1. Introduction
Human Activity Recognition (HAR) is an active area of research, since it can automatically provide valuable knowledge and context about the actions of a person using sensor input. Its importance is evidenced by the variety of the areas it is applied to, including pervasive and mobile computing [
1,
2], context-aware computing [
3,
4,
5], sports [
6,
7], health [
8,
9], elderly care [
9,
10], and ambient assisted living [
11,
12,
13]. In recent years, there has been a growing interest in the field, because of the increase of the availability of low-cost and low-power sensors, especially the ones embedded in mobile devices, along with the improvement of the data processing techniques. This growing interest can also be attributed to the increasingly aging population [
14] in the case of health and elderly care applications.
At the same time, several datasets have been collected over the years, including a range of modalities [
15]. There has been a great contribution from human activity recognition video datasets; some of the most important include the 20BN-something-something Dataset V2 [
16], VLOG [
17], and EPIC-KITCHENS [
18]. However, using video datasets for activity recognition entails potential pitfalls. Compared to using inertial sensors, there is a greater risk of violating personal data; they require a camera setup or a person actively recording the video at runtime, and their processing is heavier. The ubiquity of mobile devices and their embedded sensors have produced a multitude of datasets, which include accelerometer, gyroscope, magnetometer, and ECG data, such as the MHEALTH [
19,
20], the OPPORTUNITY Activity Recognition [
21], the PAMAP2 [
22], the USC-HAD [
23], the UTD-MHAD [
24], the WHARF [
25], the WISDM [
26], and the Actitracker [
27] datasets. A wide range of sensors has been also used to create Adaptive Assisted Living (AAL) HAR datasets, including reed switches, pressure mats, float sensors, and Passive Infrared (PIR) sensors [
28].
In the context of human physical activity recognition, competitive performance can also be achieved using only the input data from a mobile device’s sensors. This offers potential unobtrusiveness and flexibility, but also introduces a number of challenges [
29]. The motion patterns are highly subject dependent, which means that the results are heavily affected by the subjects participating in the training and testing stages. The activity complexity increases the difficulty of the recognition either because of multiple transitions between different motions or because of performing multiple activities at the same time. Energy and resource constraints should also be considered, since the capacity of mobile devices is limited, and demanding implementations will drain their battery. Localization is important to understand the context of a situation, but implementing it using GPS is problematic in indoor environments, while inferring distance covered with motion sensors usually results in the accumulation errors over time. Of course, it is also crucial to adapt research implementations to real-life problems, such as elderly care, workers’ ergonomics, youth care, and assistance for disabled people. At the same time, the privacy of sensitive data collected from the subjects must always be respected and protected, even at the expense of a solution’s performance.
The conventional method to extract knowledge from these datasets is with machine learning algorithms such as decision tree, support vector machine, naive Bayes, and hidden Markov models [
30]. They perform well in specific cases, but rely on domain-specific feature extraction and do not generalize well easily [
31]. Contrary to machine learning methods, deep learning methods perform the feature extraction automatically, and specifically, Convolutional Neural Networks (CNN), which are also translation invariant, have achieved state-of-the-art performance in many such tasks [
15].
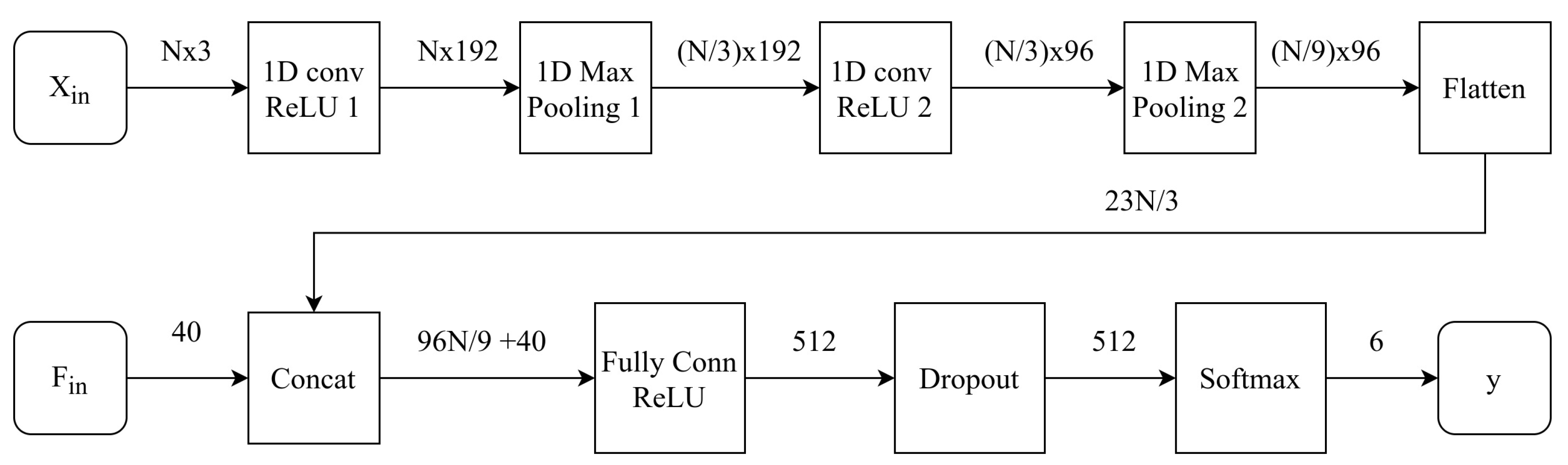
In this paper, a CNN model is proposed, which takes as the input raw tri-axial accelerometer data and passes them through the 1D convolutional and max-pooling layers. These layers effectively extract local and translation-invariant features in an unsupervised manner. The output of these layers is concatenated with an input of 40 statistical features, which supplement the previous with global characteristics. These are passed through a fully-connected and softmax layer to perform the classification. The model is trained and tested on two public HAR datasets, WISDM [
26] and Actitracker [
27], achieving state-of-the-art performance. Finally, the model is tested online on a mobile device, performing in real time, measuring and presenting significantly improved throughput and reduced size.
