1. Introduction
Nowadays, diesel engines are the prime movers in commercial transportation, power generation, and off-road applications. Their major advantages compared to other common alternatives are a better fuel economy, a lower carbon footprint, and an increased reliability. The demands on engine performance indicators—increased power output, lower fuel consumption, and emissions—require a better understanding of engine processes, further experimental investigations, and the implementation of control strategies based on numerical models.
In four-stroke engines, the process of gas exchange requires a very rapid and total release of exhaust gas from cylinders into the atmosphere, which is evaluated by exhaust back pressure (EBP), a flow resistance indicator on the exhaust duct. Unsteady friction and inertial forces, which are dependent on gas velocity, shape, and dimensions of the passages, occur. EBP is defined as the gauge pressure at the turbine outlet for turbocharged engines or at the exhaust manifold outlet for naturally aspirated engines [
1].
Diesel engine control based on numerical models tends to become more complicated as the number of independent variables increases, so multidimensional, flexible, and adaptive add-ons based on artificial intelligence (AI) are required; these systems are able to learn from experiments, solve non-linear problems, use scarce data, and predict phenomena.
To the knowledge of the authors, among the high number of articles studying the artificial neural network (ANN) prediction of diesel engine performance, there have been a lack of studies with EBP as an input parameter.
Therefore, the goal of this work was to provide a better understanding of EBP effects on diesel engine parameters, at different loads and speeds, based on engine experiments and AI simulations in order to assess the reasonable performance loss (expressed mainly in power loss) caused by the emission and noise abatement devices.
The main contribution of the paper is the AI application in the interpretation of exhaust pressure loss consequences; the added value of such an approach is the possibility to assess performance decline by means of virtual sensors implemented on smart devices.
The opportunity of the applied research was given by recent progress in cost-effective embedded systems with local processing, storage, and communication capabilities that enable the edge-computing/cloud-computing paradigm of the IoT (the Internet of Things). Centimeter-scale smart devices built around a small SoC (system on chip) IC (integrated circuit) with a WiFi and/or a BLE (Bluetooth Low Energy) radio interface for NFC (near field communications) and a PCB (printed circuit board) antenna are now able to acquire sensor signals via integrated ADCs (analog-to-digital converters). Local signal conditioning and lower/medium complexity processing are performed and results are “published” in the cloud in real-time. These CPS (cyber–physical systems)—the so called “smart dust”/“radio dust”—can also receive cloud directives and download data flows because they are fast-enough for “cyber-critical communications” with time constants much smaller than industrial ones, particularly than vehicular ones. Internet protocols drive IoT WSAN (wireless sensors and actuator networks) that build a pervasive communication eco-system for a test-bench and even for vehicular add-ons to traditional CANs (computer area networks)/device nets on-board. The software subsystems of these compact smart devices are also shrunken down to mini-programs that reside in flash, non-volatile memory chips. Such firmware is built in a low scale IDE (integrated development environment), e.g., Arduino™.
The actual efforts to embed AI in smart devices are discussed from the cloud computing/edge computing perspective.
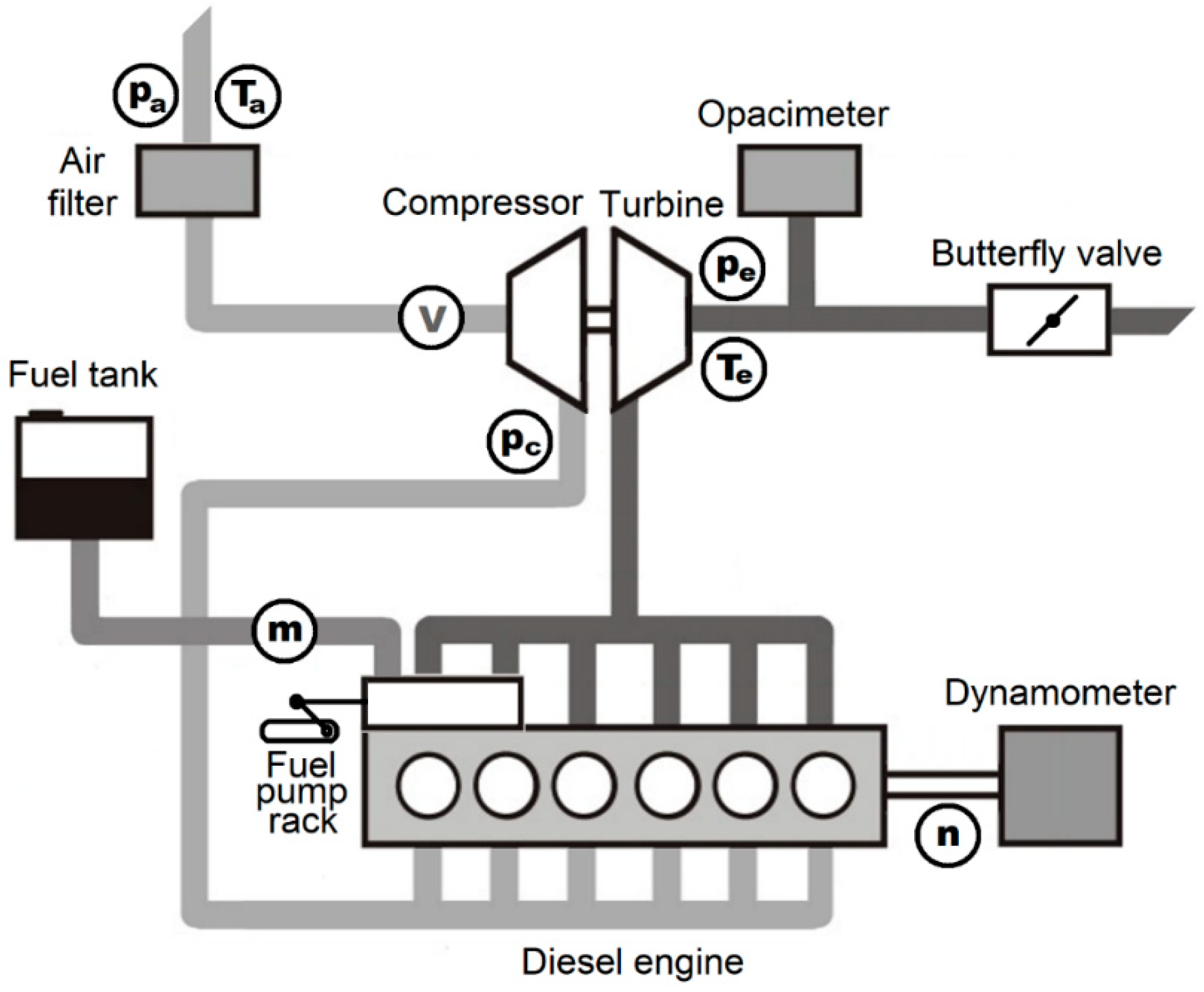
In terms of methods and apparatus, the study of the EBP effect on diesel engine performance needed a test-bench with appropriate sensors and instrumentation. The setup of data structures for AI-based calculation was followed by database preparation for ANN training and testing. AI for vehicular smart devices was implemented in finite state machine models in an approach similar to object-oriented programming (OOP). ANNs were detailed in the perspective of computational needs for cloud AI versus edge AI. The main ANN training algorithm was SGD (stochastic gradient descent) for BP (back propagation) optimization. The cloud AI implementations were based on MathWorks MATLAB online (with MaaS (Model as a Service) being the optimal choice of Gaussian regressor), the Tensorflow backend (with two APIs (application programming interfaces)—Keras and eXtended Gradient Boosting (XGBoost)) and the ANS Center ANNHUB (for a Levenberg–Marquardt algorithm implementation). Activation functions were mainly ”ReLU” (rectified linear unit) and ”tanh” (hyperbolic tangent), along with the latter’s shift and scaled version: the “sigmoid”. The edge AI high-performance solution with the hardware acceleration of AI computations was based on the NVIDIA Jetson Nano mini-system built around the “Maxwell” SOM (system on module) produced by NVIDIA. The very compact edge AI solution was based on the “TTGO” micro-system produced by LILYGO, centered on the “ESP32” SoC (system on chip) produced by Espressif. As all solutions shared the common complete dataset collected on the engine experimental bench, a separate test flow was implemented via National Instruments LabVIEW virtual instrumentation.
