1. Introduction
According to Willingham [
1], people are normally curious but are not naturally acceptable masterminds; unless cognitive conditions are adequate, humans abstain from reasoning. This behavior is attributed to three properties. To begin with, reasoning is used with moderation; human’s visual system is proficient to instantly take in a complex scene, although it is not inclined to instantly solve a puzzle. Additionally, reasoning is tiresome because it requires focus and concentration. Finally, because we ordinarily make mistakes, reasoning is uncertain. In spite of these aspects, humans like to think. Solving problems produces pleasure because there is an overlap between the brain’s areas and chemicals that are important in learning and those related to the brain’s natural reward system [
1]. Thus, adjusting a student’s cognitive style might help to improve the student’s reasoning capacity.
Moreover, according to Felder and Silverman [
2], learning styles (a part of cognitive styles) describe students’ preferences on how some subject is presented, how to work with that subject matter, and how to internalize (acquire, process, and store) information [
2]. According to Willingham [
1], students may have diverse preferences on how to learn. Thus, knowing a student’s learning style can help in finding the most suitable way to improve the learning process. There are some studies which show that learning styles allow adaptive e-learning systems to improve the learning processes of students [
3,
4,
5,
6,
7].
We characterize learning as the procedure through which information is encoded and stored in the long-term memory. For instance, customizing content to the learning styles of students is seen as useful to learning in different ways, for example, improving fulfillment, increasing learning results, and decreasing learning time [
3]. Several research works in learning systems proposed that students’ learning improved when the instructor’s teaching style matched the learning style of the students [
5].
According to Bernard et al. [
5], there are several methods to classify learning styles. One of the most known is the Felder–Silverman learning styles model (FSLSM). This model proposes four dimensions to classify learning styles, with each dimension classified in an interval ranging from 0 to 11. The first dimension of this model is active/reflective, which determines if someone prefers first experimenting with some subject and then reasoning about it (active) or reasoning first and then experimenting on the subject (reflective). The second dimension is sensing/intuitive, which determines if someone prefers touching things to learn (sensing) or observing things to induce information (intuitive). The third dimension, visual/verbal, determines if someone prefers to see charts, tables, and figures (visual) instead of reading or listening to texts (verbal), or the contrary. Finally, the sequential/global dimension determines if someone prefers to get information in a successive manner, learning step-by-step (sequential), or to get an outline of the information first and go into detail afterwards, without a predefined sequence (global).
According to Willingham [
1], the prediction of any learning styles theory is that a particular teaching method might be good for some students but not so good for others. Therefore, it is possible to take advantage of different types of learning. It is important to understand the difference between learning ability and learning style. Learning ability is the capacity for or success in certain types of thought (math, for example). In contrast to ability, learning style is the tendency to think in a particular way, for example, thinking sequentially or holistically, which is independent of context [
1]. There is an enormous contrast between the popularity of learning styles in education and evidence of their usefulness. According to Pashler [
4], the reasonable utility of using learning styles to improve student learning still needs to be demonstrated. However, in their study, Kolb and Kolb [
6] examined recent research advancements in experimental learning in higher education and analyzed how it can improve students’ learning. In their studies they concluded that learning styles can be based on research and clinical observation of learning styles’ score patterns and applied throughout the educational environment through an institutional development program.
As indicated by Willingham [
1], psychologists have made a few approaches to test this learning proposition, leading to some hypotheses. First, learning style is considered as stable within an individual. In other words, if a student has a particular learning style, that style ought to be a stable part of that student’s cognitive makeup. Second, learning style ought to be consequential; therefore, using a specific learning style should have implications on the outcomes of the student’s learning. Thus, learning styles theory must have the following three features: (1) a specific learning style should be a stable characteristic of a person; (2) individuals with different styles should think and learn differently; and (3) individuals with different styles do not, on average, differ in their ability. Traditionally, learning styles are mainly measured through surveys and questionnaires, where students are asked to self-evaluate their own behaviors. However, this approach presents some problems. First, external interference can disturb the results during its application. Second, the outcomes are influenced by the quality of the survey or questionnaire. Finally, different students may interpret questions in different ways [
5].
