1. Introduction
In recent years, many society and livelihood issues, such as traffic safety, congestion, pollution, and energy consumption are accompanied with the continuous increase of car ownership and traffic flow. According to statistics, more than 94% of traffic accidents are related to the driver’s behaviors [
1], and the driver’s distracted behaviors will affect his operating behaviors, thereby inducing a traffic accident. Additionally, the driver’s perceptions of danger greatly affect the driver’s driving behaviors.
Many scholars carry out research from multiple aspects, such as supervision on fatigue driving [
2,
3], prediction of traffic flow [
4] and so on, in order to reduce the occurrence of traffic accidents. Meanwhile intelligent driving systems are also being widely used. The current detection of road target information in intelligent driving systems mainly uses the method of combining the target detection algorithm that is based on deep learning and hardware, such as radar. Firstly, all of the road target information is identified by the vision sensor while using the target detection algorithm, and then static or dynamic objects can be identified, detected, and tracked by using radar or infrared technology, thereby taking corresponding measures. At present, the target detection algorithms that are based on deep learning are mainly divided into two categories, one of which is based on the region proposal framework, and the other is based on regression/classification framework [
5].
The target detection algorithm that is based on the regional proposal framework is based on the R-CNN target detection model that was proposed by Ross GirShick and others in 2014 [
6], and uses the idea of this model to propose a large number of better target detection models. The target detection algorithm that is based on the regional proposal framework uses the idea of R-CNN proposed by Ross GirShick et al. in 2014, and many scholars have proposed a series of better target detection models. The most representative of them is the Faster R-CNN model that was proposed by Ren Shaoqing et al. [
7]. This model greatly improving the detection speed of model. However, limited by the calculation of a large number of candidate regions, there is still a large gap between the model and the real-time detection. For the slow speed, problems, such as R-CNN and Faster R-CNN, the target detection algorithm that is based on the regression/classification framework directly implements the mapping from image pixels to bounding box coordinates and object class probability. This greatly improves the detection speed of the algorithm, but it is slightly inferior in detection accuracy. Its representatives are YOLO and SSD.
In 2016, Redmond et al. [
8] proposed Yolo, which follows the design concept of end-to-end training and real-time detection. Soon after, Redmond et al. designed Darknet-19 based on Yolo and proposed Yolov2 [
9] while using batch normalization [
10]. In 2018, Redmond drew ideas from ResNet [
11] and Feature Pyramid Networks (FPN) [
12] algorithm, and proposed Yolov3 [
13], thus greatly improving the detection accuracy. Much of the target detection in the field of intelligent driving is based on Yolo. Putra M H et al. [
14] realized a real-time human-car detector by improving Yolo. Yang W et al. [
15] proposed a real-time vehicle detection method that was based on Yolov2, which can complete vehicle detection and realize vehicle classification in real time.
When compared with Yolo, the Single Shot MultiBox Detector (SSD) that was proposed by Liu Wei et al. [
16] has three differences. The first is that SSD uses the Convolutional Neural Network (CNN) to detect directly, instead of detecting after the fully connected layer, like Yolo. Secondly, SSD extracts feature graphs of different scales for detection. The large scale feature graph (the earlier feature graph) can be used to detect small objects, while the small scale feature graph (the later feature graph) is used to detect large objects. Thirdly, SSD adopts prior frames with different dimensions and aspect ratios. Kim H et al. [
17] proposed a target detection model in the road driving environment, which was migrated from SSD on KITTI data set.
To sum up, although the two types of target detection algorithms in the field of intelligent driving currently have their own advantages in detection accuracy and speed, they are both universal target detection algorithms, that is, they will recognize all information that is captured by the visual sensors. However, it is obviously unnecessary to detect objects, such as distant trees, buildings, and even vehicles that are separated by several lanes. It is more efficient to directly detect dangerous targets or regions in front of the road and only extract the target information in the image that affects the car’s driving process, ignoring many unnecessary details.