The paper is organized as follows: After the Introduction in
Section 1,
Section 2 details the related work in the area of EBP and ANN diesel engine optimizations,
Section 3 describes the diesel engine experiments performed on the dynamometric test-bench, detailing engine characteristics, instrumentation, and operation mode procedures, as well as complete data collection.
Section 4 introduces the AI for the needs of vehicular smart devices, particularly for sensor data processing—the local/centralized placing of AI in a distributed computational environment and AI algorithms applicable to virtual sensors (mainly ANN and classification trees with linear regression branches).
Section 5 is dedicated to cloud AI implementations—via MATLAB online, the specific APIs (application programming interfaces) like Keras for ANN, XGBoost (eXtended Gradient Boosting), and the ANNHUB (for an efficient Levenberg–Marquardt implementation).
Section 6 is dedicated to the concrete implementations for edge AI, the first one to promote a maximum of miniaturization (minimal code running in an extremely compact hardware) and the second one to promote the maximum of local performance (with hardware acceleration of the AI computation).
Section 7 is an interpretation of the results with a testing and performance assessment,
Section 8 is a discussion on practical issues, alternatives, usability, and sustainability. Finally,
Section 9 presents the main conclusions of the paper.
2. Related Works
This section covers EBP investigations, mainly regarding AI-based predictions in diesel engines and vehicular energy systems. Engine performance is negatively influenced by excessive EBP, thus requiring a higher pumping work to release exhaust gas. The literature has indicated slight reduction of power output and an increase of fuel consumption, exhaust temperature, and smoke emissions. In turbocharged engines, higher EBP means higher turbine outlet pressure, which decelerates the turbocharger, limits the air mass flowrate aspirated in the compressor, and enriches the air–fuel mixture [
2,
3]. Among engine after-treatment technologies, active DPF (Diesel Particulate Filter) is the most demanding device in terms of pressure drop exigence, and it is thus of paramount importance in the triggering of thermal regeneration process [
4].
There are rather few published papers with experimental measures of EBP. For naturally aspirated single-cylinder diesel engines, EBP has been varied in the range of 1.1–1.5 bar, which explains the influence on residual gas fraction and emissions [
5,
6]; meanwhile, other work [
7] has reported increased smoke and a drop of brake thermal efficiency at low loads.
For turbocharged engines, a six-cylinder aftercooled 500 kW diesel engine has been investigated at a constant speed, and the influence of EBP on brake-specific fuel consumption (BSFC), exhaust gas temperature, and emissions was interpreted [
8]. Similarly, the testing of a 63 kW turbocharged and intercooled diesel engine at a high EBP impeded engine power, torque, and smoke opacity, reporting, at full load, a drop of power of 9% at an externally applied EBP restriction of 35% out of exhaust duct free section [
9].
Accurate EBP measurement is time-consuming and costly, being impeded by pulsing flow and high temperatures; that is why the influence of EBP increase has been frequently investigated with numerical simulation models [
5,
10]. The exhaust system has been considered a fixed-geometry restriction between the exhaust manifold and the outlet of the tailpipe being implemented a mean-value model to estimate the exhaust manifold pressure from a compressible flow equation. Simulations with Ricardo wave software on a 11-liter submarine diesel engine indicated the reduction of mass flow of air, increased brake-specific fuel consumption, and increased exhaust temperature [
3].
Emission abatement techniques such as exhaust gas recirculation (EGR) can be controlled by the accurate estimation of EGR mass flowrate, which requires the engine exhaust pressure as input data. Instead of a physical sensor, virtual sensors are preferred, but their calibration needs real measurements; for example, the research work of [
11] reported a virtual sensor, a model-based exhaust manifold pressure estimator that was calibrated with real measurements on a four-cylinder, 1.6 liter turbocharged diesel engine. Similarly, an exhaust pressure estimator was implemented on a 4.9 liter turbocharged and intercooled diesel engine fitted with DPF and DOC (Diesel Oxidation Catalyst) that was calibrated with a physical exhaust pressure sensor for DPF failure detection [
12].
An extension of the numerical models for diesel engine study, in terms of number of parameters and processing capabilities, is related to the use of AI methodologies. The most spread AI technique applied to combustion engines is an artificial neural network (ANN). An ANN is a black-box identification technique that is able to automatically learn from examples and to derive models from experimental data. Initially, output and input variables are connected through unknown relations that can be predicted by ANN after training and testing stages [
13,
14].
Many studies using ANNs in the diesel engine field have been reported, starting from two decades ago; output variables include power [
15], torque [
16,
17], mean effective pressure [
15], brake-specific fuel consumption (BSFC) [
16,
18,
19,
20], brake thermal efficiency [
21,
22], cylinder pressure [
21], cylinder temperature [
23], exhaust gas temperature [
16,
18,
22], emissions [
17,
21,
22,
24,
25], and mixture/injection parameters (fuel air equivalence ratio [
18], maximum injection pressure, and fuel flow rates [
21]).