According to Bernard et al. [
4], the characterization of learning styles is a problem that deals with many descriptors and many outputs. The descriptors may arise from many sources, such as logs, questionnaires, and databases. Moreover, the descriptors are usually associated with learning objects, such as forums, contents, outlines, quizzes, self-assignments, examples, and other types of resources. The outputs are used to permit the comprehension of learning style resulting from a combination of descriptors, which may indicate whether a student can be classified as active/reflective, sensing/intuitive, visual/verbal, or sequential/global, based on his/her approach to recognize, process, and store information. This problem is relevant because it is the first step to understand the cognitive condition to improve learning using e-learning systems [
5].
In this context, our research aims to investigate the use of computational intelligence (CI) algorithms to analyze and improve the accuracy of autonomic approaches to identify learning style. Our hypothesis is that if the learning style can be correctly identified using CI then the student’s learning preference may also be predicted. Thus, we conducted this research to identify features that may represent a student’s learning style based on massive information (big data) collected in a massive open online course (MOOC) environment and use these features to classify these learning styles. We also investigate whether a theory of learning style might be more suited to classification than others. Finally, we investigate algorithms to overcome limitations found in contemporary works.
This paper is organized as follows: This first section presents basic considerations and justifications for this work and defines its main objectives.
Section 2 presents an overall review of the key topics treated here and the main definitions upon which this work is based.
Section 3 presents the main concepts behind learning styles classification and describes the proposed model.
Section 3 also presents the data structures used to characterize the subjects, along with their materials and methods.
Section 4 presents the results obtained from the data analysis and specifies recommendations to stakeholders. In the last section, conclusions and future developments are presented.
3. Materials and Methods
The manner of integrating learning styles into an adaptive e-learning system may be divided into two essential areas: the build of a learning styles prediction model using online data (or the online learning styles classification model) and the application of this built model to an adaptive e-learning system. The development begins with choosing the learning styles model, for example, FSLSM. This is followed by determining the data sources and the learning styles attributes, and classification algorithm selections. After the evaluation, the suitable classification models and their outcomes are carried out for specific factors of the adaptive e-learning system.
The first step to build a model based on a computational intelligence algorithm is to collect and prepare a dataset. The students’ behavior was collected from an LMS (learning management system) developed specifically for this experiment. The learning objects used were content, outlines, self-assessments, exercises, quizzes, forums, questions, navigation, and examples. The behavior was collected as described in
Table 1. The 100 students graduated in Computer Science and enrolled in a post-graduate program in Computer Science and Project Management. The 26 descriptors were based on the Sheeba and Krishnan [
9] and Bernad et al. [
5] models. These descriptors were grouped into nine learning objects which are presented to the student in an LMS course. The dataset was composed of three types of measure: (a) “count”, which represents the number of times a student visits a learning object; (b) “time”, which represents the time the student spends in a learning object; and (c) “Boolean”, which represents the students’ results when responding to questions on a quiz. This record was collected for 15 days, and to summarize all the results obtained by the students, each descriptor was represented by the average of the students’ logs. The questions on the self-assessment quizzes were categorized based on whether they are about facts or concepts, require knowledge about details or overview knowledge, include graphics, charts or text only, and address building or interpreting solutions.
Table 1 shows the descriptors that were collected from the LMS. These descriptors also are considered as independent variables to build our model.
The resulting dataset does not provide a description of a learning style for each student. This information is necessary to train an algorithm based on supervised learning [
5]. To overcome this problem, we used the Felder–Silverman questionnaire, (the original questionnaire which we used can be viewed at [
19]) an adaptation to collect each student’s learning style. This questionnaire classifies a student in FSLSM using four dimensions: (a) processing (active/reflective); (b) perception (sensing/intuitive); (c) input (visual/verbal); and (d) understanding (sequential/global). This classification is constructed defining a range for each dimension (for example, processing) from (−11:0) (active) to (0:11) (reflective), and so forth. The dataset’s labels are shown in
Table 2. These labels are also considered as dependent variables in our model.