The remainder of this paper is structured as follows:
Section 2 summarizes the related work.
Section 3 presents the proposed solution, datasets, and metrics.
Section 4 describes the experimental setup and presents the results, and
Section 5 concludes this paper and proposes future improvements.
2. Related Work
Traditionally, machine learning approaches were followed in order to achieve human activity recognition [
32]. Decision trees are preferred because of their interpretability and low computational cost compared to more complex models [
30]. The J48 algorithm is an open source Java implementation of the C4.5 decision tree algorithm in [
33] and is usually used for HAR from motion sensor data, using features extracted by time domain wave analysis [
34] or statistical features [
26]. Other popular classifiers also used for HAR from motion sensor data are K-nearest neighbors and Support Vector Machines (SVMs). K-nearest neighbor classifiers were used with raw accelerometer data and shown to be inferior to using a CNN [
35], while Tharwat et al. [
36] used particle swarm optimization to produce an optimized k-NN classier. K-nearest neighbor is an Instance Based Learning (IBL) algorithm, which is relatively computationally expensive because it requires the comparison of the incoming instance with every single training instance. However, it offers the ability to adapt to new data and eliminate old data easily. Using an implementation of SVMs that does not require much processing power and memory, six indoor activities were recognized with an accuracy of 89% in [
37]. Ensemble classifiers, such as the bagging and boosting ensemble meta-algorithms [
3,
38], combine the outputs of several classifiers of the same type in order to get better results. On the other side, ensemble algorithms are more computationally expensive, since more base level algorithms need to be trained and evaluated [
30].
The state-of-the art performance of deep learning methods has been reported in various works coming from different approaches. For example, Hammerla et al. [
39] used a bi-directional Long Short-Term Memory (LSTM), which contains two parallel recurrent layers that stretch both into the “future” and into the “past”, to achieve a 92.7% f1-score on the Opportunity dataset [
21], while a combination of convolutional and recurrent layers, named DeepConvLSTM, was used by Ordonez et al. [
40], achieving 95.8% accuracy on the Skoda dataset [
41]. However, both of the above datasets require multiple wearable sensors, which enable the recognition of more complex activities, but also render the approach more intrusive.