Besides the most widely-used input parameters of engine speed and load, studies have reported power [
19], torque [
26], fuel injection parameters [
19,
22,
24], cooling fluid temperature [
18], fuel properties [
27], biodiesel blend [
21,
22], and compression ratio [
22].
New AI techniques have been developed in order to optimize engine operation in the context of vehicular energy systems. Among them, deep reinforced learning (DRL) has demonstrated a fair balance over conflicting objectives, accelerated convergence, and continuous control when applied to fuel economy [
28] and battery energy management implemented on hybrid vehicles [
29,
30].
The aforementioned ANN studies have not considered the influence of EBP on engine parameters, so one of the novelties of this study is related to the investigation of the best approach for implementing AI algorithms working as virtual sensors.
4. Artificial Intelligence for Vehicular Sensor Data Processing
The graphical analysis of the intricated curving shapes in
Figure 2 reveals a rather limited number of points that cannot accurately describe the effect of EBP on engine power. Even though the number of 246 experiments is quite high in engine research work, engine control requires a higher granularity of data on an engine performance map. Engine testing procedures are expensive, time-consuming, and need special purpose infrastructure; the number of measured vehicle parameters is limited compared to what can be done with a test-bench, which is why it is highly recommended to complement the experimental data with predictions based on artificial intelligence.
Unlike stand-alone physical sensors, virtual sensors are embedded mini-systems designed to calculate and provide data to ECUs (electronic control units). For the current work, the virtual sensor was basically an ANN or a regressor that was supplied in the normal operation phase with input data from a number of only
N physical sensors (e.g., the simplest and/or most reliable and/or cost-effective ones), data used for the estimation of the extra value, indexed (
N + 1) that are difficult to measure directly or indirectly via simple calculation formulas. Nevertheless, in the training phase, the AI model was fed with complete datasets, each including (
N + 1) values, which were measured on the engine test-bench. In the context of the present investigation, as illustrated in
Figure 3, the (3 + 1) variables were engine speed, load, EBP, and power. By applying AI, the fourth variable, effective power, was obtained based on predictions.
For modern ECUs, engine control maps have become very intricate with dedicated hardware/software architectures for each sub-system from air and fuel management to exhaust after-treatment. AI can replace one or more controllers with efficient smart devices that can be integrated into an engine’s ECU; such AI-based solutions are able to facilitate the simultaneous optimization of all apparently contradicting ECU objectives such as fuel economy, lower emissions, and higher torque and power.
In applied sciences, particularly in the field of ICEs (internal combustion engines), AI is frequently used to solve computational-intensive problems such as function approximation, prediction and process control, and the management of the complicated relationships between inputs and output variables. Due to this intrinsic complexity, the following paragraphs aim to restrict the presentation of specific concepts, chosen methods, and developed solutions to smart devices for vehicular applications. Nevertheless, a multi-disciplinary approach is preserved with some conceptual extensions written in quotes.
4.1. Placing AI in a Distributed Computational Environment
The resource-intensive modern methods of computational intelligence [
32] often involve cloud computing with theoretically infinite processing power and storage capacity. In
Figure 4, these two aspects of computing are distinctively considered.
Centralized versus localized computing extends the cloud computing/edge computing problem to cloud AI/edge AI [
33]. Modern telecom technologies of “cyber-critical communications” ensure time constants that are much smaller than those needed for vehicular applications.
Placing AI near the engine, at “the edge” of a test-bench or vehicular appliance, is a multi-criterial decision that considers mainly sensor/transducer signal conditioning, data acquisition, multi-point logging, and pre-processing for compression.
The problem is where the AI-driven “assisted” decision (for real-time automated control) is to be taken. The solutions presented in this paper demonstrate that state-of-the-art technologies enable de-centralized optimal decisions via “edge AI” (
Figure 4).
In our vision, smart devices with artificial intelligence should be modelled (in a top–down approach) as FSMs (finite state machines).
Appendix B details event-driven models for these smart devices with AI.
4.2. AI Algorithms Applicable to Virtual Sensors
The extensive AI taxonomy [
34,
35] starts from the challenging paradigm of algorithms that enable computers to solve problems they were not explicitly programmed for.
4.2.1. Artificial Neural Networks
Machine learning (ML) frequently uses ANNs that implement synthetic neurons similar to the cells of the nervous system. The similarity is structural (an ANN is organized into input-/hidden-/output-layers) but mainly functional and based on the ability to learn. As electro-chemical neuro-channels enforce synapses, ANNs can iteratively grow—via different types of successive approximations—some weights to endorse inputs’ specific contributions to intermediary results or outputs. What is making an important difference between ANNs and the computing of simple linear combinations is the “activation” of artificial neuron (weighted sum node) output.
This is very specific to neural signal propagation in the human brain cortex and is fundamental for “triggering” in event-driven models (detailed in
Appendix B). To yield the “activated” neuron’s final output
y(
x)
, an “activation function” is applied to the preliminary weighted sum
x in order to produce the actual output
y [
36]. For instance, a simple choice that frequently occurs in the next sections of the paper is that of activating the output
y = x only for positive
x and to inactivate it,
y = 0, for the rest. This very simple activation function, ReLU (rectified linear unit) is typical of simple “half-wave rectifiers”. The advantage of being linear is counter-balanced by the disadvantage of being uncompressed.
One of the most useful activation functions is the hyperbolic tangent, y = tanh (x). It compresses the neuron’s output between -1 and 1 and is also quasi-linear in reproducing x around 0 (tanh (x) ≈ x for x ≈ 0, as its derivative tanh’ (0) = 1). There are many activation alternatives; one of them is the “sigmoid”, y = 1/(1 + e−x), a “scaled” (dividing by 2) and “shifted” (finally adding ⅟₂) version of tanh. For x << 0, the sigmoid is similar to ReLU (that “inactivates”, or nullifies, y for a negative x) and similar to tanh for greater positive x >> 0, with an y also compressed to 1.
The importance of such compression is related to the preliminary “statistical” compression of an ANN’s main inputs (a procedure detailed in the next sections of the paper), which practically becomes a pre-normalization, by first subtracting the mean and then dividing the difference by σ, the standard deviation.
Each normalized sensor output that feeds the ANN is then “statistically 0-centered and compressed” between -1 and 1 (spurious extreme values—possibly caused by sporadic un-systematic errors—are less important). This is very practical for a better use of the ENOB (effective number of bits) at the ADC (analog-to-digital converter) obtained by pre-conditioning the signals (to adapt a sensor’s range to the ADC range), as detailed in
Section 6.
