Phonocardiography Signals Compression with Deep Convolutional Autoencoder for Telecare Applications



Abstract
:1. Introduction
2. Related Work
2.1. Sound Compression
2.2. Convolutional Neural Networks
2.3. Autoencoder
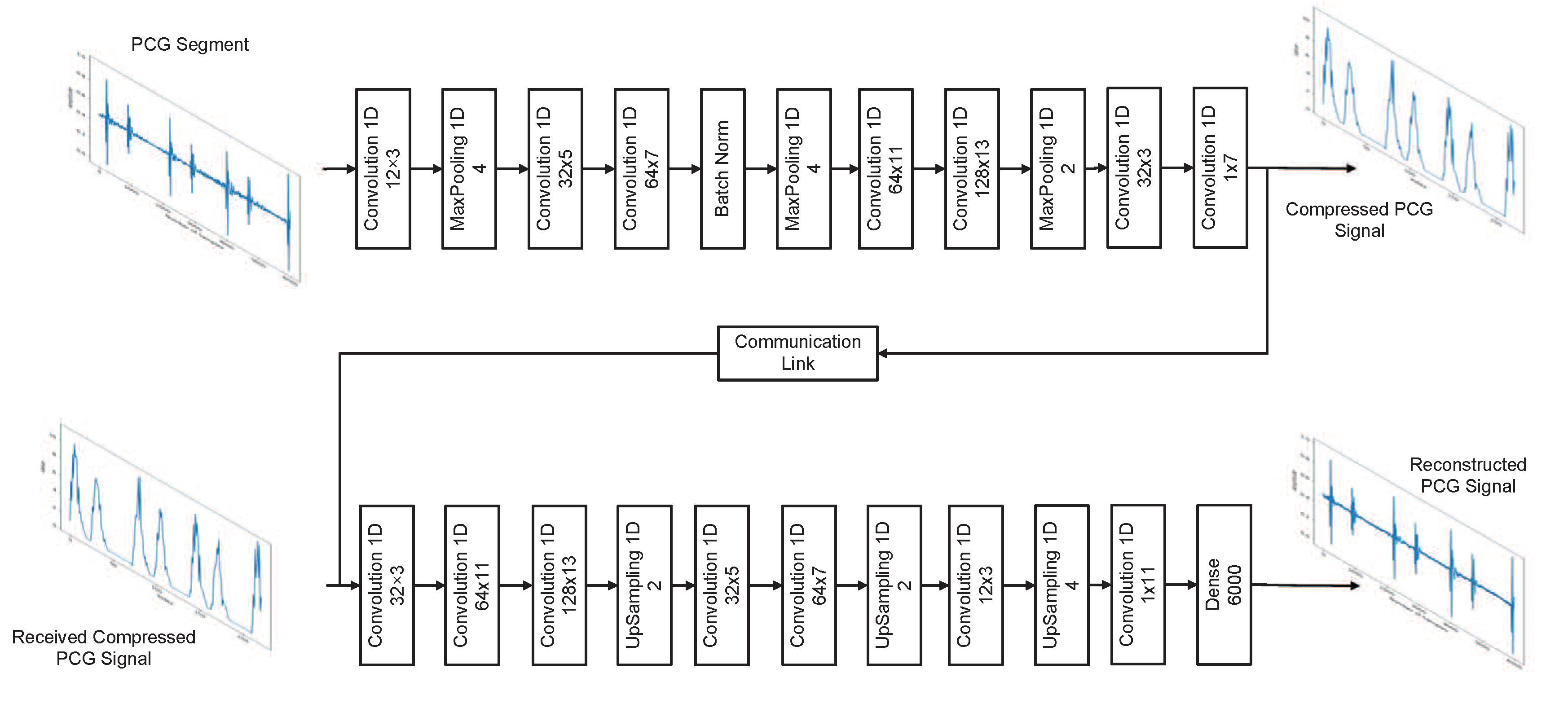
3. Method
3.1. Data Pre-Processing
- Normalization: the data are normalized, such that the values of all data sets are mapped into the ranges of [0, 1].