This work will focus on non-intrusive implementations, where data coming only from a mobile device’s sensors are used. A commonly used dataset is the UCI HAR dataset [
42] with a waist-mounted mobile device. Using its embedded accelerometer and gyroscope, three-axial linear acceleration and three-axial angular velocity were captured at a constant rate of 50 Hz. It was partitioned into two sets, where 70% of the volunteers were selected for generating the training data and 30% for generating the test data, which standardized the results of the implementations. Sikder et al. [
43] proposed a classification model based on a two-channel CNN that makes use of the frequency and power features of the collected human action signals. Ronao et al. [
44] opted for a four-layer CNN with raw sensor data input augmented by the information of the Fast Fourier Transform (FFT) of each input channel, and Ignatov et al. [
35], with a shallow CNN, raw sensor data input, and 40 statistical features, achieved top performances on the test dataset of 95.2%, 95.75%, and 97.63%, respectively. However, the sensor signals (accelerometer and gyroscope) were pre-processed by applying noise filters and then sampled in fixed-width sliding windows of 2.56 s and 50% overlap (128 readings/window) for the dataset, which means that it adds extra steps, thus time and processing power, for a real-time implementation.
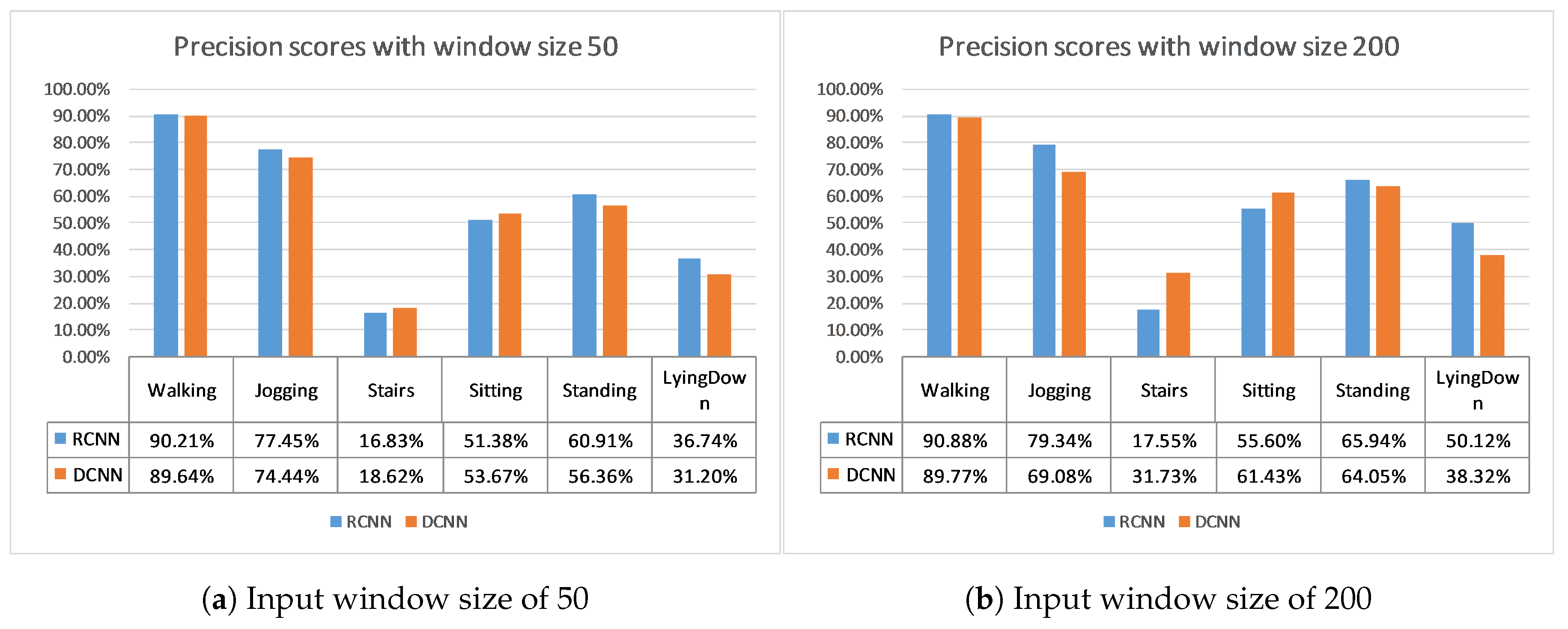
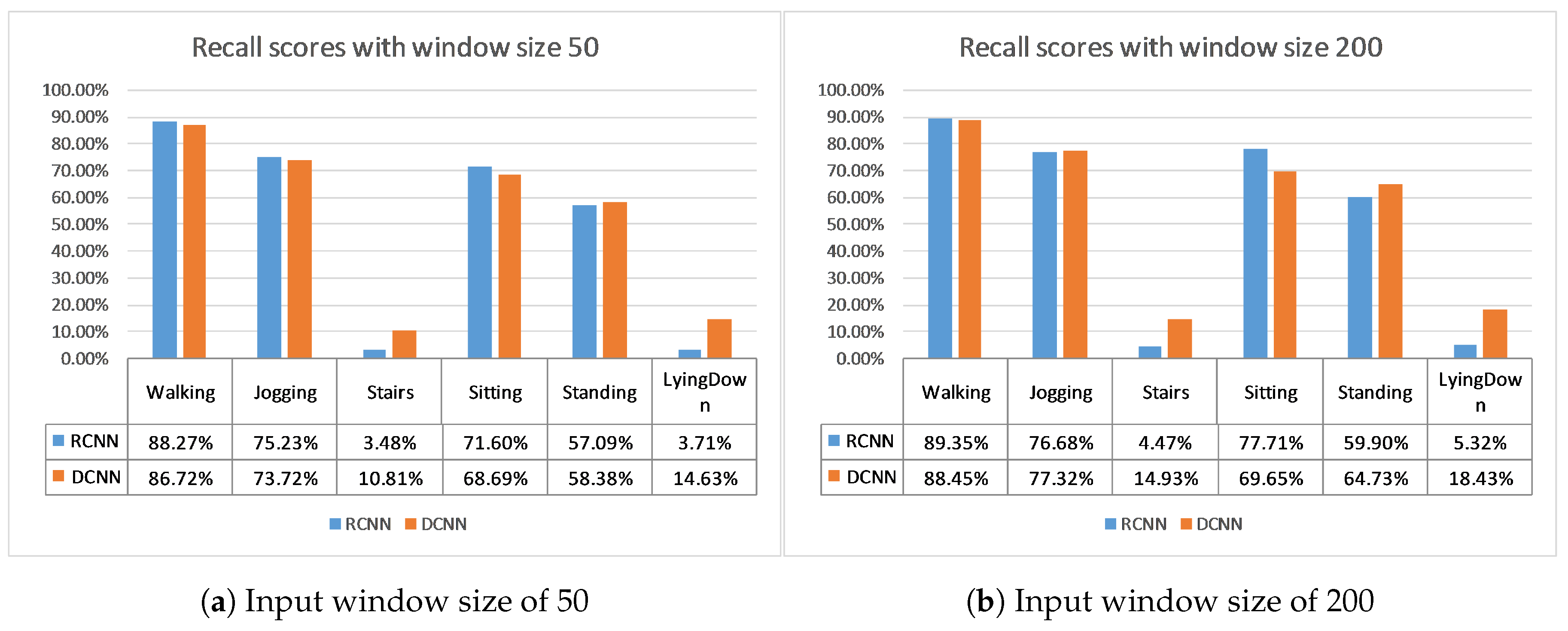
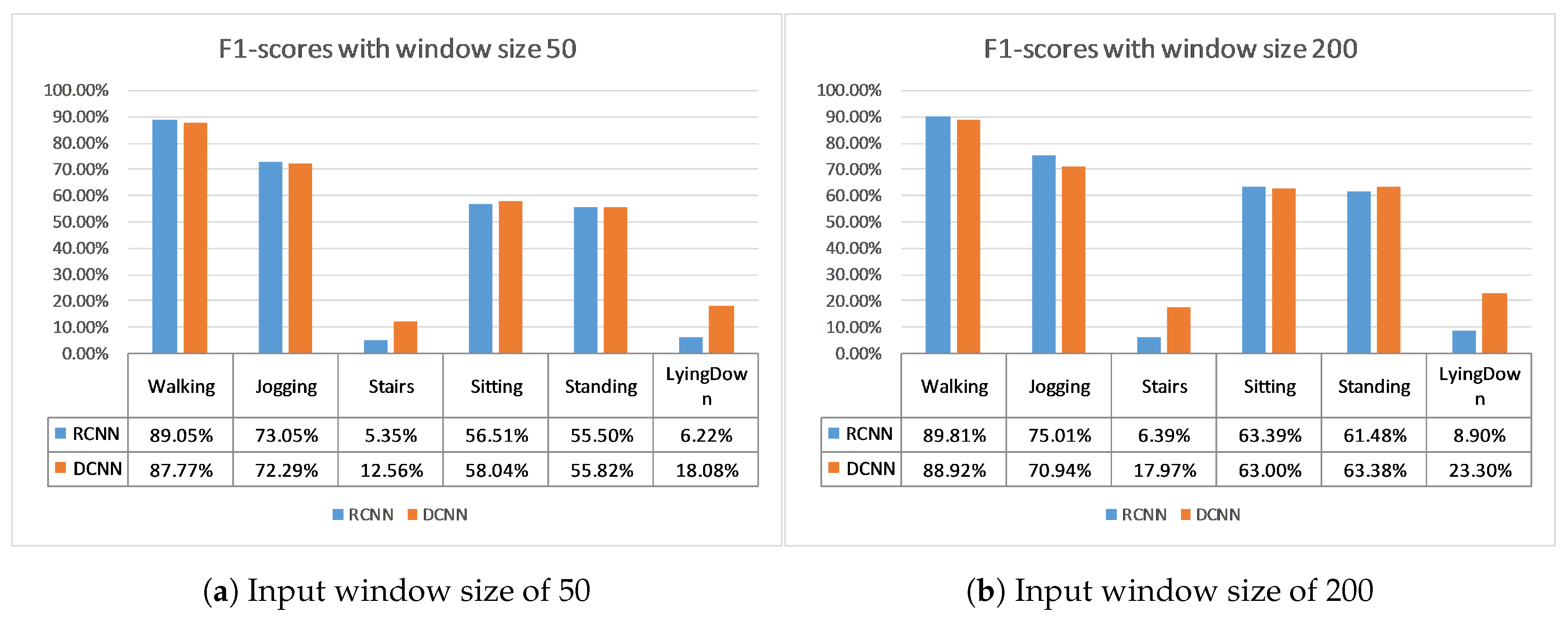
Finally, the WISDM (WIreless Sensor Data Mining) lab has produced two datasets using a pocket-placed mobile device, the WISDM [
26] and Actitracker [
27] datasets. Both datasets contain time series of tri-axial accelerometer data during six physical activities with a frequency of 20 Hz, of which the four ones are common (Walking, Jogging, Sitting, Standing), while the other two activities are different for the WISDM dataset (Upstairs and Downstairs) and for the Actitracker dataset (Stairs and Lying Down). There is no pre-selection of training data and test data, so there is a lack of consistency in reporting the results of the implementations that use these datasets. For the WISDM dataset, all previous works developed user-dependent solutions, except for [
35,
45,
46], who trained their models on the data of subjects different than the ones on which the models were tested. Kolosnjaji et al. [
45] proposed using a combination of hand-crafted features and random forest or dropout classifiers on top of them and achieved 83.46% and 85.36%, respectively, using the leave-one-out testing technique. Huang et al. [