The training of an ANN consists of the iterative optimization of the above-mentioned neurons’ weights.
Conventional ANNs use “feed-forward” computations results—from the inputs to the neurons of the first “hidden layer” and so on up to the neurons of the last hidden layer that feed the output(s) neuron(s). In this case, the usual “learning process” uses the “back propagation” (BP) of the updating increments of the weights.
These updates aim to minimize the successive approximation errors between the ANN outputs and the actual (observed and measured) output values of the training set [
37]. Iterative optimizations are done according to a chosen criterion, e.g., the minimization of MAE, the mean absolute error, or the minimization of the MSE, the mean squared error. For
n-dimensional errors
e, MAE and MSE correspond to the
L1 and
L2 norms, respectively, where
Lp =
[
38].
As for the optimization method, iterations aim to reduce (a “descent”) the error (“the gradient”) in a “stochastic” way via successive approximations.
For edge AI solutions, the chosen method was SGD (stochastic gradient descent), which computes a new modification of each ANN weight as a linear combination of the previous modification (its coefficient being the so-called “momentum”) and of the gradient itself (its coefficient being the “learning rate”). In our case, the ANN inputs were load (L), speed (S), and EBP (p), and the output was the effective power (Pe).
4.2.2. Classifier Trees
An important alternative to an ANN is the linear regression tree—each branch (computing a weighted sum with an own set of coefficients) is like an “ANN without activation” decision; this decision is now represented by the switching to another specific branch.
The regression of sub-domains is apparently profitable for training datasets like the ones produced at an engine test-bench with specific load and/or speed “steps”. We explored this alternative of classifier trees using WEKA (Waikato Environment for Knowledge Analysis) [
39]. This software environment was used, in the broader context of this paragraph, in several AI algorithm assessments as a comprehensive “workbench for machine learning”.
WEKA encloses many classifiers and regressors (Bayes classifiers, SVMs (support-vector machines) for supervised ML, etc.), as well as decision trees, e.g., ID3 (Iterative Dichotomiser type 3) or C4.5 (improved version of ID3 of the CART—classification and regression tree— type). In other fields of data analytics, e.g., clustering, WEKA offers methods like k-means (for groups of k measurement means) and EM (expectation–maximization) (of the likelihood of a statistical model estimated parameters with the observed data).
The evaluated classifier tree (applied to the engine test-bench dataset), belonging to a fifth category (in reference to the above-mentioned type 3 and 4 algorithms) builds a model (M) via a “divide et impera” procedure, presented in
Figure 5. We chose the optimized M5 method (M5P, or the M5 method that has been “pruned” or “trimmed”) that starts with a preliminary data sub-domain division and then applies the linear M5 model to each such sub-domain. The M5P alternatives offered by WEKA included RandomTree (random successive approximation of the tree), RandomForest (random combination of trees), and RepTree (repetitive combination of several trees).
Nevertheless, precaution is needed in adopting tree models: even if training data may exhibit a discrete structure for one or more inputs, this may only be frequent on experimental benches (e.g., in the standard testing of engine duty cycles and/or step-wise dynamometric brake regime) but not in road vehicles use with continuous load and speed variation.
Such a “model contamination” due to a pseudo-discrete input data structure is similar to the “memory effect” caused by scarce training sets; their number can be as low as the number of nodes available in the ANN models—an odd synthesis could even allocate an unwanted individual neuron activated only for the respective single set of inputs and delivering just the particular training output.
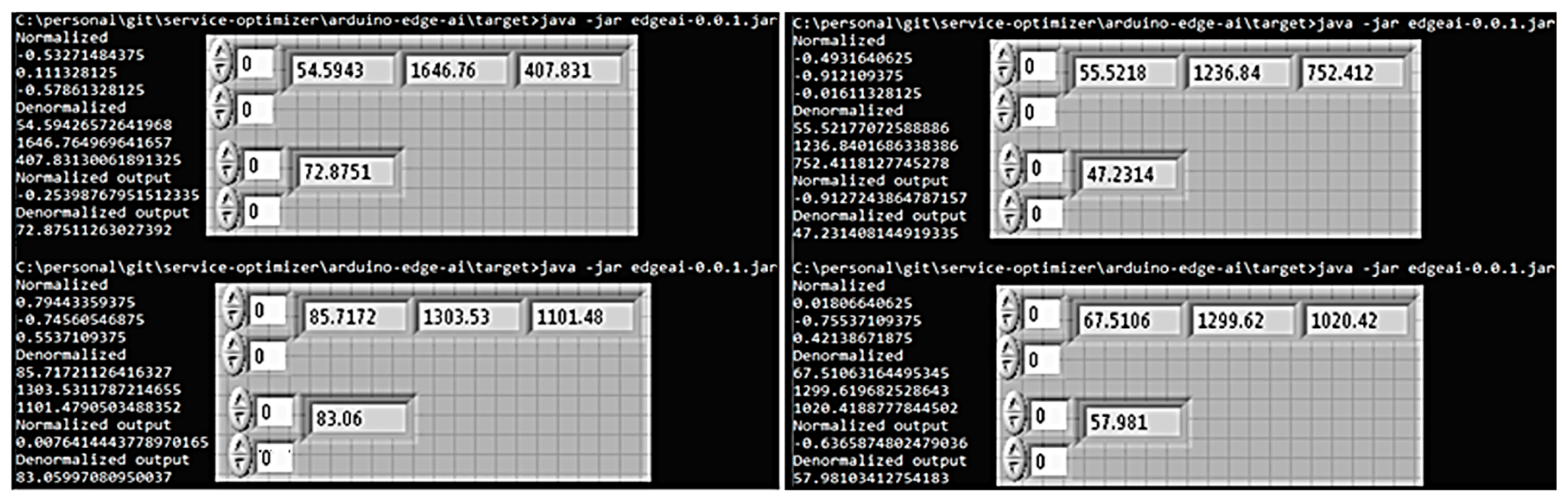
6. Edge AI Implementations
6.1. Compact ANN Implementation—“AI in a Nutshell”
The objective of this smart device implementation—edge AI for virtual sensing—is a minimal computational foot-print for a “hard-coded” ANN, with coefficients included directly in the firmware, based on a very low cost and compact board (around 10 cm
2). This proposed “AI in a nutshell” is built around a popular SoC (system on chip) and is much smaller than usual SBCs (single board computers). The experimental data, introduced in
Section 3 and detailed in
Appendix A, had 246 sets of
N + 1 = 4 test-bench measurements: load (%); rotational speed (rpm); p—EBP (mmWC); Pe (the effective power; in kW). Out of these, 184 sets were randomly chosen for training, and the rest of 62 sets were kept for testing (
Table A2). The chosen architecture of the compact ANN (with two hidden layers) is presented in
Figure 14.