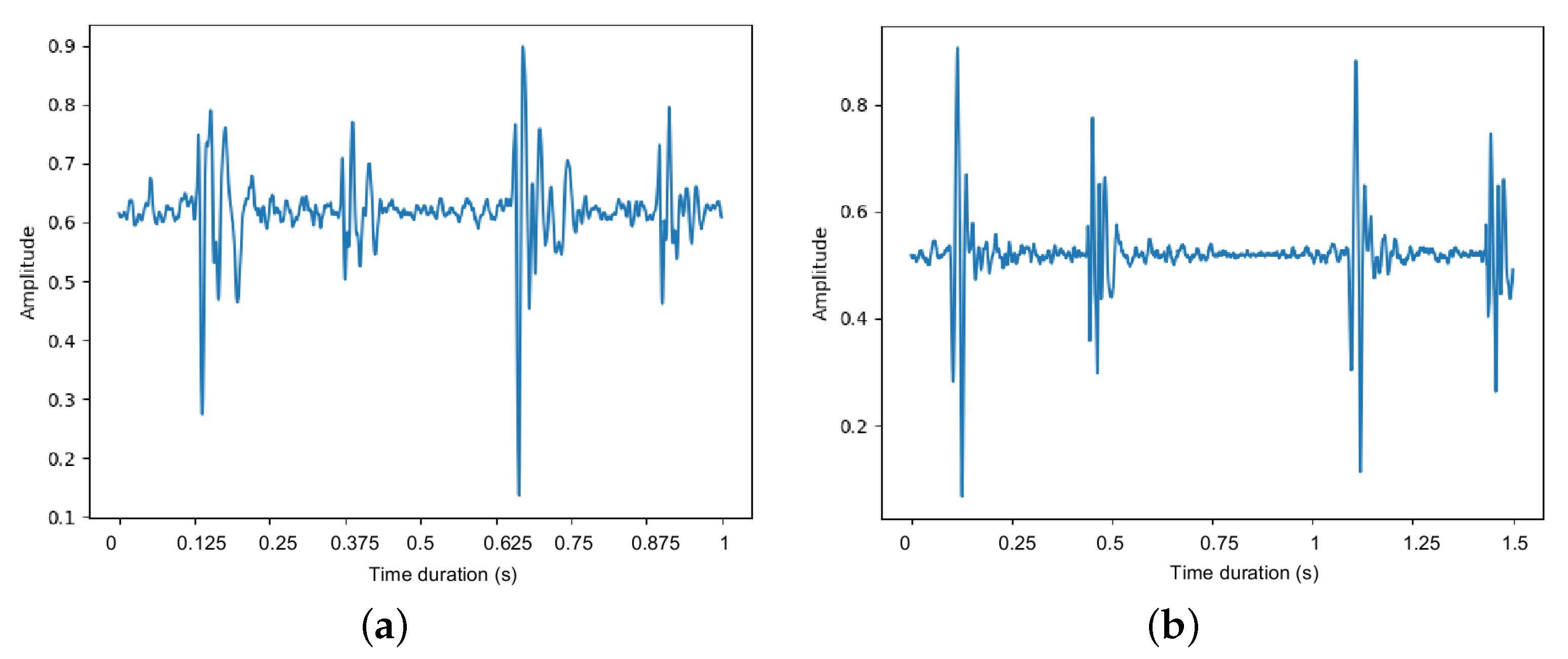
- Segmentation: we edit the heart sound into several fixed-length segments. The time duration of each segment is 3 s, which corresponds to 6000 samples at the sampling rate of 2 kHz. Note that each segment contains roughly four or five cardiac cycles.
- Overlapping: we apply a sliding window on the data segmentation to implement the data augmentation. Except for the first segment, each segment is overlapped with its previous segment by 93.33%, i.e., each segment has 400 new samples and keeps 5600 existing samples in the previous segment. It has been reported that such a time-shift-based data augmentation method is useful to prevent overfitting [36] when training the CNN networks [37].
3.2. Feature Selection
3.3. Proposed Network Model for the Deep Convolutional Autoencoder
4. Experiments
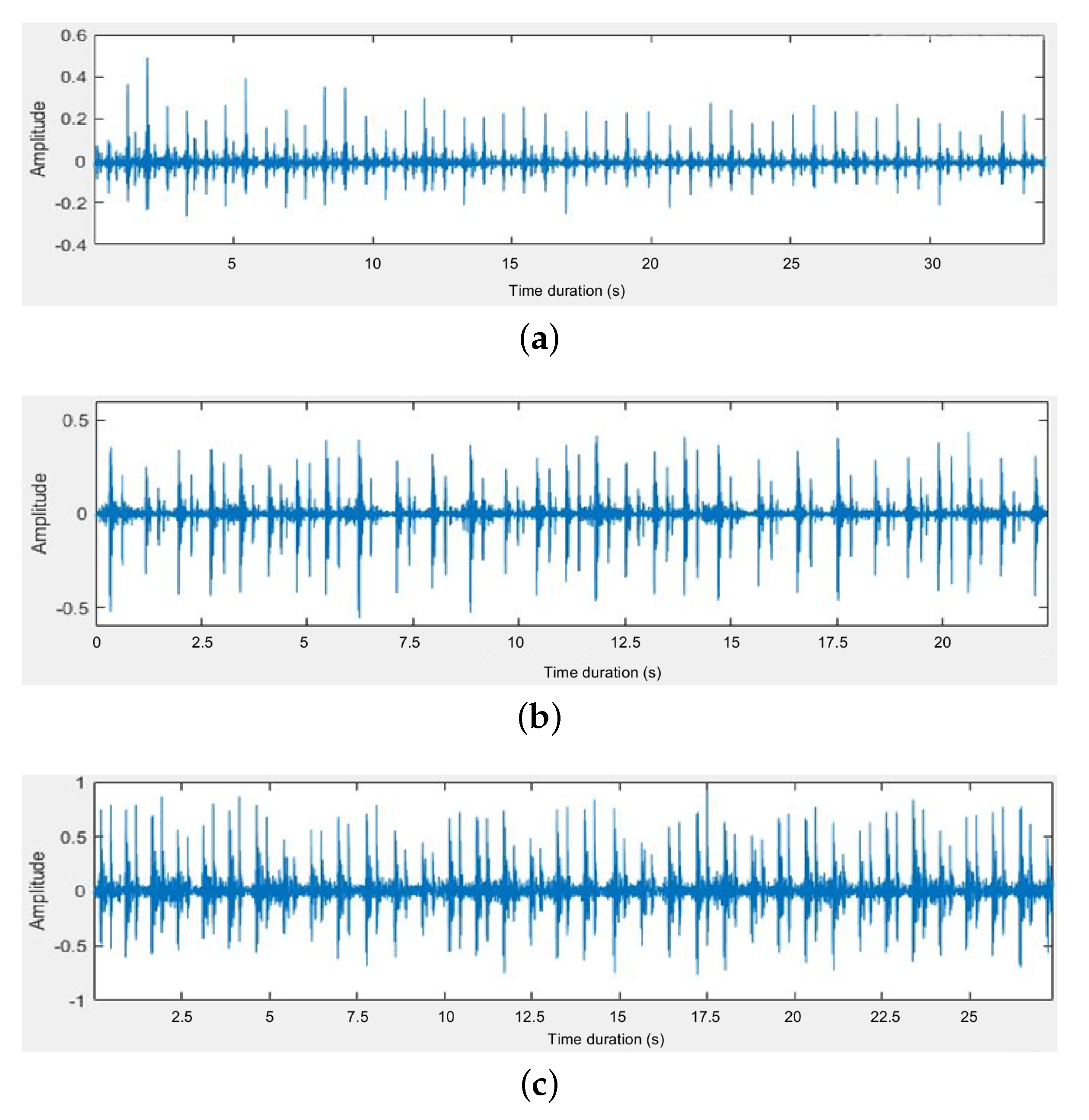
4.1. Dataset
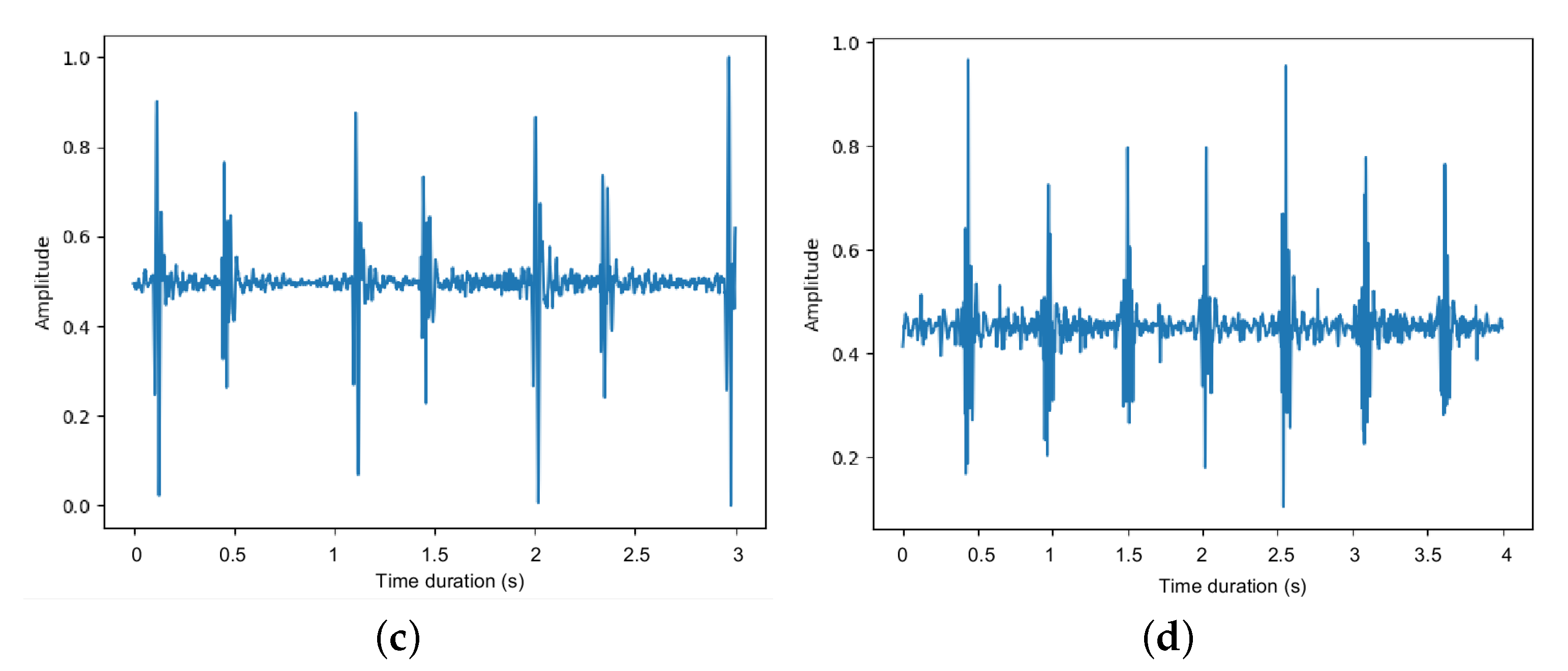
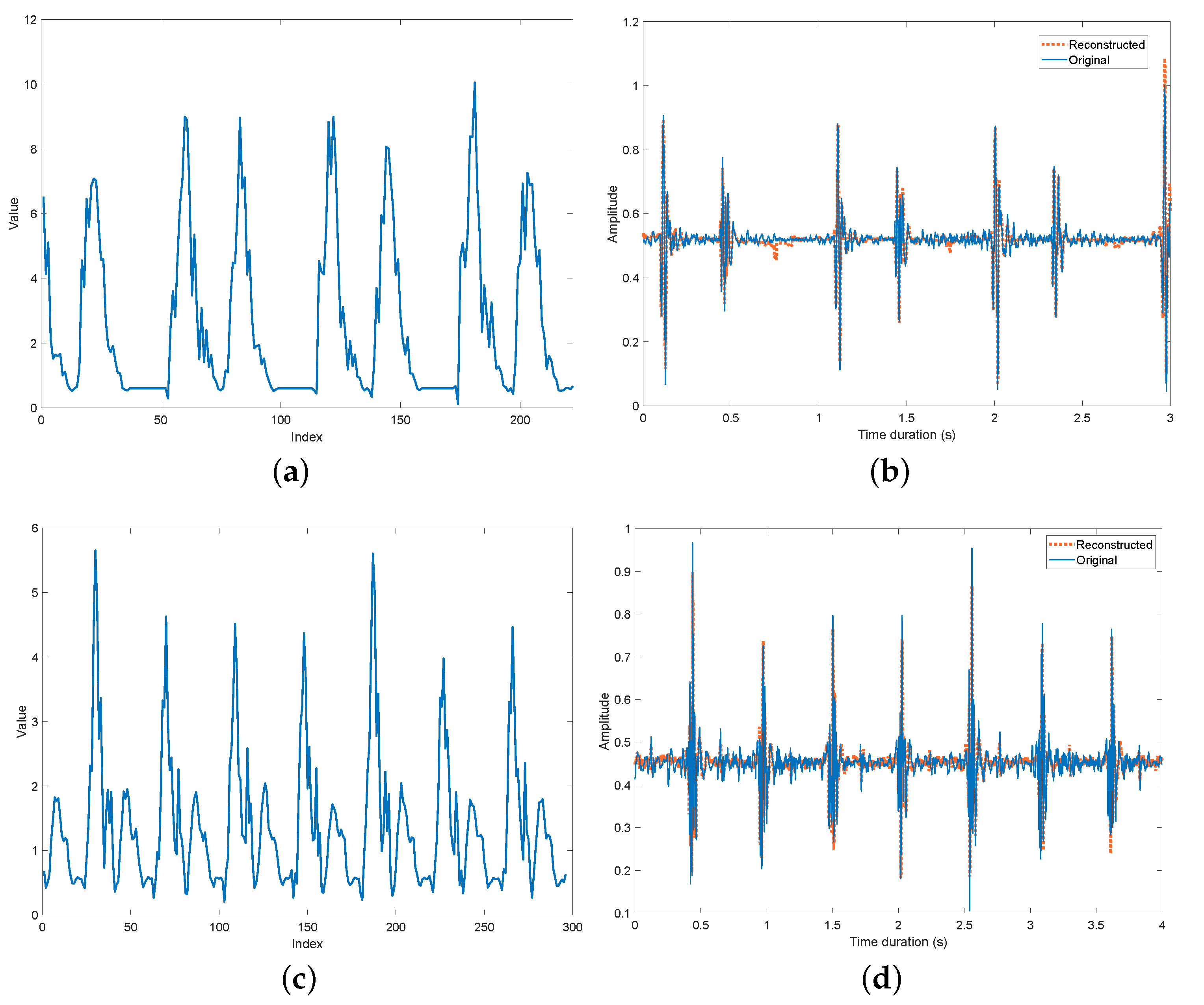
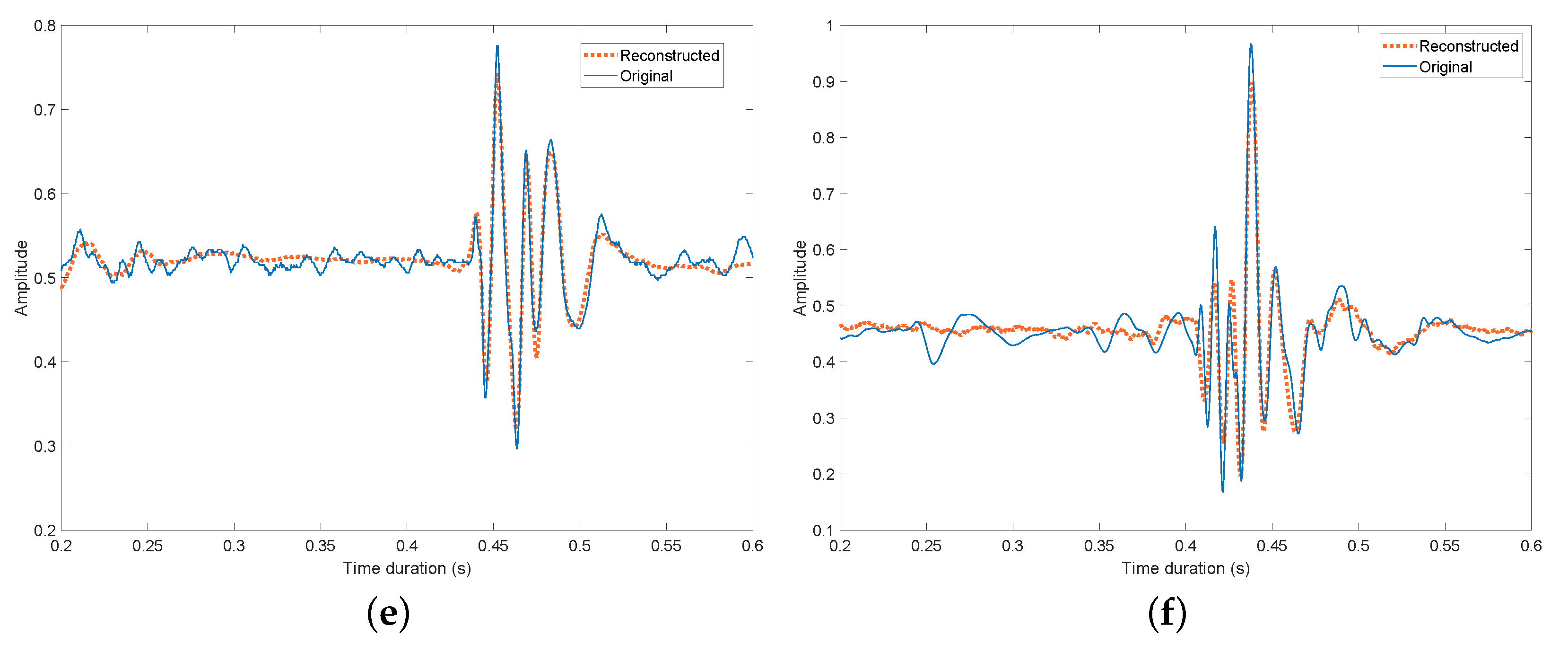
4.2. Results
4.2.1. Segment Length Evaluation
4.2.2. Compression Ratio Evaluation
4.2.3. Fixed-Point Issues
4.3. Communication Link Quality Issues
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Virani, S.S.; Alonso, A.; Benjamin, E.J.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Delling, F.N.; et al. Heart Disease and Stroke Statistics—2020 Update: A Report from the American Heart Association. Circulation 2020, 141, e139–e596. [Google Scholar] [CrossRef] [PubMed]
- Martins, M.; Gomes, P.; Oliveira, C.; Coimbra, M.; da Silva, H.P. Design and Evaluation of a Diaphragm for Electrocardiography in Electronic Stethoscopes. IEEE Trans. Biomed. Eng. 2020, 67, 391–398. [Google Scholar] [CrossRef] [PubMed]
- Babu, K.A.; Ramkumar, B.; Manikandan, M.S. Automatic Identification of S1 and S2 Heart Sounds Using Simultaneous PCG and PPG Recordings. IEEE Sensors J. 2018, 18, 9430–9440. [Google Scholar] [CrossRef]
- Abdel-Alim, O.; Hamdy, N.; El-Hanjouri, M.A. Heart Diseases Diagnosis Using Heart Sounds. In Proceedings of the Nineteenth National Radio Science Conference, Alexandra, Egypt, 19–21 March 2002; pp. 634–640. [Google Scholar] [CrossRef]