46] proposed an architecture of two cascaded CNNs, performed a seven-fold user-independent cross-validation, where five subjects were left out as a testing dataset and the rest were the training dataset, and reported an average f1-score of 84.6%. Ignatov et al. [
35] selected the first 26 subjects for their training set and tested the performance on the remaining 10 users, achieving 93.32% and 90.42% accuracy for an interval size of 200 and 50 data points, respectively. Alsheikh et al. [
47] evaluated WISDM only and achieved 98.23% accuracy by using deep belief networks and hidden Markov models, but there was no mention of how the dataset was split into training and testing. Milenkoski et al. [
48] trained an LSTM network to classify raw accelerometer data windows, but they reported an accuracy of 88.6% on an unspecified 80%/20% train/test split of the dataset. Pienaar et al. [
49] used a similar random 80%/20% train/test split, and they trained a combination of an LSTM and an RNN and achieved an accuracy of 93.8%. Wang et al. [
50] proposed a Personalized Recurrent Neural Network (PerRNN), which is a modification of the LSTM architecture, and achieved 96.44% accuracy on a personalized, i.e., user-dependent, 75%/25% dataset split. Another LSTM architecture was proposed by [
51], which achieved 92.1% accuracy on an unspecified testing dataset split. Xu et al. [
52] trained a CNN model on randomly selected 70% of the dataset and evaluated on the remaining 30% of the dataset, reporting an accuracy score of 91.97%. Another CNN model was proposed by Zeng et al. [
53], which scored 96.88% accuracy on a 10-fold user-dependent cross-validation of the WISDM dataset. As for the Actitracker dataset, which includes more subjects in the data collection, the problem persisted since Alsheikh et al. [
54] scored 86.6% accuracy, but did not explain which part of the dataset was used for testing, while Shakya et al. [
55], who achieved an impressive 92.22% accuracy, did not take the subjects into account and divided the dataset randomly, thus not excluding the data of subjects who were included in the training set. The seminal work of Ravi et al. [
56,
57] achieved high performance on both datasets, 98.6% on WISDM and 92.7% on Actitracker, using spectral domain pre-processing, deep learning, and shallow learning, but the 10-fold cross-validation was again user-dependent. Yazdanbakhsh et al. [
58] transformed the input window for every channel into an image and passed these through a dilated convolutional neural network. They evaluated in both a user-dependent fashion against Ravi et al. [
56] and a user-independent fashion against Ignatov et al. [
35] on WISDM, achieving comparable performance.