In
Appendix A,
Table A3 presents the normalization reference parameters. It is assumed that the statistics were meaningfully contained in the comprehensive training data. The mean and the standard deviation (σ) values were used extensively, not only for the preliminary normalization but also for the final de-normalization in the virtual sensor. Any future “statistic re-calibration” of the edge AI smart device should update not only the ANN weights but also these de-/normalization reference parameters.
The programming system chosen for development of the compact ANN is given in
Table 2.
The “AI in a nutshell” demonstrator was implemented with a cost-effective micro-module, TTGO™, recently marketed by LILYGO, built around a “WROOM-32” module produced by Espressif [
45] and the well-known ESP32 SoC. Edge-computing local resources are: 4 MB flash program memory, 8 MB PSRAM (pseudo-static RAM) of working memory, and a CP2104 UART (universal asynchronous receiver-transmitter) chip.
The outstanding ESP32 capabilities are the WiFi (802.11 b/g/n) and Bluetooth 4.2 BLE (low energy) protocol with BR/EDR—basic rate/enhanced data rate.
A convenient organic LED (OLED) display (128 × 64 pixels) is managed by an SSD1306 I2C (inter-integrated circuit) interface chip. As seen in
Figure 15, the micro-module also has a T-camera, a PIR (passive infra-red) AS312 sensor and a BME280 barometric environmental sensor.
Such a versatile LILYGO micro-module does not have many extra GP-I/O (general purpose input/output) pins left, so three direct wired connections were added to the two multiplexed inputs of ADC2 (GPIO 2 and 26 to channels 2 and 9) and, respectively, to channel 6 of ADC1 (GPIO34)—for this last connection, the 10 kΩ pull-up to 3.3 V was interrupted.
In order to comply with the 3.3 V supply voltage requirements of this CMOS (complementary metal-oxide-semiconductor) board and many others, the three ADC inputs had to be brought, in advance, in the 0–3.3 V interval. This means they could not be taken directly from the outputs of different kinds of sensors and needed an intermediate signal conditioning, detailed in
Section 7.2 and
Appendix E.
For the above-mentioned chosen ANN architecture, in both hidden layers, the chosen activation function was ReLU (without compression but linear and, most notably, the simplest to implement in a compact code).
As introduced in
Section 4.2.1, the chosen BP optimization method was SGD, with the NN (neural network) benchmark “nn.L1Loss” (minimizing MAE, according to the L1 norm, is one of the most robust criteria).
The value of the momentum was 0.9, and the learning rate was lr = 0.001.
After 5000 “epochs” (the number of BP optimization iterations) running on the normalized training data (182 sets), 10 × 3 = 30 coefficients “hidden1_weight” coefficients and 10 × 1 = 10 “hidden1_bias” terms (for each neuron’s linear combination of 3 inputs, a free term is added) were obtained for the three inputs in the 10 neurons of the first hidden layer. For the second hidden layer, 10 × 10 = 100 coefficients “hidden2_weight” coefficients and 10 × 1 = 10 “hidden2_bias” terms were computed.
In the ANN run, the main ANN “exploitation phase” (and also for the testing detailed in the following), the coefficients obtained after the training phase could be grouped in tables for a compact matrix calculation. The [1 × 1] result was not obtained via the simple multiplication (starting with the column vector [3 × 1] of the three inputs written to the right in the following product) [1 × 1] = [1 × 10] ∙ [10 × 10] ∙ [10 × 3] ∙ [3 × 1]. Instead, as seen in
Figure 16, there are needed three preliminary paddings with 1 elements at the right-side factors: for the [3 × 1] input and for the two [10 × 1] activated hidden layers’ outputs. Accordingly, it was needed three times, a correspondent padding of the weights arrays with the column vectors of the biases - at the left-side matrix factors:
As depicted in
Figure 17, a 10 × 4 “layer1Weights” array was obtained from the 10 × 3 = 30 coefficients “hidden1_weight” array padded with the 10 × 1 = 10 “hidden1_bias” column vector, and a 10 × 11 “layer2Weights” coefficients array was obtained from the 10 × 10 = 100 “hidden2_weight” coefficients array padded with the 10 × 1 = 10 “hidden2_bias” column vector.
More than half of this very compact code was represented by the embedded coefficients—an efficient solution that does not require reading of .CSV or similar formatted tables from an “external file system” that would misuse the reduced resources of such a tiny board.
6.2. NVIDIA Mini-System with Hardware Acceleration of AI Computing
A “cutting-edge” solution—aiming to demonstrate one of the most powerful AI resource concentrations at “the edge” of the network—was based on the NVIDIA Jetson Nano (V3); see
Figure 18. Though this development kit is remarkable compared with the features of a usual SBC (single board computer), it is quite cost-effective (priced less than twice that of an average SBC).
The mini-system is driven by a four-core advanced RISC (reduced instruction set computing) machine “ARM” A57 processor with 4 GB RAM 64 bit LPDDR4 (low-power double data rate) with 25.6 GB/s), multiple high efficiency H.264/H.265 video codecs, Ethernet 10/100/1000BASE-T, and many other general-purpose interfaces. The dedicated AI software was installed on top of the Linux OS with TensorRT libraries for “deep learning”.
The main sub-system was the 70 × 45 mm Jetson Nano SOM (“system on module”), with a special parallel NVIDIA “Maxwell” processing unit. This hardware, directly allocated to ultra-fast AI computations, has a structure inspired by parallel architectures of the graphic processors with GPC (graphics processor cluster) chips—each cluster having 5 SMs (streaming multiprocessors). Parallelism is essential for the “systolic” ANN computations, given the neurons placement and the “wave” transmission of data flows for the forward propagation (FP).
The Maxwell architecture sustains the “neuromorphic computation”:
- −
The SMs have processing units with Kernel preemption (a compromise between the prioritization and parallelism of the processes). These units are called “CUDA (compute unified device architecture) cores”, with each core having two computing sub-systems (for integers and for real numbers with floating point) and 16 load/store blocks.
- −
A Maxwell chip has 128 CUDA cores interconnected by a fast NVLink bus which has a high bandwidth memory (HBM2 - up to 59.7 GB/s).
- −
Each SM has 64 K (=65,536) registers of 32 bits and can run up to 64 warps (a “warp” is a grouping of 32 threads for the parallel execution of an instruction).
