | 0.640 | 0.630 | 0.650 | 0.607 |
| Average | 0.404 | 0.376 | 0.353 | 0.359 | 0.398 |
| Datasets | Methods | ||||
|---|---|---|---|---|---|
| K-Means | CLA | CLAMI | X-Means | Power Law Function Approach | |
| Camel1.6 | 0.282 | 0.521 | 0.622 | 0.335 | 0.500 |
| Forrest-0.8 | 0.500 | 0.500 | 0.500 | 0.500 | 1.000 |
| Synapse-1.0 | 0.063 | 0.438 | 0.063 | 0.063 | 0.875 |
| Berek | 0.250 | 0.875 | 0.750 | 0.313 | 0.875 |
| Intercafe | -- | 0.750 | 0.750 | 0.250 | 0.750 |
| Termo | 0.615 | 0.538 | 0.692 | 0.615 | 0.615 |
| Pbeans2 | 0.800 | 0.600 | 0.400 | 0.800 | 0.800 |
| ar1 | 0.667 | 0.667 | 0.667 | 0.600 | 0.778 |
| ar4 | 0.800 | 0.800 | 0.800 | 0.150 | 0.800 |
| ar5 | 0.875 | 1.000 | 1.000 | 0.900 | 1.000 |
| Apache | 0.276 | 0.704 | 0.714 | 0.459 | 0.714 |
| Safe | 0.500 | 0.727 | 0.773 | 0.591 | 0.773 |
| Average | 0.512 | 0.677 | 0.644 | 0.465 | 0.790 |
| Datasets | Methods | ||||
|---|---|---|---|---|---|
| K-Means | CLA | CLAMI | X-Means | Power law Function Approach | |
| Camel1.6 | 0.192 | 0.336 | 0.353 | 0.290 | 0.355 |
| Forrest-0.8 | 0.074 | 0.133 | 0.125 | 0.125 | 0.222 |
| Synapse-1.0 | 0.043 | 0.264 | 0.040 | 0.044 | 0.318 |
| Berek | 0.400 | 0.737 | 0.686 | 0.345 | 0.824 |
| Intercafe | - | 0.375 | 0.353 | 0.154 | 0.353 |
| Termo | 0.485 | 0.500 | 0.581 | 0.500 | 0.593 |
| Pbeans2 | 0.410 | 0.462 | 0.348 | 0.410 | 0.500 |
| ar1 | 0.229 | 0.197 | 0.185 | 0.353 | 0.206 |
| ar4 | 0.471 | 0.478 | 0.444 | 0.240 | 0.471 |
| ar5 | 0.737 | 0.640 | 0.615 | 0.740 | 0.615 |
| Apache | 0.409 | 0.715 | 0.725 | 0.529 | 0.725 |
| Safe | 0.595 | 0.681 | 0.694 | 0.619 | 0.680 |
| Average | 0.385 | 0.471 | 0.436 | 0.369 | 0.501 |
| Method | K-Means | CLA | CLAMI | X-means | Power-Law Function Approach |
|---|---|---|---|---|---|
| Complexity | - |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, J.; Liu, F. A Novel Approach for Software Defect prediction Based on the Power Law Function. Appl. Sci. 2020, 10, 1892. https://doi.org/10.3390/app10051892
Ren J, Liu F. A Novel Approach for Software Defect prediction Based on the Power Law Function. Applied Sciences. 2020; 10(5):1892. https://doi.org/10.3390/app10051892
Chicago/Turabian StyleRen, Junhua, and Feng Liu. 2020. "A Novel Approach for Software Defect prediction Based on the Power Law Function" Applied Sciences 10, no. 5: 1892. https://doi.org/10.3390/app10051892