Important factors regarding the dataset and the implementation are the sampling frequency and the window sizes used to create the time-series input. Most solutions use a sampling rate between 20 Hz and 50 Hz, while datasets sampled at 50 Hz include the MHEALTH dataset [
19,
20] and the UCI HAR dataset [
42]. The custom dataset’s frequency collected by Siirtola et al. [
59] was 40 Hz, while the WISDM [
26] and Actitracker datasets [
27] were sampled at 20 Hz. According to [
60], ninety-eight percent of the power for the walking activity was contained below 10 Hz, and ninety-nine percent was contained below 15 Hz. Furthermore, no amplitudes higher than 5% of the fundamental existed after 10 Hz. Regarding on-device implementations, the main frequencies were lower than 18 Hz when a mobile device was carried in a hip location [
61]. Lower sampling rates can reduce battery usage and memory needs. Much work has been directed toward finding the optimal window size, but most implementations use window sizes in the 1–10 s range. Most implementations use fixed window sizes of 1.28 s [
53], 1.8 s [
52], 2.5 s [
50,
51], 2.56 s [
37,
43,
44], 3.2 s [
46], 7.5 s [
59], 10 s [
26,
47,
48,
49,
54], 2 s and 5 s [
55], while Ignatov et al. tested their implementation in the 1 to 10 s window size range [
35]. An overview of the works presented in this section can be seen in
Table 1.
5. Discussion and Conclusions
When designing an implementation for mobile use, where the storage capacity is restricted, decreasing its size is a main goal. The size of a model depends on the number of its parameters, so it is the first variable that must be analyzed. We will provide an analysis for the variation of the model with an input size of 200 in favor of conciseness, but the results are similar for the one with an input size of 50. It is clear in