In all the software part of the NVIDIA-based implementation, described as follows, some capabilities that were considered, until now, as cloud-specific could be observed. For instance, this edge-computing solution used its own embedded server exactly as described in
Section 5.3. Most remarkably, it transfers data using local web services for methods invoking API and for “publishing” results. This complies with REST (REpresentational State Transfer) [
46], the modern approach of the state-driven models (mentioned in
Appendix B). The “RESTful” transition in/out signaling is done via HTTP and parameters in/out are embedded in GET (or POST) messages’ attributes directly in the URLs.
On the NVIDIA Jetson Nano, an LXDE—light-weight X11 (version 11 of the X Windows display protocol)—DE (desktop environment) was installed for intranet(/internet) access compatible with the X2Go server. In this environment, with “pip3 install” commands, the following were configured: xboost, pandas, sklearn (like in
Section 5.3), and the flask server (that enables ANN computations to be invoked via APIs like in the cloud solution described in
Section 5.3 but now locally). Prior to xboost installation, with the “cmake” command, compilation was done with the explicit activation of the CUDA-based hardware acceleration: cmake. -DUSE_CUDA=ON. In
Figure 19, it can be seen how the flask server is started (listening on port 5000 and exposing its services to the localhost) and how the HTTP command GET is invoked via the above-mentioned xboost API: the AI method “predict”. This method computes Pe for ANN inputs given as attributes of the GET message—L = 100 (%), S = 1000 (rpm), and p = 80 (mmWC)—included in the URL written in the address bar of the browser.
Using a DDNS (dynamic domain name server) a simple port forwarding may be configured on a local router to extend intranet-to-internet access using a public IP address. This modern approach became “distance-agnostic” (with the same transfers locally or remotely)—a real ubiquitous and mobile computing solution that could be installed either on the engine test-bench or on vehicles.
8. Discussion
The experimental investigations performed on the engine test-bench confirmed the influence of EBP on engine performance that had been previously reported in literature. Within the limits of the EBP variation of the present study, which was 3000 mmWC (=29.43 kPa) at the rated speed and load, the maximum engine power loss reached 3.62%, the BSFC increased with 7.32%, the exhaust gas temperature rose with 100 °C, and the boost pressure decreased with 30% (
Appendix A).
The implementation of AI into vehicular sensor data processing regarding the computational allocation (local and/or centralized) in the distributed environment was discussed.
The cloud-/edge-computing (processing–storage–tele-transmission) was extended in a cloud AI/edge AI paradigm that was used for the next sections.
The state-control approach of smart devices (detailed in
Appendix B) can be expanded to the ECUs (electronic control units) that also have on-board real-time diagnosis features and optimal decision capabilities.
All the needed parametrization can be adaptive (mostly via ANN), and all the needed transitions can be decided upon with classifiers and other AI means. Such a finite state machine model can also distribute the localized/centralized tasks according to the edge AI/cloud AI extension of the edge-/cloud-computing paradigm.
The second part of
Section 4 presented the AI algorithms applicable to virtual sensors, emphasizing ANN and then classifiers and regressors. The resource-intensive parts of AI computation were considered, at first, in the cloud with “infinite” processing power and/or storage capacity (
Section 5)—the machine learning parts starting with training of the models and up to the adversarial comprehensive model choice “MaaS” (Model as a Service) introduced in
Section 5.1 dedicated to MATLAB in the cloud.
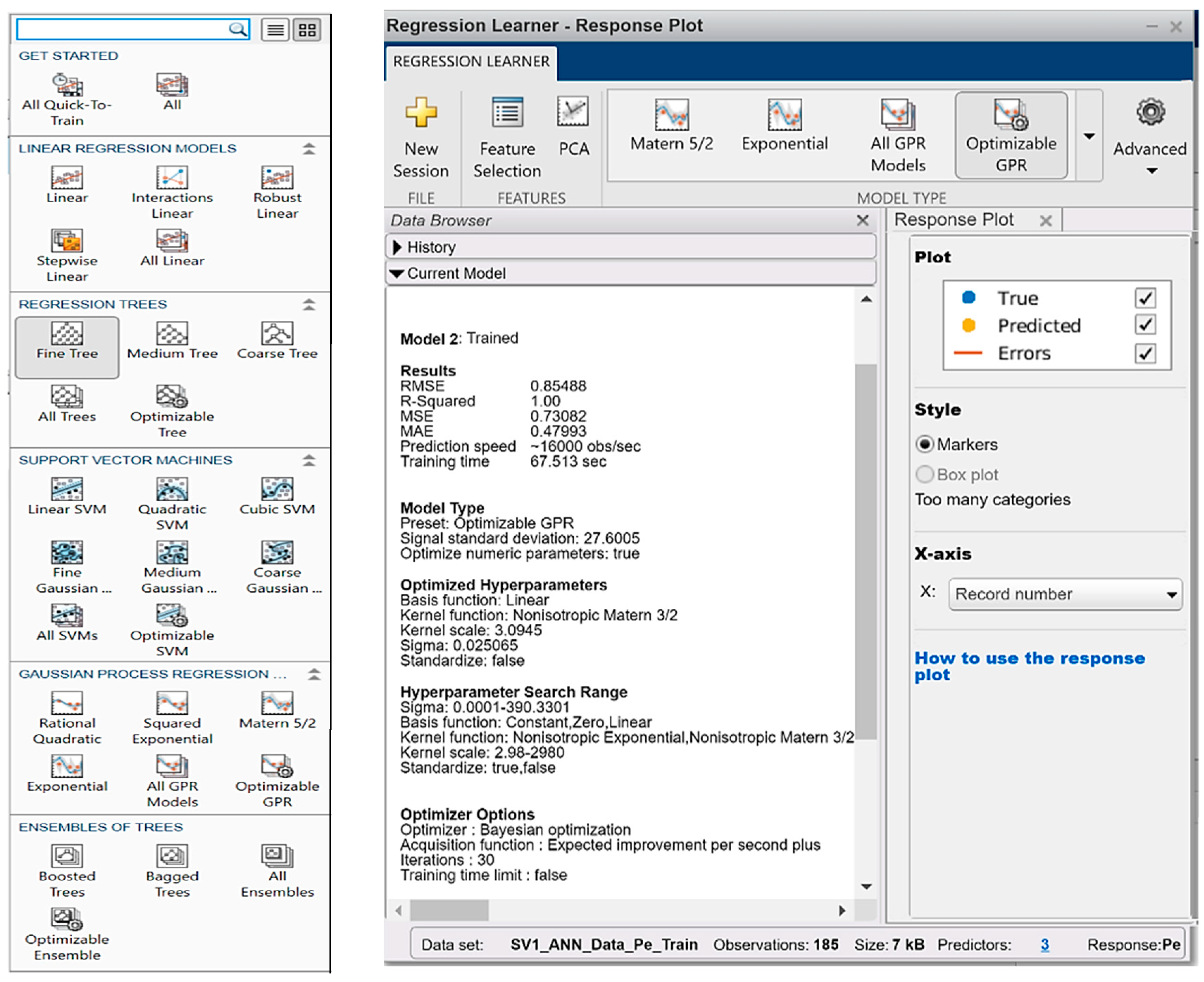
On the unique training and testing data set used in all the use-cases, MATLAB has chosen optimized GPR (Gaussian process regressor) as the best MaaS invoked via API (application programming interface).