- Sumarna; Astono, J.; Purwanto, A.; Agustika, D.K. The Improvement of Phonocardiograph Signal (PCG) Representation Through the Electronic Stethoscope. In Proceedings of the 2017 4th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Yogyakarta, Indonesia, 19–21 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Habibzadeh, H.; Dinesh, K.; Rajabi Shishvan, O.; Boggio-Dandry, A.; Sharma, G.; Soyata, T. A Survey of Healthcare Internet of Things (HIoT): A Clinical Perspective. IEEE Internet Things J. 2020, 7, 53–71. [Google Scholar] [CrossRef]
- Ozkan, H.; Ozhan, O.; Karadana, Y.; Gulcu, M.; Macit, S.; Husain, F. A Portable Wearable Tele-ECG Monitoring System. IEEE Trans. Instrum. Meas. 2020, 69, 173–182. [Google Scholar] [CrossRef]
- Aazam, M.; Zeadally, S.; Harras, K.A. Health Fog for Smart Healthcare. IEEE Consum. Electron. Mag. 2020, 9, 96–102. [Google Scholar] [CrossRef]
- Qadri, Y.A.; Nauman, A.; Zikria, Y.B.; Vasilakos, A.V.; Kim, S.W. The Future of Healthcare Internet of Things: A Survey of Emerging Technologies. IEEE Commun. Surv. Tuts. 2020, 22, 1121–1167. [Google Scholar] [CrossRef]
- Fang, S.; Yang, Y. The Impact of Weather Condition on Radio-Based Distance Estimation: A Case Study in GSM Networks with Mobile Measurements. IEEE Tran. Veh. Technol. 2016, 65, 6444–6453. [Google Scholar] [CrossRef]
- Kim, S.; Hwang, D. Murmur-adaptive compression technique for phonocardiogram signals. Elect. Lett. 2016, 52, 183–184. [Google Scholar] [CrossRef]
- Blanco-Velasco, M.; Cruz-Roldán, F.; Godino-Llorente, J.; Blanco-Velasco, J.; Armiens-Aparicio, C.; López-Ferreras, F. On the use of PRD and CR parameters for ECG compression. Med. Eng. Phys. 2005, 27, 798–802. [Google Scholar] [CrossRef]
- Hans, M.; Schafer, R.W. Lossless compression of digital audio. IEEE Signal Process. Mag. 2001, 18, 21–32. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Shu, H.; Yu, R. Lossless audio compression in the new IEEE Standard for Advanced Audio Coding. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6934–6938. [Google Scholar] [CrossRef]
- Chen, S.; Luo, G.; Lin, T. Efficient fuzzy-controlled and hybrid entropy coding strategy lossless ECG encoder VLSI design for wireless body sensor networks. Elect. Lett. 2013, 49, 1058–1060. [Google Scholar] [CrossRef]
- Tang, H.; Zhang, J.; Sun, J.; Qiu, T.; Park, Y. Phonocardiogram Signal Compression Using Sound Repetition and Vector Quantization. Comput. Biol. Med. 2016, 71, 24–34. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Alajarin, J.; Ruiz-Merino, R. Wavelet and Wavelet Packet Compression of Phonocardiograms. Electron. Lett. 2004, 40, 1040–1041. [Google Scholar] [CrossRef]