Table 15 that the fully-connected layer is the one that contains the bulk of the model’s parameters. The proposed model has almost ten times less parameters than the original one, which is due to two factors. The layer has half as many nodes as the original, and the addition of the second convolutional layer further decreases the size of the input to this layer. This convolutional layer does contribute additional parameters to the network, but this increase is negligible compared to the decrease in the fully-connected layer. This explains the considerably smaller model size of the proposed network. The smaller model size combined with the faster inference time makes the DCNN model a better fit for real-time mobile implementations.
Furthermore, the smaller and more efficient design not only does not decrease the prediction performance, but consistently slightly increases it, achieving state-of-the-art performance amongst subject-independent implementations. It is considered important to note here the motivation behind choosing and comparing against only subject-independent solutions. The main goal is to correctly evaluate the generalization capability of the network, since “seeing” data points of a subject in the training set can help the inference of the same subject in the test set, and there is no guarantee that this will work as effectively for a subject that was never in the training set [
66]. Moreover, targeting a real-time mobile use case means that the training will be performed on a desktop and the model will be used on a mobile device for inference. In most cases, the dataset for training the model will not contain data points of the end user, especially if the application becomes publicly available. Finally, the comparison of the results of subject-independent and subject-dependent solutions is unfair, since the scores of the subject-dependent solutions are expected to be higher.