The next cloud AI solution was a Keras API for ANN. The backend computing was based on Tensorflow libraries handling the main multidimensional data arrays as “tensors”. It was obtained a competitive “dense” ANN, with many neurons per layer—a step towards WNN (“wide neural networks”) up to the modern DNNs (“deep neural networks”) with many layers.
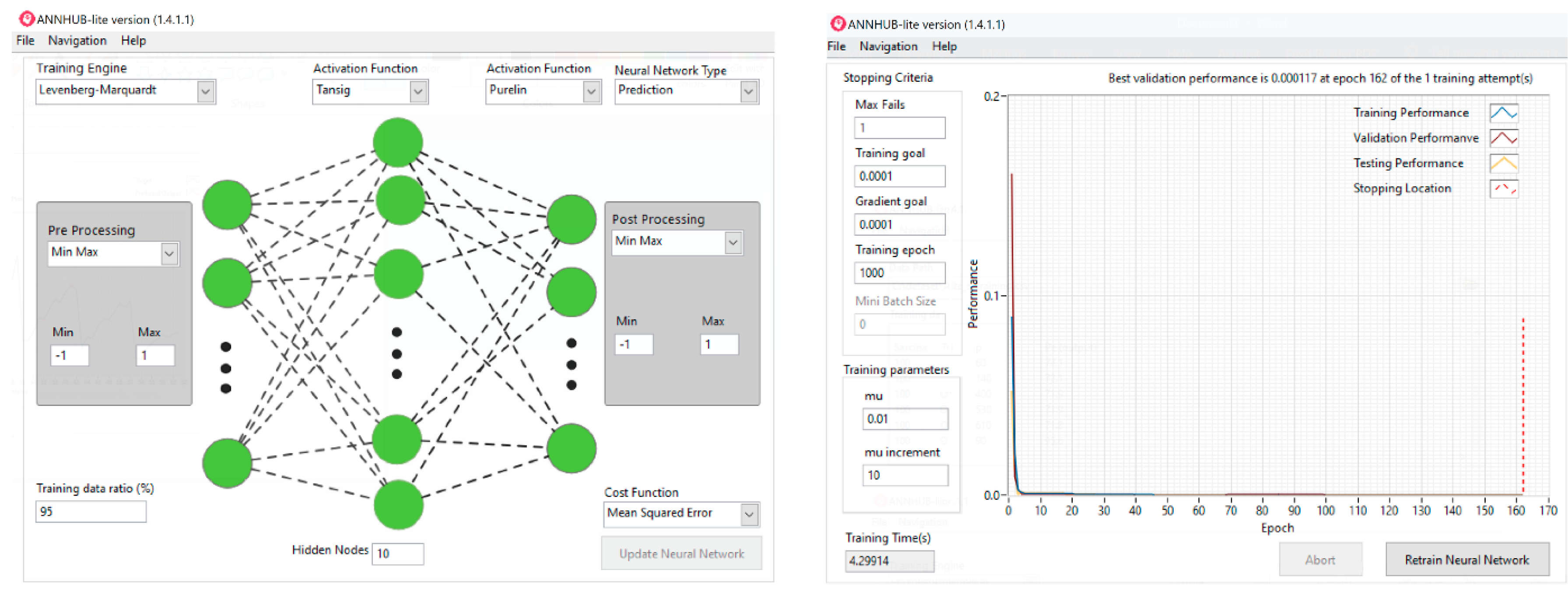
The other two API-accessed cloud AI solutions were based on “XGBoost” (XGB eXtended Gradient Boosting—of iterative optimization classifiers) and on the ANNHUB access to an effective Levenberg–Marquardt ANN.
The cloud AI approach always has the advantage of MaaS computational-intensive features. Besides the example of
Section 5.1, the solution of
Section 5.3 has also an impressive “automatic” option, GridSearch (offered by the dedicated Sklearn library) for the optimal choice out of a bunch of models trained with more combinations of parameters.
The MaaS features can be considered a future-proof capability in the trend of “continuous optimization” (powered by AI) of the running algorithms that could extend the nowadays “continuous deployment” of micro-services in the cloud.
Accessing AI cloud computations can be used also in mixed solutions, starting with edge DAQ (data acquisition) and data logging in the cloud and up to “AI caching” in the cloud (of the edge computations)—a measure that is useful for intermittent connectivity that is frequently seen in vehicular use-cases.
Even the most compact micro-boards described in
Section 6 could easily transfer the
N locally-acquired sensor outputs to the cloud that should return the
N + 1 (virtual sensor) output in real-time as result of a prediction calculation.
The two solutions proposed based on the same virtual sensor use-case are state-of-the art (referring to the actual market).
The edge AI mini-system with hardware acceleration can take over whole AI types of computing tasks; part of these computing tasks are usually present in the cloud as the model training phase (even for the above-mentioned DNN).
The NVIDIA Jetson Nano small-form factor mini-system, managed by an ARM A57 four-core processor (running a full range of AI software and a Flask micro-server on top a Linux OS) is built around a NVIDIA Maxwell SOM (system on module). In
Section 6.2, it was demonstrated how this solution can locally perform the complete range of XGBoost computations that were first introduced as an accessible cloud AI solution (
Section 5.3). Most of the cloud AI solutions presented in
Section 5 were trained offline. The SOM implementation (
Section 6.2) is the only one powerful and versatile enough for real-time edge–cloud–edge future solutions, with the training data upload/(re-)training of the model (and adversarial choice or optimization in the cloud)/download and running of the most advanced (updated or new, not only ANN) versatile model that might also have in-depth scalability. Nowadays, as smartphones have CPU/GPU/APU (central/graphical/AI processing units), this paper is endorsing an edge AI vision on engine instrumenting and control. A Jetson Nano stand-alone “palm” mini-system, even if operating locally, preserves a cloud-like server control that is “distance agnostic”. This means it is feasible a scenario of training data to be fetched from the complete instrumentalized testbed directly to such a small Jetson Nano possible “AI add-on” to the ECU, with a new model (re-)training, even for the limited update needs of “statistical re-calibration”.
