DisKnow: A Social-Driven Disaster Support Knowledge Extraction System



Abstract
:1. Introduction
2. Related Work
2.1. Social Media for Disaster Management
2.2. Disaster Classification
3. Proposed Approach
- Tweet Extraction and Filtering: The first step of our pipeline is the extraction of tweets and their related information, from the social media Twitter. To avoid overloading the system, these tweets are gathered through periodic API calls with several filters on them. These filters include the tweets’ language and geolocation, which is done by defining a center and a radius, and calculating, for each tweet, the geodesic distance between the tweet’s location and the defined center. Both the tweet’s location and defined center are geocoded using data from OpenStreetMap [40], allowing for the computation of the mentioned geodesic distance. Relevant tweet information, such as each tweet’s posting datetime and full text is also saved for further use.
- Tweet Preprocessing: This step focuses on cleaning the textual content that is specific to tweets. As we have previously mentioned, one of the challenges of using social media information, is the huge amount of noisy data it pertains. This processing pipeline uses hand-made techniques, such as regex rules, that aim to take care of specific tweet noise, such as retweeting information, hyperlinks, user mentions, and hashtags. Firstly, any information regarding retweeting, hyperlinks, and user mentions is removed, and secondly hashtag symbols are removed and their content is split by upper-case starting words.
- Translating: Translation is a natural step here, as DisKnow is being implemented as a component of a European project (grant agreement n833088) which aims to be put into effect in several countries. With this in mind, and to be able to use state-of-the-art models, which mostly exist for English, the input language is firstly detected, and then the cleaned text is translated to English. This is done using Google’s Neural Machine Translation (GNMT) [41], which consists in a deep LSTM using both residual and attention connections. This model has achieved a BLEU [42] score of 38.95 in the commonly evaluated en-fr translation task, with a vocabulary size of around 32,000 words. It is also reported to reduce translation errors by more than 60%, when compared to its competition, the Phrase-based Machine Translation (PBMT) models [41].
- Text Preprocessing: Preprocessing is an essential step for natural language algorithms. Although activities like Named Entity Recognition (NER) benefit from inputting entire texts with punctuation and the original formatting, most algorithms benefit from further processed text. This step focuses on additionally preparing tweets for Disaster Extraction. It starts by tokenizing the tweets using Natural Language Toolkit (https://www.nltk.org/) (NLTK) algorithms, and proceeds to using regex rules to lowercase all the tokenized words. Lastly, English stop words are removed, as to lessen the noise inputted to the following steps. Although lemmatization or stemming are also frequently used, in our case we found that our Disaster Extraction algorithm slightly benefited from not using them.
- Named Entity Recognition: NER is used as a tool to extract entities from the aforementioned tweets. These entities can be person names, companies, geographical locations, times, dates, etc. Their role is to complement a detected threat, in order to give users more insight. For this purpose, our system makes use of Spacy (https://spacy.io/) NER pipeline. As this pipeline is open, we are able to add new layers to it, to better embrace specific disaster detection characteristics, such as detailed locations and local businesses.
- Disaster Extraction: The next step is, without any doubt, one of the most critical steps of our system. It consists of two sequential tasks: Firstly, classifying tweet relatedness to disasters, that is, classifying if a tweet’s content is referring to a disaster event. Secondly, classifying the disaster type a tweet is referring to. To accomplish both of these tasks we have implemented two distinct convolutional neural networks (CNNs). The first CNN takes care of the first task, and if it classifies the tweet as being related to disasters, the second CNN then classifies which disaster it is, out of a predefined set of disasters it has been trained with, which are fire, flood, earthquake, explosion, and none. This last category exists as a double-check, seeing that the first CNN can detect disaster events that are not modeled by the second CNN. The second neural network outputs a list of confidence levels regarding all disaster classes.
- CrisisLexT6 (https://crisislex.org/data-collections.html#CrisisLexT6);
- CrisisLexT26 (https://crisislex.org/data-collections.html#CrisisLexT26).
- Threat Object Generation: The second to last step of our pipeline consists of joining all of the information extracted from the previous steps. That is, the tweet information extracted by the Tweet Extraction and Filtering module, all of the entities extracted by the Named Entity Recognition module, and the threat type classified by the Disaster Extraction, are all combined to form a disaster object. This step is essential, as it creates a sense of identity for the detected disasters, joining their occurrences to all of the information that define them. We consider the location, date, and type of threat to be the minimum necessary information for creating and comparing a threat. Therefore, this module also serves as an extra filtering phase, as it discards any threats the system has not been able to extract enough information from.