The labels shown in
Table 2 represent the students’ learning behavior in the FSLSM. In these cases, the 0 values (or absence of preference) are not considered in labels because when a student fills out the questionnaire, he/she needs to choose the options which represent a dimension. The overall working flow for this process is shown in
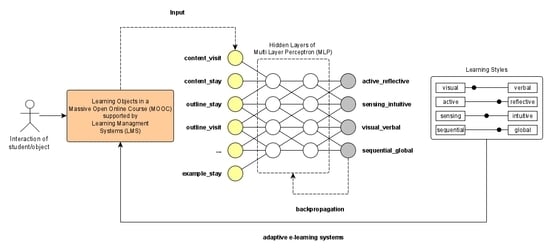
Figure 2, below.
As shown in
Figure 2, step 1 collects data from MOOC when a student interacts with a course. Then, in step 2 the system fills out the questionnaire for this student. In step 3, the results from the questionnaires based on the FSLSM are fed into a dataset. Finally, in step 4, the descriptors (independent variables) and labels (dependent variables) are combined with the raw dataset to produce an extended student classification dataset.
Since the dataset scale might be different for each student’s measure (count, time, and Boolean), the next step to proceed with the dataset construction is to normalize the data to suitably compare information among students. Neural networks can be used to normalize data in order to improve their accuracy [
5]. When analyzing two or more attributes it is often necessary to normalize the values of the attributes (for example, content_stay and content_visit), especially in those cases where the values are vastly different in scale. We use the range normalization [
17] described in Equation (1):
After this transformation, the new attribute takes on values in the range (0, 1). Moreover, we converted the range of each dimension (processing, perception, input, and understanding) from (−11:0) and (0:11) to (0, 1). This transformation is required for two reasons: (a) the learning styles are a tendency [
2,
4], thus, to represent a student as active/reflective, we used a binary variable (e.g., active or reflective, instead of 11 times active or 11 times reflective) as a relaxation problem strategy, and (b) to improve the accuracy of the algorithm to classify four outputs. This operation is shown in Equation (2).
In this case, each dimension receives TRUE to element at left and FALSE to element at right. For example, if a student’s processing dimension is <0, then the student receives TRUE denoting that it is active. On the other hand, if a student’s processing dimension is >0, then the student receives FALSE, denoting that it is reflective.
In addition, we investigate whether the dataset is imbalanced for each target. Imbalanced datasets mean the instances of one class is larger than the instances of another class (for example, more sequential rather than global in understanding dimension), where the majority and minority of class or classes are taken as negative and positive, respectively [
11].
Figure 3 shows the distribution of each target.
As shown in
Figure 3, this dataset does not have imbalanced data for any of the targets. For each dataset, the imbalance ratio (IR) is given by the division of the majority class by the minority class [
18]. As a result, we obtained active_reflective (1.04), sensing_intuitive (1.22), visual_verbal (1.63), and sequential_global (1.38).
The algorithm chosen for multi-target prediction was artificial neural network (ANN) for five reasons: (a) there is evidence that this algorithm is better suited to solve learning style classification problems [
5]; (b) since many authors use this algorithm, we can compare our results with other published ones [
3]; (c) ANN works well with rather small datasets, which is important for this line of research considering that typical datasets are rather small [
17]; (d) the problem can be translated to the network structure of an ANN; and (e) ANN allows multiple outputs analyzed at the same time. Moreover, the ANN architecture we used is feedforward multilayer perceptron, which means a neural network with one or more hidden layers [
17,
20].
The hidden layers act as feature detectors; as such, they play an important role in the operation of a multilayer perceptron. As the learning process advances throughout the multilayer perceptron, step by step the hidden neurons start to discover the features that describe the training data. They do so by performing nonlinear processing on the input data and transforming them into a new space, called the feature space. In this new space, the classes of interest in a pattern-classification task, for instance, may be more easily separated from each other than they could in the original input data space. Indeed, it is the creation of this feature space through supervised learning which distinguishes the multilayer perceptron from perceptron. Literature suggests that the number of hidden layers should be between log T (where T is the size of the training set) and 2× the number of inputs [
17].