In recent years, there have been few studies on the driver’s region of interest based on real traffic scenes. Andrea Palazzi et al. [
18] produced a video dataset of traffic scenes that can be used for predicting the driver’s attention position, named DR (eye) VE. The DR (eye) VE contains 74 segments of 5-min. traffic driving videos, which respectively record the eye movement data of eight drivers during real driving, and each only video contains one driver’s eye movement data information. In subsequent work, they used different computer vision models to train on their data set to predict the driver’s attention [
19,
20]. Tawari and Kang [
21] further improved the focus prediction results on the DR (eye) VE database through Bayesian theory.
The data set contains a total of 550,000 frames of video images, and also records GPS, vehicle speed, and other information. For the study of the driver’s visual attention mechanism in the driving scenes, the eye movement data in each video only contains a single driver, which might cause some images that are related to traffic driving to be lost due to the individual differences of the driver information. In addition, the driver reads external information in a chronological order during driving, instead of acquiring information from a single picture. Using this data set ignores the effect of chronological order on the driver’s visual attention mechanism.
We build the DVAN based on the attention model in order to simulate the driver’s visual attention mechanism. The attention model was originally used for text translation, but it is now gradually applied to the field of intelligent driving. Jaderberg et al. [
22] believe that pooling operation will lead to unrecognized or lost key information. Therefore, a spatial domain attention model was proposed in 2015, in which the spatial transformer performed corresponding spatial transformation on the spatial domain information in the picture to extract the key information. In 2017, HuJie et al. [
23] proposed a channel domain attention model, which added weight to the signals on each channel. Different weight values represent different degrees of importance of information. The larger the weight, the higher the importance of the information. In 2017, Wang Fei et al. [
24] effectively combined the attention models of spatial domain and channel domain to form a mixed domain attention model for feature extraction. However, the above attention model can only process a single picture. The driver’s visual attention mechanism processes external information in a chronological order, and rich contextual information is very important [
25]. Mnih, Volodymy et al., combined with the Recurrent Neural Network (RNN), proposed the Recurrence Attention Model [
26] in order to extract the key information from the input with time sequence features, but this model is prone to gradient attenuation or explosion when capturing the dependency relation with large time step distance in the time sequence.
Our method improves the Recurrence Attention Model and builds a driver’s visual attention network based on it, which was used to simulate the driver’s visual attention mechanism. Finally, we analyze the prediction results through the KITTI data set.
3. Experiment
3.1. Dataset Description
KITTI is the evaluation data set used in our method [
32]. KITTI is jointly founded by Karlsruhe Institute of Technology and Toyota American Institute of Technology in Germany, and it is currently the largest computer vision algorithm evaluation data set in the world under the automatic driving scene. The data set is used to evaluate the performance of computer vision technologies, such as stereo, optical flow, visual odometry, three-dimensional (3D) object detection, and 3D tracking in vehicle-mounted environment. The part of the data set is shown in
Figure 5.
KITTI contains real image data that were collected from urban, rural, and expressway scenes, with up to 15 cars and 30 pedestrians in each image, and various degrees of occlusion and truncation. The entire data set consists of 389 pairs of stereo images and optical flow diagrams, 39.2 km visual ranging sequences, and images of 3D labeled objects over 200 k, sampled and synchronized at a frequency of 10 Hz. The KITTI data set was taken with multiple cameras on the roof of cars, and only the left image was used in this article. There are 7481 training sets and 7518 test sets, with a total of eight categories: Car, Van, Truck, Tram, Pedestrian, Person (sit-ting), Cyclist, Misc. The training folder contains labels for the training set, but no labels are given for the test set. In our method, 7481 pictures in training set are made into training, test and validation according to the ratio of 8:1:1. At the same time, our method redistributes the label’s classification labels into three categories of Car, Cyclist, and Pedestrian in order to more conform to the visual attention mechanism of drivers, in which Car, Van, and Truck are all merged into Car, Pedestrian is merged, and Person (Sit-ting) is Pedestrian, and Tram and Misc are directly removed.