- Manikandan, M.S.; Dandapat, S. Wavelet Energy based Compression of Phonocardiogram (PCG) Signal for Telecardiology. In Proceedings of the 2007 IET-UK International Conference on Information and Communication Technology in Electrical Sciences (ICTES 2007), Tamil Nadu, India, 20–22 December 2007; pp. 650–654. [Google Scholar]
- Patidar, S.; Pachori, R.B. Tunable-Q Wavelet Transform based Optimal Compression of Cardiac Sound Signals. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 2193–2197. [Google Scholar] [CrossRef]
- Selesnick, I.W. Wavelet Transform with Tunable Q-Factor. IEEE Trans. Signal Process. 2011, 59, 3560–3575. [Google Scholar] [CrossRef]
- Aggarwal, V.; Gupta, S.; Patterh, M.S.; Kaur, L. Analysis of Compressed Foetal Phono-Cardio-Graphy (PCG) Signals with Discrete Cosine Transform and Discrete Wavelet Transform. IETE J. Res. 2020, 1–7. [Google Scholar] [CrossRef]
- Suárez León, A.A.; Núñez Alvarez, J.R. 1D Convolutional Neural Network for Detecting Ventricular Heartbeats. IEEE Lat. Am. Trans. 2019, 17, 1970–1977. [Google Scholar] [CrossRef]
- Chowdhury, A.; Ross, A. Fusing MFCC and LPC Features Using 1D Triplet CNN for Speaker Recognition in Severely Degraded Audio Signals. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1616–1629. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Learning Deep Features to Recognise Speech Emotion Using Merged Deep CNN. IET Signal Process. 2018, 12, 713–721. [Google Scholar] [CrossRef]
- Park, H.; Yoo, C.D. CNN-Based Learnable Gammatone Filterbank and Equal-Loudness Normalization for Environmental Sound Classification. IEEE Signal Process. Lett. 2020, 27, 411–415. [Google Scholar] [CrossRef]
- Kim, S.; Han, G. 1D CNN Based Human Respiration Pattern Recognition using Ultra Wideband Radar. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 411–414. [Google Scholar] [CrossRef]
- Xie, X.; Wang, B.; Wan, T.; Tang, W. Multivariate Abnormal Detection for Industrial Control Systems Using 1D CNN and GRU. IEEE Access 2020, 8, 88348–88359. [Google Scholar] [CrossRef]
- Guan, L.; Hu, F.; Al-Turjman, F.; Khan, M.B.; Yang, X. A Non-Contact Paraparesis Detection Technique Based on 1D-CNN. IEEE Access 2019, 7, 182280–182288. [Google Scholar] [CrossRef]