- Knowledge Base Integration: Lastly, the detected disasters must be included in our knowledge graph. This step involves all validations regarding the previous existence of our gathered data, as well as the creation of new nodes and relationships between them, to express the identity of the extracted disasters in a way that facilitate human consumption and future system integrations. To further deal with social media unreliability, all disaster nodes have an attribute which is incremented when the same disaster is detected from different tweets. This attribute can then be used as a detection threshold, to allow for better filtering of relevant threats. If new information regarding an already existing disaster is extracted from the previous steps, it is also validated and then connected with that disaster. This mechanic allows for our system to be continually learning, expanding its knowledge, and bettering the knowledge it already has.
4. Evaluation
4.1. Disaster Extraction Algorithms
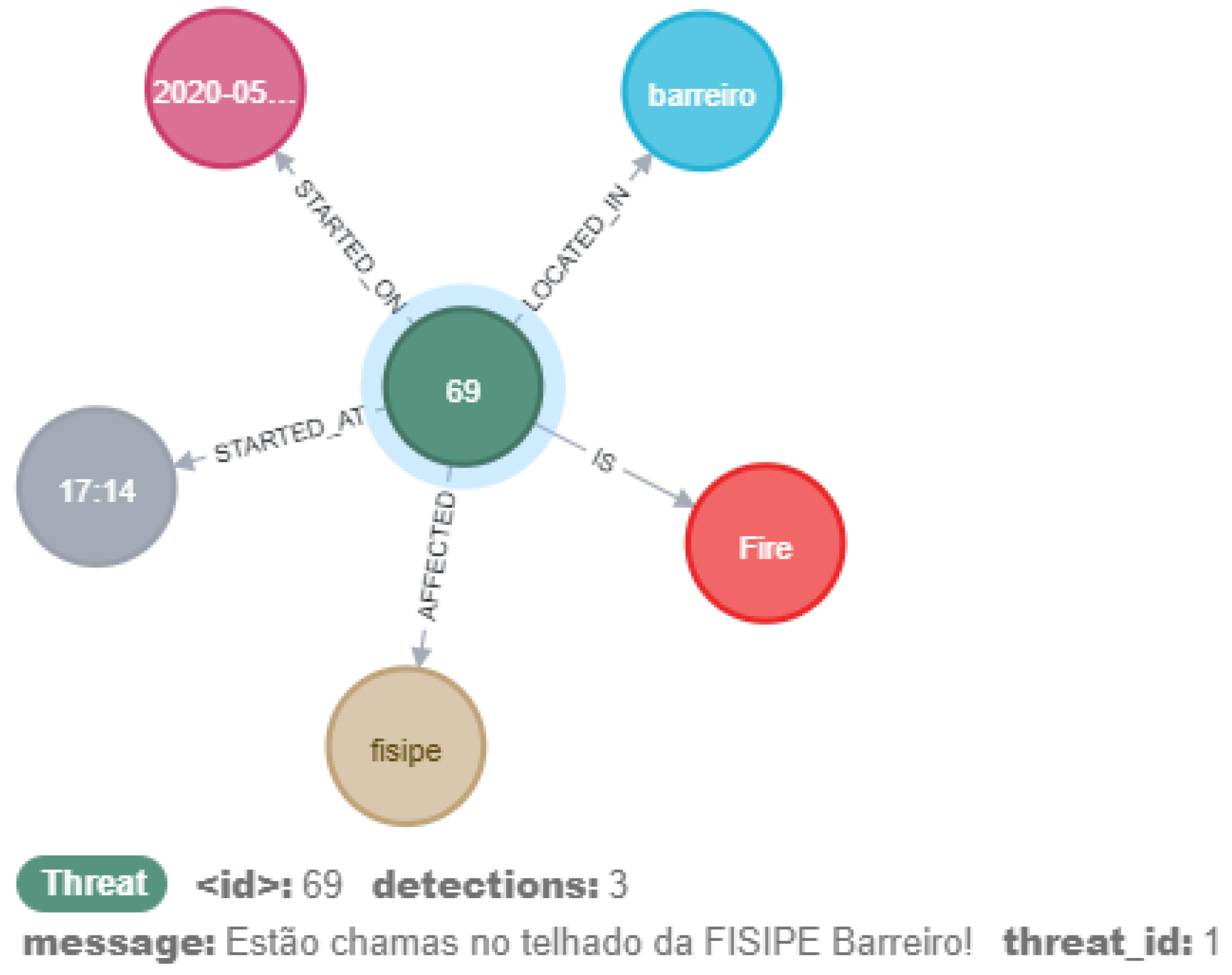
4.2. Top-Down Demonstration
- Estão chamas no telhado da FISIPE Barreiro!