3.2. Experimental Details
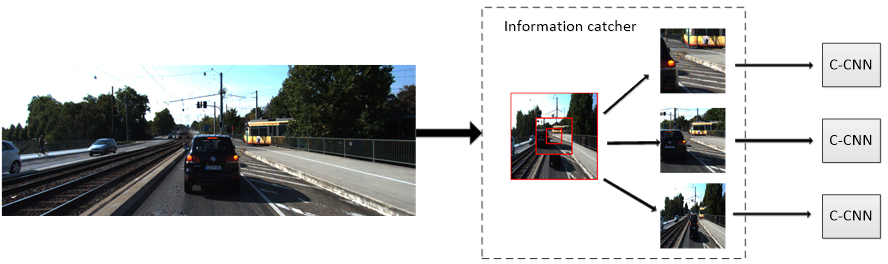
Determine the position of the initial attention point: The position of the initial attention point needs to be given in advance in our method. The first step, the coordinates of the image are converted to [−1,1], and the dot of the image is then set as the center of the image. The coordinates of the initial attention point are obtained by random sampling from the uniform distribution of [−r,r], r ∈ [0,1] under this coordinate system.
Set the parameters: The input of DVAN is the image of KITTI with the size of [376,1242,3] and
Table 1 shows the specific parameter settings. The structure of all C-CNN is the same, but the parameter settings are slightly different.
3.3. The Setting of Loss Function
The loss function of our network includes three parts, which are the loss part for classification , the loss part for attention points , and the loss part for location . Additionally, we can optimize the entire network structure by minimizing .
The loss of classification part (
Our method employs the cross entropy loss function to measure the accuracy of the predicted distribution
and the real distribution
of each category. Additionally, Formula (12) shows the expression of the loss part for classification
, where N represents the number of categories and
and
represent the
k-th component of
and
, respectively.
The loss of attention point part (
: The role of attention points is to provide C-CNN with feature points for extracting information. The prediction process by constraining attention points with
can ensure more accurate local feature extraction. We use the strategy reward mechanism in reinforcement learning [
33] to optimize the decision process of attention points, according to the particularity of attention point prediction.
Figure 6 shows the optimization process.
In our work, the Agent represents the attention point
to be predicted. The action of the attention point
represents the search of the driver’s interest target or region by the attention point. The Reward is the overlap between the predicted frame and the real frame. The Environment represents the currently processed image. The state represents the accuracy of the search for the driver’s region of interest by the attention point. Additionally,
and
are the inputs of Environment to Rward and state, respectively. Moreover, we adopted the L2 loss function to constrain the attention point in the last step, forcing it to approach the center of the target, in order to more accurately simulate the driver’s visual attention mechanism. Accordingly, the loss part
of the attention process is expressed as follows, where
is the distribution of attention points
,
is the expectation of
, and
can be optimized by scoring under the L2 criterion
to estimate.
The loss of locating part (
): Drivers will pay more attention to dangerous targets or regions ahead of the road during driving. Therefore, we only detect the targets that are most interesting to the driver in the picture in order to simulate this process in a real scenario. The coordinates of the upper left point are
and the size is
. We estimate the predicted amount
of the location by means of the maximum contingent estimation. In addition, we also construct a loss function that is related to the predicted border size
by predicting the overlap (IOU) of the border and the real border. At the same time, the accuracy of the predicted border is improved by maximizing the IOU. The loss of the positioning portion can be expressed as Equation (14).
Therefore, the loss function in our network is obtained by adding three parts, i.e., .
3.4. Experimental Results and Analysis
Figure 7 shows the results of this experiment and the change of the loss function during training. The graph (
a) is the process variation graph of loss function and the graph (
b) shows the final result of the verification of the method on the test set, where the mAP value reaches 79.3%, the overlap (IOU) reaches 58.6%, and the accuracy reaches 96.3%.
In addition, we employ Yolov2 and Yolov3 to train the data set in this paper and perform experimental comparison in order to verify the superiority of our method in real-time detection. The hardware configuration of the experimental environment is NVIDIA GTX1080 video card and 16GB of memory. The programming environment is Tensorflow. We compared the Frames Per Second (FPS) and the accuracy between different networks to show the performance of our method.