- Al-Marridi, A.Z.; Mohamed, A.; Erbad, A. Convolutional Autoencoder Approach for EEG Compression and Reconstruction in m-Health Systems. In Proceedings of the 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; pp. 370–375. [Google Scholar] [CrossRef]
- Baldi, P. Autoencoders, Unsupervised Learning, and Deep Architectures. In Proceedings of the 2011 International Conference on Unsupervised and Transfer Learning Workshop, Bellevue, WA, USA, 2 July 2012; Volume 27, pp. 37–49. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D Convolutional Neural Networks and Applications: A Survey. arXiv 2019, arXiv:eess.SP/1905.03554. [Google Scholar]
- Lai, Y.; Zheng, W.; Tang, S.; Fang, S.; Liao, W.; Tsao, Y. Improving the performance of hearing aids in noisy environments based on deep learning technology. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 404–408. [Google Scholar] [CrossRef]
- Chiang, H.; Hsieh, Y.; Fu, S.; Hung, K.; Tsao, Y.; Chien, S. Noise Reduction in ECG Signals Using Fully Convolutional Denoising Autoencoders. IEEE Access 2019, 7, 60806–60813. [Google Scholar] [CrossRef]
- Chuang, F.K.; Wang, S.S.; Hung, J.W.; Tsao, Y.; Fang, S.H. Speaker-Aware Deep Denoising Autoencoder with Embedded Speaker Identity for Speech Enhancement. In Proceedings of the 2019 Interspeech, Graz, Austria, 15–19 September 2019; pp. 3173–3177. [Google Scholar] [CrossRef] [Green Version]
- Khan, F.N.; Lau, A.P.T. Robust and Efficient Data Transmission over Noisy Communication Channels Using Stacked and Denoising Autoencoders. China Commun. 2019, 16, 72–82. [Google Scholar] [CrossRef]
- Fang, S.; Chang, W.; Tsao, Y.; Shih, H.; Wang, C. Channel State Reconstruction Using Multilevel Discrete Wavelet Transform for Improved Fingerprinting-Based Indoor Localization. IEEE Sensors J. 2016, 16, 7784–7791. [Google Scholar] [CrossRef]
- Keren, G.; Deng, J.; Pohjalainen, J.; Schuller, B. Convolutional Neural Networks with Data Augmentation for Classifying Speakers’ Native Language. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 2393–2397. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Springer, D.; Clifford, G.D. Performance of an Open-source Heart Sound Segmentation Algorithm on Eight Independent Databases. Physiol. Meas. 2017, 38, 1730–1745. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS’12 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:cs.CV/1409.1556. [Google Scholar]