A popular approach for training multilayer perceptron is the back-propagation algorithm, which incorporates the least mean squares (LMS) algorithm as a special case. The training proceeds in two steps. In the first one, referred to as the forward phase, the synaptic weights of the network are updated and the input signal is propagated through the network, layer by layer, until the output. As a consequence, in this phase, adjustments are limited to the activation potentials and outputs of the neurons in the network. (b) In the second one, called the backward phase, an error signal is produced by evaluating the output of the network with an expected response. The resulting error signal is propagated through the network, again layer by layer, but this time the propagation is performed in the backward direction. In this second step, successive updates are made to the synaptic weights of the network. Calculation of the updates for the output layer is straightforward, but it is much more difficult for the hidden layers [
17].
The back-propagation algorithm affords an approximation to the trajectory in weight space computed by the method of the stochastic gradient descent [
17]. The smaller the value of the learning rate parameter α, the smaller the changes to the synaptic weights in the network. Consequently, it will be from the first iteration to the next in a smoother fashion during the trajectory in weight space. This improvement, however, is attained at the cost of a slower rate of learning. The learning rates used were between 0.01 and 0.1, in steps of 0.01, leading to the following values: (0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1) [
17].
A training set is one of labeled data (for example, if a student is active or reflective) providing known information, which is used in supervised learning to build a classification or regression model. The training dataset is used to train the model (weights and biases in the case of artificial neural network) and then the model can see and learn from this data.
The model test is a critical but frequently underestimated part of model building and assessment. After preprocessing the data, they are needed to build a model with the potential to accurately predict further observations. If the built model completely fits the training data, it is probably not reliable after deployment in the real world. This problem is called overfit and needs to be avoided. A common manner on how to address the lack of an independent dataset for model evaluation is to reserve part of the learning data for this purpose. The basis for analyzing classifier performance is a confusion matrix (CF). This matrix describes how well a classifier can predict classes.
A typical cross validation technique is the k-fold cross validation. This method can be viewed as a recurring holdout method (holdout method divides the original dataset in two subsets, training and testing datasets). The whole data is divided into k equal subsets and each time a subset is assigned as a test set, the others are used for training the model. Thus, each observation gets a chance to be in the test and training sets; therefore, this method reduces the dependence of performance on test–training split and decreases the variance of performance metrics. Further, the extreme case of k-fold cross validation will occur when k is equal to the number of data points. It would mean that the predictive model is trained over all the data points except by one, which takes the role of a test set. This method of leaving one data point as a test set is known as leave-one-out cross validation (LOOCV) [
17]. This technique is show in
Figure 4.
As shown in
Figure 4, each iteration leaves one observation to test and the others to train. Therefore, the number of iterations is the number of observations in the dataset. The use of the leave-one-out procedure allows the model to be tested with all observations and prevents us from wasting these observations. This method was used to split the original dataset.
A classifier is evaluated based on performance metrics computed after the training process. In a binary classification problem, a matrix presents the number of instances predicted by each of the four possible outcomes: number of true positives (#TP), number of true negatives (#TN), number of false positives (#FP), and number of false negatives (#FN). Most classifier performance metrics are derived from the four values [
21]. We used the following metrics in order to improve the accuracy of our model (Equations (3)–(14)) [
22].
For binary problems, the sensitivity, specificity, positive predictive value, and negative predictive value were calculated using the positive argument. The overall method is shown in
Figure 5.
As shown in
Figure 5, the behavior of the 100 students is presented to the Multi Layer Perceptron (MLP) in order to train the neural network. The weight of each synapse (neuron connection) is obtained and the result is compared to the expected outcome (Equations (3)–(14)). When the accuracy (shown in
Table 3) is optimal (i.e., without improvement during the training step), the neural network training stops. The pseudocode that explains this method is presented below.
| Pseudocode 1: The overall idea of method to learning style classification |
|
|
|
|
|
|
|
|
|
As shown in Pseudocode 1 all the subsets (train and test) are presented to the MLP to train and test. Accuracy is one of the metrics of
Table 3 that is used to build the model, avoiding overfitting and underfitting [
17].