Figure 8 shows the comparison results. It can be clearly seen from graph (
a) that the FPS of our method is slightly lower than that of Yolov2, and it is about the same as that of Yolov3, which is sufficient for meeting the real-time requirements. It can be seen from graph (
b) that the three networks have little difference in accuracy, which might be because we only detect three types of targets.
4. Validation
In real traffic scenes, the driver’s attention to important traffic elements as well as his immediate cognition and coping with complex road scenes is one of the most important factors affecting driving safety. In the process of driving, drivers can obtain various information of road traffic through visual search. For the driver’s visual attention mechanism, the driver will not pay the same attention to all targets in the field of vision during driving, but will pay more attention to the targets or regions of most interest. Thus, it is more efficient to directly detect dangerous targets or regions in front of the road, and pay more attention to some relatively important regional targets in the image. We set the number of searches for targets on each picture to 10, that is, the number of points of attention P to 10, so as to better mine context information, in order to verify that our method can simulate the driver’s visual attention mechanism. At the same time, we analyze the sparse traffic scene, the crowded traffic scene, and the intersection traffic scene, respectively, in order to verify that the method can deal with different traffic environments.
Figure 9 shows the traffic scenes with sparse vehicles, which is extremely common in country roads. The traffic scenes in graph (
a) and graph (
b) are very similar. In these scenes, the vehicles are sparse, but there are targets that may affect the travel in the immediate right front of our vehicles, where graph (
a) shows cyclist and graph (
b) shows a red vehicle. In this case, the driver should pay more attention to cyclist and the red vehicle in order to prevent traffic accidents. It can be clearly seen from graph (
c) and (
d) that the targets affecting the forward movement of the vehicle are exactly the opposite of those shown in graph (
a) and (
b), and are located in the front left of the vehicle. Our method can also accurately locate them. In particular, the car in graph (
d) is meeting with a car and another car is moving slowly in the distance, in which case the driver will pay full attention to the silver vehicle with which he meets. According to the above analysis, our method can accurately locate the driver’s most interesting regions in the traffic scenes with sparse vehicles.
Figure 10 shows the traffic scenes with heavy traffic. For the traffic scenes in graph (
a) and (
b), there are many vehicles in the driver’s field of vision. Not only are there vehicles parked on both sides of the road, but also vehicles in front of them. At this moment, our car is passing through the middle of the road and it is getting closer to the vehicle in front of the left. The driver needs to pay more attention to the vehicle in front of the left in order to prevent collisions. In the traffic scene in graph (
c), our car is driving on the highway, and there are many vehicles. Although there are vehicles in front of the own lane, the black vehicle in the adjacent lane is closer to the vehicle and is more prone to collisions. Therefore, the driver will pay more attention to this car. It can be clearly seen from graph (
d) that the car meets with a white car on a road with many vehicles. In this scene, the driver will pay full attention to the white car meeting with it. From the above analysis, we know that our method can accurately locate the driver’s most interesting regions in the traffic scenes with heavy traffic.
Figure 11 shows the traffic scenes at the intersection. The road conditions at city intersections are very complex, and drivers need to pay more attention to them. Therefore, the effectiveness of our method can be verified to the maximum extent under this scenario. Graph (
a) shows the traffic scene, where our car is about to enter the main road from the side road. In this case, the driver pays attention to many regions, but only in the case of graph (
a), the driver’s current view is relatively wide and there is no obvious danger information. Therefore, the driver pays more attention to fast moving vehicles in order to avoid potential dangers. In the scene of graph (
b), a white vehicle passes in our vertical lane, and the white vehicle is completely exposed to the driver’s field of vision. In this traffic scene, the driver will focus on the white vehicle to prevent traffic accidents.
The scenes in graph (c) and (d) are basically similar, where our cars are waiting for red lights at the intersection. The difference is that there is a red car in front of our car in the graph (c), so the driver will pay more attention to the red car and follow it slowly through the intersection. In graph (d), our car and the white vehicle in the adjacent lane are waiting for the red light together. The driver will pay attention to the white vehicle on the adjacent lane in order to prevent scratches and other accidents at the intersection. According to the above analysis, our method can accurately locate the driver’s most interesting regions in the traffic scenes at the intersection.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}