- Giri, E.P.; Fanany, M.I.; Arymurthy, A.M.; Wijaya, S.K. Ischemic stroke identification based on EEG and EOG using 1D convolutional neural network and batch normalization. Proceedings of 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Malang, Indonesia, 15–16 October 2016; pp. 484–491. [Google Scholar] [CrossRef]
- Liu, C.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.W.; et al. An Open Access Database for the Evaluation of Heart Sound Algorithms. Physiol. Meas. 2016, 37, 2181–2213. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:cs.LG/1412.6980. [Google Scholar]
- Němcová, A.; Smisek, R.; Maršánová, L.; Smital, L.; Vitek, M. A Comparative Analysis of Methods for Evaluation of ECG Signal Quality after Compression. BioMed Res. Int. 2018, 2018, 186851. [Google Scholar] [CrossRef] [PubMed]
- Samajdar, A.; Zhu, Y.; Whatmough, P.; Mattina, M.; Krishna, T. SCALE-Sim: Systolic CNN Accelerator Simulator. arXiv 2018, arXiv:cs.DC/1811.02883. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:abs/1704.04861. [Google Scholar]
- Rabano, S.L.; Cabatuan, M.K.; Sybingco, E.; Dadios, E.P.; Calilung, E.J. Common Garbage Classification Using MobileNet. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November–2 December 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Sosa, A. Real-Time Deep Learning in Mobile Application. Available online: https://medium.com/vitalify-asia/real-time-deep-learning-in-mobile-application-25cf601a8976 (accessed on 3 August 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Layer Function | No. of Filter × Kernel Size | Activation Function | No. of Trainable Param. | Output Size |
|---|---|---|---|---|---|
| 1 | Conv 1D | 12 × 3 | ReLU | 48 | 6000 × 12 |
| 2 | MaxPool 1D | - | - | 0 | 1500 × 12 |
| 3 | Conv 1D | 32 × 5 | ReLU | 1952 | 1500 × 32 |
| 4 | Conv 1D | 64 × 7 | ReLU | 14,400 | 1500 × 64 |
| 5 | Batch Norm | - | - | 256 | 1500 × 64 |
| 6 | MaxPool 1D | - | - | 0 | 375 × 64 |
| 7 | Conv 1D | 64 × 11 | ReLU | 45,120 | 375 × 64 |
| 8 | Conv 1D | 128 × 13 | ReLU | 106,624 | 375 × 128 |
| 9 | MaxPool 1D | - | - | 0 | 187 × 128 |
| 10 | Conv 1D | 32 × 3 | ReLU | 12,320 | 187 × 32 |
| 11 | Conv 1D | 1 × 7 | ReLU | 225 | 187 × 1 |
| No. | Layer Function | No. of Filter × Kernel Size | Activation Function | No. of Trainable Param. | Output Size |
|---|---|---|---|---|---|
| 1 | Conv 1D | 32 × 3 | ReLU | 128 | 187 × 32 |
| 2 | Conv 1D | 64 × 11 | ReLU | 22,592 | 187 × 64 |