Statistical feature analysis is also performed to evaluate the importance of the features and the possible alternative approaches. More specifically, the results indicate clearly that the use of the 40 statistical features improves the performance of the network, and at the same time, all of the different feature types contribute, albeit with varying impact, to this improvement. Using PCA would help decrease the dimensionality of the feature input, but in our case, it results in inferior performance, instead. The main reason is that it requires normalization, in order to properly estimate the variance of each feature, and thus, it distorts the scale of these features. This is supported by the fact that using no features at all achieves higher performance than using normalized features.
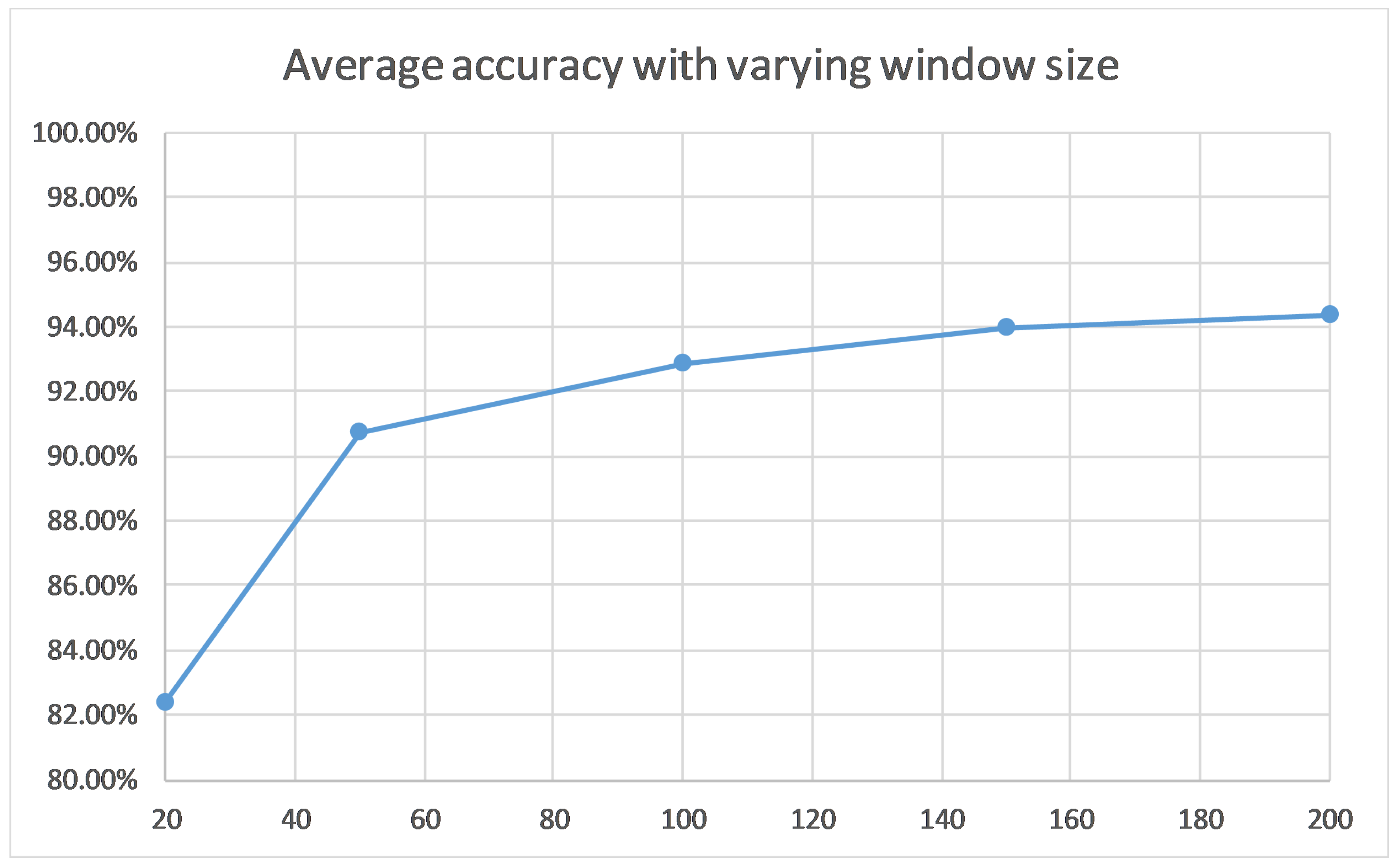
Finally, a window size analysis will enable each implementation of our solution to select the window size that more closely fits their specifications. It also justifies the selection of window size of 50 for a good trade-off of performance and efficiency and the selection of window size of 200 as the best performing one, if speed is not the most important factor.
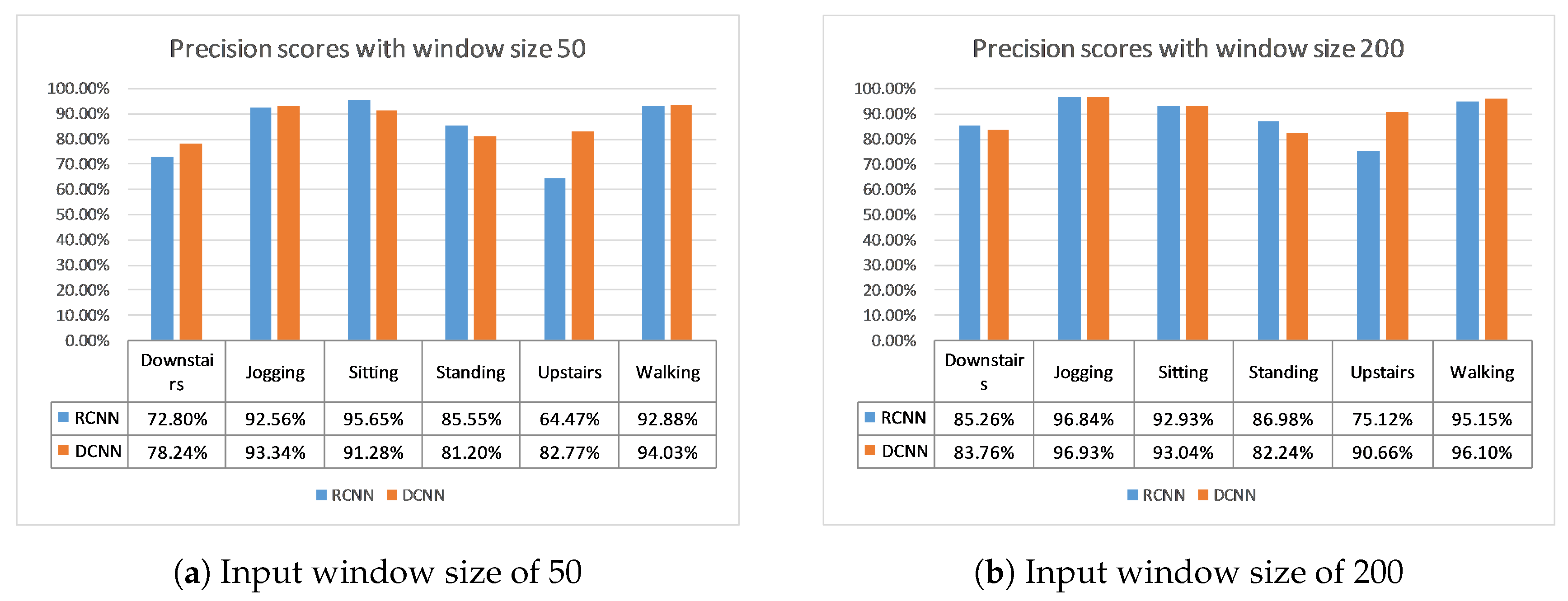
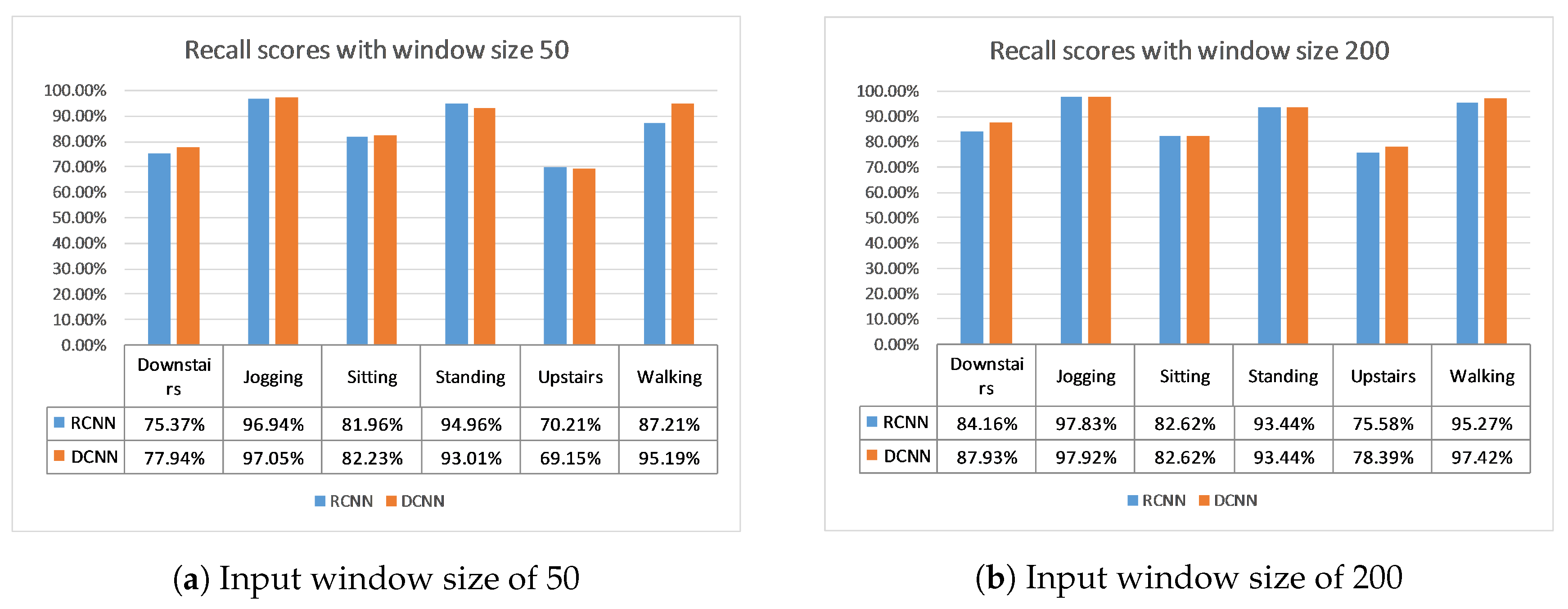
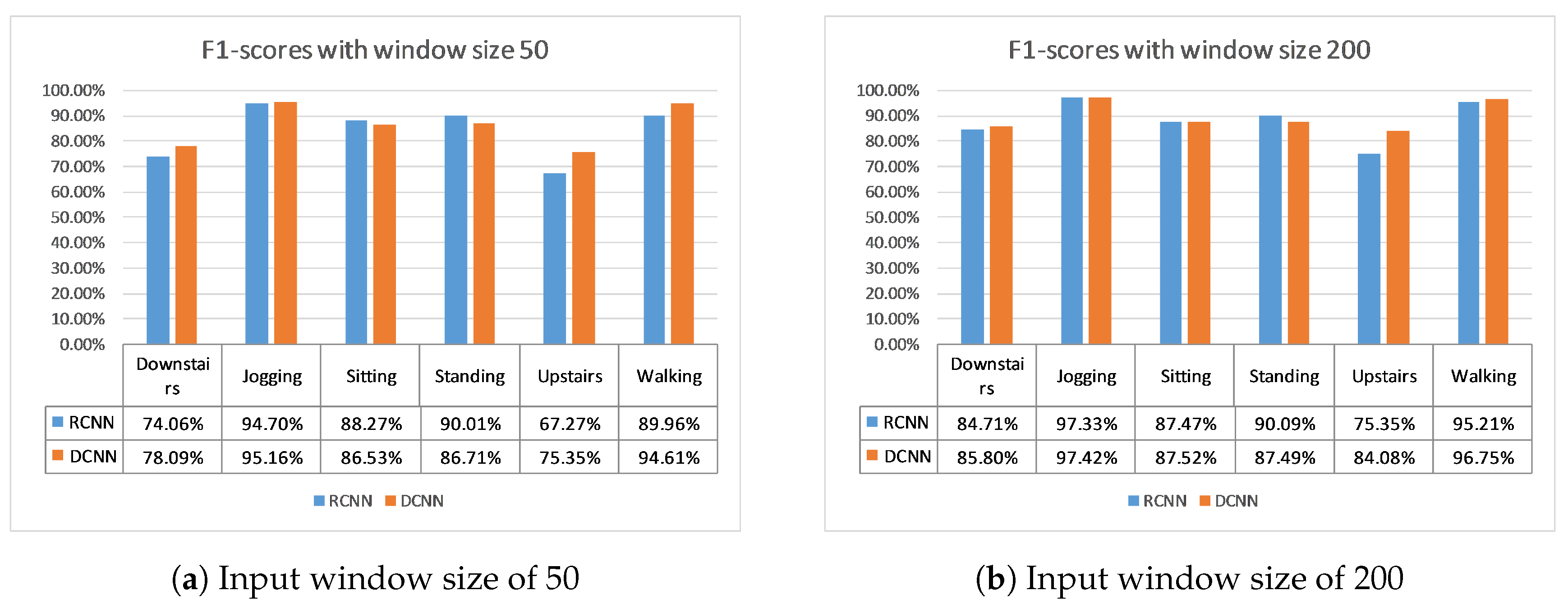
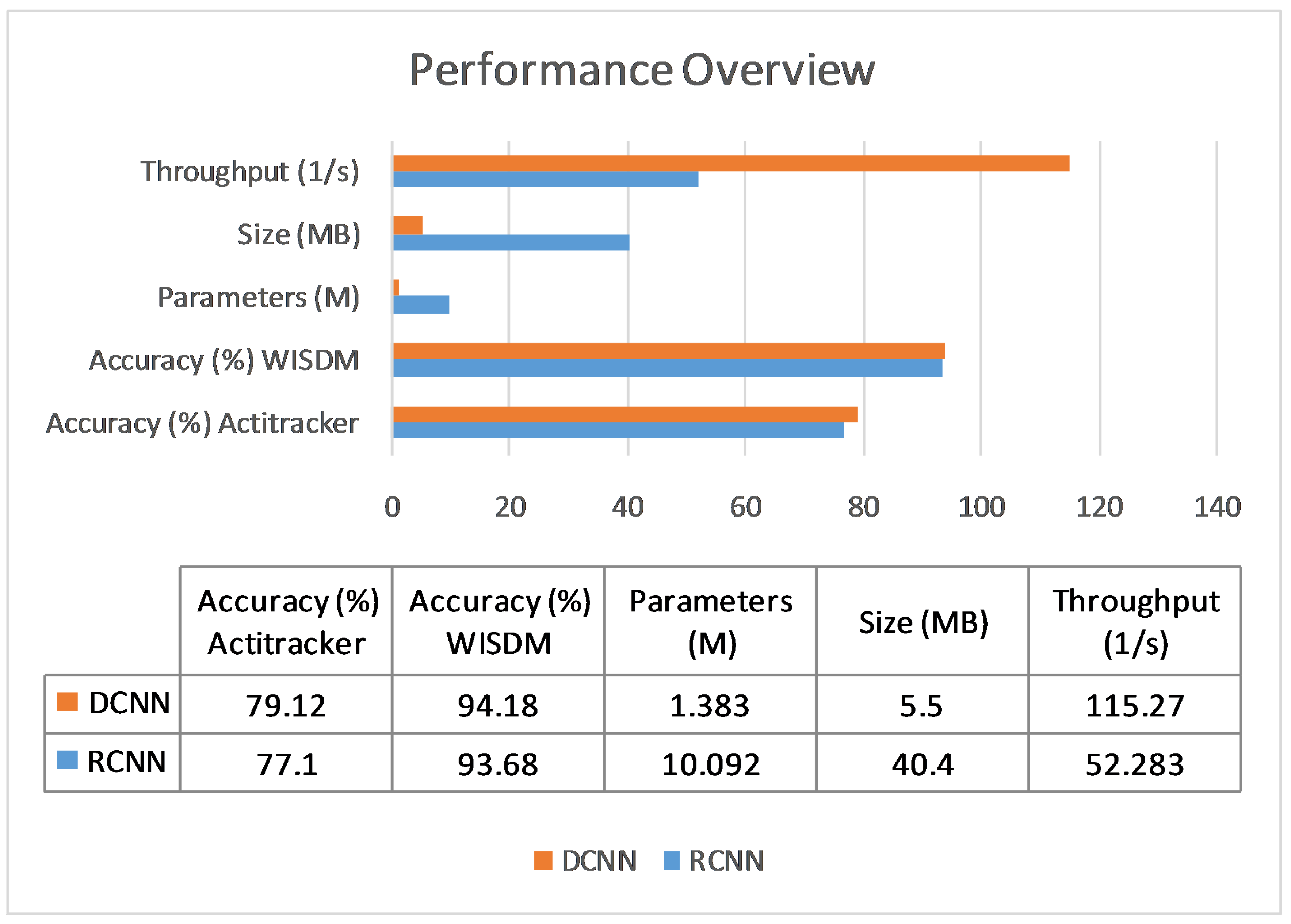
In conclusion, a novel model to recognize physical activities using only the accelerometer data from a mobile device in real time is proposed. It improves upon the state-of-the-art solution by employing a deeper convolutional neural network structure and changing the optimization methods. This improvement is evident at many