- Au secours ! Fisipe brûle à Barreiro
- #Chamas #FISIPE fogo no Barreiro!
- O incêndio da FISIPE espalhou-se para a loja da Vodafone do Barreiro
- #Catástrofe #Fogo O director da fábrica FISIPE Barreiro João Alberto ficou com queimaduras de 3o grau devido às fortes labaredas
- #Ajuda Está a transbordar água na Remax do Barreiro desde as 12h30. A Marta Almeida e a Fernanda Torre estão feridas
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dilley, M.; Chen, R.S.; Deichmann, U.; Lerner-Lam, A.L.; Arnold, M. Natural Disaster Hotspots: A Global Risk Analysis; World Bank: Washington, DC, USA, 2015. [Google Scholar]
- Poblet, M.; García-Cuesta, E.; Casanovas, P. Crowdsourcing tools for disaster management: A review of platforms and methods. In International Workshop on AI Approaches to the Complexity of Legal Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 261–274. [Google Scholar]
- Feldman, D.; Contreras, S.; Karlin, B.; Basolo, V.; Matthew, R.; Sanders, B.; Serrano, K. Communicating flood risk: Looking back and forward at traditional and social media outlets. Int. J. Disaster Risk Reduct. 2016, 15, 43–51. [Google Scholar] [CrossRef] [Green Version]
- Imran, M.; Elbassuoni, S.; Castillo, C.; Diaz, F.; Meier, P. Extracting information nuggets from disaster-Related messages in social media. In Proceedings of the 10th International ISCRAM Conference, Baden, Germany, 12–15 May 2013. [Google Scholar]
- Fohringer, J.; Dransch, D.; Kreibich, H.; Schröter, K. Social media as an information source for rapid flood inundation mapping. Nat. Hazards Earth Syst. Sci. (NHESS) 2015, 15, 2725–2738. [Google Scholar] [CrossRef] [Green Version]
- Rogstadius, J.; Kostakos, V.; Laredo, J.; Vukovic, M. A real-time social media aggregation tool: Reflections from five large-scale events. In Proceedings of the CSCWSmart Workshop at ECSCW 11, Siegen, Germany, 24–28 September 2011. [Google Scholar]
- Steiger, E.; De Albuquerque, J.P.; Zipf, A. An advanced systematic literature review on spatiotemporal analyses of twitter data. Trans. GIS 2015, 19, 809–834. [Google Scholar] [CrossRef]
- Williams, S.A.; Terras, M.M.; Warwick, C. What do people study when they study Twitter? Classifying Twitter related academic papers. J. Doc. 2013, 69, 384–410. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Rao, H.R. Twitter as a rapid response news service: An exploration in the context of the 2008 China earthquake. Electron. J. Inf. Syst. Dev. Ctries. 2010, 42, 1–22. [Google Scholar] [CrossRef]
- Tatsubori, M.; Watanabe, H.; Shibayama, A.; Sato, S.; Imamura, F. Social web in disaster archives. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 715–716. [Google Scholar]
- Trending, B.B.C. How the Paris Attacks Unfolded on Social Media. Available online: https://www.bbc.com/news/blogs-trending-34836214 (accessed on 20 May 2020).
- Vieweg, S.; Hughes, A.L.; Starbird, K.; Palen, L. Microblogging during two natural hazards events: What twitter may contribute to situational awareness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; pp. 1079–1088. [Google Scholar]
- Starbird, K.; Palen, L.; Hughes, A.L.; Vieweg, S. Chatter on the red: What hazards threat reveals about the social life of microblogged information. In Proceedings of the 2010 ACM Conference on Computer Supported Cooperative Work, Savannah, GA, USA, 6–10 February 2010; pp. 241–250. [Google Scholar]
- Starbird, K.; Palen, L. Pass it on? Retweeting in Mass Emergency; International Community on Information Systems for Crisis Response and Management: Seattle, WA, USA, 2010; pp. 1–10. [Google Scholar]
- Palmer, J. Emergency 2.0 is coming to a website near you. New Sci. 2008, 198, 24–25. [Google Scholar] [CrossRef]
- Busari, S. Tweeting the Terror: How Social Media Reacted to Mumbai. CNN International. Available online: https://edition.cnn.com/2008/WORLD/asiapcf/11/27/mumbai.twitter/ (accessed on 22 May 2020).