| 3 | Conv 1D | 128 × 13 | ReLU | 106,624 | 187 × 128 |
| 4 | Upsampling | - | - | 0 | 374 × 128 |
| 5 | Conv 1D | 32 × 5 | ReLU | 20,512 | 374 × 32 |
| 6 | Conv 1D | 64 × 7 | ReLU | 14,400 | 374 × 64 |
| 7 | Upsampling | - | - | 0 | 748 × 64 |
| 8 | Conv 1D | 12 × 3 | ReLU | 2316 | 748 × 12 |
| 9 | Upsampling | - | - | 0 | 2992 × 12 |
| 10 | Conv 1D | 1 × 11 | ReLU | 133 | 2992 × 1 |
| 11 | Dense | 6000 | Sigmoid | 17,958,000 | 6000 |
| Segment Length | 2000 | 3000 | 6000 | 8000 |
| Total Segments | 220,470 | 146,980 | 73,490 | 55,117 |
| PRD | 4.696% | 4.668% | 4.495% | 4.571% |
| Parameters | ≈4.3 × 10 | ≈9.3 × 10 | ≈3.6 × 10 | ≈6.4 × 10 |
| CR | 27 | 30 | 32 | 36 |
| Length for each Compressed Segment | 222 | 200 | 187 | 166 |
| Epoch | 389 | 368 | 362 | 345 |
| PRD | 4.416% | 4.540% | 4.601% | 4.972% |
| Max. Weight | Min. Weight | Max. Bias | Min. Bias | |
|---|---|---|---|---|
| Encoder | ||||
| Layer 1 | 0.39540452 | −0.9235797 | 0.01453111 | −0.023743011 |
| Layer 2 | - | - | - | - |
| Layer 3 | 0.6052952 | −0.8330374 | 0.033396643 | −0.054285403 |
| Layer 4 | 0.48703766 | −0.7313971 | 0.1558624 | −0.09510201 |
| Layer 5 | 0.3240463 | 0.9359407 | 0.054475907 | −0.06052749 |
| Layer 6 | - | - | - | - |
| Layer 7 | 0.24897571 | −0.49508682 | 0.052439176 | −0.082461566 |
| Layer 8 | 0.24272417 | −0.68896836 | 0.10369389 | −0.098621696 |
| Layer 9 | - | - | - | - |
| Layer 10 | 0.39203942 | −0.47291782 | 0.10768643 | −0.08815236 |
| Layer 11 | 0.52950436 | −0.3272031 | 0.13014604 | 0.13014604 |
| Decoder | ||||
| Layer 1 | 0.31976736 | −0.33887985 | 0.17345946 | −0.12427106 |
| Layer 2 | 0.33624372 | −0.7039436 | 0.11306709 | −0.10122227 |
| Layer 3 | 0.38897622 | −0.6367118 | 0.04357844 | −0.16350096 |
| Layer 4 | - | - | - | - |
| Layer 5 | 0.7269572 | −0.2668362 | 0.02763602 | −0.04904448 |
| Layer 6 | 0.5182032 | −0.63450485 | 0.039916832 | −0.038330693 |
| Layer 7 | - | - | - | - |
| Layer 8 | 0.5744175 | −0.563132 | 0.024111861 | −0.024702776 |
| Layer 9 | - | - | - | - |
| Layer 10 | 0.25195208 | −0.30334103 | 0.01607588 | 0.01607588 |
| Layer 11 | 0.44964585 | −0.87970144 | 0.071185686 | 0.071185686 |
| Word-Length | Fractional Length | PRD(%) |
|---|---|---|
| Floating-32 | - | 4.6015 |
| Fixed-20 | 17 | 4.6031 |
| Fixed-16 | 13 | 4.6127 |
| Fixed-12 | 9 | 4.6437 |
| Fixed-11 | 8 | 4.6639 |
| Fixed-10 | 7 | 4.7923 |
| Fixed-9 | 6 | 5.2162 |
| Fixed-8 | 5 | 6.1334 |