levels. Firstly, the number of parameters and the size of the model are five to eight times smaller than the previous state-of-the-art model, for instance 1.383 million model parameters instead of 10.092 million for a window size of 200. The throughput is also improved, since it is two to three times higher, namely 405 inferences per second compared to 206.88 of the previous state-of-the-art and a window size of 50. Moreover, the classification performance is better and more robust, since both models are tested on two datasets and 10-fold cross-validation is also used. Indicatively, the average accuracy on the 10-fold cross-validation on the WISDM and Actitracker datasets for a window size of 200 is 94.18% and 79.12%, 0.5% and 2% higher than the previous state-of-the-art. This means that this solution is better in terms of size, throughput, and performance, all of which are crucial for a real-time on-device application, as can be seen in
Figure 9. As an additional contribution, we investigated the impact of the statistical features in order to validate their importance and offer a comparison between the 40 statistical features and the ones created using PCA.
Among the various limitations acknowledged in this work, certain factors have been identified as fields of further research to be pursued towards improving the results of the proposed system. Even deeper convolutional neural network structures can be explored, but the size of the network needs to always be in check. A probable solution would be to also use convolutions. Another convolutional neural network with a higher receptive field could also be an alternative for substituting the global features. Finally, an implementation that also uses the gyroscope data would be interesting.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