4. Discussion
In this section, the results from the experiments are presented and discussed. We initially investigated the aspects of three types of variables: (a) count descriptors, (b) time descriptors, and (c) target descriptors where, this last one is of type count. There were no outliers found in the dataset. The median of the type count descriptors was around four accesses by the element (content_visit, outline_visit, etc.), as shown in
Figure 4. The time descriptors define the time spent in each element (content_stay, outline_stay, etc.). The zero (0) value represents that the element had no access. The median time spent in type time was around 60 s and there was restriction that limited access at 120 s because of a time session limit. Finally, the target variables’ median was around 0, which express the balanced learning styles dataset in each dimension (input, processing, perceive, and store), which means that the students are about evenly distributed between active and reflexive classes. These values are shown in
Figure 6.
We also explored the frequency from each preference dimension before target transformation into binary variables (Equation (2)). As a result, we obtained the students’ learning styles for each dimension. The dimensions active_reflective, sensing_intuitive, and sequential_global presented an approximately uniform distribution; however, the visual_verbal dimension presented a concentration close to −5, which represents a preference by the students to acquire visual information.
Figure 7 shows this analysis.
We also investigated the possibility of using the dataset to identify students’ preferences. If, for example, a determined set of attributes represents one of the four learning dimensions, these attributes may help in the dimensionality reduction and improve classifier precision [
7,
16]. The groups were investigated using the k-means algorithm to identify natural clusters in dataset. The k-means algorithm was used with k = {2, 3, 4, 5}. As a result, we obtained clusters with two and three groups with low overlap. By using a number of groups up to three, the resulting clusters overlapped. These results are shown in
Figure 8.
Additionally, another analytics technique, known as principal component analysis (PCA), was applied to investigate other relevant attributes or correlations and whether targets, of each dimension, might be explained by some descriptor (count and time). This is an important issue for dimensionality reduction in order to improve accuracy and reduce the cost of the model build [
20]. These results are shown in
Figure 9.
The dataset is balanced for the dimensions perceive, processing, and store, and presents some variation in the dimension input. In addition, there is not a predominant descriptor, making it possible to use all descriptors for the model construction.
We may identify the onset of overfitting through the use of leave-one-out (special case of k-fold cross validation), for which the training data are split into an estimation subset and a validation subset. The estimation subset of examples is used to train the network in the usual way, except for a minor modification; the training session is stopped periodically (i.e., every so many epochs), and the network is tested on the validation subset after each period of training.
In our procedure, we varied the numbers of hidden layers for each model to determine a suitable number and provide the optimal result. The best model built presents two hidden layers, 26 neurons of input, and four neurons of output. The resulting model is shown in
Figure 10.
This model evaluates all descriptors, simultaneously providing the students’ classification in each learning dimension. This is a multi-target prediction algorithm [
19]. Equations (4)–(14) were used to evaluate the model. We used the confusion matrix (CF) [
17] to classify the predictions. The results of each dimension are shown in
Table 3.
The best model built achieved 85%, 76%, 75%, and 80% accuracy in each target attribute, active_reflective, sensing_intuitive, visual_verbal, and sequential_global, respectively. These results are better than the results presented by Bernard et al. [
5] (80%, 74%, 72%, and 82% in the same order) except for sequential_global, and simultaneously deal with all descriptors and targets instead of one at a time; we generated one model while Bernard et al. [
5] generated four models to solve the problem. Moreover, we provided many performance metrics for each dimension to support further research to compare and improve their results (
Table 3). In addition, we investigated the CF using area under the curve (AUC) and receiver operating characteristics (ROC). For each target the results were superior to Bernard et al. [
5].
Figure 11 shows these results.
All metrics indicated that the model might be a method to automatically classify a student in a MOOC environment. The relation between descriptors improves the accuracy (as show in specificity and sensitivity from
Table 3). Moreover, multi-target prediction (MTP) is a class of algorithms used with the simultaneous prediction of multiple target variables of diverse types, and the model using the Felder–Silverman procedure is by far, the most popular theory applied in adaptive e-learning system [
5]. Meanwhile, from another point of view, the accuracy (and other performance metrics) of the outcomes using the proposed approach could be further improved by the use of a big dataset. Another limitation of the current research is that the results of the experiments were only tested on a platform with a specific subject (computer science and project management). The consistency of performance needs to be tested when it runs with different learning management systems and/or other online courses (for example, administration, economics, and so forth). Our future work will involve further exploration of the performance metrics and practical implications in different environments.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}