| BER | DCT Method @ CR of 15 | Proposed Method @ CR of 32 | ||
|---|---|---|---|---|
| PRD | QS | PRD | QS | |
| 43.700% | 0.343 | 7.435% | 4.304 | |
| 14.048% | 1.068 | 5.094% | 6.282 | |
| 6.436% | 2.331 | 4.815% | 6.646 | |
| 5.536% | 2.710 | 4.793% | 6.676 | |
| 5.491% | 2.732 | 4.793% | 6.676 | |
| 0 | 5.480% | 2.737 | 4.792% | 6.678 |
| Layer ID | Required Number of MAC | |
|---|---|---|
| Conv 1D (12, 3) | (6000, 1, 12, 3) | 216,000 |
| Conv 1D (32, 5) | (1500, 12, 32, 5) | 2,880,000 |
| Conv 1D (64, 7) | (1500, 32, 64, 7) | 21,504,000 |
| Conv 1D (64, 11) | (375, 64, 64, 11) | 16,896,000 |
| Conv 1D (128, 13) | (375, 64, 128, 13) | 39,936,000 |
| Conv 1D (32, 3) | (187, 128, 32, 3) | 22,978,576 |
| Conv 1D (1, 7) | (187, 32, 1, 7) | 41,888 |
| Layer ID | Required Number of MAC | |
|---|---|---|
| Conv 1D (32, 3) | (187, 1, 32, 3) | 17,952 |
| Conv 1D (64, 11) | (187, 32, 64, 11) | 4,212,736 |
| Conv 1D (128, 13) | (187, 64, 128, 13) | 19,914,752 |
| Conv 1D (32, 5) | (374, 128, 32, 5) | 7,659,520 |
| Conv 1D (64, 7) | (374, 32, 64, 7) | 5,361,664 |
| Conv 1D (12, 3) | (748, 64, 12, 3) | 1,723,392 |
| Conv 1D (1, 11) | (2,992, 12, 1, 11) | 394,944 |
| (a) MobileUNet | (b) Proposed Architecture | ||
|---|---|---|---|
| Layer | Eyeriss (Cycle) | Layer | Eyeriss (Cycle) |
| Layer1 | 111,969 | Layer1 | 6016 |
| Layer2 | 291,000 | Layer2 | 22,960 |
| Layer3 | 188,672 | Layer3 | 145,386 |
| Layer4 | 148,416 | Layer4 | 118,491 |
| Layer5 | 190,208 | Layer5 | 279,700 |
| Layer6 | 282,336 | Layer6 | 21,088 |
| Layer7 | 348,928 | Layer7 | 3906 |
| Layer8 | 73,728 | ||
| Layer9 | 171,536 | ||
| Layer10 | 134,592 | ||
| Total | 1,941,385 | Total | 597,547 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chien, Y.-R.; Hsu, K.-C.; Tsao, H.-W. Phonocardiography Signals Compression with Deep Convolutional Autoencoder for Telecare Applications. Appl. Sci. 2020, 10, 5842. https://doi.org/10.3390/app10175842
Chien Y-R, Hsu K-C, Tsao H-W. Phonocardiography Signals Compression with Deep Convolutional Autoencoder for Telecare Applications. Applied Sciences. 2020; 10(17):5842. https://doi.org/10.3390/app10175842
Chicago/Turabian StyleChien, Ying-Ren, Kai-Chieh Hsu, and Hen-Wai Tsao. 2020. "Phonocardiography Signals Compression with Deep Convolutional Autoencoder for Telecare Applications" Applied Sciences 10, no. 17: 5842. https://doi.org/10.3390/app10175842