- Meier, P. Behind the Scenes: The Digital Operations Center of the American Red Cross. Available online: http://irevolution.net/2012/04/17/red-cross-digital-ops (accessed on 22 May 2020).
- Lamont, I. A Plane Lands on the Hudson River, and Twitter Documents It All. Available online: http://www.computerworld.com/s/article/9126181 (accessed on 22 May 2020).
- Graham, M. What Can Twitter Tell Us about Hurricane Sandy Flooding? Visualised. Available online: http://www.guardian.co.uk/news/datablog/2012/oct/31/twitter-sandy-flooding (accessed on 22 May 2020).
- Graham, M.; Poorthuis, A.; Zook, M. Digital Trails of the UK Floods-How Well Do Tweets Match Observations. Available online: https://www.theguardian.com/news/datablog/2012/nov/ 28/data-shadows-twitter-uk-floods-mapped (accessed on 22 May 2020).
- Kim, J.; Hastak, M. Social network analysis: Characteristics of online social networks after a disaster. Int. J. Inf. Manag. 2018, 38, 86–96. [Google Scholar] [CrossRef]
- Lanfranchi, V.; Mazumdar, S.; Blomqvist, E.; Brewster, C. Roadmapping Discussion Summary: Social Media and Linked Data for Emergency Response. In Proceedings of the 10th Extended Semantic Web Conference, Montpellier, France, 26–30 May 2013. [Google Scholar]
- Rogstadius, J.; Kostakos, V.; Laredo, J.; Vukovic, M. Towards real-time emergency response using crowd supported analysis of social media. In Proceedings of the International Conference on Human Factors in Computing Systems (CHI 2011), Vancouver, BC, Canada, 7–12 May 2011. [Google Scholar]
- Ahmed, A. Use of Social Media in Disaster Management. In Proceedings of the 32nd International Conference on Information Systems, Shanghai, China, 4–7 December 2011. [Google Scholar]
- De Longueville, B.; Smith, R.S.; Luraschi, G. “OMG, from here, I can see the flames!” A use case of mining location based social networks to acquire spatio-temporal data on forest fires. In Proceedings of the International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; pp. 73–80. [Google Scholar]
- MacEachren, A.M.; Robinson, A.C.; Jaiswal, A.; Pezanowski, S.; Savelyev, A.; Blanford, J.; Mitra, P. Geo-twitter analytics: Applications in crisis management. In Proceedings of the 25th International Cartographic Conference, Paris, France, 3–8 July 2011; pp. 3–8. [Google Scholar]
- Murthy, D.; Longwell, S.A. Twitter and disasters: The uses of Twitter during the 2010 Pakistan floods. Inf Commun. Soc. 2013, 16, 837–855. [Google Scholar] [CrossRef]
- Bosley, J.C.; Zhao, N.W.; Hill, S.; Shofer, F.S.; Asch, D.A.; Becker, L.B.; Merchant, R.M. Decoding twitter: Surveillance and trends for cardiac arrest and resuscitation communication. Resuscitation 2013, 84, 206–212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, A.E.; Hansen, H.M.; Murphy, J.; Richards, A.K.; Duke, J.; Allen, J.A. Methodological considerations in analyzing Twitter data. J. Nat. Cancer Inst. Monogr. 2013, 2013, 140–146. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Uddin, M.Y.S.; Al Amin, M.T.; Le, H.; Abdelzaher, T.; Szymanski, B.; Nguyen, T. On diversifying source selection in social sensing. In Proceedings of the Ninth International Conference on Networked Sensing (INSS), Antwerp, Belgium, 11–14 June 2012; pp. 1–8. [Google Scholar]
- Le, H.; Wang, D.; Ahmadi, H.; Uddin, M.Y.S.; Ko, Y.H.; Abdelzaher, T.; Wang, H. Apollo: A Data Distillation Service for Social Sensing; Tech. Rep.; University of Illinois Urbana-Champaign: Champaign, IL, USA, 2012. [Google Scholar]
- Rogstadius, J.; Vukovic, M.; Teixeira, C.A.; Kostakos, V.; Karapanos, E.; Laredo, J.A. CrisisTracker: Crowdsourced social media curation for disaster awareness. IBM J. Res. Dev. 2013, 57, 1–4. [Google Scholar] [CrossRef]