At the other extreme, the very compact edge AI solution “in a nutshell” built around a super-miniature board of the TTGO™ series manufactured by LILYGO is centimeter-sized and includes also an OLED mini-display for the three inputs (load, speed and pressure) and the output (Pe). At this super-miniature extreme, though the micro-board includes a tiny digital camera, too much image processing is impossible. Currently, there are promising efforts to optimize AI software libraries—e.g., the new Arduino TinyML (“machine learning”) suite that allows for the compilation of ML models with a new TensorFlow™ Lite sub-set and code upload on micro-modules managed by the Arduino IDE (“integrated development environment”).
The compact edge AI implementation of the smart device directly includes the ANN coefficients (weights and bias) in the code. These coefficients might be simply embedded in the firmware of the virtual sensors. As shown in
Section 7.2, any calibration problem becomes a software update problem. Assuming that inputs’ statistics (mean and std dev) do not change in the long-term (without any retrofits in the exhaust and other auxiliary systems of the engine), such a “statistical re-calibration” of the smart devices is seldom needed; in this cases it is sufficient a simple ANN retraining using the fully instrumentalized test-bench. For instance, for the “AI in a nutshell” compact solution of
Section 6.1, the new coefficients (the two arrays illustrated in
Figure 17) that should be re-loaded in the Flash memory of the micro-board are updated in the code.
An intermediate edge AI solution (a compromise between implementations like those of
Section 6.1 and
Section 6.2) could involve a “bare-metal” SBC (single board computer—e.g., the very popular Raspberry Pi) that runs a dedicated Docker container. Such a container (the ideal compromise of the virtual machine principle and of the stand-alone compiled executable code) could integrate the environment strictly required for the execution of the AI model without the need to separately install, for instance, Python and the Tensorflow libraries specific to AI.
Cloud AI solutions do not usually provide access to a trained model. This should not be a problem due to API access—a convenient alternative used even for the advanced edge AI solution of
Section 6.2 (that, as already mentioned, shares the XGBoost computations with the
Section 5.3 cloud AI solution).
Even if known and “finite” at the end, a cloud-trained model might need intensive computing in order to be chosen and calculated. However, as shown in
Section 4.2.2 (where a tree classifier was developed with the M5P algorithm of WEKA), precaution is needed when adopting regression models (
Section 5.1,
Section 5.3, and
Section 6.2) that are susceptible to contamination by a pseudo-discrete structure of the training data. From this point of view, the ANN solutions (
Section 5.2,
Section 5.4, and
Section 6.1) could be preferable.
ANNs have other advantages—mostly if the coefficients are individually known and handled for different needs of the implementation (e.g., embedded at the quasi-firmware level in the solution of
Section 6.1). ANNs are prone to extrapolations (e.g., to predict the output for inputs that are beyond the range of those use in the training phase). In a classifier tree (mostly with an unknown model—e.g., cloud AI), there is still the risk such inputs not having a branch into which to be routed—such inputs might be considered “outliers”, and the computing system may decide to drop them out. For instance, if EBP is distanced with more times σ from the mean, an ANN may still give an estimate of Pe and predictable behavior for an extended input range, that represents a significant practical value for the AI-based virtual sensor. For example, considering the edge AI solution of
Section 6.1, the re-scaling of the 12 bit outputs of the ADC should be done using a scaling numerator greater than 2048 or even than 4096. The pre-conditioning of the signal (according to
Section 7.2) should be done accordingly with a greater input divider factor that compresses more of the EBP sensor’s output.
Regarding the computational overhead trade-off with the cost of the solutions, increasing the ENOB (effective number of bits), increasing the sampling frequency or even the number of artificial neurons should be limited by some merit factors like 1/(sensors accuracy) at the test-bench. Such limitations mean that solution assessment should consider not only the algorithms performance (the computational efficiency) or the accuracy of the estimations but also practical aspects like the positioning (edge-/cloud-AI) and all the telecommunication issues and the deployment (up to the above mentioned “continuous optimization” according to the modifications of data characteristics).
9. Conclusions
This paper is centered on the influence of EBP on diesel engine performance parameters. Experimental results on instrumentalized engine test-beds were supplied as training data to ANNs and regressors. These could be further used in stand-alone reliable smart devices for the accurate prediction of power loss versus externally applied EBP in a whole load/speed engine operation. Two practical virtual sensors were implemented as cost-efficient edge-AI solutions. One has an extreme local computational performance (AI with hardware acceleration). The other one has an extreme compactness (hardware miniaturization and minimal code).
The main benefits of the research work are emphasized below.
The experimental investigation has enriched the relatively scarce literature on engine EBP-power dependency.
The continuous development software paradigm was extended to the continuous optimization concept beyond the ANN versus regressors traditional trade off. Though the pseudo-discrete nature of decision trees and outliers’ treatment favored the ANNs, it was shown that the automatic selection or update of AI models is now possible in the cloud.
The implementations were framed by an extended range of criteria and a broader perspective that includes benchmarks, scalability, activation, signal conditioning, and computational resource allocation for new requirements like extrapolation and calibration.
Striving for constructive details, the state-of-the-art practical solutions aimed to rise the TRL (technology readiness level).
The novelty brought by the present work is as follows.
To the knowledge of the authors, the application of AI in engine power loss caused by EBP has not been previously reported.
The cloud AI–edge AI approach supported the applied research of artificial intelligence allocation in the distributed environment.
The MaaS adversarial choice of the AI model in the cloud was demonstrated with two APIs (MATLAB and XGB).
The design flow was extended in a distance agnostic AI chain using Jetson Nano. This complete demonstrator with hardware acceleration could be an ECU add-on capable of the real-time updating of model parameters and even of model type; the flask server solution and seamless XGB regressor download illustrates a “model-agnostic” capability.
The compactness of the hardware in the embedded micro-system demonstrator was complemented by a code-optimization with ANN coefficients in the firmware and put an “embedded AI” solution into practice. It was shown that these coefficients are suitable with the sporadically offline statistical recalibration of the “AI in a nutshell” smart device.
During the applied research on vehicular smart devices driven by artificial intelligence, a real effervescence of innovative solutions was very obvious—the “AI cloud inside” printed on some commercial modules is still a wish today, but it is almost certain tomorrow.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


