- Farzindar, A.; Khreich, W. A survey of techniques for event detection in twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Event detection and domain adaptation with convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 365–371. [Google Scholar]
- Burel, G.; Saif, H.; Fernandez, M.; Alani, H. On Semantics and Deep Learning for Event Detection in Crisis Situations. In Proceedings of the 14th International Conference (ESWC 2017), Portorož, Slovenia, 28 May–1 June 2017. [Google Scholar]
- Sit, M.A.; Koylu, C.; Demir, I. Identifying disaster-related tweets and their semantic, spatial and temporal context using deep learning, natural language processing and spatial analysis: A case study of Hurricane Irma. Int. J. Digit. Earth 2019, 12, 1205–1229. [Google Scholar] [CrossRef]
- Alam, F.; Ofli, F.; Imran, M. CrisisDPS: Crisis Data Processing Services. In Proceedings of the International Conference on Information Systems for Crisis Response and Management, Valencia, Spain, 19–22 May 2019. [Google Scholar]
- He, H.; Balakrishnan, A.; Eric, M.; Liang, P. Learning Symmetric Collaborative Dialogue Agents with Dynamic Knowledge Graph Embeddings. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Klingner, J. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Olteanu, A.; Castillo, C.; Diaz, F.; Vieweg, S. Crisislex: A lexicon for collecting and filtering microblogged communications in crises. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing EMNLP, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Test Accuracy | Test Precision | Test Recall | Test F1-Score |
|---|---|---|---|---|
| CNN [36] | - | - | - | 0.838 |
| LSTM [37] | 0.748 | - | - | 0.751 |
| CNN—DisKnow | 0.903 | 0.921 | 91.9 | 0.920 |
| Model | Test Accuracy | Test Precision | Test Recall | Test F1-Score |
|---|---|---|---|---|
| SVM [36] | - | - | - | 0.997 |
| CNN [38] | 0.930 | - | - | 0.928 |
| CNN—DisKnow | 0.884 | 0.888 | 0.876 | 0.882 |
| Component | Number of Tweets |
|---|---|
| Tweet Extraction and Filtering | 136 |
| Disaster Extraction (First CNN) | 9 |
| Disaster Extraction (Second CNN) | 7 |
| Threat Object Generation | 6 |
| Translated Tweet | Entities | Disaster |
|---|---|---|
| 1. Flames are on the roof of FISIPE Barreiro | FISIPE (Org) Barreiro (GPE) | Fire |
| 2. Help ! Fisipe burns in Barreiro | Fisipe (ORG) Barreiro (GPE) | Fire |
| 3. Flames FISIPE fire in Barreiro | FISIPE (ORG) Barreiro (GPE) | Fire |
| 4. The FISIPE fire was spread to the Vodafone do Barreiro store | FISIPE (ORG) Vodafone (ORG) Barreiro (GPE) | Fire |
| 5. Fire catastrophe FISIPE factory director Barreiro João Alberto suffered 3rd degree burns due to strong flames | FISIPE (ORG) Barreiro (GPE) João Alberto (PER) | Fire |
| 6. Help Water is overflowing at Remax do Barreiro since 12:30 pm Marta Almeida and Fernanda Torre are injured | Remax (Org) Barreiro (GPE) 12:30 (TIME) Marta Almeida (PER) Fernanda Torre (PER) | Flood |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boné, J.; Dias, M.; Ferreira, J.C.; Ribeiro, R. DisKnow: A Social-Driven Disaster Support Knowledge Extraction System. Appl. Sci. 2020, 10, 6083. https://doi.org/10.3390/app10176083
Boné J, Dias M, Ferreira JC, Ribeiro R. DisKnow: A Social-Driven Disaster Support Knowledge Extraction System. Applied Sciences. 2020; 10(17):6083. https://doi.org/10.3390/app10176083
Chicago/Turabian StyleBoné, João, Mariana Dias, João C. Ferreira, and Ricardo Ribeiro. 2020. "DisKnow: A Social-Driven Disaster Support Knowledge Extraction System" Applied Sciences 10, no. 17: 6083. https://doi.org/10.3390/app10176083